0.前言
在上一篇中,我們提到了如何創建一個UnitOfWork並通過ActionFilter設置啟用。這一篇我們將簡單介紹一下ActionFilter以及如何利用ActionFilter,順便補齊一下上一篇的工具類。
1. ActionFilter 介紹
ActionFilter全稱是ActionFilterAttribute,我們根據微軟的命名規範可以看出這是一個特性類,看一下它的聲明:
[AttributeUsage(AttributeTargets.Class | AttributeTargets.Method, AllowMultiple = true, Inherited = true)]
public abstract class ActionFilterAttribute : Attribute, IActionFilter, IFilterMetadata, IAsyncActionFilter, IAsyncResultFilter, IOrderedFilter, IResultFilter
這是一個允許標註在類和方法上的特性類,允許多個標記,標註之後子類會繼承父類的特性。然後,這個類是一個抽象類,所以我們可以通過繼承ActionFilterAttribute來編寫自己的ActionFilter。
1.1 ActionFilter的四個方法
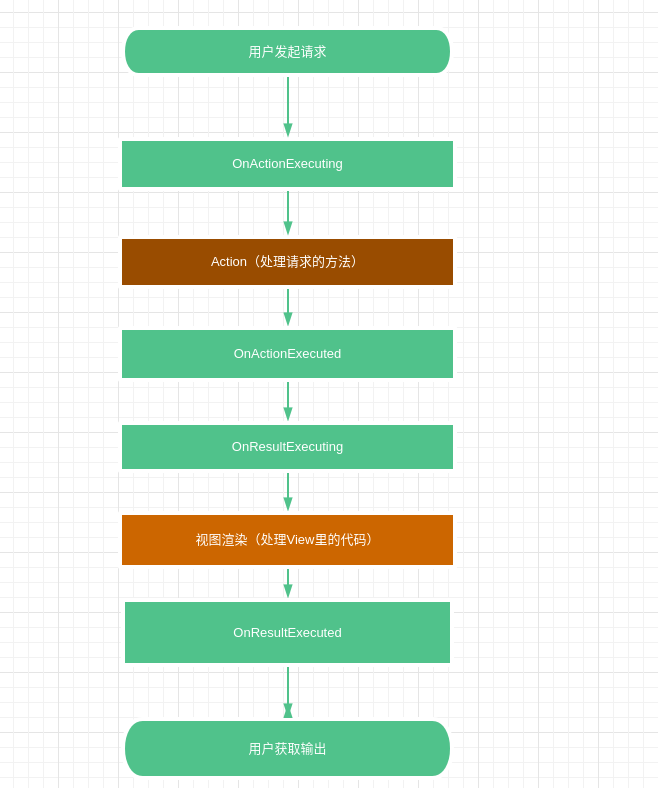
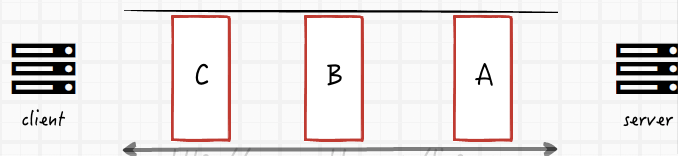
對於一個ActionFilter而言,最重要的是它的四個方法:
public virtual void OnActionExecuted(ActionExecutedContext context);
public virtual void OnActionExecuting(ActionExecutingContext context);
public virtual void OnResultExecuted(ResultExecutedContext context);
public virtual void OnResultExecuting(ResultExecutingContext context);
上圖是這四個方法在一次請求中執行的順序。在一次請求真正執行之前,想要攔截這個請求,應該使用OnActionExecuting。
為什麼單獨說這個呢?因為這個方法的出鏡率很高,大多數時候都會使用這個方法進行請求過濾。
1.2 在ActionFilter中我們能做什麼
我們來簡單介紹一下,四個方法中的四種上下文類型,看一看裏面有哪些我們可以利用的方法:
1.2.1 ActionExecutingContext
這是一個Action執行前的上下文,表示Action並未開始執行,但是已經獲取到了控制器實例:
public class ActionExecutingContext : FilterContext
{
public virtual IDictionary<string, object> ActionArguments { get; }
public virtual object Controller { get; }
public virtual IActionResult Result { get; set; }
}
ActionExecutingContext繼承自FilterContext,我們暫且不關注它的父類,只看一下它自己的屬性。
- ActionArguments 表示Action的參數列表,這裏面放着各種從用戶接到請求參數以及其他中間處理程序添加的參數
- Controller 表示執行該請求的控制器,在之前我們提過,asp.net core 對於控制器的限制很小,所以控制器什麼類型都可能,故而這裏使用object作為控制器類型
- Result 執行結果,正常情況下,在此處獲取這個屬性的值沒有意義。但是我們可以通過修改這個屬性的值,來讓我們攔截請求
1.2.2 ActionExecutedContext
ActionExecutedContext 表示Action執行完成后的上下文,這時候Action已經執行完成,我們可以通過這個獲取Action執行結果:
public class ActionExecutedContext : FilterContext
{
public virtual bool Canceled { get; set; }
public virtual object Controller { get; }
public virtual Exception Exception { get; set; }
public virtual ExceptionDispatchInfo ExceptionDispatchInfo { get; set; }
