目錄
今天我們來聊聊“鏈表(Linked list)”這個數據結構。
在我們上一章中棧與隊列底層都是採用順序存儲的這種方式的,而今天要聊的鏈表則是採用鏈式存儲,鏈表可以說是繼數組之後第二種使用得最廣泛的通用數據結構了,可見其重要性!
相比,鏈表是一種稍微複雜一點的數據結構。對於初學者來說,掌握起來也要比數組稍難一些。這兩個非常基礎、非常常用的數據結構,我們常常將會放到一塊兒來比較。所以我們先來看,這兩者有什麼區別。數組需要一塊連續的內存空間來存儲,對內存的要求比較高。而鏈表恰恰相反,它並不需要一塊連續的內存空間,它通過“指針”將一組零散的內存塊串聯起來使用,鏈表結構五花八門,今天我重點給你介紹三種最常見的鏈表結構,它們分別是:單鏈表、雙向鏈表和循環鏈表。
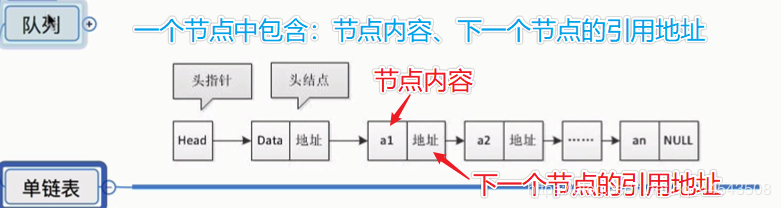
鏈表通過指針將一組零散的內存塊串聯在一起。其中,我們把內存塊稱為鏈表的“結點”。為了將所有的結點串起來,每個鏈表的結點除了存儲數據之外,還需要記錄鏈上的下一個結點的地址。而尾結點特殊的地方是:指針不是指向下一個結點,而是指向一個空地址NULL,表示這是鏈表上最後一個結點。
@
單鏈表
package demo2;
//一個節點
public class Node {
//節點內容
int data;
//下一個節點
Node next;
public Node(int data) {
this.data=data;
}
//為節點追回節點
public Node append(Node node) {
//當前節點
Node currentNode = this;
//循環向後找
while(true) {
//取出下一個節點
Node nextNode = currentNode.next;
//如果下一個節點為null,當前節點已經是最後一個節點
if(nextNode==null) {
break;
}
//賦給當前節點
currentNode = nextNode;
}
//把需要追回的節點追加為找到的當前節點的下一個節點
currentNode.next=node;
return this;
}
//插入一個節點做為當前節點的下一個節點
public void after(Node node) {
//取出下一個節點,作為下下一個節點
Node nextNext = next;
//把新節點作為當前節點的下一個節點
this.next=node;
//把下下一個節點設置為新節點的下一個節點
node.next=nextNext;
}
//显示所有節點信息
public void show() {
Node currentNode = this;
while(true) {
System.out.print(currentNode.data+" ");
//取出下一個節點
currentNode=currentNode.next;
//如果是最後一個節點
if(currentNode==null) {
break;
}
}
System.out.println();
}
//刪除下一個節點
public void removeNext() {
//取出下下一個節點
Node newNext = next.next;
//把下下一個節點設置為當前節點的下一個節點。
this.next=newNext;
}
//獲取下一個節點
public Node next() {
return this.next;
}
//獲取節點中的數據
public int getData() {
return this.data;
}
//當前節點是否是最後一個節點
public boolean isLast() {
return next==null;
}
}
單鏈表測試類
package demo2.test;
import demo2.Node;
public class TestNode {
public static void main(String[] args) {
//創建節點
Node n1 = new Node(1);
Node n2 = new Node(2);
Node n3 = new Node(3);
//追加節點
n1.append(n2).append(n3).append(new Node(4));
//取出下一個節點的數據
// System.out.println(n1.next().next().next().getData());
//判斷節點是否為最後一個節點
// System.out.println(n1.isLast());
// System.out.println(n1.next().next().next().isLast());
