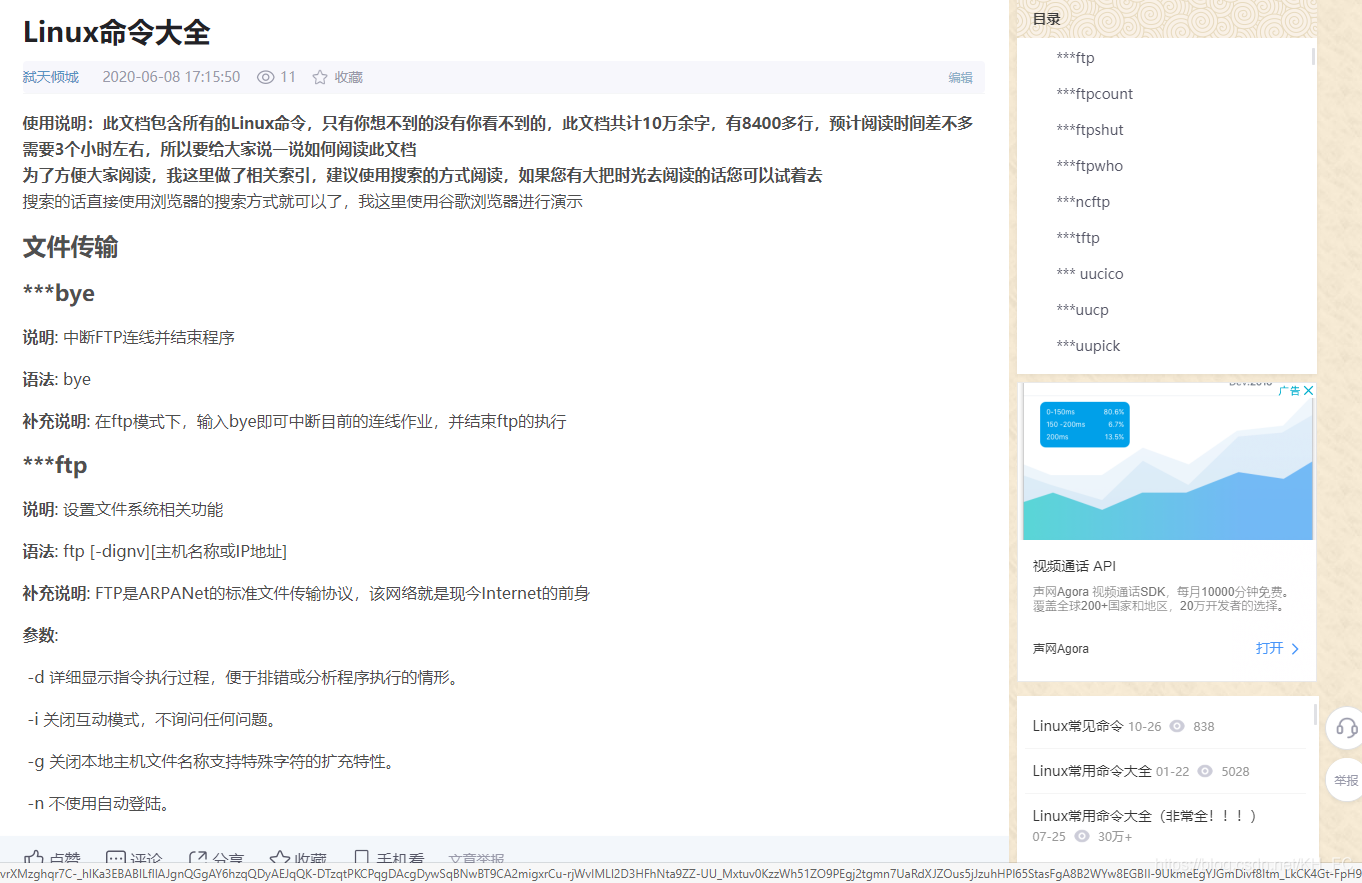
此文檔显示內容不全建議去CSDN進行閱讀Linux命令總結大全,包含所有linux命令
使用說明:此文檔包含所有的Linux命令,只有你想不到的沒有你看不到的,此文檔共計10萬餘字,有8400多行,預計閱讀時間差不多需要3個小時左右,所以要給大家說一說如何閱讀此文檔
為了方便大家閱讀,我這裏做了相關索引,建議使用搜索的方式閱讀,如果您有大把時光去閱讀的話您可以試着去
第二個方法就是找我要电子版文檔
搜索的話直接使用瀏覽器的搜索方式就可以了,我這裏使用谷歌瀏覽器進行演示
打開文檔
打開谷歌的搜索,鍵入ctrl+f
右上角出現搜索框后,直接在搜索框中輸入要查詢的命令,但是查詢結果有很多,如我直接輸入ls
共計123個結果,如果要準確搜索您需要在命令前面加三個*號,注意後面不要加空格
這下只有6個結果了
文件傳輸
***bye
說明: 中斷FTP連線並結束程序
語法: bye
補充說明: 在ftp模式下,輸入bye即可中斷目前的連線作業,並結束ftp的執行
***ftp
說明: 設置文件系統相關功能
語法: ftp [-dignv][主機名稱或IP地址]
補充說明: FTP是ARPANet的標準文件傳輸協議,該網絡就是現今Internet的前身
參數:
-d 詳細显示指令執行過程,便於排錯或分析程序執行的情形。
-i 關閉互動模式,不詢問任何問題。
-g 關閉本地主機文件名稱支持特殊字符的擴充特性。
-n 不使用自動登陸。
-v 显示指令執行過程。
***ftpcount
功能說明: 显示目前以FTP登入的用戶人數。
語法: ftpcount
補充說明: 執行這項指令可得知目前用FTP登入系統的人數以及FTP登入人數的上限。
***ftpshut
功能說明: 在指定的時間關閉FTP服務器。
語法: ftpshut [-d<分鐘>][-l<分鐘>][關閉時間][“警告信息”]
補充說明: 本指令提供系統管理者在設置的時間關閉FTP服務器,且能在關閉之前發出警告信息通知用戶。關閉時間若設置後為”none”,則會馬上關閉服務器。如果採用”+30″的方式來設置表示服務器在30分鐘之後關閉。依次類推,假設使用”1130″的格式則代表服務器會在每日的11時30分關閉,時間格式為24小時制。FTP服務器關閉后,在/etc目錄下會產生一個名稱為shutmsg的文件,把它刪除后即可再度啟動FTP服務器的功能。
參數:
-d<分鐘> 切斷所有FTP連線時間。
-l<分鐘> 停止接受FTP登入的時間。
***ftpwho
功能說明: 显示目前所有以FTP登入的用戶信息。
語法: ftpwho
補充說明: 執行這項指令可得知目前用FTP登入系統的用戶有那些人,以及他們正在進行的操作。
***ncftp
功能說明: 傳輸文件。
語法: ncftp [主機或IP地址]
補充說明: FTP讓用戶得以下載存放於服務器主機的文件,也能將文件上傳到遠端主機放置。NcFTP是文字模式FTP程序的佼佼者,它具備多樣特色, 包括显示傳輸速率,下載進度,自動續傳,標住書籤,可通過防火牆和代理服務器等。
***tftp
功能說明: 傳輸文件。
語法: tftp [主機名稱或IP地址]
補充說明: FTP讓用戶得以下載存放於遠端主機的文件,也能將文件上傳到遠端主機放置。tftp是簡單的文字模式ftp程序,它所使用的指令和FTP類似。
*** uucico
功能說明: UUCP文件傳輸服務程序。
語法: uucico [-cCDefqvwz][-i<類型>][-I<文件>][-p<連接端口號碼>][-][-rl][-s<主機>][-S<主機>][-u<用戶>][-x<類型>][–help]
補充說明: uucico是用來處理uucp或uux送到隊列的文件傳輸工具。uucico有兩種工作模式:主動模式和附屬模式。當在主動模式下時,uucico會調用遠端主機;在附屬模式下時,uucico則接受遠端主機的調用。
參數:
-c或–quiet 當不執行任何工作時,不要更改記錄文件的內容及更新目前的狀態。
-C或–ifwork 當有工作要執行時,才調用-s或-S參數所指定主機。
-D或–nodetach 不要與控制終端機離線。
-e或–loop 在附屬模式下執行,並且出現要求登入的提示畫面。
-f或–force 當執行錯誤時,不等待任何時間即重新調用主機。
-i<類型>或–stdin<類型> 當使用到標準輸入設備時,指定連接端口的類型。
-I<文件>–config<文件> 指定使用的配置文件。
-l或–prompt 出現要求登入的提示畫面。
-p<連接端口號碼>或-port<連接端口號碼> 指定連接端口號碼。
-q或–quiet 不要啟動uuxqt服務程序。
-r0或–slave 以附屬模式啟動。
-s<主機>或–system<主機> 調用指定的主機。
-u<用戶>或–login<用戶> 指定登入的用戶帳號,而不允許輸入任意的登入帳號。
-v或–version 显示版本信息,並且結束程序。
-w或–wait 在主動模式下,當執行調用動作時,則出現要求登入的提示畫面。
-x<類型>或-X<類型>或outgoing-debug<類型> 啟動指定的排錯模式。
-z或–try-next 當執行不成功時,嘗試下一個選擇而不結束程序。
–help 显示幫助,並且結束程序。
***uucp
功能說明: 在Unix系統之間傳送文件。
語法: uucp [-cCdfjmrRtvW][-g<等級>][-I<配置文件>][-n<用戶>][-x<類型>][–help][…來源][目的]
補充說明: UUCP為Unix系統之間,通過序列線來連線的協議。uucp使用UUCP協議,主要的功能為傳送文件。
參數 :
-c或–nocopy 不用將文件複製到緩衝區。
-C或–copy 將文件複製到緩衝區。
-d或–directiories 在傳送文件時,自動在[目的]建立必要的目錄。
-f或–nodirectiories 在傳送文件時,若需要在[目的]建立目錄,則放棄執行該作業。
-g<等級>或–grade<等級> 指定文件傳送作業的優先順序。
-I<配置文件>或–config<配置文件> 指定uucp配置文件。
-j或–jobid 显示作業編號。
-m或–mail 作業結束后,以电子郵件報告作業是否順利完成。
-n<用戶>或–notify<用戶> 作業結束后,以电子郵件向指定的用戶報告作業是否順利完成。
-r或–nouucico 不要立即啟動uucico服務程序,僅將作業送到隊列中,待稍後再執行。
-R或–recursive 若[來源]為目錄,則將整個目錄包含子目錄複製到[目的]。
-t或–uuto 將最後一個參數視為”主機名!用戶”。
-v或–version 显示版本信息。
-W或–noexpand 不要將目前所在的目錄加入路徑。
-x<類型>或–debug<類型>啟動指定的排錯模式。
–help 显示幫助。 [源…] 指定源文件或路徑。 [目的] 指定目標文件或路徑。
***uupick
功能說明: 處理傳送進來的文件。
語法: uupick [-v][-I<配置文件>][-s<主機>][-x<層級>][–help]
補充說明: 當其他主機通過UUCP將文件傳送進來時,可利用uupick指令取出這些文件。
參數:
-I<配置文件>或–config<配置文件> 指定配置文件。
-s<主機>或–system<主機> 處理由指定主機傳送過來的文件。
-v或–version 显示版本信息。
–help 显示幫助。
***uuto
功能說明: 將文件傳送到遠端的UUCP主機。
語法: uuto [文件][目的]
補充說明: uuto為script文件,它實際上會執行uucp,用來將文件傳送到遠端UUCP主機,並在完成工作后,以郵件通知遠端主機上的用戶。
參數: 相關參數請參考uucp指令。
備份壓縮
***ar
功能說明: 建立或修改備存文件,或是從備存文件中抽取文件。
語法: ar[-dmpqrtx][cfosSuvV][a<成員文件>][b<成員文件>][i<成員文件>][備存文件][成員文件]
補充說明: ar可讓您集合許多文件,成為單一的備存文件。在備存文件中,所有成員文件皆保有原來的屬性與權限。
參數:
指令參數:
-d 刪除備存文件中的成員文件。
-m 變更成員文件在備存文件中的次序。
-p 显示備存文件中的成員文件內容。
-q 將問家附加在備存文件末端。
-r 將文件插入備存文件中。
-t 显示備存文件中所包含的文件。
-x 自備存文件中取出成員文件。
選項參數 :
a<成員文件> 將文件插入備存文件中指定的成員文件之後。
b<成員文件> 將文件插入備存文件中指定的成員文件之前。
c 建立備存文件。
f 為避免過長的文件名不兼容於其他系統的ar指令指令,因此可利用此參數,截掉要放入備存文件中過長的成員文件名稱。
i<成員文件> 將問家插入備存文件中指定的成員文件之前。
o 保留備存文件中文件的日期。
s 若備存文件中包含了對象模式,可利用此參數建立備存文件的符號表。
S 不產生符號表。
u 只將日期較新文件插入備存文件中。
v 程序執行時显示詳細的信息。
V 显示版本信息。
***bunzip2
功能說明: .bz2文件的解壓縮程序。
語法: bunzip2 [-fkLsvV][.bz2壓縮文件]
補充說明: bunzip2可解壓縮.bz2格式的壓縮文件。bunzip2實際上是bzip2的符號連接,執行bunzip2與bzip2 -d的效果相同。
參數:
-f或–force 解壓縮時,若輸出的文件與現有文件同名時,預設不會覆蓋現有的文件。若要覆蓋,請使用此參數。
-k或–keep 在解壓縮后,預設會刪除原來的壓縮文件。若要保留壓縮文件,請使用此參數。
-s或–small 降低程序執行時,內存的使用量。
-v或–verbose 解壓縮文件時,显示詳細的信息。
-l,–license,-V或–version 显示版本信息。
***bzip2
功能說明: .bz2文件的壓縮程序。
語法: bzip2 [-cdfhkLstvVz][–repetitive-best][–repetitive-fast][- 壓縮等級][要壓縮的文件]
補充說明: bzip2採用新的壓縮演算法,壓縮效果比傳統的LZ77/LZ78壓縮演算法來得好。若沒有加上任何參數,bzip2壓縮完文件後會產生.bz2的壓縮文件,並刪除原始的文件。
參數:
-c或–stdout 將壓縮與解壓縮的結果送到標準輸出。
-d或–decompress 執行解壓縮。
-f或–force bzip2在壓縮或解壓縮時,若輸出文件與現有文件同名,預設不會覆蓋現有文件。若要覆蓋,請使用此參數。 -h或–help 显示幫助。
-k或–keep bzip2在壓縮或解壓縮后,會刪除原始的文件。若要保留原始文件,請使用此參數。 -s或–small 降低程序執行時內存的使用量。
-t或–test 測試.bz2壓縮文件的完整性。
-v或–verbose 壓縮或解壓縮文件時,显示詳細的信息。
-z或–compress 強制執行壓縮。
-L,–license,
-V或–version 显示版本信息。
–repetitive-best 若文件中有重複出現的資料時,可利用此參數提高壓縮效果。
–repetitive-fast 若文件中有重複出現的資料時,可利用此參數加快執行速度。
-壓縮等級 壓縮時的區塊大小。
***bzip2recover
功能說明: 用來修復損壞的.bz2文件。
語法: bzip2recover [.bz2 壓縮文件]
補充說明: bzip2是以區塊的方式來壓縮文件,每個區塊視為獨立的單位。因此,當某一區塊損壞時,便可利用bzip2recover,試着將文件中的區塊隔開來,以便解壓縮正常的區塊。通常只適用在壓縮文件很大的情況。
***compress
功能說明: 壓縮或解壓文件。
語法: compress [-cdfrvV][-b <壓縮效率>][文件或目錄…]
補充說明: compress是個歷史悠久的壓縮程序,文件經它壓縮后,其名稱後面會多出”.Z”的擴展名。當要解壓縮時,可執行uncompress指令。事實上uncompress是指向compress的符號連接,因此不論是壓縮或解壓縮,都可通過compress指令單獨完成。
參數:
-b<壓縮效率> 壓縮效率是一個介於9-16的數值,預設值為”16″,指定愈大的數值,壓縮效率就愈高。
-c 把壓縮后的文件輸出到標準輸出設備,不去更動原始文件。
-d 對文件進行解壓縮而非壓縮。
-f 強制保存壓縮文件,不理會文件名稱或硬連接是否存在,該文件是否為符號連接以及壓縮效率高低的問題。
-r 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-v 显示指令執行過程。
-V 显示指令版本及程序預設值。
***cpio
功能說明: 備份文件。
語法: cpio [-0aABckLovV][-C <輸入/輸出大小>][-F <備份檔>][-H <備份格式>][-O <備份檔>][–block-size=<區塊大小>][–force-local][–help][–quiet][–version] 或 cpio [-bBcdfikmnrsStuvV][-C <輸入/輸出大小>][-E <範本文件>][-F <備份檔>][-H <備份格式>][-I <備份檔>][-M <回傳信息>][-R <擁有者><:/.><所屬群組>][–block-size=<區塊大小>][–force-local][–help][–no-absolute-filenames][–no-preserve-owner][–only-verify-crc][–quiet][–sparse][–version][範本樣式…] 或 cpio [-0adkiLmpuvV][-R <擁有者><:/.><所屬群組>][–help][–no-preserve-owner][–quiet][–sparse][–version][目的目]
補充說明: cpio是用來建立,還原備份檔的工具程序,它可以加入,解開cpio或tra備份檔內的文件。
參數:
-0或–null 接受新增列控制字符,通常配合find指令的”-print0″參數使用。
-a或–reset-access-time 重新設置文件的存取時間。
-A或–append 附加到已存在的備份檔中,且這個備份檔必須存放在磁盤上,而不能放置於磁帶機里。
-b或–swap 此參數的效果和同時指定”-sS”參數相同。
-B 將輸入/輸出的區塊大小改成5210 Bytes。
-c 使用舊ASCII備份格式。
-C<區塊大小>或–io-size=<區塊大小> 設置輸入/輸出的區塊大小,單位是Byte。
-d或–make-directories 如有需要cpio會自行建立目錄。
-E<範本文件>或–pattern-file=<範本文件> 指定範本文件,其內含有一個或多個範本樣式,讓cpio解開符合範本條件的文件,格式為每列一個範本樣式。
-f或–nonmatching 讓cpio解開所有不符合範本條件的文件。
-F<備份檔>或–file=<備份檔> 指定備份檔的名稱,用來取代標準輸入或輸出,也能藉此通過網絡使用另一台主機的保存設備存取備份檔。
-H<備份格式> 指定備份時欲使用的文件格式。
-i或–extract 執行copy-in模式,還原備份檔。
-l<備份檔> 指定備份檔的名稱,用來取代標準輸入,也能藉此通過網絡使用另一台主機的保存設備讀取備份檔。
-k 此參數將忽略不予處理,僅負責解決cpio不同版本間的兼容性問題。
-l或–link 以硬連接的方式取代複製文件,可在copy-pass模式下運用。
-L或–dereference 不建立符號連接,直接複製該連接所指向的原始文件。
-m或preserve-modification-time 不去更換文件的更改時間。
-M<回傳信息>或–message=<回傳信息> 設置更換保存媒體的信息。
-n或–numeric-uid-gid 使用”-tv”參數列出備份檔的內容時,若再加上參數”-n”,則會以用戶識別碼和群組識別碼替代擁有者和群組名稱列出文件清單。
-o或–create 執行copy-out模式,建立備份檔。
-O<備份檔> 指定備份檔的名稱,用來取代標準輸出,也能藉此通過網絡 使用另一台主機的保存設備存放備份檔。
-p或–pass-through 執行copy-pass模式,略過備份步驟,直接將文件複製到目的目錄。
-r或–rename 當有文件名稱需要更動時,採用互動模式。
-R<擁有者><:/.><所屬群組>或
—-owner<擁有者><:/.><所屬群組> 在copy-in模式還原備份檔,或copy-pass模式複製文件時,可指定這些備份,複製的文件的擁有者與所屬群組。
-s或–swap-bytes 交換每對字節的內容。
-S或–swap-halfwords 交換每半個字節的內容。
-t或–list 將輸入的內容呈現出來。
-u或–unconditional 置換所有文件,不論日期時間的新舊與否,皆不予詢問而直接覆蓋。
-v或–verbose 詳細显示指令的執行過程。
-V或–dot 執行指令時,在每個文件的執行程序前面加上”.”號
–block-size=<區塊大小> 設置輸入/輸出的區塊大小,假如設置數值為5,則區塊大小為2500,若設置成10,則區塊大小為5120,依次類推。
–force-local 強制將備份檔存放在本地主機。
–help 在線幫助。
–no-absolute-filenames 使用相對路徑建立文件名稱。
–no-preserve-owner 不保留文件的擁有者,誰解開了備份檔,那些文件就歸誰所有。
-only-verify-crc 當備份檔採用CRC備份格式時,可使用這項參數檢查備份檔內的每個文件是否正確無誤。
–quiet 不显示複製了多少區塊。
–sparse 倘若一個文件內含大量的連續0字節,則將此文件存成稀疏文件。
–version 显示版本信息。
***dump
功能說明: 備份文件系統。
語法: dump [-cnu][-0123456789][-b <區塊大小>][-B <區塊數目>][-d <密度>][-f <設備名稱>][-h <層級>][-s <磁帶長度>][-T <日期>][目錄或文件系統] 或 dump [-wW]
補充說明: dump為備份工具程序,可將目錄或整個文件系統備份至指定的設備,或備份成一個大文件。
參數:
-0123456789 備份的層級。
-b<區塊大小> 指定區塊的大小,單位為KB。
-B<區塊數目> 指定備份卷冊的區塊數目。
-c 修改備份磁帶預設的密度與容量。
-d<密度> 設置磁帶的密度。單位為BPI。
-f<設備名稱> 指定備份設備。
-h<層級> 當備份層級等於或大雨指定的層級時,將不備份用戶標示為”nodump”的文件。
-n 當備份工作需要管理員介入時,向所有”operator”群組中的使用者發出通知。
-s<磁帶長度> 備份磁帶的長度,單位為英尺。
-T<日期> 指定開始備份的時間與日期。
-u 備份完畢后,在/etc/dumpdates中記錄備份的文件系統,層級,日期與時間等。
-w 與-W類似,但僅显示需要備份的文件。
-W 显示需要備份的文件及其最後一次備份的層級,時間與日期。
***gunzip
功能說明: 解壓文件。
語法: gunzip [-acfhlLnNqrtvV][-s <壓縮字尾字符串>][文件…] 或 gunzip [-acfhlLnNqrtvV][-s <壓縮字尾字符串>][目錄]
補充說明: gunzip是個使用廣泛的解壓縮程序,它用於解開被gzip壓縮過的文件,這些壓縮文件預設最後的擴展名為”.gz”。事實上gunzip就是gzip的硬連接,因此不論是壓縮或解壓縮,都可通過gzip指令單獨完成。
參數:
-a或–ascii 使用ASCII文字模式。
-c或–stdout或–to-stdout 把解壓后的文件輸出到標準輸出設備。
-f或-force 強行解開壓縮文件,不理會文件名稱或硬連接是否存在以及該文件是否為符號連接。
-h或–help 在線幫助。
-l或–list 列出壓縮文件的相關信息。
-L或–license 显示版本與版權信息。
-n或–no-name 解壓縮時,若壓縮文件內含有遠來的文件名稱及時間戳記,則將其忽略不予處理。
-N或–name 解壓縮時,若壓縮文件內含有原來的文件名稱及時間戳記,則將其回存到解開的文件上。
-q或–quiet 不显示警告信息。
-r或–recursive 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-S<壓縮字尾字符串>或–suffix<壓縮字尾字符串> 更改壓縮字尾字符串。
-t或–test 測試壓縮文件是否正確無誤。
-v或–verbose 显示指令執行過程。
-V或–version 显示版本信息。
***gzexe
功能說明: 壓縮執行文件。
語法: gzexe [-d][執行文件…]
補充說明: gzexe是用來壓縮執行文件的程序。當您去執行被壓縮過的執行文件時,該文件會自動解壓然後繼續執行,和使用一般的執行文件相同。
參數:
-d 解開壓縮文件。
***gzip
功能說明: 壓縮文件。
語法: gzip [-acdfhlLnNqrtvV][-S <壓縮字尾字符串>][-<壓縮效率>][–best/fast][文件…] 或 gzip [-acdfhlLnNqrtvV][-S <壓縮字尾字符串>][-<壓縮效率>][–best/fast][目錄]
補充說明: gzip是個使用廣泛的壓縮程序,文件經它壓縮過後,其名稱後面會多出”.gz”的擴展名。
參數:
-a或–ascii 使用ASCII文字模式。
-c或–stdout或–to-stdout 把壓縮后的文件輸出到標準輸出設備,不去更動原始文件。
-d或–decompress或—-uncompress 解開壓縮文件。
-f或–force 強行壓縮文件。不理會文件名稱或硬連接是否存在以及該文件是否為符號連接。
-h或–help 在線幫助。
-l或–list 列出壓縮文件的相關信息。
-L或–license 显示版本與版權信息。
-n或–no-name 壓縮文件時,不保存原來的文件名稱及時間戳記。
-N或–name 壓縮文件時,保存原來的文件名稱及時間戳記。
-q或–quiet 不显示警告信息。
-r或–recursive 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-S<壓縮字尾字符串>或—-suffix<壓縮字尾字符串> 更改壓縮字尾字符串。
-t或–test 測試壓縮文件是否正確無誤。
-v或–verbose 显示指令執行過程。
-V或–version 显示版本信息。
-<壓縮效率> 壓縮效率是一個介於1-9的數值,預設值為”6″,指定愈大的數值,壓縮效率就會愈高。
–best 此參數的效果和指定”-9″參數相同。
–fast 此參數的效果和指定”-1″參數相同。
***lha
功能說明: 壓縮或解壓縮文件。
語法: lha [-acdfglmnpqtuvx][-a <0/1/2>/u][-<a/c/u>d][-i][-<a/u>o][-w=<目的目錄>][-<a/u>z][壓縮文件][文件…] 或 lha [-acdfglmnpqtuvx][-a <0/1/2>/u][-<a/c/u>d][-i][-<a/u>o][-w=<目的目錄>][-<a/u>z][壓縮文件][目錄…]
補充說明: lha是從lharc演變而來的壓縮程序,文件經它壓縮后,會另外產生具有”.lzh”擴展名的壓縮文件。
參數:
-a或a 壓縮文件,並加入到壓縮文件內。
-a<0/1/2>/u</0/1/2> 壓縮文件時,採用不同的文件頭。
-c或c 壓縮文件,重新建構新的壓縮文件后,再將其加入。
-d或d 從壓縮文件內刪除指定的文件。
-<a/c/u>d或<a/c/u>d 壓縮文件,然後將其加入,重新建構,更新壓縮文件或,刪除原始文件,也就是把文件移到壓縮文件中。
-e或e 解開壓縮文件。
-f或f 強制執行lha命令,在解壓時會直接覆蓋已有的文件而不加以詢問。
-g或g 使用通用的壓縮格式,便於解決兼容性的問題。
-<e/x>i或<e/x>i 解開壓縮文件時,忽略保存在壓縮文件內的文件路徑,直接將其解壓后存放在現行目錄下或是指定的目錄中。
-l或l 列出壓縮文件的相關信息。
-m或m 此參數的效果和同時指定”-ad”參數相同。
-n或n 不執行指令,僅列出實際執行會進行的動作。
-<a/u>o或<a/u>o 採用lharc兼容格式,將壓縮后的文件加入,更新壓縮文件。
-p或p 從壓縮文件內輸出到標準輸出設備。
-q或q 不显示指令執行過程。 -t或t 檢查備份文件內的每個文件是否正確無誤。
-u或u 更換較新的文件到壓縮文件內。
-u</0/1/2>或u</0/1/2> 在文件壓縮時採用不同的文件頭,然後更新到壓縮文件內。
-v或v 詳細列出壓縮文件的相關信息。
-<e/x>w=<目的目錄>或<e/x>w=<目的目錄> 指定解壓縮的目錄。
-x或x 解開壓縮文件。
-<a/u>z或<a/u>z 不壓縮文件,直接把它加入,更新壓縮文件。
***restore
功能說明: 還原(Restore)由傾倒(Dump)操作所備份下來的文件或整個文件系統(一個分區)。
語法: restore [-cCvy][-b <區塊大小>][-D <文件系統>][-f <備份文件>][-s <文件編號>] 或 restore [-chimvy][-b <區塊大小>][-f <備份文件>][-s <文件編號>] 或 restore [-crvy][-b <區塊大小>][-f <備份文件>][-s <文件編號>] 或 restore [-cRvy][-b <區塊大小>][-D <文件系統>][-f <備份文件>][-s <文件編號>] 或 restore [chtvy][-b <區塊大小>][-D <文件系統>][-f <備份文件>][-s <文件編號>][文件…] 或 restore [-chmvxy][-b <區塊大小>][-D <文件系統>][-f <備份文件>][-s <文件編號>][文件…]
補充說明: restore 指令所進行的操作和dump指令相反,傾倒操作可用來備份文件,而還原操作則是寫回這些已備份的文件。
參數:
-b<區塊大小> 設置區塊大小,單位是Byte。
-c 不檢查傾倒操作的備份格式,僅准許讀取使用舊格式的備份文件。
-C 使用對比模式,將備份的文件與現行的文件相互對比。
-D<文件系統> 允許用戶指定文件系統的名稱。
-f<備份文件> 從指定的文件中讀取備份數據,進行還原操作。
-h 僅解出目錄而不包括與該目錄相關的所有文件。
-i 使用互動模式,在進行還原操作時,restore指令將依序詢問用戶。
-m 解開符合指定的inode編號的文件或目錄而非採用文件名稱指定。
-r 進行還原操作。
-R 全面還原文件系統時,檢查應從何處開始進行。
-s<文件編號> 當備份數據超過一卷磁帶時,您可以指定備份文件的編號。
-t 指定文件名稱,若該文件已存在備份文件中,則列出它們的名稱。
-v 显示指令執行過程。
-x 設置文件名稱,且從指定的存儲媒體里讀入它們,若該文件已存在在備份文件中,則將其還原到文件系統內。
-y 不詢問任何問題,一律以同意回答並繼續執行指令。
***tar
功能說明: 備份文件。
語法: tar [-ABcdgGhiklmMoOpPrRsStuUvwWxzZ][-b <區塊數目>][-C <目的目錄>][-f <備份文件>][-F <Script文件>][-K <文件>][-L <媒體容量>][-N <日期時間>][-T <範本文件>][-V <卷冊名稱>][-X <範本文件>][-<設備編號><存儲密度>][–after-date=<日期時間>][–atime-preserve][–backuup=<備份方式>][–checkpoint][–concatenate][–confirmation][–delete][–exclude=<範本樣式>][–force-local][–group=<群組名稱>][–help][–ignore-failed-read][–new-volume-script=<Script文件>][–newer-mtime][–no-recursion][–null][–numeric-owner][–owner=<用戶名稱>][–posix][–erve][–preserve-order][–preserve-permissions][–record-size=<區塊數目>][–recursive-unlink][–remove-files][–rsh-command=<執行指令>][–same-owner][–suffix=<備份字尾字符串>][–totals][–use-compress-program=<執行指令>][–version][–volno-file=<編號文件>][文件或目錄…]
補充說明: tar是用來建立,還原備份文件的工具程序,它可以加入,解開備份文件內的文件。
參數:
-A或–catenate 新增溫暖件到已存在的備份文件。
-b<區塊數目>或–blocking-factor=<區塊數目> 設置每筆記錄的區塊數目,每個區塊大小為12Bytes。
-B或–read-full-records 讀取數據時重設區塊大小。
-c或–create 建立新的備份文件。
-C<目的目錄>或–directory=<目的目錄> 切換到指定的目錄。
-d或–diff或–compare 對比備份文件內和文件系統上的文件的差異。
-f<備份文件>或–file=<備份文件> 指定備份文件。
-F<Script文件>或–info-script=<Script文件> 每次更換磁帶時,就執行指定的Script文件。
-g或–listed-incremental 處理GNU格式的大量備份。
-G或–incremental 處理舊的GNU格式的大量備份。
-h或–dereference 不建立符號連接,直接複製該連接所指向的原始文件。
-i或–ignore-zeros 忽略備份文件中的0 Byte區塊,也就是EOF。
-k或–keep-old-files 解開備份文件時,不覆蓋已有的文件。
-K<文件>或–starting-file=<文件> 從指定的文件開始還原。
-l或–one-file-system 複製的文件或目錄存放的文件系統,必須與tar指令執行時所處的文件系統相同,否則不予複製。
-L<媒體容量>或-tape-length=<媒體容量> 設置存放每體的容量,單位以1024 Bytes計算。
-m或–modification-time 還原文件時,不變更文件的更改時間。
-M或–multi-volume 在建立,還原備份文件或列出其中的內容時,採用多卷冊模式。
-N<日期格式>或–newer=<日期時間> 只將較指定日期更新的文件保存到備份文件里。
-o或–old-archive或–portability 將資料寫入備份文件時使用V7格式。
-O或–stdout 把從備份文件里還原的文件輸出到標準輸出設備。
-p或–same-permissions 用原來的文件權限還原文件。
-P或–absolute-names 文件名使用絕對名稱,不移除文件名稱前的”/”號。
-r或–append 新增文件到已存在的備份文件的結尾部分。
-R或–block-number 列出每個信息在備份文件中的區塊編號。
-s或–same-order 還原文件的順序和備份文件內的存放順序相同。
