一、Spark介紹
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Spark是一個快速且多功能的集群計算系統。它為多種不同語言提供高級API,和支持一般執行圖的優化引擎。它也有豐富的高級工具集,Spark SQL進行結構化數據的處理,MLib處理機器學習,GraphX進行圖處理,以及Spark Streaming流計算。
組成
它的主要組件有:
- SparkCore
- 將分佈式數據抽象為彈性分佈式數據集(RDD),實現了應用任務調度、RPC、序列化和壓縮,併為運行在其上的上層組件提供API。
- SparkSQL
- Spark Sql 是Spark來操作結構化數據的程序包,可以讓我使用SQL語句的方式來查詢數據,Spark支持 多種數據源,包含Hive表,parquest以及JSON等內容。
- SparkStreaming
- MLlib
- GraphX
- BlinkDB
- Tachyon
返回一個包含數據集前n個元素的數組
二、WordCount程序講解
編寫代碼
scala程序編寫
object WordCountDemo {
def main(args: Array[String]): Unit = {
//創建Spark配置對象
val conf = new SparkConf().setMaster("local").setAppName("MyApp")
//通過conf創建sc
val sc = new SparkContext(conf)
//讀取文件
val rdd1 = sc.textFile("/Users/README.md")
//計算
val rdd2 = rdd1.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
//打印
rdd2.take(10).foreach(println)
}
}
java程序編寫
public class WordCountJavaDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("myapp").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> rdd1 = sc.textFile("/Users/README.md");
JavaRDD<String> rdd2 = rdd1.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
List<String> list = new ArrayList<>();
String[] arr = s.split(" ");
for (String ss : arr) {
list.add(ss);
}
return list.iterator();
}
});
JavaPairRDD<String, Integer> rdd3 = rdd2.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairRDD<String, Integer> rdd4 = rdd3.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
List<Tuple2<String, Integer>> list = rdd4.collect();
for (Tuple2<String, Integer> t : list) {
System.out.println(t._1() + " " + t._2());
}
}
}
三、原理介紹
RDD
- 由一系列Partition組成
- RDD之間有一系列依賴關係
- RDD每個算子實際上是作用在每個Partition上
- RDD會提供一系列最佳位置
- 分區器是作用在KV格式的RDD上
RDD會在多個節點上存儲,就和hdfs的分佈式道理是一樣的。hdfs文件被切分為多個block存儲在各個節點上,而RDD是被切分為多個partition。不同的partition可能在不同的節點上。
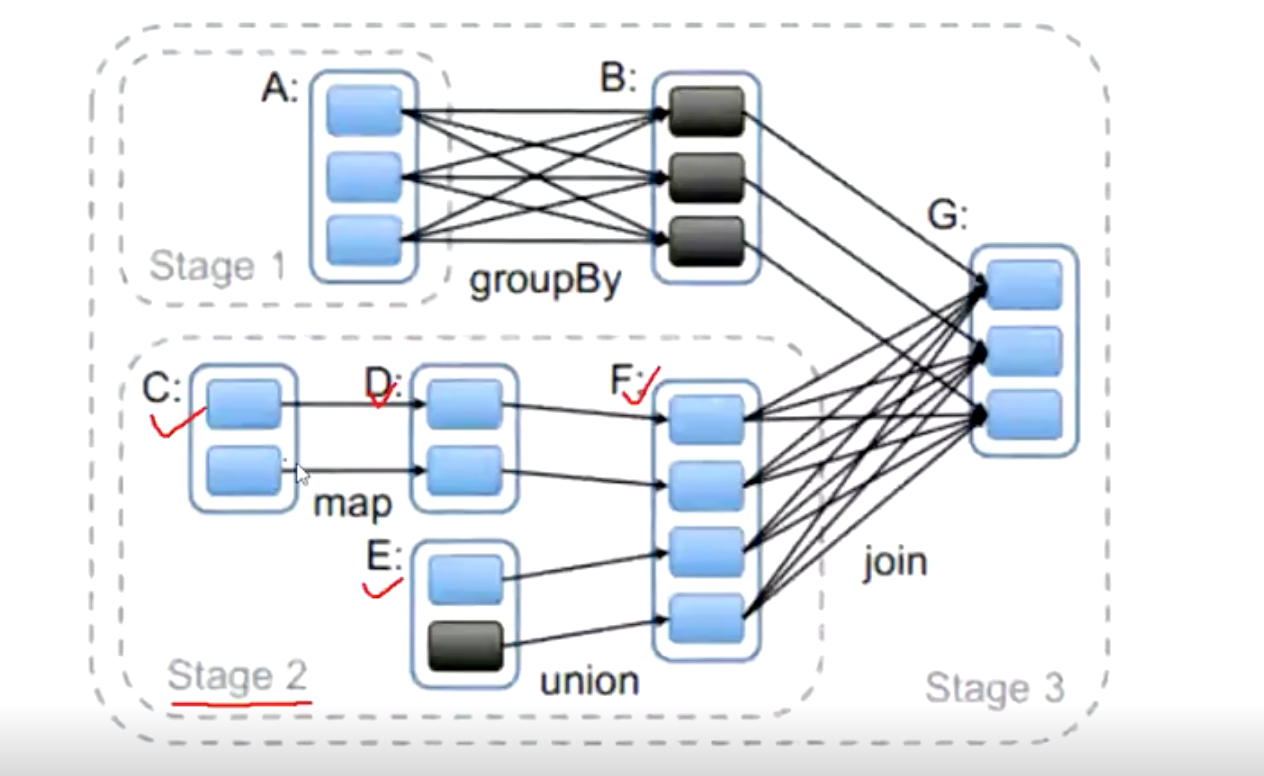
Spark執行流程
1、Driver
分發task,在分發之前,會調用RDD的方法,獲取partition的位置。
將task的計算結果,拉回到Driver端
Driver是一個JVM進程
2、Worker
寬依賴、窄依賴
圖中stage2的并行度是4,也就是有4個task。
寬依賴
父RDD與子RDD,partition的關係是一對多,就是寬依賴。寬依賴於shuffle對應。
窄依賴
父RDD與子RDD,partition的關係是一對一或多對一,就是窄依賴。
四、Spark常用算子
Transformation算子
特點:懶執行
(1)map
map的輸入變換函數應用於RDD中所有元素
(2)flatMap
flatMap與map區別在於map為“映射”,而flatMap“先映射,后扁平化”,map對每一次(func)都產生一個元素,返回一個對象,而flatMap多一步就是將所有對象合併為一個對象。
(3)flatMapValues
每個元素的Value被輸入函數映射為一系列的值,然後這些值再與原RDD中的Key組成一系列新的KV對。
代碼
x = sc.parallelize([("a", ["x", "y", "z"]), ("b", ["p", "r"])])
def f(x): return x
x.flatMapValues(f).collect()
打印結果
[('a', 'x'), ('a', 'y'), ('a', 'z'), ('b', 'p'), ('b', 'r')]
filter
過濾操作,滿足filter內function函數為true的RDD內所有元素組成一個新的數據集。
(4)groupByKey
主要作用是將相同的所有的鍵值對分組到一個集合序列當中,其順序是不確定的。
(5)reduceByKey
與groupByKey類似,卻有不同。如(a,1), (a,2), (b,1), (b,2)。groupByKey產生中間結果為( (a,1), (a,2) ), ( (b,1), (b,2) )。而reduceByKey為(a,3), (b,3)。
reduceByKey主要作用是聚合,groupByKey主要作用是分組。
(6)take
Action算子
特點:立即觸發執行
五、SparkSQL
介紹
