閱讀本文大概需要 14 分鐘。
原文:https://bit.ly/2C67m1C
作者:Jon P Smith
翻譯:王亮
聲明:我翻譯技術文章不是逐句翻譯的,而是根據我自己的理解來表述的。其中可能會去除一些本人實在不知道如何組織但又不影響理解的句子。
這是深入理解 EF Core 系列的第二篇文章。第一篇是關於 EF Core 如何從數據庫讀取數據的;而這一篇是關於 EF Core 如何向數據庫寫入數據的。這是四種數據庫操作 CRUD(新增、讀取、更新和刪除)中的 CUD 部分。
我假設你對 EF Core 已經有了一定的認識,但在深入學習之前,我們先來了解一下如何使用 EF Core,以確保我們已經掌握了一些基本知識。這是一個“深入研究”的課題,所以我準備大量的技術細節,希望我的描述方式你能理解。
本文是“深入理解 EF Core”系列中的第二篇。以下是本系列文章列表:
- 深入理解 EF Core:當 EF Core 從數據庫讀取數據時發生了什麼?
- 深入理解 EF Core:當 EF Core 寫入數據到數據庫時發生了什麼?(本文)
- 深入理解 EF Core:使用查詢過濾器軟刪除數據(敬請期待)
概要
∮. EF Core 可以通過新的或已存在的關聯關係創建一個新的實體。為此,它必須以正確的順序來組織實體類,以便能夠建立各類之間的關聯。這使得開發人員很容易寫出具有複雜關聯關係的類。
∮. 當你調用 EF Core 的 Add 命令來添加一個新條目時,會發生很多事情:
- EF Core 查找添加的類和其他類的所有關聯。對於每個關聯的類,它也會判斷是否需要在數據庫中創建一個新行,或者僅僅鏈接到數據庫中現有的行。
- 它使用現有行的主鍵或偽主鍵為新添加的條目填充外鍵信息。
∮. EF Core 可以監測你從數據庫讀取的類的屬性的變化。它通過已讀入的類的隱藏副本來實現這一點。當你調用 SaveChanges 時,它會將每個讀入的屬性值與其原始值進行比較,並且會創建相應的數據更新命令。
∮. EF Core 的 Remove 方法將刪除參數提供的實體類的主鍵所指向的數據行。如果被刪除的類有外鍵關聯,那麼數據庫會自動進行相關的操作(比如級聯刪除),但你可以更改刪除的規則。
數據寫入基礎
提示:如果你已經對 EF Core 有一定的了解,那麼你可以跳過這一部分,這隻是一個簡單的 EF Core 寫入數據的例子。
在這一節的介紹中,我將描述一下本文用到的數據庫結構,然後給出一個簡單的數據庫寫入示例。下面是類/表的基本關係圖:
這些表被映射到具有類似名稱的類,例如 Book、BookAuthor、Author,這些類的屬性名稱與表的字段名稱相同。由於篇幅有限,我不打算展開來講這些類,但您可以在我的 GitHub 倉庫[1]中查看這些類。
和讀取數據一樣,EF Core 將數據寫入數據庫也是五部分:
- 數據庫服務器,如 SQL server, Sqlite, PostgreSQL…
- 映射到數據庫的一個類或多個類—我將它們稱為實體類
- 一個繼承 EF Core 的 DbContext 的類,該類包含 EF Core 的配置
- 一個創建數據庫的方法
- 最後,向數據庫寫入數據的命令
下面的單元測試代碼來自我的 GitHub 創庫[2],展示了一個簡單的示例,它從現有數據庫中讀取 4 個 Book 實體及其關聯的 BookAuthor 和 Authors 實體。
[Fact]
public void TestWriteTestDataSqliteInMemoryOk()
{
//SETUP
var options = SqliteInMemory.CreateOptions<EfCoreContext>();
using (var context = new EfCoreContext(options))
{
context.Database.EnsureCreated();
//ATTEMPT
var book = new Book
{
Title = "Test",
Reviews = new List<Review>()
};
book.Reviews.Add(new Review { NumStars = 5 });
context.Add(book);