public virtual bool ExceptionHandled { get; set; }
public virtual IActionResult Result { get; set; }
}
同樣,繼承自FilterContext,暫且忽略。
- Canceled 表示是否被設置短路
- Controller 處理請求的控制器
- Exception 執行過程中是否發生異常,如果有異常則 有值,否則為Null
- ExceptionHandled 異常是否被處理
- Result 此處對Result進行修改不會屏蔽執行的ActionResult,但是可以向用戶隱藏對應的實現
1.2.3 ResultExecutingContext
這是在Result渲染之前執行的上下文,這時候Action已經執行完畢,正準備渲染Result:
public class ResultExecutingContext : FilterContext
{
public virtual bool Cancel { get; set; }
public virtual object Controller { get; }
public virtual IActionResult Result { get; set; }
}
- Cancel 取消當前結果執行以及後續篩選器的執行
- Controller 控制器
- Result 處理結果
1.2.4 ResultExecutedContext
Result已經執行完成了,獲取執行結果上下文:
public class ResultExecutedContext : FilterContext
{
public virtual bool Canceled { get; set; }
public virtual object Controller { get; }
public virtual Exception Exception { get; set; }
public virtual ExceptionDispatchInfo ExceptionDispatchInfo { get; set; }
public virtual bool ExceptionHandled { get; set; }
public virtual IActionResult Result { get; }
}
這個類與 ActionExecutedContext類似,就不做介紹了。
1.2.5 FilterContext
在上面的四個上下文都繼承自 FilterContext,那麼我們來看一下FilterContext中有哪些屬性或者方法:
public abstract class FilterContext : ActionContext
{
public virtual IList<IFilterMetadata> Filters { get; }
public TMetadata FindEffectivePolicy<TMetadata>() where TMetadata : IFilterMetadata;
}
可以看到FilterContext繼承了另一個ActionContext的類。小夥伴們應該對這個類要有一定的概念,這個類是Action的上下文類。它完整存在於一個Action的生命周期,所以有時候可以通過ActionContext進行Action級的數據傳遞(不推薦)。
那麼,繼續讓我們回過頭來看看ActionContext里有什麼:
public class ActionContext
{
public ActionDescriptor ActionDescriptor { get; set; }
public HttpContext HttpContext { get; set; }
public ModelStateDictionary ModelState { get; }
public RouteData RouteData { get; set; }
}
- ActionDescriptor 執行的Action描述信息,包括Action的显示名稱、一些參數等,具體用到的時候,再為大夥詳細說
- HttpContext 可以通過這個屬性獲取此次請求的Request和Response對象
- ModelState 模型校驗信息, 這部分在後續再為小夥伴們細說
- RouteData 路由信息,asp.net core 在處理請求時解析出來的路由信息,包括在程序中修改的路由信息
2. 使用ActionFilter
在《【asp.net core 系列】9 實戰之 UnitOfWork以及自定義代碼生成》也就是上一篇中,介紹到了ActionFilter與普通特性類一致,可以通過標註控制器然後啟用該ActionFilter。
