轉載自台大風險社會與政策研究中心;陳喬琪 編譯
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
摘錄自2020年8月17日中央社報導
希臘不少有錢人置產的科孚島(Corfu)一座松樹林今(17日)發生大火,強風助長下,火勢在東北沿岸持續延燒。
法新社報導,野火爆發點鄰近艾米提斯區(Erimitis)樹木林立的海濱城鎮阿吉歐史芬尼(Agios Stefanos),而當地名聲最顯赫的居民莫過於羅斯契德(Rothschild)家族及阿涅利(Agnelli)家族。
希臘當局表示,消防人員出動12輛消防車,並在飛機支援下力阻野火在這個英國媒體譽為「海上肯辛頓」(Kensington-on-sea)的地區蔓延。
希臘夏季溫度動輒超過攝氏30度,時常傳出野火。2018年7月,雅典東北濱海度假城鎮瑪蒂(Mati)的一場火勢造成102人喪生,為希臘近代史最嚴重火災。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
摘錄自2020年8月17日東森新聞報導
美國國家氣象局(National Weather Service)15日針對北加州發布龍捲風警報,而且這次是稀有的火龍捲警報,由加州洛亞爾頓的野火火源的高溫引起熱空氣與濃煙上升變成「火積雲」(pyrocumulonimbus),形成時速近100公里的火龍捲。
駭人的火龍捲15日在內華達州邊境被發現,是當空氣中的漩渦亂流因為高熱及風向造成的湍流結合而形成,在旋風內有火焰。當這些渦旋空氣繼續收緊至類似龍捲風的結構時,可以吸入燃燒中的碎塊雜物及可燃氣體,從而使旋風點起火焰。龍捲風的存在可以幫助野火更快地傳播。
美國西部各州面臨70年來最嚴重的熱浪侵襲,超過800萬人收到政府的高溫警報,沙加緬度甚至預計達到攝氏43度。加州14日甚至因為溫度過高,電網不堪負荷,導致全州陷入停電。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
摘錄自2020年8月18日公視報導
根據國際動保團體的最新調查,過去只在越南北部較為普遍的貓肉餐廳,現在已經擴展到全國各地,每年大約會吃掉100萬隻貓,而越南政府從1998年以來的吃貓肉禁令,已經在今年1月廢除,動保團體擔心情況將會雪上加霜。
越南人在二戰後民不聊生,經常抓貓狗充飢,雖然政府在1998年曾明令禁止,但民間吃貓肉的風氣仍舊存在。有老一輩的越南人認為,月初吃貓會獲得好運,避免遭遇不幸,還有的認為經常吃貓肉可以像貓一樣敏捷;而有的餐廳將貓肉稱作老虎寶寶,或小老虎之類的,讓人相信吃了可以強身壯陽。
今年1月間越南政府廢除吃貓禁令後,動保團體發現,越南各地貓肉餐廳頓時多了起來,遍及會安、胡志明市等地,而距離河內兩個小時車程的太平省,就是貓隻屠宰場的大本營,整個屠宰過程極不人道。
在揭發業者抓捕屠殺貓隻的殘忍行徑後,動保團體希望越南民眾別再吃貓肉。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
如果想從頭學起Cypress,可以看下面的系列文章哦
https://www.cnblogs.com/poloyy/category/1768839.html
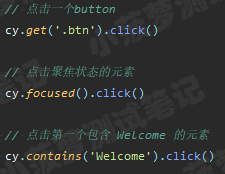
這一篇着重講點擊操作,一共有三個命令
單擊某個元素
// 單擊某個元素 .click() // 帶參數的單擊 .click(options) // 在某個位置點擊 .click(position) // 在某個位置點擊,且帶參數 .click(position, options) // 根據頁面坐標點擊 .click(x, y) // 根據頁面坐標點擊,且帶參數 .click(x, y, options)
宗旨:先獲取 DOM 元素,再對 DOM 元素操作
每個元素都有九個 position,具體可看下圖
距離 DOM 元素左上角的坐標,x 是橫軸,y 是豎軸
共有四個
// 強制點擊,和所有後續事件 // 即使該元素 “不可操作”,也會觸發點擊操作 cy.get('button').click({ force: true })
總而言之, { force: true } 跳過檢查,它將始終在所需元素處觸發事件
cy.get(‘ ul > li ‘) 共匹配四個 DOM 元素,他們均觸發單擊操作
.click() 命令還可以與 .type() 命令結合使用修飾符來觸發組合鍵操作,以便在單擊時結合鍵盤操作,例如ALT + click
| 修飾符 | 作用 | 別名 |
|---|---|---|
{alt} |
等價於 alt 鍵 | {option} |
| {ctrl} | 等價於 ctrl 鍵 | {control} |
| {shift} | 等價於 shift 鍵 |
雙擊,跟 click() 的語法 & 用法一致,只是變成了雙擊
cy.get("#main1").dblclick()
cy.get("#main1").dblclick("top")
cy.get("#main1").dblclick(15, 15)
右鍵,跟 click() 的語法 & 用法一致,只是變成了右鍵點擊
cy.get("#li1").rightclick()
cy.get("#li1").rightclick("top")
cy.get("#li1").rightclick(15, 15)
執行 .click() 必須是 DOM 元素達到了可操作狀態
.click() 將自動等待元素達到可操作狀態。
.click() 將自動等待後面鏈接的斷言通過
.click() 如果 DOM 元素一直達不到可操作狀態,可能會超時
.click() 如果後面鏈接的斷言一直不通過,可能會超時
在命令日誌中單擊 click 時,控制台console 將輸出以下鼠標事件
結尾
本文是博主基於對蔡超老師的《Cypress 從入門到精通》閱讀理解完后輸出的博文,並附上了自己的理解
對書籍感興趣的,大家可以參考本篇博客:https://www.cnblogs.com/poloyy/p/13052972.html,考慮自身需求進行購買
我的博客即將同步至騰訊雲+社區,邀請大家一同入駐:https://cloud.tencent.com/developer/support-plan?invite_code=12vd92hxgwgj1
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
synchronized鎖的原理也是大廠面試中經常會涉及的問題,本文主要通過對以下問題進行分析講解,來幫助大家理解synchronized鎖的原理。
1.synchronized鎖是什麼?鎖的對象是什麼?