//显示所有節點內容
n1.show();
//刪除一個節點
// n1.next().removeNext();
//显示所有節點內容
// n1.show();
//插入一個新節點
Node node = new Node(5);
n1.next().after(node);
n1.show();
}
}鏈表要想隨機訪問第k個元素,就沒有數組那麼高效了。因為鏈表中的數據並非連續存儲的,所以無法像數組那樣,根據首地址和下標,通過尋址公式就能直接計算出對應的內存地址,而是需要根據指針一個結點一個結點地依次遍歷,直到找到相應的結點。
你可以把鏈表想象成一個隊伍,隊伍中的每個人都只知道自己後面的人是誰,所以當我們希望知道排在第k位的人是誰的時候,我們就需要從第一個人開始,一個一個地往下數。所以,鏈表隨機訪問的性能沒有數組好,需要O(n)的時間複雜度。
雙向鏈表
接下來我們再來看一個稍微複雜的,在實際的軟件開發中,也更加常用的鏈表結構:雙向鏈表。單向鏈表只有一個方向,結點只有一個後繼指針next指向後面的結點。而雙向鏈表,顧名思義,它支持兩個方向,每個結點不止有一個後繼指針next指向後面的結點,還有一個前驅指針prev指向前面的結點。
public class DoubleNode {
//上一個節點
DoubleNode pre=this;
//下一個節點
DoubleNode next=this;
//節點數據
int data;
public DoubleNode(int data) {
this.data=data;
}
//增節點
public void after(DoubleNode node) {
//原來的下一個節點
DoubleNode nextNext = next;
//把新節點做為當前節點的下一個節點
this.next=node;
//把當前節點做新節點的前一個節點
node.pre=this;
//讓原來的下一個節點作新節點的下一個節點
node.next=nextNext;
//讓原來的下一個節點的上一個節點為新節點
nextNext.pre=node;
}
//下一個節點
public DoubleNode next() {
return this.next;
}
//上一個節點
public DoubleNode pre() {
return this.pre;
}
//獲取數據
public int getData() {
return this.data;
}
}
雙向鏈表測試
import demo2.DoubleNode;
public class TestDoubleNode {
public static void main(String[] args) {
//創建節點
DoubleNode n1 = new DoubleNode(1);
DoubleNode n2 = new DoubleNode(2);
DoubleNode n3 = new DoubleNode(3);
//追加節點
n1.after(n2);
n2.after(n3);
//查看上一個,自己,下一個節點的內容
System.out.println(n2.pre().getData());
System.out.println(n2.getData());
System.out.println(n2.next().getData());
System.out.println(n3.next().getData());
System.out.println(n1.pre().getData());
}
}
單鏈表VS雙向鏈表
如果我們希望在鏈表的某個指定結點前面插入一個結點或者刪除操作,雙向鏈表比單鏈表有很大的優勢。雙向鏈表可以在O(1)時間複雜度搞定,而單向鏈表需要O(n)的時間複雜度,除了插入、刪除操作有優勢之外,對於一個有序鏈表,雙向鏈表的按值查詢的效率也要比單鏈表高一些。因為,我們可以記錄上次查找的位置p,每次查詢時,根據要查找的值與p的大小關係,決定是往前還是往後查找,所以平均只需要查找一半的數據。
現在,你有沒有覺得雙向鏈表要比單鏈表更加高效呢?這就是為什麼在實際的軟件開發中,雙向鏈表儘管比較費內存,但還是比單鏈表的應用更加廣泛的原因。如果你熟悉Java語言,你肯定用過LinkedHashMap這個容器。如果你深入研究LinkedHashMap的實現原理,就會發現其中就用到了雙向鏈表這種數據結構。實際上,這裡有一個更加重要的知識點需要你掌握,那就是用空間換時間的設計思想。當內存空間充足的時候,如果我們更加追求代碼的執行速度,我們就可以選擇空間複雜度相對較高、但時間複雜度相對很低的算法或者數據結構。相反,如果內存比較緊缺,比如代碼跑在手機或者單片機上,這個時候,就要反過來用時間換空間的設計思路。