-S或–sparse 倘若一個文件內含大量的連續0字節,則將此文件存成稀疏文件。
-t或–list 列出備份文件的內容。
-T<範本文件>或–files-from=<範本文件> 指定範本文件,其內含有一個或多個範本樣式,讓tar解開或建立符合設置條件的文件。
-u或–update 僅置換較備份文件內的文件更新的文件。
-U或–unlink-first 解開壓縮文件還原文件之前,先解除文件的連接。
-v或–verbose 显示指令執行過程。
-V<卷冊名稱>或–label=<卷冊名稱> 建立使用指定的卷冊名稱的備份文件。
-w或–interactive 遭遇問題時先詢問用戶。
-W或–verify 寫入備份文件后,確認文件正確無誤。
-x或–extract或–get 從備份文件中還原文件。
-X<範本文件>或–exclude-from=<範本文件> 指定範本文件,其內含有一個或多個範本樣式,讓ar排除符合設置條件的文件。
-z或–gzip或–ungzip 通過gzip指令處理備份文件。
-Z或–compress或–uncompress 通過compress指令處理備份文件。
-<設備編號><存儲密度> 設置備份用的外圍設備編號及存放數據的密度。
–after-date=<日期時間> 此參數的效果和指定”-N”參數相同。
–atime-preserve 不變更文件的存取時間。
–backup=<備份方式>或–backup 移除文件前先進行備份。
–checkpoint 讀取備份文件時列出目錄名稱。
–concatenate 此參數的效果和指定”-A”參數相同。
–confirmation 此參數的效果和指定”-w”參數相同。
–delete 從備份文件中刪除指定的文件。
–exclude=<範本樣式> 排除符合範本樣式的問家。
–group=<群組名稱> 把加入設備文件中的文件的所屬群組設成指定的群組。
–help 在線幫助。
–ignore-failed-read 忽略數據讀取錯誤,不中斷程序的執行。
–new-volume-script=<Script文件> 此參數的效果和指定”-F”參數相同。
–newer-mtime 只保存更改過的文件。
–no-recursion 不做遞歸處理,也就是指定目錄下的所有文件及子目錄不予處理。
–null 從null設備讀取文件名稱。
–numeric-owner 以用戶識別碼及群組識別碼取代用戶名稱和群組名稱。
–owner=<用戶名稱> 把加入備份文件中的文件的擁有者設成指定的用戶。
–posix 將數據寫入備份文件時使用POSIX格式。
–preserve 此參數的效果和指定”-ps”參數相同。
–preserve-order 此參數的效果和指定”-A”參數相同。
–preserve-permissions 此參數的效果和指定”-p”參數相同。
–record-size=<區塊數目> 此參數的效果和指定”-b”參數相同。
–recursive-unlink 解開壓縮文件還原目錄之前,先解除整個目錄下所有文件的連接。
–remove-files 文件加入備份文件后,就將其刪除。
–rsh-command=<執行指令> 設置要在遠端主機上執行的指令,以取代rsh指令。
–same-owner 嘗試以相同的文件擁有者還原問家你。
–suffix=<備份字尾字符串> 移除文件前先行備份。
–totals 備份文件建立后,列出文件大小。
–use-compress-program=<執行指令> 通過指定的指令處理備份文件。
–version 显示版本信息。
–volno-file=<編號文件> 使用指定文件內的編號取代預設的卷冊編號。
***unarj
功能說明: 解壓縮.arj文件。
語法: unarj [eltx][.arj壓縮文件]
補充說明: unarj為.arj壓縮文件的壓縮程序。
參數:
e 解壓縮.arj文件。
l 显示壓縮文件內所包含的文件。
t 檢查壓縮文件是否正確。
x 解壓縮時保留原有的路徑。
***unzip
功能說明: 解壓縮zip文件
語法: unzip [-cflptuvz][-agCjLMnoqsVX][-P <密碼>][.zip文件][文件][-d <目錄>][-x <文件>] 或 unzip [-Z]
補充說明: unzip為.zip壓縮文件的解壓縮程序。
參數:
-c 將解壓縮的結果显示到屏幕上,並對字符做適當的轉換。
-f 更新現有的文件。
-l 显示壓縮文件內所包含的文件。
-p 與-c參數類似,會將解壓縮的結果显示到屏幕上,但不會執行任何的轉換。
-t 檢查壓縮文件是否正確。
-u 與-f參數類似,但是除了更新現有的文件外,也會將壓縮文件中的其他文件解壓縮到目錄中。
-v 執行是時显示詳細的信息。
-z 僅显示壓縮文件的備註文字。
-a 對文本文件進行必要的字符轉換。
-b 不要對文本文件進行字符轉換。
-C 壓縮文件中的文件名稱區分大小寫。
-j 不處理壓縮文件中原有的目錄路徑。
-L 將壓縮文件中的全部文件名改為小寫。
-M 將輸出結果送到more程序處理。
-n 解壓縮時不要覆蓋原有的文件。
-o 不必先詢問用戶,unzip執行后覆蓋原有文件。
-P<密碼> 使用zip的密碼選項。
-q 執行時不显示任何信息。
-s 將文件名中的空白字符轉換為底線字符。
-V 保留VMS的文件版本信息。
-X 解壓縮時同時回存文件原來的UID/GID。
[.zip文件] 指定.zip壓縮文件。
[文件] 指定要處理.zip壓縮文件中的哪些文件。
-d<目錄> 指定文件解壓縮后所要存儲的目錄。
-x<文件> 指定不要處理.zip壓縮文件中的哪些文件。
-Z unzip -Z等於執行zipinfo指令。
***zip
功能說明: 壓縮文件。
語法: zip [-AcdDfFghjJKlLmoqrSTuvVwXyz$][-b <工作目錄>][-ll][-n <字尾字符串>][-t <日期時間>][-<壓縮效率>][壓縮文件][文件…][-i <範本樣式>][-x <範本樣式>]
補充說明: zip是個使用廣泛的壓縮程序,文件經它壓縮後會另外產生具有”.zip”擴展名的壓縮文件。
參數:
-A 調整可執行的自動解壓縮文件。
-b<工作目錄> 指定暫時存放文件的目錄。
-c 替每個被壓縮的文件加上註釋。
-d 從壓縮文件內刪除指定的文件。
-D 壓縮文件內不建立目錄名稱。
-f 此參數的效果和指定”-u”參數類似,但不僅更新既有文件,如果某些文件原本不存在於壓縮文件內,使用本參數會一併將其加入壓縮文件中。
-F 嘗試修復已損壞的壓縮文件。
-g 將文件壓縮后附加在既有的壓縮文件之後,而非另行建立新的壓縮文件。
-h 在線幫助。
-i<範本樣式> 只壓縮符合條件的文件。
-j 只保存文件名稱及其內容,而不存放任何目錄名稱。
-J 刪除壓縮文件前面不必要的數據。
-k 使用MS-DOS兼容格式的文件名稱。
-l 壓縮文件時,把LF字符置換成LF+CR字符。
-ll 壓縮文件時,把LF+CR字符置換成LF字符。
-L 显示版權信息。
-m 將文件壓縮並加入壓縮文件后,刪除原始文件,即把文件移到壓縮文件中。
-n<字尾字符串> 不壓縮具有特定字尾字符串的文件。
-o 以壓縮文件內擁有最新更改時間的文件為準,將壓縮文件的更改時間設成和該文件相同。
-q 不显示指令執行過程。
-r 遞歸處理,將指定目錄下的所有文件和子目錄一併處理。
-S 包含系統和隱藏文件。
-t<日期時間> 把壓縮文件的日期設成指定的日期。
-T 檢查備份文件內的每個文件是否正確無誤。
-u 更換較新的文件到壓縮文件內。
-v 显示指令執行過程或显示版本信息。
-V 保存VMS操作系統的文件屬性。
-w 在文件名稱里假如版本編號,本參數僅在VMS操作系統下有效。
-x<範本樣式> 壓縮時排除符合條件的文件。
-X 不保存額外的文件屬性。
-y 直接保存符號連接,而非該連接所指向的文件,本參數僅在UNIX之類的系統下有效。
-z 替壓縮文件加上註釋。
-$ 保存第一個被壓縮文件所在磁盤的卷冊名稱。
-<壓縮效率> 壓縮效率是一個介於1-9的數值。
***zipinfo
功能說明: 列出壓縮文件信息。
語法: zipinfo [-12hlmMstTvz][壓縮文件][文件…][-x <範本樣式>]
補充說明: 執行zipinfo指令可得知zip壓縮文件的詳細信息。
參數:
-1 只列出文件名稱。
-2 此參數的效果和指定”-1″參數類似,但可搭配”-h”,”-t”和”-z”參數使用。
-h 只列出壓縮文件的文件名稱。
-l 此參數的效果和指定”-m”參數類似,但會列出原始文件的大小而非每個文件的壓縮率。
-m 此參數的效果和指定”-s”參數類似,但多會列出每個文件的壓縮率。
-M 若信息內容超過一個畫面,則採用類似more指令的方式列出信息。
-s 用類似執行”ls -l”指令的效果列出壓縮文件內容。
-t 只列出壓縮文件內所包含的文件數目,壓縮前後的文件大小及壓縮率。
-T 將壓縮文件內每個文件的日期時間用年,月,日,時,分,秒的順序列出。
-v 詳細显示壓縮文件內每一個文件的信息。
-x<範本樣式> 不列出符合條件的文件的信息。
-z 如果壓縮文件內含有註釋,就將註釋显示出來。
文件管理
***diff
功能說明: 比較文件的差異。
語法: diff [-abBcdefHilnNpPqrstTuvwy][-<行數>][-C <行數>][-D <巨集名稱>][-I <字符或字符串>][-S <文件>][-W <寬度>][-x <文件或目錄>][-X <文件>][–help][–left-column][–suppress-common-line][文件或目錄1][文件或目錄2]
補充說明: diff以逐行的方式,比較文本文件的異同處。所是指定要比較目錄,則diff會比較目錄中相同文件名的文件,但不會比較其中子目錄。
參數:
-<行數> 指定要显示多少行的文本。此參數必須與-c或-u參數一併使用。
-a或–text diff預設只會逐行比較文本文件。
-b或–ignore-space-change 不檢查空格字符的不同。
-B或–ignore-blank-lines 不檢查空白行。
-c 显示全部內文,並標出不同之處。
-C<行數>或–context<行數> 與執行”-c-<行數>”指令相同。
-d或–minimal 使用不同的演算法,以較小的單位來做比較。
-D<巨集名稱>或ifdef<巨集名稱> 此參數的輸出格式可用於前置處理器巨集。
-e或–ed 此參數的輸出格式可用於ed的script文件。
-f或-forward-ed 輸出的格式類似ed的script文件,但按照原來文件的順序來显示不同處。
-H或–speed-large-files 比較大文件時,可加快速度。
-l<字符或字符串>或–ignore-matching-lines<字符或字符串> 若兩個文件在某幾行有所不同,而這幾行同時都包含了選項中指定的字符或字符串,則不显示這兩個文件的差異。
-i或–ignore-case 不檢查大小寫的不同。
-l或–paginate 將結果交由pr程序來分頁。
-n或–rcs 將比較結果以RCS的格式來显示。
-N或–new-file 在比較目錄時,若文件A僅出現在某個目錄中,預設會显示: Only in目錄:文件A若使用-N參數,則diff會將文件A與一個空白的文件比較。
-p 若比較的文件為C語言的程序碼文件時,显示差異所在的函數名稱。
-P或–unidirectional-new-file 與-N類似,但只有當第二個目錄包含了一個第一個目錄所沒有的文件時,才會將這個文件與空白的文件做比較。
-q或–brief 僅显示有無差異,不显示詳細的信息。
-r或–recursive 比較子目錄中的文件。
-s或–report-identical-files 若沒有發現任何差異,仍然显示信息。
-S<文件>或–starting-file<文件> 在比較目錄時,從指定的文件開始比較。
-t或–expand-tabs 在輸出時,將tab字符展開。
-T或–initial-tab 在每行前面加上tab字符以便對齊。
-u,-U<列數>或–unified=<列數> 以合併的方式來显示文件內容的不同。
-v或–version 显示版本信息。
-w或–ignore-all-space 忽略全部的空格字符。
-W<寬度>或–width<寬度> 在使用-y參數時,指定欄寬。
-x<文件名或目錄>或–exclude<文件名或目錄> 不比較選項中所指定的文件或目錄。
-X<文件>或–exclude-from<文件> 您可以將文件或目錄類型存成文本文件,然後在=<文件>中指定此文本文件。
-y或–side-by-side 以並列的方式显示文件的異同之處。
–help 显示幫助。
–left-column 在使用-y參數時,若兩個文件某一行內容相同,則僅在左側的欄位显示該行內容。
–suppress-common-lines 在使用-y參數時,僅显示不同之處。
***diffstat
功能說明: 根據diff的比較結果,显示統計数字。
語法: diff [-wV][-n <文件名長度>][-p <文件名長度>]
補充說明: diffstat讀取diff的輸出結果,然後統計各文件的插入,刪除,修改等差異計量。
參數:
-n<文件名長度> 指定文件名長度,指定的長度必須大於或等於所有文件中最長的文件名。
-p<文件名長度> 與-n參數相同,但此處的<文件名長度>包括了文件的路徑。
-w 指定輸出時欄位的寬度。
-V 显示版本信息。
***file
功能說明: 辨識文件類型。
語法: file [-beLvz][-f <名稱文件>][-m <魔法数字文件>…][文件或目錄…]
補充說明: 通過file指令,我們得以辨識該文件的類型。
參數:
-b 列出辨識結果時,不显示文件名稱。
-c 詳細显示指令執行過程,便於排錯或分析程序執行的情形。
-f<名稱文件> 指定名稱文件,其內容有一個或多個文件名稱呢感,讓file依序辨識這些文件,格式為每列一個文件名稱。
-L 直接显示符號連接所指向的文件的類別。
-m<魔法数字文件> 指定魔法数字文件。
-v 显示版本信息。
-z 嘗試去解讀壓縮文件的內容。
***find
功能說明: 查找文件或目錄。
語法: find [目錄…][-amin <分鐘>][-anewer <參考文件或目錄>][-atime <24小時數>][-cmin <分鐘>][-cnewer <參考文件或目錄>][-ctime <24小時數>][-daystart][-depyh][-empty][-exec <執行指令>][-false][-fls <列表文件>][-follow][-fprint <列表文件>][-fprint0 <列表文件>][-fprintf <列表文件><輸出格式>][-fstype <文件系統類型>][-gid <群組識別碼>][-group <群組名稱>][-help][-ilname <範本樣式>][-iname <範本樣式>][-inum ][-ipath <範本樣式>][-iregex <範本樣式>][-links <連接數目>][-lname <範本樣式>][-ls][-maxdepth <目錄層級>][-mindepth <目錄層級>][-mmin <分鐘>][-mount] [-mtime <24小時數>][-name <範本樣式>][-newer <參考文件或目錄>][-nogroup][noleaf] [-nouser][-ok <執行指令>][-path <範本樣式>][-perm <權限數值>][-print][-print0][-printf <輸出格式>][-prune][-regex <範本樣式>][-size <文件大小>][-true][-type <文件類型>][-uid <用戶識別碼>][-used <日數>][-user <擁有者名稱>][-version][-xdev][-xtype <文件類型>]
補充說明: find指令用於查找符合條件的文件。任何位於參數之前的字符串都將被視為欲查找的目錄。
參數:
-amin<分鐘> 查找在指定時間曾被存取過的文件或目錄,單位以分鐘計算。
-anewer<參考文件或目錄> 查找其存取時間較指定文件或目錄的存取時間更接近現在的文件或目錄。
-atime<24小時數> 查找在指定時間曾被存取過的文件或目錄,單位以24小時計算。
-cmin<分鐘> 查找在指定時間之時被更改的文件或目錄。
-cnewer<參考文件或目錄> 查找其更改時間較指定文件或目錄的更改時間更接近現在的文件或目錄。
-ctime<24小時數> 查找在指定時間之時被更改的文件或目錄,單位以24小時計算。
-daystart 從本日開始計算時間。
-depth 從指定目錄下最深層的子目錄開始查找。
-expty 尋找文件大小為0 Byte的文件,或目錄下沒有任何子目錄或文件的空目錄。
-exec<執行指令> 假設find指令的回傳值為True,就執行該指令。
-false 將find指令的回傳值皆設為False。
-fls<列表文件> 此參數的效果和指定”-ls”參數類似,但會把結果保存為指定的列表文件。
-follow 排除符號連接。
-fprint<列表文件> 此參數的效果和指定”-print”參數類似,但會把結果保存成指定的列表文件。
-fprint0<列表文件> 此參數的效果和指定”-print0″參數類似,但會把結果保存成指定的列表文件。
-fprintf<列表文件><輸出格式> 此參數的效果和指定”-printf”參數類似,但會把結果保存成指定的列表文件。
-fstype<文件系統類型> 只尋找該文件系統類型下的文件或目錄。
-gid<群組識別碼> 查找符合指定之群組識別碼的文件或目錄。
-group<群組名稱> 查找符合指定之群組名稱的文件或目錄。
-help或–help 在線幫助。
-ilname<範本樣式> 此參數的效果和指定”-lname”參數類似,但忽略字符大小寫的差別。
-iname<範本樣式> 此參數的效果和指定”-name”參數類似,但忽略字符大小寫的差別。
-inum<inode編號> 查找符合指定的inode編號的文件或目錄。
-ipath<範本樣式> 此參數的效果和指定”-ipath”參數類似,但忽略字符大小寫的差別。
-iregex<範本樣式> 此參數的效果和指定”-regexe”參數類似,但忽略字符大小寫的差別。
-links<連接數目> 查找符合指定的硬連接數目的文件或目錄。
-iname<範本樣式> 指定字符串作為尋找符號連接的範本樣式。
-ls 假設find指令的回傳值為True,就將文件或目錄名稱列出到標準輸出。
-maxdepth<目錄層級> 設置最大目錄層級。
-mindepth<目錄層級> 設置最小目錄層級。
-mmin<分鐘> 查找在指定時間曾被更改過的文件或目錄,單位以分鐘計算。
-mount 此參數的效果和指定”-xdev”相同。
-mtime<24小時數> 查找在指定時間曾被更改過的文件或目錄,單位以24小時計算。
-name<範本樣式> 指定字符串作為尋找文件或目錄的範本樣式。
-newer<參考文件或目錄> 查找其更改時間較指定文件或目錄的更改時間更接近現在的文件或目錄。
-nogroup 找出不屬於本地主機群組識別碼的文件或目錄。
-noleaf 不去考慮目錄至少需擁有兩個硬連接存在。
-nouser 找出不屬於本地主機用戶識別碼的文件或目錄。
-ok<執行指令> 此參數的效果和指定”-exec”參數類似,但在執行指令之前會先詢問用戶,若回答”y”或”Y”,則放棄執行指令。
-path<範本樣式> 指定字符串作為尋找目錄的範本樣式。
-perm<權限數值> 查找符合指定的權限數值的文件或目錄。
-print 假設find指令的回傳值為True,就將文件或目錄名稱列出到標準輸出。格式為每列一個名稱,每個名稱之前皆有”./”字符串。
-print0 假設find指令的回傳值為True,就將文件或目錄名稱列出到標準輸出。格式為全部的名稱皆在同一行。
-printf<輸出格式> 假設find指令的回傳值為True,就將文件或目錄名稱列出到標準輸出。格式可以自行指定。
-prune 不尋找字符串作為尋找文件或目錄的範本樣式。
-regex<範本樣式> 指定字符串作為尋找文件或目錄的範本樣式。
-size<文件大小> 查找符合指定的文件大小的文件。
-true 將find指令的回傳值皆設為True。
-typ<文件類型> 只尋找符合指定的文件類型的文件。
-uid<用戶識別碼> 查找符合指定的用戶識別碼的文件或目錄。
-used<日數> 查找文件或目錄被更改之後在指定時間曾被存取過的文件或目錄,單位以日計算。
-user<擁有者名稱> 查找符合指定的擁有者名稱的文件或目錄。
-version或–version 显示版本信息。
-xdev 將範圍局限在先行的文件系統中。
-xtype<文件類型> 此參數的效果和指定”-type”參數類似,差別在於它針對符號連接檢查。
***git
功能說明: 文字模式下的文件管理員。
語法: git
補充說明: git是用來管理文件的程序,它十分類似DOS下的Norton Commander,具有互動式操作界面。它的操作方法和Norton Commander幾乎一樣,略訴如下:
F1 :執行info指令,查詢指令相關信息,會要求您輸入欲查詢的名稱。
F2 :執行cat指令,列出文件內容。
F3 :執行gitview指令,觀看文件內容。
F4 :執行vi指令,編輯文件內容。
F5 :執行cp指令,複製文件或目錄,會要求您輸入目標文件或目錄。
F6 :執行mv指令,移動文件或目錄,或是更改其名稱,會要求您輸入目標文件或目錄。
F7 :執行mkdir指令,建立目錄。
F8 :執行rm指令,刪除文件或目錄。
F9 :執行make指令,批處理執行指令或編譯程序時,會要求您輸入相關命令。
F10 :離開git文件管理員。
***gitview
功能說明: Hex/ASCII的看文件程序。
語法: gitview [-bchilv][文件]
補充說明: gitview指令可用於觀看文件的內容,它會同時显示十六進制和ASCII格式的字碼。
參數:
-b 單色模式,不使用ANSI控制碼显示彩色。
-c 彩色模式,使用ANSI控制碼显示色彩。
-h 在線幫助。
-i 显示存放gitview程序的所在位置。
-l 不使用先前的显示字符。
-v 显示版本信息。
***ln
功能說明: 連接文件或目錄。
語法: ln [-bdfinsv][-S <字尾備份字符串>][-V <備份方式>][–help][–version][源文件或目錄][目標文件或目錄] 或 ln [-bdfinsv][-S <字尾備份字符串>][-V <備份方式>][–help][–version][源文件或目錄…][目的目錄]
補充說明: ln指令用在連接文件或目錄,如同時指定兩個以上的文件或目錄,且最後的目的地是一個已經存在的目錄,則會把前面指定的所有文件或目錄複製到該目錄中。若同時指定多個文件或目錄,且最後的目的地並非是一個已存在的目錄,則會出現錯誤信息。
參數:
-b或–backup 刪除,覆蓋目標文件之前的備份。
-d或-F或–directory 建立目錄的硬連接。
-f或–force 強行建立文件或目錄的連接,不論文件或目錄是否存在。
-i或–interactive 覆蓋既有文件之前先詢問用戶。
-n或–no-dereference 把符號連接的目的目錄視為一般文件。
-s或–symbolic 對源文件建立符號連接,而非硬連接。
-S<字尾備份字符串>或–suffix=<字尾備份字符串> 用”-b”參數備份目標文件后,備份文件的字尾會被加上一個備份字符串,預設的字尾備份字符串是符號”~”,您可通過”-S”參數來改變它。
-v或–verbose 显示指令執行過程。
-V<備份方式>或–version-control=<備份方式> 用”-b”參數備份目標文件后,備份文件的字尾會被加上一個備份字符串,這個字符串不僅可用”-S”參數變更,當使用”-V”參數<備份方式>指定不同備份方式時,也會產生不同字尾的備份字符串。
–help 在線幫助。
–version 显示版本信息。
***locate
功能說明: 查找文件。
語法: locate [-d <數據庫文件>][–help][–version][範本樣式…]
補充說明: locate指令用於查找符合條件的文件,它會去保存文件與目錄名稱的數據庫內,查找合乎範本樣式條件的文件或目錄。
參數:
-d<數據庫文件>或–database=<數據庫文件> 設置locate指令使用的數據庫。locate指令預設的數據庫位於/var/lib/slocate目錄里,文件名為slocate.db,您可使用這個參數另行指定。
–help 在線幫助。
–version 显示版本信息。
***lsattr
功能說明: 显示文件屬性。
語法: lsattr [-adlRvV][文件或目錄…]
補充說明: 用chattr執行改變文件或目錄的屬性,可執行lsattr指令查詢其屬性。
參數:
-a 显示所有文件和目錄,包括以”.”為名稱開頭字符的額外內建,現行目錄”.”與上層目錄”..”。
-d 显示,目錄名稱,而非其內容。
-l 此參數目前沒有任何作用。
-R 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-v 显示文件或目錄版本。
-V 显示版本信息。
***mattrib
功能說明: 變更或显示MS-DOS文件的屬性。
語法: mattrib [+/-][ahrs][-/X][文件] 或 mattrib [-/X][文件]
補充說明: mattrib為mtools工具指令,模擬MS-DOS的attrib指令,可變更MS-DOS文件的屬性。
參數:
+/- “+”代表開啟指定的文件屬性。”-“代表關閉指定的文件屬性。
a 備份屬性。使備份程序可用來判斷文件是否已經備份過。
h 隱藏屬性。
r 只讀屬性。
s 系統屬性。
-/ 列出指定目錄及子目錄下所有文件的屬性。
-X 显示文件屬性時,中間不輸入空格。
***mc
功能說明: 提供一個菜單式的文件管理程序。
語法: mc [-abcdfhkPstuUVx][-C <參數>][-l <文件>][-v <文件>][目錄]
補充說明: 執行mc之後,將會看到菜單式的文件管理程序,共分成4個部分。
參數:
-a 當mc程序畫線時不用繪圖字符畫線。
-b 使用單色模式显示。
-c 使用彩色模式显示。
-C<參數> 指定显示的顏色。
-d 不使用鼠標。
-f 显示mc函數庫所在的目錄。
-h 显示幫助。
-k 重設softkeys成預設置。
-l<文件> 在指定文件中保存ftpfs對話窗的內容。
-P 程序結束時,列出最後的工作目錄。
-s 用慢速的終端機模式显示,在這模式下將減少大量的繪圖及文字显示。
-t 使用TEMPCAP變量設置終端機,而不使用預設置。
-u 不用目前的shell程序。
-U 使用目前的shell程序。
-v<文件> 使用mc的內部編輯器來显示指定的文件。
-V 显示版本信息。
-x 指定以xterm模式显示。
***mcopy
功能說明: 複製MS-DOS文件。
語法: mcopy [-bnmpQt/][源文件][目標文件或目錄]
補充說明: mcopy為mtools工具指令,可在MS-DOS文件系統中複製文件或是在MS-DOS與Linux的文件系統之間複製文件。mcopy會MS-DOS磁盤驅動器代號出現的位置來判斷如何複製文件。
參數:
-b 批處理模式。
-n 覆蓋其他文件時,不需進行確認而直接覆蓋。
-m 將源文件修改時間設為目標文件的修改時間。
-p 將源文件屬性設為目標文件的屬性。
-Q 複製多個文件時,若發生錯誤,則立即結束程序。
-t 轉換文本文件。
-/ 複製子目錄以及其中的所有文件。
***mdel
功能說明: 刪除MS-DOS文件。
語法: mdel [文件…]
補充說明: mdel為mtools工具指令,模擬MS-DOS的del指令,可刪除MS-DOS文件系統中的文件。
***mdir
功能說明: 显示MS-DOS目錄。
語法: mdir [-afwx/][目錄]
補充說明: mdir為mtools工具指令,模擬MS-DOS的dir指令,可显示MS-DOS文件系統中的目錄內容。
參數:
-/ 显示目錄下所有子目錄與文件。
-a 显示隱藏文件。
-f 不显示磁盤所剩餘的可用空間。
-w 僅显示目錄或文件名稱,並以橫排方式呈現,以便一次能显示較多的目錄或文件。
-X 僅显示目錄下所有子目錄與文件的完整路徑,不显示其他信息。
***mktemp
功能說明: 建立暫存文件。
語法: mktemp [-qu][文件名參數]
補充說明: mktemp可建立一個暫存文件,供shell script使用。
參數:
-q 執行時若發生錯誤,不會显示任何信息。
-u 暫存文件會在mktemp結束前先行刪除。
[文件名參數] 文件名參數必須是以”自訂名稱.XXXXXX”的格式。
***mmove
功能說明: 在MS-DOS文件系統中,移動文件或目錄,或更改名稱。
語法: mmove [源文件或目錄…][目標文件或目錄]
補充說明: mmove為mtools工具指令,模擬MS-DOS的move指令,可在MS-DOS文件系統中移動現有的文件或目錄,或是更改現有文件或目錄的名稱。
***mread
功能說明: 將MS-DOS文件複製到Linux/Unix的目錄中。
語法: mread [MS-DOS文件…][Linux文件或目錄]
補充說明: mread為mtools工具指令,可將MS-DOS文件複製到Linux的文件系統中。這個指令目前已經不常用,一般都使用mcopy指令來代替。
***mren
功能說明: 更改MS-DOS文件或目錄的名稱,或是移動文件或目錄。
語法: mren [源文件或目錄…][目標文件或目錄]
補充說明: mren為MS-DOS工具指令,模擬MS-DOS的ren指令,可更改MS-DOS文件或目錄名稱。除此之外,ren也可移動文件或目錄,但僅限於在同一設備內
***mshowfat
功能說明: 显示MS-DOS文件在FAT中的記錄。
語法: mshowfat [文件…]
補充說明: mshowfat為mtools工具指令,可显示MS-DOS文件在FAT中的記錄編號。
***mtools
功能說明: 显示mtools支持的指令。
語法: mtools
補充說明: mtools為MS-DOS文件系統的工具程序,可模擬許多MS-DOS的指令。這些指令都是mtools的符號連接,因此會有一些共同的特性。
參數:
-a 長文件名重複時自動更改目標文件的長文件名。
-A 短文件名重複但長文件名不同時自動更改目標文件的短文件名。
-o 長文件名重複時,將目標文件覆蓋現有的文件。
-O 短文件名重複但長文件名不同時,將目標文件覆蓋現有的文件。
-r 長文件名重複時,要求用戶更改目標文件的長文件名。
-R 短文件名重複但長文件名不同時,要求用戶更改目標文件的短文件名。
-s 長文件名重複時,則不處理該目標文件。
-S 短文件名重複但長文件名不同時,則不處理該目標文件。
-v 執行時显示詳細的說明。
-V 显示版本信息。
***mtoolstest
功能說明: 測試並显示mtools的相關設置。
語法: mtoolstest
補充說明: mtoolstest為mtools工具指令,可讀取與分析mtools的配置文件,並在屏幕上显示結果。
***mv
功能說明: 移動或更名現有的文件或目錄。
語法: mv [-bfiuv][–help][–version][-S <附加字尾>][-V <方法>][源文件或目錄][目標文件或目錄]