context.SaveChanges();
//VERIFY
var bookWithReview = context.Books
.Include(x => x.Reviews).Single()
bookWithReview.Reviews.Count.ShouldEqual(1);
}
}
現在,如果我們將單元測試代碼對應到上面的 5 部分,結果是這樣的:
- 數據庫服務器——第 5 行:我選擇了一個 Sqlite 數據庫服務器,在本例中是
SqliteInMemory.CreateOptions 方法,它使用我的一個 NuGet 包 EfCore.TestSupport 創建了一個內存數據庫(內存中的數據庫對於單元測試非常有用,因為你可以為這個測試建立一個新的空數據庫)。
- 實體類——和上一篇結構差不多,但是多了一個與 Book 關聯的 Review 實體類。
- 一個繼承 DbContext 的類——第 6 行:EfCoreContext 類繼承了 DbContext 類並配置了從類到數據庫的映射關係(你可以在我的 GitHub 倉庫[3] 中查看該類)。
- 一個創建數據庫的方法——第 8 行:第一次執行時,這句代碼會創建一個新的數據庫,包括創建正確的表、鍵、索引等。EnsureCreated 方法用於單元測試,但對於真實的應用程序,你最好手動執行 EF Core 的 Migration 命令。
- 向數據庫寫入數據的命令——第 17 到 18 行:
- 第 17 行:Add 方法告訴 EF Core 需要將一個 Book 實體及其關係(在本例中,只是一個 Review 實體)寫入數據庫。
- 第 18 行:SaveChange 方法將在數據庫中的 Books 和 Reviews 表中創建新行。
在 //VERIFY 註釋之後的最後幾行用來檢查數據是否已經被寫入數據庫。
在本例中,你向數據庫添加了新的記錄(SQL 的 INSERT INTO 命令)。EF Core 也可以處理更新和刪除數據庫的數據,下一節介紹這個新增示例,然後介紹其他新增、更新和刪除的示例。
寫入數據時數據庫端發生了什麼
我將從創建一個新的 Book 實體類和新的 Review 實體類開始。這兩個類的關係比較簡單。使用上面單元測試的例子,主要代碼如下:
var book = new Book
{
Title = "Test",
Reviews = new List<Review>()
};
book.Reviews.Add(new Review { NumStars = 1 });
context.Add(book);
context.SaveChanges();
為了將這兩個實體添加到數據庫,EF Core 需要這樣做:
- 確定它應該以什麼順序創建這些新行——在本例中,它必須在 Books 表中創建一行,這樣它就擁有 Books 的主鍵。
- 將主鍵複製到與其關聯的外鍵——在本例中,它將 Books 中的主鍵 BookId 複製到 Review 的外鍵。
- 複製數據庫中新創建的數據,以便實體類正確表示數據庫的數據——在這種情況下,它必須複製 BookId 並更新 BookId 屬性,包括 Book 和 Review 實體類以及 Review 實體類的 ReviewId。
下面我們看看上面代碼生成的 SQL 語句:
-- 第一次訪問數據庫
SET NOCOUNT ON;
-- 向數據庫的 Books 表生成一條新數據.
-- 數據庫生成 Books 的主鍵值
INSERT INTO [Books] ([Description], [Title], ...)
VALUES (@p0, @p1, @p2, @p3, @p4, @p5, @p6);
-- 返回主鍵值,檢查並確認數據行是否已添加
SELECT [BookId] FROM [Books]
WHERE @@ROWCOUNT = 1 AND [BookId] = scope_identity();
-- 第二次訪問數據庫
SET NOCOUNT ON;
-- 向數據庫的 Review 表生成一條新數據.
-- 數據庫生成 Review 的主鍵值
INSERT INTO [Review] ([BookId], [Comment], ...)
