整理:鄒敏惠(環境資訊中心記者)
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
0T版本則採用的是6速雙離合。有趣的是,1。5T採用7速雙離合,2。0T採用的是6速雙離合,這種做法倒與同是上汽出品的榮威RX5一樣。細分車型分析2017款銳騰的全系指導定價為9。88-16。88萬,而上一款的銳騰定價為10。97-17。97萬,整體售價門檻降低,而新增的全系標配的LED日間行車燈,車內後排出風口等配置,可以說MG銳騰此次經歷的是一個“降價增配”的中期改款。
MG 銳騰
一台家用車的百公里加速時間在10秒左右,那是比較正常的數值,而如果一台車的百公里加速時間在8秒內,可以說它的性能不容小覷,而如果一台車的加速時間在8秒內,還是一台自主品牌車型,更是一台SUV;它是誰?它是今天的主角—MG銳騰。
2017款的MG銳騰已經在近期上市,作為MG品牌下的首款SUV,中期改款后的它有什麼特點?不妨接着往下看看。
MG銳騰
指導價格:9.88-16.88萬(2017款)
2017款MG銳騰儘管是中期改款,但是改動幅度還是相對較大的,首先採用了面積更大的前進氣格柵,視覺效果上更加囂張,用全系標配的縱置LED日間行車燈替代了前霧燈;並且予以類似導風口的運動包圍裝飾。車尾的下包圍設計與前臉處相呼應,線條更加飽滿,將運動風格貫徹全車。
可以看出MG銳騰的設計風格將車輛的視覺效果營造得更加動感,但是小編個人覺得,MG未來會投產的一款小型SUV採用的大面積進氣格柵或許會更加好看,你們覺得呢?
內飾也讓設計師“動過刀”,融入了一定金屬風格的內飾看上去更加精緻,後排座椅出風口變為全系標配,這一點,必須要表揚一下,我一直在強調,後排出風口的搭載,不僅僅是提升了整車的檔次感,更是一定程度上照顧了後排乘客的需求。
動力層面新款銳騰沒有太多變化,採用的是1.5T和2.0T兩款渦輪增壓發動機,前者最大馬力169匹,峰值扭矩250牛米,後者最大馬力220匹,峰值扭矩350牛米;1.5T的發動機採用的是6速手動或者7速雙離合變速箱,而2.0T版本則採用的是6速雙離合。
有趣的是,1.5T採用7速雙離合,2.0T採用的是6速雙離合,這種做法倒與同是上汽出品的榮威RX5一樣。
細分車型分析
2017款銳騰的全系指導定價為9.88-16.88萬,而上一款的銳騰定價為10.97-17.97萬,整體售價門檻降低,而新增的全系標配的LED日間行車燈,車內後排出風口等配置,可以說MG銳騰此次經歷的是一個“降價增配”的中期改款。
由於售價9.88萬的最低配手動都市版沒有國人關注的ESp,所以不做推薦。小編個人推薦購買的是20T(1.5T)12.88萬的自動豪華版和13.88萬的自動尊享版。
一萬元的差距在於:無鑰匙進入和點火系統、定速巡航、主駕駛電動座椅調節、座椅加熱、自動頭燈、電動后視鏡摺疊這類便利性配置。是否選擇,就看你是否真心需要了。
MG銳騰的定位瞄準的消費人群是年輕一代的消費群體,MG的品牌源自於英國,但現在全部歸於上汽集團所有,作為品牌旗下的首款SUV,本次中期改款的感動幅度還算是比較大,而且增加了很實用的配置,性價比進一步提高。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
個人認為,昂克賽拉的兩廂版本比三廂版本更能體現魂動設計的精髓,整體的車身線條勾畫風格帶有一種柔美的韻律感,立體感強烈的車頭造型和線條飽滿,層次感豐富的線條所勾勒出的車尾,讓這台小車的氣質更加靈動時尚。對於昂科賽拉,在裸車價十五萬這個層次可以考慮的是兩廂2。
高顏值運動兩廂車
隨着時代的發展,兩廂版本的車型越來越被普羅大眾所接受;憑藉著動感時尚的外形,靈活的操控特性,越來越多的處於職業上升期的職場精英人士都會考慮選擇一款兩廂車作為人生首台代步工具。
作為一款兩廂轎車,我們不需要太高的預算,15萬左右的售價區間是當下很多人可接受的購車標準,本次小編整理了三款兼顧了顏值和操控的兩廂小車,供各位看官參考。
美系的不羈—別克威朗
儘管別克威朗2017款三廂版本已經上市,但是小編個人覺得2016款的兩廂版本威朗更具有年輕氣質。
威朗兩廂版看上去非常緊湊,沒有一絲拖泥帶水之感;前臉直瀑式的進氣格柵較為狹窄,營造出一種較為兇狠的俯衝式前臉,攻擊性很足,而車尾的懸浮式車頂也是當下較為時尚流行的設計元素,車尾用大量的線條勾勒出層次感豐富,頗上檔次的感覺。
小編推薦的車型是兩廂GS 20T雙離合燃情運動型,搭載的是一款1.5T直噴渦輪增壓發動機,最大馬力169匹,峰值扭矩250牛米,與之配合的是7速雙離合變速箱,1700轉迎來高扭矩平台,速度起來后頗有一種小鋼炮的勁頭。
雖然指導價格在17.59萬,但由於現在別克車型的全系降價幅度非常客觀,以廣州為例,普遍降價都到達2萬,威朗GS燃情運動型優惠后裸車價也就是在15萬左右,是一款非常不錯的A+級緊湊兩廂小車。
日系的騷氣—馬自達昂克賽拉
初窺馬自達的魂動設計理念之時,小編腦海中首先蹦出來的形容詞就是“騷氣”,這個形容詞在這裏不包含任何貶義。
個人認為,昂克賽拉的兩廂版本比三廂版本更能體現魂動設計的精髓,整體的車身線條勾畫風格帶有一種柔美的韻律感,立體感強烈的車頭造型和線條飽滿,層次感豐富的線條所勾勒出的車尾,讓這台小車的氣質更加靈動時尚。
對於昂科賽拉,在裸車價十五萬這個層次可以考慮的是兩廂2.0L自動運動型,搭載的是創馳藍天2.0L自然吸氣發動機,最大馬力158匹,峰值扭矩202牛米,傳動系統採用的是6速手自一體變速箱。基於馬自達一貫對於操控性的調校,昂科賽拉的駕駛樂趣和運動性能可以說是同級中名列前茅的存在,儘管賬面參數看上去不大,但是主觀感受還是一款非常快的小車。
法式的浪漫—標緻308S
近來法系車的設計師的設計理念少了一絲誇張與天馬行空,轉而回歸到更加平實圓潤更讓大眾所接受的風格,但從308S的外觀上還是可以看出一點法國人的浪漫情調。
車頭圓潤陰柔,不張揚跋扈,卻也個性十足,308S的前臉可以說是目前標緻品牌所採用的家族風格前臉的開山之作,車尾的后保險杠在308S的車身上看起來顯得比較寬大,肌肉感非常強烈。
標緻308S推薦車型是1.2T自動勁馳版,別小看了這台1.2T發動機,最大馬力136匹,峰值扭矩230牛米,這個參數已經可以趕超目前很多小排量4缸渦輪增壓發動機,韌勁十足的底盤,1750轉迎來的高扭矩爆發,以及戰鬥氛圍充足的駕駛艙,動感時尚、個性十足是我對於這台法系小車的評價。
全文總結:以上三款車型都是將外觀設計感、操控運動感兼顧的比較均衡的兩廂車型,外觀上更符合當下年輕消費者的審美,而都具備着不俗的動力表現;至於選擇哪個,以上三款車代表了三個車系,就看你對哪個品牌、哪個車系的選擇更加具有好感了。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
我們都知道,帶着一個小朋友出門得帶多少瑣碎的東西,如衣服、玩具、零食、備用藥品等等。當帶着兩個孩子出門時,出行所帶的物品自是翻倍。這時,可把第三排放倒,大大的拓寬了後備廂的空間,有充裕的空間放置行李,哪怕還要放上一輛兒童自行車,也不成問題。
2016年發生了不少大事,G20峰會舉辦、軍隊改革、註冊制提上議程等等,但是真正讓廣大中國老百姓關注的只有一件事,那就是二胎政策全面放開。
計劃生育這已經實行了三十多年的基本國策,深深地影響了現在已成為社會中流砥柱的80后這一代人。
有人說80后是最牛(tong)逼(ku)的一代,80後讀小學時讀大學不要錢,80後讀大學時讀小學不要錢;80后沒工作時工作是包分配的,80后開始找工作時只能自己拼搏;80后沒到結婚年齡時騎單車就能結婚,80後到了結婚年齡時必須有車子房子才能結婚,而二胎政策放開后,80后更是需要養四個老人加上兩個孩子。
儘管有着重重的困難,但根據一份對80后555人隨機調查的數據表示,還是有92%的人都是想生二胎的。因為對於80后這代來說,實在是太了解獨生子女的難處了:商量事情,找父母不合適,找朋友不是時刻在身邊;沒有能撒嬌的哥哥姐姐,沒有能展現對弟弟妹妹關懷的機會;和家人出外更加是沒有同齡人相伴玩耍,只能跟着爸媽,少了很多童年應該有的歡樂。
所以即使是現在奶粉、尿片要找海淘,去一次醫院檢查要排上大半天的隊,從幼兒園開始就要擔憂戶口所在地、有沒有學位房,每周安排滿滿的補習班、興趣班……這些繁重的壓力,他們還是想生二胎,為的就是能給下一代一個更好的生長環境。
當然,除去壓力之外,80后也很注重人與人之間的互動。他們會經常與朋友相聚、運動,也會時常和家人外出遊玩,讓孩子有更廣闊的視野和活動空間。因為他們都是不愛受拘束的人,所以他們的出行首選就是自駕游。這樣對於這一代的二胎家庭來說,家庭用車的選擇就至關重要了。安全舒適是必須要保證的,然後上有老下有小,足夠的座位也是不可或缺的。
小編覺得選擇一台7座SUV車型就是最合適的,因為一家四口,加上兩位老人家,這是他們最基本的用車需求。7座SUV不僅能夠滿足一個大家庭對於座位空間以及舒適性的需求,而帥氣的外觀以及不錯的通過性又能夠賦予它一些越野能力,比MpV更顯個性。7座SUV不僅可以滿足一家人日常使用以及車主的個性需求,還能帶你走更遠的路,去想去的地方。
當然這台7座SUV除了有寬敞的空間、優秀的舒適性以及可靠性外,安全性也必須是佼佼者,在小編看來廣汽豐田漢蘭達就是這樣的一款車。為什麼呢?
