環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※聚甘新
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
 |
特斯拉執行長馬斯克(Elon Musk)再發豪語,宣稱旗下電動車在2017年底,就能具備自動駕駛功能,一路從洛杉磯開到紐約。Seeking Alpha網站認為,特斯拉有信心在短時間內開發出自動駕駛系統,得歸功於Nvidia。
Seeking Alpha 24日報導,特斯拉原本與以色列商Mobileye合作,採用EyeQ3晶片,旗下電動車具備自動緊急煞車、碰撞警示、維持車道等功能,不過特斯拉和Mobileye分手,改採Nvidia系統之後,原有的先進駕駛輔助系統(ADAS)全部泡湯。
既然如此,特斯拉為何敢放話明年底就有自動駕駛?文章稱,Nvidia研發出革命性的自駕系統,該公司蒐集人類實際開車影片,搭配方向盤的操控角度,用來訓練類神經網路(Neural Network、NN);也就是說,每一格駕駛畫面,都有正確答案,讓NN學會打方向盤的角度;再搭配偏離車道時,如何修正重回線道的資料等,讓電腦掌握開車技巧。
這個方式的特點在於,NN能「全面」掌握駕駛技術。在此之前,業者多把自駕細分成多個項目,如辨識物體、道路等,接著再加以結合,無法確認電腦是否真的完全抓到開車訣竅。Nvidia這套新方法簡單快速,不到一年就有極佳成效,汽車能在多種狀況下自動駕駛(影片見此),如果以此一系統為基礎,應能迅速讓自駕功力大增。文章猜測,特斯拉正是相中此點,才捨棄舊愛Mobileye、改和Nvidia合作。
文章指稱,特斯拉運用Nvidia技術開發出自駕車模型,能從人類實際開車情況和反應中學習,加快研發進展。然而該文警告,問題是機器學習不知道什麼時候會碰上瓶頸,以為NN能就此一帆風順學會開車,過於樂觀。自駕車門檻極高,NN學習過程或許會陷入停滯,難以達標。該文指出,目前谷歌自駕車的開車技術仍不如人類,特斯拉更是遠遠落後。
BusinessInsider報導,特斯拉(Tesla Motors Inc.)執行長(CEO)馬斯克(Elon Musk)19日在記者會上表示,2017年底特斯拉旗下車種將可啟動無人駕駛模式、自洛杉磯開到紐約時代廣場。馬斯克今年初曾表示,特斯拉自駕車將可在2018年橫越美國。他在19日的媒體發表會上提到,特斯拉自駕車的安全性比人類駕駛要高出一倍或更多,硬體基礎已經都準備妥當,只待軟體以及相關法規到位。
特斯拉10月19日發布新聞稿宣布,即日起出廠的旗下所有電動車(包括Model 3)都將配備全自動駕駛硬體配件。特斯拉指出,自駕功能將令車輛安全性大幅提高。
特斯拉新出廠車款配備8個鏡頭、具有360度視角,可視距離達250公尺;12個新版超音波感測器將可進一步提升車輛視覺能力、使得軟硬物件偵測距離較前一代提升一倍。具有增強處理效能的前向雷達可讓車輛掌握前方的車輛動向以及大雨、霧、灰塵等路況。
(本文由授權提供。照片來源:shared by CC 2.0)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※聚甘新
一般的電動車用電池約有7~8 年的使用壽命,但因含有鋰、硫酸等重金屬,若無妥善回收處理,將有環境汙染之虞。香港政府所引入的首批電動車之電池屆臨退役,專家呼籲政府盡速制訂回收辦法,以避免更嚴重的環境破壞。
香港《蘋果日報》報導,香港在豁免電動車首次登記稅後,電動車數量急速從2010年的100輛以下成長到今年8月的6,167輛,其中以Tesla和Volkswagen最受歡迎。以一般電動車用電池約7年的平均壽命來看,香港首批電動車的舊電池已屆臨汰役,但香港目前仍無回收制度;若廢電池隨意丟棄,所造成的重金屬汙染恐怕較傳統柴油車和汽油車更嚴重,完全背離環保的美意。
香港汽車會副會長李耀培表示,車用電池的儲電量若降低到70%,就可能影響電動車行動速度,甚至造成熄火,進而影響行車安全,因此在此階段就會汰役換新。不過,這也意味著汰役的車用電池其實仍有70%的蓄電量,經妥善處理後可進行二次運用。
報導指出,香港過去會將這類廢電池交給有牌照的化學廢物處置設施進行初步處理,之後再出口到海外回收。但李耀培表示,這只是把汙染丟出香港,並沒有解決問題。他呼籲政府應制定長遠的回收機制,或可參考英國、歐洲等國家將汰役的電動車用電池改製為風力、太陽能儲能設備,更能有效利用電池,且也有助環保。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※聚甘新
首先是個人的一些閱讀源碼的小技巧,不一定適用每個人,可以直接跳過。
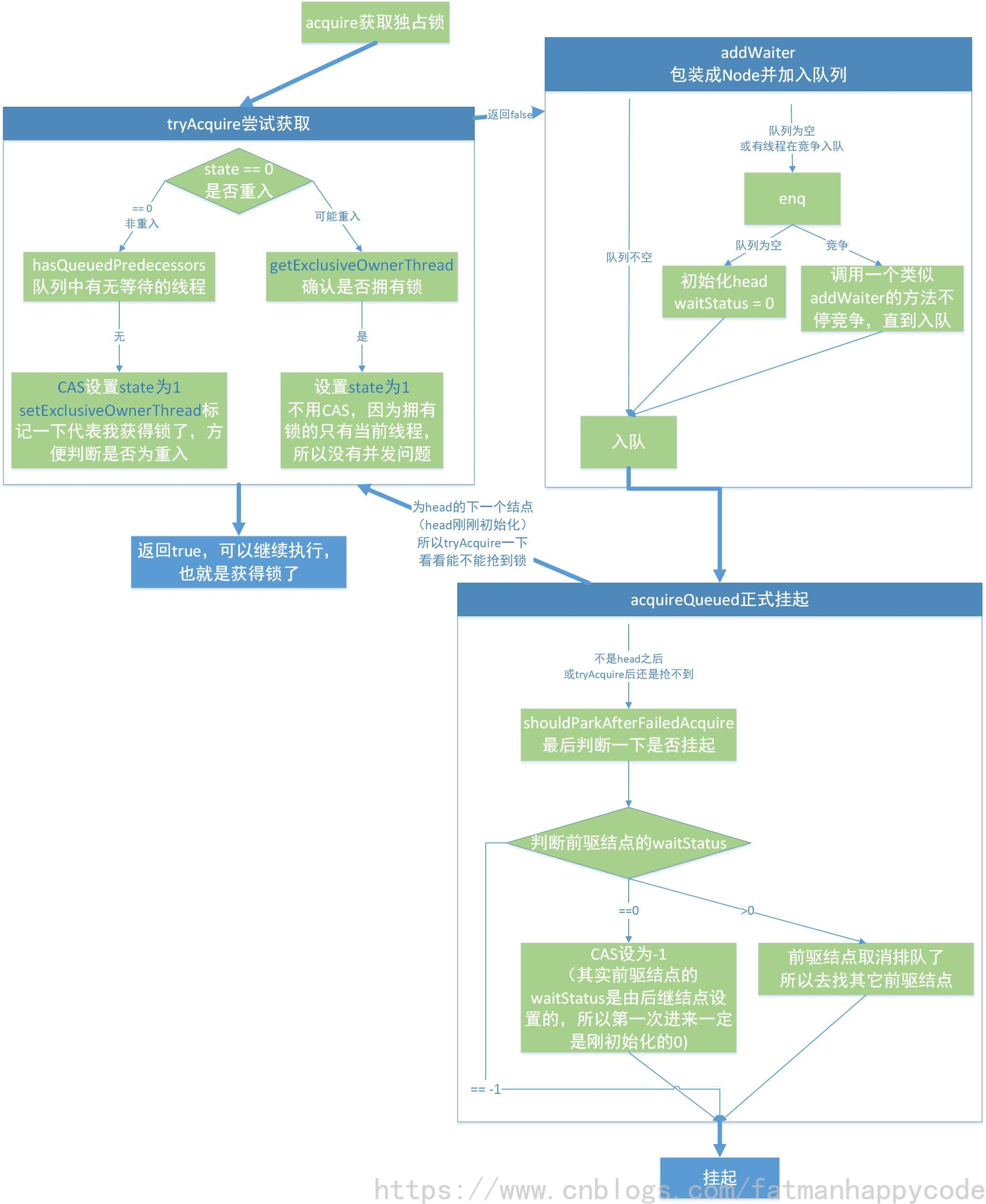
個人覺得大多數情況下跟着一篇優秀的博客配合著看就足夠了,之後再自己寫博客總結一遍加深印象,畫一下流程圖基本都能理順。(圖為學AQS時本人畫的獲取獨佔鎖流程圖)
配合idea看類之間的關係(ctrl+alt+shift+u)的功能也能更好的理解整個項目的整體架構。因為很多源碼其實並不是真的複雜,只是為了擴展性優雅簡潔等原因建立了大量的接口和抽象類以及各種設計模式,使得項目看起來很龐大很複雜,藉助這個功能有利於你排除掉一些你暫時不想去關心的設計邏輯。知道那個部分才是最核心的邏輯,專註於去看核心代碼。
但是如果你看的博客裏面剛好缺少了一部分你想看的內容,而你又找不到資料,需要自己去看,又或者你想看的源碼一點點資料都找不到的情況下想去看源碼。
這個時候比較有作用的就是註釋,源碼中的註釋看不懂也沒關係,放到百度翻譯里基本也能理解大概的意思。仔細看完方法或類的註釋之後你就理解了接下來這個類大致是在做什麼,之後讀它的源碼會通順很多,有一些方法或類甚至在你看完註釋之後就已經能知道你想看的內容了,已經沒有需要繼續往下讀了。
不僅僅是類或方法的註釋文檔,方法中代碼的註釋也很重要,基本上稍微複雜一點點的代碼,甚至有時候加個鎖,作者都會認認真真的寫一行註釋解釋自己這麼做的原因。
還有一點是適當忽略一些不重要的細節,這個主要看你想看什麼,一般我們看第一遍大多數只是想知道大致的流程是什麼樣的,所以可以適當忽略併發邏輯和一些方法里的內容(看一眼註釋先知道這個方法會做什麼的就夠了)。第一遍大致知道流程,第二第三遍再去深究細節和併發邏輯等。
多用debug,很多時候源碼走的路線會和你想象中的有很大不同,你以為會進入這個if,其實他偷偷進了else。
經常看到利用短路機制的代碼,這裏以 AbstractQueuedSynchronizer 的 acquire 方法為例子,只有 tryAcquire 獲取鎖失敗, !tryAcquire 返回 true 時才會執行後面進入阻塞隊列並掛起的方法,如果獲取鎖成功了,根據短路機制自然不會執行入隊方法。
// AbstractQueuedSynchronizer.acquire(int arg) if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) { selfInterrupt(); }
ReentrantReadWriteLock的這段代碼里將AQS的state一分為二給共享鎖和獨佔鎖使用,個人覺得這種設計非常巧妙:
// ReentrantReadWriteLock abstract static class Sync extends AbstractQueuedSynchronizer { // 下面這塊說的就是將 state 一分為二,高 16 位用於共享模式,低16位用於獨佔模式 static final int SHARED_SHIFT = 16; static final int SHARED_UNIT = (1 << SHARED_SHIFT); static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1; static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1; // 取 c 的高 16 位值,代表讀鎖的獲取次數(包括重入) static int sharedCount(int c) { return c >>> SHARED_SHIFT; } // 取 c 的低 16 位值,代表寫鎖的重入次數,因為寫鎖是獨佔模式 static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