2.偏向鎖,輕量級鎖,重量級鎖的執行流程是怎樣的?
3.為什麼說是輕量級,重量級鎖是不公平的?
4.重量級鎖為什麼需要自旋操作?
5.什麼時候會發生鎖升級,鎖降級?
6.偏向鎖,輕量鎖,重量鎖的適用場景,優缺點是什麼?
synchronized的英文意思就是同步的意思,就是可以讓synchronized修飾的方法,代碼塊,每次只能有一個線程在執行,以此來實現數據的安全。
一般可以修飾同步代碼塊、實例方法、靜態方法,加鎖對象分別為同步代碼塊塊括號內的對象、實例對象、類。
在實現原理上,
public class SyncTest {
private Object lockObject = new Object();
public void syncBlock(){
//修飾代碼塊,加鎖對象為lockObject
synchronized (lockObject){
System.out.println("hello block");
}
}
//修飾實例方法,加鎖對象為當前的實例對象
public synchronized void syncMethod(){
System.out.println("hello method");
}
//修飾靜態方法,加鎖對象為當前的類
public static synchronized void staticSyncMethod(){
System.out.println("hello method");
}
}
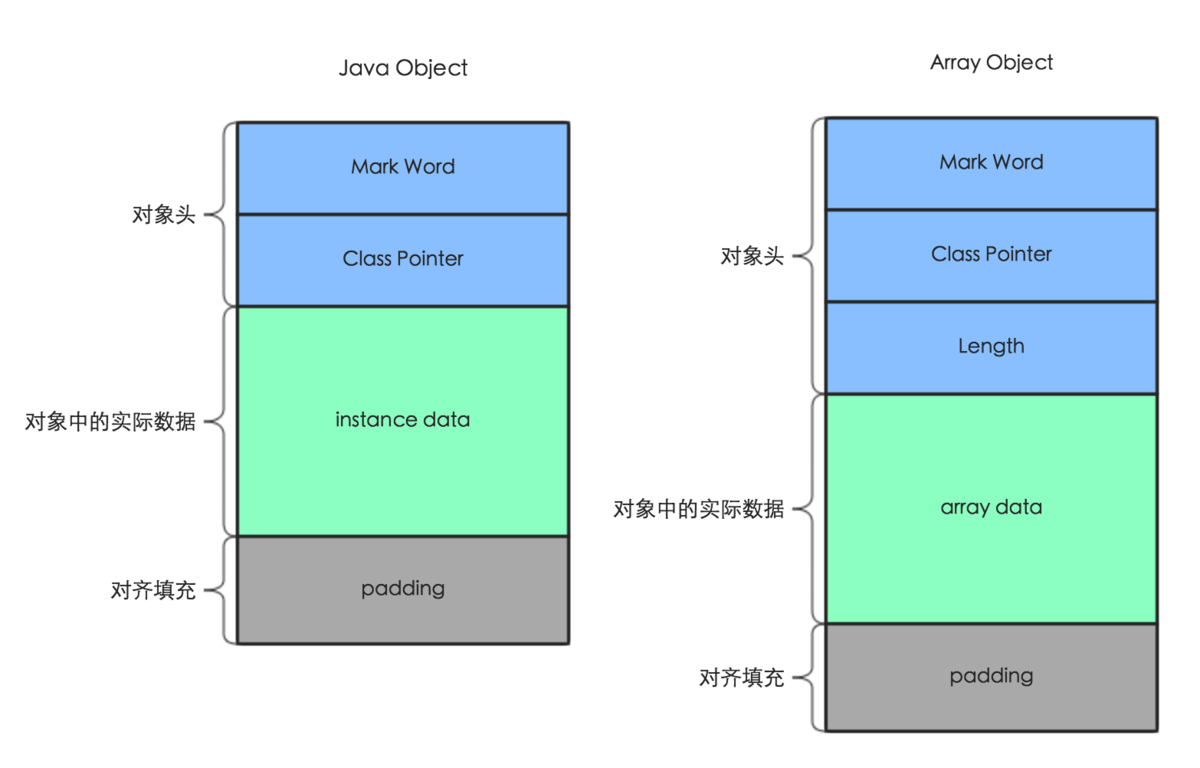
在JVM中,一個Java對象其實由對象頭+實例數據+對齊填充三部分組成,而對象頭主要包含Mark Word+指向對象所屬的類的指針組成(如果是數組對象,還會包含長度)。像下圖一樣:
Mark Word:存儲對象自身的運行時數據,例如hashCode,GC分代年齡,鎖狀態標誌,線程持有的鎖等等。在32位系統佔4字節,在64位系統中佔8字節,所以它能存儲的數據量是有限的,所以主要通過設立是否偏向鎖的標誌位和鎖標誌位用於區分其他位數存儲的數據是什麼,具體請看下圖:
鎖信息都是存在鎖對象的Mark Word中的,當對象狀態為偏向鎖時,Mark Word存儲的是偏向的線程ID;當狀態為輕量級鎖時,Mark Word存儲的是指向線程棧中Lock Record的指針;當狀態為重量級鎖時,Mark Word為指向堆中的monitor對象的指針。
這是網上找到的一個流程圖,可以先看流程圖,結合著文字來了解執行流程
Hotspot的作者經過以往的研究發現大多數情況下鎖不僅不存在多線程競爭,而且總是由同一線程多次獲得,於是引入了偏向鎖。
簡單的來說,就是主要鎖處於偏向鎖狀態時,會在Mark Word中存當前持有偏向鎖的線程ID,如果獲取鎖的線程ID與它一致就說明是同一個線程,可以直接執行,不用像輕量級鎖那樣執行CAS操作來加鎖和解鎖。
線程發現是匿名偏向狀態(也就是鎖對象的Mark Word沒有存儲線程ID),則會用CAS指令,將mark word中的thread id由0改成當前線程Id。如果成功,則代表獲得了偏向鎖,繼續執行同步塊中的代碼。否則,將偏向鎖撤銷,升級為輕量級鎖。
發現鎖對象存儲的線程ID就是當前線程的ID,會往當前線程的棧中添加一條Displaced Mark Word為空的Lock Record中,然後繼續執行同步塊的代碼,因為操縱的是線程私有的棧,因此不需要用到CAS指令;由此可見偏向鎖模式下,當被偏向的線程再次嘗試獲得鎖時,僅僅進行幾個簡單的操作就可以了,在這種情況下,synchronized關鍵字帶來的性能開銷基本可以忽略。
當沒有獲得鎖的線程進入同步塊時,發現當前是偏向鎖狀態,並且存儲的是其他線程ID(也就是其他線程正在持有偏向鎖),則會進入到撤銷偏向鎖的邏輯里,一般來說,會在safepoint中去查看偏向的線程是否還存活
mark word改為無鎖狀態(unlocked)由此可見,偏向鎖升級的時機為:當一個線程獲得了偏向鎖,在執行時,只要有另一個線程嘗試獲得偏向鎖,並且當前持有偏向鎖的線程還在同步塊中執行,則該偏向鎖就會升級成輕量級鎖。
因此偏向鎖的解鎖很簡單,其僅僅將線程的棧中的最近一條lock record的obj字段設置為null。需要注意的是,偏向鎖的解鎖步驟中並不會修改鎖對象Mark Word中的thread id,簡單的說就是鎖對象處於偏向鎖時,Mark Word中的thread id 可能是正在執行同步塊的線程的id,也可能是上次執行完已經釋放偏向鎖的thread id,主要是為了上次持有偏向鎖的這個線程在下次執行同步塊時,判斷Mark Word中的thread id相同就可以直接執行,而不用通過CAS操作去將自己的thread id設置到鎖對象Mark Word中。