補充說明: mv可移動文件或目錄,或是更改文件或目錄的名稱。
參數:
-b或–backup 若需覆蓋文件,則覆蓋前先行備份。
-f或–force 若目標文件或目錄與現有的文件或目錄重複,則直接覆蓋現有的文 件或目錄。
-i或–interactive 覆蓋前先行詢問用戶。
-S<附加字尾>或
–suffix=<附加字尾> 與-b參數一併使用,可指定備份文件的所要附加的字尾。
-u或–update 在移動或更改文件名時,若目標文件已存在,且其文件日期比源文件新,則不覆蓋目標文件。
-v或–verbose 執行時显示詳細的信息。
-V=<方法>或 –version-control=<方法> 與-b參數一併使用,可指定備份的方法。
–help 显示幫助。
–version 显示版本信息。
***od
功能說明: 輸出文件內容。
語法: od [-abcdfhilovx][-A <字碼基數>][-j <字符數目>][-N <字符數目>][-s <字符串字符數>][-t <輸出格式>][-w <每列字符數>][–help][–version][文件…]
補充說明: od指令會讀取所給予的文件的內容,並將其內容以八進制字碼呈現出來。
參數:
-a 此參數的效果和同時指定”-ta”參數相同。
-A<字碼基數> 選擇要以何種基數計算字碼。
-b 此參數的效果和同時指定”-toC”參數相同。
-c 此參數的效果和同時指定”-tC”參數相同。
-d 此參數的效果和同時指定”-tu2″參數相同。
-f 此參數的效果和同時指定”-tfF”參數相同。
-h 此參數的效果和同時指定”-tx2″參數相同。
-i 此參數的效果和同時指定”-td2″參數相同。
-j<字符數目>或–skip-bytes=<字符數目> 略過設置的字符數目。
-l 此參數的效果和同時指定”-td4″參數相同。
-N<字符數目>或–read-bytes=<字符數目> 到設置的字符數目為止。
-o 此參數的效果和同時指定”-to2″參數相同。
-s<字符串字符數>或–strings=<字符串字符數> 只显示符合指定的字符數目的字符串。
-t<輸出格式>或–format=<輸出格式> 設置輸出格式。
-v或–output-duplicates 輸出時不省略重複的數據。
-w<每列字符數>或–width=<每列字符數> 設置每列的最大字符數。
-x 此參數的效果和同時指定”-h”參數相同。
–help 在線幫助。
-version 显示版本信息。
***paste
功能說明: 合併文件的列。
語法: paste [-s][-d <間隔字符>][–help][–version][文件…]
補充說明: paste指令會把每個文件以列對列的方式,一列列地加以合併。
參數:
-d<間隔字符>或–delimiters=<間隔字符> 用指定的間隔字符取代跳格字符。
-s或–serial 串列進行而非平行處理。
–help 在線幫助。
–version 显示幫助信息。
***patch
功能說明: 修補文件。
語法: patch [-bceEflnNRstTuvZ][-B <備份字首字符串>][-d <工作目錄>][-D <標示符號>][-F <監別列數>][-g <控制數值>][-i <修補文件>][-o <輸出文件>][-p <剝離層級>][-r <拒絕文件>][-V <備份方式>][-Y <備份字首字符串>][-z <備份字尾字符串>][–backup-if -mismatch][–binary][–help][–nobackup-if-mismatch][–verbose][原始文件 <修補文件>] 或 path [-p <剝離層級>] < [修補文件]
補充說明: patch指令讓用戶利用設置修補文件的方式,修改,更新原始文件。倘若一次僅修改一個文件,可直接在指令列中下達指令依序執行。如果配合修補文件的方式則能一次修補大批文件,這也是Linux系統核心的升級方法之一。
參數:
-b或–backup 備份每一個原始文件。
-B<備份字首字符串>或–prefix=<備份字首字符串> 設置文件備份時,附加在文件名稱前面的字首字符串,該字符串可以是路徑名稱。
-c或–context 把修補數據解譯成關聯性的差異。
-d<工作目錄>或–directory=<工作目錄> 設置工作目錄。
-D<標示符號>或–ifdef=<標示符號> 用指定的符號把改變的地方標示出來。
-e或–ed 把修補數據解譯成ed指令可用的敘述文件。
E或–remove-empty-files 若修補過後輸出的文件其內容是一片空白,則移除該文件。
-f或–force 此參數的效果和指定”-t”參數類似,但會假設修補數據的版本為新 版本。
-F<監別列數>或–fuzz<監別列數> 設置監別列數的最大值。
-g<控制數值>或–get=<控制數值> 設置以RSC或SCCS控制修補作業。
-i<修補文件>或–input=<修補文件> 讀取指定的修補問家你。
-l或–ignore-whitespace 忽略修補數據與輸入數據的跳格,空格字符。
-n或–normal 把修補數據解譯成一般性的差異。
-N或–forward 忽略修補的數據較原始文件的版本更舊,或該版本的修補數據已使 用過。
-o<輸出文件>或–output=<輸出文件> 設置輸出文件的名稱,修補過的文件會以該名稱存放。
-p<剝離層級>或–strip=<剝離層級> 設置欲剝離幾層路徑名稱。
-f<拒絕文件>或–reject-file=<拒絕文件> 設置保存拒絕修補相關信息的文件名稱,預設的文件名稱為.rej。
-R或–reverse 假設修補數據是由新舊文件交換位置而產生。
-s或–quiet或–silent 不显示指令執行過程,除非發生錯誤。
-t或–batch 自動略過錯誤,不詢問任何問題。
-T或–set-time 此參數的效果和指定”-Z”參數類似,但以本地時間為主。
-u或–unified 把修補數據解譯成一致化的差異。
-v或–version 显示版本信息。
-V<備份方式>或–version-control=<備份方式> 用”-b”參數備份目標文件后,備份文件的字尾會被加上一個備份字符串,這個字符串不僅可用”-z”參數變更,當使用”-V”參數指定不同備份方式時,也會產生不同字尾的備份字符串。
-Y<備份字首字符串>或–basename-prefix=–<備份字首字符串> 設置文件備份時,附加在文件基本名稱開頭的字首字符串。
-z<備份字尾字符串>或–suffix=<備份字尾字符串> 此參數的效果和指定”-B”參數類似,差別在於修補作業使用的路徑與文件名若為src/linux/fs/super.c,加上”backup/”字符串后,文件super.c會備份於/src/linux/fs/backup目錄里。
-Z或–set-utc 把修補過的文件更改,存取時間設為UTC。
–backup-if-mismatch 在修補數據不完全吻合,且沒有刻意指定要備份文件時,才備份文件。
–binary 以二進制模式讀寫數據,而不通過標準輸出設備。
–help 在線幫助。
–nobackup-if-mismatch 在修補數據不完全吻合,且沒有刻意指定要備份文件時,不要備份文件。
–verbose 詳細显示指令的執行過程。
***rcp
功能說明: 遠端複製文件或目錄。
語法: rcp [-pr][源文件或目錄][目標文件或目錄] 或 rcp [-pr][源文件或目錄…][目標文件]
補充說明 :rcp指令用在遠端複製文件或目錄,如同時指定兩個以上的文件或目錄,且最後的目的地是一個已經存在的目錄,則它灰把前面指定的所有文件或目錄複製到該目錄中。
參數 :
-p 保留源文件或目錄的屬性,包括擁有者,所屬群組,權限與時間。
-r 遞歸處理,將指定目錄下的文件與子目錄一併處理。
***rhmask
功能說明: 產生與還原加密文件。
語法: rhmask [加密文件][輸出文件] 或 rhmask [-d][加密文件][源文件][輸出文件]
補充說明: 執行rhmask指令可製作加密過的文件,方便用戶在公開的網絡上傳輸該文件,而不至於被任意盜用。
參數:
-d 產生加密過的文件。
***rm
功能說明: 刪除文件或目錄。
語法: rm [-dfirv][–help][–version][文件或目錄…]
補充說明: 執行rm指令可刪除文件或目錄,如欲刪除目錄必須加上參數”-r”,否則預設僅會刪除文件。
參數:
-d或–directory 直接把欲刪除的目錄的硬連接數據刪成0,刪除該目錄。
-f或–force 強制刪除文件或目錄。
-i或–interactive 刪除既有文件或目錄之前先詢問用戶。
-r或-R或–recursive 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-v或–verbose 显示指令執行過程。
–help 在線幫助。
–version 显示版本信息。
***slocate
功能說明: 查找文件或目錄。
語法: slocate [-u][–help][–version][-d <目錄>][查找的文件]
補充說明: slocate本身具有一個數據庫,裏面存放了系統中文件與目錄的相關信息。
參數:
-d<目錄>或–database=<目錄> 指定數據庫所在的目錄。
-u 更新slocate數據庫。
–help 显示幫助。
–version 显示版本信息。
***split
功能說明: 切割文件。
語法: split [–help][–version][-<行數>][-b <字節>][-C <字節>][-l <行數>][要切割的文件][輸出文件名]
補充說明: split可將文件切成較小的文件,預設每1000行會切成一個小文件。
參數:
-<行數>或-l<行數> 指定每多少行就要切成一個小文件。
-b<字節> 指定每多少字就要切成一個小文件。
-C<字節> 與-b參數類似,但切割時盡量維持每行的完整性。
–help 显示幫助。
–version 显示版本信息。
[輸出文件名] 設置切割後文件的前置文件名,split會自動在前置文件名后再加上編號。
***tee
功能說明: 讀取標準輸入的數據,並將其內容輸出成文件。
語法: tee [-ai][–help][–version][文件…]
補充說明: tee指令會從標準輸入設備讀取數據,將其內容輸出到標準輸出設備,同時保存成文件。
參數:
-a或–append 附加到既有文件的後面,而非覆蓋它.
-i-i或–ignore-interrupts 忽略中斷信號。
–help 在線幫助。
–version 显示版本信息。
***tmpwatch
功能說明: 刪除暫存文件。
語法: tmpwatch [-afqv][–test][超期時間][目錄…]
補充說明: 執行tmpwatch指令可刪除不必要的暫存文件,您可以設置文件超期時間,單位以小時計算。
參數:
-a或–all 刪除任何類型的文件。
-f或–force 強制刪除文件或目錄,其效果類似rm指令的”-f”參數。
-q或–quiet 不显示指令執行過程。
-v或–verbose 詳細显示指令執行過程。
-test 僅作測試,並不真的刪除文件或目錄。
***touch
功能說明: 改變文件或目錄時間。
語法: touch [-acfm][-d <日期時間>][-r <參考文件或目錄>][-t <日期時間>][–help] [–version][文件或目錄…] 或 touch [-acfm][–help][–version][日期時間][文件或目錄…]
補充說明: 使用touch指令可更改文件或目錄的日期時間,包括存取時間和更改時間。
參數:
-a或–time=atime或–time=access或–time=use 只更改存取時間。
-c或–no-create 不建立任何文件。
-d<時間日期> 使用指定的日期時間,而非現在的時間。
-f 此參數將忽略不予處理,僅負責解決BSD版本touch指令的兼容性問題。
-m或–time=mtime或–time=modify 只更改變動時間。
-r<參考文件或目錄> 把指定文件或目錄的日期時間,統統設成和參考文件或目錄的日期時間相同。
-t<日期時間> 使用指定的日期時間,而非現在的時間。
–help 在線幫助。
–version 显示版本信息。
***umask
功能說明: 指定在建立文件時預設的權限掩碼。
語法: umask [-S][權限掩碼]
補充說明: umask可用來設定[權限掩碼]。[權限掩碼]是由3個八進制的数字所組成,將現有的存取權限減掉權限掩碼后,即可產生建立文件時預設的權限。
參數:
-S 以文字的方式來表示權限掩碼。
***whereis
功能說明: 查找文件。
語法: whereis [-bfmsu][-B <目錄>…][-M <目錄>…][-S <目錄>…][文件…]
補充說明: whereis指令會在特定目錄中查找符合條件的文件。這些文件的烈性應屬於原始代碼,二進制文件,或是幫助文件。
參數:
-b 只查找二進制文件。
-B<目錄> 只在設置的目錄下查找二進制文件。
-f 不显示文件名前的路徑名稱。
-m 只查找說明文件。
-M<目錄> 只在設置的目錄下查找說明文件。
-s 只查找原始代碼文件。
-S<目錄> 只在設置的目錄下查找原始代碼文件。
-u 查找不包含指定類型的文件。
***which
功能說明: 查找文件
語法: which [文件…]
補充說明: which指令會在環境變量$PATH設置的目錄里查找符合條件的文件。
參數:
-n<文件名長度> 指定文件名長度,指定的長度必須大於或等於所有文件中最長的文件名。
-p<文件名長度> 與-n參數相同,但此處的<文件名長度>包括了文件的路徑。
-w 指定輸出時欄位的寬度。
-V 显示版本信息。
***cat
使用權限: 所有使用者
語法: cat [-AbeEnstTuv] [–help] [–version] fileName
說明: 把檔案串連接後傳到基本輸出(螢幕或加 ** > fileName** 到另一個檔案)
參數:
-n 或 –number 由 1 開始對所有輸出的行數編號
-b 或 –number-nonblank 和 -n 相似,只不過對於空白行不編號
-s 或 –squeeze-blank 當遇到有連續兩行以上的空白行,就代換為一行的空白行
-v 或 –show-nonprinting
示例:
cat -n textfile1 > textfile2 把 textfile1 的檔案內容加上行號后輸入 textfile2 這個檔案里
cat -b textfile1 textfile2 >> textfile3 把 textfile1 和 textfile2 的檔案內容加上行號(空白行不加)之後將內容附加到 textfile3 里。
***chattr
功能說明: 改變文件屬性。
語法: chattr [-RV][-v<版本編號>][+/-/=<屬性>][文件或目錄…]
補充說明: 這項指令可改變存放在ext2文件系統上的文件或目錄屬性,這些屬性共有以下8種模式:
a:讓文件或目錄僅供附加用途。
b:不更新文件或目錄的最後存取時間。
c:將文件或目錄壓縮后存放。
d:將文件或目錄排除在傾倒操作之外。
i:不得任意更動文件或目錄。
s:保密性刪除文件或目錄。
S:即時更新文件或目錄。
u:預防以外刪除。
參數:
-R 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-v<版本編號> 設置文件或目錄版本。
-V 显示指令執行過程。
+<屬性> 開啟文件或目錄的該項屬性。
-<屬性> 關閉文件或目錄的該項屬性。
=<屬性> 指定文件或目錄的該項屬性。
***chgrp
功能說明: 變更文件或目錄的所屬群組。
語法: chgrp [-cfhRv][–help][–version][所屬群組][文件或目錄…] 或 chgrp [-cfhRv][–help][–reference=<參考文件或目錄>][–version][文件或目錄…]
補充說明: 在UNIX系統家族裡,文件或目錄權限的掌控以擁有者及所屬群組來管理。您可以使用chgrp指令去變更文件與目錄的所屬群組,設置方式採用群組名稱或群組識別碼皆可。
參數:
-c或–changes 效果類似”-v”參數,但僅回報更改的部分。
-f或–quiet或–silent 不显示錯誤信息。
-h或–no-dereference 只對符號連接的文件作修改,而不更動其他任何相關文件。
-R或–recursive 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-v或–verbose 显示指令執行過程。
–help 在線幫助。
–reference=<參考文件或目錄> 把指定文件或目錄的所屬群組全部設成和參考文件或目錄的所屬群組相同。
–version 显示版本信息。
***chmod
功能說明: 變更文件或目錄的權限。
語法: chmod [-cfRv][–help][–version][<權限範圍>+/-/=<權限設置…>][文件或目錄…] 或 chmod [-cfRv][–help][–version][数字代號][文件或目錄…] 或 chmod [-cfRv][–help][–reference=<參考文件或目錄>][–version][文件或目錄…]
補充說明: 在UNIX系統家族裡,文件或目錄權限的控制分別以讀取,寫入,執行3種一般權限來區分,另有3種特殊權限可供運用,再搭配擁有者與所屬群組管理權限範圍。您可以使用chmod指令去變更文件與目錄的權限,設置方式採用文字或数字代號皆可。符號連接的權限無法變更,如果您對符號連接修改權限,其改變會作用在被連接的原始文件。權限範圍的表示法如下:
u:User,即文件或目錄的擁有者。
g:Group,即文件或目錄的所屬群組。
o:Other,除了文件或目錄擁有者或所屬群組之外,其他用戶皆屬於這個範圍。
a:All,即全部的用戶,包含擁有者,所屬群組以及其他用戶。
有關權限代號的部分,列表於下:
r:讀取權限,数字代號為”4″。
w:寫入權限,数字代號為”2″。
x:執行或切換權限,数字代號為”1″。
-:不具任何權限,数字代號為”0″。
s:特殊?b>功能說明:變更文件或目錄的權限。
參數:
-c或–changes 效果類似”-v”參數,但僅回報更改的部分。
-f或–quiet或–silent 不显示錯誤信息。
-R或–recursive 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-v或–verbose 显示指令執行過程。
–help 在線幫助。
–reference=<參考文件或目錄> 把指定文件或目錄的權限全部設成和參考文件或目錄的權限相同
–version 显示版本信息。
<權限範圍>+<權限設置> 開啟權限範圍的文件或目錄的該項權限設置。
<權限範圍>-<權限設置> 關閉權限範圍的文件或目錄的該項權限設置。
<權限範圍>=<權限設置> 指定權限範圍的文件或目錄的該項權限設置。
***chown
功能說明: 變更文件或目錄的擁有者或所屬群組。
語法: chown [-cfhRv][–dereference][–help][–version][擁有者.<所屬群組>][文件或目錄..] 或chown [-chfRv][–dereference][–help][–version][.所屬群組][文件或目錄… …] 或chown [-cfhRv][–dereference][–help][–reference=<參考文件或目錄>][–version][文件或目錄…]
補充說明: 在UNIX系統家族裡,文件或目錄權限的掌控以擁有者及所屬群組來管理。您可以使用chown指令去變更文件與目錄的擁有者或所屬群組,設置方式採用用戶名稱或用戶識別碼皆可,設置群組則用群組名稱或群組識別碼。
參數:
-c或–changes 效果類似”-v”參數,但僅回報更改的部分。
-f或–quite或–silent 不显示錯誤信息。
-h或–no-dereference 之對符號連接的文件作修改,而不更動其他任何相關文件。
-R或–recursive 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-v或–version 显示指令執行過程。
–dereference 效果和”-h”參數相同。
–help 在線幫助。
–reference=<參考文件或目錄> 把指定文件或目錄的擁有者與所屬群組全部設成和參考文件或目 錄的擁有者與所屬群組相同。
–version 显示版本信息。
***cksum
功能說明: 檢查文件的CRC是否正確。
語法: cksum [–help][–version][文件…]
補充說明: CRC是一種排錯檢查方式,該演算法的標準由CCITT所指定,至少可檢測到99.998%的已知錯誤。指定文件交由cksum演算,它會回報計算結果,供用戶核對文件是否正確無誤。若不指定任何文件名稱或是所給予的文件名為”-“,則cksum指令會從標準輸入設備讀取數據。
參數:
–help 在線幫助。
–version 显示版本信息。
***cmp
功能說明: 比較兩個文件是否有差異。
語法: cmp [-clsv][-i <字符數目>][–help][第一個文件][第二個文件]
補充說明: 當相互比較的兩個文件完全一樣時,則該指令不會显示任何信息。若發現有所差異,預設會標示出第一個不同之處的字符和列數編號。若不指定任何文件名稱或是所給予的文件名為”-“,則cmp指令會從標準輸入設備讀取數據。
參數:
-c或–print-chars 除了標明差異處的十進制字碼之外,一併显示該字符所對應字符。
-i<字符數目>或–ignore-initial=<字符數目> 指定一個數目。
-l或–verbose 標示出所有不一樣的地方。
-s或–quiet或–silent 不显示錯誤信息。
-v或–version 显示版本信息。
–help 在線幫助。
***cp
功能說明: 複製文件或目錄。
語法: cp [-abdfilpPrRsuvx][-S <備份字尾字符串>][-V <備份方式>][–help][–spares=<使用時機>][–version][源文件或目錄][目標文件或目錄] [目的目錄]
補充說明: cp指令用在複製文件或目錄,如同時指定兩個以上的文件或目錄,且最後的目的地是一個已經存在的目錄,則它會把前面指定的所有文件或目錄複製到該目錄中。若同時指定多個文件或目錄,而最後的目的地並非是一個已存在的目錄,則會出現錯誤信息。
參數:
-a或–archive 此參數的效果和同時指定”-dpR”參數相同。
-b或–backup 刪除,覆蓋目標文件之前的備份,備份文件會在字尾加上一個備份字符串。
-d或–no-dereference 當複製符號連接時,把目標文件或目錄也建立為符號連接,並指向與源文件或目錄連接的原始文件或目錄。
-f或–force 強行複製文件或目錄,不論目標文件或目錄是否已存在。
-i或–interactive 覆蓋既有文件之前先詢問用戶。
-l或–link 對源文件建立硬連接,而非複製文件。
-p或–preserve 保留源文件或目錄的屬性。
-P或–parents 保留源文件或目錄的路徑。
-r 遞歸處理,將指定目錄下的文件與子目錄一併處理。
-R或–recursive 遞歸處理,將指定目錄下的所有文件與子目錄一併處理。
-s或–symbolic-link 對源文件建立符號連接,而非複製文件。
-S<備份字尾字符串>或–suffix=<備份字尾字符串> 用”-b”參數備份目標文件后,備份文件的字尾會被加上一個備份字符串,預設的備份字尾字符串是符號”~”。
-u或–update 使用這項參數后只會在源文件的更改時間較目標文件更新時或是 名稱相互對應的目標文件並不存在,才複製文件。
-v或–verbose 显示指令執行過程。
-V<備份方式>或–version-control=<備份方式> 用”-b”參數備份目標文件后,備份文件的字尾會被加上一個備份字符串,這字符串不僅可用”-S”參數變更,當使用”-V”參數指定不同備份方式時,也會產生不同字尾的備份字串。
-x或–one-file-system 複製的文件或目錄存放的文件系統,必須與cp指令執行時所處的文件系統相同,否則不予複製。
–help 在線幫助。
–sparse=<使用時機> 設置保存稀疏文件的時機。
–version 显示版本信息。
***cut
使用權限: 所有使用者
用法: cut -cnum1-num2 filename 說明:显示每行從開頭算起 num1 到 num2 的文字。
範例:
shell>> cat example
test2
this is test1
shell>> cut -c0-6 example ## print 開頭算起前 6 個字元 t
est2
this i
***indent
功能說明: 調整C原始代碼文件的格式。
語法: indent [參數][源文件] 或 indent [參數][源文件][-o 目標文件]
補充說明: indent可辨識C的原始代碼文件,並加以格式化,以方便程序設計師閱讀。
參數:
-bad或–blank-lines-after-declarations 在聲明區段或加上空白行。
-bap或–blank-lines-after-procedures 在程序或加上空白行。
-bbb或–blank-lines-after-block-comments 在註釋區段后加上空白行。
-bc或–blank-lines-after-commas 在聲明區段中,若出現逗號即換行。
-bl或–braces-after-if-line if(或是else,for等等)與後面執行區段的”{“不同行,且”}”自成一行。
-bli<縮排格數>或–brace-indent<縮排格數> 設置{ }縮排的格數。
-br或–braces-on-if-line if(或是else,for等等)與後面執行跛段的”{“不同行,且”}”自成一行。
-bs或–blank-before-sizeof 在sizeof之後空一格。
-c<欄數>或–comment-indentation<欄數> 將註釋置於程序碼右側指定的欄位。
-cd<欄數>或–declaration-comment-column<欄數> 將註釋置於聲明右側指定的欄位。
-cdb或–comment-delimiters-on-blank-lines 註釋符號自成一行。
-ce或–cuddle-else 將else置於”}”(if執行區段的結尾)之後。
-ci<縮排格數>或–continuation-indentation<縮排格數> 敘述過長而換行時,指定換行后縮排的格數。
-cli<縮排格數>或–case-indentation-<縮排格數> 使用case時,switch縮排的格數。
-cp<欄數>或-else-endif-column<欄數> 將註釋置於else與elseif敘述右側定的欄位。
-cs或–space-after-cast 在cast之後空一格。
-d<縮排格數>或-line-comments-indentation<縮排格數> 針對不是放在程序碼右側的註釋,設置其縮排格數。
-di<欄數>或–declaration-indentation<欄數> 將聲明區段的變量置於指定的欄位。
-fc1或–format-first-column-comments 針對放在每行最前端的註釋,設置其格式。
-fca或–format-all-comments 設置所有註釋的格式。
-gnu或–gnu-style 指定使用GNU的格式,此為預設值。
-i<格數>或–indent-level<格數> 設置縮排的格數。
-ip<格數>或–parameter-indentation<格數> 設置參數的縮排格數。
-kr或–k-and-r-style 指定使用Kernighan&Ritchie的格式。
-lp或–continue-at-parentheses 敘述過長而換行,且敘述中包含了括弧時,將括弧中的每行起始欄位內容垂直對其排列。
-nbad或–no-blank-lines-after-declarations 在聲明區段后不要加上空白行。
-nbap或–no-blank-lines-after-procedures 在程序后不要加上空白行。
-nbbb或–no-blank-lines-after-block-comments 在註釋區段后不要加上空白行。
-nbc或–no-blank-lines-after-commas 在聲明區段中,即使出現逗號,仍舊不要換行。
-ncdb或–no-comment-delimiters-on-blank-lines 註釋符號不要自成一行。
-nce或–dont-cuddle-else 不要將else置於”}”之後。
-ncs或–no-space-after-casts 不要在cast之後空一格。
-nfc1或–dont-format-first-column-comments 不要格式化放在每行最前端的註釋。
-nfca或–dont-format-comments 不要格式化任何的註釋。
-nip或–no-parameter-indentation 參數不要縮排。
-nlp或–dont-line-up-parentheses 敘述過長而換行,且敘述中包含了括弧時,不用將括弧中的每行起始欄位垂直對其排列。
-npcs或–no-space-after-function-call-names 在調用的函數名稱之後,不要加上空格。
-npro或–ignore-profile 不要讀取indent的配置文件.indent.pro。
-npsl或–dont-break-procedure-type 程序類型與程序名稱放在同一行。
-nsc或–dont-star-comments 註解左側不要加上星號(*)。
-nsob或–leave-optional-semicolon 不用處理多餘的空白行。
-nss或–dont-space-special-semicolon 若for或while區段僅有一行時,在分號前不加上空格。
-nv或–no-verbosity 不显示詳細的信息。
-orig或–original 使用Berkeley的格式。
-pcs或–space-after-procedure-calls 在調用的函數名稱與”{“之間加上空格。
-psl或–procnames-start-lines 程序類型置於程序名稱的前一行。
-sc或–start-left-side-of-comments 在每行註釋左側加上星號(*)。
-sob或–swallow-optional-blank-lines 刪除多餘的空白行。
-ss或–space-special-semicolon 若for或swile區段今有一行時,在分號前加上空格。
-st或–standard-output 將結果显示在標準輸出設備。
-T 數據類型名稱縮排。
-ts<格數>或–tab-size<格數> 設置tab的長度。
-v或–verbose 執行時显示詳細的信息。
-version 显示版本信息。
磁盤管理
***cd
功能說明: 切換目錄。
語法: cd [目的目錄]
補充說明:
cd指令可讓用戶在不同的目錄間切換,但該用戶必須擁有足夠的權限進入目的目錄。
***df
功能說明: 显示磁盤的相關信息。