大空間
毫無爭議的同級第一
大空間是這個級別SUV的生存之本,漢蘭達作為這個級別SUV的開創者,在空間表現上自然不會讓人失望。漢蘭達的車身尺寸為4855*1925*1720mm,軸距為2790mm,這已經是一台全尺寸SUV的尺寸表現了。大尺寸帶來最大的好處就是大空間,漢蘭達的第二排腿部空間最大能夠達到1270mm,而同級的福特銳界僅為800mm,即使是售價百萬的加長奔馳S級,也僅僅為930mm而已。
而且相較於MpV而言,擁有大7座空間的漢蘭達更是宜商宜家。三排座位足夠7人乘坐,5人乘坐時折起第三排可是小貨車級別超大後備廂。座椅完全可依據乘坐的人數與放置的行李數量靈活地調整,二、三排座位可以根據不同需要拆分放倒調節,想坐哪裡就坐哪裡,想裝啥就裝啥,更加便捷實用。
我們都知道,帶着一個小朋友出門得帶多少瑣碎的東西,如衣服、玩具、零食、備用藥品等等。當帶着兩個孩子出門時,出行所帶的物品自是翻倍。這時,可把第三排放倒,大大的拓寬了後備廂的空間,有充裕的空間放置行李,哪怕還要放上一輛兒童自行車,也不成問題。
同時,漢蘭達在第二排處設計了兩個兒童安全座椅接口。而足夠寬敞的第二排,即使裝了兩個安全座椅,仍有比較充裕的空間,方便家長照顧孩子。當然,現在二胎家庭的孩子年齡會有一定差距,很多時候只需要安裝一張安全座椅,乘坐的空間更顯充裕。
安全性
北美同級SUV中唯一“頂級安全+”評價
對於家庭用戶來說,汽車的安全性是很重要的一個指標,畢竟一台家用7座SUV上往往滿載着三代人,漢蘭達在安全性上的表現怎樣呢?漢蘭達在我國的C-NACp測試中獲得5星評價,其中難度較高的側面碰撞和鞭打測試漢蘭達均獲得滿分。
這當然不是巧合,漢蘭達的工程師在設計研發階段便十分下功夫,漢蘭達獨有的GOA車身大家都不陌生,GOA車身的核心便是超高剛性的車身與有效的吸能設計。要知道發生強烈碰撞時,乘坐艙不變形以及發動機艙的緩衝吸能才是保證生命安全的關鍵。其它諸如VSC車身穩定系統,ACC自適應巡航、pCS預碰撞剎車輔助系統、RCTA倒車警示系統、BSM行車變道警示系統等諸多主動安全配置也能夠為安全行駛保駕護航。
低油耗
車主油耗9.0L/100km左右
對於漢蘭達這個級別尺寸的大7座SUV來說,除了輕易超過1.8噸的重量之外,往往都搭載了2.0T的發動機,大多數車型百公里油耗也是輕鬆飆上13升以上。這對於上有老下有小的顧家好男人來說,真的是錢包難受有木有?而豐田車省油大家都是比較熟悉的,那麼漢蘭達的油耗是什麼水平呢?
漢蘭達2.0T四驅車型的工信部油耗為8.7L/100km,車主反映實際使用油耗為9.0L/100km左右,而同級的銳界2.0T四驅車型的工信部油耗就已高達10L/100km,大家都知道渦輪增壓車型實際油耗要比工信部油耗高不少,那麼實際油耗想都不敢想了。畢竟兩個孩子耗費的奶粉、紙尿片等等的消耗品花銷真不小,要是油費省下來的就可以更多的花費在小孩子身上了!
大空間能保證一家人出行的便利和舒適,出眾的安全性能夠為家人的安全保駕護航,低油耗意味着低使用成本。在小編看來只有具備了這三個優勢的SUV才能成為一部合格的大7座家用SUV車型,真正走進千家萬戶。
漢蘭達自從推出伊始便受到熱捧,不僅僅是因為多年耕耘下來的口碑使然,更是強大產品實力的印證,漢蘭達的出現為中國的二胎家庭提出了一個完美的出行解決方案,實實在在的大7座空間與感動世界的可靠品質,最高評價的安全性與優異的油耗表現都是中國消費者最需要的,20-30萬左右許許多多的7座SUV可以選擇,而小編推薦的只有漢蘭達這一款。
本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
摘錄自2020年7月28日中央廣播電台報導
根據一項28日發布的報告,澳洲在2019年到2020年所發生的前所未見野火災難中,有將近30億動物死亡或被迫遷徙。報告指出,這場野火是「現代歷史中最慘烈的野火災難之一」。這項由數所澳洲大學科學家所進行的研究指出,被侵襲的野生生命包括1.43億哺乳類動物,24.6億爬蟲類、1.8億鳥類,以及5,100萬的蛙類。
雖然報告沒有說明有多少動物因野火死亡,但報告作者之一狄克曼(Chris Dickman)表示,由於缺乏食物、避難所以及未受到保護,那些從烈焰中逃出的動物前景「可能很不好」。
雪梨大學(University of Sydney)的首席科學家伊登(Lily van Eeden)表示,今天公佈的這項調查是首度涵蓋全澳洲大陸的野火區。
這項調查的結果仍在處理中,最終報告將於下個月底發布。不過,報告作者們表示,30億動物受影響的這個數字不太可能改變。
生物多樣性
環境新聞
國際新聞
澳洲
澳洲野火
氣候變遷
棲地保育
森林
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
摘錄自2020年7月28日公視報導
南美洲除了要應付疫情之外,還有森林野火狀況。像巴西的西南邊,靠近玻利維亞和巴拉圭的濕地區域,在今年上半年,起火次數比去年增加158%。
橫跨巴西、玻利維亞和巴拉圭,號稱全球最大熱帶濕地的潘塔納烏。除了是世界第一大的水生植物集中地,也是動植物最密集的生態系統。然而,它和巴西北部的亞馬遜河流域一樣,面臨濫墾濫伐的危機。
外電報導指出,今年上半年當地零星的野火多達2534起,比去年同期的981起暴增百分之158,還沒過完的7月,又增加1300多起。被燒毀的森林和草地總面積,高達5100平方公里,相當於雙北、基隆、桃園再加上半個宜蘭縣的範圍。
儘管巴西政府在7月16日頒布行政命令,禁止農民焚燒林地開墾,有效期限4個月,但禁令頒布以來,野火仍舊超過1000起,凸顯問題的嚴重性。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
目錄
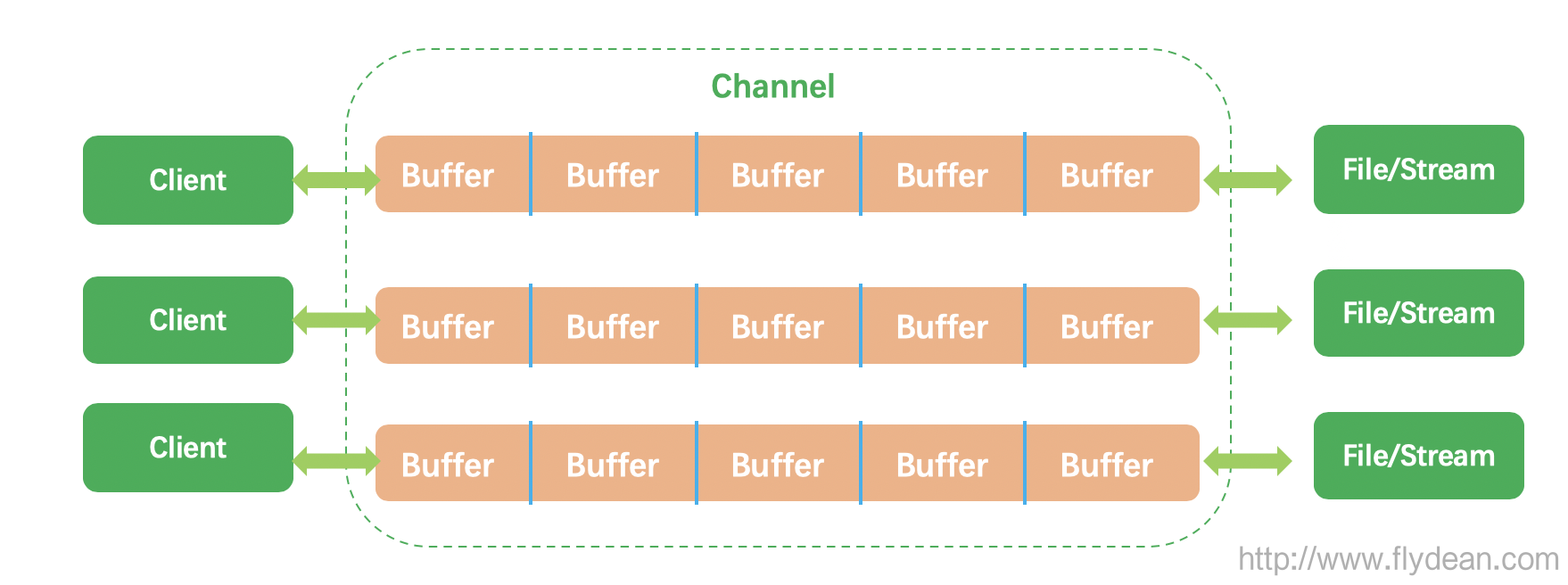
小師妹,你還記得我們使用IO和NIO的初心嗎?
小師妹:F師兄,使用IO和NIO不就是為了讓生活更美好,世界充滿愛嗎?讓我等程序員可以優雅的將數據從一個地方搬運到另外一個地方。利其器,善其事,才有更多的時間去享受生活呀。
善,如果將數據比做人,IO,NIO的目的就是把人運到美國。
小師妹:F師兄,為什麼要運到美國呀,美國現在新冠太嚴重了,還是待在中國吧。中國是世界上最安全的國家!
好吧,為了保險起見,我們要把人運到上海。人就是數據,怎麼運過去呢?可以坐飛機,坐汽車,坐火車,這些什麼飛機,汽車,火車就可以看做是一個一個的Buffer。
最後飛機的航線,汽車的公路和火車的軌道就可以看做是一個個的channel。
更多精彩內容且看:
簡單點講,channel就是負責運送Buffer的通道。
IO按源頭來分,可以分為兩種,從文件來的File IO,從Stream來的Stream IO。不管哪種IO,都可以通過channel來運送數據。
雖然數據的來源只有兩種,但是JDK中Channel的分類可不少,如下圖所示:
先來看看最基本的,也是最頂層的接口Channel:
public interface Channel extends Closeable {
public boolean isOpen();
public void close() throws IOException;
}
最頂層的Channel很簡單,繼承了Closeable接口,需要實現兩個方法isOpen和close。
一個用來判斷channel是否打開,一個用來關閉channel。
小師妹:F師兄,頂層的Channel怎麼這麼簡單,完全不符合Channel很複雜的人設啊。
別急,JDK這麼做其實也是有道理的,因為是頂層的接口,必須要更加抽象更加通用,結果,一通用就發現還真的就只有這麼兩個方法是通用的。
所以為了應對這個問題,Channel中定義了很多種不同的類型。
最最底層的Channel有5大類型,分別是:
這5大channel中,和文件File有關的就是這個FileChannel了。
FileChannel可以從RandomAccessFile, FileInputStream或者FileOutputStream中通過調用getChannel()來得到。
也可以直接調用FileChannel中的open方法傳入Path創建。
public abstract class FileChannel
extends AbstractInterruptibleChannel
implements SeekableByteChannel, GatheringByteChannel, ScatteringByteChannel
我們看下FileChannel繼承或者實現的接口和類。
AbstractInterruptibleChannel實現了InterruptibleChannel接口,interrupt大家都知道吧,用來中斷線程執行的利器。來看一下下面一段非常玄妙的代碼:
protected final void begin() {
if (interruptor == null) {
interruptor = new Interruptible() {
public void interrupt(Thread target) {
synchronized (closeLock) {
if (closed)
return;
closed = true;
interrupted = target;
try {
AbstractInterruptibleChannel.this.implCloseChannel();
} catch (IOException x) { }
}
}};
}
blockedOn(interruptor);
Thread me = Thread.currentThread();
if (me.isInterrupted())
interruptor.interrupt(me);
}
上面這段代碼就是AbstractInterruptibleChannel的核心所在。
首先定義了一個Interruptible的實例,這個實例中有一個interrupt方法,用來關閉Channel。
然後獲得當前線程的實例,判斷當前線程是否Interrupted,如果是的話,就調用Interruptible的interrupt方法將當前channel關閉。
SeekableByteChannel用來連接Entry或者File。它有一個獨特的屬性叫做position,表示當前讀取的位置。可以被修改。
GatheringByteChannel和ScatteringByteChannel表示可以一次讀寫一個Buffer序列結合(Buffer Array):
public long write(ByteBuffer[] srcs, int offset, int length)
throws IOException;
public long read(ByteBuffer[] dsts, int offset, int length)
throws IOException;
在講其他幾個Channel之前,我們看一個和下面幾個channel相關的Selector:
這裏要介紹一個新的Channel類型叫做SelectableChannel,之前的FileChannel的連接是一對一的,也就是說一個channel要對應一個處理的線程。而SelectableChannel則是一對多的,也就是說一個處理線程可以通過Selector來對應處理多個channel。
SelectableChannel通過註冊不同的SelectionKey,實現對多個Channel的監聽。後面我們會具體的講解Selector的使用,敬請期待。
DatagramChannel是用來處理UDP的Channel。它自帶了Open方法來創建實例。
來看看DatagramChannel的定義:
public abstract class DatagramChannel
extends AbstractSelectableChannel
implements ByteChannel, ScatteringByteChannel, GatheringByteChannel, MulticastChannel
ByteChannel表示它同時是ReadableByteChannel也是WritableByteChannel,可以同時寫入和讀取。
MulticastChannel代表的是一種多播協議。正好和UDP對應。
SocketChannel是用來處理TCP的channel。它也是通過Open方法來創建的。
public abstract class SocketChannel
extends AbstractSelectableChannel
implements ByteChannel, ScatteringByteChannel, GatheringByteChannel, NetworkChannel
SocketChannel跟DatagramChannel的唯一不同之處就是實現的是NetworkChannel借口。
NetworkChannel提供了一些network socket的操作,比如綁定地址等。
ServerSocketChannel也是一個NetworkChannel,它主要用在服務器端的監聽。
public abstract class ServerSocketChannel
extends AbstractSelectableChannel
implements NetworkChannel
最後AsynchronousSocketChannel是一種異步的Channel:
public abstract class AsynchronousSocketChannel
implements AsynchronousByteChannel, NetworkChannel
為什麼是異步呢?我們看一個方法:
public abstract Future<Integer> read(ByteBuffer dst);
可以看到返回值是一個Future,所以read方法可以立刻返回,只在我們需要的時候從Future中取值即可。
小師妹:F師兄,講了這麼多種類的Channel,看得我眼花繚亂,能不能講一個Channel的具體例子呢?