這是偏向鎖執行的大概流程:
重量級鎖依賴於底層的操作系統的Mutex Lock來實現的,但是由於使用Mutex Lock需要將當前線程掛起並從用戶態切換到內核態來執行,這種切換的代價是非常昂貴的,而在大部分時候可能並沒有多線程競爭,只是這段時間是線程A執行同步塊,另外一段時間是線程B來執行同步塊,僅僅是多線程交替執行,並不是同時執行,也沒有競爭,如果採用重量級鎖效率比較低。以及在重量級鎖中,沒有獲得鎖的線程會阻塞,獲得鎖之後線程會被喚醒,阻塞和喚醒的操作是比較耗時間的,如果同步塊的代碼執行比較快,等待鎖的線程可以進行先進行自旋操作(就是不釋放CPU,執行一些空指令或者是幾次for循環),等待獲取鎖,這樣效率比較高。所以輕量級鎖天然瞄準不存在鎖競爭的場景,如果存在鎖競爭但不激烈,仍然可以用自旋鎖優化,自旋失敗后再升級為重量級鎖。
JVM會為每個線程在當前線程的棧幀中創建用於存儲鎖記錄的空間,我們稱為Displaced Mark Word。如果一個線程獲得鎖的時候發現是輕量級鎖,會把鎖的Mark Word複製到自己的Displaced Mark Word裏面。
然後線程嘗試用CAS操作將鎖的Mark Word替換為自己線程棧中拷貝的鎖記錄的指針。如果成功,當前線程獲得鎖,如果失敗,表示Mark Word已經被替換成了其他線程的鎖記錄,說明在與其它線程競爭鎖,當前線程就嘗試使用自旋來獲取鎖。
自旋:不斷嘗試去獲取鎖,一般用循環來實現。
自旋是需要消耗CPU的,如果一直獲取不到鎖的話,那該線程就一直處在自旋狀態,白白浪費CPU資源。
JDK採用了適應性自旋,簡單來說就是線程如果自旋成功了,則下次自旋的次數會更多,如果自旋失敗了,則自旋的次數就會減少。
自旋也不是一直進行下去的,如果自旋到一定程度(和JVM、操作系統相關),依然沒有獲取到鎖,稱為自旋失敗,那麼這個線程會阻塞。同時這個鎖就會升級成重量級鎖。
在釋放鎖時,當前線程會使用CAS操作將Displaced Mark Word的內容複製回鎖的Mark Word裏面。如果沒有發生競爭,那麼這個複製的操作會成功。如果有其他線程因為自旋多次導致輕量級鎖升級成了重量級鎖,那麼CAS操作會失敗,此時會釋放鎖並喚醒被阻塞的線程。
輕量級鎖的加鎖解鎖流程圖:
當多個線程同時請求某個重量級鎖時,重量級鎖會設置幾種狀態用來區分請求的線程:
Contention List:所有請求鎖的線程將被首先放置到該競爭隊列,我也不知道為什麼網上的文章都叫它隊列,其實這個隊列是先進后出的,更像是棧,就是當Entry List為空時,Owner線程會直接從Contention List的隊列尾部(后加入的線程中)取一個線程,讓它成為OnDeck線程去競爭鎖。(主要是剛來獲取重量級鎖的線程是回進行自旋操作來獲取鎖,獲取不到才會進從Contention List,所以OnDeck線程主要與剛進來還在自旋,還沒有進入到Contention List的線程競爭)
Entry List:Contention List中那些有資格成為候選人的線程被移到Entry List,主要是為了減少對Contention List的併發訪問,因為既會添加新線程到隊尾,也會從隊尾取線程。
Wait Set:那些調用wait方法被阻塞的線程被放置到Wait Set。
OnDeck:任何時刻最多只能有一個線程正在競爭鎖,該線程稱為OnDeck。
Owner:獲得鎖的線程稱為Owner
。
!Owner:釋放鎖的線程
流程圖如下:
步驟1是線程在進入Contention List時阻塞等待之前,程會先嘗試自旋使用CAS操作獲取鎖,如果獲取不到就進入Contention List隊列的尾部。
步驟2是Owner線程在解鎖時,如果Entry List為空,那麼會先將Contention List中隊列尾部的部分線程移動到Entry List
步驟3是Owner線程在解鎖時,如果Entry List不為空,從Entry List中取一個線程,讓它成為OnDeck線程,Owner線程並不直接把鎖傳遞給OnDeck線程,而是把鎖競爭的權利交給OnDeck,OnDeck需要重新競爭鎖,JVM中這種選擇行為稱為 “競爭切換”。(主要是與還沒有進入到Contention