語法: df [-ahHiklmPT][–block-size=<區塊大小>][-t <文件系統類型>][-x <文件系統類型>][–help][–no-sync][–sync][–version][文件或設備]
補充說明: df可显示磁盤的文件系統與使用情形。
參數:
-a或–all 包含全部的文件系統。
–block-size=<區塊大小> 以指定的區塊大小來显示區塊數目。
-h或–human-readable 以可讀性較高的方式來显示信息。
-H或–si 與-h參數相同,但在計算時是以1000 Bytes為換算單位而非1024 Bytes。
-i或–inodes 显示inode的信息。
-k或–kilobytes 指定區塊大小為1024字節。
-l或–local 僅显示本地端的文件系統。
-m或–megabytes 指定區塊大小為1048576字節。
–no-sync 在取得磁盤使用信息前,不要執行sync指令,此為預設值。
-P或–portability 使用POSIX的輸出格式。
–sync 在取得磁盤使用信息前,先執行sync指令。
-t<文件系統類型>或–type=<文件系統類型> 僅显示指定文件系統類型的磁盤信息。
-T或–print-type 显示文件系統的類型。
-x<文件系統類型>或–exclude-type=<文件系統類型> 不要显示指定文件系統類型的磁盤信息。
–help 显示幫助。
–version 显示版本信息。
[文件或設備] 指定磁盤設備。
***dirs
功能說明: 显示目錄記錄。
語法: dirs [+/-n -l]
補充說明: 显示目錄堆疊中的記錄。
參數:
+n 显示從左邊算起第n筆的目錄。
-n 显示從右邊算起第n筆的目錄。
-l 显示目錄完整的記錄。
***du
功能說明: 显示目錄或文件的大小。
語法: du [-abcDhHklmsSx][-L <符號連接>][-X <文件>][–block-size][–exclude=<目錄或文件>][–max-depth=<目錄層數>][–help][–version][目錄或文件]
補充說明: du會显示指定的目錄或文件所佔用的磁盤空間。
參數:
-a或-all 显示目錄中個別文件的大小。
-b或-bytes 显示目錄或文件大小時,以byte為單位。
-c或–total 除了显示個別目錄或文件的大小外,同時也显示所有目錄或文件的總和。
-D或–dereference-args 显示指定符號連接的源文件大小。
-h或–human-readable 以K,M,G為單位,提高信息的可讀性。
-H或–si 與-h參數相同,但是K,M,G是以1000為換算單位。
-k或–kilobytes 以1024 bytes為單位。
-l或–count-links 重複計算硬件連接的文件。
-L<符號連接>或–dereference<符號連接> 显示選項中所指定符號連接的源文件大小。
-m或–megabytes 以1MB為單位。
-s或–summarize 僅显示總計。
-S或–separate-dirs 显示個別目錄的大小時,並不含其子目錄的大小。
-x或–one-file-xystem 以一開始處理時的文件系統為準,若遇上其它不同的文件系統目錄則略過。
-X<文件>或–exclude-from=<文件> 在<文件>指定目錄或文件。
–exclude=<目錄或文件> 略過指定的目錄或文件。
–max-depth=<目錄層數> 超過指定層數的目錄后,予以忽略。
–help 显示幫助。
–version 显示版本信息。
***edquota
功能說明: 編輯用戶或群組的quota。
語法: edquota [-p <源用戶名稱>][-ug][用戶或群組名稱…] 或 edquota [-ug] -t
補充說明: edquota預設會使用vi來編輯使用者或群組的quota設置。
參數:
-u 設置用戶的quota,這是預設的參數。
-g 設置群組的quota。
-p<源用戶名稱> 將源用戶的quota設置套用至其他用戶或群組。
-t 設置寬限期限。
***eject
功能說明: 退出抽取式設備。
語法: eject [-dfhnqrstv][-a <開關>][-c <光驅編號>][設備]
補充說明: 若設備已掛入,則eject會先將該設備卸除再退出。
參數: [設備] 設備可以是驅動程序名稱,也可以是掛入點。
-a<開關>或–auto<開關> 控制設備的自動退出功能。
-c<光驅編號>或–changerslut<光驅編號> 選擇光驅櫃中的光驅。
-d或–default 显示預設的設備,而不是實際執行動作。
-f或–floppy 退出抽取式磁盤。
-h或–help 显示幫助。
-n或–noop 显示指定的設備。
-q或–tape 退出磁帶。
-r或–cdrom 退出光盤。
-s或–scsi 以SCSI指令來退出設備。
-t或–trayclose 關閉光盤的托盤。
-v或–verbose 執行時,显示詳細的說明。
***lndir
功能說明: 連接目錄內容。
語法: lndir [-ignorelinks][-silent][源目錄][目的目錄]
補充說明: 執行lndir指令,可一口氣把源目錄底下的文件和子目錄統統建立起相互對應的符號連接。
參數:
-ignorelinks 直接建立符號連接的符號連接。
-silent 不显示指令執行過程。
***ls
功能說明: 列出目錄內容。
語法: ls [-1aAbBcCdDfFgGhHiklLmnNopqQrRsStuUvxX][-I <範本樣式>][-T <跳格字數>][-w <每列字符數>][–block-size=<區塊大小>][–color=<使用時機>][–format=<列表格式>][–full-time][–help][–indicator-style=<標註樣式>][–quoting-style=<引號樣式>][–show-control-chars][–sort=<排序方式>][–time=<時間戳記>][–version][文件或目錄…]
補充說明: 執行ls指令可列出目錄的內容,包括文件和子目錄的名稱。
參數:
-1 每列僅显示一個文件或目錄名稱。
-a或–all 下所有文件和目錄。
-A或–almost-all 显示所有文件和目錄,但不显示現行目錄和上層目錄。
-b或–escape 显示脫離字符。
-B或–ignore-backups 忽略備份文件和目錄。
-c 以更改時間排序,显示文件和目錄。
-C 以又上至下,從左到右的直行方式显示文件和目錄名稱。
-d或–directory 显示目錄名稱而非其內容。
-D或–dired 用Emacs的模式產生文件和目錄列表。
-f 此參數的效果和同時指定”aU”參數相同,並關閉”lst”參數的效果。
-F或–classify 在執行文件,目錄,Socket,符號連接,管道名稱後面,各自加上”*”,”/”,”=”,”@”,”|”號。 *
-g 次參數將忽略不予處理。
-G或–no-group 不显示群組名稱。
-h或–human-readable 用”K”,”M”,”G”來显示文件和目錄的大小。
-H或–si 此參數的效果和指定”-h”參數類似,但計算單位是1000Bytes而非1024Bytes。
-i或–inode 显示文件和目錄的inode編號。
-I<範本樣式>或–ignore=<範本樣式> 不显示符合範本樣式的文件或目錄名稱。
-k或–kilobytes 此參數的效果和指定”block-size=1024″參數相同。
-l 使用詳細格式列表。
-L或–dereference 如遇到性質為符號連接的文件或目錄,直接列出該連接所指向的原始文件或目錄。
-m 用”,”號區隔每個文件和目錄的名稱。
-n或–numeric-uid-gid 以用戶識別碼和群組識別碼替代其名稱。
-N或–literal 直接列出文件和目錄名稱,包括控制字符。
-o 此參數的效果和指定”-l” 參數類似,但不列出群組名稱或識別碼。
-p或–file-type 此參數的效果和指定”-F”參數類似,但不會在執行文件名稱後面加上”*”號。
-q或–hide-control-chars 用”?”號取代控制字符,列出文件和目錄名稱。
-Q或–quote-name 把文件和目錄名稱以””號標示起來。
-r或–reverse 反向排序。
-R或–recursive 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-s或–size 显示文件和目錄的大小,以區塊為單位。
-S 用文件和目錄的大小排序。
-t 用文件和目錄的更改時間排序。
-T<跳格字符>或–tabsize=<跳格字數> 設置跳格字符所對應的空白字符數。
-u 以最後存取時間排序,显示文件和目錄。
-U 列出文件和目錄名稱時不予排序。
-v 文件和目錄的名稱列表以版本進行排序。
-w<每列字符數>或–width=<每列字符數> 設置每列的最大字符數。
-x 以從左到右,由上至下的橫列方式显示文件和目錄名稱。
-X 以文件和目錄的最後一個擴展名排序。
–block-size=<區塊大小> 指定存放文件的區塊大小。
–color=<列表格式> 培植文件和目錄的列表格式。
–full-time 列出完整的日期與時間。
–help 在線幫助。
–indicator-style=<標註樣式> 在文件和目錄等名稱後面加上標註,易於辨識該名稱所屬的類型。
–quoting-syte=<引號樣式> 把文件和目錄名稱以指定的引號樣式標示起來。
–show-control-chars 在文件和目錄列表時,使用控制字符。
–sort=<排序方式> 配置文件和目錄列表的排序方式。
–time=<時間戳記> 用指定的時間戳記取代更改時間。
–version 显示版本信息。
***mcd
功能說明: 在MS-DOS文件系統中切換工作目錄
語法: mcd [目錄名稱]
補充說明:
mcd為mtools工具指令,可在MS-DOS文件系統中切換工作目錄。若不加任何參數,則显示目前所在的磁盤與工作目錄。
***mdeltree
功能說明: 刪除MS-DOS目錄
語法: mdeltree [目錄…]
補充說明: mdel為mtools工具指令,模擬MS-DOS的deltree指令,可刪除MS-DOS文件系統中的目錄及目錄下所有子目錄與文件。
***mdu
功能說明: 显示MS-DOS目錄所佔用的磁盤空間。
語法: mdu [-as][目錄]
補充說明: mdu為mstools工具指令,可显示MS-DOS文件系統中目錄所佔用的磁盤空間。
參數:
-a 显示每個文件及整個目錄所佔用的空間。
-s 僅显示整個目錄所佔用的空間。
***mkdir
功能說明: 建立目錄
語法: mkdir [-p][–help][–version][-m <目錄屬性>][目錄名稱]
補充說明: mkdir可建立目錄並同時設置目錄的權限。
參數:
-m<目錄屬性>或–mode<目錄屬性> 建立目錄時同時設置目錄的權限。
-p或–parents 若所要建立目錄的上層目錄目前尚未建立,則會一併建立上層目錄。
–help 显示幫助。
–verbose 執行時显示詳細的信息。
–version 显示版本信息。
***mlabel
功能說明: 显示或設置MS-DOS磁盤驅動器的標籤名稱。
語法: mlabel [-csvV][驅動器代號][標籤名稱]
補充說明: mlabel為mtools工具指令,模擬MS-DOS的label指令,可显示或設置MS-DOS磁盤驅動器的標籤名稱。
參數:
-c 清楚標籤名稱
-s 显示標籤名稱
-v 執行時显示詳細的信息。
-V 显示版本信息。
***mmd
功能說明: 在MS-DOS文件系統中建立目錄。
語法: mmd [目錄…]
補充說明: mmd為mtools工具指令,模擬MS-DOS的md指令,可在MS-DOS的文件系統中建立目錄。
***mmount
功能說明: 掛入MS-DOS文件系統。
語法: mmount [驅動器代號][mount參數]
補充說明: mmount為mtools工具指令,可根據[mount參數]中的設置,將磁盤內容掛入到Linux目錄中。
參數:
[mount參數]的用法請參考mount指令
***mrd
功能說明: 刪除MS-DOS文件系統中的目錄。
語法: mrd [目錄…]
補充說明: mrd為mtools工具指令,模擬MS-DOS的rd指令,可刪除MS-DOS的目錄。
***mzip
功能說明: Zip/Jaz磁盤驅動器控制指令。
語法: mzip [-efpqruwx]
補充說明: mzip為mtools工具指令,可設置Zip或Jaz磁盤驅動區的保護模式以及執行退出磁盤的動作。
參數:
-e 退出磁盤。
-f 與-e參數一併使用,不管是否已經掛入磁盤中的文件系統,一律強制退出磁盤。
-p 設置磁盤的寫入密碼。
-q 显示目前的狀態。
-r 將磁盤設為防寫狀態。
-u 退出磁盤以前,暫時解除磁盤的保護狀態。
-w 將磁盤設為可寫入狀態。
-x 設置磁盤的密碼。
***pwd
功能說明: 显示工作目錄。
語法: pwd [–help][–version]
補充說明: 執行pwd指令可立刻得知您目前所在的工作目錄的絕對路徑名稱。
參數:
–help 在線幫助。
–version 显示版本信息。
***quota
功能說明: 显示磁盤已使用的空間與限制。
語法: quota [-quvV][用戶名稱…] 或 quota [-gqvV][群組名稱…]
補充說明: 執行quota指令,可查詢磁盤空間的限制,並得知已使用多少空間。
參數:
-g 列出群組的磁盤空間限制。
-q 簡明列表,只列出超過限制的部分。
-u 列出用戶的磁盤空間限制。
-v 显示該用戶或群組,在所有掛入系統的存儲設備的空間限制。
-V 显示版本信息。
***quotacheck
功能說明: 檢查磁盤的使用空間與限制。
語法: quotacheck [-adgRuv][文件系統…]
補充說明: 執行quotacheck指令,掃描掛入系統的分區,並在各分區的文件系統根目錄下產生quota.user和quota.group文件,設置用戶和群組的磁盤空間限制。
參數:
-a 掃描在/etc/fstab文件里,有加入quota設置的分區。
-d 詳細显示指令執行過程,便於排錯或了解程序執行的情形。
-g 掃描磁盤空間時,計算每個群組識別碼所佔用的目錄和文件數目。
-R 排除根目錄所在的分區。
-u 掃描磁盤空間時,計算每個用戶識別碼所佔用的目錄和文件數目。
-v 显示指令執行過程。
***quotaoff
功能說明: 關閉磁盤空間限制。
語法: quotaoff [-aguv][文件系統…]
補充說明: 執行quotaoff指令可關閉用戶和群組的磁盤空間限制。
參數:
-a 關閉在/etc/fstab文件里,有加入quota設置的分區的空間限制。
-g 關閉群組的磁盤空間限制。
-u 關閉用戶的磁盤空間限制。
-v 显示指令執行過程。
***quotaon
功能說明: 開啟磁盤空間限制。
語法: quotaon [-aguv][文件系統…]
補充說明: 執行quotaon指令可開啟用戶和群組的才磅秒年空間限制,各分區的文件系統根目錄必須有quota.user和quota.group配置文件。
參數:
-a 開啟在/ect/fstab文件里,有加入quota設置的分區的空間限制。
-g 開啟群組的磁盤空間限制。
-u 開啟用戶的磁盤空間限制。
-v 显示指令指令執行過程。
***repquota
功能說明: 檢查磁盤空間限制的狀態。
語法: repquota [-aguv][文件系統…]
補充說明: 執行repquota指令,可報告磁盤空間限制的狀況,清楚得知每位用戶或每個群組已使用多少空間。
參數:
-a 列出在/etc/fstab文件里,有加入quota設置的分區的使用狀況,包括用戶和群組。
-g 列出所有群組的磁盤空間限制。
-u 列出所有用戶的磁盤空間限制。
-v 显示該用戶或群組的所有空間限制。
***rmdir
功能說明: 刪除目錄。
語法: rmdir [-p][–help][–ignore-fail-on-non-empty][–verbose][–version][目錄…]
補充說明: 當有空目錄要刪除時,可使用rmdir指令。
參數:
-p或–parents 刪除指定目錄后,若該目錄的上層目錄已變成空目錄,則將其一併刪除。
–help 在線幫助。
–ignore-fail-on-non-empty 忽略非空目錄的錯誤信息。
–verbose 显示指令執行過程。
–version 显示版本信息。
***rmt
功能說明: 遠端磁帶傳輸協議模塊。
語法: rmt
補充說明: 通過rmt指令,用戶可通過IPC連線,遠端操控磁帶機的傾倒和還原操作。
***stat
功能說明: 显示inode內容。
語法: stat [文件或目錄]
補充說明: stat以文字的格式來显示inode的內容。
***tree
功能說明: 以樹狀圖列出目錄的內容。
語法: tree [-aACdDfFgilnNpqstux][-I <範本樣式>][-P <範本樣式>][目錄…]
補充說明: 執行tree指令,它會列出指定目錄下的所有文件,包括子目錄里的文件。
參數:
-a 显示所有文件和目錄。
-A 使用ASNI繪圖字符显示樹狀圖而非以ASCII字符組合。
-C 在文件和目錄清單加上色彩,便於區分各種類型。
-d 显示目錄名稱而非內容。
-D 列出文件或目錄的更改時間。
-f 在每個文件或目錄之前,显示完整的相對路徑名稱。
-F 在執行文件,目錄,Socket,符號連接,管道名稱名稱,各自加上”*”,”/”,”=”,”@”,”|”號。
-g 列出文件或目錄的所屬群組名稱,沒有對應的名稱時,則显示群組識別碼。
-i 不以階梯狀列出文件或目錄名稱。
-I<範本樣式> 不显示符合範本樣式的文件或目錄名稱。
-l 如遇到性質為符號連接的目錄,直接列出該連接所指向的原始目錄。
-n 不在文件和目錄清單加上色彩。
-N 直接列出文件和目錄名稱,包括控制字符。
-p 列出權限標示。
-P<範本樣式> 只显示符合範本樣式的文件或目錄名稱。
-q 用”?”號取代控制字符,列出文件和目錄名稱。
-s 列出文件或目錄大小。
-t 用文件和目錄的更改時間排序。
-u 列出文件或目錄的擁有者名稱,沒有對應的名稱時,則显示用戶識別碼。
-x 將範圍局限在現行的文件系統中,若指定目錄下的某些子目錄,其存放於另一個文件系統上,則將該子目錄予以排除在尋找範圍外。
***umount
功能說明: 卸除文件系統。
語法: umount [-ahnrvV][-t <文件系統類型>][文件系統]
補充說明: umount可卸除目前掛在Linux目錄中的文件系統。
參數:
-a 卸除/etc/mtab中記錄的所有文件系統。
-h 显示幫助。
-n 卸除時不要將信息存入/etc/mtab文件中。
-r 若無法成功卸除,則嘗試以只讀的方式重新掛入文件系統。
-t<文件系統類型> 僅卸除選項中所指定的文件系統。
-v 執行時显示詳細的信息。
-V 显示版本信息。
[文件系統] 除了直接指定文件系統外,也可以用設備名稱或掛入點來表示文件系統。
磁盤維護
***badblocks
功能說明: 檢查磁盤裝置中損壞的區塊。
語法: badblocks [-svw][-b <區塊大小>][-o <輸出文件>][磁盤裝置][磁盤區塊數][啟始區塊]
補充說明: 執行指令時須指定所要檢查的磁盤裝置,及此裝置的磁盤區塊數。
參數:
-b<區塊大小> 指定磁盤的區塊大小,單位為字節。
-o<輸出文件> 將檢查的結果寫入指定的輸出文件。
-s 在檢查時显示進度。
-v 執行時显示詳細的信息。
-w 在檢查時,執行寫入測試。
[磁盤裝置] 指定要檢查的磁盤裝置。
[磁盤區塊數] 指定磁盤裝置的區塊總數。
[啟始區塊] 指定要從哪個區塊開始檢查。
***cfdisk
功能說明: 磁盤分區。
語法: cfdisk [-avz][-c <柱面數目>-h <磁頭數目>-s <盤區數目>][-P <r,s,t>][外圍設備代號]
補充說明: cfdisk是用來磁盤分區的程序,它十分類似DOS的fdisk,具有互動式操作界面而非傳統fdisk的問答式界面,您可以輕易地利用方向鍵來操控分區操作。
參數:
-a 在程序里不用反白代表選取,而以箭頭表示。
-c<柱面數目> 忽略BIOS的數值,直接指定磁盤的柱面數目。
-h<磁頭數目> 忽略BIOS的數值,直接指定磁盤的磁頭數目。
-P<r,s,t> 显示分區表的內容,附加參數”r”會显示整個分區表的詳細資料,附加參數”s”會依照磁區的順序显示相關信息,附加參數”t”則會以磁頭,磁區,柱面的方式來显示資料。
-s<磁區數目> 忽略BIOS的數值,直接指定磁盤的磁區數目。
-v 显示版本信息。
-z 不讀取現有的分區,直接當作沒有分區的新磁盤使用。
***dd
功能說明: 讀取,轉換並輸出數據。
語法: dd [bs=<字節數>][cbs=<字節數>][conv=<關鍵字>][count=<區塊數>][ibs=<字節數>][if=<文件>][obs=<字節數>][of=<文件>][seek=<區塊數>][skip=<區塊數>][–help][–version]
補充說明: dd可從標準輸入或文件讀取數據,依指定的格式來轉換數據,再輸出到文件,設備或標準輸出。
參數:
bs=<字節數> 將ibs( 輸入)與obs(輸出)設成指定的字節數。
cbs=<字節數> 轉換時,每次只轉換指定的字節數。
conv=<關鍵字> 指定文件轉換的方式。
count=<區塊數> 僅讀取指定的區塊數。
ibs=<字節數> 每次讀取的字節數。
if=<文件> 從文件讀取。
obs=<字節數> 每次輸出的字節數。
of=<文件> 輸出到文件。
seek=<區塊數> 一開始輸出時,跳過指定的區塊數。
skip=<區塊數> 一開始讀取時,跳過指定的區塊數。
–help 幫助。
–version 显示版本信息。
***e2fsck
功能說明: 檢查ext2文件系統的正確性。
語法: e2fsck [-acCdfFnprsStvVy][-b ][-B <區塊大小>][-l <文件>][-L <文件>][設備名稱]
補充說明: e2fsck執行后的傳回值及代表意義如下。
0 沒有任何錯誤發生。
1 文件系統發生錯誤,並且已經修正。
2 文件系統發生錯誤,並且已經修正。
4 文件系統發生錯誤,但沒有修正。
8 運作時發生錯誤。
16 使用的語法發生錯誤。
128 共享的函數庫發生錯誤。
參數:
-a 不詢問使用者意見,便自動修復文件系統。
-b 指定superblock,而不使用預設的superblock。
-B<區塊大小> 指定區塊的大小,單位為字節。
-c 一併執行badblocks,以標示損壞的區塊。
-C 將檢查過程的信息完整記錄在file descriptor中,使得整個檢查過程都能完整監控。
-d 显示排錯信息。
-f 即使文件系統沒有錯誤跡象,仍強制地檢查正確性。
-F 執行前先清除設備的緩衝區。
-l<文件> 將文件中指定的區塊加到損壞區塊列表。
-L<文件> 先清除損壞區塊列表,再將文件中指定的區塊加到損壞區塊列表。因此損壞區塊列表的區塊跟文件中指定的區塊是一樣的。
-n 以只讀模式開啟文件系統,並採取非互動方式執行,所有的問題對話均設置以”no”回答。
-p 不詢問使用者意見,便自動修復文件系統。
-r 此參數只為了兼容性而存在,並無實際作用。
-s 如果文件系統的字節順序不適當,就交換字節順序,否則不做任何動作。
-S 不管文件系統的字節順序,一律交換字節順序。
-t 显示時間信息。
-v 執行時显示詳細的信息。
-V 显示版本信息。
-y 採取非互動方式執行,所有的問題均設置以”yes”回答。
***ext2ed
功能說明: ext2文件系統編輯程序。
語法: ext2ed
補充說明: ext2ed可直接處理硬盤分區上的數據,這指令只有Red Hat Linux才提供。
參數:
功能說明: ext2文件系統編輯程序。
語法: ext2ed
補充說明: ext2ed可直接處理硬盤分區上的數據,這指令只有Red Hat Linux才提供。
參數:
一般指令
setdevice[設備名稱] 指定要處理的設備。 disablewrite 將ext2ed設為只讀的狀態。 enablewrite 將ext2ed設為可讀寫的狀態。 help[指令] 显示個別指令的幫助。 next 移至下一個單位,單位會依目前所在的模式而異。 prev 移至前一個單位,單位會依目前所在的模式而異。 pgup 移至下一頁。 pgdn 移至上一頁。 set 修改目前的數據,參數會依目前所在的模式而異。 writedata 在執行此指令之後,才會實際修改分區中的數據。
ext2進入3種模式的指令
super 進入main superblock,即Superblock模式。 group<編號> 進入指定的group,即Group模式。 cd<目錄或文件> 在inode模式下,進入指定的目錄或文件,即Inode模式。
Superblock模式
gocopy<備份編號> 進入指定的superblock備份。 setactivecopy 將目前所在的superblock,複製到main superblock。
Group模式
blockbitmap 显示目前groupo的區塊圖。 inode 進入目前group的第一個inode。 inodebitmap 显示目前group的inode二進制碼。
Inode模式
dir 進入目錄模式。 file 進入文件模式。
***fdisk
功能說明: 磁盤分區。
語法: fdisk [-b <分區大小>][-uv][外圍設備代號] 或 fdisk [-l][-b <分區大小>][-uv][外圍設備代號…] 或 fdisk [-s <分區編號>]
補充說明: fdisk是用來磁盤分區的程序,它採用傳統的問答式界面,而非類似DOS fdisk的cfdisk互動式操作界面,因此在使用上較為不便,但功能卻絲毫不打折扣。
參數:
-b<分區大小> 指定每個分區的大小。
-l 列出指定的外圍設備的分區表狀況。
-s<分區編號> 將指定的分區大小輸出到標準輸出上,單位為區塊。
-u 搭配”-l”參數列表,會用分區數目取代柱面數目,來表示每個分區的起始地址。
-v 显示版本信息。
***fsck.ext2
功能說明: 檢查文件系統並嘗試修復錯誤。
語法: fsck.ext2 [-acdfFnprsStvVy][-b <分區第一個磁區地址>][-B <區塊大小>][-C <反敘述器>][-I <inode緩衝區塊數>][-l/L <損壞區塊文件>][-P <處理inode大小>][外圍設備代號]
補充說明: 當ext2文件系統發生錯誤時,可用fsck.ext2指令嘗試加以修復。
參數:
-a 自動修復文件系統,不詢問任何問題。
-b<分區第一個磁區地址> 指定分區的第一個磁區的起始地址,也就是Super Block。
-B<區塊大小> 設置該分區每個區塊的大小。
-c 檢查指定的文件系統內,是否存在有損壞的區塊。
-C<反敘述器> 指定反敘述器,fsck.ext2指令會把全部的執行過程,都交由其逆向敘述,便於排錯或監控程序執行的情形。
-d 詳細显示指令執行過程,便於排錯或分析程序執行的情形。
-f 強制對該文件系統進行完整檢查,縱然該文件系統在慨略檢查下沒有問題。
-F 檢查文件系統之前,先清理該保存設備塊區內的數據。
-I<inode緩衝區塊數> 設置欲檢查的文件系統,其inode緩衝區的區塊數目。
-l<損壞區塊文件> 把文件中所列出的區塊,視為損壞區塊並將其標示出來,避免應用程序使用該區塊。
-L<損壞區塊文件> 此參數的效果和指定”-l”參數類似,但在參考損壞區塊文件標示損壞區塊之前,會先將原來標示成損壞區塊者統統清楚,即全部重新設置,而非僅是加入新的損壞區塊標示。
-n 把欲檢查的文件系統設成只讀,並關閉互動模式,否決所有詢問的問題。
-p 此參數的效果和指定”-a”參數相同。
-P<處理inode大小> 設置fsck.ext2指令所能處理的inode大小為多少。
-r 此參數將忽略不予處理,僅負責解決兼容性的問題。
-s 檢查文件系統時,交換每對字節的內容。
-S 此參數的效果和指定”-s”參數類似,但不論該文件系統是否已是標準位順序,一律交換每對字節的內容。
-t 显示fsck.ext2指令的時序信息。
-v 詳細显示指令執行過程。
-V 显示版本信息。
-y 關閉互動模式,且同意所有詢問的問題。
***fsck
功能說明: 檢查文件系統並嘗試修復錯誤。
語法: fsck [-aANPrRsTV][-t <文件系統類型>][文件系統…]
補充說明: 當文件系統發生錯誤四化,可用fsck指令嘗試加以修復。
參數:
-a 自動修復文件系統,不詢問任何問題。
-A 依照/etc/fstab配置文件的內容,檢查文件內所列的全部文件系統。
-N 不執行指令,僅列出實際執行會進行的動作。
-P 當搭配”-A”參數使用時,則會同時檢查所有的文件系統。
-r 採用互動模式,在執行修復時詢問問題,讓用戶得以確認並決定處理方式。
-R 當搭配”-A”參數使用時,則會略過/目錄的文件系統不予檢查。
-s 依序執行檢查作業,而非同時執行。
-t<文件系統類型> 指定要檢查的文件系統類型。
-T 執行fsck指令時,不显示標題信息。
-V 显示指令執行過程。
***fsck.minix
功能說明: 檢查文件系統並嘗試修復錯誤。
語法: fsck.minix [-aflmrsv][外圍設備代號]
補充說明: 當minix文件系統發生錯誤時,可用fsck.minix指令嘗試加以參考。
參數:
-a 自動修復文件系統,不詢問任何問題。
-f 強制對該文件系統進行完整檢查,縱然該文件系統在慨略檢查下沒有問題。
-l 列出所有文件名稱。
-m 使用類似MINIX操作系統的警告信息。
-r 採用互動模式,在執行修復時詢問問題,讓用戶得以確認並決定處理方式。
-s 显示該分區第一個磁區的相關信息。
-v 显示指令執行過程。
***fsconf
功能說明: 設置文件系統相關功能。
語法: fsconf [–check]
補充說明: fsconf是Red Hat Linux發行版專門用來調整Linux各項設置的程序。
參數: –chedk 檢查特定文件的權限。
***hdparm
功能說明: 显示與設定硬盤的參數。
語法: hdparm [-CfghiIqtTvyYZ][-a <快取分區>][-A <0或1>][-c ][-d <0或1>][-k <0或1>][-K <0或1>][-m <分區數>][-n <0或1>][-p ][-P <分區數>][-r <0或1>][-S <時間>][-u <0或1>][-W <0或1>][-X <傳輸模式>][設備]
補充說明: hdparm可檢測,显示與設定IDE或SCSI硬盤的參數。
參數:
-a<快取分區> 設定讀取文件時,預先存入塊區的分區數,若不加上<快取分區>選項,則显示目前的設定。
-A<0或1> 啟動或關閉讀取文件時的快取功能。
-c<I/O模式> 設定IDE32位I/O模式。
-C 檢測IDE硬盤的電源管理模式。
-d<0或1> 設定磁盤的DMA模式。
-f 將內存緩衝區的數據寫入硬盤,並清楚緩衝區。
-g 显示硬盤的磁軌,磁頭,磁區等參數。
-h 显示幫助。
-i 显示硬盤的硬件規格信息,這些信息是在開機時由硬盤本身所提供。
-I 直接讀取硬盤所提供的硬件規格信息。
-k<0或1> 重設硬盤時,保留-dmu參數的設定。
-K<0或1> 重設硬盤時,保留-APSWXZ參數的設定。
-m<磁區數> 設定硬盤多重分區存取的分區數。
-n<0或1> 忽略硬盤寫入時所發生的錯誤。