VALUES (@p7, @p8, @p9, @p10);
-- 返回主鍵值,檢查並確認數據行是否已添加
SELECT [ReviewId] FROM [Review]
WHERE @@ROWCOUNT = 1 AND [ReviewId] = scope_identity();
重要的一點是,EF Core 是按正確的順序處理實體類的,這樣它就可以填充外鍵。這是簡單的例子,但我遇到一個客戶項目的例子是,我不得不建立一個非常複雜的數據組成的 15 個不同的實體類,一些實體類是新增,一些是更新和刪除,EF Core 通過一個 SaveChanges 將把所有工作有序地完成了庫。因此,EF Core 使開發者可以很容易地將複雜的數據寫入數據庫。
我之所以提到這一點,是因為我看到過在 EF Core 代碼中,開發人員多次調用 SaveChanges 方法來從第一個新增命令中獲得主鍵,並把它設置為相關實體的外鍵。例如:
var book = new Book
{
Title = "Test"
};
context.Add(book);
context.SaveChanges();
var review = new Review { BookId = book.BookId, NumStars = 1 }
context.Add(review);
context.SaveChanges();
雖然這代碼效果是一樣的,但它有一個缺陷——如果第二 SaveChanges 失敗,那麼就會發生部分數據更新到數據庫的情況。在某種情況下,這可能不是個問題,但對於像我客戶那種需要保證數據一致的情況,就非常糟糕了。
因此,從中得到的收穫是,您不需要將主鍵複製到外鍵中,因為你可以設置導航屬性,EF Core 將為您挑選出外鍵。因此,如果你認為需要調用兩次 SaveChanges,那麼通常意味着你沒有設置正確的導航屬性來處理這種情況。
寫數據時 DbContext 做了什麼
在上一節中,你看到了 EF Core 在數據庫端做了什麼,現在你要看看在 EF Core 中發生了什麼。大多數情況,你不需要知道,但有時候知道這些是非常重要的。例如,你只能在 SaveChanges 之前捕獲數據的狀態。而對於自增主鍵,你只有在 SaveChanges 被調用之後才能拿到主鍵的值。
與上一個示例相比,這個示例稍微複雜一些。在這個示例中,我想向你展示 EF Core 通過從數據庫中讀取的已有實體類的實例來處理另一個實體類的新實例。下面的代碼創建了一個新的 Book,但 Author 已經在數據庫中了。代碼註明了階段 1、階段 2 和階段 3,然後我用圖表描述每個階段發生的事情。
// 階段 1
var author = context.Authors.First();
var bookAuthor = new BookAuthor { Author = author };
var book = new Book
{
Title = "Test Book",
AuthorsLink = new List<BookAuthor> { bookAuthor }
};
// 階段 2
context.Add(book);
// 階段 3
context.SaveChanges();
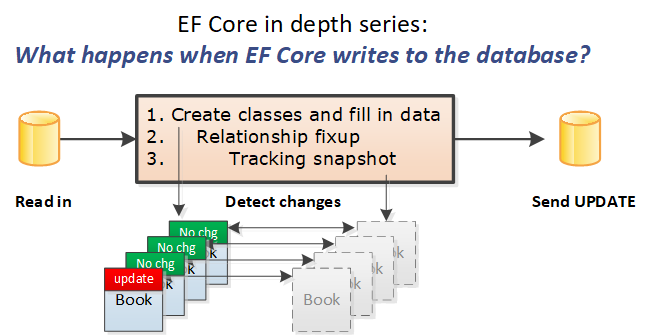
接下來的三個圖向你展示了實體類及其跟蹤數據在每個階段內發生的事情。每個圖显示了其階段結束時的以下數據:
- 流程的每個階段中每個實例的狀態。
- Book 和 BookAuthor 類是棕色的,表示它們是類的新實例,需要添加到數據庫中,而 Author 實體類是藍色的,表示從數據庫中讀取的實例。
- 主鍵和外鍵旁邊的括號是其當前的值。如果一個鍵是 (0),那麼它還沒有被設值。
- 箭頭連線連接的是從導航屬性到其相應實體類。
- 每個階段之間的變化通過粗體文本或箭頭連線的粗線显示。
下圖显示了階段 1 完成后的情況。用於設置一個新的 Book 實體類(左)和一個新的 BookAuthor 實體類(中),後者將 Book 連接接到一個現有的 Author 實體類(右)。
階段 1 這是調用任何 EF Core 方法之前的起點。
下一個圖显示了執行 context.Add(book) 之後的情況。更改部分以粗體显示。
你可能會驚訝於執行 Add 方法時所發生的事情。它將作為參數提供的實體的狀態設置為 Added(在本例中為 Book 實體)。然後通過導航屬性或外鍵值查看與該實體連接的所有實體。對於每個被連接的實體,它會執行以下操作(注意:我不知道它們執行的確切順序)。
- 如果實體未被跟蹤(即其當前狀態為 Detached),則將其狀態設置為 Added——在本例中,它是 BookAuthor 實體。
