環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
摘錄自2020年1月21日自由時報報導
墨西哥米卻肯州(Michoacan state)21日傳出,在當地設立帝王斑蝶保育園區羅薩利歐(El Rosario)的蝴蝶保育專家戈麥茲(Homero Gomez)已失蹤超過1週,外界擔憂他已經慘遭犯罪集團毒手。
據 ,戈麥茲本月13日早晨發訊息推廣蝴蝶保育後,手機即失去訊號,家人通報失蹤至今已超過1週,外界擔憂他恐怕已慘遭犯罪集團綁架或毒手。目前已有超過200名志工開始協尋戈麥茲,人權團體也請求官方加強搜索戈麥茲的下落,同時調查他的失蹤是否與盜伐集團有關聯。墨西哥自2006年起已有超過6萬人失蹤,其中不乏人權工作者及環境保育者。
截圖自戈麥茲
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
摘錄自2020年01月21日中央社報導
美國總統川普今(21日)在瑞士達佛斯(Davos)的年度世界經濟論壇(WEF)上把矛頭對準環保「長年厄運先知」,並表示對氣候危機的警告是「愚蠢的」。
川普在瑞士滑雪勝地第50屆世界經濟論壇發表主題演說,吹捧化石燃料、放鬆管制及蓬勃發展的美國經濟,跟瑞典環保少女童貝里(Greta Thunberg)等人提出的可怕警告,形成鮮明對比。
童貝里才在同場論壇上譴責,各國政府在扭轉氣候變遷上,「基本上什麼也沒做」。川普在幾小時後的演說中表示:「我們必須拒絕長年厄運先知,以及他們的末日預言。」
川普登上達佛斯講台前,瑞士總統剛在演說中呼籲全世界關心地球,但川普卻宣揚美國是「石油及天然氣第一大出口國」。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
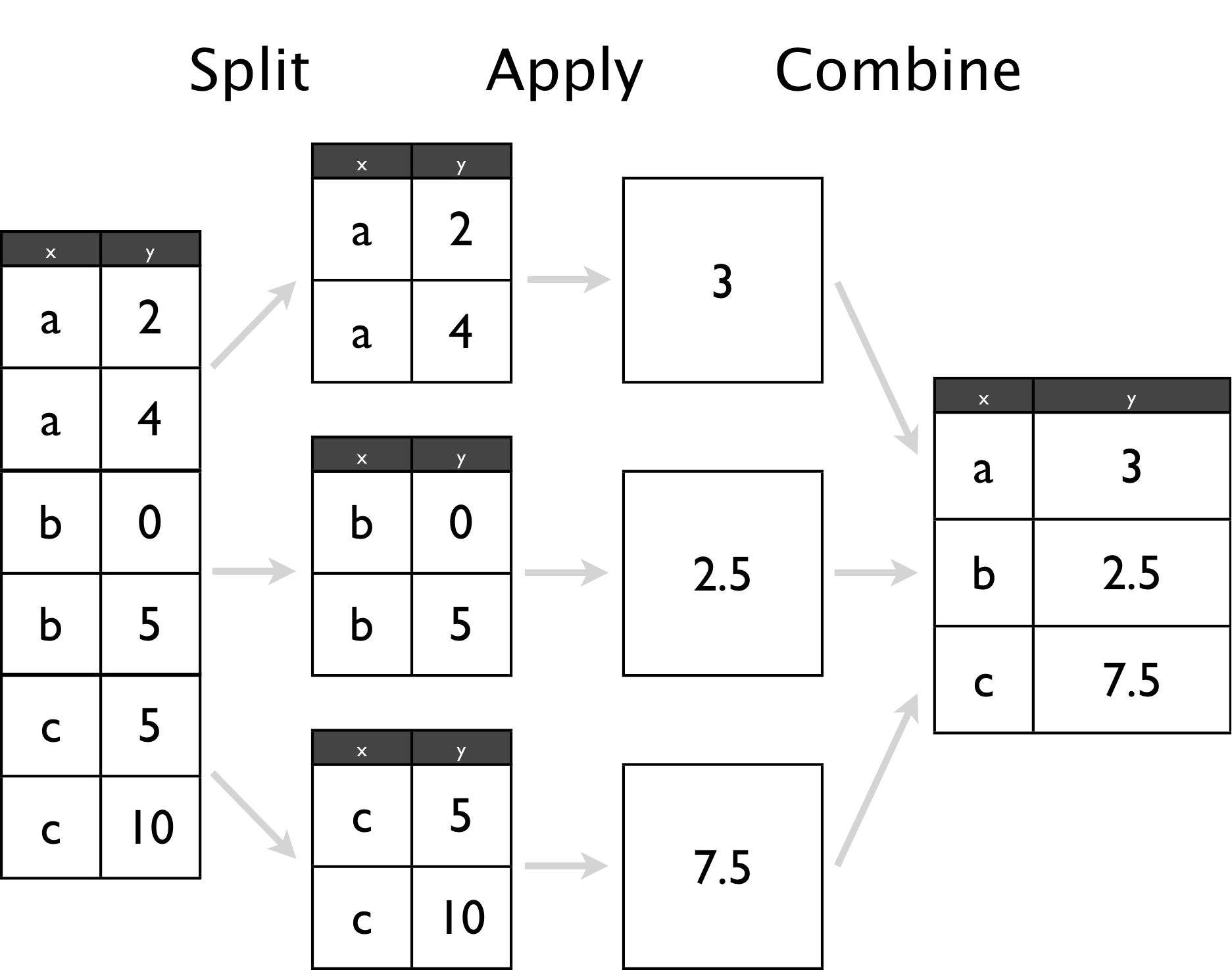
如果Pandas只是能把一些數據變成 dataframe 這樣優美的格式,那麼Pandas絕不會成為叱吒風雲的數據分析中心組件。因為在數據分析過程中,描述數據是通過一些列的統計指標實現的,分析結果也需要由具體的分組行為,對各組橫向縱向對比。
GroupBy 就是這樣的一個有力武器。事實上,SQL語言在Pandas出現的幾十年前就成為了高級數據分析人員的標準工具,很大一部分原因正是因為它有標準的SELECT xx FROM xx WHERE condition GROUP BY xx HAVING condition 範式。
感謝 Wes Mckinney及其團隊,除了SQL之外,我們多了一個更靈活、適應性更強的工具,而非困在SQL Shell或Python里步履沉重。
SELECT Column1, Column2, mean(Column3), sum(Column4)
FROM SomeTable
WHERE Condition 1
GROUP BY Column1, Column2
HAVING Condition2
df [Condition1].groupby([Column1, Column2], as_index=False).agg({Column3: “mean”, Column4: “sum”}).filter(Condition2)
GroupBy可以分解為三個步驟:
那麼,這一套行雲流水的動作是如何完成的呢?