-p<PIO模式> 設定硬盤的PIO模式。
-P<磁區數> 設定硬盤內部快取的分區數。
-q 在執行後續的參數時,不在屏幕上显示任何信息。
-r<0或1> 設定硬盤的讀寫模式。
-S<時間> 設定硬盤進入省電模式前的等待時間。
-t 評估硬盤的讀取效率。
-T 平谷硬盤快取的讀取效率。
-u<0或1> 在硬盤存取時,允許其他中斷要求同時執行。
-v 显示硬盤的相關設定。
-W<0或1> 設定硬盤的寫入快取。
-X<傳輸模式> 設定硬盤的傳輸模式。
-y 使IDE硬盤進入省電模式。
-Y 使IDE硬盤進入睡眠模式。
-Z 關閉某些Seagate硬盤的自動省電功能。
***losetup
功能說明: 設置循環設備。
語法: losetup [-d][-e <加密方式>][-o <平移數目>][循環設備代號][文件]
補充說明: 循環設備可把文件虛擬成區塊設備,籍以模擬整個文件系統,讓用戶得以將其視為硬盤驅動器,光驅或軟驅等設備,並掛入當作目錄來使用。
參數:
-d 卸除設備。
-e<加密方式> 啟動加密編碼。
-o<平移數目> 設置數據平移的數目。
***mbadblocks
功能說明: 檢查MS-DOS文件系統的磁盤是否有損壞的磁區。
語法: mbadblocks [驅動器代號]
補充說明: mbadblocks為mtools工具指令,可用來掃描MS-DOS文件系統的磁盤驅動器,並標示出損壞的磁區。
***mformat
功能說明: 對MS-DOS文件系統的磁盤進行格式化。
語法: mformat [-1aCFIKX][-0 <數據傳輸率>][-2 <磁區數>][-A <數據傳輸率>][-B <開機區文件>][-c <叢集大小>][-h <磁頭數>][-H <隱藏磁區數>][-l <磁盤標籤>][-M <磁區大小>][-n <序號>][-r <根目錄大小>][-s <磁區數>][-S <磁區大小>][-t <柱面數>][驅動器代號]
補充說明: mformat為mtools工具指令,模擬MS-DOS的format指令,可將指定的磁盤或硬盤分區格式化為MS-DOS文件系統。
參數:
-0<數據傳輸率> 指定第0磁軌的數據傳輸率。
-1 不使用2M格式。
-2<磁區數> 指定在第0磁軌的第0個磁頭的磁區數,也就是所謂的2M格式。
-a 指定產生Atari格式的序號。
-A<數據傳輸率> 指定第0磁軌以外所有磁軌的數據傳輸率。
-B<開機區文件> 從指定的文件來建立開機區。
-c<叢集大小> 指定叢集大小,單位為磁區。
-C 建立磁盤MS-DOS文件系統的映像文件。
-F 以FAT32來格式化磁盤。
-H<隱藏磁區數> 指定隱藏磁區的數目。
-I 指定FAT32的frVersion編號。
-k 盡可能地保留原有的開機區。
-l<磁盤標籤> 指定磁盤標籤名稱。
-M<磁區大小> 指定MS-DOS文件系統所使用的磁區大小,預設應該與硬體磁區大小相同,單位為字節。
-n<序號> 指定序號。
-r<根目錄大小> 指定根目錄的大小,單位為磁區。
-s<磁區數> 指定每一磁軌所包含的磁區數目。
-S<磁區大小> 指定硬件磁區大小。
-t<柱面數> 指定柱面數目。
-X 格式化XDF磁盤。
***mkbootdisk
功能說明: 建立目前系統的啟動盤。
語法: mkbootdisk [–noprompt][–verbose][–version][–device <設備>][–mkinitrdargs <參數>][kernel 版本]
補充說明: mkbootdisk可建立目前系統的啟動盤。
參數:
–device<設備> 指定設備。
–mkinitrdargs<參數> 設置mkinitrd的參數。
–noprompt 不會提示用戶插入磁盤。
–verbose 執行時显示詳細的信息。
–version 显示版本信息。
***mkdosfs
功能說明: 建立MS-DOS文件系統。
語法: mkdosfs [-cv][-f ][-F <FAT記錄的單位>][-i <磁盤序號>][-l <文件名>][-m <信息文件>][-n <標籤>][-r <根目錄項目數>][-s <磁區數>][設備名稱][區塊數]
補充說明: mkdosfs可在Linux下,將磁盤格式化為MS-DOS文件系統的格式。
參數:
-c 檢查是否有損壞的區塊。
-f<FAT數目> 指定FAT的數目,目前支持1與2兩種選項。
-F<FAT記錄的單位> 指定FAT記錄的單位為12或16位。
-i<磁盤序號> 設置文件系統的磁盤序號。
-l<文件名> 從指定的文件中,讀取文件系統中損壞區塊的信息。
-m<信息文件> 若以次文件系統開機,而卻因操作系統沒有正常安裝,則會显示選項中所指定的信息文件內容。
-n<標籤> 設置文件系統的磁盤標籤名稱。
-r<根目錄項目數> 設置根目錄最多能記載項目數。
-s<磁區數> 指定每個叢集所包含的磁區數。
-v 執行時显示詳細的信息。
***mke2fs
功能說明: 建立ext2文件系統。
語法: mke2fs [-cFMqrSvV][-b <區塊大小>][-f <不連續區段大小>][-i <字節>][-N <inode數>][-l <文件>][-L <標籤>][-m <百分比值>][-R=<區塊數>][ 設備名稱][區塊數]
補充說明: mke2fs可建立Linux的ext2文件系統。
參數:
-b<區塊大小> 指定區塊大小,單位為字節。
-c 檢查是否有損壞的區塊。
-f<不連續區段大小> 指定不連續區段的大小,單位為字節。
-F 不管指定的設備為何,強制執行mke2fs。
-i<字節> 指定”字節/inode”的比例。
-N<inode數> 指定要建立的inode數目。
-l<文件> 從指定的文件中,讀取文件西中損壞區塊的信息。
-L<標籤> 設置文件系統的標籤名稱。
-m<百分比值> 指定給管理員保留區塊的比例,預設為5%。
-M 記錄最後一次掛入的目錄。
-q 執行時不显示任何信息。
-r 指定要建立的ext2文件系統版本。
-R=<區塊數> 設置磁盤陣列參數。
-S 僅寫入superblock與group descriptors,而不更改inode able inode bitmap以及block bitmap。
-v 執行時显示詳細信息。
-V 显示版本信息。
*** mkfs.ext2
功能說明: 與mke2fs相同。
***mkfs
功能說明: 建立各種文件系統。
語法: mkfs [-vV][fs][-f <文件系統類型>][設備名稱][區塊數]
補充說明: mkfs本身並不執行建立文件系統的工作,而是去調用相關的程序來執行。
參數:
fs 指定建立文件系統時的參數。
-t<文件系統類型> 指定要建立何種文件系統。
-v 显示版本信息與詳細的使用方法。
-V 显示簡要的使用方法。
***mkfs.minix
功能說明: 建立Minix文件系統。
語法: mkfs.minix [-cv][-i ][-l <文件>][-n <文件名長度>][設備名稱][區塊數]
補充說明: mkfs.minix可建立Minix文件系統。
參數:
-c 檢查是否有損壞的區塊。
-i<inode數目> 指定文件系統的inode總數。
-l<文件> 從指定的文件中,讀取文件系統中損壞區塊的信息。
-n<文件名長度> 指定文件名稱長度的上限。
-v 建立第2版的Minix文件系統。
***mkfs.msdos
功能說明: 與mkdosfs相同。
***mkinitrd
功能說明: 建立要載入ramdisk的映像文件。
語法: mkinitrd [-fv][–omit-scsi-modules][–version][–preload=<模塊名稱>][–with=<模塊名稱>][映像文件][Kernel 版本]
補充說明: mkinitrd可建立映像文件,以供Linux開機時載入ramdisk。
參數:
-f 若指定的映像問家名稱與現有文件重複,則覆蓋現有的文件。
-v 執行時显示詳細的信息。
–omit-scsi-modules 不要載入SCSI模塊。
–preload=<模塊名稱> 指定要載入的模塊。
–with=<模塊名稱> 指定要載入的模塊。
–version 显示版本信息。
***mkisofs
功能說明: 建立ISO 9660映像文件。
語法: mkisofs [-adDfhJlLNrRTvz][-print-size][-quiet][-A <應用程序ID>][-abstract <摘要文件>][-b <開機映像文件>][-biblio <ISBN文件>][-c <開機文件名稱>][-C <盤區編號,磁區編號>][-copyright <版權信息文件>][-hide <目錄或文件名>][-hide-joliet <文件或目錄名>][-log-file <記錄文件>][-m <目錄或文件名>][-M <開機映像文件>][-o <映像文件>][-p <數據處理人>][-P <光盤發行人>][-sysid <系統ID >][-V <光盤ID >][-volset <卷冊集ID>][-volset-size <光盤總數>][-volset-seqno <卷冊序號>][-x <目錄>][目錄或文件]
補充說明: mkisofs可將指定的目錄與文件做成ISO 9660格式的映像文件,以供刻錄光盤。
參數:
-a或–all mkisofs通常不處理備份文件。使用此參數可以把備份文件加到映像文件中。
-A<應用程序ID>或-appid<應用程序ID> 指定光盤的應用程序ID。
-abstract<摘要文件> 指定摘要文件的文件名。
-b<開機映像文件>或-eltorito-boot<開機映像文件> 指定在製作可開機光盤時所需的開機映像文件。
-biblio<ISBN文件> 指定ISBN文件的文件名,ISBN文件位於光盤根目錄下,記錄光盤的ISBN。
-c<開機文件名稱> 製作可開機光盤時,mkisofs會將開機映像文件中的全-eltorito-catalog<開機文件名稱>全部內容作成一個文件。
-C<盤區編號,盤區編號> 將許多節區合成一個映像文件時,必須使用此參數。 –
copyright<版權信息文件> 指定版權信息文件的文件名。
-d或-omit-period 省略文件后的句號。
-D或-disable-deep-relocation ISO 9660最多只能處理8層的目錄,超過8層的部分,RRIP會自動將它們設置成ISO 9660兼容的格式。使用-D參數可關閉此功能。
-f或-follow-links 忽略符號連接。
-h 显示幫助。
-hide<目錄或文件名> 使指定的目錄或文件在ISO 9660或Rock RidgeExtensions的系統中隱藏。
-hide-joliet<目錄或文件名> 使指定的目錄或文件在Joliet系統中隱藏。
-J或-joliet 使用Joliet格式的目錄與文件名稱。
-l或-full-iso9660-filenames 使用ISO 9660 32字符長度的文件名。
-L或-allow-leading-dots 允許文件名的第一個字符為句號。
-log-file<記錄文件> 在執行過程中若有錯誤信息,預設會显示在屏幕上。
-m<目錄或文件名>或-exclude<目錄或文件名> 指定的目錄或文件名將不會房入映像文件中。
-M<映像文件>或-prev-session<映像文件> 與指定的映像文件合併。
-N或-omit-version-number 省略ISO 9660文件中的版本信息。
-o<映像文件>或-output<映像文件> 指定映像文件的名稱。
-p<數據處理人>或-preparer<數據處理人> 記錄光盤的數據處理人。
-print-size 显示預估的文件系統大小。
-quiet 執行時不显示任何信息。
-r或-rational-rock 使用Rock Ridge Extensions,並開放全部文件的讀取權限。
-R或-rock 使用Rock Ridge Extensions。
-sysid<系統ID> 指定光盤的系統ID。
-T或-translation-table 建立文件名的轉換表,適用於不支持Rock Ridge Extensions的系統上。
-v或-verbose 執行時显示詳細的信息。
-V<光盤ID>或-volid<光盤ID> 指定光盤的卷冊集ID。
-volset-size<光盤總數> 指定卷冊集所包含的光盤張數。
-volset-seqno<卷冊序號> 指定光盤片在卷冊集中的編號。
-x<目錄> 指定的目錄將不會放入映像文件中。
-z 建立通透性壓縮文件的SUSP記錄,此記錄目前只在Alpha機器上的Linux有效。
***mkswap
功能說明: 設置交換區(swap area)。
語法: mkswap [-cf][-v0][-v1][設備名稱或文件][交換區大小]
補充說明: mkswap可將磁盤分區或文件設為Linux的交換區。
參數:
-c 建立交換區前,先檢查是否有損壞的區塊。
-f 在SPARC電腦上建立交換區時,要加上此參數。
-v0 建立舊式交換區,此為預設值。
-v1 建立新式交換區。 [交換區大小] 指定交換區的大小,單位為1024字節。
***mpartition
功能說明: 建立或刪除MS-DOS的分區。
語法: mpartition [-acdfIprv][-b <磁區數>][-h <磁頭數>][l <磁區數>][-s <磁區數>][-t <柱面數>][驅動器代號]
補充說明: mpartition為mtools工具指令,可建立或刪除磁盤分區。
參數:
-a 將分區設置為可開機分區。
-b<磁區數> 建立分區時,指定要從第幾個磁區開始建立分區。
-c 建立分區。
-d 將分區設置為無法開機的分區。
-f 強制地修改分區而不管檢查時發生的錯誤信息。
-h<磁頭數> 建立分區時,指定分區的磁頭數。
-I 刪除全部的分區。
-l<磁區數> 建立分區時,指定分區的容量大小,單位為磁區數。
-p 當要重新建立分區時,显示命令列。
-r 刪除分區。
-s<磁區數> 建立分區時,指定每個磁軌的磁區數。
-t<柱面數> 建立分區時,指定分區的柱面數。
-v 與-p參數一併使用,若沒有同時下達修改分區的命令,則显示目前分區的狀態。
***sfdisk
功能說明: 硬盤恩區工具程序。
語法: sfdisk [-?Tvx][-d <硬盤>][-g <硬盤>][-l <硬盤>][-s <分區>][-V <硬盤>]
補充說明: sfdisk為硬盤分區工具程序,可显示分區的設置信息,並檢查分區是否正常。
參數:
-?或–help 显示幫助。
-d<硬盤> 显示硬盤分區的設置。
-g<硬盤>或–show-geometry<硬盤> 显示硬盤的CHS參數。
-l<硬盤> 显示后硬盤分區的相關設置。
-s<分區> 显示分區的大小,單位為區塊。
-T或–list-types 显示所有sfdisk能辨識的文件系統ID。
-v或–version 显示版本信息。
-V<硬盤>或–verify<硬盤> 檢查硬盤分區是否正常。
-x或–show-extend 显示擴展分區中的邏輯分區。
***swapoff
功能說明: 關閉系統交換區(swap area)。
語法: swapoff [設備]
補充說明: swapoff實際上為swapon的符號連接,可用來關閉系統的交換區。
***swapon
功能說明: 啟動系統交換區(swap area)。
語法: swapon [-ahsV][-p <優先順序>][設備]
補充說明: Linux系統的內存管理必須使用交換區來建立虛擬內存。
-a 將/etc/fstab文件中所有設置為swap的設備,啟動為交換區。
-h 显示幫助。
-p<優先順序> 指定交換區的優先順序。
-s 显示交換區的使用狀況。
-V 显示版本信息。
***symlinks
功能說明: 維護符號連接的工具程序。
語法: symlinks [-cdrstv][目錄]
補充說明: symlinks可檢查目錄中的符號連接,並显示符號連接類型。以下為symlinks可判斷的符號連接類型: absolute:符號連接使用了絕對路徑。
dangling:原始文件已經不存在。
lengthy:符號連接的路徑中包含了多餘的”../”。
messy:符號連接的路徑中包含了多餘的”/”。
other_fs:原始文件位於其他文件系統中。
relative:符號連接使用了相對路徑。
參數:
-c 將使用絕對路徑的符號連接轉換為相對路徑。
-d 移除dangling類型的符號連接。
-r 檢查目錄下所有子目錄中的符號連接。
-s 檢查lengthy類型的符號連接。
-t 與-c一併使用時,會显示如何將絕對路徑的符號連接轉換為相對路徑,但不會實際轉換。
-v 显示所有類型的符號連接。
***sync
功能說明: 將內存緩衝區內的數據寫入磁盤。
語法: sync [–help][–version]
補充說明: 在Linux系統中,當數據需要存入磁盤時,通常會先放到緩衝區內,等到適當的時刻再寫入磁盤,如此可提高系統的執行效率。
參數:
–help 显示幫助。
-version 显示版本信息。
系統設置
***alias
功能說明:設置指令的別名。
語法:alias[別名]=[指令名稱]
補充說明:用戶可利用alias,自定指令的別名。若僅輸入alias,則可列出目前所有的別名設置。 alias的效力僅及於該次登入的操作。若要每次登入是即自動設好別名,可在.profile或.cshrc中設定指令的別名。
參數:若不加任何參數,則列出目前所有的別名設置。
***apmd
功能說明:進階電源管理服務程序。
語法:apmd [-u v V W][-p <百分比變化量>][-w <百分比值>]
補充說明:apmd負責BIOS進階電源管理(APM)相關的記錄,警告與管理工作。
參數:
-p<百分比變化量>或–percentage<百分比變化量> 當電力變化的幅度超出設置的百分比變化量,即記錄事件百分比變化量的預設值為5,若設置值超過100,則關閉此功能。
-u或–utc 將BIOS時鐘設為UTC,以便從懸待模式恢復時,將-u參數傳送至clock或hwclock程序。
-v或–verbose 記錄所有的APM事件。
-V或–version 显示版本信息。
-w<百分比值>或–warn<百分比值> 當電池不在充電狀態時,且電池電量低於設置的百分比值,則在syslog(2)的ALERT層記錄警告信息。百分比值的預設置為10,若設置為0,則關閉此功能。
-W或–wall 發出警告信息給所有人。
***aumix
功能說明:設置音效裝置。
語法:aumix [-123bcilmoprstvwWx][(+/-)強度][PqR][-dfhILqS]
補充說明:設置各項音效裝置的信號強度以及指定播放與錄音的裝置。
參數:
[-123bcilmoprstvwWx]為頻道參數,用來指定裝置的頻道;
[PqR]可用來指定播放或錄音裝置;
[-dfhILqS] 則為指令參數。若不加任何參數,aumix會显示簡單的圖形界面供調整設置頻道參數: -1 輸入信號線1。 -2 輸入信號線2。 -3 輸入信號線3。
-b 低音。
-c CD。
-i 輸入信號強度。
-m 麥克風。
-o 輸出信號強度。
-p PC喇叭。
-r 錄音。
-s 合成器。
-t 高音。
-v 主音量。
-w PCM。
-W PCM2。
-x 混音器。
(+/-)強度 出現(+/-)時,代表在原有的強度上加減指定值。若未使用(+/-),則直接將強度設為指定值。 指定音效裝置
P 指定播放裝置。
q 显示頻道設置。
R 指定錄音裝置。
指令參數
-d 指定音效裝置的名稱。
-f 指定存儲或載入設置的文件。
-h 在使用時显示信息。
-I 以圖形界面方式來執行aumix。
-L 從$HOME/.aumixrc或/etc/aumixrc載入設置。
-q 显示所有頻道的設置值。
-S 將設置值保存至/HOME/.aumixrc。
***bind
功能說明:显示或設置鍵盤按鍵與其相關的功能。
語法:bind [-dlv][-f <按鍵配置文件>][-m <按鍵配置>][-q <功能>]
補充說明:您可以利用bind命令了解有哪些按鍵組合與其功能,也可以自行指定要用哪些按鍵組合。
參數:
-d 显示按鍵配置的內容。
-f<按鍵配置文件> 載入指定的按鍵配置文件。
-l 列出所有的功能。
-m<按鍵配置> 指定按鍵配置。
-q<功能> 显示指定功能的按鍵。
-v 列出目前的按鍵配置與其功能。
***chkconfig
功能說明:檢查,設置系統的各種服務。
語法:chkconfig [–add][–del][–list][系統服務] 或 chkconfig [–level <等級代號>][系統服務][on/off/reset]
補充說明:這是Red Hat公司遵循GPL規則所開發的程序,它可查詢操作系統在每一個執行等級中會執行哪些系統服務,其中包括各類常駐服務。
參數:
–add 增加所指定的系統服務,讓chkconfig指令得以管理它,並同時在系統啟動的敘述文件內增加相關數據。
–del 刪除所指定的系統服務,不再由chkconfig指令管理,並同時在系統啟動的敘述文件內刪除相關數據。
–level<等級代號> 指定讀系統服務要在哪一個執行等級中開啟或關畢
***chroot
功能說明:改變根目錄。
語法:chroot [–help][–version][目的目錄][執行指令…]
補充說明:把根目錄換成指定的目的目錄。
參數:
–help 在線幫助。
–version 显示版本信息。
***clock
功能說明:調整 RTC 時間。
語法:clock [–adjust][–debug][–directisa][–getepoch][–hctosys][–set –date=”<日期時間>”][–setepoch –epoch=< >][–show][–systohc][–test][–utc][–version]
補充說明:RTC 是電腦內建的硬件時間,執行這項指令可以显示現在時刻,調整硬件時鐘的時間,將系統時間設成與硬件時鐘之時間一致,或是把系統時間回存到硬件時鐘。
參數:
–adjust 第一次使用”–set”或”–systohc”參數設置硬件時鐘,會在/etc目錄下產生一個名稱為adjtime的文件。當再次使用這兩個參數調整硬件時鐘,此文件便會記錄兩次調整間之差異,日後執行clock指令加上”–adjust”參數時,程序會自動根 據記錄文件的數值差異,計算出平均值,自動調整硬件時鐘的時間。
–debug 詳細显示指令執行過程,便於排錯或了解程序執行的情形。
–directisa 告訴clock指令不要通過/dev/rtc設備文件,直接對硬件時鐘進行存取。這個參數適用於僅有ISA總線結構的老式電腦。
–getepoch 把系統核心內的硬件時鐘新時代數值,呈現到標準輸出設備。
–hctosys Hardware Clock to System Time,把系統時間設成和硬件時鐘一致。由於這個動作將會造成系統全面更新文件的存取時間,所以最好在系統啟動時就執行它。
–set–date 設置硬件時鐘的日期和時間。
–setepoch–epoch=<年份> 設置系統核心之硬件時鐘的新時代數值,年份以四位樹字表示。
–show 讀取硬件時鐘的時間,並將其呈現至標準輸出設備。
–systohc System Time to Hardware Clock,將系統時間存回硬件時鐘內。
–test 僅作測試,並不真的將時間寫入硬件時鐘或系統時間。
–utc 把硬件時鐘上的時間時為CUT,有時也稱為UTC或UCT。
–version 显示版本信息。
***crontab
功能說明:設置計時器。
語法:crontab [-u <用戶名稱>][配置文件] 或 crontab [-u <用戶名稱>][-elr]
補充說明:cron是一個常駐服務,它提供計時器的功能,讓用戶在特定的時間得以執行預設的指令或程序。只要用戶會編輯計時器的配置文件,就可以使用計時器的功能。其配置文件格式如下:
Minute Hour Day Month DayOFWeek Command
參數:
-e 編輯該用戶的計時器設置。
-l 列出該用戶的計時器設置。
-r 刪除該用戶的計時器設置。
-u<用戶名稱> 指定要設定計時器的用戶名稱。
***declare
功能說明:聲明 shell 變量。
語法:declare [+/-][rxi][變量名稱=設置值] 或 declare -f
補充說明:declare為shell指令,在第一種語法中可用來聲明變量並設置變量的屬性([rix]即為變量的屬性),在第二種語法中可用來显示shell函數。若不加上任何參數,則會显示全部的shell變量與函數(與執行set指令的效果相同)。
參數:
+/- “-“可用來指定變量的屬性,”+”則是取消變量所設的屬性。
-f 僅显示函數。
r 將變量設置為只讀。
x 指定的變量會成為環境變量,可供shell以外的程序來使用。
i [設置值]可以是數值,字符串或運算式。
***depmod
功能說明:分析可載入模塊的相依性。
語法:depmod [-adeisvV][-m <文件>][–help][模塊名稱]
補充說明:depmod可檢測模塊的相依性,供modprobe在安裝模塊時使用。
參數:
-a或–all 分析所有可用的模塊。
-d或debug 執行排錯模式。
-e 輸出無法參照的符號。
-i 不檢查符號表的版本。
-m<文件>或system-map<文件> 使用指定的符號表文件。
-s或–system-log 在系統記錄中記錄錯誤。
-v或–verbose 執行時显示詳細的信息。
-V或–version 显示版本信息。
–help 显示幫助。
***dircolors
功能說明:設置 ls 指令在显示目錄或文件時所用的色彩。
語法:dircolors [色彩配置文件] 或 dircolors [-bcp][–help][–version]
補充說明:dircolors可根據[色彩配置文件]來設置LS_COLORS環境變量或是显示設置LS_COLORS環境變量的shell指令。
參數:
-b或–sh或–bourne-shell 显示在Boume shell中,將LS_COLORS設為目前預設置的shell指令。
-c或–csh或–c-shell 显示在C shell中,將LS_COLORS設為目前預設置的shell指令。
-p或–print-database 显示預設置
-help 显示幫助。
-version 显示版本信息。
***dmesg
功能說明:显示開機信息。
語法:dmesg [-cn][-s <緩衝區大小>]
補充說明:kernel會將開機信息存儲在ring buffer中。您若是開機時來不及查看信息,可利用dmesg來查看。開機信息亦保存在/var/log目錄中,名稱為dmesg的文件里。
參數:
-c 显示信息后,清除ring buffer中的內容。
-s<緩衝區大小> 預設置為8196,剛好等於ring buffer的大小。
-n 設置記錄信息的層級。
***enable
功能說明:啟動或關閉 shell 內建指令。
語法:enable [-n][-all][內建指令]
補充說明:若要執行的文件名稱與shell內建指令相同,可用enable -n來關閉shell內建指令。若不加-n參數,enable可重新啟動關閉的指令。
參數:
-n 關閉指定的shell內建指令。
-all 显示shell所有關閉與啟動的指令
***eval
功能說明:重新運算求出參數的內容。
語法:eval [參數]
補充說明:eval可讀取一連串的參數,然後再依參數本身的特性來執行。
參數:
參數不限數目,彼此之間用分號分開。
***export
功能說明:設置或显示環境變量。
語法:export [-fnp][變量名稱]=[變量設置值]
補充說明:在shell中執行程序時,shell會提供一組環境變量。export可新增,修改或刪除環境變量,供後續執行的程序使用。export的效力僅及於該此登陸操作。
參數:
-f 代表[變量名稱]中為函數名稱。
-n 刪除指定的變量。變量實際上並未刪除,只是不會輸出到後續指令的執行環境中。
-p 列出所有的shell賦予程序的環境變量。
***fbset
功能說明:設置景框緩衝區。
語法:fbset [-ahinsvVx][-db <信息文件>][-fb <外圍設備代號>][–test][显示模式]
補充說明:fbset指令可用於設置景框緩衝區的大小,還能調整畫面之分辨率,位置,高低寬窄,色彩 深度,並可決定是否啟動先卡之各項硬件特性。
參數:
-a或–all 改變所有使用該設備之虛擬終端機的显示模式。
-db<信息文件> 指定显示模式的信息文件,預設值文件名稱為fb.modes,存放在/etc目錄下
-fb<外圍設備代號> 指定用來做為輸出景框緩衝區之外圍設備,預設置為”/dev/fd0″。
-h或-help 在線幫助。
-i或–info 列出所有景框緩衝區之相關信息。
-ifb<外圍設備代號> 使用另一個景框緩衝區外圍設備之設置值。
-n或–now 馬上改變显示模式。
-ofb<外圍設備代號> 此參數效果和指定”-fb”參數相同。
-s或–show 列出目前显示模式之設置。
-v或–verbose 显示指令執行過程。
-V或–version 显示版本信息。
-x或–xfree86 使用XFree86兼容模式。
–test 僅做測試,並不改變現行的显示模式。
***grpconv
功能說明:開啟群組的投影密碼。
語法:grpconv
補充說明:Linux系統里的用戶和群組密碼,分別存放在/etc目錄下的passwd和group文件中。因系統運作所需,任何人都得以讀取它們,造成安全上的破綻。投影密碼將文件內的密碼改存在/etc目錄下的shadow和gshadow文件內,只允許系統管理者讀取,同時把原密碼置換為”x”字符。投影密碼的功能可隨時開啟或關閉,您只需執行grpconv指令就能開啟群組投影密碼。
***grpunconv
功能說明:關閉群組的投影密碼。
語法:grpunconv
補充說明:執行grpunconv指令可關閉群組投影密碼,它會把密碼從gshadow文件內,回存到group文件里。
***hwclock
功能說明:显示與設定硬件時鐘。
語法:hwclock [–adjust][–debug][–directisa][–hctosys][–show][–systohc][–test] [–utc][–version][–set –date=<日期與時間>]
補充說明:在Linux中有硬件時鐘與系統時鐘等兩種時鐘。硬件時鐘是指主機板上的時鐘設備,也就是通常可在BIOS畫面設定的時鐘。系統時鐘則是指kernel中的時鐘。當Linux啟動時,系統時鐘會去讀取硬件時鐘的設定,之後系統時鐘即獨立運作。所有Linux相關指令與函數都是讀取系統時鐘的設定。
參數:
–adjust hwclock每次更改硬件時鐘時,都會記錄在/etc/adjtime文件中。使用–adjust參數,可使hwclock根據先前的記錄來估算硬件時鐘的偏差,並用來校正目前的硬件時鐘。
–debug 显示hwclock執行時詳細的信息。
–directisa hwclock預設從/dev/rtc設備來存取硬件時鐘。若無法存取時,可用此參數直接以I/O指令來存取硬件時鐘。
–hctosys 將系統時鐘調整為與目前的硬件時鐘一致。
–set –date=<日期與時間> 設定硬件時鐘。
–show 显示硬件時鐘的時間與日期。
–systohc 將硬件時鐘調整為與目前的系統時鐘一致。
–test 僅測試程序,而不會實際更改硬件時鐘。