忘記在哪裡看到的了,翻了一下瀏覽記錄應該是在Java AIO部分的源碼里,這種寫法感覺很簡潔就記下來了,不過可讀性似乎不太高,特別是第一種乍一看還以為是lambda表達式
意思等同於 for (int i = 0; i < n; i++) ,但是 while(n– > 0) 和 while (–n >= 0) 這種寫法會直接改變n的值
在很多jdk的源碼中我們都可以看到 xx = null // help GC 這樣的代碼,用來置空引用,幫助jvm完成gc。具體可以了解可達性算法。
這裏我們以LinkList為例子:
// LinkList 的方法 private E unlinkFirst(Node<E> f) { final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; }
在很多地方都會使用位移來進行運算,平時寫算法題也一樣很多人都這麼使用,下面以 ArrayList 的 grow 方法為例子,這裏通過右移1位使 oldCapacity 變為原來的0.5倍,之後加上它本身得到 newCapacity
// ArrayList.grow(int minCapacity) private void grow(int minCapacity) { // . . . . . . int newCapacity = oldCapacity + (oldCapacity >> 1);//newCapacity就是1.5倍的oldCapacity // . . . . . . }
以上是我目前的水平所能總結出來的,後續學到其他的會繼續更新,如果大家有什麼補充的請告訴我
最後慣例附一圖:(根本不存在想雇傭我的地方( ´_ゝ`).jpg)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※聚甘新
在開始本文之前,真的好想做個問卷調查,到底有多少人和我一樣,對 JsonConvert 的認識只局限在 SerializeObject 和 DeserializeObject 這兩個方法上(┬_┬), 這樣我也好結伴同行,不再孤單落魄,或許是這兩個方法基本上能夠解決工作中 80% 的場景,對於我來說確實是這樣,但隨着編碼的延續,終究還是會遇到那剩下的 20% ,所以呀。。。
我的場景是這樣的:前段時間寫業務代碼的時候,我有一個自定義的客戶算法類型的Model,這個Model中有這種算法類型下的客戶群以及Report統計信息,還用了 HashSet 記錄了該類型下的 CustomerID集合,為了方便講述,我把Model簡化如下:
class CustomerAlgorithmModel
{
public string DisplayName { get; set; }
public int CustomerType { get; set; }
public ReprotModel Report { get; set; }
public HashSet<int> CustomerIDHash { get; set; }
}
class ReprotModel
{
public int TotalCustomerCount { get; set; }
public int TotalTradeCount { get; set; }
}
那有意思的就來了,我個人是有記日誌的癖好,就想着以後不會出現死無對證的情況,然後就理所當然的使用 JsonConvert.SerializeObject, 這一下就出問題了,日誌送入到了 ElasticSearch ,然後通過 Kibana 查不出來,為啥呢? 看完上面的 Model 我想你也猜到了原因,json體太大了哈,好歹 CustomerIDHash 中也有幾十萬個撒,這一下全導出成json了,這 size 還能小嗎? 要不我寫段代碼看一看。
static void Main(string[] args)
{
var algorithModel = new CustomerAlgorithmModel()
{
CustomerType = 1,
DisplayName = "",
Report = new ReprotModel()
{
TotalCustomerCount = 1000,
TotalTradeCount = 50
},
CustomerIDHash = new HashSet<int>(Enumerable.Range(1, 500000))
};
var json = JsonConvert.SerializeObject(algorithModel);
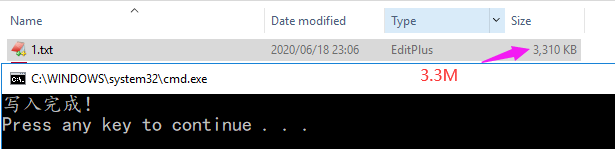
File.WriteAllText("1.txt", json, Encoding.UTF8);
Console.WriteLine("寫入完成!");
}
可以看到,僅一個json就 3.3M,這樣的記錄多來幾打后,在 kibana 上一檢索,瀏覽器就卡的要死,其實 CustomerIDHash 這個字段對我來說是可有可無的,就算存下來了也沒啥大用,所以需求就來了,如何屏蔽掉 CustomerIDHash。
有問題就網上搜啊,這一搜馬上就有人告訴你可以使用 JsonIgnoreAttribute 忽略特性,加好這個特性後繼續跑一下程序。
[Newtonsoft.Json.JsonIgnore]
public HashSet<int> CustomerIDHash { get; set; }
太好了,終於搞定了,但是靜下心來想一想,總感覺心裏有那麼一點不舒服,為什麼這麼說,一旦你給這個 CustomerIDHash 套上了 JsonIgnore ,這就意味着它在 JsonConvet 的世界中從此消失,也不管是誰在使用這個Model, 但這並不是我的初衷,我的初衷僅僅是為了在記錄日誌的時候踢掉 CustomerIDHash,可千萬不要影響在其他場景下的使用哈,現在這種做法就會給自己,給別人挖坑,埋下了不可預知的bug,我想你應該明白我的意思,還得繼續尋找下一個方案。
真的,Newtonsoft 太強大了,我都想寫一個專題好好彌補彌補我的知識盲區,其實在這個場景中不就是想把 HashSet<int> 給屏蔽掉嘛,Newtonsoft 中專門提供了一個針對特定類型的自定義處理類,接下來我就寫一段:
/// <summary>
/// 自定義一個 針對 HashSet<int> 的轉換類
/// </summary>
public class HashSetConverter : Newtonsoft.Json.JsonConverter<HashSet<int>>
{
public override HashSet<int> ReadJson(JsonReader reader, Type objectType, HashSet<int> existingValue, bool hasExistingValue, JsonSerializer serializer)
{
return existingValue;
}
public override void WriteJson(JsonWriter writer, HashSet<int> value, JsonSerializer serializer)
{
writer.WriteNull();
}
}
就是這麼簡單,然後就可以在 SerializeObject 的時候指定下自定義的 HashSetConverter 即可,然後再將程序跑起來看一下。
var json = JsonConvert.SerializeObject(algorithModel, Formatting.Indented, new HashSetConverter());
從圖中看,貌似也是解決了,但我突然發現自己要鑽牛角尖了,如果我的實體中又來了一個頂級優質客戶群的 TopNCustomerIDHash,但因為這個CustomerID 比較少,我希望在 Json 中能保留下來,然後就是踢掉的那個 CustomerIDHash 我要保留 CustomerIDHash.Length ,哈哈,搞事情哈,那接下來怎麼解決呢?