好的小師妹,我們現在講一個使用Channel進行文件拷貝的例子,雖然Channel提供了transferTo的方法可以非常簡單的進行拷貝,但是為了能夠看清楚Channel的通用使用,我們選擇一個更加常規的例子:
public void useChannelCopy() throws IOException {
FileInputStream input = new FileInputStream ("src/main/resources/www.flydean.com");
FileOutputStream output = new FileOutputStream ("src/main/resources/www.flydean.com.txt");
try(ReadableByteChannel source = input.getChannel(); WritableByteChannel dest = output.getChannel()){
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (source.read(buffer) != -1)
{
// flip buffer,準備寫入
buffer.flip();
// 查看是否有更多的內容
while (buffer.hasRemaining())
{
dest.write(buffer);
}
// clear buffer,供下一次使用
buffer.clear();
}
}
}
上面的例子中我們從InputStream中讀取Buffer,然後寫入到FileOutputStream。
今天講解了Channel的具體分類,和一個簡單的例子,後面我們會再體驗一下Channel的其他例子,敬請期待。
本文的例子https://github.com/ddean2009/learn-java-io-nio
本文作者:flydean程序那些事
本文鏈接:http://www.flydean.com/java-io-nio-channel/
本文來源:flydean的博客
歡迎關注我的公眾號:程序那些事,更多精彩等着您!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
本系列文章:
讀源碼,我們可以從第一行讀起
你知道Spring是怎麼解析配置類的嗎?
配置類為什麼要添加@Configuration註解?
推薦閱讀:
Spring官網閱讀 | 總結篇
Spring雜談
本系列文章將會帶你一行行的將Spring的源碼吃透,推薦閱讀的文章是閱讀源碼的基礎!
在開始探討源碼前,我們先思考兩個問題:
通過new關鍵字,反射,克隆等手段創建出來的就是對象。在Spring中,Bean一定是一個對象,但是對象不一定是一個Bean,一個被創建出來的對象要變成一個Bean要經過很多複雜的工序,例如需要被我們的
BeanPostProcessor處理,需要經過初始化,需要經過AOP(AOP本身也是由後置處理器完成的)等。
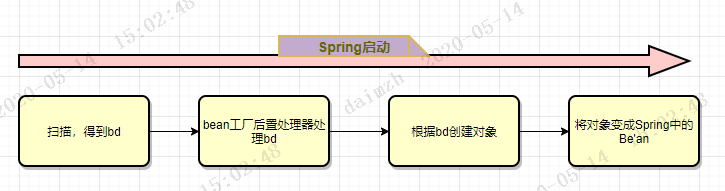
我們還是回到流程圖中,其中相關的步驟如下:
在前面的三篇文章中,我們已經分析到了第3-5步的源碼,而如果你對Spring源碼稍有了解的話,就是知道創建對象以及將對象變成一個Bean的過程發生在第3-11步驟中。中間的五步分別做了什麼呢?
就像名字所說的那樣,註冊BeanPostProcessor,這段代碼在Spring官網閱讀(八)容器的擴展點(三)(BeanPostProcessor)已經分析過了,所以在本文就直接跳過了,如果你沒有看過之前的文章也沒有關係,你只需要知道,在這裏Spring將所有的BeanPostProcessor註冊到了容器中
初始化容器中的messageSource,如果程序員沒有提供,默認會創建一個org.springframework.context.support.DelegatingMessageSource,Spring官網閱讀(十一)ApplicationContext詳細介紹(上) 已經介紹過了。
初始化事件分發器,如果程序員沒有提供,那麼默認創建一個org.springframework.context.event.ApplicationEventMulticaster,Spring官網閱讀(十二)ApplicationContext詳解(中)已經做過詳細分析,不再贅述
留給子類複寫擴展使用
註冊事件監聽器,就是將容器中所有實現了org.springframework.context.ApplicationListener接口的對象放入到監聽器的集合中。
在完成了上面的一些準備工作后,Spring開始來創建Bean了,按照流程,首先被調用的就是
finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory)方法,我們就以這個方法為入口,一步步跟蹤源碼,看看Spring中的Bean到底是怎麼創建出來的,當然,本文主要關注的是創建對象的這個過程,對象變成Bean的流程我們在後續文章中再分析
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// 初始化一個ConversionService用於類型轉換,這個ConversionService會在實例化對象的時候用到
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
// 添加一個StringValueResolver,用於處理佔位符,可以看到,默認情況下就是使用環境中的屬性值來替代佔位符中的屬性
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
// 創建所有的LoadTimeWeaverAware
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// 靜態織入完成后將臨時的類加載器設置為null,所以除了創建LoadTimeWeaverAware時可能會用到臨時類加載器,其餘情況下都為空
beanFactory.setTempClassLoader(null);
// 將所有的配置信息凍結
beanFactory.freezeConfiguration();
// 開始進行真正的創建
beanFactory.preInstantiateSingletons();
}
上面的方法最終調用了org.springframework.beans.factory.support.DefaultListableBeanFactory#preInstantiateSingletons來創建Bean。
其源碼如下:
public void preInstantiateSingletons() throws BeansException {
// 所有bd的名稱
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// 遍歷所有bd,一個個進行創建
for (String beanName : beanNames) {
// 獲取到指定名稱對應的bd
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
// 對不是延遲加載的單例的Bean進行創建
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// 判斷是否是一個FactoryBean
if (isFactoryBean(beanName)) {
// 如果是一個factoryBean的話,先創建這個factoryBean,創建factoryBean時,需要在beanName前面拼接一個&符號
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
final FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged((PrivilegedAction<Boolean>)
((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
// 判斷是否是一個SmartFactoryBean,並且不是懶加載的,就意味着,在創建了這個factoryBean之後要立馬調用它的getObject方法創建另外一個Bean
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
// 不是factoryBean的話,我們直接創建就行了
getBean(beanName);
}
}
}
// 在創建了所有的Bean之後,遍歷
for (String beanName : beanNames) {
// 這一步其實是從緩存中獲取對應的創建的Bean,這裏獲取到的必定是單例的
Object singletonInstance = getSingleton(beanName);
// 判斷是否是一個SmartInitializingSingleton,最典型的就是我們之前分析過的EventListenerMethodProcessor,在這一步完成了對已經創建好的Bean的解析,會判斷其方法上是否有 @EventListener註解,會將這個註解標註的方法通過EventListenerFactory轉換成一個事件監聽器並添加到監聽器的集合中
if (singletonInstance instanceof SmartInitializingSingleton) {
final SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
}
上面這段代碼整體來說應該不難,不過它涉及到了一個點就是factoryBean,如果你對它不夠了解的話,請參考我之前的一篇文章:Spring官網閱讀(七)容器的擴展點(二)FactoryBean
從上面的代碼分析中我們可以知道,Spring最終都會調用到getBean方法,而getBean並不是真正幹活的,doGetBean才是。另外doGetBean可以分為兩種情況
FactoryBean,此時實際傳入的name = & + beanNamename = beanName其代碼如下:
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
// 前面我們說過了,傳入的name可能時& + beanName這種形式,這裏做的就是去除掉&,得到beanName
final String beanName = transformedBeanName(name);
Object bean;
// 這個方法就很牛逼了,通過它解決了循環依賴的問題,不過目前我們只需要知道它是從單例池中獲取已經創建的Bean即可,循環依賴後面我單獨寫一篇文章
// 方法作用:已經創建的Bean會被放到單例池中,這裏就是從單例池中獲取
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
// 如果直接從單例池中獲取到了這個bean(sharedInstance),我們能直接返回嗎?
// 當然不能,因為獲取到的Bean可能是一個factoryBean,如果我們傳入的name是 & + beanName 這種形式的話,那是可以返回的,但是我們傳入的更可能是一個beanName,那麼這個時候Spring就還需要調用這個sharedInstance的getObject方法來創建真正被需要的Bean
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
// 在緩存中獲取不到這個Bean
// 原型下的循環依賴直接報錯
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// 核心要義,找不到我們就從父容器中再找一次
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
String nameToLookup = originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory) {
return ((AbstractBeanFactory) parentBeanFactory).doGetBean(
nameToLookup, requiredType, args, typeCheckOnly);
}
else if (args != null) {
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else if (requiredType != null) {
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
else {
return (T) parentBeanFactory.getBean(nameToLookup);
}
}
// 如果不僅僅是為了類型推斷,也就是代表我們要對進行實例化
// 那麼就將bean標記為正在創建中,其實就是將這個beanName放入到alreadyCreated這個set集合中
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
try {
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
// 檢查合併后的bd是否是abstract,這個檢查現在已經沒有作用了,必定會通過
checkMergedBeanDefinition(mbd, beanName, args);
// @DependsOn註解標註的當前這個Bean所依賴的bean名稱的集合,就是說在創建當前這個Bean前,必須要先將其依賴的Bean先完成創建
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
// 遍歷所有申明的依賴
for (String dep : dependsOn) {
// 如果這個bean所依賴的bean又依賴了當前這個bean,出現了循環依賴,直接報錯
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
// 註冊bean跟其依賴的依賴關係,key為依賴,value為依賴所從屬的bean
registerDependentBean(dep, beanName);
try {
// 先創建其依賴的Bean
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}
// 我們目前只分析單例的創建,單例看懂了,原型自然就懂了
if (mbd.isSingleton()) {
// 這裏再次調用了getSingleton方法,這裏跟方法開頭調用的getSingleton的區別在於,這個方法多傳入了一個ObjectFactory類型的參數,這個ObjectFactory會返回一個Bean
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 省略原型跟域對象的相關代碼
return (T) bean;
}
配合註釋看這段代碼應該也不難吧,我們重點關注最後在調用的這段方法即可
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
// 從單例池中獲取,這個地方肯定也獲取不到
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 工廠已經在銷毀階段了,這個時候還在創建Bean的話,就直接拋出異常
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
// 在單例創建前,記錄一下正在創建的單例的名稱,就是把beanName放入到singletonsCurrentlyInCreation這個set集合中去
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 這裏調用了singletonFactory的getObject方法,對應的實現就是在doGetBean中的那一段lambda表達式
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// 省略異常處理
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// 在單例完成創建后,將beanName從singletonsCurrentlyInCreation中移除
// 標志著這個單例已經完成了創建
afterSingletonCreation(beanName);
}
if (newSingleton) {
// 添加到單例池中
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
分析完上面這段代碼,我們會發現,核心的創建Bean的邏輯就是在singletonFactory.getObject()這句代碼中,而其實現就是在doGetBean方法中的那一段lambda表達式,如下:
實際就是通過createBean這個方法創建了一個Bean然後返回,createBean又幹了什麼呢?