循環鏈表
循環鏈表是一種特殊的單鏈表。實際上,循環鏈表也很簡單。它跟單鏈表唯一的區別就在尾結點。我們知道,單鏈表的尾結點指針指向空地址,表示這就是最後的結點了。而循環鏈表的尾結點指針是指向鏈表的頭結點。和單鏈表相比,循環鏈表的優點是從鏈尾到鏈頭比較方便。當要處理的數據具有環型結構特點時,就特別適合採用循環鏈表。比如著名的約瑟夫問題。儘管用單鏈表也可以實現,但是用循環鏈表實現的話,代碼就會簡潔很多。
package demo2;
//一個節點
public class LoopNode {
//節點內容
int data;
//下一個節點
LoopNode next=this;
public LoopNode(int data) {
this.data=data;
}
//插入一個節點做為當前節點的下一個節點
public void after(LoopNode node) {
//取出下一個節點,作為下下一個節點
LoopNode nextNext = next;
//把新節點作為當前節點的下一個節點
this.next=node;
//把下下一個節點設置為新節點的下一個節點
node.next=nextNext;
}
//刪除下一個節點
public void removeNext() {
//取出下下一個節點
LoopNode newNext = next.next;
//把下下一個節點設置為當前節點的下一個節點。
this.next=newNext;
}
//獲取下一個節點
public LoopNode next() {
return this.next;
}
//獲取節點中的數據
public int getData() {
return this.data;
}
}
循環鏈表測試
package demo2.test;
import demo2.LoopNode;
public class TestLoopNode {
public static void main(String[] args) {
LoopNode n1 = new LoopNode(1);
LoopNode n2 = new LoopNode(2);
LoopNode n3 = new LoopNode(3);
LoopNode n4 = new LoopNode(4);
//增加節點
n1.after(n2);
n2.after(n3);
n3.after(n4);
System.out.println(n1.next().getData());
System.out.println(n2.next().getData());
System.out.println(n3.next().getData());
System.out.println(n4.next().getData());
}
}
最後,我們再對比一下數組,數組的缺點是大小固定,一經聲明就要佔用整塊連續內存空間。如果聲明的數組過大,系統可能沒有足夠的連續內存空間分配給它,導致“內存不足(out of memory)”。如果聲明的數組過小,則可能出現不夠用的情況。這時只能再申請一個更大的內存空間,把原數組拷貝進去,非常費時。鏈表本身沒有大小的限制,天然地支持動態擴容,我覺得這也是它與數組最大的區別。
你可能會說,我們Java中的ArrayList容器,也可以支持動態擴容啊?事實上當我們往支持動態擴容的數組中插入一個數據時,如果數組中沒有空閑空間了,就會申請一個更大的空間,將數據拷貝過去,而數據拷貝的操作是非常耗時的。
我舉一個稍微極端的例子。如果我們用ArrayList存儲了了1GB大小的數據,這個時候已經沒有空閑空間了,當我們再插入數據的時候,ArrayList會申請一個1.5GB大小的存儲空間,並且把原來那1GB的數據拷貝到新申請的空間上。聽起來是不是就很耗時?
除此之外,如果你的代碼對內存的使用非常苛刻,那數組就更適合你。因為鏈表中的每個結點都需要消耗額外的存儲空間去存儲一份指向下一個結點的指針,所以內存消耗會翻倍。而且,對鏈表進行頻繁的插入、刪除操作,還會導致頻繁的內存申請和釋放,容易造成內存碎片,如果是Java語言,就有可能會導致頻繁的GC(Garbage Collection,垃圾回收)。
所以,在我們實際的開發中,針對不同類型的項目,要根據具體情況,權衡究竟是選擇數組還是鏈表!
如果本文對你有一點點幫助,那麼請點個讚唄,謝謝~
最後,若有不足或者不正之處,歡迎指正批評,感激不盡!如果有疑問歡迎留言,絕對第一時間回復!
歡迎各位關注我的公眾號,一起探討技術,嚮往技術,追求技術,說好了來了就是盆友喔…
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?