class CustomerAlgorithmModel
{
public HashSet<int> CustomerIDHash { get; set; }
// topN 優質客戶群
public HashSet<int> TopNCustomerIDHash { get; set; }
}
public override void WriteJson(JsonWriter writer, HashSet<int> value, JsonSerializer serializer)
{
if (writer.Path == "TopNCustomerIDHash")
{
writer.WriteStartArray();
foreach (var item in value)
{
writer.WriteValue(item);
}
writer.WriteEndArray();
}
else
{
writer.WriteValue(value.Count);
}
}
var algorithModel = new CustomerAlgorithmModel()
{
CustomerType = 1,
DisplayName = "",
Report = new ReprotModel()
{
TotalCustomerCount = 1000,
TotalTradeCount = 50
},
CustomerIDHash = new HashSet<int>(Enumerable.Range(1, 500000)),
TopNCustomerIDHash = new HashSet<int>(Enumerable.Range(1, 10)),
};
三塊都搞定后就可以把程序跑起來了,如下圖:
貌似鑽牛角尖的問題是解決了,既然鑽牛角尖肯定要各種鄙視,比如這裏的 ReportModel 我是不需要的,CustomerType 我也是不需要的,我僅僅需要看一下 DisplayName 和 TotalCustomerCount 這兩個字段就可以了, 那這個要怎麼解決呢?
確實很多時候記日誌,就是為了跟蹤 Model 中你特別關心的那幾個字段,所以摻雜了多餘的字段確實也是沒必要的,這裏可以用匿名來解決,我就來寫一段代碼:
var json = JsonConvert.SerializeObject(new
{
algorithModel.DisplayName,
algorithModel.Report.TotalCustomerCount
}, Formatting.Indented);
雖然阻擊了幾個回合,但同時也發現了 Newtonsoft 中還有特別多的未挖掘功能,真的需要好好研究研究,源碼已下好,接下來準備做個系列來解剖一下,值得一提的是 .Net中已自帶了 System.Text.Json.JsonSerializer 類,目前來看功能還不算太豐富,簡單用用還是可以的,本篇就說到這裏,希望對您有幫助。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※聚甘新
VUE+Element 前端是一個純粹的前端處理,前面介紹了很多都是Vue+Element開發的基礎,從本章隨筆開始,就需要進入深水區了,需要結合ABP框架使用(如果不知道,請自行補習一下我的隨筆:ABP框架使用),ABP框架作為後端,是一個非常不錯的技術方向,但是前端再使用Asp.NET 進行開發的話,雖然會快捷一點,不過可能顯得有點累贅了,因此BS的前端選項採用Vue+Element來做管理(後續可能會視情況加入Vue+AntDesign),CS前端我已經完成了使用Winform+ABP的模式了。本篇隨筆主要介紹Vue+Element+ABP的整合方式,先從登錄開始介紹。
ABP是ASP.NET Boilerplate的簡稱,ABP是一個開源且文檔友好的應用程序框架。ABP不僅僅是一個框架,它還提供了一個最徍實踐的基於領域驅動設計(DDD)的體繫結構模型。
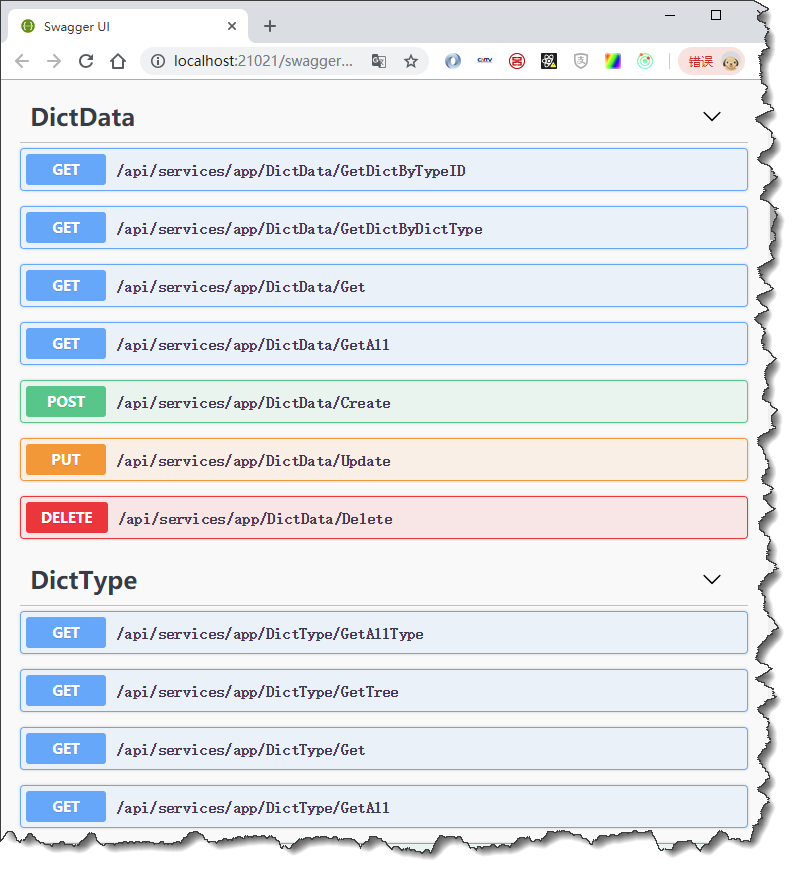
啟動Host的項目,我們可以看到Swagger的管理界面如下所示。
我們登錄獲得用戶訪問令牌token后,測試字典類型或者字典數據的接口,才能返迴響應的數據。
我根據ABP後端項目之間的關係,整理了一個架構的圖形。
應用服務層是整個ABP框架的靈魂所在,對內協同倉儲對象實現數據的處理,對外配合Web.Core、Web.Host項目提供Web API的服務,而Web.Core、Web.Host項目幾乎不需要進行修改,因此應用服務層就是一個非常關鍵的部分,需要考慮對用戶登錄的驗證、接口權限的認證、以及對審計日誌的記錄處理,以及異常的跟蹤和傳遞,基本上應用服務層就是一個大內總管的角色,重要性不言而喻。
對於通過Winform方式展示界面,以Web API方式和後端的ABP的Web API服務進行數據交互,是我們之前已經完成的項目,項目界面如下所示。
主體框架界面採用的是基於菜單的動態生成,以及多文檔的界面布局,具有非常好的美觀性和易用性。
左側的功能樹列表和頂部的菜單模塊,可以根據角色擁有的權限進行動態構建,不同的角色具有不同的菜單功能點,如下是測試用戶登錄后具有的界面。
之前我們開發完成的Vue+Element的前端項目,默認已經具有登錄系統的功能,不過登錄是採用mock方式進行驗證並處理的,本篇隨筆介紹是基於實際的ABP項目進行用戶身份的登錄處理,這個也是開發其他接口展示數據的開始步驟,必須通過真實的用戶身份登錄後台,獲得對應的token令牌,才能進行下一步接口的開發工作。
例如對應登錄界面上,界面效果如下所示。
在用戶登錄界面中,我們處理用戶登錄邏輯代碼如下所示。
// 處理登錄事件 handleLogin() { this.$refs.loginForm.validate(valid => { if (valid) { this.loading = true this.$store .dispatch('user/login', this.loginForm) .then(() => { this.$router.push({ path: this.redirect || '/' }) this.loading = false }) .catch(() => { this.loading = false }) } else { console.log('error submit!!') return false } }) }
這裏主要就是調用Store模塊裏面的用戶Action處理操作。
例如對於用戶store模塊裏面的登錄Action函數如下所示。
const actions = { // user login login({ commit }, userInfo) { const { username, password } = userInfo return new Promise((resolve, reject) => { login({ username: username.trim(), password: password }).then(response => { const { result } = response // 獲取返回對象的 result var token = result.accessToken var userId = result.userId // 記錄令牌和用戶Id commit('SET_TOKEN', token) commit('SET_USERID', userId) // 存儲cookie setToken(token) setUserId(userId) resolve() }).catch(error => { reject(error) }) }) },
而其中 login({ username: username.trim(), password: password }) 操作,是通過API封裝處理的調用,使用前在Store模塊中先引入API模塊,如下所示。
import { login, logout, getInfo } from '@/api/user'
而其中 API模塊代碼如下所示。
export function login(data) { return request({ url: '/abp/TokenAuth/Authenticate', method: 'post', data: { UsernameOrEmailAddress: data.username, password: data.password } }) }
這裏我們用了一個/abp的前綴,用來給WebProxy的處理,實現地址的轉義,從而可以實現跨站的處理,讓前端調用外部地址就和調用本地地址一樣,無縫對接。
我們來看看vue.config.js裏面對於這個代理的轉義操作代碼。
而 http://localhost:21021/api 地址指向的項目,是我們本地使用ABP開發的一個後端Web API項目,我們可以通過地址 http://localhost:21021/swagger/index.html 進行接口的查看。
我們打開獲取授權令牌的Authenticate接口,查看它的接口定義內容
通過標註的1,2,我們可以看到這個接口的輸入參數和輸出JSON信息,從而為我們封裝Web API的調用提供很好的參考。
ABP框架統一返回的結果是result,這個result裏面才是返回對應的接口內容,如上面的輸出JSON信息裏面的定義。
所以在登陸返回結果后,我們要返回它的result對象,然後在進行數據的處理。
const { result } = response // 獲取返回對象的 result
然後通過result來訪問其他屬性即可。
var token = result.accessToken // 用戶令牌 var userId = result.userId // 用戶id
用戶登錄成功后,並獲取到對應的數據,我們就可以把必要的數據,如token和userid存儲在State和Cookie裏面了。
// 修改State對象,記錄令牌和用戶Id commit('SET_TOKEN', token) commit('SET_USERID', userId) // 存儲cookie setToken(token) setUserId(userId)
有了這些信息,我們就可以進一步獲取用戶的相關信息,如用戶名稱、介紹,包含角色列表和權限列表等內容了。