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
RootBeanDefinition mbdToUse = mbd;
// 解析得到beanClass,為什麼需要解析呢?如果是從XML中解析出來的標籤屬性肯定是個字符串嘛
// 所以這裏需要加載類,得到Class對象
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
// 對XML標籤中定義的lookUp屬性進行預處理,如果只能根據名字找到一個就標記為非重載的,這樣在後續就不需要去推斷到底是哪個方法了,對於@LookUp註解標註的方法是不需要在這裏處理的,AutowiredAnnotationBeanPostProcessor會處理這個註解
try {
mbdToUse.prepareMethodOverrides();
}
// 省略異常處理...
try {
// 在實例化對象前,會經過後置處理器處理
// 這個後置處理器的提供了一個短路機制,就是可以提前結束整個Bean的生命周期,直接從這裏返回一個Bean
// 不過我們一般不會這麼做,它的另外一個作用就是對AOP提供了支持,在這裡會將一些不需要被代理的Bean進行標記,就本文而言,你可以暫時理解它沒有起到任何作用
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
// 省略異常處理...
try {
// doXXX方法,真正幹活的方法,doCreateBean,真正創建Bean的方法
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
// 省略異常處理...
}
本文只探討對象是怎麼創建的,至於怎麼從一個對象變成了Bean,在後面的文章我們再討論,所以我們主要就關注下面這段代碼
// 這個方法真正創建了Bean,創建一個Bean會經過 創建對象 > 依賴注入 > 初始化 這三個過程,在這個過程中,BeanPostPorcessor會穿插執行,本文主要探討的是創建對象的過程,所以關於依賴注入及初始化我們暫時省略,在後續的文章中再繼續研究
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
// 這行代碼看起來就跟factoryBean相關,這是什麼意思呢?
// 在下文我會通過例子介紹下,你可以暫時理解為,這個地方返回的就是個null
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
// 這裏真正的創建了對象
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 省略依賴注入,初始化
}
這裏我先分析下this.factoryBeanInstanceCache.remove(beanName)這行代碼。這裏需要說一句,我寫的這個源碼分析的系列非常的細節,之所以選擇這樣一個個扣細節是因為我自己在閱讀源碼過程中經常會被這些問題阻塞,那麼藉著這些文章將自己踩過的坑分享出來可以減少作為讀者的你自己在閱讀源碼時的障礙,其次也能夠提升自己閱讀源碼的能力。如果你對這些細節不感興趣的話,可以直接跳過,能把握源碼的主線即可。言歸正傳,我們回到這行代碼this.factoryBeanInstanceCache.remove(beanName)。什麼時候factoryBeanInstanceCache這個集合中會有值呢?這裏我還是以示例代碼來說明這個問題,示例代碼如下:
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(Config.class);
}
}
// 沒有做什麼特殊的配置,就是掃描了需要的組件,測試時換成你自己的包名
@ComponentScan("com.dmz.source.instantiation")
@Configuration
public class Config {
}
// 這裏申明了一個FactoryBean,並且通過@DependsOn註解申明了這個FactoryBean的創建要在orderService之後,主要目的是為了在DmzFactoryBean創建前讓容器發生一次屬性注入
@Component
@DependsOn("orderService")
public class DmzFactoryBean implements FactoryBean<DmzService> {
@Override
public DmzService getObject() throws Exception {
return new DmzService();
}
@Override
public Class<?> getObjectType() {
return DmzService.class;
}
}
// 沒有通過註解的方式將它放到容器中,而是通過上面的DmzFactoryBean來管理對應的Bean
public class DmzService {
}
// OrderService中需要注入dmzService
@Component
public class OrderService {
@Autowired
DmzService dmzService;
}
在這段代碼中,因為我們明確的表示了DmzFactoryBean是依賴於orderService的,所以必定會先創建orderService再創建DmzFactoryBean,創建orderService的流程如下:
其中的屬性注入階段,我們需要細化,也可以畫圖如下:
為orderService進行屬性注入可以分為這麼幾步
找到需要注入的注入點,也就是orderService中的dmzService字段
根據字段的類型以及名稱去容器中查詢符合要求的Bean
當遍歷到一個FactroyBean時,為了確定其getObject方法返回的對象的類型需要創建這個FactroyBean(只會到對象級別),然後調用這個創建好的FactroyBean的getObjectType方法明確其類型並與注入點需要的類型比較,看是否是一個候選的Bean,在創建這個FactroyBean時就將其放入了factoryBeanInstanceCache中。
在確定了唯一的候選Bean之後,Spring就會對這個Bean進行創建,創建的過程又經過三個步驟
在創建對象時,因為此時factoryBeanInstanceCache已經緩存了這個Bean對應的對象,所以直接通過this.factoryBeanInstanceCache.remove(beanName)這行代碼就返回了,避免了二次創建對象。
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
Class<?> beanClass = resolveBeanClass(mbd, beanName);
// 省略異常
// 通過bd中提供的instanceSupplier來獲取一個對象
// 正常bd中都不會有這個instanceSupplier屬性,這裏也是Spring提供的一個擴展點,但實際上不常用
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}
// bd中提供了factoryMethodName屬性,那麼要使用工廠方法的方式來創建對象,工廠方法又會區分靜態工廠方法跟實例工廠方法
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
// 在原型模式下,如果已經創建過一次這個Bean了,那麼就不需要再次推斷構造函數了
boolean resolved = false; // 是否推斷過構造函數
boolean autowireNecessary = false; // 構造函數是否需要進行注入
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
if (autowireNecessary) {
return autowireConstructor(beanName, mbd, null, null);
}
else {
return instantiateBean(beanName, mbd);
}
}
// 推斷構造函數
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// 調用無參構造函數創建對象
return instantiateBean(beanName, mbd);
}
上面這段代碼在Spring官網閱讀(一)容器及實例化 已經分析過了,但是當時我們沒有深究創建對象的細節,所以本文將詳細探討Spring中的這個對象到底是怎麼創建出來的,這也是本文的主題。
在Spring官網閱讀(一)容器及實例化 這篇文章中,我畫了下面這麼一張圖
從上圖中我們可以知道Spring在實例化對象的時候有這麼幾種方式
我們接下來就一一分析其中的細節:
在Spring官網閱讀(一)容器及實例化 文中介紹過這種方式,因為這種方式我們基本不會使用,並不重要,所以這裏就不再贅述,我這裏就直接給出一個使用示例,大家自行體會吧
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
// 直接註冊一個Bean,並且指定它的supplier就是Service::new
ac.registerBean("service", Service.class,Service::new,zhe'sh);
ac.refresh();
System.out.println(ac.getBean("service"));
}
對應代碼如下:
protected BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
return new ConstructorResolver(this).instantiateUsingFactoryMethod(beanName, mbd, explicitArgs);
}
上面這段代碼主要幹了兩件事
ConstructorResolver對象,從類名來看,它是一個構造器解析器instantiateUsingFactoryMethod方法,這個方法見名知意,使用FactoryMethod來完成實例化基於此,我們解決一個問題,ConstructorResolver是什麼?
在要研究一個類前,我們最先應該從哪裡入手呢?很多沒有經驗的同學可能會悶頭看代碼,但是實際上最好的學習方式是先閱讀類上的javaDoc
ConstructorResolver上的javaDoc如下:
上面這段javaDoc翻譯過來就是這個類就是用來解析構造函數跟工廠方法的代理者,並且它是通過參數匹配的方式來進行推斷構造方法或者工廠方法。
看到這裏不知道小夥伴們是否有疑問,就是明明這個類不僅負責推斷構造函數,還會負責推斷工廠方法,那麼為什麼類名會叫做ConstructorResolver呢?我們知道Spring的代碼在業界來說絕對是最規範的,沒有之一,這樣來說的話,這個類最合適的名稱應該是ConstructorAndFactoryMethodResolver才對,因為它不僅負責推斷了構造函數還負責推斷了工廠方法嘛!
這裏我需要說一下我自己的理解。對於一個Bean,它是通過構造函數完成實例化的,或者通過工廠方法實例化的,其實在這個Bean看來都沒有太大區別,這兩者都可以稱之為這個Bean的構造器,因為通過它們都能構造出一個Bean。所以Spring就把兩者統稱為構造器了,所以這個類名也就被稱為ConstructorResolver了。
Spring在很多地方體現了這種實現,例如在XML配置的情況下,不論我們是使用構造函數創建對象還是使用工廠方法創建對象,其參數的標籤都是使用constructor-arg。比如下面這個例子
<bean id="dmzServiceGetFromStaticMethod"
factory-bean="factoryBean"
factory-method="getObject">
<constructor-arg type="java.lang.String" value="hello" name="s"/>
<constructor-arg type="com.dmz.source.instantiation.service.DmzFactory" ref="factoryBean"/>
</bean>
<!--測試靜態工廠方法創建對象-->
<bean id="service"
class="com.dmz.official.service.MyFactoryBean"
factory-method="staticGet">
<constructor-arg type="java.lang.String" value="hello"/>
</bean>
<bean id="dmzService" class="com.dmz.source.instantiation.service.DmzService">
<constructor-arg name="s" value="hello"/>
</bean>
在對這個類有了大概的了解后,我們就需要來分析它的源碼,這裏我就不把它單獨拎出來分析了,我們藉著Spring的流程看看這個類幹了什麼事情
核心目的:推斷出要使用的factoryMethod以及調用這個FactoryMethod要使用的參數,然後反射調用這個方法實例化出一個對象
這個方法的代碼太長了,所以我們將它拆分成為一段一段的來分析
在分析上面的代碼之前,我們先來看看這個方法的參數都是什麼含義
方法上關於參數的介紹如圖所示
beanName:當前要實例化的Bean的名稱mbd:當前要實例化的Bean對應的BeanDefinitionexplicitArgs:這個參數在容器啟動階段我們可以認定它就是null,只有显示的調用了getBean方法,並且傳入了明確的參數,例如:getBean("dmzService","hello")這種情況下才會不為null,我們分析這個方法的時候就直接認定這個參數為null即可。public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代碼:創建並初始話一個BeanWrapperImpl
BeanWrapperImpl bw = new BeanWrapperImpl();
this.beanFactory.initBeanWrapper(bw);
// ......
}
BeanWrapperImpl是什麼呢?如果你看過我之前的文章:Spring官網閱讀(十四)Spring中的BeanWrapper及類型轉換,那麼你對這個類應該不會陌生,它就是對Bean進行了一層包裝,並且在創建Bean的時候以及進行屬性注入的時候能夠進行類型轉換。就算你沒看過之前的文章也沒關係,只要記住兩點
其層級關係如下:
回到我們的源碼分析,我們先來看看new BeanWrapperImpl()做了什麼事情?