groupby 實現 agg、apply、transform、filter實現具體的操作 concat 等實現其中,在apply這一步,通常由以下四類操作:
注意,這裏討論的apply,agg,transform,filter方法都是限制在 pandas.core.groupby.DataFrameGroupBy裏面,不能跟 pandas.core.groupby.DataFrame混淆。
先導入需要用到的模塊
import numpy as np
import pandas as pd
import sys, traceback
from itertools import chaindf_0 = pd.DataFrame({'A': list(chain(*[['foo', 'bar']*4])),
'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C': np.random.randn(8),
'D': np.random.randn(8)})df_0| A | B | C | D | |
|---|---|---|---|---|
| 0 | foo | one | 1.145852 | 0.210586 |
| 1 | bar | one | -1.343518 | -2.064735 |
| 2 | foo | two | 0.544624 | 1.125505 |
| 3 | bar | three | 1.090288 | -0.296160 |
| 4 | foo | two | -1.854274 | 1.348597 |
| 5 | bar | two | -0.246072 | -0.598949 |
| 6 | foo | one | 0.348484 | 0.429300 |
| 7 | bar | three | 1.477379 | 0.917027 |
df_01 = df_0.copy()
df_01.groupby(["A", "B"], as_index=False, sort=False).agg({"C": "sum", "D": "mean"})| A | B | C | D | |
|---|---|---|---|---|
| 0 | foo | one | 1.494336 | 0.319943 |
| 1 | bar | one | -1.343518 | -2.064735 |
| 2 | foo | two | -1.309649 | 1.237051 |
| 3 | bar | three | 2.567667 | 0.310433 |
| 4 | bar | two | -0.246072 | -0.598949 |
df_02 = df_0.copy()
df_02.groupby(["A", "B"]).agg({"C": "sum", "D": "mean"}).reset_index()| A | B | C | D | |
|---|---|---|---|---|
| 0 | bar | one | -1.343518 | -2.064735 |
| 1 | bar | three | 2.567667 | 0.310433 |
| 2 | bar | two | -0.246072 | -0.598949 |
| 3 | foo | one | 1.494336 | 0.319943 |
| 4 | foo | two | -1.309649 | 1.237051 |
as_index=False 參數是一個好的習慣,因為如果dataframe非常巨大(比如達到GB以上規模)時,先生成一個Groupby對象,然後再調用reset_index()會有額外的時間消耗。如果要得到一個多層索引的數據框,使用默認的as_index=True即可,例如下面的例子:
df_03 = df_0.copy()
df_03.groupby(["A", "B"]).agg({"C": "sum", "D": "mean"})
| C | D | ||
|---|---|---|---|
| A | B | ||
| bar | one | -1.343518 | -2.064735 |
| three | 2.567667 | 0.310433 | |
| two | -0.246072 | -0.598949 | |
| foo | one | 1.494336 | 0.319943 |
| two | -1.309649 | 1.237051 |
注意,as_index僅當做aggregation操作時有效,如果是其他操作,例如transform,指定這個參數是無效的
df_04 = df_0.copy()
df_04.groupby(["A", "B"], as_index=True).transform(lambda x: x * x)
| C | D | |
|---|---|---|
| 0 | 1.312976 | 0.044347 |
| 1 | 1.805040 | 4.263130 |
| 2 | 0.296616 | 1.266761 |
| 3 | 1.188727 | 0.087711 |
| 4 | 3.438331 | 1.818714 |
| 5 | 0.060552 | 0.358740 |
| 6 | 0.121441 | 0.184298 |
| 7 | 2.182650 | 0.840938 |
可以看到,我們得到了一個和df_0一樣長度的新dataframe,同時我們還希望A,B能成為索引,但這並沒有生效。
pd.Grouperpd.Grouper 比 groupby更強大、更靈活,它不僅支持普通的分組,還支持按照時間進行升採樣或降採樣分組
df_1 = pd.read_excel("dataset\sample-salesv3.xlsx")
df_1["date"] = pd.to_datetime(df_1["date"])
df_1.head()
| account number | name | sku | quantity | unit price | ext price | date | |
|---|---|---|---|---|---|---|---|
| 0 | 740150 | Barton LLC | B1-20000 | 39 | 86.69 | 3380.91 | 2014-01-01 07:21:51 |
| 1 | 714466 | Trantow-Barrows | S2-77896 | -1 | 63.16 | -63.16 | 2014-01-01 10:00:47 |
| 2 | 218895 | Kulas Inc | B1-69924 | 23 | 90.70 | 2086.10 | 2014-01-01 13:24:58 |
| 3 | 307599 | Kassulke, Ondricka and Metz | S1-65481 | 41 | 21.05 | 863.05 | 2014-01-01 15:05:22 |
| 4 | 412290 | Jerde-Hilpert | S2-34077 | 6 | 83.21 | 499.26 | 2014-01-01 23:26:55 |
【例子】計算每個月的ext price總和
df_1.set_index("date").resample("M")["ext price"].sum()
date
2014-01-31 185361.66
2014-02-28 146211.62
2014-03-31 203921.38
2014-04-30 174574.11
2014-05-31 165418.55
2014-06-30 174089.33
2014-07-31 191662.11
2014-08-31 153778.59
2014-09-30 168443.17
2014-10-31 171495.32
2014-11-30 119961.22
2014-12-31 163867.26
Freq: M, Name: ext price, dtype: float64df_1.groupby(pd.Grouper(key="date", freq="M"))["ext price"].sum()
date
2014-01-31 185361.66
2014-02-28 146211.62
2014-03-31 203921.38
2014-04-30 174574.11
2014-05-31 165418.55
2014-06-30 174089.33
2014-07-31 191662.11
2014-08-31 153778.59
2014-09-30 168443.17
2014-10-31 171495.32
2014-11-30 119961.22
2014-12-31 163867.26
Freq: M, Name: ext price, dtype: float64兩種寫法都得到了相同的結果,並且看上去第二種寫法似乎有點兒難以理解。再看一個例子
【例子】計算每個客戶每個月的ext price總和
df_1.set_index("date").groupby("name")["ext price"].resample("M").sum().head(20)
name date
Barton LLC 2014-01-31 6177.57
2014-02-28 12218.03
2014-03-31 3513.53
2014-04-30 11474.20
2014-05-31 10220.17
2014-06-30 10463.73
2014-07-31 6750.48
2014-08-31 17541.46
2014-09-30 14053.61
2014-10-31 9351.68
2014-11-30 4901.14
2014-12-31 2772.90
Cronin, Oberbrunner and Spencer 2014-01-31 1141.75
2014-02-28 13976.26
2014-03-31 11691.62
2014-04-30 3685.44
2014-05-31 6760.11
2014-06-30 5379.67
2014-07-31 6020.30
2014-08-31 5399.58
Name: ext price, dtype: float64df_1.groupby(["name", pd.Grouper(key="date",freq="M")])["ext price"].sum().head(20)
name date
Barton LLC 2014-01-31 6177.57
2014-02-28 12218.03
2014-03-31 3513.53
2014-04-30 11474.20
2014-05-31 10220.17
2014-06-30 10463.73
2014-07-31 6750.48
2014-08-31 17541.46
2014-09-30 14053.61
2014-10-31 9351.68
2014-11-30 4901.14
2014-12-31 2772.90
Cronin, Oberbrunner and Spencer 2014-01-31 1141.75
2014-02-28 13976.26
2014-03-31 11691.62
2014-04-30 3685.44
2014-05-31 6760.11
2014-06-30 5379.67
2014-07-31 6020.30
2014-08-31 5399.58
Name: ext price, dtype: float64這次,第二種寫法遠比第一種寫法清爽、便於理解。這種按照特定字段和時間採樣的混合分組,請優先考慮用pd.Grouper
如果只是做完拆分動作,沒有做後續的apply,得到的是一個groupby對象。這裏討論下如何訪問拆分出來的組
主要方法為:
groupsget_groupdf_2 = pd.DataFrame({'X': ['A', 'B', 'A', 'B'], 'Y': [1, 4, 3, 2]})
df_2
| X | Y | |
|---|---|---|
| 0 | A | 1 |
| 1 | B | 4 |
| 2 | A | 3 |
| 3 | B | 2 |
groups方法可以看到所有的組df_2.groupby("X").groups
{'A': Int64Index([0, 2], dtype='int64'),
'B': Int64Index([1, 3], dtype='int64')}get_group方法可以訪問到指定的組df_2.groupby("X", as_index=True).get_group(name="A")
| X | Y | |
|---|---|---|
| 0 | A | 1 |
| 2 | A | 3 |
注意,get_group方法中,name參數只能傳遞單個str,不可以傳入list,儘管Pandas中的其他地方常常能看到這類傳參。如果是多列做主鍵的拆分,可以傳入tuple。
for name, group in df_2.groupby("X"):
print(name)
print(group,"\n")
A
X Y
0 A 1
2 A 3
B
X Y
1 B 4
3 B 2
這裏介紹一個小技巧,如果你得到一個<pandas.core.groupby.groupby.DataFrameGroupBy object對象,想要將它還原成其原本的 dataframe ,有一個非常簡便的方法值得一提:
gropbyed_object.apply(lambda x: x)
囿於篇幅,就不對API逐個解釋了,這裏僅指出最容易忽視也最容易出錯的三個參數
| 參數 | 注意事項 |
|---|---|
| level | 僅作用於層次化索引的數據框時有效 |
| as_index | 僅對數據框做 agg 操作時有效, |
| group_keys | 僅在調用 apply 時有效 |
拆分完成后,可以對各個組做一些的操作,總體說來可以分為以下四類:
先總括地對比下這四類操作
Series壓縮成一個標量值的都是agg操作,例如求和、求均值、求極值等統計計算groupby對象做變換,得到子集或一個新的數據框的操作是apply或transform filterapply 和 transform有那麼一點相似,下文會重點剖析二者
agg和apply都可以對特定列的數據傳入函數,並且依照函數進行計算。但是區別在於,agg更加靈活高效,可以一次完成操作。而apply需要輾轉多次才能完成相同操作。
df_3 = pd.DataFrame({"name":["Foo", "Bar", "Foo", "Bar"], "score":[80,80,95,70]})
df_3
| name | score | |
|---|---|---|
| 0 | Foo | 80 |
| 1 | Bar | 80 |
| 2 | Foo | 95 |
| 3 | Bar | 70 |
我們需要計算出每個人的總分、最高分、最低分
(1)使用apply方法
df_3.groupby("name", sort=False).score.apply(lambda x: x.sum())
name
Foo 175
Bar 150
Name: score, dtype: int64df_3.groupby("name", sort=False).score.apply(lambda x: x.max())
name
Foo 95
Bar 80
Name: score, dtype: int64df_3.groupby("name", sort=False).score.apply(lambda x: x.min())
name
Foo 80
Bar 70
Name: score, dtype: int64顯然,我們輾轉操作了3次,並且還需要額外一次操作(將所得到的三個值粘合起來)
(2)使用agg方法