例如對應用戶信息獲取接口的ABP後端地址是 http://localhost:21021//api/services/app/User/Get
那麼我們前端就需要在API模塊裏面構建它的訪問地址(/abp/services/app/User/Get)和接口處理了。
export function getInfo(id) { return request({ url: '/abp/services/app/User/Get', method: 'get', params: { id } }) }
如上所示,在Store模塊里引入API模塊,如下所示。
import { login, logout, getInfo } from '@/api/user'
然後在Store模塊中封裝一個Action用來處理用戶信息的獲取的。
// 獲取用戶信息 getInfo({ commit, state }) { return new Promise((resolve, reject) => { getInfo(state.userid).then(response => { const { result } = response console.log(result) // 輸出測試 if (!result) { reject('Verification failed, please Login again.') } const { roles, roleNames, name, fullName } = result // 角色非空提醒處理 if (!roles || roles.length <= 0) { reject('getInfo: roles must be a non-null array!') } commit('SET_ROLES', { roles, roleNames }) commit('SET_NAME', name) // commit('SET_AVATAR', avatar) //可以動態設置頭像 commit('SET_INTRODUCTION', fullName) resolve(result) }).catch(error => { reject(error) }) }) },
Vue + Element前端項目的視圖、Store模塊、API模塊、Web API之間關係如下所示。
登錄后我們獲取用戶身份信息,在控制台中記錄返回對象信息,可以供參考,如下所示
有了token信息,我們就可以繼續其他接口的數據請求或者提交了,從而可以實現更多的管理功能了。
後續隨筆將基於ABP接口對接的基礎上進行更多界面功能的開發和整合。
列出一下前面幾篇隨筆的連接,供參考:
循序漸進VUE+Element 前端應用開發(1)— 開發環境的準備工作
循序漸進VUE+Element 前端應用開發(2)— Vuex中的API、Store和View的使用
循序漸進VUE+Element 前端應用開發(3)— 動態菜單和路由的關聯處理
循序漸進VUE+Element 前端應用開發(4)— 獲取後端數據及產品信息頁面的處理
循序漸進VUE+Element 前端應用開發(5)— 表格列表頁面的查詢,列表展示和字段轉義處理
循序漸進VUE+Element 前端應用開發(6)— 常規Element 界面組件的使用
循序漸進VUE+Element 前端應用開發(7)— 介紹一些常規的JS處理函數
循序漸進VUE+Element 前端應用開發(8)— 樹列表組件的使用
循序漸進VUE+Element 前端應用開發(9)— 界面語言國際化的處理
循序漸進VUE+Element 前端應用開發(11)— 圖標的維護和使用
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※聚甘新
Redis中List是通過ListNode構造的雙向鏈表。
特點:
1.雙端:獲取某個結點的前驅和後繼結點都是O(1)
2.無環:表頭的prev指針和表尾的next指針都指向NULL,對鏈表的訪問都是以NULL為終點
3.帶表頭指針和表尾指針:獲取表頭和表尾的複雜度都是O(1)
4.帶鏈表長度計數器:len屬性記錄,獲取鏈表長度O(1)
5.多態:鏈表結點使用void*指針來保存結點的值,並且可以通過鏈表結構的三個函數為結點值設置類型特定函數,所以鏈表可以保存各種不同類型的值
雙向鏈表詳解:https://www.cnblogs.com/vic-tory/p/13140779.html
中文網:http://redis.cn/commands.html#list
// listNode 雙端鏈表節點 typedef struct listNode { // 前置節點 struct listNode *prev; // 後置節點 struct listNode *next; // 節點的值 void *value; } listNode;
// list 雙端鏈表 typedef struct list { // 在c語言中,用結構體的方式來模擬對象是一種常見的手法 // 表頭節點 listNode *head; // 表尾節點 listNode *tail; // 節點值複製函數 void *(*dup)(void *ptr); // 節點值釋放函數 void(*free)(void *ptr); // 節點值對比函數 int(*match)(void *ptr, void *key); // 鏈表所包含的節點數量 unsigned long len; } list;
/* 作為宏實現的函數 */ //獲取長度 #define listLength(l) ((l)->len) //獲取頭節點 #define listFirst(l) ((l)->head) //獲取尾結點 #define listLast(l) ((l)->tail) //獲取前一個結點 #define listPrevNode(n) ((n)->prev) //獲取后一個結點 #define listNextNode(n) ((n)->next) //獲取結點的值 是一個void類型指針 #define listNodeValue(n) ((n)->value) /* 下面3個函數主要用來設置list結構中3個函數指針,參數m為method的意思 */ #define listSetDupMethod(l,m) ((l)->dup = (m)) #define listSetFreeMethod(l,m) ((l)->free = (m)) #define listSetMatchMethod(l,m) ((l)->match = (m)) /* 下面3個函數主要用來獲取list結構的單個函數指針 */ #define listGetDupMethod(l) ((l)->dup) #define listGetFree(l) ((l)->free) #define listGetMatchMethod(l) ((l)->match)
listCreate函數:創建一個不包含任何結點的新鏈表
/* * listCreate 創建一個新的鏈表 * * 創建成功返回鏈表,失敗返回 NULL 。 * * T = O(1) */ list *listCreate(void) { struct list *list; // 分配內存 if ((list = zmalloc(sizeof(*list))) == NULL) return NULL;//內存分配失敗則返回NULL // 初始化屬性 list->head = list->tail = NULL;//空鏈表 list->len = 0; list->dup = NULL; list->free = NULL; list->match = NULL; return list; }
listAddNodeHead函數:將一個包含給定值的新結點添加到給定鏈表的表頭
/* * listAddNodeHead 將一個包含有給定值指針 value 的新節點添加到鏈表的表頭 * * 如果為新節點分配內存出錯,那麼不執行任何動作,僅返回 NULL * * 如果執行成功,返回傳入的鏈表指針 * * T = O(1) */ list *listAddNodeHead(list *list, void *value) { listNode *node; // 為節點分配內存 if ((node = zmalloc(sizeof(*node))) == NULL) return NULL; // 保存值指針 node->value = value; // 添加節點到空鏈表 if (list->len == 0) { list->head = list->tail = node; //該結點的前驅和後繼都為NULL node->prev = node->next = NULL; } else { // 添加節點到非空鏈表 node->prev = NULL; node->next = list->head; list->head->prev = node; list->head = node; } // 更新鏈表節點數 list->len++; return list; }
listAddNodeTail函數:將一個包含給定值的新結點插入到給定鏈表的表尾
/* * listAddNodeTail 將一個包含有給定值指針 value 的新節點添加到鏈表的表尾 * * 如果為新節點分配內存出錯,那麼不執行任何動作,僅返回 NULL * * 如果執行成功,返回傳入的鏈表指針 * * T = O(1) */ list *listAddNodeTail(list *list, void *value) { listNode *node; // 為新節點分配內存 if ((node = zmalloc(sizeof(*node))) == NULL) return NULL; // 保存值指針 node->value = value; // 目標鏈表為空 if (list->len == 0) { list->head = list->tail = node; node->prev = node->next = NULL; }//目標鏈非空 else { node->prev = list->tail; node->next = NULL; list->tail->next = node; list->tail = node; } // 更新鏈表節點數 list->len++; return list; }