–utc 若要使用格林威治時間,請加入此參數,hwclock會執行轉換的工作。
–version 显示版本信息。
***insmod
功能說明:載入模塊。
語法:insmod [-fkmpsvxX][-o <模塊名稱>][模塊文件][符號名稱 = 符號值]
補充說明:Linux有許多功能是通過模塊的方式,在需要時才載入kernel。如此可使kernel較為精簡,進而提高效率,以及保有較大的彈性。這類可載入的模塊,通常是設備驅動程序。
參數:
-f 不檢查目前kernel版本與模塊編譯時的kernel版本是否一致,強制將模塊載入。
-k 將模塊設置為自動卸除。
-m 輸出模塊的載入信息。
-o<模塊名稱> 指定模塊的名稱,可使用模塊文件的文件名。
-p 測試模塊是否能正確地載入kernel。
-s 將所有信息記錄在系統記錄文件中。
-v 執行時显示詳細的信息。
-x 不要匯出模塊的外部符號。
-X 匯出模塊所有的外部符號,此為預設置。
***kbdconfig
功能說明:設置鍵盤類型。
語法:kbdconfig [–back][–test]
補充說明:kbdconfig(Red Hat Linux才有的指令)是一個用來設置鍵盤的程序,提供圖形化的操作界面。kbdconfig實際上是修改/etc/sysconfig/keyboard的鍵盤配置文件。
參數:
–back 執行時將預設的Cancel按鈕更改為Back按鈕。
–test 僅作測試,不會實際更改設置。
***lilo
功能說明:安裝核心載入,開機管理程序。
語法:lilo [-clqtV][-b<外圍設備代號>][-C<配置文件>][-d<延遲時間>][-D<識別標籤>][-f<幾何參數文件>][-i<開機磁區文件>][-I<識別標籤>][-m<映射文件>][-P][-r<根目錄>][-R<執行指令>…][-s<備份文件>][-S<備份文件>][-uU<外圍設備代號>][-v…]
補充說明:lilo是個Linux系統核心載入程序,同時具備管理開機的功能。單獨執行lilo指令,它會讀取/etc/目錄下的lilo.conf配置文件,然後根據其內容安裝lilo。
參數:
-b<外圍設備代號> 指定安裝lilo之處的外圍設備代號。
-c 使用緊緻映射模式。
-C<配置文件> 指定lilo的配置文件。
-d<延遲時間> 設置開機延遲時間。
-D<識別標籤> 指定開機后預設啟動的操作系統,或系統核心識別標籤。
-f<幾何參數文件> 指定磁盤的幾何參數配置文件。
-i<開機磁區文件> 指定欲使用的開機磁區文件,預設是/boot目錄里的boot.b文件。
-I<識別標籤> 显示系統核心存放之處。
-l 產生線形磁區地址。
-m<映射文件> 指定映射文件。
-P<fix/ignore> 決定要修復或忽略分區表的錯誤。
-q 列出映射的系統核心文件。
-r<根目錄> 設置系統啟動時欲掛入成為根目錄的目錄。
-R<執行指令> 設置下次啟動系統時,首先執行的指令。
-s<備份文件> 指定備份文件。
-S<備份文件> 強制指定備份文件。
-t 不執行指令,僅列出實際執行會進行的動作。
-u<外圍色設備代號> 刪除lilo。
-U<外圍設備代號> 此參數的效果和指定”-u”參數類似,當不檢查時間戳記。
-v 显示指令執行過程。
-V 显示版本信息。
***liloconfig
功能說明:設置核心載入,開機管理程序。
語法:liloconfig
補充說明:liloconfig是Slackware發行版專門用來調整lilo設置的程序。它通過互動式操作界面,讓用戶能夠利用鍵盤上的方向鍵等,輕易地操控lilo的安裝,設置作業,而無須下達各種參數或撰寫配置文件。
***lsmod
功能說明:显示已載入系統的模塊。
語法:lsmod
補充說明:執行lsmod指令,會列出所有已載入系統的模塊。Linux操作系統的核心具有模塊化的特性,應此在編譯核心時,務須把全部的功能都放入核心。您可以將這些功能編譯成一個個單獨的模塊,待需要時再分別載入。
***minfo
功能說明:显示MS-DOS文件系統的各項參數。
語法:</>minfo [-v][驅動器代號] *
*補充說明:minfo為mtools工具指令,可显示MS-DOS系統磁盤的各項參數,包括磁區數,磁頭數…等。
參數:
-v 除了一般信息外,並显示可開機磁區的內容。
***mkkickstart
功能說明:建立安裝的組態文件。
語法:mkkickstart [–bootp][–dhcp][–nonet][–nox][–version][–nfs <遠端電腦:路徑>]
補充說明:mkkickstart可根據目前系統的設置來建立組態文件,供其他電腦在安裝時使用。組態文件的內容包括使用語言,網絡環境,系統磁盤狀態,以及X Windows的設置等信息。
參數:
–bootp 安裝與開機時,使用BOOTP。
–dhcp 安裝與開機時,使用DHCP。
–nfs<遠端電腦:路徑> 使用指定的網絡路徑安裝。
–nonet 不要進行網絡設置,即假設在沒有網絡環境的狀態下。
–nox 不要進行X Windows的環境設置。
–version 显示版本信息。
***modinfo
功能說明:显示kernel模塊的信息。
語法:modinfo [-adhpV][模塊文件]
補充說明:modinfo會显示kernel模塊的對象文件,以显示該模塊的相關信息。
參數:
-a或–author 显示模塊開發人員。
-d或–description 显示模塊的說明。
-h或–help 显示modinfo的參數使用方法。
-p或–parameters 显示模塊所支持的參數。
-V或–version 显示版本信息。
***modprobe
功能說明:自動處理可載入模塊。
語法:modprobe [-acdlrtvV][–help][模塊文件][符號名稱 = 符號值]
補充說明:modprobe可載入指定的個別模塊,或是載入一組相依的模塊。modprobe會根據depmod所產生的相依關係,決定要載入哪些模塊。若在載入過程中發生錯誤,在modprobe會卸載整組的模塊。
參數:
-a或–all 載入全部的模塊。
-c或–show-conf 显示所有模塊的設置信息。
-d或–debug 使用排錯模式。
-l或–list 显示可用的模塊。
-r或–remove 模塊閑置不用時,即自動卸載模塊。
-t或–type 指定模塊類型。
-v或–verbose 執行時显示詳細的信息。
-V或–version 显示版本信息。
-help 显示幫助。
***mouseconfig
功能說明:設置鼠標相關參數。
語法:mouseconfig [–back][–emulthree][–help][–expert][–kickstart][–noprobe][–test][–device <連接端口>][鼠標類型]
補充說明:mouseconfig為鼠標設置程序,可自動設置相關參數,或者用戶也可以利用所提供互動模式自行設置鼠標。mouseconfig是Red Hat Linux才有的命令。
參數:
–back 在設置畫面上显示Back按鈕,而取代預設的Cancel按鈕。
–device<連接端口> 指定硬件連接端口。可用的選項有ttyS0,ttyS1,ttyS2,ttyS3與orpsaux。
–emulthree 將二鈕鼠標模擬成三鈕鼠標。
–help 显示幫助以及所有支持的鼠標類型。
–expert 程序預設可自動判斷部分設置值。若要自行設置,請使用–expert參數。
–kickstart 讓程序自動檢測並保存所有的鼠標設置。
–noprobe 不要檢測鼠標設備。
–test 測試模式,不會改變任何設置。
***ntsysv
功能說明:設置系統的各種服務。
語法:ntsysv [–back][–level <等級代號>]
補充說明:這是Red Hat公司遵循GPL規則所開發的程序,它具有互動式操作界面,您可以輕易地利用方向鍵和空格鍵等,開啟,關閉操作系統在每個執行等級中,所要執行的系統服務。
參數:
–back 在互動式界面里,显示Back鈕,而非Cancel鈕。
–level <等級代號> 在指定的執行等級中,決定要開啟或關閉哪些系統服務。
***passwd
功能說明:設置密碼。
語法:passwd [-dklS][-u <-f>][用戶名稱]
補充說明:passwd指令讓用戶可以更改自己的密碼,而系統管理者則能用它管理系統用戶的密碼。只有管理者可以指定用戶名稱,一般用戶只能變更自己的密碼。
參數:
-d 刪除密碼。本參數僅有系統管理者才能使用。
-f 強制執行。
-k 設置只有在密碼過期失效后,方能更新。
-l 鎖住密碼。
-s 列出密碼的相關信息。本參數僅有系統管理者才能使用。
-u 解開已上鎖的帳號。
***pwconv
功能說明:開啟用戶的投影密碼。
語法:pwconv
補充說明:Linux系統里的用戶和群組密碼,分別存放在名稱為passwd和group的文件中, 這兩個文件位於/etc目錄下。因系統運作所需,任何人都得以讀取它們,造成安全上的破綻。投影密碼將文件內的密碼改存在/etc目錄下的shadow和gshadow文件內,只允許系統管理者讀取,同時把原密碼置換為”x”字符,有效的強化了系統的安全性。
***pwunconv
功能說明:關閉用戶的投影密碼。
語法:pwunconv
補充說明:執行pwunconv指令可以關閉用戶投影密碼,它會把密碼從shadow文件內,重回存到passwd文件里。
***rdate
功能說明:显示其他主機的日期與時間。
語法:rdate [-ps][主機名稱或IP地址…]
補充說明:執行rdate指令,向其他主機詢問系統時間並显示出來。
參數:
-p 显示遠端主機的日期與時間。
-s 把從遠端主機收到的日期和時間,回存到本地主機的系統時間。
***resize
功能說明:設置終端機視窗的大小。
語法:resize [-cu][-s <列數> <行數>]
補充說明:執行resize指令可設置虛擬終端機的視窗大小。
參數:
-c 就算用戶環境並非C Shell,也用C Shell指令改變視窗大小。
-s <列數> <行數> 設置終端機視窗的垂直高度和水平寬度。
-u 就算用戶環境並非Bourne Shell,也用Bourne Shell指令改變視窗大小。
***rmmod
功能說明:刪除模塊。
語法:rmmod [-as][模塊名稱…]
補充說明:執行rmmod指令,可刪除不需要的模塊。Linux操作系統的核心具有模塊化的特性,應此在編譯核心時,務須把全部的功能都放如核心。你可以將這些功能編譯成一個個單獨的模塊,待有需要時再分別載入它們。
參數:
-a 刪除所有目前不需要的模塊。
-s 把信息輸出至syslog常駐服務,而非終端機界面。
***rpm
功能說明:管理套件。
語法:rpm [-acdhilqRsv][-b<完成階段><套間檔>+][-e<套件擋>][-f<文件>+][-i<套件檔>][-p<套件檔>+][-U<套件檔>][-vv][–addsign<套件檔>+][–allfiles][–allmatches][–badreloc][–buildroot<根目錄>][–changelog][–checksig<套件檔>+][–clean][–dbpath<數據庫目錄>][–dump][–excludedocs][–excludepath<排除目錄>][–force][–ftpproxy<主機名稱或IP地址>][–ftpport<通信端口>][–help][–httpproxy<主機名稱或IP地址>][–httpport<通信端口>][–ignorearch][–ignoreos][–ignoresize][–includedocs][–initdb][justdb][–nobulid][–nodeps][–nofiles][–nogpg][–nomd5][–nopgp][–noorder][–noscripts][–notriggers][–oldpackage][–percent][–pipe<執行指令>][–prefix<目的目錄>][–provides][–queryformat<檔頭格式>][–querytags][–rcfile<配置檔>][–rebulid<套件檔>][–rebuliddb][–recompile<套件檔>][–relocate<原目錄>=<新目錄>][–replacefiles][–replacepkgs][–requires][–resign<套件檔>+][–rmsource][–rmsource<文件>][–root<根目錄>][–scripts][–setperms][–setugids][–short-circuit][–sign][–target=<安裝平台>+][–test][–timecheck<檢查秒數>][–triggeredby<套件檔>][–triggers][–verify][–version][–whatprovides<功能特性>][–whatrequires<功能特性>]
補充說明:rmp原本是Red Hat Linux發行版專門用來管理Linux各項套件的程序,由於它遵循GPL規則且功能強大方便,因而廣受歡迎。逐漸受到其他發行版的採用。RPM套件管理方式的出現,讓Linux易於安裝,升級,間接提升了Linux的適用度。
參數:
-a 查詢所有套件。
-b<完成階段><套件檔>+或-t <完成階段><套件檔>+ 設置包裝套件的完成階段,並指定套件檔的文件名稱。
-c 只列出組態配置文件,本參數需配合”-l”參數使用。
-d 只列出文本文件,本參數需配合”-l”參數使用。
-e<套件檔>或–erase<套件檔> 刪除指定的套件。
-f<文件>+ 查詢擁有指定文件的套件。
-h或–hash 套件安裝時列出標記。
-i 显示套件的相關信息。
-i<套件檔>或–install<套件檔> 安裝指定的套件檔。
-l 显示套件的文件列表。
-p<套件檔>+ 查詢指定的RPM套件檔。
-q 使用詢問模式,當遇到任何問題時,rpm指令會先詢問用戶。
-R 显示套件的關聯性信息。 -s 显示文件狀態,本參數需配合”-l”參數使用。
-U<套件檔>或–upgrade<套件檔> 升級指定的套件檔。
-v 显示指令執行過程。
-vv 詳細显示指令執行過程,便於排錯。
-addsign<套件檔>+ 在指定的套件里加上新的簽名認證。
–allfiles 安裝所有文件。
–allmatches 刪除符合指定的套件所包含的文件。
–badreloc 發生錯誤時,重新配置文件。
–buildroot<根目錄> 設置產生套件時,欲當作根目錄的目錄。
–changelog 显示套件的更改記錄。
–checksig<套件檔>+ 檢驗該套件的簽名認證。
–clean 完成套件的包裝后,刪除包裝過程中所建立的目錄。
–dbpath<數據庫目錄> 設置欲存放RPM數據庫的目錄。
–dump 显示每個文件的驗證信息。本參數需配合”-l”參數使用。
–excludedocs 安裝套件時,不要安裝文件。
–excludepath<排除目錄> 忽略在指定目錄里的所有文件。
–force 強行置換套件或文件。
–ftpproxy<主機名稱或IP地址> 指定FTP代理服務器。
–ftpport<通信端口> 設置FTP服務器或代理服務器使用的通信端口。
–help 在線幫助。
–httpproxy<主機名稱或IP地址> 指定HTTP代理服務器。
–httpport<通信端口> 設置HTTP服務器或代理服務器使用的通信端口。
–ignorearch 不驗證套件檔的結構正確性。
–ignoreos 不驗證套件檔的結構正確性。
–ignoresize 安裝前不檢查磁盤空間是否足夠。
–includedocs 安裝套件時,一併安裝文件。
–initdb 確認有正確的數據庫可以使用。
–justdb 更新數據庫,當不變動任何文件。
–nobulid 不執行任何完成階段。
–nodeps 不驗證套件檔的相互關聯性。
–nofiles 不驗證文件的屬性。
–nogpg 略過所有GPG的簽名認證。
–nomd5 不使用MD5編碼演算確認文件的大小與正確性。
–nopgp 略過所有PGP的簽名認證。
–noorder 不重新編排套件的安裝順序,以便滿足其彼此間的關聯性。
–noscripts 不執行任何安裝Script文件。
–notriggers 不執行該套件包裝內的任何Script文件。
–oldpackage 升級成舊版本的套件。
–percent 安裝套件時显示完成度百分比。
–pipe<執行指令> 建立管道,把輸出結果轉為該執行指令的輸入數據。
–prefix<目的目錄> 若重新配置文件,就把文件放到指定的目錄下。
–provides 查詢該套件所提供的兼容度。
–queryformat<檔頭格式> 設置檔頭的表示方式。
–querytags 列出可用於檔頭格式的標籤。
–rcfile<配置文件> 使用指定的配置文件。
–rebulid<套件檔> 安裝原始代碼套件,重新產生二進制文件的套件。
–rebuliddb 以現有的數據庫為主,重建一份數據庫。
–recompile<套件檔> 此參數的效果和指定”–rebulid”參數類似,當不產生套件檔。
–relocate<原目錄>=<新目錄> 把本來會放到原目錄下的文件改放到新目錄。
–replacefiles 強行置換文件。
–replacepkgs 強行置換套件。
–requires 查詢該套件所需要的兼容度。
–resing<套件檔>+ 刪除現有認證,重新產生簽名認證。
–rmsource 完成套件的包裝后,刪除原始代碼。
–rmsource<文件> 刪除原始代碼和指定的文件。
–root<根目錄> 設置欲當作根目錄的目錄。
–scripts 列出安裝套件的Script的變量。
–setperms 設置文件的權限。
–setugids 設置文件的擁有者和所屬群組。
–short-circuit 直接略過指定完成階段的步驟。
–sign 產生PGP或GPG的簽名認證。
–target=<安裝平台>+ 設置產生的套件的安裝平台。
–test 僅作測試,並不真的安裝套件。
–timecheck<檢查秒數> 設置檢查時間的計時秒數。
–triggeredby<套件檔> 查詢該套件的包裝者。
–triggers 展示套件檔內的包裝Script。
–verify 此參數的效果和指定”-q”參數相同。
–version 显示版本信息。
–whatprovides<功能特性> 查詢該套件對指定的功能特性所提供的兼容度。
–whatrequires<功能特性> 查詢該套件對指定的功能特性所需要的兼容度。
***set
功能說明:設置shell。
語法:set [+-abCdefhHklmnpPtuvx]
補充說明:set指令能設置所使用shell的執行方式,可依照不同的需求來做設置。
參數:
-a 標示已修改的變量,以供輸出至環境變量。
-b 使被中止的後台程序立刻回報執行狀態。
-C 轉向所產生的文件無法覆蓋已存在的文件。
-d Shell預設會用雜湊表記憶使用過的指令,以加速指令的執行。使用-d參數可取消。
-e 若指令傳回值不等於0,則立即退出shell。
-f 取消使用通配符。
-h 自動記錄函數的所在位置。
-H Shell 可利用”!”加<指令編號>的方式來執行history中記錄的指令。
-k 指令所給的參數都會被視為此指令的環境變量。
-l 記錄for循環的變量名稱。
-m 使用監視模式。
-n 只讀取指令,而不實際執行。
-p 啟動優先順序模式。
-P 啟動-P參數后,執行指令時,會以實際的文件或目錄來取代符號連接。
-t 執行完隨後的指令,即退出shell。
-u 當執行時使用到未定義過的變量,則显示錯誤信息。
-v 显示shell所讀取的輸入值。
-x 執行指令后,會先显示該指令及所下的參數。
+<參數> 取消某個set曾啟動的參數。
***setconsole
功能說明:設置系統終端。
語法:setconsole [serial][ttya][ttyb]
補充說明:setconsole可用來指定系統終端。
參數:
serial 使用PROM終端。
ttya,cua0或ttyS0 使用第1個串口設備作為終端。
ttyb,cua1或ttyS1 使用第2個串口設備作為終端。
video 使用主機上的現卡作為終端。
***setenv
功能說明:查詢或显示環境變量。
語法:setenv [變量名稱][變量值]
補充說明:setenv為tsch中查詢或設置環境變量的指令。
***setup
功能說明:設置公用程序。
語法:setup
補充說明:setup是一個設置公用程序,提供圖形界面的操作方式。在setup中可設置7類的選項:
1.登陸認證方式
2.鍵盤組態設置
3.鼠標組態設置
4.開機時所要啟動的系統服務
5.聲卡組態設置
6.時區設置
7.X Windows組態設置
***sndconfig
功能說明:設置聲卡。
語法:sndconfig [–help][–noautoconfig][–noprobe]
補充說明:sndconfig為聲卡設置程序,支持PnP設置,可自動檢測並設置PnP聲卡。
參數:
–help 显示幫助。
–noautoconfig 不自動設置PnP的聲卡。
–noprobe 不自動檢測PnP聲卡。
***SVGAText Mode
功能說明:加強文字模式的显示畫面。
語法:SVGATextMode [-acdfhmnrsv][-t <配置文件>][模式]
補充說明:SVGATextMode可用來設置文字模式下的显示畫面,包括分辨率,字體和更新頻率等。
參數:
-a 如果新显示模式的屏幕大小與原先不同時,SVGATextMode會執行必要的系統設置。
-c 維持原有的VGA時脈。
-d 執行時會显示詳細的信息,供排錯時參考。
-f 不要執行配置文件中有關字體載入的指令。
-h 显示幫助。
-m 允許1×1的方式來重設屏幕大小。
-n 僅測試指定的模式。
-r 通知或重設與屏幕大小相關的程序。
-s 显示配置文件中所有可用的模式。
-t<配置文件> 指定配置文件。
-v SVGATextMode在配置新的显示模式時,預設會先檢查垂直與水平的更新更新頻率是否在配置文件所指定的範圍內,如果不在範圍內,則不設置新的显示模式。
模式] [模式]參數必須是配置文件中模式的名稱。
***timeconfig
功能說明:設置時區。
語法:timeconfig [–arc][–back][–test][–utc][時區名稱]
補充說明:這是Red Hat公司遵循GPL規則所開發的程序,它具有互動式操作界面,您可以輕易地利用方向鍵和空格鍵等,設置系統時間所屬的時區。
參數:
–arc 使用Alpha硬件結構的格式存儲系統時間。
–back 在互動式界面里,显示Back鈕而非Cancel鈕。
–test 僅作測試,並不真的改變系統的時區。
–utc 把硬件時鐘上的時間視為CUT,有時也稱為UTC或UCT。
***ulimit
功能說明:控制shell程序的資源。
語法:ulimit [-aHS][-c ][-d <數據節區大小>][-f <文件大小>][-m <內存大小>][-n <文件數目>][-p <緩衝區大小>][-s <堆疊大小>][-t <CPU時間>][-u <程序數目>][-v <虛擬內存大小>]
補充說明:ulimit為shell內建指令,可用來控制shell執行程序的資源。
參數:
-a 显示目前資源限制的設定。
-c <core文件上限> 設定core文件的最大值,單位為區塊。
-d <數據節區大小> 程序數據節區的最大值,單位為KB。
-f <文件大小> shell所能建立的最大文件,單位為區塊。
-H 設定資源的硬性限制,也就是管理員所設下的限制。
-m <內存大小> 指定可使用內存的上限,單位為KB。
-n <文件數目> 指定同一時間最多可開啟的文件數。
-p <緩衝區大小> 指定管道緩衝區的大小,單位512字節。
-s <堆疊大小> 指定堆疊的上限,單位為KB。
-S 設定資源的彈性限制。
-t <CPU時間> 指定CPU使用時間的上限,單位為秒。
-u <程序數目> 用戶最多可開啟的程序數目。
-v <虛擬內存大小> 指定可使用的虛擬內存上限,單位為KB。
***unalias
功能說明:刪除別名。
語法:unalias [-a][別名]
補充說明:unalias為shell內建指令,可刪除別名設置。
參數:
-a 刪除全部的別名。
***unset
功能說明:刪除變量或函數。
語法:unset [-fv][變量或函數名稱]
補充說明:unset為shell內建指令,可刪除變量或函數。
參數:
-f 僅刪除函數。
-v 僅刪除變量。
系統管理
***adduser
功能說明:新增用戶帳號。
語法:adduser
補充說明:在Slackware中,adduser指令是個script程序,利用交談的方式取得輸入的用戶帳號資料,然後再交由真正建立帳號的useradd指令建立新用戶,如此可方便管理員建立用戶帳號。在Red Hat Linux中,adduser指令則是useradd指令的符號連接,兩者實際上是同一個指令。
***chfn
功能說明:改變finger指令显示的信息。
語法:chfn [-f <真實姓名>][-h <家中電話>][-o <辦公地址>][-p <辦公電話>][-uv][帳號名稱]
補充說明:chfn指令可用來更改執行finger指令時所显示的信息,這些信息都存放在/etc目錄里的asswd文件里。若不指定任何參數,則chfn指令會進入問答式界面。
參數:
-f<真實姓名>或–full-name<真實姓名> 設置真實姓名。
-h<家中電話>或–home-phone<家中電話> 設置家中的電話號碼。
-o<辦公地址>或–office<辦公地址> 設置辦公室的地址。
-p<辦公電話>或–office-phone<辦公電話> 設置辦公室的電話號碼。
-u或–help 在線幫助。
-v或-version 显示版本信息。
***chsh
功能說明:更換登入系統時使用的shell。
語法:chsh [-luv][-s ][用戶名稱]
補充說明:每位用戶在登入系統時,都會擁有預設的shell環境,這個指令可更改其預設值。若不指定 任何參數與用戶名稱,則chsh會以應答的方式進行設置。
參數:
-s<shell 名稱>或–shell<shell 名稱> 更改系統預設的shell環境。
-l或–list-shells 列出目前系統可用的shell清單。
-u或–help 在線幫助。
-v或-version 显示版本信息。
***date
功能說明:显示或設置系統時間與日期。
語法:date [-d <字符串>][-u][+%H%I%K%l%M%P%r%s%S%T%X%Z%a%A%b%B%c%d%D%j%m%U%w%x%y%Y%n%t] 或date [-s <字符串>][-u][MMDDhhmmCCYYss] 或 date [–help][–version]
補充說明:第一種語法可用來显示系統日期或時間,以%為開頭的參數為格式參數,可指定日期或時間的显示格式。第二種語法可用來設置系統日期與時間。只有管理員才有設置日期與時間的權限。若不加任何參數,data會显示目前的日期與時間。
參數:
%H 小時(以00-23來表示)。
%I 小時(以01-12來表示)。
%K 小時(以0-23來表示)。
%l 小時(以0-12來表示)。
%M 分鐘(以00-59來表示)。
%P AM或PM。
%r 時間(含時分秒,小時以12小時AM/PM來表示)。
%s 總秒數。起算時間為1970-01-01 00:00:00 UTC。
%S 秒(以本地的慣用法來表示)。
%T 時間(含時分秒,小時以24小時制來表示)。
%X 時間(以本地的慣用法來表示)。
%Z 市區。
%a 星期的縮寫。
%A 星期的完整名稱。
%b 月份英文名的縮寫。
%B 月份的完整英文名稱。
%c 日期與時間。只輸入date指令也會显示同樣的結果。
%d 日期(以01-31來表示)。
%D 日期(含年月日)。
%j 該年中的第幾天。
%m 月份(以01-12來表示)。
%U 該年中的周數。
%w 該周的天數,0代表周日,1代表周一,異詞類推。
%x 日期(以本地的慣用法來表示)。
%y 年份(以00-99來表示)。
%Y 年份(以四位數來表示)。
%n 在显示時,插入新的一行。
%t 在显示時,插入tab。
MM 月份(必要)。
DD 日期(必要)。
hh 小時(必要)。
mm 分鐘(必要)。
CC 年份的前兩位數(選擇性)。
YY 年份的后兩位數(選擇性)。
ss 秒(選擇性)。
-d<字符串> 显示字符串所指的日期與時間。字符串前後必須加上雙引號。
-s<字符串> 根據字符串來設置日期與時間。字符串前後必須加上雙引號。
-u 显示GMT。
–help 在線幫助。
–version 显示版本信息。
***exit
功能說明:退出目前的shell。
語法:exit [狀態值]
補充說明:執行exit可使shell以指定的狀態值退出。若不設置狀態值參數,則shell以預設值退出。狀態值0代表執行成功,其他值代表執行失敗。exit也可用在script,離開正在執行的script,回到shell。
***finger
功能說明:查找並显示用戶信息。
語法:finger [-lmsp][帳號名稱…]
補充說明:finger指令會去查找,並显示指定帳號的用戶相關信息,包括本地與遠端主機的用戶皆可,帳號名稱沒有大小寫的差別。單獨執行finger指令,它會显示本地主機現在所有的用戶的登陸信息,包括帳號名稱,真實姓名,登入終端機,閑置時間,登入時間以及地址和電話。
參數:
-l 列出該用戶的帳號名稱,真實姓名,用戶專屬目錄,登入所用的Shell,登入時間,轉信地址,电子郵件狀態,還有計劃文件和方案文件內容。
-m 排除查找用戶的真實姓名。
-s 列出該用戶的帳號名稱,真實姓名,登入終端機,閑置時間,登入時間以及地址和電話。
-p 列出該用戶的帳號名稱,真實姓名,用戶專屬目錄,登入所用的Shell,登入時間,轉信地址,电子郵件狀態,但不显示該用戶的計劃文件和方案文件內容。
***free
功能說明:显示內存狀態。
語法: free [-bkmotV][-s <間隔秒數>]
補充說明:free指令會显示內存的使用情況,包括實體內存,虛擬的交換文件內存,共享內存區段,以及系統核心使用的緩衝區等。
參數:
-b 以Byte為單位显示內存使用情況。
-k 以KB為單位显示內存使用情況。
-m 以MB為單位显示內存使用情況。
-o 不显示緩衝區調節列。
-s<間隔秒數> 持續觀察內存使用狀況。
-t 显示內存總和列。
-V 显示版本信息。
***fwhois
功能說明:查找並显示用戶信息。
語法:fwhios [帳號名稱]
補充說明:本指令的功能有點類似finger指令,它會去查找並显示指定帳號的用戶相關信息。不同之處在於fwhois指令是到Network Solutions的WHOIS數據庫去查找,該帳號名稱必須有在上面註冊才能尋獲,且名稱沒有大小寫的差別。
***gitps
功能說明:報告程序狀況。
語法:gitps [acefgjlnrsSTuvwxX][p <程序識別碼>][t <終端機編號>][U <帳號名稱>]
補充說明:gitps是用來報告並管理程序執行的指令,基本上它就是通過ps指令來報告,管理程序,也能通過gitps指令隨時中斷,刪除不必要的程序。因為gitps指令會去執行ps指令,所以其參數和ps指令相當類似。
參數:
a 显示 現行終端機下的所有程序,包括其他用戶的程序。
c 列出程序時,显示每個程序真正的指令名稱,而不包含路徑,參數或是常駐服務的標示.