Spark SQL is a Spark module for structured data processing. Unlike the basic Spark RDD API, the interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimizations. There are several ways to interact with Spark SQL including SQL and the Dataset API. When computing a result the same execution engine is used, independent of which API/language you are using to express the computation. This unification means that developers can easily switch back and forth between different APIs based on which provides the most natural way to express a given transformation.
SparkSQL是Spark的一個用來處理結構化數據的模塊。使用類似SQL的方式訪問Hadoop,實現MR計算。
Datasets的概念
A Dataset is a distributed collection of data. Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine. A Dataset can be constructed from JVM objects and then manipulated using functional transformations (map, flatMap, filter, etc.). The Dataset API is available in Scala and Java. Python does not have the support for the Dataset API. But due to Python’s dynamic nature, many of the benefits of the Dataset API are already available (i.e. you can access the field of a row by name naturally row.columnName). The case for R is similar.
Dataset是分佈式數據集合。
DataFrames概念
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. The DataFrame API is available in Scala, Java, Python, and R. In Scala and Java, a DataFrame is represented by a Dataset of Rows. In the Scala API, DataFrame is simply a type alias of Dataset[Row]. While, in Java API, users need to use Dataset to represent a DataFrame.
基本使用
(1)創建DataFrames
數據
{"id":"1","name":"zhangsan","age":"12"}
{"id":"2","name":"lisi","age":"12"}
{"id":"3","name":"wangwu","age":"12"}
代碼
object SparkSqlDemo {
def main(args: Array[String]): Unit = {
//創建Spark配置對象
val conf = new SparkConf().setMaster("local[4]").setAppName("MyApp");
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config(conf)
.getOrCreate()
val df = spark.read.json("/Users/opensource/dev-problem/source/people_sample_json.json");
df.show()
}
}
(2)查詢
val df = spark.read.json("/Users/fangzhijie/opensource/dev-problem/source/people_sample_json.json");
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people WHERE name = 'zhangsan'")
sqlDF.show()
六、SparkStreaming
介紹
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.
基本使用
(1)簡單使用
object SparkStreamingDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//創建Spark流上下文
val ssc = new StreamingContext(conf, Seconds(1))
//創建Socket文本流
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
//啟動
ssc.start()
//等待結束
ssc.awaitTermination() // Wait for the computation to terminate
}
}
使用shell命令監聽端口,輸入待計算內容
$ nc -lk 9999
原理
SparkStreaming的編程抽象是離散化流(DStream),它是一個RDD序列,每個RDD代表數據流中一個時間片內的數據。
參考文檔
《Spark快速大數據分析》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※大陸寄台灣空運注意事項
※大陸海運台灣交貨時間多久?
※避免吃悶虧無故遭抬價!台中搬家公司免費估價,有契約讓您安心有保障!