對應代碼如下:
// 第一步:調用空參構造
public BeanWrapperImpl() {
// 調用另外一個構造函數,表示要註冊默認的屬性編輯器
this(true);
}
// 這個構造函數表明是否要註冊默認編輯器,上面傳入的值為true,表示需要註冊
public BeanWrapperImpl(boolean registerDefaultEditors) {
super(registerDefaultEditors);
}
// 調用到父類的構造函數,確定要使用默認的屬性編輯器
protected AbstractNestablePropertyAccessor(boolean registerDefaultEditors) {
if (registerDefaultEditors) {
registerDefaultEditors();
}
// 對typeConverterDelegate進行初始化
this.typeConverterDelegate = new TypeConverterDelegate(this);
}
總的來說創建的過程非常簡單。第一,確定要註冊默認的屬性編輯器;第二,對typeConverterDelegate屬性進行初始化。
緊接着,我們看看在初始化這個BeanWrapper做了什麼?
// 初始化BeanWrapper,主要就是將容器中配置的conversionService賦值到當前這個BeanWrapper上
// 同時註冊定製的屬性編輯器
protected void initBeanWrapper(BeanWrapper bw) {
bw.setConversionService(getConversionService());
registerCustomEditors(bw);
}
還記得conversionService在什麼時候被放到容器中的嗎?就是在finishBeanFactoryInitialization的時候啦~!
對conversionService屬性完成賦值后就開始註冊定製的屬性編輯器,代碼如下:
// 傳入的參數就是我們的BeanWrapper,它同時也是一個屬性編輯器註冊表
protected void registerCustomEditors(PropertyEditorRegistry registry) {
PropertyEditorRegistrySupport registrySupport =
(registry instanceof PropertyEditorRegistrySupport ? (PropertyEditorRegistrySupport) registry : null);
if (registrySupport != null) {
// 這個配置的作用就是在註冊默認的屬性編輯器時,可以增加對數組到字符串的轉換功能
// 默認就是通過","來切割字符串轉換成數組,對應的屬性編輯器就是StringArrayPropertyEditor
registrySupport.useConfigValueEditors();
}
// 將容器中的屬性編輯器註冊到當前的這個BeanWrapper
if (!this.propertyEditorRegistrars.isEmpty()) {
for (PropertyEditorRegistrar registrar : this.propertyEditorRegistrars) {
registrar.registerCustomEditors(registry);
// 省略異常處理~
}
}
// 這裏我們沒有添加任何的自定義的屬性編輯器,所以肯定為空
if (!this.customEditors.isEmpty()) {
this.customEditors.forEach((requiredType, editorClass) ->
registry.registerCustomEditor(requiredType, BeanUtils.instantiateClass(editorClass)));
}
}
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 省略已經分析的第一段代碼,到這裏已經得到了一個具有類型轉換功能的BeanWrapper
// 實例化這個Bean的工廠Bean
Object factoryBean;
// 工廠Bean的Class
Class<?> factoryClass;
// 靜態工廠方法或者是實例化工廠方法
boolean isStatic;
/*下面這段代碼就是為上面申明的這三個屬性賦值*/
String factoryBeanName = mbd.getFactoryBeanName();
// 如果創建這個Bean的工廠就是這個Bean本身的話,那麼直接拋出異常
if (factoryBeanName != null) {
if (factoryBeanName.equals(beanName)) {
throw new BeanDefinitionStoreException(mbd.getResourceDescription(), beanName,
"factory-bean reference points back to the same bean definition");
}
// 得到創建這個Bean的工廠Bean
factoryBean = this.beanFactory.getBean(factoryBeanName);
if (mbd.isSingleton() && this.beanFactory.containsSingleton(beanName)) {
throw new ImplicitlyAppearedSingletonException();
}
factoryClass = factoryBean.getClass();
isStatic = false;
}
else {
// factoryBeanName為null,說明是通過靜態工廠方法來實例化Bean的
// 靜態工廠進行實例化Bean,beanClass屬性必須要是工廠的class,如果為空,直接報錯
if (!mbd.hasBeanClass()) {
throw new BeanDefinitionStoreException(mbd.getResourceDescription(), beanName,
"bean definition declares neither a bean class nor a factory-bean reference");
}
factoryBean = null;
factoryClass = mbd.getBeanClass();
isStatic = true;
}
// 省略後續代碼
}
小總結:
這段代碼很簡單,就是確認實例化當前這個Bean的工廠方法是靜態工廠還是實例工廠,如果是實例工廠,那麼找出對應的工廠Bean。
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 省略第一段,第二段代碼
// 到這裏已經得到了一個BeanWrapper,明確了實例化當前這個Bean到底是靜態工廠還是實例工廠
// 並且已經確定了工廠Bean
// 最終確定的要用來創建對象的方法
Method factoryMethodToUse = null;
ArgumentsHolder argsHolderToUse = null;
Object[] argsToUse = null;
// 參數分析時已經說過,explicitArgs就是null
if (explicitArgs != null) {
argsToUse = explicitArgs;
}
else {
// 下面這段代碼是什麼意思呢?
// 在原型模式下,我們會多次創建一個Bean,所以Spring對參數以及所使用的方法做了緩存
// 在第二次創建原型對象的時候會進入這段緩存的邏輯
// 但是這裡有個問題,為什麼Spring對參數有兩個緩存呢?
// 一:resolvedConstructorArguments
// 二:preparedConstructorArguments
// 這裏主要是因為,直接使用解析好的構造的參數,因為這樣會導致創建出來的所有Bean都引用同一個屬性
Object[] argsToResolve = null;
synchronized (mbd.constructorArgumentLock) {
factoryMethodToUse = (Method) mbd.resolvedConstructorOrFactoryMethod;
// 緩存已經解析過的工廠方法或者構造方法
if (factoryMethodToUse != null && mbd.constructorArgumentsResolved) {
// resolvedConstructorArguments跟preparedConstructorArguments都是對參數的緩存
argsToUse = mbd.resolvedConstructorArguments;
if (argsToUse == null) {
argsToResolve = mbd.preparedConstructorArguments;
}
}
}
if (argsToResolve != null) {
// preparedConstructorArguments需要再次進行解析
argsToUse = resolvePreparedArguments(beanName, mbd, bw, factoryMethodToUse, argsToResolve);
}
}
// 省略後續代碼
}
小總結:
上面這段代碼應該沒什麼大問題,其核心思想就是從緩存中取已經解析出來的方法以及參數,這段代碼只會在原型模式下生效,因為單例的話對象只會創建一次嘛~!最大的問題在於,為什麼在對參數進行緩存的時候使用了兩個不同的集合,並且緩存后的參數還需要再次解析,這個問題我們暫且放着,不妨帶着這個問題往下看。
因為接下來要分析的代碼就比較複雜了,所以為了讓你徹底看到代碼的執行流程,下面我會使用示例+流程圖+文字的方式來分析源碼。
示例代碼如下(這個例子覆蓋接下來要分析的所有流程):
配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"
default-autowire="constructor"><!--這裏開啟自動注入,並且是通過構造函數進行自動注入-->
<!--factoryObject 提供了創建對象的方法-->
<bean id="factoryObject" class="com.dmz.spring.first.instantiation.service.FactoryObject"/>
<!--提供一個用於測試自動注入的對象-->
<bean class="com.dmz.spring.first.instantiation.service.OrderService" id="orderService"/>
<!--主要測試這個對象的實例化過程-->
<bean id="dmzService" factory-bean="factoryObject" factory-method="getDmz" scope="prototype">
<constructor-arg name="name" value="dmz"/>
<constructor-arg name="age" value="18"/>
<constructor-arg name="birthDay" value="2020-05-23"/>
</bean>
<!--測試靜態方法實例化對象的過程-->
<bean id="indexService" class="com.dmz.spring.first.instantiation.service.FactoryObject"
factory-method="staticGetIndex"/>
<!--提供這個轉換器,用於轉換dmzService中的birthDay屬性,從字符串轉換成日期對象-->
<bean class="org.springframework.context.support.ConversionServiceFactoryBean" id="conversionService">
<property name="converters">
<set>
<bean class="com.dmz.spring.first.instantiation.service.ConverterStr2Date"/>
</set>
</property>
</bean>
</beans>
測試代碼:
public class FactoryObject {
public DmzService getDmz(String name, int age, Date birthDay, OrderService orderService) {
System.out.println("getDmz with "+"name,age,birthDay and orderService");
return new DmzService();
}
public DmzService getDmz(String name, int age, Date birthDay) {
System.out.println("getDmz with "+"name,age,birthDay");
return new DmzService();
}
public DmzService getDmz(String name, int age) {
System.out.println("getDmz with "+"name,age");
return new DmzService();
}
public DmzService getDmz() {
System.out.println("getDmz with empty arg");
return new DmzService();
}
public static IndexService staticGetIndex() {
return new IndexService();
}
}
public class DmzService {
}
public class IndexService {
}
public class OrderService {
}
public class ConverterStr2Date implements Converter<String, Date> {
@Override
public Date convert(String source) {
try {
return new SimpleDateFormat("yyyy-MM-dd").parse(source);
} catch (ParseException e) {
return null;
}
}
}
/**
* @author 程序員DMZ
* @Date Create in 23:14 2020/5/21
* @Blog https://daimingzhi.blog.csdn.net/
*/
public class Main {
public static void main(String[] args) {
ClassPathXmlApplicationContext cc = new ClassPathXmlApplicationContext();
cc.setConfigLocation("application.xml");
cc.refresh();
cc.getBean("dmzService");
// 兩次調用,用於測試緩存的方法及參數
// cc.getBean("dmzService");
}
}
運行上面的代碼會發現,程序打印:
getDmz with name,age,birthDay and orderService
具體原因我相信你看了接下來的源碼分析自然就懂了
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代碼:到這裏已經得到了一個BeanWrapper,並對這個BeanWrapper做了初始化
// 第二段代碼:明確了實例化當前這個Bean到底是靜態工廠還是實例工廠
// 第三段代碼:以及從緩存中取過了對應了方法以及參數
// 進入第四段代碼分析,執行到這段代碼說明是第一次實例化這個對象
if (factoryMethodToUse == null || argsToUse == null) {
// 如果被cglib代理的話,獲取父類的class
factoryClass = ClassUtils.getUserClass(factoryClass);
// 獲取到工廠類中的所有方法,接下來要一步步從這些方法中篩選出來符合要求的方法
Method[] rawCandidates = getCandidateMethods(factoryClass, mbd);
List<Method> candidateList = new ArrayList<>();
// 第一步篩選:之前 在第二段代碼中已經推斷了方法是靜態或者非靜態的
// 所以這裏第一個要求就是要滿足靜態/非靜態這個條件
// 第二個要求就是必須符合bd中定義的factoryMethodName的名稱
// 其中第二個要求請注意,如果bd是一個configurationClassBeanDefinition,也就是說是通過掃描@Bean註解產生的,那麼在判斷時還會添加是否標註了@Bean註解
for (Method candidate : rawCandidates) {
if (Modifier.isStatic(candidate.getModifiers()) == isStatic && mbd.isFactoryMethod(candidate)) {
candidateList.add(candidate);
}
}
// 將之前得到的方法集合轉換成數組
// 到這一步得到的其實就是某一個方法的所有重載方法
// 比如dmz(),dmz(String name),dmz(String name,int age)
Method[] candidates = candidateList.toArray(new Method[0]);
// 排序,public跟參數多的優先級越高
AutowireUtils.sortFactoryMethods(candidates);
// 用來保存從配置文件中解析出來的參數
ConstructorArgumentValues resolvedValues = null;
// 是否使用了自動注入,本段代碼中沒有使用到這個屬性,但是在後面用到了
boolean autowiring = (mbd.getResolvedAutowireMode() == AutowireCapableBeanFactory.AUTOWIRE_CONSTRUCTOR);
int minTypeDiffWeight = Integer.MAX_VALUE;
// 可能出現多個符合要求的方法,用這個集合保存,實際上如果這個集合有值,就會拋出異常了
Set<Method> ambiguousFactoryMethods = null;
int minNrOfArgs;
// 必定為null,不考慮了
if (explicitArgs != null) {
minNrOfArgs = explicitArgs.length;
}
else {
// 就是說配置文件中指定了要使用的參數,那麼需要對其進行解析,解析后的值就存儲在resolvedValues這個集合中
if (mbd.hasConstructorArgumentValues()) {
// 通過解析constructor-arg標籤,將參數封裝成了ConstructorArgumentValues
// ConstructorArgumentValues這個類在下文我們專門分析
ConstructorArgumentValues cargs = mbd.getConstructorArgumentValues();
resolvedValues = new ConstructorArgumentValues();
// 解析標籤中的屬性,類似進行類型轉換,後文進行詳細分析
minNrOfArgs = resolveConstructorArguments(beanName, mbd, bw, cargs, resolvedValues);
}
else {
// 配置文件中沒有指定要使用的參數,所以執行方法的最小參數個數就是0
minNrOfArgs = 0;
}
}
// 省略後續代碼....