df_3.groupby("name", sort=False).agg({"score": [np.sum, np.max, np.min]})
| score | |||
|---|---|---|---|
| sum | amax | amin | |
| name | |||
| Foo | 175 | 95 | 80 |
| Bar | 150 | 80 | 70 |
小結 agg一次可以對多個列獨立地調用不同的函數,而apply一次只能對多個列調用相同的一個函數。
transform作用於數據框自身,並且返回變換后的值。返回的對象和原對象擁有相同數目的行,但可以擴展列。注意返回的對象不是就地修改了原對象,而是創建了一個新對象。也就是說原對象沒變。
df_4 = pd.DataFrame({'A': range(3), 'B': range(1, 4)})
df_4
| A | B | |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 2 |
| 2 | 2 | 3 |
df_4.transform(lambda x: x + 1)
| A | B | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 2 | 3 |
| 2 | 3 | 4 |
可以對數據框先分組,然後對各組賦予一個變換,例如元素自增1。下面這個例子意義不大,可以直接做變換。
df_2.groupby("X").transform(lambda x: x + 1)
| Y | |
|---|---|
| 0 | 2 |
| 1 | 5 |
| 2 | 4 |
| 3 | 3 |
下面舉一個更實際的例子
df_5 = pd.read_csv(r"dataset\tips.csv")
df_5.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
現在我們想知道每天,各數值列的均值
對比以下 agg 和 transform 兩種操作
df_5.groupby("day").aggregate("mean")
| total_bill | tip | size | |
|---|---|---|---|
| day | |||
| Fri | 17.151579 | 2.734737 | 2.105263 |
| Sat | 20.441379 | 2.993103 | 2.517241 |
| Sun | 21.410000 | 3.255132 | 2.842105 |
| Thur | 17.682742 | 2.771452 | 2.451613 |
df_5.groupby('day').transform(lambda x : x.mean()).total_bill.unique()
array([21.41 , 20.44137931, 17.68274194, 17.15157895])觀察得知,兩種操作是相同的,都是對各個小組求均值。所不同的是,agg方法僅返回4行(即壓縮后的統計值),而transform返回一個和原數據框同樣長度的新數據框。
transform 和 apply 的不同主要體現在兩方面:
apply 對於每個組,都是同時在所有列上面調用函數;而 transform 是對每個組,依次在每一列上調用函數 apply 可以返回標量、Series、dataframe——取決於你在什麼上面調用了apply 方法;而 transform 只能返回一個類似於數組的序列,例如一維的 Series、array、list,並且最重要的是,要和原始組有同樣的長度,否則會引發錯誤。【例子】通過打印對象的類型來對比兩種方法的工作對象
df_6 = pd.DataFrame({'State':['Texas', 'Texas', 'Florida', 'Florida'],
'a':[4,5,1,3], 'b':[6,10,3,11]})
df_6
| State | a | b | |
|---|---|---|---|
| 0 | Texas | 4 | 6 |
| 1 | Texas | 5 | 10 |
| 2 | Florida | 1 | 3 |
| 3 | Florida | 3 | 11 |
def inspect(x):
print(type(x))
print(x)
df_6.groupby("State").apply(inspect)
<class 'pandas.core.frame.DataFrame'>
State a b
2 Florida 1 3
3 Florida 3 11
<class 'pandas.core.frame.DataFrame'>
State a b
2 Florida 1 3
3 Florida 3 11
<class 'pandas.core.frame.DataFrame'>
State a b
0 Texas 4 6
1 Texas 5 10從打印結果我們清晰地看到兩點:apply 每次作用的對象是一個 dataframe,其次第一個組被計算了兩次,這是因為pandas會通過這種機制來對比是否有更快的方式完成後面剩下組的計算。
df_6.groupby("State").transform(inspect)
<class 'pandas.core.series.Series'>
2 1
3 3
Name: a, dtype: int64
<class 'pandas.core.series.Series'>
2 3
3 11
Name: b, dtype: int64
<class 'pandas.core.frame.DataFrame'>
a b
2 1 3
3 3 11
<class 'pandas.core.series.Series'>
0 4
1 5
Name: a, dtype: int64
<class 'pandas.core.series.Series'>
0 6
1 10
Name: b, dtype: int64從打印結果我們也清晰地看到兩點:transform每次只計算一列;會出現計算了一個組整體的情況,這有點令人費解,待研究。
從上面的對比,我們直接得到了一個有用的警示:不要傳一個同時涉及到多列的函數給transform方法,因為那麼做只會得到錯誤。例如下面的代碼所示:
def subtract(x):
return x["a"] - x["b"]
try:
df_6.groupby("State").transform(subtract)
except Exception:
exc_type, exc_value, exc_traceback = sys.exc_info()
formatted_lines = traceback.format_exc().splitlines()
print(formatted_lines[-1])
KeyError: ('a', 'occurred at index a')另一個警示則是:在使用 transform 方法的時候,不要去試圖修改返回結果的長度,那樣不僅會引發錯誤,而且traceback的信息非常隱晦,很可能你需要花很長時間才能真正意識到錯誤所在。
def return_more(x):
return np.arange(3)
try:
df_6.groupby("State").transform(return_more)
except Exception:
exc_type, exc_value, exc_traceback = sys.exc_info()
formatted_lines = traceback.format_exc().splitlines()
print(formatted_lines[-1])
ValueError: Length mismatch: Expected axis has 6 elements, new values have 4 elements這個報錯信息有點彆扭,期待返回6個元素,但是返回的結果只有4個元素;其實,應該說預期的返回為4個元素,但是現在卻返回6個元素,這樣比較容易理解錯誤所在。
最後,讓我們以一條有用的經驗結束這個talk:如果你確信自己想要的操作時同時作用於多列,並且速度最好還很快,請不要用transform方法,Talk9有一個這方面的好例子。
(1)一次對所有列調用多個函數
df_0.groupby("A").agg([np.sum, np.mean, np.min])
| C | D | |||||
|---|---|---|---|---|---|---|
| sum | mean | amin | sum | mean | amin | |
| A | ||||||
| bar | 0.978077 | 0.244519 | -1.343518 | -2.042817 | -0.510704 | -2.064735 |
| foo | 0.184686 | 0.046172 | -1.854274 | 3.113988 | 0.778497 | 0.210586 |
(2)一次對特定列調用多個函數
df_0.groupby("A")["C"].agg([np.sum, np.mean, np.min])
| sum | mean | amin | |
|---|---|---|---|
| A | |||
| bar | 0.978077 | 0.244519 | -1.343518 |
| foo | 0.184686 | 0.046172 | -1.854274 |
(3)對不同列調用不同函數
df_0.groupby("A").agg({"C": [np.sum, np.mean], "D": [np.max, np.min]})
| C | D | |||
|---|---|---|---|---|
| sum | mean | amax | amin | |
| A | ||||
| bar | 0.978077 | 0.244519 | 0.917027 | -2.064735 |
| foo | 0.184686 | 0.046172 | 1.348597 | 0.210586 |
df_0.groupby("A").agg({"C": "sum", "D": "min"})
| C | D | |
|---|---|---|
| A | ||
| bar | 0.978077 | -2.064735 |
| foo | 0.184686 | 0.210586 |
(4)對同一列調用不同函數,並且直接重命名
df_0.groupby("A")["C"].agg([("Largest", "max"), ("Smallest", "min")])
| Largest | Smallest | |
|---|---|---|
| A | ||
| bar | 1.477379 | -1.343518 |
| foo | 1.145852 | -1.854274 |
(5)對多個列調用同一個函數
agg_keys = {}.fromkeys(["C", "D"], "sum")
df_0.groupby("A").agg(agg_keys)
| C | D | |
|---|---|---|
| A | ||
| bar | 0.978077 | -2.042817 |
| foo | 0.184686 | 3.113988 |
(6)注意agg會忽略缺失值,這在計數時需要加以注意
df_7 = pd.DataFrame({"ID":["A","A","A","B","B"], "Num": [1,np.nan, 1,1,1]})
df_7
| ID | Num | |
|---|---|---|
| 0 | A | 1.0 |
| 1 | A | NaN |
| 2 | A | 1.0 |
| 3 | B | 1.0 |
| 4 | B | 1.0 |
df_7.groupby("ID").agg({"Num":"count"})
| Num | |
|---|---|
| ID | |
| A | 2 |
| B | 2 |
注意:Pandas 中的 count,sum,mean,median,std,var,min,max等函數都用C語言優化過。所以,還是那句話,如果你在大數據集上使用agg,最好使用這些函數而非從numpy那裡借用np.sum等方法,一個緩慢的程序是由每一步的緩慢積累而成的。
通常,在對一個 dataframe 分組並且完成既定的操作之後,可以直接返回結果,也可以視需求對結果作一層過濾。這個過濾一般都是指 filter 操作,但是務必要理解清楚自己到底需要對組作過濾還是對組內的每一行作過濾。這個Talk就來討論過濾這個話題。
【例子】找出每門課程考試分數低於這門課程平均分的學生
df_8 = pd.DataFrame({"Subject": list(chain(*[["Math"]*3,["Computer"]*3])),
"Student": list(chain(*[["Chan", "Ida", "Ada"]*2])),
"Score": [80,90,85,90,85,95]})
df_8
| Subject | Student | Score | |
|---|---|---|---|
| 0 | Math | Chan | 80 |
| 1 | Math | Ida | 90 |
| 2 | Math | Ada | 85 |
| 3 | Computer | Chan | 90 |
| 4 | Computer | Ida | 85 |
| 5 | Computer | Ada | 95 |
這樣一個需求是否適合用 filter 來處理呢?我們試試看:
try:
df_8.groupby("Subject").filter(lambda x: x["Score"] < x["Score"].mean())
except Exception:
exc_type, exc_value, exc_traceback = sys.exc_info()
formatted_lines = traceback.format_exc().splitlines()
print(formatted_lines[-1])
TypeError: filter function returned a Series, but expected a scalar bool顯然不行,因為 filter 實際上做的事情是要麼留下這個組,要麼過濾掉這個組。我們在這裏弄混淆的東西,和我們初學 SQL時弄混 WHERE 和 HAVING 是一回事。就像需要記住 HAVING 是一個組內語法一樣,請記住 filter 是一個組內方法。
我們先解決這個例子,正確的做法如下:
df_8.groupby("Subject").apply(lambda g: g[g.Score < g.Score.mean()])
| Subject | Student | Score | ||
|---|---|---|---|---|
| Subject | ||||
| Computer | 4 | Computer | Ida | 85 |
| Math | 0 | Math | Chan | 80 |
而關於 filter,我們援引官方文檔上的例子作為對比
df_9 = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar'],
'B' : [1, 2, 3, 4, 5, 6],
'C' : [2.0, 5., 8., 1., 2., 9.]})
df_9
| A | B | C | |
|---|---|---|---|
| 0 | foo | 1 | 2.0 |
| 1 | bar | 2 | 5.0 |
| 2 | foo | 3 | 8.0 |
| 3 | bar | 4 | 1.0 |
| 4 | foo | 5 | 2.0 |
| 5 | bar | 6 | 9.0 |
df_9.groupby('A').filter(lambda x: x['B'].mean() > 3.)
