我們知道感知器算法對於不能完全線性分割的數據是無能為力的,在這一篇將會介紹另一種非常有效的二分類模型——邏輯回歸。在分類任務中,它被廣泛使用
邏輯回歸是一個分類模型,在實現之前我們先介紹幾個概念:
幾率(odds ratio):
\[ \frac {p}{(1-p)} \]
其中p表示樣本為正例的概率,當然是我們來定義正例是什麼,比如我們要預測某種疾病的發生概率,那麼我們將患病的樣本記為正例,不患病的樣本記為負例。為了解釋清楚邏輯回歸的原理,我們先介紹幾個概念。
我們定義對數幾率函數(logit function)為:
\[ logit(p) = log \frac {p}{(1-p)} \]
對數幾率函數的自變量p取值範圍為0-1,通過函數將其轉化到整個實數範圍中,我們使用它來定義一個特徵值和對數幾率之間的線性關係為:
\[ logit(p(y=1|x)) = w_0x_0+w_1x_1+…+w_mx_m = \sum_i^nw_ix_i=w^Tx \]
在這裏,p(y=1|x)是某個樣本屬於類別1的條件概率。我們關心的是某個樣本屬於某個類別的概率,剛好是對數幾率函數的反函數,我們稱這個反函數為邏輯函數(logistics function),有時簡寫為sigmoid函數:
\[ \phi(z) = \frac{1}{1+e^{-z}} \]
其中z是權重向量w和輸入向量x的線性組合:
\[ z = w^Tx=w_0+w_1x_1+…+w_mx_m \]
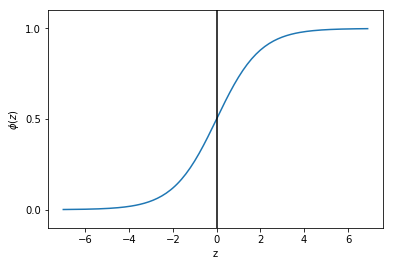
現在我們畫出這個函數圖像:
import matplotlib.pyplot as pltimport numpy as npdef sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))z = np.arange(-7, 7, 0.1)phi_z = sigmoid(z)plt.plot(z, phi_z)
plt.axvline(0.0, color='k')
plt.axhspan(0.0, 1.0, facecolor='1.0', alpha=1.0, ls='dotted')
plt.yticks([0.0, 0.5, 1.0])
plt.ylim(-0.1, 1.1)
plt.xlabel('z')
plt.ylabel('$\phi (z)$')
plt.show()可以看出當z接近於正無窮大時,函數值接近1,同樣當z接近於負無窮大時,函數值接近0。所以我們知道sigmoid函數將一個實數輸入轉化為一個範圍為0-1的一個輸出。
我們將邏輯函數將我們之前學過的Adaline聯繫起來,在Adaline中,我們的激活函數的函數值與輸入值相同,而在邏輯函數中,激活函數為sigmoid函數。
sigmoid函數的輸出被解釋為某個樣本屬於類別1的概率,用公式表示為:
\[ \hat y=\begin{cases}1,\quad \phi(z)\ge 0.5 \\\\0,\quad otherwise\end{cases} \]
也就是當函數值大於0.5時,表示某個樣本屬於類別1的概率大於0.5,於是我們就將此樣本預測為類別1,否則為類別0。我們仔細觀察上面的sigmoid函數圖像,上式也等價於:
\[ \hat y=\begin{cases}1,\quad z\ge 0.0 \\\\0,\quad otherwise\end{cases} \]
邏輯回歸的受歡迎之處就在於它可以預測發生某件事的概率,而不是預測這件事情是否發生。
我們已經介紹了邏輯回歸如何預測類別概率,接下來我們來看看邏輯回歸如何更新權重參數w。
對於Adaline,我們的損失函數為:
\[ J(w) = \sum_i\frac12(\phi(z^{(i)})-y^{(i)})^2 \]
我們通過最小化這個損失函數來更新權重w。為了解釋我們如何得到邏輯回歸的損失函數,在構建邏輯回歸模型時我們要最大化似然L(假設數據集中的所有樣本都是互相獨立的):
\[ L(w)=P(y|x,w)=\prod^n_{i=1}P(y^{(i)}|x^{(i)};w)=\prod^n_{i=1}(\phi(z^{(i)}))^{y^{(i)}}(1-\phi(z^{(i)}))^{1-y^{(i)}} \]
