這個年代,對中年人販賣焦慮是件普遍的事情,尤其是對程序員。35歲左右都是一個坎,不管是國內的華為、阿里,還是國外的facebook,這種焦慮和恐慌逼得程序員不得不時刻充電。學習的方式有很多,做項目、線下線上課程、看書、看博客、看源碼等等。
相比其他方法,看書(尤其是經典書籍)的好處在於,知識點比較系統全面,講解比較清楚,質量也有所保證。
這一兩年,也看了一些書,技術和非技術都有,可是回頭想想,記得多少,又有哪些用到了實處,似乎很少。於是,懷疑哪裡出了問題,是年紀大了記性不好?還是讀書的方法出了問題?
因此,為了更好的閱讀,我們就得先掌握科學、高效閱讀的方法,而就是指導我們科學閱讀的利器。
“how to read a book” is a metabook about how to read a book
本文地址:
主動閱讀
how to read a book反覆強調 主動閱讀:為了學習知識、增進理解而閱讀,而不是為了獲得諮詢。獲取信息、諮詢所需要的理解力恰好是讀者擁有的,而為了知識而進行的主動閱讀是需要讀者的努力,當然也只有這樣讀者才能成長。
閱讀是作者與讀者的交流,作者拋出問題,然後給出答案,而讀者需要去判斷作者給出的答案是否合理,這個過程就需要讀者的思考。
那麼,怎麼才算是主動閱讀呢,要做到主動閱讀,至少要回答以下四個問題:
- 整體來說,這本書在討論什麼問題
- 圍繞核心問題,作者有哪些主要的想法、論點
- 作者所述是否合理,是部分合理,還是全部合理。當然,這一點的基礎是讀者能回答出上兩個問題
- 這本書與讀者有何關係,有何啟發,如何運用
關於跳出舒適圈
主動閱讀強調的是需要努力才能掌握知識的閱讀,其實換一種流行的說法就是跳出舒適圈,需要每次都有所進步。
不過,是否跳出舒適圈並不是簡單的0或者1問題,跳出多遠呢?比如閱讀一本全新領域的書,基本上都看不懂,強迫自己看下去也很痛苦。
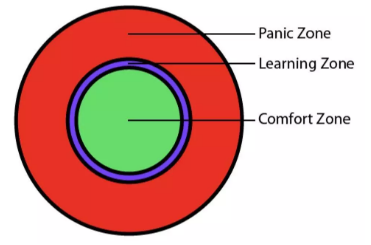
恰好前一段時間在簡書上看到一篇很有意思的文章: 。在這篇文章中,首先是給出下面這張圖:
從中可以看到,對於學習這件事情,自內而外分三個區
- 舒適區,conform zone
- 學習區,learning zone
- 恐慌區,panic zone
閱讀的舒適區,大約就是為了獲取諮詢、信息而進行的閱讀。而主動閱讀就得跳出舒適區,需要小心意的是,別跳太遠,一下跳到恐慌區反而會有負作用。
那麼,跳多遠是合適的呢,這篇文章中參考了機器學習的一個實驗,指出15.87%是個理想值。就是說,閱讀的時候,應該有85%的內容是讀者能理解的,這樣學習起來既愉快,而且效率也最高。
當然,這個具體的數值因人而異,至少說,如果略讀一本書,大多數的概念都不了解,那麼可能這本書對現階段的你可能不是最好的選擇。
閱讀的四個層次
閱讀的層級,按對閱讀者的要求從低到高排序,分別是:
- 基礎閱讀(elementary reading)
- 檢視閱讀(inspectional reading)
- 分析閱讀(analytical reading)
- 主題閱讀(syntopical reading)
基礎閱讀的典型問題是,“這個句子在說什麼?”基礎閱讀的能力,應該是在基礎教育的時候就培養的,而且對於絕大多數人來說應該不存在問題。不幸的是,對於程序員–需要閱讀英文原版書籍、論文的程序員–來說,這有時候確實是個問題。雖然筆者也過了英語六級,但是在閱讀英文資料的時候還是可能因為詞彙、語法而卡殼。
檢視閱讀其實就是略讀、粗讀,在較短的時間內掌握一本書的重點、整體架構。典型問題就是:“這本書在談什麼?”或者:“這本書的架構如何?”或是:“這本書包含哪些部分?”
