1.簡介
Jmeter官網對邏輯控制器的解釋是:“Logic Controllers determine the order in which Samplers are processed.”。
意思是說,邏輯控制器可以控制採樣器(samplers)的執行順序。由此可知,控制器需要和採樣器一起使用,否則控制器就沒有什麼意義了。放在控制器下面的所有的採樣器都會當做一個整體,執行時也會一起被執行。
JMeter邏輯控制器可以對元件的執行邏輯進行控制,除僅一次控制器外,其他可以嵌套別的種類的邏輯控制器。
2.邏輯控制器分類
JMeter中的Logic Controller分為兩類:
(1)控制測試計劃執行過程中節點的邏輯執行順序,如:Loop Controller、If Controller等;
(2)對測試計劃中的腳本進行分組、方便JMeter統計執行結果以及進行腳本的運行時控制等,如:Throughput Controller、Transaction Controller。
3.預覽邏輯控制器家族
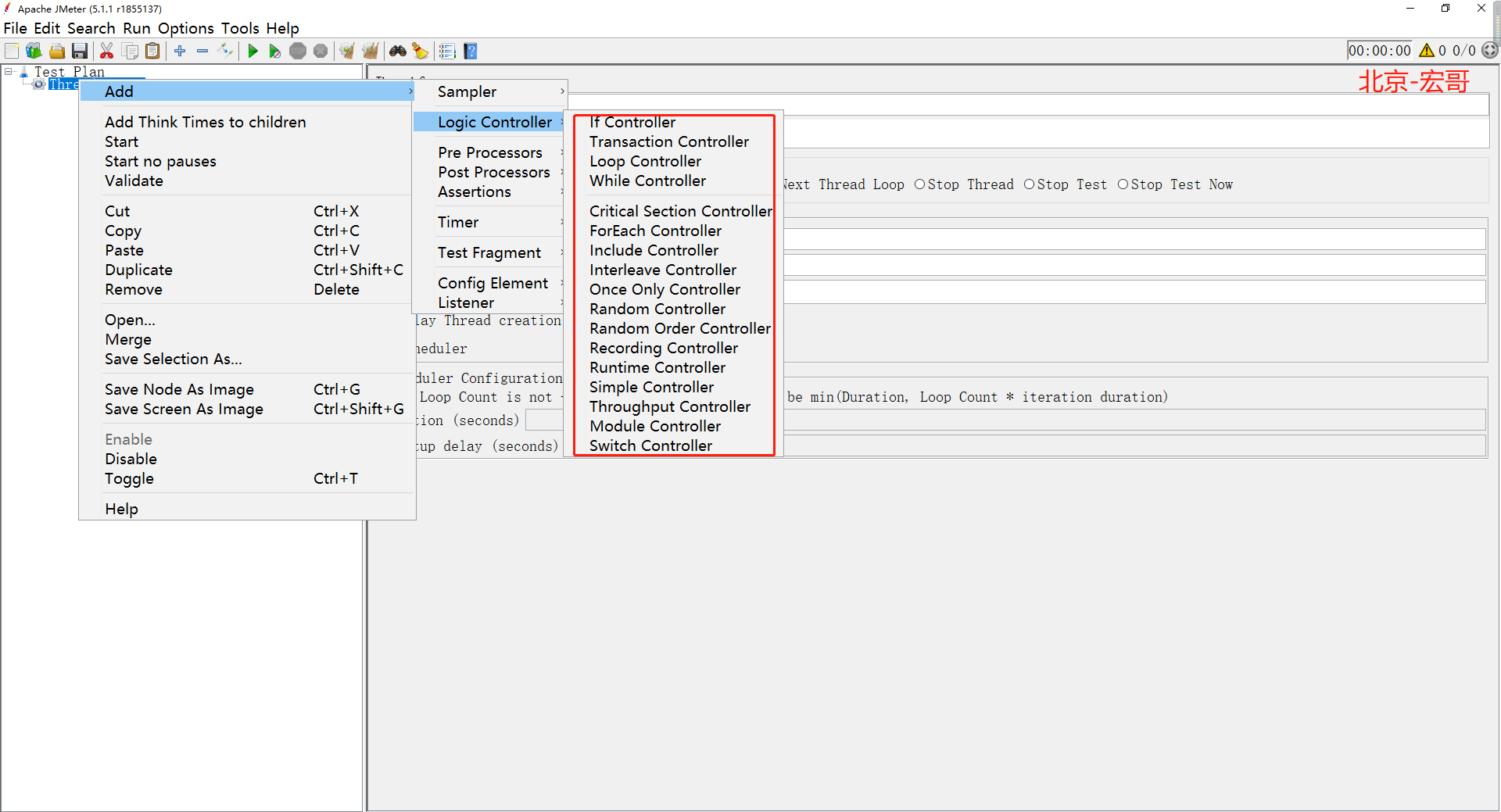
首先我們來看一下JMeter的邏輯控制器,路徑:線程組(用戶)->添加->邏輯控制器(Logic Controller);我們可以清楚地看到JMeter5中共有17個邏輯控制器,如下圖所示:
如果上圖您看得不是很清楚的話,宏哥總結了一個思維導圖,關於JMeter5的邏輯控制器類型,如下圖所示:
通過以上的了解,我們對邏輯控制器有了一個大致的了解和認識。下面宏哥就給小夥伴或則童鞋們分享講解一些通常在工作中會用到的邏輯控制器。
4.常用邏輯控制器詳解
這一小節,宏哥就由上而下地詳細地講解一下常用的邏輯控制器。由於時間關係,宏哥將這部分分為上、中、下三個部分講解。
4.1if Controller
在實際工作中,當使用Jmeter進行接口測試或者性能測試時,有時需要根據不同條件做不同的操作,為了解決這個問題,Jmeter提供了IF控制器。顧名思義,IF控制器實現了代碼中IF的功能,通過判斷表達式的True/False來判定是否執行相應的操作。通過條件判斷下邊的節點執行不執行。
1、我們先來看看這個if Controller長得是啥樣子,路徑:線程組 > 添加 > 邏輯控制器 > 如果 (if) 控制器,如下圖所示:
2、關鍵參數說明如下:
Name:名稱,可以隨意設置,甚至為空;
Comments:註釋,可隨意設置,可以為空。
Expression (must evaluate to true or false) :表達式(值必須是true或false),也就是說,在右邊文本框中輸入的條件值必須是true 或 false,(默認情況下)
Interpret Condition as Variable Expression?:默認勾選項,將條件解釋為變量表達式(需要使用__jexl3 or __groovy 表達式)
Evaluate for all children?:條件作用於每個子項(具體理解宏哥會在後邊實戰篇列舉例子說明),判斷條件是否針對所有子節點,默認不勾選,只在if Controller的入口處判斷一次。