e 列出程序時,显示每個程序所使用的環境變量。
f 用ASCII字符显示樹狀結構,表達程序間的相互關係。
g 显示現行終端機下的所有程序,包括群組領導者的程序。
j 採用工作控制的格式來显示程序狀況。
l 採用纖細的格式來显示程序狀況。
n 以数字來表示USER和WCHAN欄位。
p<程序識別碼> 指定程序識別碼,並列出該程序的狀況。
r 只列出現行終端機正在執行中的程序。
s 採用程序信號的格式显示程序狀況。
S 列出程序時,包括已中斷的子程序信息。
t<終端機機標號> 指定終端機編號,並列出屬於該終端機的程序的狀況。
T 显示現行終端機下的所有程序。
u 以用戶為主的格式來显示程序狀況。
U<帳號名稱> 列出屬於該用戶的程序的狀況。
v 採用虛擬內存的格式显示程序狀況。
w 採用寬闊的格式來显示程序狀況。
x 显示所有程序,不以終端機來區分。
X 採用舊試的Linux i386登陸格式显示程序狀況。
***groupdel
功能說明:刪除群組。
語法:groupdel [群組名稱]
補充說明:需要從系統上刪除群組時,可用groupdel指令來完成這項工作。倘若該群組中仍包括某些用戶,則必須先刪除這些用戶后,方能刪除群組。
***groupmod
功能說明:更改群組識別碼或名稱。
語法:groupmod [-g <群組識別碼> <-o>][-n <新群組名稱>][群組名稱]
補充說明: 需要更改群組的識別碼或名稱時,可用groupmod指令來完成這項工作。
參數:
-g <群組識別碼> 設置欲使用的群組識別碼。
-o 重複使用群組識別碼。
-n <新群組名稱> 設置欲使用的群組名稱。
halt
功能說明:關閉系統。
語法:halt [-dfinpw]
補充說明:halt會先檢測系統的runlevel。若runlevel為0或6,則關閉系統,否則即調用shutdown來關閉系統。
參數:
-d 不要在wtmp中記錄。
-f 不論目前的runlevel為何,不調用shutdown即強制關閉系統。
-i 在halt之前,關閉全部的網絡界面。
-n halt前,不用先執行sync。
-p halt之後,執行poweroff。
-w 僅在wtmp中記錄,而不實際結束系統。
***id
功能說明:显示用戶的ID,以及所屬群組的ID。
語法:id [-gGnru][–help][–version][用戶名稱]
補充說明:id會显示用戶以及所屬群組的實際與有效ID。若兩個ID相同,則僅显示實際ID。若僅指定用戶名稱,則显示目前用戶的ID。
參數:
-g或–group 显示用戶所屬群組的ID。
-G或–groups 显示用戶所屬附加群組的ID。
-n或–name 显示用戶,所屬群組或附加群組的名稱。
-r或–real 显示實際ID。
-u或–user 显示用戶ID。
-help 显示幫助。
-version 显示版本信息。
***kill
功能說明:刪除執行中的程序或工作。
語法:kill [-s <信息名稱或編號>][程序] 或 kill [-l <信息編號>]
補充說明:kill可將指定的信息送至程序。預設的信息為SIGTERM(15),可將指定程序終止。若仍無法終止該程序,可使用SIGKILL(9)信息嘗試強制刪除程序。程序或工作的編號可利用ps指令或jobs指令查看。
參數:
-l <信息編號> 若不加<信息編號>選項,則-l參數會列出全部的信息名稱。
-s <信息名稱或編號> 指定要送出的信息。
[程序] [程序]可以是程序的PID或是PGID,也可以是工作編號。
***last
功能說明:列出目前與過去登入系統的用戶相關信息。
語法:last [-adRx][-f <記錄文件>][-n <显示列數>][帳號名稱…][終端機編號…]
補充說明:單獨執行last指令,它會讀取位於/var/log目錄下,名稱為wtmp的文件,並把該給文件的內容記錄的登入系統的用戶名單全部显示出來。
參數:
-a 把從何處登入系統的主機名稱或IP地址,显示在最後一行。
-d 將IP地址轉換成主機名稱。
-f <記錄文件> 指定記錄文件。
-n <显示列數>或-<显示列數> 設置列出名單的显示列數。
-R 不显示登入系統的主機名稱或IP地址。
-x 显示系統關機,重新開機,以及執行等級的改變等信息。
***lastb
功能說明:列出登入系統失敗的用戶相關信息。
語法:lastb [-adRx][-f <記錄文件>][-n <显示列數>][帳號名稱…][終端機編號…]
補充說明:單獨執行lastb指令,它會讀取位於/var/log目錄下,名稱為btmp的文件,並把該文件內容 記錄的登入失敗的用戶名單,全部显示出來。
參數:
-a 把從何處登入系統的主機名稱或IP地址显示在最後一行。
-d 將IP地址轉換成主機名稱。
-f<記錄文件> 指定記錄文件。
-n<显示列數>或-<显示列數> 設置列出名單的显示列數。
-R 不显示登入系統的主機名稱或IP地址。
-x 显示系統關機,重新開機,以及執行等級的改變等信息。
***login
功能說明:登入系統。
語法:login
補充說明:login指令讓用戶登入系統,您亦可通過它的功能隨時更換登入身份。在Slackware發行版中 ,您可在指令後面附加欲登入的用戶名稱,它會直接詢問密碼,等待用戶輸入。當/etc目錄里含名稱為nologin的文件時,系統只root帳號登入系統,其他用戶一律不準登入。
***logname
功能說明:显示用戶名稱。
語法:logname [–help][–version]
補充說明:執行logname指令,它會显示目前用戶的名稱。
參數:
–help 在線幫助。
–vesion 显示版本信息。
***logout
功能說明:退出系統。
語法:logout
補充說明:logout指令讓用戶退出系統,其功能和login指令相互對應。
***logrotate
功能說明:管理記錄文件。
語法:logrotate [-?dfv][-s <狀態文件>][–usage][配置文件]
補充說明:使用logrotate指令,可讓你輕鬆管理系統所產生的記錄文件。它提供自動替換,壓縮,刪除和郵寄記錄文件,每個記錄文件都可被設置成每日,每周或每月處理,也能在文件太大時立即處理。您必須自行編輯,指定配置文件,預設的配置文件存放在/etc目錄下,文件名稱為logrotate.conf。
參數:
-?或–help 在線幫助。
-d或–debug 詳細显示指令執行過程,便於排錯或了解程序執行的情況。
-f或–force 強行啟動記錄文件維護操作,縱使logrotate指令認為沒有需要亦然。
-s<狀態文件>或–state=<狀態文件> 使用指定的狀態文件。
-v或–version 显示指令執行過程。
-usage 显示指令基本用法。
***newgrp
功能說明:登入另一個群組。
語法:newgrp [群組名稱]
補充說明:newgrp指令類似login指令,當它是以相同的帳號,另一個群組名稱,再次登入系統。欲使用newgrp指令切換群組,您必須是該群組的用戶,否則將無法登入指定的群組。單一用戶要同時隸屬多個群組,需利用交替用戶的設置。若不指定群組名稱,則newgrp指令會登入該用戶名稱的預設群組。
***nice
功能說明:設置優先權。
語法:nice [-n <優先等級>][–help][–version][執行指令]
補充說明:nice指令可以改變程序執行的優先權等級。
參數:
-n<優先等級>或-<優先等級>或–adjustment=<優先等級> 設置欲執行的指令的優先權等級。等級的範圍從-20-19,其中-20最高,19最低,只有系統管理者可以設置負數的等級。
–help 在線幫助。
–version 显示版本信息。
***procinfo
功能說明:显示系統狀態。
語法:procinfo [-abdDfhimsSv][-F <輸出文件>][-n <間隔秒數>]
補充說明:procinfo指令從/proc目錄里讀取相關數據,將數據妥善整理過後輸出到標準輸出設備。
參數:
-a 显示所有信息。
-b 显示磁盤設備的區塊數目,而非存取數目。
-d 显示系統信息每秒間的變化差額,而非總和的數值。本參數必須配合”-f”參數使用
-D 此參數效果和指定”-d”參數類似,但內存和交換文件的信息為總和數值。
-f 進入全畫面的互動式操作界面。
-F<輸出文件> 把信息狀態輸出到文件保存起來,而非預設的標準輸出設備。
-h 在線幫助。
-i 显示完整的IRP列表。
-m 显示系統模塊和外圍設備等相關信息。
-n間隔秒數> 設置全畫面互動模式的信息更新速度,單位以秒計算。
-s 显示系統的內存,磁盤空間,IRP和DMA等信息,此為預設值。
-S 搭配參數”-d”或”-D”使用時,每秒都會更新信息,不論是否有使用參數”-n”。
-v 显示版本信息。
***ps
功能說明:報告程序狀況。
語法:ps [-aAcdefHjlmNVwy][acefghLnrsSTuvxX][-C <指令名稱>][-g <群組名稱>][-G <群組識別碼>][-p <程序識別碼>][p <程序識別碼>][-s <階段作業>][-t <終端機編號>][t <終端機編號>][-u <用戶識別碼>][-U <用戶識別碼>][U <用戶名稱>][-<程序識別碼>][–cols <每列字符數>][–columns <每列字符數>][–cumulative][–deselect][–forest][–headers][–help][–info][–lines <显示列數>][–no-headers][–group <群組名稱>][-Group <群組識別碼>][–pid <程序識別碼>][–rows <显示列數>][–sid <階段作業>][–tty <終端機編號>][–user <用戶名稱>][–User <用戶識別碼>][–version][–width <每列字符數>]
補充說明:ps是用來報告程序執行狀況的指令,您可以搭配kill指令隨時中斷,刪除不必要的程序。
參數:
-a 显示所有終端機下執行的程序,除了階段作業領導者之外。
a 显示現行終端機下的所有程序,包括其他用戶的程序。
-A 显示所有程序。
-c 显示CLS和PRI欄位。
c 列出程序時,显示每個程序真正的指令名稱,而不包含路徑,參數或常駐服務的標示。
-C<指令名稱> 指定執行指令的名稱,並列出該指令的程序的狀況。
-d 显示所有程序,但不包括階段作業領導者的程序。
-e 此參數的效果和指定”A”參數相同。
e 列出程序時,显示每個程序所使用的環境變量。
-f 显示UID,PPIP,C與STIME欄位。
f 用ASCII字符显示樹狀結構,表達程序間的相互關係。
-g<群組名稱> 此參數的效果和指定”-G”參數相同,當亦能使用階段作業領導者的名稱來指定。
g 显示現行終端機下的所有程序,包括群組領導者的程序。
-G<群組識別碼> 列出屬於該群組的程序的狀況,也可使用群組名稱來指定。
h 不显示標題列。
-H 显示樹狀結構,表示程序間的相互關係。
-j或j 採用工作控制的格式显示程序狀況。
-l或l 採用詳細的格式來显示程序狀況。
L 列出欄位的相關信息。
-m或m 显示所有的執行緒。
n 以数字來表示USER和WCHAN欄位。
-N 显示所有的程序,除了執行ps指令終端機下的程序之外。
-p<程序識別碼> 指定程序識別碼,並列出該程序的狀況。
p<程序識別碼> 此參數的效果和指定”-p”參數相同,只在列表格式方面稍有差異。
r 只列出現行終端機正在執行中的程序。
-s<階段作業> 指定階段作業的程序識別碼,並列出隸屬該階段作業的程序的狀況。
s 採用程序信號的格式显示程序狀況。
S 列出程序時,包括已中斷的子程序資料。
-t<終端機編號> 指定終端機編號,並列出屬於該終端機的程序的狀況。
t<終端機編號> 此參數的效果和指定”-t”參數相同,只在列表格式方面稍有差異。
-T 显示現行終端機下的所有程序。
-u<用戶識別碼> 此參數的效果和指定”-U”參數相同。
u 以用戶為主的格式來显示程序狀況。
-U<用戶識別碼> 列出屬於該用戶的程序的狀況,也可使用用戶名稱來指定。
U<用戶名稱> 列出屬於該用戶的程序的狀況。
v 採用虛擬內存的格式显示程序狀況。
-V或V 显示版本信息。
-w或w 採用寬闊的格式來显示程序狀況。
x 显示所有程序,不以終端機來區分。
X 採用舊式的Linux i386登陸格式显示程序狀況。
-y 配合參數”-l”使用時,不显示F(flag)欄位,並以RSS欄位取代ADDR欄位 。
-<程序識別碼> 此參數的效果和指定”p”參數相同。
–cols<每列字符數> 設置每列的最大字符數。
–columns<每列字符數> 此參數的效果和指定”–cols”參數相同。
–cumulative 此參數的效果和指定”S”參數相同。
–deselect 此參數的效果和指定”-N”參數相同。
–forest 此參數的效果和指定”f”參數相同。
–headers 重複显示標題列。
–help 在線幫助。
–info 显示排錯信息。
–lines<显示列數> 設置显示畫面的列數。
–no-headers 此參數的效果和指定”h”參數相同,只在列表格式方面稍有差異。
–group<群組名稱> 此參數的效果和指定”-G”參數相同。
–Group<群組識別碼> 此參數的效果和指定”-G”參數相同。
–pid<程序識別碼> 此參數的效果和指定”-p”參數相同。
–rows<显示列數> 此參數的效果和指定”–lines”參數相同。
–sid<階段作業> 此參數的效果和指定”-s”參數相同。
–tty<終端機編號> 此參數的效果和指定”-t”參數相同。
–user<用戶名稱> 此參數的效果和指定”-U”參數相同。
–User<用戶識別碼> 此參數的效果和指定”-U”參數相同。
–version 此參數的效果和指定”-V”參數相同。
–widty<每列字符數> 此參數的效果和指定”-cols”參數相同。
***pstree
功能說明:以樹狀圖显示程序。
語法:pstree [-acGhlnpuUV][-H <程序識別碼>][<程序識別碼>/<用戶名稱>]
補充說明:pstree指令用ASCII字符显示樹狀結構,清楚地表達程序間的相互關係。如果不指定程序識別碼或用戶名稱,則會把系統啟動時的第一個程序視為基層,並显示之後的所有程序。若指定用戶名稱,便會以隸屬該用戶的第一個程序當作基層,然後显示該用戶的所有程序。
參數:
-a 显示每個程序的完整指令,包含路徑,參數或是常駐服務的標示。
-c 不使用精簡標示法。
-G 使用VT100終端機的列繪圖字符。
-h 列出樹狀圖時,特別標明現在執行的程序。
-H<程序識別碼> 此參數的效果和指定”-h”參數類似,但特別標明指定的程序。
-l 採用長列格式显示樹狀圖。
-n 用程序識別碼排序。預設是以程序名稱來排序。
-p 显示程序識別碼。
-u 显示用戶名稱。
-U 使用UTF-8列繪圖字符。
-V 显示版本信息。
***reboot
功能說明:重新開機。
語法:dreboot [-dfinw]
補充說明:執行reboot指令可讓系統停止運作,並重新開機。
參數:
-d 重新開機時不把數據寫入記錄文件/var/tmp/wtmp。本參數具有”-n”參數的效果。
-f 強制重新開機,不調用shutdown指令的功能。
-i 在重開機之前,先關閉所有網絡界面。
-n 重開機之前不檢查是否有未結束的程序。
-w 僅做測試,並不真的將系統重新開機,只會把重開機的數據寫入/var/log目錄下的wtmp記錄文件。
***renice
功能說明:調整優先權。
語法:renice [優先等級][-g <程序群組名稱>…][-p <程序識別碼>…][-u <用戶名稱>…]
補充說明:renice指令可重新調整程序執行的優先權等級。預設是以程序識別碼指定程序調整其優先權,您亦可以指定程序群組或用戶名稱調整優先權等級,並修改所有隸屬於該程序群組或用戶的程序的優先權。等級範圍從-20–19,只有系統管理者可以改變其他用戶程序的優先權,也僅有系統管理者可以設置負數等級。
參數:
-g <程序群組名稱> 使用程序群組名稱,修改所有隸屬於該程序群組的程序的優先權。
-p <程序識別碼> 改變該程序的優先權等級,此參數為預設值。
-u <用戶名稱> 指定用戶名稱,修改所有隸屬於該用戶的程序的優先權。
***rlogin
功能說明:遠端登入。
語法:rlogin [-8EL][-e <脫離字符>][-l <用戶名稱>][主機名稱或IP地址]
補充說明:執行rlogin指令開啟終端機階段操作,並登入遠端主機。
參數:
-8 允許輸入8位字符數據。
-e脫離字符> 設置脫離字符。
-E 濾除脫離字符。
-l用戶名稱> 指定要登入遠端主機的用戶名稱。
-L 使用litout模式進行遠端登入階段操作。
***rsh
功能說明:遠端登入的Shell。
語法:rsh [-dn][-l <用戶名稱>][主機名稱或IP地址][執行指令]
補充說明:rsh提供用戶環境,也就是Shell,以便指令能夠在指定的遠端主機上執行。
參數:
-d 使用Socket層級的排錯功能。
-l<用戶名稱> 指定要登入遠端主機的用戶名稱。
-n 把輸入的指令號向代號為/dev/null的特殊外圍設備。
***rwho
功能說明:查看系統用戶。
語法:rwho [-a]
補充說明:rwho指令的效果類似who指令,但它會显示局域網裡所有主機的用戶。主機必須提供rwhod常駐服務的功能,方可使用rwho指令。
參數:
-a 列出所有的用戶,包括閑置時間超過1個小時以上的用戶。
***screen
功能說明:多重視窗管理程序。
語法:screen [-AmRvx -ls -wipe][-d <作業名稱>][-h <行數>][-r <作業名稱>][-s ][-S <作業名稱>]
補充說明:screen為多重視窗管理程序。此處所謂的視窗,是指一個全屏幕的文字模式畫面。通常只有在使用telnet登入主機或是使用老式的終端機時,才有可能用到screen程序。
參數:
-A 將所有的視窗都調整為目前終端機的大小。
-d<作業名稱> 將指定的screen作業離線。
-h<行數> 指定視窗的緩衝區行數。
-m 即使目前已在作業中的screen作業,仍強制建立新的screen作業。
-r<作業名稱> 恢復離線的screen作業。
-R 先試圖恢復離線的作業。若找不到離線的作業,即建立新的screen作業。
-s 指定建立新視窗時,所要執行的shell。
-S<作業名稱> 指定screen作業的名稱。
-v 显示版本信息。
-x 恢復之前離線的screen作業。
-ls或–list 显示目前所有的screen作業。
-wipe 檢查目前所有的screen作業,並刪除已經無法使用的screen作業。
***shutdown
功能說明:系統關機指令。
語法:shutdown [-efFhknr][-t 秒數][時間][警告信息]
補充說明:shutdown指令可以關閉所有程序,並依用戶的需要,進行重新開機或關機的動作。
參數:
-c 當執行”shutdown -h 11:50″指令時,只要按+鍵就可以中斷關機的指令。
-f 重新啟動時不執行fsck。
-F 重新啟動時執行fsck。
-h 將系統關機。
-k 只是送出信息給所有用戶,但不會實際關機。
-n 不調用init程序進行關機,而由shutdown自己進行。
-r shutdown之後重新啟動。
-t<秒數> 送出警告信息和刪除信息之間要延遲多少秒。
[時間] 設置多久時間后執行shutdown指令。
[警告信息] 要傳送給所有登入用戶的信息。
***sliplogin
功能說明:將SLIP接口加入標準輸入。
語法:sliplogin [用戶名稱]
補充說明:sliplogin可將SLIP接口加入標準輸入,把一般終端機的連線變成SLIP連線。通常可用來建立SLIP服務器,讓遠端電腦以SLIP連線到服務器。sliplogin活去檢查/etc/slip/slip.hosts文件中是否有相同的用戶名稱。通過檢查后,sliplogin會調用執行shell script來設置IP地址,子網掩碼等網絡界面環境。此shell script通常是/etc/slip/slip.login。
***su
功能說明:變更用戶身份。
語法:su [-flmp][–help][–version][-][-c <指令>][-s ][用戶帳號]
補充說明:su可讓用戶暫時變更登入的身份。變更時須輸入所要變更的用戶帳號與密碼。
參數:
-c<指令>或–command=<指令> 執行完指定的指令后,即恢復原來的身份。
-f或–fast 適用於csh與tsch,使shell不用去讀取啟動文件。
-.-l或–login 改變身份時,也同時變更工作目錄,以及HOME,SHELL,USER,LOGNAME。此外,也會變更PATH變量。
-m,-p或–preserve-environment 變更身份時,不要變更環境變量。
-s 或–shell= 指定要執行的shell。
–help 显示幫助。
–version 显示版本信息。
[用戶帳號] 指定要變更的用戶。若不指定此參數,則預設變更為root。
***sudo
功能說明:以其他身份來執行指令。
語法:sudo [-bhHpV][-s ][-u <用戶>][指令] 或 sudo [-klv]
補充說明:sudo可讓用戶以其他的身份來執行指定的指令,預設的身份為root。在/etc/sudoers中設置了可執行sudo指令的用戶。若其未經授權的用戶企圖使用sudo,則會發出警告的郵件給管理員。用戶使用sudo時,必須先輸入密碼,之後有5分鐘的有效期限,超過期限則必須重新輸入密碼。
參數:
-b 在後台執行指令。
-h 显示幫助。
-H 將HOME環境變量設為新身份的HOME環境變量。
-k 結束密碼的有效期限,也就是下次再執行sudo時便需要輸入密碼。
-l 列出目前用戶可執行與無法執行的指令。
-p 改變詢問密碼的提示符號。
-s 執行指定的shell。
-u<用戶> 以指定的用戶作為新的身份。若不加上此參數,則預設以root作為新的身份。
-v 延長密碼有效期限5分鐘。
-V 显示版本信息。
***suspend
功能說明:暫停執行shell。
語法:suspend [-f]
補充說明:suspend為shell內建指令,可暫停目前正在執行的shell。若要恢復,則必須使用SIGCONT信息。
參數:
-f 若目前執行的shell為登入的shell,則suspend預設無法暫停此shell。若要強迫暫停登入的shell,則必須使用-f參數。
***swatch
功能說明:系統監控程序。
語法:swatch [-A <分隔字符>][-c <設置文件>][-f <記錄文件>][-I <分隔字符>][-P <分隔字符>][-r <時間>][-t <記錄文件>]
補充說明:swatch可用來監控系統記錄文件,並在發現特定的事件時,執行指定的動作。swatch所監控的事件以及對應事件的動作都存放在swatch的配置文件中。預設的配置文件為擁護根目錄下的.swatchrc。然而在Red Hat Linux的預設用戶根目錄下並沒有.swatchrc配置文件,您可將/usr/doc/swatch-2.2/config_files/swatchrc.personal文件複製到用戶根目錄下的.swatchrc,然後修改.swatchrc所要監控的事件及執行的動作。
參數:
-A<分隔字符> 預設配置文件中,動作的分隔字符,預設為逗號。
-c設置文件> 指定配置文件,而不使用預設的配置文件。
-f記錄文件> 檢查指定的記錄文件,檢查完畢后不會繼續監控該記錄文件。
-I分隔字符> 指定輸入記錄的分隔字符,預設為換行字符。
-P分隔字符> 指定配置文件中,事件的分隔字符,預設為逗號。
-r時間> 在指定的時間重新啟動。
-t<記錄文件> 檢查指定的記錄文件,並且會監控加入記錄文件中的後繼記錄。
***tload
功能說明:显示系統負載狀況。
語法:tload [-V][-d <間隔秒數>][-s <刻度大小>][終端機編號]
補充說明:tload指令使用ASCII字符簡單地以文字模式显示系統負載狀態。假設不給予終端機編號,則會在執行tload指令的終端機显示負載情形。
參數:
-d<間隔秒數> 設置tload檢測系統負載的間隔時間,單位以秒計算。
-s<刻度大小> 設置圖表的垂直刻度大小,單位以列計算。
-V 显示版本信息。
***top
功能說明:显示,管理執行中的程序。
語法:top [bciqsS][d <間隔秒數>][n <執行次數>]
補充說明:執行top指令可显示目前正在系統中執行的程序,並通過它所提供的互動式界面,用熱鍵加以管理。
參數:
b 使用批處理模式。
c 列出程序時,显示每個程序的完整指令,包括指令名稱,路徑和參數等相關信息。
d<間隔秒數> 設置top監控程序執行狀況的間隔時間,單位以秒計算。
i 執行top指令時,忽略閑置或是已成為Zombie的程序。
n<執行次數> 設置監控信息的更新次數。
q 持續監控程序執行的狀況。
s 使用保密模式,消除互動模式下的潛在危機。
S 使用累計模式,其效果類似ps指令的”-S”參數。
***uname
功能說明:显示系統信息。
語法:uname [-amnrsv][–help][–version]
補充說明:uname可显示電腦以及操作系統的相關信息。
參數:
-a或–all 显示全部的信息。
-m或–machine 显示電腦類型。
-n或-nodename 显示在網絡上的主機名稱。
-r或–release 显示操作系統的發行編號。
-s或–sysname 显示操作系統名稱。
-v 显示操作系統的版本。
–help 显示幫助。
–version 显示版本信息。
***useradd
功能說明:建立用戶帳號。
語法:useradd [-mMnr][-c <備註>][-d <登入目錄>][-e <有效期限>][-f <緩衝天數>][-g <群組>][-G <群組>][-s ][-u ][用戶帳號] 或 useradd -D [-b][-e <有效期限>][-f <緩衝天數>][-g <群組>][-G <群組>][-s ]
補充說明:useradd可用來建立用戶帳號。帳號建好之後,再用passwd設定帳號的密碼.而可用userdel刪除帳號。使用useradd指令所建立的帳號,實際上是保存在/etc/passwd文本文件中。
參數:
-c<備註> 加上備註文字。備註文字會保存在passwd的備註欄位中。
-d<登入目錄> 指定用戶登入時的啟始目錄。
-D 變更預設值.