- 它用主鍵的值填充正確的外鍵的值。如果連接的主鍵還不可用,它將為跟蹤的主鍵和外鍵數據的 CurrentValue 屬性設置一個惟一的負數。你可以在上圖中看到這一點。
- 它填充當前未設值的導航屬性——如上圖中所示。
最後一個階段,即階段 3,是調用 SaveChanges 方法時發生的情況,如圖所示。
在“寫數據時數據庫端發生了什麼”一節中,數據庫更改的任何列都被複制回實體類中,以便實體與數據庫匹配。在本例中,數據更新到數據庫時會把主鍵值更新到 Book 的 BookId 和 BookAuthor 的 BookId。
而且,此次數據庫寫入完成后,涉及的所有實體的狀態都會被更新為 Unchanged。
對於上面這樣一個很長的解釋,很多時候你不需要知道這些細節,你只管它“工作了”就行。但是,當某些東西不能正常工作或者想做一些複雜的事情時,比如記錄實體類的更改,那麼了解這個就非常有用。
更新數據到數據庫時發生了什麼
上面的示例是關於向數據庫添加新記錄的,但是沒有進行更新。在這一節中,我將展示當你更新數據庫中已有的記錄時會發生什麼。這裏使用我上一篇文章“EF Core 讀取數據時發生了什麼?”中講到的查詢例子。
這個更新很簡單,只有三行,但是它在代碼中有三個階段:讀取、更新和保存。
var books = context.Books.ToList();
books.First().PublishedOn = new DateTime(2020, 1, 1);
context.SaveChanges();
下圖展示了這三個階段:
如你所見,你使用的查詢類型很重要——普通查詢加載數據並把返回的實體保存一份“跟蹤快照”,返回的實體類被稱為“被跟蹤的”。如果實體沒有沒跟蹤,則無法更新它。
注意:上一節中的 Author 實體類也是被“跟蹤”的。在這個例子中,Author 的跟蹤狀態告訴 EF Core Author 已經在數據庫中,因此不會再次創建。
因此,如果你更改了加載的跟蹤實體類中的任何屬性,那麼當你調用 SaveChanges 時,它會將所有跟蹤的實體類與它們的跟蹤快照進行比較。對於每個類,它遍歷映射到數據庫字段的所有屬性。這個過程稱為更改跟蹤,它將檢測被跟蹤實體中的每一個更改,包括 Title、PubishedOn 等非關係屬性。
在這個簡單的示例中,只有 4 個 Book 實體,但在實際應用程序中,您可能已經加載了許多相互連接的實體類。在這一點上,比較階段可能需要一段時間。因此,你應該嘗試只加載需要更改的實體類。
注意:EF Core 有一個名為 Update 的命令,它用於更新每個屬性/列的特定情況。EF Core 會自動跟蹤更改,默認只更新已更改的屬性/列。
每次更新都將創建一個 SQL UPDATE 命令,所有這些更新都將在一個 SQL 事務中執行。使用 SQL 事務意味着所有更新都作為一個整體,如果其中任何一部分失敗,那麼事務中的任何數據庫更改都會失效。
從數據庫刪除數據時發生了什麼
CRUD 的最後一部分是 DELETE,這在某些情況很簡單,你只需要調用 context.Remove()。在另一些情況它很複雜,例如,當你刪除另一個實體類依賴的實體類時會發生什麼?
刪除映射到數據庫的實體類的方法是 Remove。舉個例子,我加載一個特定的 Book,然後刪除它。
var book = context.Books
.Single(p => p.Title == "Quantum Networking");
context.Remove(book);
context.SaveChanges();
它的階段如下:
- 加載要刪除的 Book 實體類。這會獲取它的所有屬性數據,但對於刪除,您實際上只需要實體類的主鍵。
- 調用 Remove 方法其實是將 Book 的狀態標記為 Deleted。這些信息會有序地存儲在跟蹤快照中。
- 最後,SaveChanges 創建一個 SQL DELETE 命令,該命令與任何其他數據庫更改一起發送到數據庫,並且在一個 SQL 事務中。
這看起來很簡單,但這裏發生了一些重要的事情,從代碼看並不明顯。原來書名為“Quantum Networking”的書有其他一些實體類關聯到到它——在某個特定的測試用例中,書名為“Quantum Networking”的書關聯到以下實體類:
- 兩個 Review
- 一個 PriceOffer
- 一個 BookAuthor
現在,Review、PriceOffer 和 BookAuthor 實體類只與這本書相關——我們使用術語叫依賴於 Book 實體類。因此,如果這本書被刪除了,那麼這些 Review、PriceOffer 和所關聯的 BookAuthor 數據行也應該被刪除。如果不刪除,那麼數據庫的關聯關係就是不正確的,SQL 數據庫將拋出異常。那麼,為什麼做這個刪除工作?