List,還在自旋獲取重量級鎖的線程競爭)
步驟4就是OnDeck線程獲取到鎖,成為Owner線程進行執行。
步驟5就是Owner線程調用鎖對象的wait()方法進行等待,會移動到Wait Set中,並且會釋放CPU資源,也同時釋放鎖,
步驟6.就是當其他線程調用鎖對象的notify()方法,之前調用wait方法等待的這個線程才會從Wait Set移動到Entry List,等待獲取鎖。
偏向鎖由於不涉及到多個線程競爭,所以談不上公平不公平,輕量級鎖獲取鎖的方式是多個線程進行自旋操作,然後使用用CAS操作將鎖的Mark Word替換為指向自己線程棧中拷貝的鎖記錄的指針,所以誰能獲得鎖就看運氣,不看先後順序。重量級鎖不公平主要在於剛進入到重量級的鎖的線程不會直接進入Contention List隊列,而是自旋去獲取鎖,所以後進來的線程也有一定的幾率先獲得到鎖,所以是不公平的。
因為那些處於ContetionList、EntryList、WaitSet中的線程均處於阻塞狀態,阻塞操作由操作系統完成(在Linxu下通過pthread_mutex_lock函數)。線程被阻塞后便進入內核(Linux)調度狀態,這個會導致系統在用戶態與內核態之間來回切換,嚴重影響鎖的性能。如果同步塊中代碼比較少,執行比較快的話,後進來的線程先自旋獲取鎖,先執行,而不進入阻塞狀態,減少額外的開銷,可以提高系統吞吐量。
偏向鎖升級為輕量級鎖:
就是有不同的線程競爭鎖時。具體來看就是當一個線程發現當前鎖狀態是偏向鎖,然後鎖對象存儲的Thread id是其他線程的id,並且去Thread id對應的線程棧查詢到的lock record的obj字段不為null(代表當前持有偏向鎖的線程還在執行同步塊)。那麼該偏向鎖就會升級成輕量級鎖。
輕量級鎖升級為重量級鎖:
就是在輕量級鎖中,沒有獲取到鎖的線程進行自旋,自旋到一定次數還沒有獲取到鎖就會進行鎖升級,因為自旋也是佔用CPU的,長時間自旋也是很耗性能的。
鎖降級
因為如果沒有多線程競爭,還是使用重量級鎖會造成額外的開銷,所以當JVM進入SafePoint安全點(可以簡單的認為安全點就是所有用戶線程都停止的,只有JVM垃圾回收線程可以執行)的時候,會檢查是否有閑置的Monitor,然後試圖進行降級。
篇幅有限,下面是各種鎖的優缺點,來自《併發編程的藝術》:
| 鎖 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 偏向鎖 | 加鎖和解鎖不需要額外的消耗,和執行非同步方法比僅存在納秒級的差距。 | 如果線程間存在鎖競爭,會帶來額外的鎖撤銷的消耗。 | 適用於只有一個線程訪問同步塊場景。 |
| 輕量級鎖 | 競爭的線程不會阻塞,提高了程序的響應速度。 | 如果始終得不到鎖競爭的線程使用自旋會消耗CPU。 | 追求響應時間。同步塊執行速度非常快。 |
| 重量級鎖 | 線程競爭不使用自旋,不會消耗CPU。 | 線程阻塞,響應時間緩慢。 | 追求吞吐量。同步塊執行速度較長。 |
參考鏈接:
https://github.com/farmerjohngit/myblog/issues/12
http://redspider.group:4000/article/02/9.html
https://blog.csdn.net/bohu83/article/details/51141836
https://blog.csdn.net/Dev_Hugh/article/details/106577862
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
【摘要】對於mysql主備實例,seconds_behind_master是衡量master與slave之間延時的一個重要參數。通過在slave上執行”show slave status;”可以獲取seconds_behind_master的值。
對於mysql主備實例,seconds_behind_master是衡量master與slave之間延時的一個重要參數。通過在slave上執行”show slave status;”可以獲取seconds_behind_master的值。
Definition:The number of seconds that the slave SQL thread is behind processing the master binary log.