而分析閱讀是全盤的閱讀、完整的閱讀,或是說優質的閱讀。也就是我們常說的,要把一本書讀厚。分析閱讀需要反覆的咀嚼、消化,自然是非常耗時間的,因此我們進行分析閱讀的書籍應該是經過挑選的經典書籍。
最後的主題閱讀,其實就是帶着問題去閱讀。前面的檢視閱讀和分析閱讀都是指閱讀某一本書,而主題閱讀通常需要閱讀好幾本書,才能從不同角度去思考、解決一個問題。
下面依次簡單介紹檢視閱讀、分析閱讀、主題閱讀的基本方法、規則。
檢視閱讀
檢視閱讀既可以作為獨立的閱讀方式,又可以作為分析閱讀或者主題閱讀的前置步驟。
檢視閱讀的第一個階段是有系統的略讀或粗讀。
- 先看書名頁,然後如果有序就先看序
看完序章之後,其實就對這本書的主題有了概念,可以為這本書進行分類了。 - 研究目錄頁,對這本書的基本架構做概括性的理解
- 如果書中附有索引,也要檢閱一下。
- 如果那是本包着書衣的新書,不妨讀一下出版者的介紹。
- 從你對一本書目錄很概略,甚至有點模糊的印象當中,開始挑幾個看來跟主題息息相關的篇章來看。如果這些篇章在開頭或結尾有摘要說明(很多會有),就要仔細地閱讀這些說明。
- 最重要的是,不要忽略最後的兩三頁,很少有作者能拒絕這樣的誘惑,而不在結尾幾頁將自己認為既新又重要的觀點重新整理一遍的。
在how to read a book一書中,每章節的最後,作者都會進行總結、概括。
通過上述步驟,就可以從主體、架構上了解一本書,至少能夠判斷,這本書是否值得花時間更深入的閱讀。
檢視閱讀的第二個階段是粗淺的閱讀,也就是說頭到尾先快速的讀完一遍,關注的重點在於理解的部分,不要因為暫時不能理解的部分而停頓,這樣閱讀一遍之後也是會很有收益的。
分析閱讀
分析閱讀的第一階段,或,找出一本書在談些什麼的四個規則:
第一個規則:依照書本的種類與主題作分類。
how to read a book對書籍分類是這樣的:首先按照是否是虛構,分成小說類和論說類。論說類的書籍是為了傳遞知識,也是探討的重點。
對於論說類,又分為實用性作品和理論性作品。理論性的作品是在教你這是什麼,實用性的作品在教你如何去做你想要做的事,或你認為應該做的事。
how to read a book本身就是一本實用性的書籍
第二個規則:用最簡短的句子說出整本書在談些什麼。
第二個規則,就是要能說出整本書的大意,整體上來把握一本書。這一部分,通過閱讀書目和序章基本上就能有答案
第三個規則:按照順序與關係,列出全書的重要部分。將全書的綱要擬出來之後,再將各個部分的綱要也一一列出。
一本好書,就像一棟好房子,每個部分都要很有秩序地排列起來。每個重要部分都要有一定的獨立性。
這有點類似金字塔原理中的MECE(Mutually Exclusive Collectively Exhaustive),架構良好的書籍也會按照符合邏輯的順序展示主題相關的每一個部分。
第四個規則:找出作者在問的問題,或作者想要解決的問題。
一本書的作者在開始寫作時,都是有一個問題或一連串的問題,而這本書的內容就是一個答案,或許多答案。在分析閱讀的第一個階段,讀者都明白作者將解答的是什麼樣的問題。
分析閱讀的第二個階段,或找出一本書到底在詳細說什麼的規則(詮釋一本書的內容):
第五規則:詮釋作者使用的關鍵字,與作者達成共識。
同一個詞彙,在不同的語境下有不同的語義,比如“事務”這個詞語,不同領域裏面的含義千差萬別。在特定的領域裏面,我們常常稱這種專門用語及特殊字彙為術語。為了搞清楚一本書在說些啥,首先得找出這些術語,然後分辨出術語在這本書當中最精確的意義。
如何找出術語呢,如果比較熟悉書籍所在領域,那麼自然就能找出這些專門的詞彙;反過來,只要看到不是平常慣見的詞彙,就會知道那些字一定是專門用語。
如何衡量是否有作者就某個術語的精確意義達成了共識呢?讀者可以用自己的話語來解釋這個術語。
第六個規則:從最重要的句子中抓出作者的重要主旨。
主旨,也是一種聲明。那是作者在表達他對某件事的判斷。主旨所聲明的是知識或觀點。這也是為什麼我們說表達這種聲明的句子是敘述句(declarative),而提出問題的句子是疑問句(interrogative)
如何判斷自己是否吸收了一本書的主旨呢?有以下方法
- 能否用自己的語言重新表達?
- 舉出一個自己所經歷過的主旨所形容的經驗,或與主旨有某種相關的經驗?
- 就作者所闡述的特殊情況,說明其中通用於一般的道理?