}
小總結:
因為在實例化對象前必定要先確定具體要使用的方法,所以這裏先做的第一件事就是確定要在哪個範圍內去推斷要使用的factoryMethod呢?
最大的範圍就是這個factoryClass的所有方法,也就是源碼中的
rawCandidates其次需要在
rawCandidates中進一步做推斷,因為在前面第二段代碼的時候已經確定了是靜態方法還是非靜態方法,並且BeanDefinition也指定了factoryMethodName,那麼基於這兩個條件這裏就需要對rawCandidates進一步進行篩選,得到一個candidateList集合。我們對示例的代碼進行調試會發現
確實如我們所料,
rawCandidates是factoryClass中的所有方法,candidateList是所有getDmz的重載方法。在確定了推斷factoryMethod的範圍后,那麼接下來要根據什麼去確定到底使用哪個方法呢?換個問題,怎麼區分這麼些重載的方法呢?肯定是根據方法參數嘛!
所以接下來要做的就是去解析要使用的參數了~
對於Spring而言,方法的參數會分為兩種
- 配置文件中指定的
- 自動注入模式下,需要去容器中查找的
在上面的代碼中,Spring就是將配置文件中指定的參數做了一次解析,對應方法就是
resolveConstructorArguments。在查看這個方法的源碼前,我們先看看
ConstructorArgumentValues這個類public class ConstructorArgumentValues { // 通過下標方式指定的參數 private final Map<Integer, ValueHolder> indexedArgumentValues = new LinkedHashMap<>(); // 沒有指定下標 private final List<ValueHolder> genericArgumentValues = new ArrayList<>(); // 省略無關代碼..... }在前文的註釋中我們也說過了,它主要的作用就是封裝解析
constructor-arg標籤得到的屬性,解析標籤對應的方法就是org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parseConstructorArgElement,這個方法我就不帶大家看了,有興趣的可以自行閱讀。它主要有兩個屬性
- indexedArgumentValues
- genericArgumentValues
對應的就是我們兩種指定參數的方法,如下:
<bean id="dmzService" factory-bean="factoryObject" factory-method="getDmz" scope="prototype"> <constructor-arg name="name" value="dmz"/> <constructor-arg name="age" value="18"/> <constructor-arg index="2" value="2020-05-23"/> <!-- <constructor-arg name="birthDay" value="2020-05-23"/>--> </bean>其中的name跟age屬性會被解析為
genericArgumentValues,而index=2會被解析為indexedArgumentValues。在對
ConstructorArgumentValues有一定認知之後,我們再來看看resolveConstructorArguments的代碼:// 方法目的:解析配置文件中指定的方法參數 // beanName:bean名稱 // mbd:beanName對應的beanDefinition // bw:通過它進行類型轉換 // ConstructorArgumentValues cargs:解析標籤得到的屬性,還沒有經過解析(類型轉換) // ConstructorArgumentValues resolvedValues:已經經過解析的參數 // 返回值:返回方法需要的最小參數個數 private int resolveConstructorArguments(String beanName, RootBeanDefinition mbd, BeanWrapper bw, ConstructorArgumentValues cargs, ConstructorArgumentValues resolvedValues) { // 是否有定製的類型轉換器,沒有的話直接使用BeanWrapper進行類型轉換 TypeConverter customConverter = this.beanFactory.getCustomTypeConverter(); TypeConverter converter = (customConverter != null ? customConverter : bw); // 構造一個BeanDefinitionValueResolver,專門用於解析constructor-arg中的value屬性,實際上還包括ref屬性,內嵌bean標籤等等 BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this.beanFactory, beanName, mbd, converter); // minNrOfArgs 記錄執行方法要求的最小參數個數,一般情況下就是等於constructor-arg標籤指定的參數數量 int minNrOfArgs = cargs.getArgumentCount(); for (Map.Entry<Integer, ConstructorArgumentValues.ValueHolder> entry : cargs.getIndexedArgumentValues().entrySet()) { int index = entry.getKey(); if (index < 0) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid constructor argument index: " + index); } // 這是啥意思呢? // 這個代碼我認為是有問題的,並且我給Spring官方已經提了一個issue,官方將會在5.2.7版本中修復 // 暫且你先這樣理解 // 假設A方法直接在配置文件中指定了index=3上要使用的參數,那麼這個時候A方法至少需要4個參數 // 但是其餘的3個參數可能不是通過constructor-arg標籤指定的,而是直接自動注入進來的,那麼在配置文件中我們就只配置了index=3上的參數,也就是說 int minNrOfArgs = cargs.getArgumentCount()=1,這個時候 index=3,minNrOfArgs=1, 所以 minNrOfArgs = 3+1 if (index > minNrOfArgs) { minNrOfArgs = index + 1; } ConstructorArgumentValues.ValueHolder valueHolder = entry.getValue(); // 如果已經轉換過了,直接添加到resolvedValues集合中 if (valueHolder.isConverted()) { resolvedValues.addIndexedArgumentValue(index, valueHolder); } else { // 解析value/ref/內嵌bean標籤等 Object resolvedValue = valueResolver.resolveValueIfNecessary("constructor argument", valueHolder.getValue()); // 將解析后的resolvedValue封裝成一個新的ValueHolder,並將其source設置為解析constructor-arg得到的那個ValueHolder,後期會用到這個屬性進行判斷 ConstructorArgumentValues.ValueHolder resolvedValueHolder = new ConstructorArgumentValues.ValueHolder(resolvedValue, valueHolder.getType(), valueHolder.getName()); resolvedValueHolder.setSource(valueHolder); resolvedValues.addIndexedArgumentValue(index, resolvedValueHolder); } } // 對getGenericArgumentValues進行解析,代碼基本一樣,不再贅述 return minNrOfArgs; }可以看到,最終的解析邏輯就在
resolveValueIfNecessary這個方法中,那麼這個方法又做了什麼呢?// 這個方法的目的就是將解析constructor-arg標籤得到的value值進行一次解析 // 在解析標籤時ref屬性會被封裝為RuntimeBeanReference,那麼在這裏進行解析時就會去調用getBean // 在解析value屬性會會被封裝為TypedStringValue,那麼這裡會嘗試去進行一個轉換 // 關於標籤的解析大家有興趣的話可以去看看org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parsePropertyValue // 這裏不再贅述了 public Object resolveValueIfNecessary(Object argName, @Nullable Object value) { // 解析constructor-arg標籤中的ref屬性,實際就是調用了getBean if (value instanceof RuntimeBeanReference) { RuntimeBeanReference ref = (RuntimeBeanReference) value; return resolveReference(argName, ref); } // ...... /** * <constructor-arg> * <set value-type="java.lang.String"> * <value>1</value> * </set> * </constructor-arg> * 通過上面set標籤中的value-type屬性對value進行類型轉換, * 如果value-type屬性為空,那麼這裏不會進行類型轉換 */ else if (value instanceof TypedStringValue) { TypedStringValue typedStringValue = (TypedStringValue) value; Object valueObject = evaluate(typedStringValue); try { Class<?> resolvedTargetType = resolveTargetType(typedStringValue); if (resolvedTargetType != null) { return this.typeConverter.convertIfNecessary(valueObject, resolvedTargetType); } else { return valueObject; } } catch (Throwable ex) { // Improve the message by showing the context. throw new BeanCreationException( this.beanDefinition.getResourceDescription(), this.beanName, "Error converting typed String value for " + argName, ex); } } // 省略後續代碼.... }就我們上面的例子而言,經過
resolveValueIfNecessary方法並不能產生實際的影響,因為在XML中我們沒有配置ref屬性或者value-type屬性。畫圖如下:
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代碼:到這裏已經得到了一個BeanWrapper,並對這個BeanWrapper做了初始化
// 第二段代碼:明確了實例化當前這個Bean到底是靜態工廠還是實例工廠
// 第三段代碼:以及從緩存中取過了對應了方法以及參數
// 第四段代碼:明確了方法需要的最小的參數數量並對配置文件中的標籤屬性進行了一次解析
// 進入第五段代碼分析
// 保存在創建方法參數數組過程中發生的異常,如果最終沒有找到合適的方法,那麼將這個異常信息封裝后拋出
LinkedList<UnsatisfiedDependencyException> causes = null;
// 開始遍歷所有在第四段代碼中查詢到的符合要求的方法
for (Method candidate : candidates) {
// 方法的參數類型
Class<?>[] paramTypes = candidate.getParameterTypes();
// 候選的方法的參數必須要大於在第四段這推斷出來的最小參數個數
if (paramTypes.length >= minNrOfArgs) {
ArgumentsHolder argsHolder;
// 必定為null,不考慮
if (explicitArgs != null) {
// Explicit arguments given -> arguments length must match exactly.
if (paramTypes.length != explicitArgs.length) {
continue;
}
argsHolder = new ArgumentsHolder(explicitArgs);
}
else {
// Resolved constructor arguments: type conversion and/or autowiring necessary.
try {
// 獲取參數的具體名稱
String[] paramNames = null;
ParameterNameDiscoverer pnd = this.beanFactory.getParameterNameDiscoverer();
if (pnd != null) {
paramNames = pnd.getParameterNames(candidate);
}
// 根據方法的參數名稱以及配置文件中配置的參數創建一個參數數組用於執行工廠方法
argsHolder = createArgumentArray(
beanName, mbd, resolvedValues, bw, paramTypes, paramNames, candidate, autowiring);
}
// 在創建參數數組的時候可能發生異常,這個時候的異常不能直接拋出,要確保所有的候選方法遍歷完成,只要有一個方法符合要求即可,但是如果遍歷完所有方法還是沒找到合適的構造器,那麼直接拋出這些異常
catch (UnsatisfiedDependencyException ex) {
if (logger.isTraceEnabled()) {
logger.trace("Ignoring factory method [" + candidate + "] of bean '" + beanName + "': " + ex);
}
// Swallow and try next overloaded factory method.
if (causes == null) {
causes = new LinkedList<>();
}
causes.add(ex);
continue;
}
// 計算類型差異
// 首先判斷bd中是寬鬆模式還是嚴格模式,目前看來只有@Bean標註的方法解析得到的Bean會使用嚴格模式來計算類型差異,其餘都是使用寬鬆模式
// 嚴格模式下,
int typeDiffWeight = (mbd.isLenientConstructorResolution() ?
argsHolder.getTypeDifferenceWeight(paramTypes) : argsHolder.getAssignabilityWeight(paramTypes));
// 選擇一個類型差異最小的方法
if (typeDiffWeight < minTypeDiffWeight) {
factoryMethodToUse = candidate;
argsHolderToUse = argsHolder;
argsToUse = argsHolder.arguments;
minTypeDiffWeight = typeDiffWeight;
ambiguousFactoryMethods = null;
}
// 省略後續代碼.......