注意:敲黑板!!!敲腦殼啦!!!
1、文本框上的黃色感嘆號,就是提示你,建議採用__jexl3 or __groovy 表達式,以提高性能,也就是默認的方式。
2、if 控制器 只能作用於其下的子項
4.1.1默認用法
1、默認用法,就是採用__jexl3 or __groovy 表達式if 控制器下有一個 訪問北京宏哥的博客園首頁的取樣器,只有if條件滿足時,才會執行該取樣器。採用默認方式,將條件’北京宏哥’==’北京宏哥’,放入 __jexl3表達式中。如下圖所示:
2、如果不知道表達式如何使用,可使用Jmeter 的函數助手,函數助手圖標 > 選擇_jexl3 > 在值的輸入框輸入’北京宏哥’==’北京宏哥’ > 點擊‘生成’ > 全選Ctrl+C複製 > Ctrl+V粘貼到表達式處 如下圖所示:
3、配置好以後,運行JMeter,選擇HTML,然後查看結果樹,如下圖所示:
4.1.2直接輸入條件
1、直接輸入只需要去掉 “Interpret Condition as Variable Expression?” 前面複選框,直接輸入條件: ‘北京宏哥’==’北京宏哥’ 。訪問北京宏哥的博客園的首頁的取樣器將被執行。如下圖所示:
2、配置好以後,運行JMeter,選擇HTML,然後查看結果樹,如下圖所示:
4.13條件中使用變量
我們在日常工作中在很多的測試場景下,需要根據用戶變量或者上一個取樣器的返回值來進行條件判斷,從而決定是否需要執行某一個的取樣器。
1、首先我們新增一個用戶變量:北京宏哥。條件:北京宏哥 的值為 宏哥 的時候,才執行訪問北京宏哥博客園的首頁的取樣器。如下圖所示:
用戶變量及配置,如下圖所示:
2、IF Controller及配置,或者可以用表達式:${__jexl3(‘${北京宏哥}’==’宏哥’ ,)}。如下圖所示:
4.1.4Evaluate for all children? 的用法
1、宏哥在上面的小節中講解和分享了在條件中如何使用變量,我們假設一種測試場景:如果 if 控制器下的取樣器執行后,改變了該變量的值,if 控制器下 其後的取樣器還會被繼續執行嗎?跟隨宏哥一起來看看下面的列子:
2、改變“北京宏哥”變量的值為“北京宏哥”,如下圖所示:
3、JMeter執行過程的邏輯分析:
(1) if 控制器下 有 3 個取樣器,變量 北京宏哥 的初始值為 宏哥,if 控制器的條件為:${__jexl3(“${北京宏哥}”==”宏哥”,)}。
(2)開始執行的時候滿足條件,那麼按理說應該執行 訪問博客園首頁 、訪問北京宏哥的博客園首頁、訪問宏哥的JMeter系列文章 3個取樣器,
(3)但是 訪問北京宏哥的博客園首頁 執行后,將 北京宏哥 的值變了 北京宏哥,已經不能滿足 “${北京宏哥}”==”宏哥” 條件。
(4)所以 訪問宏哥的JMeter系列文章 這個取樣器不會被執行。
4、運行JMeter,查看結果樹,對比運行結果和宏哥分析的一致,如下圖所示:
5、如果這個時候,去掉 Evaluate for all children? 的勾選,會發生什麼呢,大家可以自己動手試試。修改後記得點擊“保存”。下邊是宏哥的執行結果,如下下圖所示:
另外,如果時字符串必須要用引號,變量都認為是字符串的形式,如:${__jexl3(“${北京宏哥}”==”宏哥”,)}。
4.2Transaction Controller
事務響應時間是我們衡量業務性能的主要指標,事務控制器可以把其他節點下的取樣器執行消耗時間累加在一起,便於統計。同時對每一個取樣器的執行時間進行統計。
如果事務控制器下的取樣器有多個,只有當所有的取樣器都運行成功,整個事務控制器定義的事物才算成功。
用於將Test Plan中的特定部分組織成一個Transaction,JMeter中Transaction的作用在於,可以針對Transaction統計其響應時間、吞吐量等。比如說,一個用戶操作可能需要多個Sampler來模擬,此時使用Transaction Controller,可以更準確地得到該用戶操作的性能指標,如響應時間等。這個時間包含該控制器範圍內的所有處理時間,而不僅僅是採樣器的。
這個就非常有用了。我們前面有提到過事務的概念,有時候我們不關心單個請求的響應時間,而是關心一組相關請求的整體響應時間,怎麼來統計呢?就需要藉助事務這個概念,把這組請求,放到一個事務控制器下面。
1、我們先來看看這個Transaction Controller長得是啥樣子,路徑:線程組 > 添加 > 邏輯控制器 > 事務控制器,如下圖所示:
2、關鍵參數說明如下:
Name:名稱,可以隨意設置,甚至為空;
Comments:註釋,可隨意設置,可以為空;
generate parent sample:選擇是否生成一個父取樣器;
include duration of timer and pre-post processors in generated samle:是否包含定時器,選擇將在取樣器前與后加上延時。(宏哥建議大家不要勾選,否則統計就比較麻煩了,還需要你扣除延時)
4.2.1generate parent sample用法
1、宏哥列舉一個測試場景:我們需要了解 訪問博客園首頁 訪問北京宏哥的博客園首頁這兩個請求的單個請求的響應時間,那麼就來看看如下實例。
(1)單個請求,那麼不勾選generate parent sample,如下圖所示:
2、運行JMeter,查看聚合報告的單個請求的響應時間,如下圖所示:
1、宏哥列舉一個測試場景:我們需要了解 訪問博客園首頁 訪問北京宏哥的博客園首頁這兩個請求作為一組請求的響應時間,那麼就來看看如下實例。
(1)一組請求,那麼勾選generate parent sample,如下圖所示:
2、運行JMeter,查看聚合報告的一組請求的響應時間,如下圖所示:
4.3Loop Controller
循環控制器可以控制在其節點下的元件的執行次數,可以是具體数字,也可以是變量。
1、我們先來看看這個Loop Controller長得是啥樣子,默認循環一次。路徑:線程組 > 添加 > 邏輯控制器 > 循環控制器,如下圖所示:
2、關鍵參數說明如下:
Name:名稱,可以隨意設置,甚至為空;
Comments:註釋,可隨意設置,可以為空;
Forever:勾選上這一項表示一直循環下去。
注意:敲黑板,敲腦殼!!!