| A | B | C | |
|---|---|---|---|
| 1 | bar | 2 | 5.0 |
| 3 | bar | 4 | 1.0 |
| 5 | bar | 6 | 9.0 |
df_10 = pd.DataFrame({"ID":["A","A","A","B","B","B"], "Num": [100,np.nan,300,np.nan,500,600]})
df_10
| ID | Num | |
|---|---|---|
| 0 | A | 100.0 |
| 1 | A | NaN |
| 2 | A | 300.0 |
| 3 | B | NaN |
| 4 | B | 500.0 |
| 5 | B | 600.0 |
df_10.groupby("ID", as_index=False).Num.transform(lambda x: x.fillna(method="ffill")).transform(lambda x: x.fillna(method="bfill"))
| Num | |
|---|---|
| 0 | 100.0 |
| 1 | 100.0 |
| 2 | 300.0 |
| 3 | 500.0 |
| 4 | 500.0 |
| 5 | 600.0 |
如果dataframe比較大(超過1GB),transform + lambda方法會比較慢,可以用下面這個方法,速度約比上面的組合快100倍。
df_10.groupby("ID",as_index=False).ffill().groupby("ID",as_index=False).bfill()
| ID | Num | |
|---|---|---|
| 0 | A | 100.0 |
| 1 | A | 100.0 |
| 2 | A | 300.0 |
| 3 | B | 500.0 |
| 4 | B | 500.0 |
| 5 | B | 600.0 |
參考資料:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
Scrapy 是一個使用 Python 語言開發,為了爬取網站數據,提取結構性數據而編寫的應用框架,它用途廣泛,比如:數據挖掘、監測和自動化測試。安裝使用終端命令 pip install Scrapy 即可。
Scrapy 比較吸引人的地方是:我們可以根據需求對其進行修改,它提供了多種類型的爬蟲基類,如:BaseSpider、sitemap 爬蟲等,新版本提供了對 web2.0 爬蟲的支持。
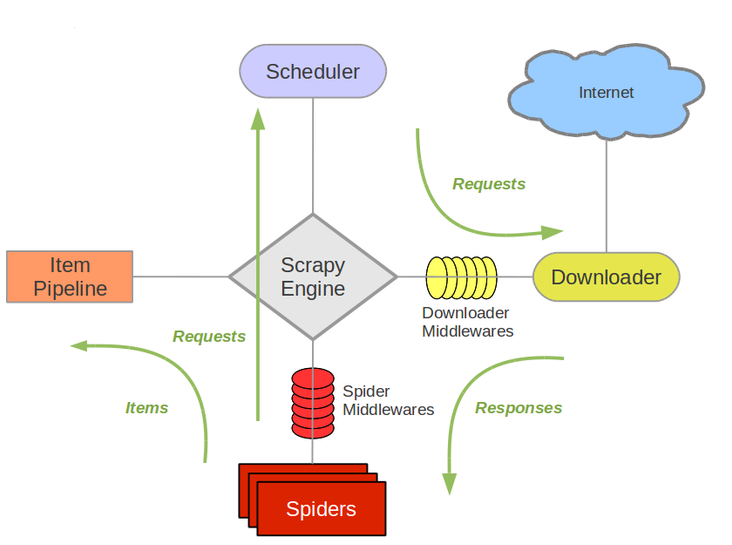
Scrapy Engine(引擎):負責 Spider、ItemPipeline、Downloader、Scheduler 中間的通訊,信號、數據傳遞等。
Scheduler(調度器):負責接受引擎發送過來的 Request 請求,並按照一定的方式進行整理排列、入隊,當引擎需要時,交還給引擎。
Downloader(下載器):負責下載 Scrapy Engine(引擎) 發送的所有 Requests 請求,並將其獲取到的 Responses 交還給 Scrapy Engine(引擎),由引擎交給 Spider 來處理。
Spider(爬蟲):負責處理所有 Responses,從中解析提取數據,獲取 Item 字段需要的數據,並將需要跟進的 URL 提交給引擎,再次進入 Scheduler(調度器)。
Item Pipeline(管道):負責處理 Spider 中獲取到的 Item,並進行後期處理,如:詳細解析、過濾、存儲等。
Downloader Middlewares(下載中間件):一個可以自定義擴展下載功能的組件,如:設置代理、設置請求頭等。
Spider Middlewares(Spider 中間件):一個可以自定擴展和操作引擎和 Spider 中間通信的功能組件,如:自定義 request 請求、過濾 response 等。
總的來說就是:Spider 和 Item Pipeline 需要我們自己實現,Downloader Middlewares 和 Spider Middlewares 我們可以根據需求自定義。
1)Spider 將需要發送請求的 URL 交給 Scrapy Engine 交給調度器;
2)Scrapy Engine 將請求 URL 轉給 Scheduler;
3)Scheduler 對請求進行排序整理等處理后返回給 Scrapy Engine;
4)Scrapy Engine 拿到請求后通過 Middlewares 發送給 Downloader;
5)Downloader 向互聯網發送請求,在獲取到響應后,又經過 Middlewares 發送給 Scrapy Engine。
6)Scrapy Engine 獲取到響應后,返回給 Spider,Spider 處理響應,並從中解析提取數據;
7)Spider 將解析的數據經 Scrapy Engine 交給 Item Pipeline, Item Pipeline 對數據進行後期處理;
8)提取 URL 重新經 Scrapy Engine 交給Scheduler 進行下一個循環,直到無 URL 請求結束。
Scrapy 提供了對 request 的去重處理,去重類 RFPDupeFilter 在 dupefilters.py 文件中,路徑為:Python安裝目錄\Lib\site-packages\scrapy ,該類裏面有個方法 request_seen 方法,源碼如下:
def request_seen(self, request):
# 計算 request 的指紋
fp = self.request_fingerprint(request)
# 判斷指紋是否已經存在
if fp in self.fingerprints:
# 存在
return True
# 不存在,加入到指紋集合中
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)它在 Scheduler 接受請求的時候被調用,進而調用 request_fingerprint 方法(為 request 生成一個指紋),源碼如下:
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]在上面代碼中我們可以看到
fp = hashlib.sha1()
...
cache[include_headers] = fp.hexdigest()它為每一個傳遞過來的 URL 生成一個固定長度的唯一的哈希值。再看一下 __init__ 方法,源碼如下:
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)我們可以看到裏面有 self.fingerprints = set() 這段代碼,就是通過 set 集合的特點(set 不允許有重複值)進行去重。
去重通過 dont_filter 參數設置,如圖所示
dont_filter 為 False 開啟去重,為 True 不去重。
製作 Scrapy 爬蟲需如下四步:
我們以爬取去哪兒網北京景區信息為例,如圖所示:
在我們需要新建項目的目錄,使用終端命令 scrapy startproject 項目名 創建項目,我創建的目錄結構如圖所示:
Item 是保存爬取數據的容器,使用的方法和字典差不多。我們計劃提取的信息包括:area(區域)、sight(景點)、level(等級)、price(價格),在 items.py 定義信息,源碼如下:
import scrapy
class TicketspiderItem(scrapy.Item):
area = scrapy.Field()
sight = scrapy.Field()
level = scrapy.Field()
price = scrapy.Field()
pass在 spiders 目錄下使用終端命令 scrapy genspider 文件名 要爬取的網址 創建爬蟲文件,然後對其修改及編寫爬取的具體實現,源碼如下:
import scrapy
from ticketSpider.items import TicketspiderItem
class QunarSpider(scrapy.Spider):
name = 'qunar'
allowed_domains = ['piao.qunar.com']
start_urls = ['https://piao.qunar.com/ticket/list.htm?keyword=%E5%8C%97%E4%BA%AC®ion=&from=mpl_search_suggest']
def parse(self, response):