}
小總結:這段代碼的核心思想就是根據
第四段代碼從配置文件中解析出來的參數構造方法執行所需要的實際參數數組。如果構建成功就代表這個方法可以用於實例化Bean,然後計算實際使用的參數跟方法上申明的參數的”差異值“,並在所有符合要求的方法中選擇一個差異值最小的方法接下來,我們來分析方法實現的細節
- 構建方法使用的參數數組,也就是
createArgumentArray方法,其源碼如下:/* beanName:要實例化的Bean的名稱 * mbd:對應Bean的BeanDefinition * resolvedValues:從配置文件中解析出來的並嘗試過類型轉換的參數 * bw:在這裏主要就是用作類型轉換器 * paramTypes:當前遍歷到的候選的方法的參數類型數組 * paramNames:當前遍歷到的候選的方法的參數名稱 * executable:當前遍歷到的候選的方法 * autowiring:是否時自動注入 */ private ArgumentsHolder createArgumentArray( String beanName, RootBeanDefinition mbd, @Nullable ConstructorArgumentValues resolvedValues, BeanWrapper bw, Class<?>[] paramTypes, @Nullable String[] paramNames, Executable executable, boolean autowiring) throws UnsatisfiedDependencyException { TypeConverter customConverter = this.beanFactory.getCustomTypeConverter(); TypeConverter converter = (customConverter != null ? customConverter : bw); ArgumentsHolder args = new ArgumentsHolder(paramTypes.length); Set<ConstructorArgumentValues.ValueHolder> usedValueHolders = new HashSet<>(paramTypes.length); Set<String> autowiredBeanNames = new LinkedHashSet<>(4); // 遍歷候選方法的參數,跟據方法實際需要的類型到resolvedValues中去匹配 for (int paramIndex = 0; paramIndex < paramTypes.length; paramIndex++) { Class<?> paramType = paramTypes[paramIndex]; String paramName = (paramNames != null ? paramNames[paramIndex] : ""); ConstructorArgumentValues.ValueHolder valueHolder = null; if (resolvedValues != null) { // 首先,根據方法參數的下標到resolvedValues中找對應的下標的屬性 // 如果沒找到再根據方法的參數名/類型去resolvedValues查找 valueHolder = resolvedValues.getArgumentValue(paramIndex, paramType, paramName, usedValueHolders); // 如果都沒找到 // 1.是自動注入並且方法的參數長度正好跟配置中的參數數量相等 // 2.不是自動注入 // 那麼按照順序一次選取 if (valueHolder == null && (!autowiring || paramTypes.length == resolvedValues.getArgumentCount())) { valueHolder = resolvedValues.getGenericArgumentValue(null, null, usedValueHolders); } } // 也就是說在配置的參數中找到了合適的值可以應用於這個方法上 if (valueHolder != null) { // 防止同一個參數被應用了多次 usedValueHolders.add(valueHolder); Object originalValue = valueHolder.getValue(); Object convertedValue; // 已經進行過類型轉換就不會需要再次進行類型轉換 if (valueHolder.isConverted()) { convertedValue = valueHolder.getConvertedValue(); args.preparedArguments[paramIndex] = convertedValue; } else { // 嘗試將配置的值轉換成方法參數需要的類型 MethodParameter methodParam = MethodParameter.forExecutable(executable, paramIndex); try { // 進行類型轉換 convertedValue = converter.convertIfNecessary(originalValue, paramType, methodParam); } catch (TypeMismatchException ex) { // 拋出UnsatisfiedDependencyException,在調用該方法處會被捕獲 } Object sourceHolder = valueHolder.getSource(); // 只要是valueHolder存在,到這裏這個判斷必定成立 if (sourceHolder instanceof ConstructorArgumentValues.ValueHolder) { Object sourceValue = ((ConstructorArgumentValues.ValueHolder) sourceHolder).getValue(); args.resolveNecessary = true; args.preparedArguments[paramIndex] = sourceValue; } } args.arguments[paramIndex] = convertedValue; args.rawArguments[paramIndex] = originalValue; } else { // 方法執行需要參數,但是resolvedValues中沒有提供這個參數,也就是說這個參數是要自動注入到Bean中的 MethodParameter methodParam = MethodParameter.forExecutable(executable, paramIndex); // 不是自動注入,直接拋出異常 if (!autowiring) { // 拋出UnsatisfiedDependencyException,在調用該方法處會被捕獲 } try { // 自動注入的情況下,調用getBean獲取需要注入的Bean Object autowiredArgument = resolveAutowiredArgument(methodParam, beanName, autowiredBeanNames, converter); // 把getBean返回的Bean封裝到本次方法執行時需要的參數數組中去 args.rawArguments[paramIndex] = autowiredArgument; args.arguments[paramIndex] = autowiredArgument; // 標誌這個參數是自動注入的 args.preparedArguments[paramIndex] = new AutowiredArgumentMarker(); // 自動注入的情況下,在第二次調用時,需要重新處理,不能直接緩存 args.resolveNecessary = true; } catch (BeansException ex) { // 拋出UnsatisfiedDependencyException,在調用該方法處會被捕獲 } } } // 註冊Bean之間的依賴關係 for (String autowiredBeanName : autowiredBeanNames) { this.beanFactory.registerDependentBean(autowiredBeanName, beanName); if (logger.isDebugEnabled()) { logger.debug("Autowiring by type from bean name '" + beanName + "' via " + (executable instanceof Constructor ? "constructor" : "factory method") + " to bean named '" + autowiredBeanName + "'"); } } return args; }上面這段代碼說難也難,說簡單也簡單,如果要徹底看懂它到底幹了什麼還是很有難度的。簡單來說,它就是從第四段代碼解析出來的參數中查找當前的這個候選方法需要的參數。如果找到了,那麼嘗試對其進行類型轉換,將其轉換成符合方法要求的類型,如果沒有找到那麼還需要判斷當前方法的這個參數能不能進行自動注入,如果可以自動注入的話,那麼調用getBean得到需要的Bean,並將其注入到方法需要的參數中。
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代碼:到這裏已經得到了一個BeanWrapper,並對這個BeanWrapper做了初始化
// 第二段代碼:明確了實例化當前這個Bean到底是靜態工廠還是實例工廠
// 第三段代碼:以及從緩存中取過了對應了方法以及參數
// 第四段代碼:明確了方法需要的最小的參數數量並對配置文件中的標籤屬性進行了一次解析
// 第五段代碼:到這裏已經確定了可以使用來實例化Bean的方法是哪個
// 省略拋出異常的代碼,就是在對推斷出來的方法做驗證
// 1.推斷出來的方法不能為null
// 2.推斷出來的方法返回值不能為void
// 3.推斷出來的方法不能有多個
// 對參數進行緩存
if (explicitArgs == null && argsHolderToUse != null) {
argsHolderToUse.storeCache(mbd, factoryMethodToUse);
}
}
try {
Object beanInstance;
if (System.getSecurityManager() != null) {
final Object fb = factoryBean;
final Method factoryMethod = factoryMethodToUse;
final Object[] args = argsToUse;
beanInstance = AccessController.doPrivileged((PrivilegedAction<Object>) () ->
beanFactory.getInstantiationStrategy().instantiate(mbd, beanName, beanFactory, fb, factoryMethod, args),
beanFactory.getAccessControlContext());
}
else {
// 反射調用對應方法進行實例化
// 1.獲取InstantiationStrategy,主要就是SimpleInstantiationStrategy跟CglibSubclassingInstantiationStrategy,其中CglibSubclassingInstantiationStrategy主要是用來處理beanDefinition中的lookupMethod跟replaceMethod。通常來說我們使用的就是SimpleInstantiationStrateg
// 2.SimpleInstantiationStrateg就是單純的通過反射調用方法
beanInstance = this.beanFactory.getInstantiationStrategy().instantiate(
mbd, beanName, this.beanFactory, factoryBean, factoryMethodToUse, argsToUse);
}
// beanWrapper在這裏對Bean進行了包裝
bw.setBeanInstance(beanInstance);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean instantiation via factory method failed", ex);
}
}
上面這段代碼的主要目的就是
- 緩存參數,原型可能多次創建同一個對象
- 反射調用推斷出來的factoryMethod
如果上面你對使用factoryMethd進行實例化對象已經足夠了解的話,那麼下面的源碼分析基本沒有什麼很大區別,我們接着看看代碼。
首先,我們回到createBeanInstance方法中,
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
// 上面的代碼已經分析過了
// 1.使用supplier來得到一個對象
// 2.通過factotryMethod方法實例化一個對象
// 看起來是不是有點熟悉,在使用factotryMethod創建對象時也有差不多這樣的一段代碼,看起來就是使用緩存好的方法直接創建一個對象
boolean resolved = false;
boolean autowireNecessary = false;
// 不對這個參數進行討論,就認為一直為null
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
// bd中的resolvedConstructorOrFactoryMethod不為空,說明已經解析過構造方法了
if (mbd.resolvedConstructorOrFactoryMethod != null) {
// resolved標誌是否解析過構造方法
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
// 構造函數已經解析過了,並且這個構造函數在調用時需要自動注入參數
if (autowireNecessary) {
// 此時部分解析好的參數已經存在了beanDefinition中,並且構造函數也在bd中
// 那麼在這裏只會從緩存中去取構造函數以及參數然後反射調用
return autowireConstructor(beanName, mbd, null, null);
}
else {
// 這裏就是直接反射調用空參構造
return instantiateBean(beanName, mbd);
}
}
// 推斷出能夠使用的需要參數的構造函數
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
// 在推斷出來的構造函數中選取一個合適的方法來進行Bean的實例化
// ctors不為null:說明存在1個或多個@Autowired標註的方法
// mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR:說明是自動注入
// mbd.hasConstructorArgumentValues():配置文件中配置了構造函數要使用的參數
// !ObjectUtils.isEmpty(args):外部傳入的參數,必定為null,不多考慮
// 上面的條件只要滿足一個就會進入到autowireConstructor方法
// 第一個條件滿足,那麼通過autowireConstructor在推斷出來的構造函數中再進一步選擇一個差異值最小的,參數最長的構造函數
// 第二個條件滿足,說明沒有@Autowired標註的方法,但是需要進行自動注入,那麼通過autowireConstructor會去遍歷類中申明的所有構造函數,並查找一個差異值最小的,參數最長的構造函數
// 第三個條件滿足,說明不是自動注入,那麼要通過配置中的參數去類中申明的所有構造函數中匹配
// 第四個必定為null,不考慮
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// 反射調用空參構造
return instantiateBean(beanName, mbd);
}
因為autowireConstructor方法的執行邏輯跟instantiateUsingFactoryMethod方法的執行邏輯基本一致,只是將Method對象換成了Constructor對象,所以對這個方法我不再做詳細的分析。
我們主要就看看determineConstructorsFromBeanPostProcessors這個方法吧,這個方法的主要目的就是推斷出候選的構造方法。
// 實際調用的就是AutowiredAnnotationBeanPostProcessor中的determineCandidateConstructors方法
// 這個方法看起來很長,但實際確很簡單,就是通過@Autowired註解確定哪些構造方法可以作為候選方法,其實在使用factoryMethod來實例化對象的時候也有這種邏輯在其中,後續在總結的時候我們對比一下
public Constructor<?>[] determineCandidateConstructors(Class<?> beanClass, final String beanName)
throws BeanCreationException {
// 這裏做的事情很簡單,就是將@Lookup註解標註的方法封裝成LookupOverride添加到BeanDefinition中的methodOverrides屬性中,如果這個屬性不為空,在實例化對象的時候不能選用SimpleInstantiationStrateg,而要使用CglibSubclassingInstantiationStrategy,通過cglib代理給方法加一層攔截了邏輯
// 避免重複檢查
if (!this.lookupMethodsChecked.contains(beanName)) {
try {
ReflectionUtils.doWithMethods(beanClass, method -> {
Lookup lookup = method.getAnnotation(Lookup.class);
if (lookup != null) {
Assert.state(this.beanFactory != null, "No BeanFactory available"); // 將@Lookup註解標註的方法封裝成LookupOverride
LookupOverride override = new LookupOverride(method, lookup.value());
try {
// 添加到BeanDefinition中的methodOverrides屬性中
RootBeanDefinition mbd = (RootBeanDefinition)
this.beanFactory.getMergedBeanDefinition(beanName);
mbd.getMethodOverrides().addOverride(override);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(beanName,
"Cannot apply @Lookup to beans without corresponding bean definition");
}
}
});
}
catch (IllegalStateException ex) {
throw new BeanCreationException(beanName, "Lookup method resolution failed", ex);
}
this.lookupMethodsChecked.add(beanName);
}
// 接下來要開始確定到底哪些構造函數能被作為候選者
// 先嘗試從緩存中獲取
Constructor<?>[] candidateConstructors = this.candidateConstructorsCache.get(beanClass);
if (candidateConstructors == null) {
// Fully synchronized resolution now...