第七個規則:找出作者的論述,重新架構這些論述的前因後果,以明白作者的主張。
第八規則:確定作者已經解決了哪些問題,還有哪些是未解決的。在未解決的問題中,確定哪些是作者認為自己無法解決的問題。
分析閱讀的第三階段:像是溝通知識一樣地評論一本書的規則
第九規則:除非你已經完成大綱架構,也能詮釋整本書了,否則不要輕易批評。(在你說出:“我讀懂了!”之前,不要說你同意、不同意或暫緩評論。)
第十規則:不要爭強好勝,非辯到底不可。
第十一規則:在說出評論之前,你要能證明自己區別得出真正的知識與個人觀點的不同。
主題閱讀
主題閱讀是閱讀的最高層級,即帶着某個特定問題去大量閱讀相關書籍中的相關章節。檢視閱讀和分析閱讀都是以書為中心,而主題閱讀是以特定問題為核心。
在主題閱讀中有兩個階段。一個是準備階段,另一個是主題閱讀本身。
主題閱讀的準備階段是為了觀察、選擇研究範圍,一定程度上會用到檢視閱讀的規則
- 針對你要研究的主題,設計一份試驗性的書目。你可以參考圖書館目錄、專家的建議與書中的書目索引。
- 瀏覽這份書目上所有的書,確定哪些與你的主題相關,並就你的主題建立起清楚的概念。
主題閱讀的第二個階段:閱讀所有第一階段收集到的書籍
- 瀏覽所有在第一階段被認定與你主題相關的書,找出最相關的章節。
- 根據主題創造出一套中立的詞彙,帶引作者與你達成共識——無論作者是否實際用到這些詞彙,所有的作者,或至少絕大部分的作者都可以用這套詞彙來詮釋。
- 建立一个中立的主旨,列出一連串的問題——無論作者是否明白談過這些問題,所有的作者,或者至少大多數的作者都要能解讀為針對這些問題提供了他們的回答。
- 界定主要及次要的議題。然後將作者針對各個問題的不同意見整理陳列在各個議題之旁。你要記住,各個作者之間或之中,不見得一定存在着某個議題。有時候,你需要針對一些不是作者主要關心範圍的事情,把他的觀點解讀,才能建構出這種議題。
- 分析這些討論。這得把問題和議題按順序排列,以求突顯主題。比較有共通性的議題,要放在比較沒有共通性的議題之前。各個議題之間的關係也要清楚地界定出來。
注意:理想上,要一直保持對話式的疏離與客觀。要做到這一點,每當你要解讀某個作家對一個議題的觀點時,必須從他自己的文章中引一段話來並列。
如何實踐閱讀
在how to read a book的最後一章 “閱讀與心智的成長”, 有兩個觀點,個人是深表認同的
- 如果你所讀的書都在你的能力範圍之內,你就沒法提升自己的閱讀能力。你必須能操縱超越你能力的書,或所說的,閱讀超越你頭腦的書
- 如果讀者閱讀了一本實用的書,並接受作者的觀點,認同他的建議是適當又有效的,那麼讀者一定要照着這樣的建議行事
第一點其實就是要從舒適區跳到學習區,主動閱讀。關於這一點,已經在本文第一章進行了討論。
第二點,就是學以致用。
我們常說,聽過很多道理,卻依然過不好這一生,也許道理已經懂了,但是沒有落到實處,自然不會有任何改變。對於閱讀更是如此,閱讀相比教學而言,更需要學習者的主動,而且閱讀本身比較慢,也很少存在很強烈的時間壓力和考核目標,如果讀者不主動去刻意使用,那麼大概率過一段時間就忘了。
實用性書籍閱讀
前面對書籍分為了虛構類、實用類、理論類。對於程序員的技術閱讀而言,大多時候都是實用類。閱讀的目標都是為了提高自己的能力,將知識應用到工作中。
在閱讀任何一種實用書時,一定要問自己兩個主要的問題。
第一:作者的目的是什麼?
第二:他建議用什麼方法達到這個目的?