Type:time_t(long)
計算方式如下:
rpl_slave.cc::show_slave_status_send_data() if ((mi->get_master_log_pos() == mi->rli->get_group_master_log_pos()) && (!strcmp(mi->get_master_log_name(), mi->rli->get_group_master_log_name()))) { if (mi->slave_running == MYSQL_SLAVE_RUN_CONNECT) protocol->store(0LL); else protocol->store_null(); } else { long time_diff = ((long)(time(0) - mi->rli->last_master_timestamp) - mi->clock_diff_with_master); protocol->store( (longlong)(mi->rli->last_master_timestamp ? max(0L, time_diff) : 0)); }
主要分為以下兩種情況:
• SQL線程等待IO線程獲取主機binlog,此時seconds_behind_master為0,表示備機與主機之間無延時;
• SQL線程處理relay log,此時seconds_behind_master通過(long)(time(0) – mi->rli->last_master_timestamp) – mi->clock_diff_with_master計算得到;
定義:
• 主庫binlog中事件的時間。
• type: time_t (long)
計算方式:
last_master_timestamp根據備機是否并行複製有不同的計算方式。
rpl_slave.cc:exec_relay_log_event() if ((!rli->is_parallel_exec() || rli->last_master_timestamp == 0) && !(ev->is_artificial_event() || ev->is_relay_log_event() || (ev->common_header->when.tv_sec == 0) || ev->get_type_code() == binary_log::FORMAT_DESCRIPTION_EVENT || ev->server_id == 0)) { rli->last_master_timestamp= ev->common_header->when.tv_sec + (time_t) ev->exec_time; DBUG_ASSERT(rli->last_master_timestamp >= 0); }
在該模式下,last_master_timestamp表示為每一個event的結束時間,其中when.tv_sec表示event的開始時間,exec_time表示事務的執行時間。該值的計算在apply_event之前,所以event還未執行時,last_master_timestamp已經被更新。由於exec_time僅在Query_log_event中存在,所以last_master_timestamp在應用一個事務的不同event階段變化。以一個包含兩條insert語句的事務為例,在該代碼段的調用時,打印出event的類型、時間戳和執行時間
create table t1(a int PRIMARY KEY AUTO_INCREMENT ,b longblob) engine=innodb; begin; insert into t1(b) select repeat('a',104857600); insert into t1(b) select repeat('a',104857600); commit;
10T06:41:32.628554Z 11 [Note] [MY-000000] [Repl] event_type: 33 GTID_LOG_EVENT 2020-02-10T06:41:32.628601Z 11 [Note] [MY-000000] [Repl] event_time: 1581316890 2020-02-10T06:41:32.628614Z 11 [Note] [MY-000000] [Repl] event_exec_time: 0 2020-02-10T06:41:32.628692Z 11 [Note] [MY-000000] [Repl] event_type: 2 QUERY_EVENT 2020-02-10T06:41:32.628704Z 11 [Note] [MY-000000] [Repl] event_time: 1581316823 2020-02-10T06:41:32.628713Z 11 [Note] [MY-000000] [Repl] event_exec_time: 35 2020-02-10T06:41:32.629037Z 11 [Note] [MY-000000] [Repl] event_type: 19 TABLE_MAP_EVENT 2020-02-10T06:41:32.629057Z 11 [Note] [MY-000000] [Repl] event_time: 1581316823 2020-02-10T06:41:32.629063Z 11 [Note] [MY-000000] [Repl] event_exec_time: 0 2020-02-10T06:41:33.644111Z 11 [Note] [MY-000000] [Repl] event_type: 30 WRITE_ROWS_EVENT 2020-02-10T06:41:33.644149Z 11 [Note] [MY-000000] [Repl] event_time: 1581316823 2020-02-10T06:41:33.644156Z 11 [Note] [MY-000000] [Repl] event_exec_time: 0 2020-02-10T06:41:43.520272Z 0 [Note] [MY-011953] [InnoDB] Page cleaner took 9185ms to flush 3 and evict 0 pages 2020-02-10T06:42:05.982458Z 11 [Note] [MY-000000] [Repl] event_type: 19 TABLE_MAP_EVENT 2020-02-10T06:42:05.982488Z 11 [Note] [MY-000000] [Repl] event_time: 1581316858 2020-02-10T06:42:05.982495Z 11 [Note] [MY-000000] [Repl] event_exec_time: 0 2020-02-10T06:42:06.569345Z 11 [Note] [MY-000000] [Repl] event_type: 30 WRITE_ROWS_EVENT 2020-02-10T06:42:06.569376Z 11 [Note] [MY-000000] [Repl] event_time: 1581316858 2020-02-10T06:42:06.569384Z 11 [Note] [MY-000000] [Repl] event_exec_time: 0 2020-02-10T06:42:16.506176Z 0 [Note] [MY-011953] [InnoDB] Page cleaner took 9352ms to flush 8 and evict 0 pages 2020-02-10T06:42:37.202507Z 11 [Note] [MY-000000] [Repl] event_type: 16 XID_EVENT 2020-02-10T06:42:37.202539Z 11 [Note] [MY-000000] [Repl] event_time: 1581316890 2020-02-10T06:42:37.202546Z 11 [Note] [MY-000000] [Repl] event_exec_time: 0
rpl_slave.cc mts_checkpoint_routine ts = rli->gaq->empty() ? 0 : reinterpret_cast<Slave_job_group *>(rli->gaq->head_queue())->ts; rli->reset_notified_checkpoint(cnt, ts, true); /* end-of "Coordinator::"commit_positions" */