如果同時設置了線程組的循環次數和循環控制器的循環次數,那循環控制器的子節點運行的次數為兩個數值相乘的結果。
4.3.1Thread Group和循環控制器的區別
1、現在宏哥準備兩個請求,設置線程組1個線程,5次loop,下邊有一個請求:訪問北京宏哥的博客園首頁 一個Loop Controller(設置2次loop),下邊有一個請求:訪問博客園首頁
(1)線程組,如下圖所示:
(2)循環控制器,如下圖所示:
2、運行JMeter,查看結果樹,為了清楚地看出結果,宏哥將第一個請求故意配置成失敗的;如下圖所示:
從上邊的結果可以看出:
(1)如果同時設置了線程組的循環次數和循環控制器的循環次數,那循環控制器的子節點運行的次數為兩個數值相乘的結果。
(2)運行順序是:先執行線程組裡的循環,再執行循環控制器里的循環。
4.4While Controller
While條件控制器,其節點下的元件將一直運行直到While 條件為false。
1、我們先來看看這個While Controller長得是啥樣子,默認循環一次。路徑:線程組 > 添加 > 邏輯控制器 > While控制器,如下圖所示:
2、關鍵參數說明如下:
Name:名稱,可以隨意設置,甚至為空;
Comments:註釋,可隨意設置,可以為空;
Condition:接受變量表達式與變量。條件為 Flase 的時候,才會跳出 While 循環,否則一直執行 While 控制器下的元件。
3、While控制器提供三個常量
(1)Blank:當循環中最後一個取樣器失敗后停止
(2)LAST:當循換前有取樣器失敗,不進入循環
(3)Otherwise:當判斷條件為false時,停止循環
4.4.1Blank
1、不填(空):當 While 控制器下最後一個樣例執行失敗后 跳出循環,如下圖所示:
2、運行JMeter,查看結果樹,(你可以通過鼠標拖動最後失敗的取樣器,移動到第一個或者第二個位置的時候,運行JMeter后,會發現在一直運行);如下圖所示:
4.4.2LAST
LAST :當 While 控制器下最後一個樣例執行失敗后 跳出循環,如果 While 控制器 前一個樣例執行失敗,則不會進入While循環,也就是不會執行While控制器下的樣例。
1、取樣器樹還是上邊的位置和順序。這次我們在While控制器表達式處填寫:LAST,如下圖所示:
2、運行JMeter,查看結果樹,(你可以通過鼠標拖動最後失敗的取樣器,移動到第一個或者第二個位置的時候,運行JMeter后,會發現在一直運行);細心的你可以發現循環只跑一遍,與不填 的結果是一樣的如下圖所示:
3、但是輸入LAST的時候,還會出現一個結果,那就是:如果While 控制器 的前一個樣例執行失敗,則不會進入While 控制器
在While 控制器 前面 添加兩個取樣器:取樣器1 訪問百度,取樣器2 訪問北京宏哥 使取樣器2 訪問北京宏哥 執行失敗。取樣器2必須在While控制器前邊且執行失敗。如下圖所示:
4、運行JMeter,查看結果樹,執行結果發現,取樣器1、取樣器2 執行了,但沒有進入While 控制器,如下圖所示:
4.4.3Otherwise
自定義條件:值為True 或 False的函數/變量/屬性 表達式;類似前邊講解的IF控制器,宏哥這裏就照貓畫虎的舉個例子。
1、用戶自定義變量,變量名:北京宏哥,變量值:true,如下圖所示:
2、While控制器配置,取到變量的值:${北京宏哥},填寫到表達式的地方,如下圖所示:
3、JMeter執行過程的邏輯分析:
(1)北京宏哥用戶(線程組)下 有 1 個用戶自定義變量,變量 北京宏哥 的值為 true,While控制器的條件為:${北京宏哥} 取到的值始終是 true。
(2)所以一旦開始執行始終滿足條件,那麼按理說就應該一直執行 訪問博客園首頁 、訪問北京宏哥的博客園首頁、訪問宏哥的JMeter系列文章 3個取樣器,
4、運行JMeter,查看結果樹,(運行JMeter后,會發現在一直運行),對比一下,與宏哥的分析是不是高度一致哈;如下圖所示:
5.小結
好了,今天關於邏輯控制器的上篇就講解到這裏,這一篇主要介紹了 IF控制器、Transaction Controller、Loop Controller和While控制器。
您的肯定就是我進步的動力。如果你感覺還不錯,就請鼓勵一下吧!記得隨手點波 推薦 不要忘記哦!!!
別忘了點 推薦 留下您來過的痕迹
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?