sight_items = response.css('#search-list .sight_item')
for sight_item in sight_items:
item = TicketspiderItem()
item['area'] = sight_item.css('::attr(data-districts)').extract_first()
item['sight'] = sight_item.css('::attr(data-sight-name)').extract_first()
item['level'] = sight_item.css('.level::text').extract_first()
item['price'] = sight_item.css('.sight_item_price em::text').extract_first()
yield item
# 翻頁
next_url = response.css('.next::attr(href)').extract_first()
if next_url:
next_url = "https://piao.qunar.com" + next_url
yield scrapy.Request(
next_url,
callback=self.parse
)簡單介紹一下:
yield
在上面的代碼中我們看到有個 yield,簡單說一下,yield 是一個關鍵字,作用和 return 差不多,差別在於 yield 返回的是一個生成器(在 Python 中,一邊循環一邊計算的機制,稱為生成器),它的作用是:有利於減小服務器資源,在列表中所有數據存入內存,而生成器相當於一種方法而不是具體的信息,佔用內存小。
爬蟲偽裝
通常需要對爬蟲進行一些偽裝,關於爬蟲偽裝可通過【】做一下簡單了解,這裏我們使用一個最簡單的方法處理一下。
pip install scrapy-fake-useragent 安裝DOWNLOADER_MIDDLEWARES = {
# 關閉默認方法
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
# 開啟
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
}我們將數據保存到本地的 csv 文件中,csv 具體操作可以參考:,下面看一下具體實現。
首先,在 pipelines.py 中編寫實現,源碼如下:
import csv
class TicketspiderPipeline(object):
def __init__(self):
self.f = open('ticker.csv', 'w', encoding='utf-8', newline='')
self.fieldnames = ['area', 'sight', 'level', 'price']
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
self.writer.writeheader()
def process_item(self, item, spider):
self.writer.writerow(item)
return item
def close(self, spider):
self.f.close()然後,將 settings.py 文件中如下代碼:
ITEM_PIPELINES = {
'ticketSpider.pipelines.TicketspiderPipeline': 300,
}放開即可。
我們在 settings.py 的同級目錄下創建運行文件,名字自定義,放入如下代碼:
from scrapy.cmdline import execute
execute('scrapy crawl 爬蟲名'.split())這個爬蟲名就是我們之前在爬蟲文件中的 name 屬性值,最後在 Pycharm 運行該文件即可。
參考:
完整代碼請關注文末公眾號,後台回復 qs 獲取。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
目錄
AI的真實感一直是遊戲AI程序員追求的目標,如何做出能給玩家真實感,挑戰性又不會勸退玩家的AI,既需要AI程序員有一定的程序功底,還需要廣泛地閱讀和遊戲人工智能相關的課題,比如:心理學,生物學,認知科學乃至軍事戰術等,在你閱讀時你會不斷迸發出更好的想法;還需要和團隊多溝通,無論是程序員還是策劃,甚至是老闆,他們有時一個好的想法就能為你設計的遊戲AI增強真實性。
請牢記一點:遊戲AI的真實感需要服務於遊戲本身,其唯一目的是讓玩家玩遊戲覺得更有趣。
雖然本篇博客會較少代碼講解,但更多地是希望講解一些學習AI過程中遇到的或想到的方法,然後可以根據做的遊戲的不同將這些想法融入設計的遊戲AI里。
遊戲AI並非越智能越好,因為就算是人類,有時也會犯錯,所以為了讓遊戲AI更真實,有時需要讓遊戲AI犯錯,才會使玩家有更愉快的遊戲體驗(而不是被電腦打爆)。
有兩種方式誘使AI犯錯:
先使AI“完美”,再讓它變傻
當設計AI使用的算法時,通過假設和估算,允許悄悄混進“錯誤”。
以足球AI為例,前者用一個取值為一個固定大小範圍的隨機值的變量作為干擾值(隨機噪聲),使AI每次判斷踢球方向時產生小錯誤;後者是讓AI用圓而非橢圓(估算)來描述對手的截球範圍,既簡化了AI算法,又實現”不完美“。當然,在不同的遊戲里如何使AI犯錯就得因遊戲而論了。
而在不少FPS遊戲里,在遊戲AI第一次射擊玩家時讓其專門射偏是一個好主意,能提醒玩家有AI的出現,在未受傷前做好準備。尤其在玩家需要探索一間充滿敵人的屋子時,給了玩家一個了解基本形勢的機會並量力而行,不至於一進門就被集火殺死。
射偏還有其他好處:
對於許多類遊戲而言,想讓AI看起來智能,需要AI有精確的感知模仿,並不是說簡單地模仿立體視覺和聽力,還要其決策邏輯和其感知能力保持一致。
有些遊戲不太需要這種感知模擬,一是它會佔用不少的CPU和內存的資源,二是有些遊戲使用這種感知模擬並不會提升遊戲體驗。
1.你安靜地接近一個敵人AI打算背後刺殺,結果他立刻轉過身一槍把你秒了(可能聽到眨眼睛的聲音)。
【我起了,一槍秒了,有什麼好說的】
2.你潛行在黑暗處匍匐前行,旁邊一個守衛明明看不到暗處,就突然發現了你,給你來了一槍。
【是不是玩不起?AI開掛實錘】
這就是典型的具有全能的感知能力的AI,這可能是因為AI程序員為了輕鬆或沒有考慮到事實和感知,這樣的AI只會讓玩家失去玩遊戲的興趣。因此需要將AI的視覺和聽覺限製得與玩家一樣,聽力範圍限制,無法看到黑暗裡的物品,視力範圍90°,不能透視等。
這又牽扯出一個經典的話題:AI可以作弊嗎?
這裏的作弊不僅指的是AI使用了玩家不能使用的能力,或者單方面獲取比玩家更多的信息,獲得更多資源,還包括AI擁有程序員設計的完善的決策設計,當他能夠打敗玩家時卻放棄了那個可以獲勝的決策而製造出失誤的表象,也就是放水。
我認為是可以的。其實大部分遊戲的AI都是會作弊的,除非沒必要,比如紅警,街霸,還有不少戰略遊戲裏面,AI都是會作弊的,因為這樣能更快速有效地給玩家製造緊迫感,實現難度控制。 需要給予作弊能力的關鍵在於玩家和遊戲AI之間天生處於不平等地位。
大部分AI還未能實現自我學習的能力,都是靠經驗豐富的遊戲AI程序員花費大量時間去模擬玩家實現接近玩家的AI,而且目前費了好大勁實現的自主學習的AI又其實與會作弊的AI(指的是作弊得恰到好處的)給予玩家的遊戲體驗的差別並不大,廠商為了遊戲體驗和成本,街機廳的老闆為了恰飯,所以才會選擇了給予作弊。
在《可汗:戰爭之王2》(一款即時戰略遊戲)中,有兩個巧妙的作弊:
歸根結底,當且僅當AI作弊能提高玩家體驗時,就應該讓AI作弊。但記得一點:讓你的AI作弊得不易被發現,否則就是另一種狀況了。
圖為《可汗:戰爭之王2》
1.你和精英怪單挑,一套下去發現打不過,瀕臨死亡被逼到角落陰暗處,精英怪丟失了目標不再攻擊,回到原本看守的地方,你莫名其妙活下來了。
2.你刺殺了一位守衛,他臨死前叫了一聲,一群守衛立刻趕來,你來不及隱藏屍體就躲進衣櫃,緊張地準備着守衛發現屍體后搜索房間時的一場惡戰,結果他們從屍體上踩了過去,彷彿沒看到屍體。
這些情況是因為AI感知得太少,也說明了為了讓AI更真實,需要一種機制讓AI模仿人類的短期記憶。
在我博客所參考的那本書里舉了個很生動的例子:
當一名AI遇到兩名玩家,他的視野里有兩名與他距離不同的分別位於左右的玩家,兩條線表示視野
當他判斷左邊那個玩家離他更近,對他威脅程度更大時,他往左邊轉準備攻擊左邊玩家,這時他一左轉右邊玩家丟失在他視野之外(AI也就不會再警惕右邊玩家)
然後那名玩家(丟失在右邊視野的)直接走到AI右邊將其殺死
這個例子就很形象說明了AI需要短期記憶,不然若遊戲裏面發生上面所舉這個例子,玩家會強烈地感覺到: 我上當了!他不是人!