-e<有效期限> 指定帳號的有效期限。
-f<緩衝天數> 指定在密碼過期后多少天即關閉該帳號。
-g<群組> 指定用戶所屬的群組。
-G<群組> 指定用戶所屬的附加群組。
-m 自動建立用戶的登入目錄。
-M 不要自動建立用戶的登入目錄。
-n 取消建立以用戶名稱為名的群組.
-r 建立系統帳號。
-s 指定用戶登入后所使用的shell。
-u 指定用戶ID。
***userconf
功能說明:用戶帳號設置程序。
語法:userconf [–addgroup <群組>][–adduser <用戶ID><群組><用戶名稱>][–delgroup <群組>][–deluser <用戶ID>][–help]
補充說明:userconf實際上為linuxconf的符號連接,提供圖形界面的操作方式,供管理員建立與管理各類帳號。若不加任何參數,即進入圖形界面。
參數:
–addgroup<群組> 新增群組。
–adduser<用戶ID><群組><用戶名稱> 新增用戶帳號。
–delgroup<群組> 刪除群組。
–deluser<用戶ID> 刪除用戶帳號。
–help 显示幫助。
***userdel
功能說明:刪除用戶帳號。
語法:userdel [-r][用戶帳號]
補充說明:userdel可刪除用戶帳號與相關的文件。若不加參數,則僅刪除用戶帳號,而不刪除相關文件。
參數:
-f 刪除用戶登入目錄以及目錄中所有文件。
***usermod
功能說明:修改用戶帳號。
語法:usermod [-LU][-c <備註>][-d <登入目錄>][-e <有效期限>][-f <緩衝天數>][-g <群組>][-G <群組>][-l <帳號名稱>][-s ][-u ][用戶帳號]
補充說明:usermod可用來修改用戶帳號的各項設定。
參數:
-c<備註> 修改用戶帳號的備註文字。
-d登入目錄> 修改用戶登入時的目錄。
-e<有效期限> 修改帳號的有效期限。
-f<緩衝天數> 修改在密碼過期后多少天即關閉該帳號。
-g<群組> 修改用戶所屬的群組。
-G<群組> 修改用戶所屬的附加群組。
-l<帳號名稱> 修改用戶帳號名稱。
-L 鎖定用戶密碼,使密碼無效。
-s 修改用戶登入后所使用的shell。
-u 修改用戶ID。
-U 解除密碼鎖定。
***vlock
功能說明:鎖住虛擬終端。
語法:vlock [-achv]
補充說明:執行vlock指令可鎖住虛擬終端,避免他人使用。
參數:
-a或–all 鎖住所有的終端階段作業,如果您在全屏幕的終端中使用本參數,則會將用鍵盤 切換終端機的功能一併關閉。
-c或–current 鎖住目前的終端階段作業,此為預設值。
-h或–help 在線幫助。
-v或–version 显示版本信息。
***w
功能說明:显示目前登入系統的用戶信息。
語法:w [-fhlsuV][用戶名稱]
補充說明:執行這項指令可得知目前登入系統的用戶有那些人,以及他們正在執行的程序。單獨執行w 指令會显示所有的用戶,您也可指定用戶名稱,僅显示某位用戶的相關信息。
參數:
-f 開啟或關閉显示用戶從何處登入系統。
-h 不显示各欄位的標題信息列。
-l 使用詳細格式列表,此為預設值。
-s 使用簡潔格式列表,不显示用戶登入時間,終端機階段作業和程序所耗費的CPU時間。
-u 忽略執行程序的名稱,以及該程序耗費CPU時間的信息。
-V 显示版本信息。
***who
功能說明:显示目前登入系統的用戶信息。
語法:who [-Himqsw][–help][–version][am i][記錄文件]
補充說明:執行這項指令可得知目前有那些用戶登入系統,單獨執行who指令會列出登入帳號,使用的 終端機,登入時間以及從何處登入或正在使用哪個X显示器。
參數:
-H或–heading 显示各欄位的標題信息列。
-i或-u或–idle 显示閑置時間,若該用戶在前一分鐘之內有進行任何動作,將標示成”.”號,如果該用戶已超過24小時沒有任何動作,則標示出”old”字符串。
-m 此參數的效果和指定”am i”字符串相同。
-q或–count 只显示登入系統的帳號名稱和總人數。
-s 此參數將忽略不予處理,僅負責解決who指令其他版本的兼容性問題。
-w或-T或–mesg或–message或–writable 显示用戶的信息狀態欄。
–help 在線幫助。
–version 显示版本信息。
***whoami
功能說明:先似乎用戶名稱。
語法:whoami [–help][–version]
補充說明:显示自身的用戶名稱,本指令相當於執行”id -un”指令。
參數:
–help 在線幫助。
–version 显示版本信息。
***whois
功能說明:查找並显示用戶信息。
語法:whois [帳號名稱]
補充說明:whois指令會去查找並显示指定帳號的用戶相關信息,因為它是到Network Solutions的WHOIS數據庫去查找,所以該帳號名稱必須在上面註冊方能尋獲,且名稱沒有大小寫的差別。
文檔管理
***col
功能說明:過濾控制字符。
語法:col [-bfx][-l<緩衝區列數>]
補充說明:在許多UNIX說明文件里,都有RLF控制字符。當我們運用shell特殊字符”>”和”>>”,把說明文件的內容輸出成純文本文件時,控制字符會變成亂碼,col指令則能有效濾除這些控制字符。
參數:
-b 過濾掉所有的控制字符,包括RLF和HRLF。
-f 濾除RLF字符,但允許將HRLF字符呈現出來。
-x 以多個空格字符來表示跳格字符。
-l<緩衝區列數> 預設的內存緩衝區有128列,您可以自行指定緩衝區的大小。
***colrm
功能說明:濾掉指定的行。
語法:colrm [開始行數編號<結束行數編號>]
補充說明:colrm指令從標準輸入設備讀取書記,轉而輸出到標準輸出設備。如果不加任何參數,則該指令不會過濾任何一行。
***comm
功能說明:比較兩個已排過序的文件。
語法:comm [-123][–help][–version][第1個文件][第2個文件]
補充說明:這項指令會一列列地比較兩個已排序文件的差異,並將其結果显示出來,如果沒有指定任何參數,則會把結果分成3行显示:第1行僅是在第1個文件中出現過的列,第2行是僅在第2個文件中出現過的列,第3行則是在第1與第2個文件里都出現過的列。若給予的文件名稱為”-“,則comm指令會從標準輸入設備讀取數據。
參數:
-1 不显示只在第1個文件里出現過的列。
-2 不显示只在第2個文件里出現過的列。
-3 不显示只在第1和第2個文件里出現過的列。
–help 在線幫助。
–version 显示版本信息。
***csplit
功能說明:分割文件。
語法:csplit [-kqsz][-b<輸出格式>][-f<輸出字首字符串>][-n<輸出文件名位數>][–help][–version][文件][範本樣式…]
補充說明:將文件依照指定的範本樣式予以切割后,分別保存成名稱為xx00,xx01,xx02…的文件。若給予的文件名稱為”-“,則csplit指令會從標準輸入設備讀取數據。
參數:
-b<輸出格式>或–suffix-format=<輸出格式> 預設的輸出格式其文件名稱為xx00,xx01…等,您可以通過改變<輸出格式>來改變輸出的文件名。
-f<輸出字首字符串>或–prefix=<輸出字首字符串> 預設的輸出字首字符串其文件名為xx00,xx01…等,如果你指定輸出字首字符串為”hello”,則輸出的文件名稱會變成hello00,hello01…等。
-k或–keep-files 保留文件,就算髮生錯誤或中斷執行,也不能刪除已經輸出保存的文件。
-n<輸出文件名位數>或–digits=<輸出文件名位數> 預設的輸出文件名位數其文件名稱為xx00,xx01…等,如果你指定輸出文件名位數為”3″,則輸出的文件名稱會變成xx000,xx001…等。
-q或-s或–quiet或–silent 不显示指令執行過程。
-z或–elide-empty-files 刪除長度為0 Byte文件。
–help 在線幫助。
–version 显示版本信息。
***ed
功能說明:文本編輯器。
語法:ed [-][-Gs][-p<字符串>][–help][–version][文件]
補充說明:ed是Linux中功能最簡單的文本編輯程序,一次僅能編輯一行而非全屏幕方式的操作。
參數:
-G或–traditional 提供回兼容的功能。
-p<字符串> 指定ed在command mode的提示字符。
-s,-,–quiet或–silent 不執行開啟文件時的檢查功能。
–help 显示幫助。
–version 显示版本信息。
***egrep
功能說明:在文件內查找指定的字符串。egrep執行效果如grep -E,使用的語法及參數可參照grep指令,與grep不同點在於解讀字符串的方法,egrep是用extended regular expression語法來解讀,而grep則用basic regular expression語法,extended regular expression比basic regular expression有更完整的表達規範。
***ex
功能說明:在Ex模式下啟動vim文本編輯器。ex執行效果如同vi -E,使用語法及參數可參照vi指令,如要從Ex模式回到普通模式,則在vim中輸入:vi或:visual即可。
***fgrep
功能說明:查找文件里符合條件的字符串。
語法:fgrep [範本樣式][文件或目錄…]
補充說明:本指令相當於執行grep指令加上參數”-F”,詳見grep指令說明。
***fmt
功能說明:編排文本文件。
語法:fmt [-cstu][-p<列起始字符串>][-w<每列字符數>][–help][–version][文件…]
補充說明:fmt指令會從指定的文件里讀取內容,將其依照指定格式重新編排后,輸出到標準輸出設備。若指定的文件名為”-“,則fmt指令會從標準輸入設備讀取數據。
參數:
-c或–crown-margin 每段前兩列縮排。
-p<列起始字符串>或-prefix=<列起始字符串> 僅合併含有指定字符串的列,通常運用在程序語言的註解方面。
-s或–split-only 只拆開字數超出每列字符數的列,但不合併字數不足每列字符數的列。
-t或–tagged-paragraph 每列前兩列縮排,但第1列和第2列的縮排格式不同。
-u或–uniform-spacing 每個字符之間都以一個空格字符間隔,每個句子之間則兩個空格字符分隔。
-w<每列字符數>或–width=<每列字符數>或-<每列字符數> 設置每列的最大字符數。
–help 在線幫助。
–version 显示版本信息。
***fold
功能說明:限制文件列寬。
語法:fold [-bs][-w<每列行數>][–help][–version][文件…]
補充說明:fold指令會從指定的文件里讀取內容,將超過限定列寬的列加入增列字符后,輸出到標準輸出設備。若不指定任何文件名稱,或是所給予的文件名為“-”,則fold指令會從標準輸入設備讀取數據。
參數:
-b或–bytes 以Byte為單位計算列寬,而非採用行數編號為單位。
-s或–spaces 以空格字符作為換列點。
-w<每列行數>或–width<每列行數> 設置每列的最大行數。
–help 在線幫助。
–version 显示版本信息。
***grep
功能說明:查找文件里符合條件的字符串。
語法:grep [-abcEFGhHilLnqrsvVwxy][-A<显示列數>][-B<显示列數>][-C<显示列數>][-d<進行動作>][-e<範本樣式>][-f<範本文件>][–help][範本樣式][文件或目錄…]
補充說明:grep指令用於查找內容包含指定的範本樣式的文件,如果發現某文件的內容符合所指定的範本樣式,預設grep指令會把含有範本樣式的那一列显示出來。若不指定任何文件名稱,或是所給予的文件名為“-”,則grep指令會從標準輸入設備讀取數據。
參數:
-a或–text 不要忽略二進制的數據。
-A<显示列數>或–after-context=<显示列數> 除了显示符合範本樣式的那一列之外,並显示該列之後的內容。
-b或–byte-offset 在显示符合範本樣式的那一列之前,標示出該列第一個字符的位編號。
-B<显示列數>或–before-context=<显示列數> 除了显示符合範本樣式的那一列之外,並显示該列之前的內容。
-c或–count 計算符合範本樣式的列數。
-C<显示列數>或–context=<显示列數>或-<显示列數> 除了显示符合範本樣式的那一列之外,並显示該列之前後的內容。
-d<進行動作>或–directories=<進行動作> 當指定要查找的是目錄而非文件時,必須使用這項參數,否則grep指令將回報信息並停止動作。
-e<範本樣式>或–regexp=<範本樣式> 指定字符串做為查找文件內容的範本樣式。
-E或–extended-regexp 將範本樣式為延伸的普通表示法來使用。
-f<範本文件>或–file=<範本文件> 指定範本文件,其內容含有一個或多個範本樣式,讓grep查找符合範本條件的文件內容,格式為每列一個範本樣式。
-F或–fixed-regexp 將範本樣式視為固定字符串的列表。
-G或–basic-regexp 將範本樣式視為普通的表示法來使用。
-h或–no-filename 在显示符合範本樣式的那一列之前,不標示該列所屬的文件名稱。
-H或–with-filename 在显示符合範本樣式的那一列之前,表示該列所屬的文件名稱。
-i或–ignore-case 忽略字符大小寫的差別。
-l或–file-with-matches 列出文件內容符合指定的範本樣式的文件名稱。
-L或–files-without-match 列出文件內容不符合指定的範本樣式的文件名稱。
-n或–line-number 在显示符合範本樣式的那一列之前,標示出該列的列數編號。
-q或–quiet或–silent 不显示任何信息。
-r或–recursive 此參數的效果和指定“-d recurse”參數相同。
-s或–no-messages 不显示錯誤信息。
-v或–revert-match 反轉查找。
-V或–version 显示版本信息。
-w或–word-regexp 只显示全字符合的列。
-x或–line-regexp 只显示全列符合的列。
-y 此參數的效果和指定“-i”參數相同。
–help 在線幫助。
***ispell
功能說明:拼字檢查程序。
語法:ispell [-aAbBClmMnNPStVx][-d<字典文件>][-L<行數>][-p<字典文件>][-w<非字母字符>][-W<字符串長度>][要檢查的文件]
補充說明:ispell預設會使用/usr/lib/ispell/english.hash字典文件來檢查文本文件。若在檢查的文件中找到字典沒有的詞彙,ispell會建議使用的詞彙,或是讓你將新的詞彙加入個人字典。
參數:
-a 當其他程序輸出送到ispell時,必須使用此參數。
-A 讀取到”&Include File&”字符串時,就去檢查字符串后所指定文件的內容。
-b 產生備份文件,文件名為.bak。
-B 檢查連字錯誤。
-C 不檢查連字錯誤。
-d<字典文件> 指定字典文件。
-l 從標準輸入設備讀取字符串,結束后显示拼錯的詞彙。
-L<行數> 指定內文显示的行數。
-m 自動考慮字尾的變化。
-M 進入ispell后,在畫面下方显示指令的按鍵。
-n 檢查的文件為noff或troff的格式。
-N 進入ispell后,在畫面下方不显示指令的按鍵。
-p<字典文件> 指定個人字典文件。
-P 不考慮字尾變化的情形。
-S 不排序建議取代的詞彙。
-t 檢查的文件為TeX或LaTeX的格式。
-V 非ANSI標準的字符會以”M-^”的方式來显示。
-w<非字母字符> 檢查時,特別挑出含有指定的字符。
-W<字符串長度> 不檢查指定長度的詞彙。
-x 不要產生備份文件。
***jed
功能說明:編輯文本文件。
語法:jed [-2n][-batch][-f<函數>][-g<行數>][-i<文件>][-I<文件>][-s<字符串>][文件]
補充說明:Jed是以Slang所寫成的程序,適合用來編輯程序原始代碼。
參數:
-2 显示上下兩個編輯區。
-batch 以批處理模式來執行。
-f<函數> 執行Slang函數。
-g<行數> 移到緩衝區中指定的行數。
-i<文件> 將指定的文件載入緩衝區。
-i<文件> 載入Slang原始代碼文件。
-n 不要載入jed.rc配置文件。
-s<字符串> 查找並移到指定的字符串。
***joe
功能說明:編輯文本文件。
語法:joe [-asis][-beep][-csmode][-dopadding][-exask][-force][-help][-keepup][-lightoff][-arking][-mid][-nobackups][-nonotice][-nosta][-noxon][-orphan][-backpath<目錄>][-columns<欄位>][-lines<行數>][-pg<行數>][-skiptop<行數>][-autoindent crlf linums overwrite rdonly wordwrap][+<行數>][-indentc<縮排字符>][-istep<縮排字符數>][-keymap<按鍵配置文件>][-lmargin<欄數>][-rmargin<欄數>][-tab<欄數>][要編輯的文件]
補充說明:Joe是一個功能強大的全屏幕文本編輯程序。操作的複雜度要比Pico高一點,但是功能較為齊全。Joe一次可開啟多個文件,每個文件各放在一個編輯區內,並可在文件之間執行剪貼的動作。
參數: 以下為程序參數
-asis 字符碼超過127的字符不做任何處理。
-backpath<目錄> 指定備份文件的目錄。
-beep 編輯時,若有錯誤即發出嘩聲。
-columns<欄位> 設置欄數。
-csmode 可執行連續查找模式。
-dopadding 是程序跟tty間存在緩衝區。
-exask 在程序中,執行”Ctrl+k+x”時,會先確認是否要保存文件。
-force 強制在最後一行的結尾處加上換行符號。
-help 執行程序時一併显示幫助。
-keepup 在進入程序后,畫面上方為狀態列。
-lightoff 選取的區塊在執行完區塊命令后,就會回復成原來的狀態。
-lines<行數> 設置行數。
-marking 在選取區塊時,反白區塊會隨着光標移動。
-mid 當光標移出畫面時,即自動卷頁,使光標回到中央。
-nobackups 不建立備份文件。
-nonotice 程序執行時,不显示版權信息。
-nosta 程序執行時,不显示狀態列。
-noxon 嘗試取消“Ctrl+s”與“Ctrl+q”鍵的功能。
-orphan 若同時開啟一個以上的文件,則其他文件會置於獨立的緩衝區,而不會另外開啟編輯區。
-pg<行數> 按“PageUp”或“PageDown”換頁時,所要保留前一頁的行數。
-skiptop<行數> 不使用屏幕上方指定的行數。
以下為文件參數
+<行數> 指定開啟文件時,光標所在的行數。
-autoindent 自動縮排。
-crlf 在換行時,使用CR-LF字符。
-indentc<縮排字符> 執行縮排時,實際插入的字符。
-istep<縮排字符數> 每次執行縮排時,所移動的縮排字符數。
-keymap<按鍵配置文件> 使用不同的按鍵配置文件。
-linums 在每行前面加上行號。
-lmargin<欄數> 設置左側邊界。
-overwrite 設置覆蓋模式。
-rmargin<欄數> 設置右側邊界。
-tab<欄數> 設置tab的寬度。
-rdonly 以只讀的方式開啟文件-wordwrap編輯時若超過右側邊界,則自動換行。
***join
功能說明:將兩個文件中,指定欄位內容相同的行連接起來。
語法:join [-i][-a<1或2>][-e<字符串>][-o<格式>][-t<字符>][-v<1或2>][-1<欄位>][-2<欄位>][–help][–version][文件1][文件2]
補充說明:找出兩個文件中,指定欄位內容相同的行,並加以合併,再輸出到標準輸出設備。
參數:
-a<1或2> 除了显示原來的輸出內容之外,還显示指令文件中沒有相同欄位的行。
-e<字符串> 若[文件1]與[文件2]中找不到指定的欄位,則在輸出中填入選項中的字符串。
-i或–igore-case 比較欄位內容時,忽略大小寫的差異。
-o<格式> 按照指定的格式來显示結果。
-t<字符> 使用欄位的分隔字符。
-v<1或2> 跟-a相同,但是只显示文件中沒有相同欄位的行。
-1<欄位> 連接[文件1]指定的欄位。
-2<欄位> 連接[文件2]指定的欄位。
–help 显示幫助。
–version 显示版本信息。
***look
功能說明:查詢單字。
語法:look [-adf][-t<字尾字符串>][字首字符串][字典文件]
補充說明:look指令用於英文單字的查詢。您僅需給予它欲查詢的字首字符串,它會显示所有開頭字符串符合該條件的單字。
參數:
-a 使用另一個字典文件web2,該文件也位於/usr/dict目錄下。
-d 只對比英文字母和数字,其餘一慨忽略不予比對。
-f 忽略字符大小寫差別。
-t<字尾字符串> 設置字尾字符串。
***mtype
功能說明:显示MS-DOS文件的內容。
語法:mtype [-st][文件]
補充說明:mtype為mtools工具指令,模擬MS-DOS的type指令,可显示MS-DOS文件的內容。
參數:
-s 去除8位字符碼集的第一個位,使它兼容於7位的ASCII。
-t 將MS-DOS文本文件中的“換行+光標移至行首”字符轉換成Linux的換行字符。
***pico
功能說明:編輯文字文件。
語法:pico [-bdefghjkmqtvwxz][-n<間隔秒數>][-o<工作目錄>][-r<編輯頁寬>][-s<拼字檢查器>][+<列數編號>][文件]
補充說明:pico是個簡單易用、以显示導向為主的文字編輯程序,它伴隨着處理电子郵件和新聞組的程序pine而來。
參數:
-b 開啟置換的功能。
-d 開啟刪除的功能。
-e 使用完整的文件名稱。
-f 支持鍵盤上的F1、F2…等功能鍵。
-g 显示光標。
-h 在線幫助。
-j 開啟切換的功能。
-k 預設pico在使用剪下命令時,會把光標所在的列的內容全部刪除。
-m 開啟鼠標支持的功能,您可用鼠標點選命令列表。
-n<間隔秒數> 設置多久檢查一次新郵件。
-o<工作目錄> 設置工作目錄。
-q 忽略預設值。
-r<編輯頁寬> 設置編輯文件的頁寬。
-s<拼字檢查器> 另外指定拼字檢查器。
-t 啟動工具模式。
-v 啟動閱讀模式,用戶只能觀看,無法編輯文件的內容。
-w 關閉自動換行,通過這個參數可以編輯內容很長的列。
-x 關閉換面下方的命令列表。
-z 讓pico可被Ctrl+z中斷,暫存在後台作業里。
+<列數編號> 執行pico指令進入編輯模式時,從指定的列數開始編輯。
***rgrep
功能說明:遞歸查找文件里符合條件的字符串。
語法:rgrep [-?BcDFhHilnNrv][-R<範本樣式>][-W<列長度>][-x<擴展名>][–help][–version][範本樣式][文件或目錄…]
補充說明:rgrep指令的功能和grep指令類似,可查找內容包含指定的範本樣式的文件,如果發現某文件的內容符合所指定的範本樣式,預設rgrep指令會把含有範本樣式的那一列显示出來。
參數:
-? 显示範本樣式與範例的說明。
-B 忽略二進制的數據。
-c 計算符合範本樣式的列數。
-D 排錯模式,只列出指令搜尋的目錄清單,而不會讀取文件內容。
-F 當遇到符號連接時,rgrep預設是忽略不予處理,加上本參數后,rgrep指令就會讀取該連接所指向的原始文件的內容。
-h 特別將符合範本樣式的字符串標示出來。
-H 只列出符合範本樣式的字符串,而非显示整列的內容。
-i 忽略字符大小寫的差別。
-l 列出文件內容符合指定的範本樣式的文件名稱。
-n 在显示符合坊本樣式的那一列之前,標示出該列的列數編號。
-N 不要遞歸處理。
-r 遞歸處理,將指定目錄下的所有文件及子目錄一併處理。
-R<範本樣式> 此參數的效果和指定“-r”參數類似,但只主力符合範本樣式文件名稱的文件。
-v 反轉查找。
-W<列長度> 限制符合範本樣式的字符串所在列,必須擁有的字符數。
-x<擴展名> 只處理符合指定擴展名的文件名稱的文件。
–help 在線幫助。
–version 显示版本信息。
***sed
功能說明:利用script來處理文本文件。
語法:
sed [-hnV][-e<script>][-f<script文件>][文本文件]
補充說明:sed可依照script的指令,來處理、編輯文本文件。
參數:
-e
刷新評論 刷新頁面 返回頂部 本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※回頭車貨運收費標準
※推薦評價好的iphone維修中心
※超省錢租車方案
※台中搬家遵守搬運三大原則,讓您的家具不再被破壞!
※推薦台中搬家公司優質服務,可到府估價