listInsertNode函數:將一個給定值的新結點插入到給定結點之前或者之後
/* * listInsertNode 創建一個包含值 value 的新節點,並將它插入到 old_node 的之前或之後 * * 如果 after 為 0 ,將新節點插入到 old_node 之前。 * 如果 after 為 1 ,將新節點插入到 old_node 之後。 * * T = O(1) */ list *listInsertNode(list *list, listNode *old_node, void *value, int after) { listNode *node; // 創建新節點 if ((node = zmalloc(sizeof(*node))) == NULL) return NULL; // 保存值 node->value = value; // 將新節點添加到給定節點之後 if (after) { node->prev = old_node; node->next = old_node->next; // 給定節點是原表尾節點 if (list->tail == old_node) { list->tail = node; } } // 將新節點添加到給定節點之前 else { node->next = old_node; node->prev = old_node->prev; // 給定節點是原表頭節點 if (list->head == old_node) { list->head = node; } } // 更新新節點的前置指針 if (node->prev != NULL) { node->prev->next = node; } // 更新新節點的後置指針 if (node->next != NULL) { node->next->prev = node; } // 更新鏈表節點數 list->len++; return list; }
listDelNode函數:從指定的list中刪除給定的結點
/* * listDelNode 從鏈表 list 中刪除給定節點 node * * 對節點私有值(private value of the node)的釋放工作由調用者進行。該函數一定會成功. * * T = O(1) */ void listDelNode(list *list, listNode *node) { // 調整前置節點的指針 if (node->prev) node->prev->next = node->next; else list->head = node->next; // 調整後置節點的指針 if (node->next) node->next->prev = node->prev; else list->tail = node->prev; // 釋放值 if (list->free) list->free(node->value); // 釋放節點 zfree(node); // 鏈表數減一 list->len--; }
listRelease函數:釋放給定鏈表以及鏈表中所有結點
/* * listRelease 釋放整個鏈表,以及鏈表中所有節點, 這個函數不可能會失敗. * * T = O(N) */ void listRelease(list *list) { unsigned long len; listNode *current, *next; // 指向頭指針 current = list->head; // 遍歷整個鏈表 len = list->len; while (len--) { next = current->next; // 如果有設置值釋放函數,那麼調用它 if (list->free) list->free(current->value); // 釋放節點結構 zfree(current); current = next; } // 釋放鏈表結構 zfree(list); }
該函數不僅釋放了表結點的內存還釋放了表結構的內存
listGetIterator函數:為給定鏈表創建一個迭代器
在講這個函數之前,我們應該先看看鏈表迭代器的結構:
// listIter 雙端鏈表迭代器 typedef struct listIter { // 當前迭代到的節點 listNode *next; // 迭代的方向 int direction; } listIter;
迭起器只有兩個重要的屬性:當前迭代到的結點,迭代的方向
下面再看看鏈表的迭代器創建函數
/* * listGetIterator 為給定鏈表創建一個迭代器, * 之後每次對這個迭代器調用 listNext 都返回被迭代到的鏈表節點,調用該函數不會失敗 * * direction 參數決定了迭代器的迭代方向: * AL_START_HEAD :從表頭向表尾迭代 * AL_START_TAIL :從表尾想表頭迭代 * * T = O(1) */ listIter *listGetIterator(list *list, int direction) { // 為迭代器分配內存 listIter *iter; if ((iter = zmalloc(sizeof(*iter))) == NULL) return NULL; // 根據迭代方向,設置迭代器的起始節點 if (direction == AL_START_HEAD) iter->next = list->head; else iter->next = list->tail; // 記錄迭代方向 iter->direction = direction; return iter; }
listReleaseIterator函數:釋放指定的迭代器
/* * listReleaseIterator 釋放迭代器 * * T = O(1) */ void listReleaseIterator(listIter *iter) { zfree(iter); }
listRewind函數和listRewindTail函數:迭代器重新指向表頭或者表尾的函數
/* * 將迭代器的方向設置為 AL_START_HEAD, * 並將迭代指針重新指向表頭節點。 * * T = O(1) */ void listRewind(list *list, listIter *li) { li->next = list->head; li->direction = AL_START_HEAD; } /* * 將迭代器的方向設置為 AL_START_TAIL, * 並將迭代指針重新指向表尾節點。 * * T = O(1) */ void listRewindTail(list *list, listIter *li) { li->next = list->tail; li->direction = AL_START_TAIL; }
listNext函數:返回當前迭代器指向的結點
/* * 返回迭代器當前所指向的節點。 * * 刪除當前節點是允許的,但不能修改鏈表裡的其他節點。 * * 函數要麼返回一個節點,要麼返回 NULL,常見的用法是: * * iter = listGetIterator(list,<direction>); * while ((node = listNext(iter)) != NULL) { * doSomethingWith(listNodeValue(node)); * } * * T = O(1) */ listNode *listNext(listIter *iter) { listNode *current = iter->next; if (current != NULL) { // 根據方向選擇下一個節點 if (iter->direction == AL_START_HEAD) // 保存下一個節點,防止當前節點被刪除而造成指針丟失 iter->next = current->next; else // 保存下一個節點,防止當前節點被刪除而造成指針丟失 iter->next = current->prev; } return current; }
該函數保持了當前結點的下一個結點,避免了當前結點被刪除而迭代器無法繼續迭代的尷尬情況
listDup函數:複製整個鏈表,返回副本
/* * 複製整個鏈表。 * * 複製成功返回輸入鏈表的副本, * 如果因為內存不足而造成複製失敗,返回 NULL 。 * * 如果鏈表有設置值複製函數 dup ,那麼對值的複製將使用複製函數進行, * 否則,新節點將和舊節點共享同一個指針。 * * 無論複製是成功還是失敗,輸入節點都不會修改。 * * T = O(N) */ list *listDup(list *orig) { list *copy;//鏈表副本 listIter *iter;//鏈表迭代器 listNode *node;//鏈表結點 // 創建新的空鏈表 if ((copy = listCreate()) == NULL) return NULL;//創建空的鏈表失敗則返回NULL // 設置副本鏈表的節點值處理函數 copy->dup = orig->dup; copy->free = orig->free; copy->match = orig->match; //獲取輸入鏈表的迭代器 iter = listGetIterator(orig, AL_START_HEAD); //遍歷整個輸入鏈表進行複製 while ((node = listNext(iter)) != NULL) { //副本結點值 void *value; // 存在複製函數 if (copy->dup) { //調用複製函數複製 value = copy->dup(node->value); //複製結果為空,說明複製失敗 if (value == NULL) { //複製失敗則釋放副本鏈表和迭代器,避免內存泄漏 listRelease(copy); listReleaseIterator(iter); return NULL; } } //不存在複製函數 則直接指針指向 else value = node->value; // 將節點添加到副本鏈表 if (listAddNodeTail(copy, value) == NULL) { //如果不能成功添加,則釋放副本鏈表和迭代器,避免內存泄漏 listRelease(copy); listReleaseIterator(iter); return NULL; } } // 釋放迭代器 listReleaseIterator(iter); // 返回副本 return copy; }