在該模式下備機上存在一個分發隊列gaq,如果gaq為空,則設置last_commit_timestamp為0;如果gaq不為空,則此時維護一個checkpoint點lwm,lwm之前的事務全部在備機上執行完成,此時last_commit_timestamp被更新為lwm所在事務執行完成后的時間。該時間類型為time_t類型。
ptr_group->ts = common_header->when.tv_sec + (time_t)exec_time; // Seconds_behind_master related rli->rli_checkpoint_seqno++;
if (update_timestamp) { mysql_mutex_lock(&data_lock); last_master_timestamp = new_ts; mysql_mutex_unlock(&data_lock); }
在并行複製下,event執行完成之後才會更新last_master_timestamp,所以非并行複製和并行複製下的seconds_behind_master會存在差異。
定義:
• The difference in seconds between the clock of the master and the clock of the slave (second – first). It must be signed as it may be <0 or >0. clock_diff_with_master is computed when the I/O thread starts; for this the I/O thread does a SELECT UNIX_TIMESTAMP() on the master.
• type: long
rpl_slave.cc::get_master_version_and_clock() if (!mysql_real_query(mysql, STRING_WITH_LEN("SELECT UNIX_TIMESTAMP()")) && (master_res= mysql_store_result(mysql)) && (master_row= mysql_fetch_row(master_res))) { mysql_mutex_lock(&mi->data_lock); mi->clock_diff_with_master= (long) (time((time_t*) 0) - strtoul(master_row[0], 0, 10)); DBUG_EXECUTE_IF("dbug.mts.force_clock_diff_eq_0", mi->clock_diff_with_master= 0;); mysql_mutex_unlock(&mi->data_lock); }
該差值僅被計算一次,在master與slave建立聯繫時處理。
定義:
• the difference from the statement’s original start timestamp and the time at which it completed executing.
• type: unsigned long
struct timeval end_time; ulonglong micro_end_time = my_micro_time(); my_micro_time_to_timeval(micro_end_time, &end_time); exec_time = end_time.tv_sec - thd_arg->query_start_in_secs();
(1)time_t time(time_t timer) time_t為long類型,返回的數值僅精確到秒;
(2)int gettimeofday (struct timeval *tv, struct timezone *tz) 可以獲得微秒級的當前時間;
(3)timeval結構
#include <time.h> stuct timeval { time_t tv_sec; /*seconds*/ suseconds_t tv_usec; /*microseconds*/ }
使用seconds_behind_master衡量主備延時只能精確到秒級別,且在某些場景下,seconds_behind_master並不能準確反映主備之間的延時。主備異常時,可以結合seconds_behind_master源碼進行具體分析。
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
轉載請註明出處:葡萄城官網,葡萄城為開發者提供專業的開發工具、解決方案和服務,賦能開發者。
原文出處:https://dzone.com/articles/dry-dont-repeat-yourself
我們之前就發過一篇相關的文章:https://www.cnblogs.com/powertoolsteam/p/12758496.html 其中也提到了包括DRY在內的一些軟件開發的原則。
DRY 是軟件開發的原則之一,其目的主要是為了避免代碼重複,指導開發者盡量以抽象的思維去解決重複,基本上是,當您發現自己一遍又一遍地編寫相同的代碼時,可能會有更好的方法。
讓我們先看一個例子,看看這個例子是否可以改進,以及如何通過重構來避免代碼重複。
這裡有一個簡單的Report類,該類接收一些數據並通過控制台以格式化的方式直接輸出。
我們這裏使用php的一個代碼片段來舉例,相信大家對代碼的結構和想要完成的工作都不難理解,所以為了大家更容易理解,我只對一些下面用到的php函數定義做一個解釋:
class Report
{
public function show(array $data)
{
echo "Report: " . ucwords(strtolower($data["name"])) . "\n";
echo "Product: " . ucwords(strtolower($data["product"])) . "\n";
echo "Start date: " . date("Y/m/d", $data["startDate"]) . "\n";
echo "End date: " . date("Y/m/d", $data["endDate"]) . "\n";
echo "Total: " . $data["total"] . "\n";
echo "Average x day: " . floor($data["total"] / 365) . "\n";
echo "Average x week: " . floor($data["total"] / 52) . "\n";
}
}
可以看到,上面的代碼完成目標是沒有任何問題的。
這時我們對Report類提出一個新的需求:把所有字符串也可以保存到文件中。
我們經過一通複製和粘貼上面的代碼,新建一個名為saveToFile的函數,就可以很快的完成這個需求,代碼如下:
class Report
{
public function show(array $data)
{
echo "Report: " . ucwords(strtolower($data["name"])) . "\n";
echo "Product: " . ucwords(strtolower($data["product"])) . "\n";
echo "Start date: " . date("Y/m/d", $data["startDate"]) . "\n";
echo "End date: " . date("Y/m/d", $data["endDate"]) . "\n";
echo "Total: " . $data["total"] . "\n";
echo "Average x day: " . floor($data["total"] / 365) . "\n";
echo "Average x week: " . floor($data["total"] / 52) . "\n";
echo "Average x month: " . floor($data["total"] / 12) . "\n";
}
public function saveToFile(array $data)
{
$report = '';
$report .= "Report: " . ucwords(strtolower($data["name"])) . "\n";