至於如何實現短期記憶,視你所期望的遊戲效果而自由改變,一般是以一個值作為可記憶時間,用最後敵人出現的位置作為記錄,增加相應的決策判斷,並在下次發現該對象時更新記憶系統相關信息,當超過記憶時間或決策判斷不會對自身產生影響則將其移除於記憶系統。
不同的AI如果有不同的角色設計,就需要在其AI行為方面表現其個性,就算沒有角色設計,也應該盡量避免所有的AI的思考方式是一致的(容易讓玩家感受到虛假感),以產生有隨機個性的AI。
簡單來說,因為AI的行為決策系統計算不同行為的期望值分數都被限制在同一範圍內(如 0~1),那我們可以通過對每個分數乘以其所需個性趨向的一個偏移常量,就能輕鬆生成有不同個性特點的AI。比如FPS遊戲里,膽小的人永遠會把自己的生存放在第一位而較為謹慎,所以將其對藥品和防具的尋找行為的期望值偏量設為1.5,而暴躁好鬥的人會更趨向於進攻,所以將其攻擊目標的行為期望值偏量設為1.5。
如果你的遊戲設計要求一個角色的個性在該遊戲中保持不變,那你就需要為每個具有個性的角色建立單獨的腳本文件,用來存放其所有特性數據。如果你的遊戲設計沒有什麼角色個性設計,那麼你也可以在決策系統中計算期望值分數時加入一個固定大小範圍的隨機個性偏移量,以生成不同行為趨向的角色。
而除了隨機個性偏移量,有些時候還會由角色設計而增加更多個性化的選擇趨向,如武器方面,說話方式,甚至塑造人物精神,增加犧牲自我,保護隊友的決策。
在使命召喚中我印象最深的是格里戈斯上士 ,臨危之際不忘把隊友”肥皂” 拖向掩體!然後自己卻與敵人繼續交火,獻出了自己的生命,當時玩的時候感覺非常的感動,確定是塑造了一位有血有肉的有偉大精神的真實角色形象。
圖右一為格里戈斯上士
首先是一些遊戲不太需要AI具有預判性,比如:說galgame,劇情解密類;而一些遊戲就需要具有預判性的AI,比如說:策略類遊戲,棋類遊戲。具有一定的預判性的AI會給玩家帶來驚喜,真實感與挑戰性(不要盲目增強,如果整個阿爾法狗出來就直接勸退玩家了)。
簡單的預判比如說:
當地圖上的某些特定的物件即將重生時,比如說LOL裏面的野區資源,又或者說是守望先鋒裏面固定點重新刷新的醫療包,出色的玩家會提前準備好前往目標處以保證搶先佔有它,那就可以讓遊戲AI用算法提前預計最近的即將再生或未被奪取的資源點,並規劃路徑前往。
圖為lol里蓋倫預判敵人路過補視野草叢埋伏
又或者是在攻擊和追逐敵人時計算移動目標位置時加入敵人的速度及運動方向,預判其下個時間的位置進行追逐或攻擊。
複雜的預判比如說:
在FPS遊戲中,出色的老兵在打傷了敵人後,會提前到距離受傷敵人最近的醫療包處進行埋伏,當敵人到來時給予致命一擊。那麼遊戲AI也可以模仿這種預判思維,在攻擊成功判斷後添加一個搜索並前往離受傷者最後出現的地方最近的醫療包處進行埋伏的決策,可以想象到玩家如果遇到這種會預判的電腦時的驚訝,並激起其挑戰慾望。
當然,預判總會有失策的時候,人類有時不也是如此,比如有些玩家不去找醫療包,或者摸清AI的習慣(只會埋伏最近那個醫療點)等情況,那麼就提醒你,不能所有AI都是具有同樣的預判思想(可以通過AI個性來生成不同思考方式的AI),甚至就如一個玩笑:我預判到你預判到我會預判,於是我不預判了。沒有預判的AI也許就是具有最強預判性的AI呢?滑稽.jpg
正如一本書中寫道:老謀深算的AI應該跟它的壽命成正比。倘若設計一個採用了前沿技術,具有複雜思考系統的AI,但如果它在遊戲中僅僅被期望活幾秒鐘的話,那將毫無意義。
而且AI的智能程度也需要與其設計的角色的智能等級相匹配。比如說一個戰爭策略遊戲里,不同的士兵有不同的軍銜,比如 上尉、中尉、少尉 等,越高軍銜的軍官一般會有越高的智能等級,所以需要相應地提高其智能程度,比如加入較為複雜的戰略決策。
而拿簡單的舉例:假如你在遊戲里潛行時不小心發出聲響,那麼普通守衛只是過來看了看周圍,沒發現什麼人就又回到原來的崗位,而精英守衛就可以加入更為精明或謹慎的行為:先往發出聲響的地方(如草場)掃射一下,若沒發現異常才將狀態改為正常守衛,返回其守衛處,或者加入殺個回馬槍的決策。這些有趣的謹慎行為也會讓玩家更不敢把AI當成是傻瓜,甚至感受到樂趣。不過還是記住設計AI的原則,不要讓AI過於謹慎導致玩家喪失樂趣。
先來看看兩個例子
這兩種結果就使得遊戲要麼像一個埋伏式(持久戰)的較量,要麼像比賽追逐的遊戲,兩種情況無疑都比較無聊。所以絕對的真實也可能帶來遊戲有趣性的下降。
雖然追求AI能給人帶來真實感,但玩家其實也有一定的寬容能力,具有瑕疵的AI他們也會自行腦補:畢竟它終究是個AI。所以不必過分追求真實,又不能輕視AI真實感對於遊戲體驗的提升的重要性,還是牢記最重要的一點,也是追求AI的真實感的唯一目的:讓遊戲更有趣!
參考學習自《遊戲人工智能編程案例精粹》《遊戲人工智能》
轉載標明出處:作者AMzz 博客:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
用戶進程想要執行IO操作時(例如想要讀磁盤數據、向磁盤寫數據、讀鍵盤的輸入等等),由於用戶進程工作在用戶模式下,它沒有執行這些操作的權限,只能通過發起對應的系統調用請求操作系統幫忙完成這些操作。這裏因為系統調用產生中斷將陷入到內核,進行一次上下文切換操作。
內核進程幫忙執行IO操作時,由於IO操作相比於CPU來說是極慢的操作,CPU不應該等待在這個過程中,而是切換到其它進程上去執行其它任務。這裏再次涉及到一次上下文切換:從內核態回到用戶態的其它進程。
DMA要求硬件的支持,需要在硬件中集成一個小型的“CPU”,比如現在的机械硬盤、固態硬盤、網卡等硬件都帶有DMA功能,這樣操作系統要執行IO操作時,直接將相關指令發送給這些DMA硬件,DMA處理器負責IO操作,而操作系統這時可以放棄CPU,讓CPU去執行其它進程。例如對於讀磁盤文件時,操作系統將相關指令以及數據應寫在哪個內存地址發送給DMA硬件后,由DMA硬件去讀寫數據到指定內存地址,當IO操作完成后,DMA硬件通過總線發送一個硬件中斷給CPU,於是陷入到內核態(這裏涉及了一次上下文切換),內核就知道了IO已經完成,於是將Kernel Buffer數據拷貝到用戶進程的IO Buffer,並準備調度用戶進程(再次上下文切換)。
假如不使用DMA硬件的話,那麼IO操作過程中,操作系統將多次參与,負責將硬件數據讀入或讀出內存,操作系統參与意味着要陷入到內核態,並且獲取CPU控制權,這也意味着要進行大量的上下文切換以及佔用大量CPU資源。
而使用DMA后,只有4次必要的上下文切換,且IO操作的過程中完全不需要消耗CPU資源。
除了DMA,還有更高級的RDMA(Remote Direct Memory Access)機制,它需要操作系統和硬件的支持,還需要編寫RDMA方式的代碼。
前面介紹緩衝空間時提到過,一般情況下,每個用戶進程要讀、寫數據,都會經過兩個必要的緩衝層:內核空間的Kernel Buffer、用戶空間的IO Buffer。例如讀文件數據時,先將數據拷貝到內核的緩衝空間(page cache),然後陷入內核,內核將該緩衝空間數據拷貝到用戶空間的緩衝空間(IO Buffer),當調度到用戶進程時,用戶進程從自己的緩衝空間讀取數據。
DMA機制並沒有繞過這兩個緩衝層,但使用RDMA機制,程序可以直接繞過Kernel Buffer,內核發現是RDMA操作后,直接告訴RDMA硬件將讀取的數據(寫操作也一樣)寫入到用戶空間的IO Buffer,而不需要先拷貝到Kernel Buffer,再拷貝到IO Buffer。雖然RDMA機制相比DMA不會減少上下文切換次數,但是它減少了內存數據拷貝的過程,相當於是使用了O_DIRECT標記的直接IO技術。
DMA和RDMA兩種技術對比如圖:RDMA一般實現在網卡上,但出於方便理解,下圖直接使用磁盤來描述
像這種繞過內核功能的技術,通常稱為內核旁路(Kernel Bypass),RDMA技術內核旁路的是一種,還有像TOE也是內核旁路的一種。
雖然RDMA比較優秀,但是它需要硬件、操作系統和代碼的同時支持,對編程而言是一個比較大的衝擊,所以目前使用的非常少。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
目錄
一、java內存模型
1.1、抽象結構圖
1.2、概念介紹
二、volatile詳解
2.1、概念
2.2、保證內存可見性
2.3、不保證原子性
2.4、有序性
java 內存模型
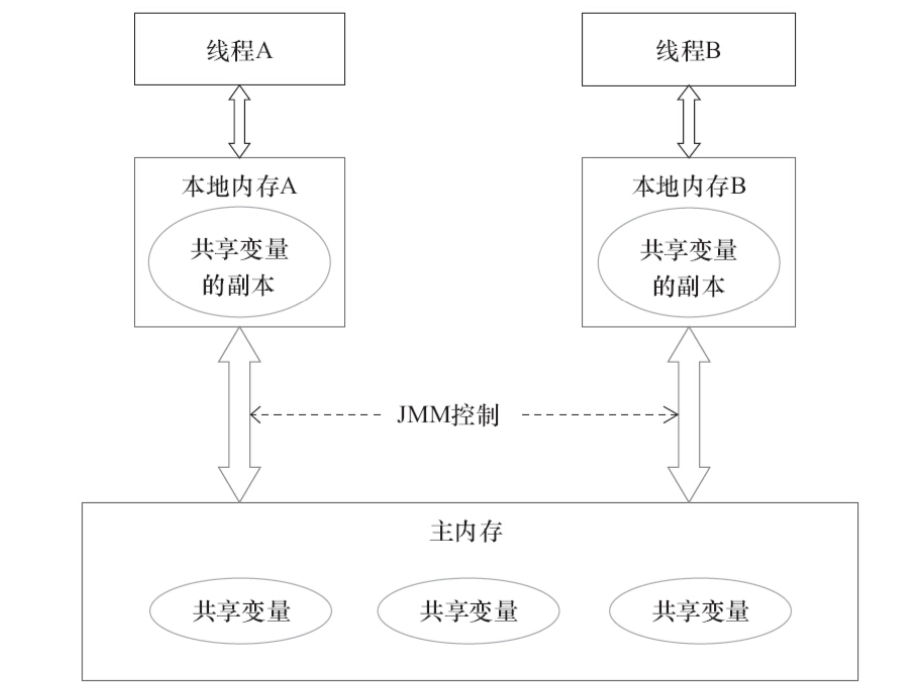
即Java memory model(簡稱JMM), java線程之間的通信由JMM控制,決定一個線程對共享變量的寫入何時對另一個線程可見。多線程通信通常分為2類:共享內存和消息傳遞
JMM採用的就是共享內存來實現線程間的通信,且通信是隱式的,對程序開發人員是透明的,所以在了解其原理了,才會對線程之間通信,同步,內存可見性問題有進一步認識,避免開發中出錯。線程之間如何通信?