這裏所發生的都是因為設置了級聯刪除,級聯刪除規則設置了 Books 表和三個依賴表之間的數據庫關係。
下面是 EF Core 為創建 Review 表而生成的 SQL 命令的一個示例:
CREATE TABLE [Review] (
[ReviewId] int NOT NULL IDENTITY,
[VoterName] nvarchar(max) NULL,
[NumStars] int NOT NULL,
[Comment] nvarchar(max) NULL,
[BookId] int NOT NULL,
CONSTRAINT [PK_Review] PRIMARY KEY ([ReviewId]),
CONSTRAINT [FK_Review_Books_BookId] FOREIGN KEY ([BookId])
REFERENCES [Books] ([BookId]) ON DELETE CASCADE
);
CONSTRAINT 語句部分定義了約束規則,該約束表示 Review 通過 BookId 列鏈接到 Books 表中的一行。在該約束的最後,你將看到關於 DELETE 級聯的規則。它告訴數據庫,如果它鏈接的書被刪除了,那麼這個 Review 也應該被刪除。這意味着書的刪除是允許的,因為所有相關的行也被刪除了。
這是非常有用的,但有時候想要更改刪除規則怎麼辦?比如我決定不允許刪除客戶訂單中存在的書。為了做到這一點,我在 DbContext 中添加了一些 EF Core 配置來改變刪除規則,如下:
public class EfCoreContext : DbContext
{
private readonly Guid _userId;
public EfCoreContext(DbContextOptions<EfCoreContext> options)
: base(options)
public DbSet<Book> Books { get; set; }
//… 其它 DbSet<T>
protected override void OnModelCreating(ModelBuilder modelBuilder
{
//… 其它代碼
modelBuilder.Entity<LineItem>()
.HasOne(p => p.ChosenBook)
.WithMany()
.OnDelete(DeleteBehavior.Restrict);
}
}
一旦該配置應用到數據庫,就不會生成 SQL 語句的 DELETE CASCADE。這意味着,如果你試圖刪除客戶訂單中的一本書,那麼數據庫將返回一個錯誤,EF Core 將把這個錯誤變成一個異常。
這使你對正在發生的事情有一個更深的了解,但是還有相當多的內容我沒有介紹(但我在我的書中介紹了)。這裡有一些關於刪除我還沒有提到的事情:
- 實體類之間可以有 required 關係(依賴關係)和 optional 關係,EF Core 為每種類型使用不同的規則。
- EF Core 可以通過設置 DeleteBehavior 來設置級聯刪除規則,當實體類存在循環關聯關係時,可以用它避免一些錯誤——一些數據庫在發現循環刪除時會拋出錯誤。
- 你可以在調用 Remove 方法時提供一個新的只有主鍵有值的類來刪除實體類。這在處理只返回主鍵的場景非常有用。
總結
本文我介紹了 CRUD 中的新增、更新和刪除部分,前一篇文章介紹了讀取部分。
正如您所看到的,使用 EF Core 在數據庫中創建記錄很容易,但內部很複雜。你通常不需要知道 EF Core 或數據庫中發生了什麼,但了解一些細節可以讓你更好地利用 EF Core 的優勢。
更新也很簡單——只需在你讀入的實體類中更改一個或多個屬性,當你調用 SaveChanges 時,EF Core 會找到已更改的數據,並構建 SQL 命令更新數據庫。這適用於非關係屬性(如圖 Book 的 Title 屬性)和導航屬性(你可以在他們的關係)。
最後,我們看了一個刪除案例。同樣很容易使用,但很多處理也是在背後執行的。 另外,敬請關注我的下一篇文章,我將討論所謂的“軟刪除”。如果你設置了一個標誌,EF Core 就不會再看到這個實體類了,它仍然在數據庫中,但它是隱藏的。
希望本文對你有用,也希望你關注本系列的更多文章。
祝你編程愉快!
[1]. https://bit.ly/2MXK3ZY
[2]. https://bit.ly/2Yza7QQ
[3]. https://bit.ly/2Y0UORO
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
※聚甘新