$report .= "Product: " . ucwords(strtolower($data["product"])) . "\n";
$report .= "Start date: " . date("Y/m/d", $data["startDate"]) . "\n";
$report .= "End date: " . date("Y/m/d", $data["endDate"]) . "\n";
$report .= "Total: " . $data["total"] . "\n";
$report .= "Average x day: " . floor($data["total"] / 365) . "\n";
$report .= "Average x week: " . floor($data["total"] / 52) . "\n";
$report .= "Average x month: " . floor($data["total"] / 12) . "\n";
file_put_contents("./report.txt", $report);
}
}
那麼,上面的代碼能夠滿足我們提出的需求嗎?答案當然“是的”。但是從技術角度來看,這段代碼似乎是有些問題的,它的重複代碼到處都是。無論是對代碼閱讀及後期維護來講,這都是一場噩夢。
所以我們需要進行一些重構,抽象能抽象的方法,讓冗繁的代碼變得更簡潔。
首先,我們對Report類進行功能上的抽象,生成報告並輸出一共可以分為兩個功能,一個只負責創建Report,一個只負責如何處理Report,那麼讓我們開始重構吧。
class Report
{
public function show(array $data)
{
echo $this->createReport($data);
}
public function saveToFile(array $data)
{
file_put_contents("./report.txt", $this->createReport($data));
}
private function createReport(array $data): string
{
$report = '';
$report .= "Report: " . ucwords(strtolower($data["name"])) . "\n";
$report .= "Product: " . ucwords(strtolower($data["product"])) . "\n";
$report .= "Start date: " . date("Y/m/d", $data["startDate"]) . "\n";
$report .= "End date: " . date("Y/m/d", $data["endDate"]) . "\n";
$report .= "Total: " . $data["total"] . "\n";
$report .= "Average x day: " . floor($data["total"] / 365) . "\n";
$report .= "Average x week: " . floor($data["total"] / 52) . "\n";
$report .= "Average x month: " . floor($data["total"] / 12) . "\n";
return $report;
}
}
現在看起來更清楚一些,對嗎?
下面我們還有函數使用重複的問題要解決,例如,Report和Products的名稱函數使用重複:
$report .= "Report: " . ucwords(strtolower($data["name"])) . "\n"; $report .= "Product: " . ucwords(strtolower($data["product"])) . "\n";
我們可以將這些轉換抽象為一個新的函數:
private function normalizeName($name): string
{
return ucwords(strtolower($name));
}
另一個重複:日期格式。
$report .= "Start date: " . date("Y/m/d", $data["startDate"]) . "\n";
$report .= "End date: " . date("Y/m/d", $data["endDate"]) . "\n";
讓我們將其抽象為:
private function formatDate($date): string
{
return date("Y/m/d", $date);
}
最後一個:平均值計算。
$report .= "Average x day: " . floor($data["total"] / 365) . "\n"; $report .= "Average x week: " . floor($data["total"] / 52) . "\n"; $report .= "Average x month: " . floor($data["total"] / 12) . "\n";
儘管計算結果並不完全相同,但執行的操作大家是一致的,所以可以抽象為如下:
private function calculateAverage(array $data, $period): string
{
return floor($data["total"] / $period);
}
所以,經過了一番重構,最終的Report類變為了如下:
class Report
{
public function show(array $data)
{
echo $this->createReport($data);
}
public function saveToFile(array $data)
{
file_put_contents("./report.txt", $this->createReport($data));
}
private function createReport(array $data)
{
$report = '';
$report .= "Report: " . $this->normalizeName($data["name"]) . "\n";
$report .= "Product: " . $this->normalizeName($data["product"]) . "\n";
$report .= "Start date: " . $this->formatDate($data["startDate"]) . "\n";
$report .= "End date: " . $this->formatDate($data["endDate"]) . "\n";
$report .= "Total: " . $data["total"] . "\n";
$report .= "Average x day: " . $this->calculateAverage($data, 365) . "\n";
$report .= "Average x week: " . $this->calculateAverage($data, 52) . "\n";
$report .= "Average x month: " . $this->calculateAverage($data, 12) . "\n";
return $report;
}
private function formatDate($date): string
{
return date("Y/m/d", $date);
}
private function calculateAverage(array $data, $period): string
{
return floor($data["total"] / $period);
}
private function normalizeName($name): string
{
return ucwords(strtolower($name));
}
}
這是一個簡單的例子,實際情況可能比這要更加複雜的多,但我僅想通過這個實例向大家說明一個問題,那就是避免重複代碼的重要性及我們如何通過重構去處理重複代碼。
有時候重複一次相同的代碼可能沒問題,但是當第三次我們寫出相同的代碼時,那就說明是時候重構你的代碼了。
請記住DRY原則,並隨時抱着不要重複自己代碼的想法去完成開發工作。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