如果複製失敗則要注意釋放副本鏈表和迭代器,避免內存泄漏
listSearchKey函數:查找list中值和key匹配的結點
/* * 查找鏈表 list 中值和 key 匹配的節點。 * * 對比操作由鏈表的 match 函數負責進行, * 如果沒有設置 match 函數, * 那麼直接通過對比值的指針來決定是否匹配。 * * 如果匹配成功,那麼第一個匹配的節點會被返回。 * 如果沒有匹配任何節點,那麼返回 NULL 。 * * T = O(N) */ listNode *listSearchKey(list *list, void *key) { listIter *iter;//鏈表迭代器 listNode *node;//鏈表結點 //獲得鏈表迭代器 iter = listGetIterator(list, AL_START_HEAD); //遍歷整個鏈表查詢 while ((node = listNext(iter)) != NULL) { //存在比較函數 if (list->match) { //利用比較函數進行比較 if (list->match(node->value, key)) { //返回目標結點之前釋放迭代器空間,避免內存泄漏 listReleaseIterator(iter); return node; } } //不存在比較函數 else { //直接比較 if (key == node->value) { //返回目標結點之前釋放迭代器空間,避免內存泄漏 listReleaseIterator(iter); // 找到 return node; } } } //返回目標結點之前釋放迭代器空間,避免內存泄漏 listReleaseIterator(iter); // 未找到 return NULL; }
listIndex函數:返回鏈表在給定索引上的值
/* * 返回鏈表在給定索引上的值。 * * 索引以 0 為起始,也可以是負數, -1 表示鏈表最後一個節點,諸如此類。 * * 如果索引超出範圍(out of range),返回 NULL 。 * * T = O(N) */ listNode *listIndex(list *list, long index) { listNode *n;//鏈表結點 /* n不用設置成NULL的原因: 如果索引超出範圍, 那肯定是找到表頭或者表尾沒有找到, 表頭的前驅和表尾的後繼都是NULL, 所以這裏n不用設置為NULL,直接設置也可以*/ // 如果索引為負數,從表尾開始查找 if (index < 0) { //變成正數,方便索引 index = (-index) - 1; //從尾部開始找 n = list->tail; //尋找 因為從尾部開始找,所以是前驅 while (index-- && n) n = n->prev; } // 如果索引為正數,從表頭開始查找 else { //從頭部開始找 n = list->head; //尋找 因為從頭部開始找,所以是後繼 while (index-- && n) n = n->next; } return n; }
listRotate函數:取出鏈表的表尾結點放到表頭,成為新的表頭結點
/* * 取出鏈表的表尾節點,並將它移動到表頭,成為新的表頭節點。 * * T = O(1) */ void listRotate(list *list) { //表尾結點 listNode *tail = list->tail; //如果鏈表中只有一個元素,那麼表頭就是表尾,可以直接返回 if (listLength(list) <= 1) return; // 重新設置表尾節點 list->tail = tail->prev; list->tail->next = NULL; // 插入到表頭 list->head->prev = tail; tail->prev = NULL; tail->next = list->head; list->head = tail; }
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※聚甘新
默認情況下,Docker網絡使用僅使用主機虛機網橋bridge,主機內的所有容器都連接至該網橋。連接到此橋的所有容器都可以彼此通信,但不能與不同主機上的容器通信。通常,這種通信使用端口映射來處理,其中容器端口綁定到主機上的端口,所有通信都通過物理主機上的端口路由。
當有大量主機和容器時,使用此模式,需要手動管理所有端口綁定非常不現實。
為了支持跨集群的容器之間的通信,OpenShift容器平台使用了軟件定義的網絡(SDN)方法。軟件定義的網絡是一種網絡模型,它通過幾個網絡層的抽象來管理網絡服務。SDN將處理流量的軟件(稱為控制平面)和路由流量的底層機制(稱為數據平面)解耦。SDN支持控制平面和數據平面之間的通信。
在OpenShift Container Platform 3.9中(之後簡稱OCP),管理員可以為pod網絡配置三個SDN插件:
cluster network由OpenShift SDN建立和維護,它使用Open vSwitch創建overlay網絡,master節點不能通過集群網絡訪問容器,除非master同時也為node節點。
注意:VNID為0的project可以與所有其他pod通信,在OpenShift容器平台中,默認項目的VNID為0。
在默認的OpenShift容器平台安裝中,每個pod都有一個惟一的IP地址。pod中的所有容器都對外表現在相同的主機上。給每個pod提供自己的IP地址意味着,在端口分配、網絡、DNS、負載平衡、應用程序配置和遷移方面,pod被視為物理主機或虛擬機的獨立節點(僅從網絡層面看待)。
Kubernetes提供了service的概念,在任何OpenShift應用程序中,service都是必不可少的資源。service充當一個或多個pod前的負載平衡器。該service提供一個固定的IP地址,並且允許與pod通信,而不必跟蹤單獨的pod IP地址。
大多數實際應用程序都不是作為單個pod運行的。它們需要水平伸縮,這樣應用程序就可以在許多pod上運行,以滿足不斷增長的用戶需求。在OpenShift集群中,pod不斷地在集群中的節點之間創建和銷毀。每次創建pod時,它們都會獲得一個不同的IP地址。一個service提供一個單獨的、惟一的IP地址供其他pod使用,而不依賴於pod運行的節點,因此一個pod不必一定需要發現另一個pod的IP地址。客戶端通過service的請求在不同pod之間實現負載均衡。
service背後運行的一組pod由OpenShift容器平台自動管理。每個service都被分配了一個唯一的IP地址供客戶端連接。這個IP地址也來自OpenShift SDN,它與pod的內部網絡不同,也只在集群中可見。每個與selector匹配的pod都作為endpoint添加到service資源中。當創建和銷毀pods時,service後面的endpoint將自動更新。
service yaml語法:
1 - apiVersion: v1 2 kind: Service #聲明資源類型 3 metadata: 4 labels: 5 app: hello-openshift 6 name: hello-openshift #服務的唯一名稱 7 spec: 8 ports:, 9 - name: 8080-tcp 10 port: 8080 #服務對外公開的端口客戶機連接到服務端口 11 protocol: TCP 12 targetPort: 8080 #targetPort屬性必須匹配pod容器定義中的containerPort,服務將數據包轉發到pod中定義的目標端口。 13 selector: #該服務使用selector屬性查找要轉發數據包的pod。目標pod的元數據中需要有匹配的標籤。如果服務發現多個具有匹配標籤的pod,它將在它們之間實現負載 14 app: hello-openshift 15 deploymentconfig: hello-openshift
默認情況下,pod和service IP地址不能從OpenShift集群外部訪問。對於需要從OpenShift集群外部訪問服務的應用程序,可以通過以下三種方式。
HostPort/HostNetwork:在這種方法中,client可以通過主機上的網絡端口直接訪問集群中的應用程序pod。應用程序pod中的端口被綁定到運行該pod的主機上的端口。這種方法在集群中運行大量pod時,存在端口衝突的風險。
NodePort:這是一種較老的基於Kubernetes的方法,通過綁定到node主機上的可用端口,將service公開給外部客戶端,然後node主機代理到service IP地址的連接。使用oc edit svc命令編輯服務屬性,指定NodePort的類型,併為NodePort屬性提供端口值。OpenShift然後通過node主機的公共IP地址和nodePort中設置的端口值代理到服務的連接。這種方法支持非http通信。
OpenShift routes:OpenShift中的推薦方式。它使用唯一的URL公開服務。使用oc expose命令公開用於外部訪問的服務,或者從OpenShift web控制台公開服務。在這種方法中,目前只支持HTTP、HTTPS、TLS whit SNI和WebSockets。
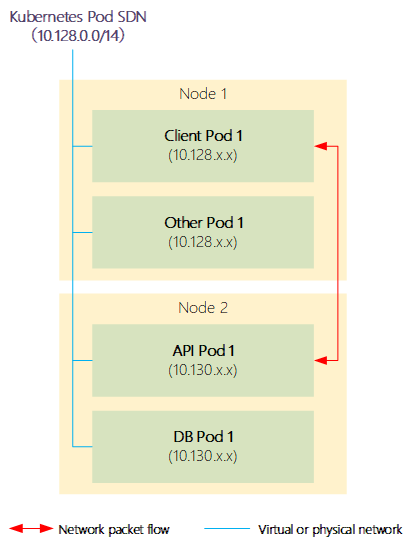
附圖:显示了NodePort服務如何允許外部訪問Kubernetes服務。
service nodeport yaml語法:
1 apiVersion: v1 2 kind: Service 3 metadata: 4 ... 5 spec: 6 ports: 7 - name: 3306-tcp 8 port: 3306 9 protocol: TCP 10 targetPort: 3306 #pod目標端口,即需要和pod定義的端口匹配 11 nodePort: 30306 #OpenShift集群中主機上的端口,暴露給外部客戶端 12 selector: 13 app: mysqldb 14 deploymentconfig: mysqldb 15 sessionAffinity: None 16 type: NodePort #服務的類型,如NodePort 17 ...