因為大多數情況下,一個ActionFilter並不會僅僅局限於一個控制器,而是應用於多個控制器。所以這時候,我們通常會設置一個基礎控制器,在這個控制器上進行標註,然後讓子類繼承這個控制器。通過這種方式來實現一次聲明多次使用。
當然,在asp.net core 中添加了另外的一種使用ActionFilter的方式,Setup.cs中
public void ConfigureServices(IServiceCollection services)
{
services.AddControllersWithViews();
}
默認是這樣的,我們可以通過設置參數來添加一個全局應用的Filter,例如說我們上一篇中創建的 UnitOfWorkFilterAttribute:
services.AddControllersWithViews(options=>
{
options.Filters.Add<UnitOfWorkFilterAttribute>();
});
通過這種方式可以啟用一個全局ActionFilter。如果需要使用asp.net core的默認依賴注入可以使用 AddService進行配置。(依賴注入的內容在後續會講解)。
3. 工具類生成
繼續上一篇遺留的內容:
public static void CreateEntityTypeConfig(Type type)
{
var targetNamespace = type.Namespace.Replace("Data.Models", "");
if (targetNamespace.StartsWith("."))
{
targetNamespace = targetNamespace.Remove(0);
}
var targetDir = Path.Combine(new[] { CurrentDirect, "Domain.Implements", "EntityConfigures" }.Concat(
targetNamespace.Split('.')).ToArray());
if (!Directory.Exists(targetDir))
{
Directory.CreateDirectory(targetDir);
}
var baseName = type.Name.Replace("Entity", "");
if (!string.IsNullOrEmpty(targetNamespace))
{
targetNamespace = $".{targetNamespace}";
}
var file = $"using {type.Namespace};" +
$"\r\nusing Microsoft.EntityFrameworkCore;" +
$"\r\nusing Microsoft.EntityFrameworkCore.Metadata.Builders;" +
$"\r\nnamespace Domain.Implements.EntityConfigures{targetNamespace}" +
"\r\n{" +
$"\r\n\tpublic class {baseName}Config : IEntityTypeConfiguration<{type.Name}>" +
"\r\n\t{" +
"\r\n\t\tpublic void Configure(EntityTypeBuilder<SysUser> builder)" +
"\r\n\t\t{" +
$"\r\n\t\t\tbuilder.ToTable(\"{baseName}\");" +
$"\r\n\t\t\tbuilder.HasKey(p => p.Id);" +
"\r\n\t\t}\r\n\t}\r\n}";
File.WriteAllText(Path.Combine(targetDir, $"{baseName}Config.cs"), file);
}
工具類其實本質上就是一次文件寫入的方法,本身沒什麼難度。
不過,這裏還有有個小問題,每次調用都會覆蓋原有的文件,還有就是這裏面有很多可以優化的地方,小夥伴們可以自己試試去優化一下,讓代碼更好看一點。
4 總結
到目前為止,實戰系列也有了幾篇,很多小夥伴問我能提供一下源碼嗎?當然,能呀。不過不是現在,容我留個謎底。當主要框架功能完成之後,我就會給小夥伴們發代碼的。
其實也是因為現在還沒個完整的,開放給小夥伴們也沒啥意義。當然了,跟着一塊敲,也是能實現的哈。關鍵地方的代碼都有。
更多內容煩請關注我的博客《高先生小屋》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司“嚨底家”!
※推薦評價好的iphone維修中心
※聚甘新