在上一篇關於Spring的@Import註解的文章《【Spring註解驅動開發】使用@Import註解給容器中快速導入一個組件》中,我們簡單介紹了如何使用@Import註解給容器中快速導入一個組件,而我們知道,@Import註解總共包含三種使用方法,分別為:直接填class數組方式;ImportSelector方法(重點);ImportBeanDefinitionRegistrar方式。那麼,今天,我們就一起來學習關於@Import註解非常重要的第二種方式:ImportSelector方式。
項目工程源碼已經提交到GitHub:https://github.com/sunshinelyz/spring-annotation
ImportSelector接口是至spring中導入外部配置的核心接口,在SpringBoot的自動化配置和@EnableXXX(功能性註解)都有它的存在。我們先來看一下ImportSelector接口的源碼,如下所示。
package org.springframework.context.annotation;
import java.util.function.Predicate;
import org.springframework.core.type.AnnotationMetadata;
import org.springframework.lang.Nullable;
public interface ImportSelector {
String[] selectImports(AnnotationMetadata importingClassMetadata);
@Nullable
default Predicate<String> getExclusionFilter() {
return null;
}
}
該接口文檔上說的明明白白,其主要作用是收集需要導入的配置類,selectImports()方法的返回值就是我們向Spring容器中導入的類的全類名。如果該接口的實現類同時實現EnvironmentAware, BeanFactoryAware ,BeanClassLoaderAware或者ResourceLoaderAware,那麼在調用其selectImports方法之前先調用上述接口中對應的方法,如果需要在所有的@Configuration處理完在導入時可以實現DeferredImportSelector接口。
在ImportSelector接口的selectImports()方法中,存在一個AnnotationMetadata類型的參數,這個參數能夠獲取到當前標註@Import註解的類的所有註解信息。
注意:如果ImportSelector接口展開講的話,可以單獨寫一篇文章,那我就放在下一篇文章中講吧,這裏就不贅述了,嘿嘿。
首先,我們創建一個MyImportSelector類實現ImportSelector接口,如下所示。
package io.mykit.spring.plugins.register.selector;
import org.springframework.context.annotation.ImportSelector;
import org.springframework.core.type.AnnotationMetadata;
/**
* @author binghe
* @version 1.0.0
* @description 測試@Import註解中使用ImportSelector
* 自定義邏輯,返回需要導入的組件
*/
public class MyImportSelector implements ImportSelector {
/**
* 返回值為需要導入到容器中的bean的全類名數組
* AnnotationMetadata:當前標註@Import註解的類的所有註解信息
*/
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
return new String[0];
}
}
接下來,我們在PersonConfig2類的@Import註解中,導入MyImportSelector類,如下所示。
@Configuration
@Import({Department.class, Employee.class, MyImportSelector.class})
public class PersonConfig2 {
至於使用MyImportSelector導入哪些bean,就需要在MyImportSelector類的selectImports()方法中進行設置了,只要在MyImportSelector類的selectImports()方法中返回要導入的類的全類名(包名+類名)即可。
我們繼承創建兩個Java bean對象,分別為User和Role,如下所示。
package io.mykit.spring.plugins.register.bean;
/**
* @author binghe
* @version 1.0.0
* @description 測試ImportSelector
*/
public class User {
}
package io.mykit.spring.plugins.register.bean;
/**
* @author binghe
* @version 1.0.0
* @description 測試ImportSelector
*/
public class Role {
}
接下來,我們將User類和Role類的全類名返回到MyImportSelector類的selectImports()方法中,此時,MyImportSelector類的selectImports()方法如下所示。
/**
* 返回值為需要導入到容器中的bean的全類名數組
* AnnotationMetadata:當前標註@Import註解的類的所有註解信息
*/
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
return new String[]{
User.class.getName(),
Role.class.getName()
};
}
接下來,我們運行SpringBeanTest類的testAnnotationConfig7()方法,輸出的結果信息如下所示。
org.springframework.context.annotation.internalConfigurationAnnotationProcessor
org.springframework.context.annotation.internalAutowiredAnnotationProcessor
org.springframework.context.annotation.internalCommonAnnotationProcessor
org.springframework.context.event.internalEventListenerProcessor
org.springframework.context.event.internalEventListenerFactory
personConfig2
io.mykit.spring.plugins.register.bean.Department
io.mykit.spring.plugins.register.bean.Employee
io.mykit.spring.plugins.register.bean.User
io.mykit.spring.plugins.register.bean.Role
person
binghe001
可以看到,輸出結果中多出了io.mykit.spring.plugins.register.bean.User和io.mykit.spring.plugins.register.bean.Role。
說明使用ImportSelector已經成功將User類和Role類導入到了Spring容器中。
好了,咱們今天就聊到這兒吧!別忘了給個在看和轉發,讓更多的人看到,一起學習一起進步!!
項目工程源碼已經提交到GitHub:https://github.com/sunshinelyz/spring-annotation
如果覺得文章對你有點幫助,請微信搜索並關注「 冰河技術 」微信公眾號,跟冰河學習Spring註解驅動開發。公眾號回復“spring註解”關鍵字,領取Spring註解驅動開發核心知識圖,讓Spring註解驅動開發不再迷茫。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!