OpenShift將服務綁定到服務定義的nodePort屬性中定義的值,併為集群中所有node(包括master)上的流量打開該端口。外部客戶端可以連接到node端口上的任何節點的公共IP地址來訪問服務。請求會在服務後面的各個pod之間實現輪詢的負載平衡。
OpenShift route主要限於HTTP和HTTPS流量,但是節點端口可以處理非HTTP流量,當設置好公開的端口后,客戶機可以使用TCP或UDP的協議連接到該端口。
提示:缺省情況下,NodePort屬性的端口號限制在30000-32767之間,可通過在OpenShift主配置文件中配置範圍。
node port在集群中的所有node上都是打開的,包括master節點。如果沒有提供node端口值,OpenShift將自動在配置範圍內分配一個隨機端口。
pod可以使用其主機的地址與外部網絡通信。只要主機能夠解析pod需要到達的服務器,pod就可以使用網絡地址轉換(network address translation, NAT)機制與目標服務器通信。
[student@workstation ~]$ lab install-prepare setup
[student@workstation ~]$ cd /home/student/do280-ansible
[student@workstation do280-ansible]$ ./install.sh
提示:以上準備為部署一個正確的OpenShift平台。
[student@workstation ~]$ lab openshift-network setup #準備本實驗環境
[student@workstation ~]$ oc login -u developer -p redhat https://master.lab.example.com
[student@workstation ~]$ oc new-project network-test #創建project
[student@workstation ~]$ oc new-app –name=hello -i php:7.0 http://registry.lab.example.com/scaling
[student@workstation ~]$ oc get pods
NAME READY STATUS RESTARTS AGE
hello-1-build 1/1 Running 0 8s
[student@workstation ~]$ oc scale –replicas=2 dc hello
[student@workstation ~]$ oc get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
hello-1-kszfh 1/1 Running 0 11m 10.128.0.21 node1.lab.example.com
hello-1-q7wk2 1/1 Running 0 11m 10.129.0.37 node2.lab.example.com
[student@workstation ~]$ curl http://10.128.0.21:8080
curl: (7) Failed connect to 10.128.0.21:8080; Network is unreachable
[root@node1 ~]# curl http://10.128.0.21:8080
1 <html> 2 <head> 3 <title>PHP Test</title> 4 </head> 5 <body> 6 <br/> Server IP: 10.128.0.21 7 </body> 8 </html> 9 [root@node1 ~]# curl http://10.129.0.37:8080 10 <html> 11 <head> 12 <title>PHP Test</title> 13 </head> 14 <body> 15 <br/> Server IP: 10.129.0.37 16 </body> 17 </html>
提示:默認情況下,pod的ip屬於內部,集群內部節點可以使用pod ip訪問,集群外部(如workstation)無法訪問。
[student@workstation ~]$ oc get svc hello
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello ClusterIP 172.30.253.212 <none> 8080/TCP 14m
[student@workstation ~]$ curl http://172.30.253.212:8080
curl: (7) Failed connect to 172.30.253.212:8080; Network is unreachable
[root@node1 ~]# curl http://172.30.253.212:8080 #驗證負載均衡
1 <html> 2 <head> 3 <title>PHP Test</title> 4 </head> 5 <body> 6 <br/> Server IP: 10.128.0.21 7 </body> 8 </html> 9 [root@node1 ~]# curl http://172.30.253.212:8080 #驗證負載均衡 10 <html> 11 <head> 12 <title>PHP Test</title> 13 </head> 14 <body> 15 <br/> Server IP: 10.129.0.37 16 </body> 17 </html>
提示:默認情況下,cluster的ip屬於內部,集群內部節點可以使用cluster ip訪問,集群外部(如workstation)無法訪問。
[student@workstation ~]$ oc describe svc hello
Name: hello
Namespace: network-test
Labels: app=hello
Annotations: openshift.io/generated-by=OpenShiftNewApp
Selector: app=hello,deploymentconfig=hello
Type: ClusterIP
IP: 172.30.253.212
Port: 8080-tcp 8080/TCP
TargetPort: 8080/TCP
Endpoints: 10.128.0.21:8080,10.129.0.37:8080
Session Affinity: None
Events: <none>
解釋:
endpoint:显示請求路由到的pod IP地址列表。當pod有更新后,endpoint將自動更新。
Selector:OpenShift使用為pods定義的選擇器和標籤來使用給定的集群IP,以便實現應用的負載均衡。如上所示為OpenShift將此服務的請求路由到所有標記為app=hello和deploymentconfig=hello的pod。
[student@workstation ~]$ oc describe pod hello-1-kszfh
使用NodePort方式設置外部訪問。
[student@workstation ~]$ oc edit svc hello
1 apiVersion: v1 2 kind: Service 3 metadata: 4 annotations: 5 openshift.io/generated-by: OpenShiftNewApp 6 creationTimestamp: 2019-07-19T15:50:09Z 7 labels: 8 app: hello 9 name: hello 10 namespace: network-test 11 resourceVersion: "24496" 12 selfLink: /api/v1/namespaces/network-test/services/hello 13 uid: e348e2a3-aa3c-11e9-b230-52540000fa0a 14 spec: 15 clusterIP: 172.30.253.212 16 ports: 17 - name: 8080-tcp 18 port: 8080 19 protocol: TCP 20 targetPort: 8080 21 nodePort: 30800 22 selector: 23 app: hello 24 deploymentconfig: hello 25 sessionAffinity: None 26 type: NodePort 27 status:
[student@workstation ~]$ oc describe svc hello
Name: hello
Namespace: network-test
Labels: app=hello
Annotations: openshift.io/generated-by=OpenShiftNewApp
Selector: app=hello,deploymentconfig=hello
Type: NodePort #驗證是否為NodePort
IP: 172.30.253.212
Port: 8080-tcp 8080/TCP
TargetPort: 8080/TCP
NodePort: 8080-tcp 30800/TCP
Endpoints: 10.128.0.21:8080,10.129.0.37:8080
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
[student@workstation ~]$ curl http://node1.lab.example.com:30800
1 <html> 2 <head> 3 <title>PHP Test</title> 4 </head> 5 <body> 6 <br/> Server IP: 10.128.0.21 7 </body> 8 </html>
[student@workstation ~]$ curl http://node2.lab.example.com:30800
1 <html> 2 <head> 3 <title>PHP Test</title> 4 </head> 5 <body> 6 <br/> Server IP: 10.129.0.37 7 </body> 8 </html>
[student@workstation ~]$ oc rsh hello-1-kszfh #使用pod的shell
sh-4.2$ curl http://services.lab.example.com
OpenShift service允許在OpenShift中的pod之間進行網絡訪問;
OpenShift routes允許從OpenShift外部對pods進行網絡訪問。
路由概念上是通過連接公網IP和DNS主機名訪問內網service IP。在實踐中,為了提高性能和減少延遲,OpenShift route通過OpenShift創建的網絡直接連接到pod,使用該服務只查找endpoint,service只是協助查詢Pod地址。
OpenShift 路由功能由router service提供,該服務在OpenShift實例中作為一個pod運行,可以像任何其他常規pod一樣伸縮和複製。router service基於開源軟件HAProxy實現。
OpenShift route配置的公共DNS主機名需要指向運行router的節點的公共IP地址。route pod與常規應用程序pod不同,它綁定到節點的公共IP地址,而不是內部pod網絡。這通常使用DNS通配符配置。
1 - apiVersion: v1 2 kind: Route #聲明為route類型 3 metadata: 4 creationTimestamp: null 5 labels: 6 app: quoteapp 7 name: quoteapp #路由器名字 8 spec: 9 host: quoteapp.apps.lab.example.com #與route關聯的FQDN,必須預先配置,以解析到OpenShift route pod運行的節點的IP地址 10 port: 11 targetPort: 8080-tcp 12 to: #一個對象,該對象聲明此route指向的資源類型(在本例中是OpenShift service),以及該資源的名稱(quoteapp) 13 kind: Service 14 name: quoteapp
提示:不同資源類型可以使用相同的名稱,如一個名為quoteapp的route可以指向一個名為quoteapp的service。
service通過selector與pod的label進行匹配,router通過name與service的name匹配。
創建route最簡單和推薦的方法是使用oc expose命令,將service資源名稱作為輸入參數。–name選項可用於控制route資源的名稱,–hostname選項可用於為route提供自定義主機名。
示例:
[user@demo ~]$ oc expose service quote \
–name quote –hostname=quoteapp.apps.lab.example.com
從模板或不帶–hostname參數的oc expose命令創建的路由,命名方式為:
<route-name>-<project-name>.<default-domain>
解釋
route-name:route的名稱,或原始資源的名稱;
project-name:包含資源的項目的名稱;
default-domain:該值是在OpenShift master上配置的,它對應於作為安裝OpenShift先決條件列出的通配符DNS域。
例如,在OpenShift集群中名為test的project中創建一條名為quote的路由,其中子域為apps.example.com,則FQDN為quote-test.apps.example.com
注意:承載通配符域的DNS服務器不知道任何route的主機名,它只將任何名稱解析為已配置的ip。只有OpenShift route知道route主機名,將每個主機都當作HTTP虛擬主機。無效的通配符域主機名,即不與任何route對應的主機名,將被OpenShift路由器阻塞。
通過向oc create提供JSON或YAML資源定義文件,也可以像其他OpenShift資源一樣創建route資源。
oc new-app命令在從容器映像、Dockerfiles或應用程序源代碼構建pod時不創建route資源。
oc new-app命令不知道pod是否打算從OpenShift實例外部訪問。當oc new-app命令從模板創建一組pod時,沒有什麼可以阻止模板將路由資源包含到應用程序中。
默認路由子域是在OpenShift配置文件master-config.yaml中的routingConfig字段中定義,使用關鍵字subdomain。
routingConfig:
subdomain: apps.example.com
默認情況下,OpenShift HAProxy route綁定到主機端口80 (HTTP)和443 (HTTPS)。route必須放置在這些端口不使用的節點上。或者,可以通過設置ROUTER_SERVICE_HTTP_PORT和ROUTER_SERVICE_HTTPS_PORT環境變量來配置路由器監聽其他端口.