比如筆者之前閱讀了《clean code》這本書,作者的目的就是讓我們認識到代碼整潔的重要性以及如何寫出整潔的代碼。而如何寫出整潔代碼呢,作者先從小到大,指出應該如何命名、寫好函數、寫好注意、寫好一個類;然後再給出一個完整的逐步改善的列子。
在how to read a book中,給出了主動閱讀一本書,至少要回答的四個問題,這裏回顧一下
- 整體來說,這本書在討論什麼問題
- 圍繞核心問題,作者有哪些主要的想法、論點
- 作者所述是否合理,是部分合理,還是全部合理
- 這本書與讀者有何關係,有何啟發,如何運用
這四點對於閱讀適用類書籍來說非常合適
第一點,實用性書籍討論的問題,其實就是作者作者寫這本書的目的,即希望讀者去做到的事情。
第二點,實用性書籍中的主要想法和論點,即使就是作者闡釋為什麼要這麼做、如何達到這個目的。
第三點,作者所述是否正確、合理,對於實用性的書籍,更多的是你是否認同作者的目的、以及達成目的的方法。
第四點,對於實用性書籍,如果你認同了作者的說法,那麼就得採取行動才行。
上面四點,最難的就是落實,學以致用,知行合一。
刻意練習
很多時候,我們看完一本書,或者看完一個在線課程,我們就認為掌握了知識。其實不然,掌握知識需要知識的內隱化,讓這部分知識成為習慣、潛意識。這個過程並沒有捷徑可走,需要不斷的練習,只不過一些知識、技能是每天都能用到的,而有一些則較少用到,對於後者,則需要專門安排時間來刻意練習。
比如,當我們看完了how to read a book這本書,想要掌握分析閱讀的技能。那麼需要按照規則一步步執行,這個過程中可能就要求也不同的速度、注意力反覆閱讀一本書,也許會讓人覺得麻煩 — 為什麼不看一遍就搞定?對於一個熟練掌握分析閱讀能力的人來說,也許確實可以在一遍閱讀中同時遵守這些規則,但前提是已經熟練掌握了每一個規則。
就像學游泳一樣,對於新手,會花大量的時間來練習移臂、擺腿、換氣,一遍又一遍的重複這些枯燥的動作。但對於老手來說,似乎從來不會刻意注意這些動作,如果注意這些動作,反而還游不好。但是,為了要忘掉這些單一的動作,一開始就必須先分別學會每一個單一的動作,只有這樣,你才能將所有的動作連結起來。
如何刻意練習 實用性書籍閱讀這件事情呢?RIA拆書法是個可行的辦法:
RIA拆書法
RIA拆書法來自一書,不過本人沒有讀過這本書,對於RIA拆書法,感覺這篇文章 介紹得很清楚。
如圖所示,RIA分為四個階段
- R: 找到有價值、感興趣的片段
- I:用自己的語言重述知識
- A1:描述自己的相關經驗
- A2:思考自己怎麼應用,指定計劃
其中,I、A1、A2這三步要求讀者用不同顏色的便簽做記錄,貼在原書頁處。
其實,這幾點都是how to read a book中的規則的具體體現,比如I和A1,其實就是分析閱讀的第六個規則中衡量自己是否掌握了主旨的方法,而A2則是閱讀實用性書籍需要回答的第四個問題。
RIA的好處在於通過這幾個標籤強迫讀者停下來進行思考、記錄,將思考的結果和原問題保持在同一個地方,方便回顧;不同顏色的便簽也是很好的視覺刺激,方便記憶。
最後,RIA拆書法還要求:看完一本書後,把所有的A2便簽拿出來貼在牆上,提醒自己日後應用,落實行動。
所以RIA的正式貫徹了學習 — 思考 — 實踐這個流程,值得借鑒 參考。
自我實踐:讀好下一本書
上面的內容,其實都是我所學到的“如何閱讀一本(實用性)書籍”的知識,具體怎麼落實呢?打算用《金字塔原理》這本書來實踐,這本書聽聞已久,也簡單知道其內容,但還沒有仔細閱讀過。
怎麼閱讀呢,會按照以下步驟(checklist)
- 思考清楚閱讀一本書的目的是什麼,以此決定是檢視閱讀、分析閱讀還是主題閱讀,甚至決定要不要閱讀這本書(閱讀書籍不一定是解決問題的最有效方法,或者當前自己的知識貯備還無法閱讀這麼一本書)。以下步驟假設均決定分析閱讀
- 如果確定要分析閱讀,那麼應按照smart原則來設立讀這本書的目標。核心在於輸出是怎麼樣的,具體的閱讀計劃(每天讀多少,什麼時候讀完)
- 利用檢視閱讀,找出這本書的主旨(作者要探討的問題)、主體架構、問題的簡要答案。檢視閱讀也會幫助去調整閱讀計劃。檢視閱讀注重以下幾部分
- 書目、序章
- 目錄,每章總結
- 結語
- 分析閱讀這本書,做好筆記。分析閱讀注意事項:
- 使用8020法則,嘗試按照重要性挑戰閱讀速度、時間分配,不重要的章節速讀
- 核心的部分採用RIA方法(複述、聯想、如何應用)
- 分析閱讀完成之後,回答閱讀一本實用性書籍應該回答的四個問題。此時可參考輔助閱讀,看看其他讀者的總結和思考。
- 加強記憶、內化,分為三步:
- 筆記:在閱讀的過程中就應完成;
- 博客、腦圖二選一,對筆記進行凝練,深入思考;
- 分享、實踐二選一,理論知識一般適用於分享,而實用性知識盡量去實踐。
- 如何實踐落實,總結RIA方法中所有A2,整理成一個checklist(电子版或者紙版),定期逐項check是否有做到
爭取年內搞定!
references
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