在java中多個線程之間要想通信,如上圖所示,每個線程在需要操作某個共享變量時,會將該主內存中這個共享變量拷貝一份副本存在在自己的本地內存(也叫工作內存,這裏只是JMM的一個抽象概念,即將其籠統看做一片內存區域,用於每個線程存放變量,實際涉及到緩存,寄存器和其他硬件),線程操作這個副本,比如 int i = 1;一個線程想要進行 i++操作,會先將變量 i =1 的值先拷貝到自己本地內存操作,完成 i++,結果 i=2,此時主內存中的值還是1,在線程將結果刷新到主內存后,主內存值就更新為2,數據達到一致了。
如果線程A,線程B同時將 主內存中 i =1拷貝副本到自己本地內存,線程A想要 將i+1,而線程B想要將 int j=i,將賦值給j,那麼如何保證線程之間的協作,此時就會涉及到線程之間的同步以及內存可見性問題了。(後文分析synchronized/lock)
那線程之間實現通信需要經過2個步驟,藉助主內存為中間媒介:
線程A (發送消息)-->(接收消息) 線程B
1、線程A將本地內存共享變量值刷新到主內存中,更新值;
2、線程B從主內存中讀取已更新過的共享變量;共享內存中涉及到哪些變量稱為共享變量?
這裏的共享內存指的是jvm中堆內存中,所有堆內存在線程之間共享,因為棧中存儲的是方法及其內部的局部變量,不在此涉及。
共享變量:對於多線程之間能夠共同操作的變量,包含實例域,靜態域,數組元素。即有成員變量,靜態變量等等,
不涉及到局部變量(所以局部變量不涉及到內存可見性問題)多線程在java內存模型中涉及到三個問題
-1、volatile 是 java中的關鍵字,可修飾字段,可以保證共享變量的在內存的可見性,有序性,不保證原子性。
-2、作用:在了解java內存模型后,才能更加了解volatile在JMM中的作用,volatile在JMM中為了保證內存的可見性,即是線程之間操作共享變量的可見性。volatile 寫的內存語義:
當寫一個volatile修飾的共享變量時,JMM會把該線程的本地內存的共享變量副本值刷新到主內存中;
volatile 讀的內存語義:
當讀一個volatile修飾的共享變量時,JMM會將該線程的本地內存的共享變量副本置為無效,要求線程重新去主內存中獲取最新的值。不衝突!java內存模型控制線程工作內存與主內存之間共享變量會同步,即線程從主內存中讀一份副本到工作內存,又刷新到主內存,那怎麼還需要 volatile來保證可見性,不是JMM自己能控制嗎,一般情況下JMM可以控制 2份內存數據一致性,但是在多線程併發環境下,雖然最終線程工作內存中的共享變量會同步到主內存,但這需要時間和觸發條件,線程之間同時操作共享變量協作時,就需要保證每次都能獲取到主內存的最新數據,保證看到的工作變量是最後一次修改后的值,這個JMM沒法控制保證,這就需要volatile或者後文要講的 synchronized和鎖的同步機制來實現了。1、多個線程出現內存不可見問題示例
/**
* @author zdd
* Description: 測試線程之間,內存不可見問題
*/
public class TestVisibilityMain {
private static boolean isRunning = true;
// 可嘗試添加volatile執行,其餘不變,查看線程A是否被停止
//private static volatile boolean isRunning = true;
public static void main(String[] args) throws InterruptedException {
//1,開啟線程A,讀取共享變量值 isRunning,默認為true
new Thread(()->{
// --> 此處用的lamda表達式,{}內相當於Thread的run方法內部需執行任務
System.out.println(Thread.currentThread().getName() + "進入run方法");
while (isRunning == true) {
}
System.out.println(Thread.currentThread().getName()+"被停止!");
},"A").start();
//2,主線程休眠1s, 確保線程A先被調度執行
TimeUnit.SECONDS.sleep(1);
//3,主線程修改共享變量值 為flase,驗證線程A是否能夠獲取到最新值,跳出while循環 --> 驗證可見性
isRunning =false;
System.out.println(Thread.currentThread().getName() +"修改isRunning為: " + isRunning);
}
} 執行結果如下圖:
上面代碼 while裏面是一個空循環,沒有操作,如果我在裏面加一句打印語句,線程A會被停止,這是怎麼回事呢?
原:while (isRunning == true) {}
改1:
while (isRunning == true) {
System.out.println("進入循環");
}
原來 println方法裏面加了 synchronized關鍵字,在加了鎖既保證原子性,也保證了可見性,會實現線程的工作內存與主內存共享變量的同步。
源代碼如下:
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}
改2:
while (isRunning == true) {
//改為這樣,也可以停止線程A
synchronized (TestVisibilityMain.class){}
}/**
* @author zdd
* Description: 測試volatile的不具有原子性
*/
public class TestVolatileAtomic {
private static volatile int number;
//開啟線程數
private static final int THREAD_COUNT =10;
//執行 +1 操作
public static void increment() {
//讓每個線程進行加1次數大一些,能夠更容易出現volatile對複合操作(i++)沒有原子性的錯誤
for (int i = 0; i < 10000; i++) {
number++;
}
System.out.println(Thread.currentThread().getName() +"的number值: "+number);
}
public static int getNumber() {
return number;
}
public static void main(String[] args) throws InterruptedException {
TestVolatileAtomic volatileAtomic = new TestVolatileAtomic();
Thread[] threads = new Thread[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
threads[i]=
new Thread(()->{
// 做循環自增操作
volatileAtomic.increment();
System.out.println(Thread.currentThread().getName() +"的number值: "+volatileAtomic.getNumber());
},"thread-"+i);
}
for (int i = 0; i <10; i++) {
//開啟線程
threads[i].start();
}
//主線程休眠4s,確保上麵線程都執行完畢
TimeUnit.SECONDS.sleep(4);
System.out.println("執行完畢,number最終值為:"+volatileAtomic.getNumber());
}
}
執行結果:number的最後值不一定是 10*10000= 100000的結果
//1,increment()方法上加上 synchronized關鍵字同步
public static synchronized void increment() {
//讓每個線程進行加1次數大一些,能夠更容易出現volatile對複合操作(i++)沒有原子性的錯誤
for (int i = 0; i < 10000; i++) {
number++;
}
System.out.println(Thread.currentThread().getName() +"的number值: "+number);
}
//2,使用Lock,使用其實現類可重入鎖 ReentrantLock
static Lock lock = new ReentrantLock();
//執行 +1 操作
public static void increment() {
lock.lock();
try {
for (int i = 0; i < 10000; i++) {
number++;
}
System.out.println(Thread.currentThread().getName() + "的number值: " + number);
} finally {
lock.unlock();
}
}運行結果如圖:
對單個volatile變量的讀/寫具有原子性,而對像 i++這種複合操作不具有原子性。
上面代碼 i++操作可以分為3個步驟
-1 先讀取變量i的值 i
-2 進行i+1操作 temp= i+1
-3 修改i的值 i= temp
比如:比如在線程A,B同時去操作共享變量i, i的初始值為10,A,B同時去獲取i的值,A對i進行 temp =i+1,此時i的值還沒變, 線程B也對i進行 temp=i+1了,線程A執行i=temp的操作,i的值變為11,此時由於 volatile可見性,會刷新A的 i值到主內存,主內存中i此時也更新為11了,線程B接收到通知自己i無效了,重新讀取i=11,雖然i=11,但是已經進行過 temp= i+1了,此時temp =11,線程B繼續第三步,i=temp =11, 預期結果是i被A,B自增各一次,結果i=12,現在為11,出現數據錯誤。-1,重排序概念:重排序是編譯器和處理器為了優化程序性能而對指令序列重新排序的一種手段
即:程序員編寫的程序代碼的順序,在實際執行的時候是不一樣的,這其中編譯器和處理器在不影響最終執行結果的基礎上會做一些優化調整,有重新排序的操作,為了提高程序執行的併發性能。
-2,重排序分類: 編譯重排序,處理器重排序
-4,單線程下,重排序沒有問題,但是在多線程環境下,可能會破壞程序的語義.為了實現volatile的內存語義,JMM會限制編譯器和處理器重排序
-1 制定了重排序規則表防止編譯器重排序
volatile重排序規則表(圖摘自書-併發編程的藝術)
-2 插入內存屏障防止處理器重排序
參考資料:
1、Java併發編程的藝術- 方騰飛
2、java多線程編程核心技術- 高洪岩
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
在眾多的編程語言中,我們的基礎語法總是少不了一些專業語法,比如像定義變量,條件語句,for循環,數組,函數等等,vue.js這個優秀的前端框架中也有同樣的語法,我們換一個名詞,將條件語句改成專業詞彙叫做條件渲染,循環語句改成專業詞彙叫做列表渲染,這樣比較舒服一點。
學會條件渲染的使用
學會可復用的key的使用
學會列表渲染的使用
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title></title> </head> <body> <div id="app01"> <span v-if="type==='A'">成績為A</span> </div> <script src="../js/vue.js"></script> <script> let vm=new Vue({ el:'#app01', data:{ type:'A' }, methods:{ }, watch:{ }, computed:{ } }) </script> </body> </html>
結果:成績為A
v-if判斷條件是否相等,就像if一樣,如果相等,那麼值就會true,與之對應的還有v-else,v-else-if
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title></title> </head> <body> <div id="app01"> <span v-if="type==='A'">成績為A</span> <span v-else>成績為B</span> </div> <script src="../js/vue.js"></script> <script> let vm=new Vue({ el:'#app01', data:{ type:'B' }, methods:{ }, watch:{ }, computed:{ } }) </script> </body> </html>
結果:成績為B
我們做一個小練習,鞏固一下v-if和v-else的使用,需求如下:點擊一個按鈕時,按鈕上的文字變為显示,再次點擊時按鈕上的文字變為隱藏,當按鈕上的文字显示隱藏時,显示紅色,按鈕上的文字變為显示時显示藍色
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title></title> <style type="text/css"> .box{ width: 100px; height: 100px; } .red{ background: red; } .blue{ background: blue; } </style> </head> <body> <div id="app"> <button @click="handleClick">{{text}}</button> <div v-if="show" class="box red"></div> <div v-else class="blue box"></div> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ show:true, text:'隱藏' }, methods:{ handleClick(){ this.show=!this.show; this.text=this.show?'隱藏':'显示' } } }) </script> </body> </html>
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title></title> </head> <body> <div id="app01"> <input type="text" v-model="type"/> <div v-if="type==='A'">成績為A</div> <div v-else-if="type==='B'">成績為B</div> <div v-else-if="type==='C'">成績為C</div> <div v-else>不及格</div> </div> <script src="../js/vue.js"></script> <script> let vm=new Vue({ el:'#app01', data:{ type:'' }, methods:{ }, watch:{ }, computed:{ } }) </script> </body> </html>
說起這個v-show,其實和v-if有與曲同工的妙處,但是又有不同的地方,我們來看下示例你就秒懂了