路由器支持以下協議:
路由可以是安全的,也可以是非安全的。安全route提供了使用幾種類型的TLS方式來向客戶端提供證書的能力。不安全路由是最容易配置的,因為它們不需要密鑰或證書,但是安全路由會加密進出pod的流量。
在創建安全路由之前,需要生成TLS證書。
示例:如下步驟創建名為test.example.com的路由創建一個簡單的自簽名證書。
[user@demo ~]$ openssl genrsa -out example.key 2048
[user@demo ~]$ openssl req -new -key example.key -out example.csr -subj “/C=US/ST=CA/L=Los Angeles/O=Example/OU=IT/CN=test.example.com”
[user@demo ~]$ openssl x509 -req -days 366 -in example.csr -signkey example.key -out example.crt
[user@demo ~]$ oc create route edge –service=test \
–hostname=test.example.com \
–key=example.key –cert=example.crt
wildcard policy允許用戶定義domain中所有主機的route。route可以使用wildcardPolicy字段將wildcard policy指定為其配置的一部分。OpenShift路由器支持通配符路由,通過設置路由器部署配置中的ROUTER_ALLOW_WILDCARD_ROUTES環境變量為true,從而可將wildcardPolicy屬性設置為子域的任何route都由路由器提供服務。路由器根據route的通配符策略暴露相關的service。
示例:如下下示例表示對於三個不同的路由,a.lab.example.com、b.lab.example.com和c.lab.example.com,它們應該路由到一個名為test的OpenShift服務,可以使用通配符策略配置路由。
[user@demo ~]$ oc scale dc/router –replicas=0
[user@demo ~]$ oc set env dc/router ROUTER_ALLOW_WILDCARD_ROUTES=true
[user@demo ~]$ oc scale dc/router –replicas=1
[user@demo ~]$ oc expose svc test –wildcard-policy=Subdomain \
–hostname=’www.lab.example.com’
在master節點上,在default中查找router
[root@master]# oc project default
[root@master]# oc get pods
在master節點上,檢查路由器環境變量,以找到運行在pod中的HAProxy進程的連接參數
[root@master]# oc env pod router-1-32toa –list | tail -n 6
提示:當創建路由器時,STATS_PASSWORD變量中的密碼是隨機生成的。STATS_USERNAME和STATS_PORT變量有固定的默認值,但是它們都可以在路由器創建時更改。
在router運行的節點上,配置firewall-cmd以打開STATS_PORT變量指定的端口。
[root@node ~]# firewall-cmd –permanent –zone=public –add-port=1936
[root@node ~]# firewall-cmd –reload
打開web瀏覽器並訪問HAProxy statistics URL 為 http://nodeIP:STATS_PORT/。
在User Name字段中輸入STATS_USERNAME的值,在Password字段中輸入STATS_PASSWORD的值,然後單擊OK。則會显示的HAProxy metrics頁面。
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
[student@workstation ~]$ lab secure-route setup #準備本實驗環境
[student@workstation ~]$ oc login -u developer -p redhat https://master.lab.example.com
[student@workstation ~]$ oc new-project secure-route #創建project
[student@workstation ~]$ oc new-app –docker-image=registry.lab.example.com/openshift/hello-openshift –name=hello
[student@workstation ~]$ oc get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
hello-1-wwgkr 1/1 Running 0 20s 10.129.0.38 node2.lab.example.com
[student@workstation ~]$ cd /home/student/DO280/labs/secure-route/ #使用環境中的腳本快速創建TLS自簽名證書
[student@workstation secure-route]$ ./create-cert.sh
[student@workstation secure-route]$ ll
-rw-r–r–. 1 student student 550 Aug 7 2018 commands.txt
-rwxr-xr-x. 1 student student 506 Jul 19 2018 create-cert.sh
-rw-rw-r–. 1 student student 1224 Jul 20 10:43 hello.apps.lab.example.com.crt
-rw-rw-r–. 1 student student 1017 Jul 20 10:43 hello.apps.lab.example.com.csr
-rw-rw-r–. 1 student student 1679 Jul 20 10:43 hello.apps.lab.example.com.key
[student@workstation secure-route]$ oc create route edge \
> –service=hello –hostname=hello.apps.lab.example.com \
> –key=hello.apps.lab.example.com.key \
> –cert=hello.apps.lab.example.com.crt
[student@workstation secure-route]$ oc get route
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
hello hello.apps.lab.example.com hello 8080-tcp edge None
[student@workstation secure-route]$ oc get route hello -o yaml #以yaml格式查看route
[student@workstation ~]$ curl http://hello.apps.lab.example.com #以http形式訪問會無法轉發至後端任何pod
1 …… 2 <h1>Application is not available</h1> 3 <p>The application is currently not serving requests at this endpoint. It may not have been started or is still starting.</p> 4 ……
[student@workstation ~]$ curl -k -vvv https://hello.apps.lab.example.com #以https形式訪問
1 …… 2 Hello OpenShift! 3 * Connection #0 to host hello.apps.lab.example.com left intact 4 ……
由於加密的通信在路由器上終止,並且請求使用不安全的HTTP轉發到pods,所以可以使用pod IP地址通過普通HTTP訪問應用程序。為此,請使用oc get pods -o命令中指定的IP地址。
[student@workstation secure-route]$ oc get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
hello-1-wwgkr 1/1 Running 0 21m 10.129.0.38 node2.lab.example.com
[root@node1 ~]# curl -vvv http://10.129.0.38:8080
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
[student@workstation ~]$ lab network-review setup
[student@workstation ~]$ oc login -u developer -p redhat \
https://master.lab.example.com
[student@workstation ~]$ oc get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
hello-openshift-1-6ls8z 1/1 Running 0 2m 10.128.0.23 node1.lab.example.com
[student@workstation ~]$ oc get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-openshift ClusterIP 172.30.124.237 <none> 8080/TCP,8888/TCP 2m
[student@workstation ~]$ oc get route
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
hello-openshift hello.apps.lab.example.com hello-opensift 8080-tcp None
[student@workstation ~]$ curl http://hello.apps.lab.example.com #測試http訪問
1 …… 2 <h1>Application is not available</h1> 3 <p>The application is currently not serving requests at this endpoint. It may not have been started or is still starting.</p> 4 ……
[root@node1 ~]# curl http://10.128.0.23:8080 #測試使用pod ip訪問
Hello OpenShift!
[root@node1 ~]# curl http://172.30.124.237:8080 #測試使用cluster ip訪問
curl: (7) Failed connect to 172.30.124.237:8080; Connection refused
[student@workstation ~]$ oc describe svc hello-openshift -n network-review
提示:由上可知,沒有endpoint,endpoint是使用selector對pod的label進行匹配。
[student@workstation ~]$ oc describe pod hello-openshift-1-6ls8z #查看pod詳情
故障點:由上可知,Selector的label不一致,則沒有標記為hello_openshift的pod能進行匹配。
[student@workstation ~]$ oc edit svc hello-openshift
1 …… 2 selector: 3 app: hello-openshift 4 deploymentconfig: hello-openshift 5 sessionAffinity: None 6 ……
[root@node1 ~]# curl http://10.128.0.23:8080 #測試使用pod ip訪問
Hello OpenShift!
[root@node1 ~]# curl http://172.30.124.237:8080 #再次測試
Hello OpenShift!
[student@workstation ~]$ curl http://hello.apps.lab.example.com #測試http訪問
1 …… 2 <h1>Application is not available</h1> 3 <p>The application is currently not serving requests at this endpoint. It may not have been started or is still starting.</p> 4 ……
[student@workstation ~]$ oc describe route hello-openshift
故障點:由上可知,此路由沒有endpoint。即對route的URL請求沒有後端endpoint進行響應。路由器查詢service的endpoint,並註冊有效的endpoint來實現負載平衡。同時發現service名稱中有一個拼寫錯誤,它應該是hello-openshift。
[student@workstation ~]$ oc edit route hello-openshift
1 …… 2 spec: 3 host: hello.apps.lab.example.com 4 port: 5 targetPort: 8080-tcp 6 to: 7 kind: Service 8 name: hello-openshift 9 weight: 100 10 wildcardPolicy: None 11 ……
[root@node1 ~]# curl http://hello.apps.lab.example.com #再次測試
Hello OpenShift!
[student@workstation ~]$ lab network-review grade #使用腳本判斷 本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※聚甘新