通常我們會最大化L的log形式,我們稱之為對數似然函數:
\[ l(w)=logL(w)=\sum_{i=1}^n\left[y^{(i)}log(\phi(z^{(i)})+(1-y^{(i)})log(1-\phi(z^{(i)}))\right] \]
這樣做有兩個好處,一是當似然很小時,取對數減小了数字下溢的可能性,二是取對數后將乘法轉化為了加法,可以更容易的得到函數的導數。現在我們可以使用一個梯度下降法來最大化對數似然函數,我們將上面的對數似然函數轉化為求最小值的損失函數J:
\[ J(w)=\sum_{i=1}^n\left[-y^{(i)}log(\phi(z^{(i)}))-(1-y^{(i)})log(1-\phi(z^{(i)}))\right] \]
為了更清晰的理解上式,我們假設對一個樣本計算它的損失函數:
\[ J(\phi(z),y;w)=-ylog(\phi(z))-(1-y)log(1-\phi(z)) \]
可以看出,當y=0時,式子的第一部分為0,當y=1時,式子的第二部分為0,也就是:
\[ J(\phi(z),y;w)=\begin{cases}-log(\phi(z)),\quad if\ y=1 \\\\-log(1-\phi(z)),\quad if \ y=0\end{cases} \]
可以看出,當我們預測樣本所屬於的類別時,當預測類別是樣本真實類別的概率越大時,損失越接近0,而當預測類別是真實類別的概率越小時,損失越接近無窮大。
作為舉例,我們這裏對權重向量w中的一個分量進行更新,首先我們求此分量的偏導數:
\[ \frac{\partial }{\partial w_j}l(w) = \left(y\frac{1}{\phi(z)}-(1-y)\frac{1}{1-\phi(z)}\right)\frac{\partial }{\partial w_j}\phi(z) \]
在繼續下去之前,我們先計算一下sigmoid函數的偏導數:
\[ \frac{\partial }{\partial z}\phi(z) = \frac{\partial }{\partial z}\frac{1}{1+e^{-z}}=\frac{1}{(1+e^{-z})^2}e^{-z}=\frac{1}{1+e^{-z}}(1-\frac{1}{1+e^{-z}})\\=\phi(z)(1-\phi(z)) \]
現在我們繼續:
\[ \left(y\frac{1}{\phi(z)}-(1-y)\frac{1}{1-\phi(z)}\right)\frac{\partial }{\partial w_j}\phi(z)\\=\left(y\frac{1}{\phi(z)}-(1-y)\frac{1}{1-\phi(z)}\right)\phi(z)(1-\phi(z))\frac{\partial }{\partial w_j}z\\=\left(y(1-\phi(z))-(1-y)\phi(z)\right)x_j\\=(y-\phi(z))x_j \]
所以我們的更新規則為:
\[ w_j = w_j + \eta\sum^n_{i=1}\left(y^{(i)}-\phi(z^{(i)})\right)x_j^{(i)} \]
因為我們要同時更新權重向量w的所有分量,所以我們更新規則為(此處w為向量):
\[ w = w+\Delta w\\\Delta w = \eta\nabla l(w) \]
因為最大化對數似然函數也就等價於最小化損失函數J,於是梯度下降更新規則為:
\[ \Delta w_j=-\eta\frac{\partial J}{\partial w_j}=\eta\sum^n_{i=1}\left(y^{(i)}-\phi(z^{(i)})\right)x^{(i)}_j\\w=w+\Delta w,\Delta w=-\eta \nabla J(w) \]
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!