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title></title> <style type="text/css"> .box{ width: 100px; height: 100px; } .red{ background: red; } .blue{ background: blue; } </style> </head> <body> <div id="app"> <div v-show="show" class="box red"></div> <button @click="handleClick()">{{text}}</button> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ show:true, text:'隱藏', }, methods:{ handleClick(){ this.show=!this.show; this.text=this.show?'隱藏':'显示' } }, computed:{ } }) </script> </body> </html>
當按鈕變為显示的時候,背景顏色消失,這裏就不截圖了,有興趣的小夥伴可以自己去嘗試,既然v-if可以幫我們實現元素的显示和隱藏,那我們還需要v-show干什麼呢?不妨看下接下來的實例。
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title></title> <style type="text/css"> .box{ width: 100px; height: 100px; } .red{ background: red; } .blue{ background: blue; } </style> </head> <body> <div id="app"> <div v-show="show" class="box red"></div> <div class="box blue" v-if="show"></div> <button @click="handleClick()">{{text}}</button> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ show:true, text:'隱藏', }, methods:{ handleClick(){ this.show=!this.show; this.text=this.show?'隱藏':'显示' } }, computed:{ } }) </script> </body> </html>
當我們點擊按鈕的時候
現在結果已經出來了,使用v-show的dom元素,dom元素只是簡單的切換display屬性,而v-if會將dom元素移除,當我們再次點擊時,v-if又會重新渲染元素,可想而知如果頻繁的切換的話,那麼有多麼的耗費性能,因此我總結了如下幾點
頻繁的切換显示/隱藏要使用v-show
只判斷一次時,使用v-if
我們都知道js操作dom元素是非常消耗性能的,但是我們需要盡量的避免這個問題,vue中為我們提供了一個template標籤,這個標籤叫做模板(至於什麼叫做模板,後期的博客會講到),我們先看一個示例
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title></title> <style type="text/css"> .box{ width: 100px; height: 100px; } .red{ background: red; } .blue{ background: blue; } </style> </head> <body> <div id="app"> <div v-if="show"> <div class="box red"></div> <div class="box blue"></div> </div> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ show:true, }, methods:{ }, computed:{ } }) </script> </body> </html>
我們想讓圖上的那個div消失,不想為了管理同一組元素而多生成一個節點,這樣是非常消耗性能的,我們將div標籤變成template標籤
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title></title> <style type="text/css"> .box{ width: 100px; height: 100px; } .red{ background: red; } .blue{ background: blue; } </style> </head> <body> <div id="app"> <div v-if="show"> <div class="box red"></div> <div class="box blue"></div> </div> <template v-if="show"> <div class="box red"></div> <div class="box blue"></div> </template> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ show:true, }, methods:{ }, computed:{ } }) </script> </body> </html>
View Code
現在我有心中萌生了一個想法,v-if可以使用template,那麼v-show是否可以使用呢?
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title></title> <style type="text/css"> .box{ width: 100px; height: 100px; } .red{ background: red; } .blue{ background: blue; } </style> </head> <body> <div id="app"> <template v-if="show"> <div class="box red"></div> <div class="box blue"></div> </template> <template v-show="show"> <div class="box red"></div> <div class="box blue"></div> </template> <button @click="handleClick()">{{text}}</button> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ show:true, text:'隱藏', }, methods:{ handleClick(){ this.show=!this.show; this.text=this.show?'隱藏':'显示' } }, computed:{ } }) </script> </body> </html>
View Code
答案是v-if可以使用template,而v-show不能使用template
Vue 會盡可能高效地渲染元素,通常會復用已有元素而不是從頭開始渲染。這麼做除了使 Vue 變得非常快之外,還有其它一些好處。例如,如果你允許用戶在不同的登錄方式之間切換。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title></title> </head> <body> <div id="app01"> <template v-if="type==='username'"> <label>用戶名</label> <input type="text" placeholder="請輸入您的賬號" /> </template> <template v-else> <label>郵箱</label> <input type="text" placeholder="請輸入您的郵箱" /> </template> <p> <a href=""@click.prevent="type='username'">用戶名登錄</a>| <a href=""@click.prevent="type='email'">郵箱登錄</a> </p> </div> <script src="../js/vue.js"></script> <script> let vm=new Vue({ el:'#app01', data:{ isShow:true, type:'username' }, methods:{ }, watch:{ }, computed:{ } }) </script> </body> </html>
結果:
當我們在用戶名登錄和郵箱切換的時候,我們發現我們輸入的內容始終保持,為什麼呢?總的來說,因為兩個模板使用了相同的元素,input不會被替換掉——僅僅是替換了它的 placeholder屬性,這樣也不總是符合實際需求,所以 Vue 為你提供了一種方式來表達這兩個元素是完全獨立的,不要復用它們,只需添加一個具有唯一值的key屬性即可。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title></title> </head> <body> <div id="app01"> <template v-if="type==='username'"> <label>用戶名:</label> <input type="text" placeholder="請輸入您的用戶名" key='usename'/> </template> <template v-else> <label>郵箱:</label> <input type="text" placeholder="請輸入您的郵箱" key='email'/> </template> <p> <a href=""@click.prevent="type='username'">用戶名登錄</a>| <a href=""@click.prevent="type='email'">郵箱登錄</a> </p> </div> <script src="../js/vue.js"></script> <script> let vm=new Vue({ el:'#app01', data:{ isShow:true, type:'username' }, methods:{ }, watch:{ }, computed:{ } }) </script> </body> </html>
結果:
現在我們點擊切換的時候,輸入框都會重新渲染,當然我們的<label>標籤依舊的高效的復用,因為它沒有添加key。
我們用v-for指令根據一組數組的選項列表進行渲染,v-for指令需要以item in items的形式的特殊語法,items是原數據數組並且item是元素迭代的別名
語法:(item,index) in|of items
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>v-for的基本使用</title> </head> <body> <div id="app"> <ul> <li v-for="(item) in arr">{{item}}</li> </ul> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ arr:['apple','banana','pear'] }, methods:{ }, computed:{ } }) </script> </body> </html>
結果:
當然v-for中也可以帶第二個參數index
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>v-for的基本使用</title> </head> <body> <div id="app"> <ul> <li v-for="(item,index) in arr">{{item}}--{{index}}</li> </ul> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ arr:['apple','banana','pear'] }, methods:{ }, computed:{ } }) </script> </body> </html>
View Code
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>v-for的基本使用</title> </head> <body> <div id="app"> <ul> <li v-for="(item,index) in arr">{{item}}--{{index}}</li> </ul> <ul> <li v-for="item in 'helloworld'">{{item}}</li> </ul> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ arr:['apple','banana','pear'] }, methods:{ }, computed:{ } }) </script> </body> </html>
View Code
語法:(value,key,index) of | in items
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>v-for迭代對象</title> </head> <body> <div id="app"> <ul> <li v-for="(value,key,index) of obj">{{value}}-{{key}}-{{index}}</li> </ul> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ obj:{ name:'kk', age:18, sex:'male' } }, methods:{ }, computed:{ } }) </script> </body> </html>
結果:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>v-for迭代對象</title> </head> <body> <div id="app"> <ul> <li v-for="(value,key,index) of obj">{{value}}-{{key}}-{{index}}</li> </ul> <ul> <li v-for="item in 10">{{item}}</li> </ul> </div> <script src="../js/vue.js" type="text/javascript" charset="utf-8"></script> <script type="text/javascript"> let vm=new Vue({ el:'#app', data:{ obj:{ name:'kk', age:18, sex:'male' } }, methods:{ }, computed:{ } }) </script> </body> </html>
結果:
注意:但我們迭代整數的時候,item從1開始而不是從0開始
在本章內容中,我們一共學習了三個知識點,分別是條件渲染的使用(v-if,v-else,v-else-if),管理可復用的key,列表渲染(v-for的基本使用等等),本章的內容也多但是在實際應用上非常廣泛,畢竟這些是非常基礎的語法,基礎不牢,地動山搖,學習任何東西都需要自己一步一個腳印走出來。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!