synchronized (this.candidateConstructorsCache) {
candidateConstructors = this.candidateConstructorsCache.get(beanClass);、
// 緩存中無法獲取到,進入正式的推斷過程
if (candidateConstructors == null) {
Constructor<?>[] rawCandidates;
try {
// 第一步:先查詢這個類所有的構造函數,包括私有的
rawCandidates = beanClass.getDeclaredConstructors();
}
catch (Throwable ex) {
// 省略異常信息
}
List<Constructor<?>> candidates = new ArrayList<>(rawCandidates.length);
// 保存添加了Autowired註解並且required屬性為true的構造方法
Constructor<?> requiredConstructor = null;
// 空參構造
Constructor<?> defaultConstructor = null;
// 看方法註釋上說明的,這裏除非是kotlin的類,否則必定為null,不做過多考慮,我們就將其當作null
Constructor<?> primaryConstructor = BeanUtils.findPrimaryConstructor(beanClass);
int nonSyntheticConstructors = 0;
// 對類中的所有構造方法進行遍歷
for (Constructor<?> candidate : rawCandidates) {
// 非合成方法
if (!candidate.isSynthetic()) {
nonSyntheticConstructors++;
}
else if (primaryConstructor != null) {
continue;
}
// 查詢方法上是否有Autowired註解
AnnotationAttributes ann = findAutowiredAnnotation(candidate);
if (ann == null) {
// userClass != beanClass說明這個類進行了cglib代理
Class<?> userClass = ClassUtils.getUserClass(beanClass);
if (userClass != beanClass) {
try {
// 如果進行了cglib代理,那麼在父類上再次查找Autowired註解
Constructor<?> superCtor =
userClass.getDeclaredConstructor(candidate.getParameterTypes());
ann = findAutowiredAnnotation(superCtor);
}
catch (NoSuchMethodException ex) {
// Simply proceed, no equivalent superclass constructor found...
}
}
}
// 說明當前的這個構造函數上有Autowired註解
if (ann != null) {
if (requiredConstructor != null) {
// 省略異常拋出
}
// 獲取Autowired註解中的required屬性
boolean required = determineRequiredStatus(ann);
if (required) {
// 類中存在多個@Autowired標註的方法,並且某個方法的@Autowired註解上被申明了required屬性要為true,那麼直接報錯
if (!candidates.isEmpty()) {
// 省略異常拋出
}
requiredConstructor = candidate;
}
// 添加到集合中,這個集合存儲的都是被@Autowired註解標註的方法
candidates.add(candidate);
}
// 空參構造函數
else if (candidate.getParameterCount() == 0) {
defaultConstructor = candidate;
}
}
if (!candidates.isEmpty()) {
// 存在多個被@Autowired標註的方法
// 並且所有的required屬性被設置成了false (默認為true)
if (requiredConstructor == null) {
// 存在空參構造函數,注意,空參構造函數可以不被@Autowired註解標註
if (defaultConstructor != null) {
// 將空參構造函數也加入到候選的方法中去
candidates.add(defaultConstructor);
}
// 省略日誌打印
}
candidateConstructors = candidates.toArray(new Constructor<?>[0]);
}
// 也就是說,類中只提供了一個構造函數,並且這個構造函數不是空參構造函數
else if (rawCandidates.length == 1 && rawCandidates[0].getParameterCount() > 0) {
candidateConstructors = new Constructor<?>[] {rawCandidates[0]};
}
// 省略中間兩個判斷,primaryConstructor必定為null,不考慮
// .....
}
else {
// 說明無法推斷出來
candidateConstructors = new Constructor<?>[0];
}
this.candidateConstructorsCache.put(beanClass, candidateConstructors);
}
}
}
return (candidateConstructors.length > 0 ? candidateConstructors : null);
}
這裏我簡單總結下這個方法的作用
獲取到類中的所有構造函數
查找到被
@Autowired註解標註的構造函數
- 如果存在多個被
@Autowired標註的構造函數,並且其required屬性沒有被設置為true,那麼返回這些被標註的函數的集合(空參構造即使沒有添加@Autowired也會被添加到集合中)- 如果存在多個被
@Autowired標註的構造函數,並且其中一個的required屬性被設置成了true,那麼直接報錯- 如果只有一個構造函數被
@Autowired標註,並且其required屬性被設置成了true,那麼直接返回這個構造函數如果沒有被
@Autowired標註標註的構造函數,但是類中有且只有一個構造函數,並且這個構造函數不是空參構造函數,那麼返回這個構造函數上面的條件都不滿足,那麼
determineCandidateConstructors這個方法就無法推斷出合適的構造函數了
可以看到,通過AutowiredAnnotationBeanPostProcessor的determineCandidateConstructors方法可以處理構造函數上的@Autowired註解。
但是,請注意,這個方法並不能決定到底使用哪個構造函數來創建對象(即使它只推斷出來一個,也不一定能夠使用),它只是通過@Autowired註解來確定構造函數的候選者,在構造函數都沒有添加@Autowired註解的情況下,這個方法推斷不出來任何方法。真正確定到底使用哪個構造函數是交由autowireConstructor方法來決定的。前文已經分析過了instantiateUsingFactoryMethod方法,autowireConstructor的邏輯基本跟它一致,所以這裏不再做詳細的分析。
從上圖中可以看到,整體邏輯上它們並沒有什麼區別,只是查找的對象從factoryMethod換成了構造函數
細節的差異主要體現在推斷方法上
它們之間的差異我已經在圖中標識出來了,主要就是兩點
- 通過構造函數實例化對象,多了一層處理,就是要處理構造函數上的@Autowired註解以及方法上的@LookUp註解(要決定選取哪一種實例化策略,
SimpleInstantiationStrategy/CglibSubclassingInstantiationStrategy)- 在最終的選取也存在差異,對於facotyMehod而言,在寬鬆模式下(
除ConfigurationClassBeanDefinition外,也就是掃描@Bean得到的BeanDefinition,都是寬鬆模式),會選取一個最精準的方法,在嚴格模式下,會選取一個參數最長的方法- 對於構造函數而言,會必定會選取一個參數最長的方法
思考了很久,我還是決定再補充一些內容,就是關於上面兩幅圖的最後一步,對應的核心代碼如下:
int typeDiffWeight = (mbd.isLenientConstructorResolution() ?
argsHolder.getTypeDifferenceWeight(paramTypes) : argsHolder.getAssignabilityWeight(paramTypes));
if (typeDiffWeight < minTypeDiffWeight) {
factoryMethodToUse = candidate;
argsHolderToUse = argsHolder;
argsToUse = argsHolder.arguments;
minTypeDiffWeight = typeDiffWeight;
ambiguousFactoryMethods = null;
}
判斷bd是嚴格模式還是寬鬆模式,上面說過很多次了,bd默認就是寬鬆模式,只要在ConfigurationClassBeanDefinition中使用嚴格模式,也就是掃描@Bean標註的方法註冊的bd(對應的代碼可以參考:org.springframework.context.annotation.ConfigurationClassBeanDefinitionReader#loadBeanDefinitionsForBeanMethod方法)
我們再看看嚴格模式跟寬鬆模式在計算差異值時的區別
public int getTypeDifferenceWeight(Class<?>[] paramTypes) {
// 計算實際使用的參數跟方法申明的參數的差異值
int typeDiffWeight = MethodInvoker.getTypeDifferenceWeight(paramTypes, this.arguments);
// 計算沒有經過類型轉換的參數跟方法申明的參數的差異值
int rawTypeDiffWeight = MethodInvoker.getTypeDifferenceWeight(paramTypes, this.rawArguments) - 1024;
return (rawTypeDiffWeight < typeDiffWeight ? rawTypeDiffWeight : typeDiffWeight);
}
public static int getTypeDifferenceWeight(Class<?>[] paramTypes, Object[] args) {
int result = 0;
for (int i = 0; i < paramTypes.length; i++) {
// 在出現類型轉換時,下面這個判斷才會成立,也就是在比較rawArguments跟paramTypes的差異時才可能滿足這個條件
if (!ClassUtils.isAssignableValue(paramTypes[i], args[i])) {
return Integer.MAX_VALUE;
}
if (args[i] != null) {
Class<?> paramType = paramTypes[i];
Class<?> superClass = args[i].getClass().getSuperclass();
while (superClass != null) {
// 如果我們傳入的值是方法上申明的參數的子類,那麼每多一層繼承關係,差異值加2
if (paramType.equals(superClass)) {
result = result + 2;
superClass = null;
}
else if (ClassUtils.isAssignable(paramType, superClass)) {
result = result + 2;
superClass = superClass.getSuperclass();
}
else {
superClass = null;
}
}
// 判斷方法的參數是不是一個接口,如果是,那麼差異值加1
if (paramType.isInterface()) {
result = result + 1;
}
}
}
return result;
}
public int getAssignabilityWeight(Class<?>[] paramTypes) {
// 嚴格模式下,只有三種返回值
// 1.Integer.MAX_VALUE,經過類型轉換后還是不符合要求,返回最大的類型差異
// 因為解析后的參數可能返回一個NullBean(創建對象的方法返回了null,Spring會將其包裝成一個NullBean),不過一般不會出現這種情況,所以我們可以當這種情況不存在
for (int i = 0; i < paramTypes.length; i++) {
if (!ClassUtils.isAssignableValue(paramTypes[i], this.arguments[i])) {
return Integer.MAX_VALUE;
}
}
// 2.Integer.MAX_VALUE - 512,進行過了類型轉換才符合要求
for (int i = 0; i < paramTypes.length; i++) {
if (!ClassUtils.isAssignableValue(paramTypes[i], this.rawArguments[i])) {
return Integer.MAX_VALUE - 512;
}
}
// 3.Integer.MAX_VALUE - 1024,沒有經過類型轉換就已經符合要求了,返回最小的類型差異
return Integer.MAX_VALUE - 1024;
}
首先,不管是factoryMethod還是constructor,都是採用上面的兩個方法來計算類型差異,但是正常來說,只有factoryMethod會採用到嚴格模式(除非程序員手動干預,比如通過Bean工廠後置處理器修改了bd中的屬性,這樣通常來說沒有很大意義)
所以我們分為三種情況討論
這種情況下,會選取一個最精確的方法,同時方法的參數要盡量長
測試代碼:
public class FactoryObject {
public DmzService getDmz() {
System.out.println(0);
return new DmzService();
}
public DmzService getDmz(OrderService indexService) {
System.out.println(1);
return new DmzService();
}
public DmzService getDmz(OrderService orderService, IndexService indexService) {
System.out.println(2);
return new DmzService();
}
public DmzService getDmz(OrderService orderService, IndexService indexService,IA ia) {
System.out.println(3);
return new DmzService();
}
}
public class ServiceImpl implements IService {
}
public class IAImpl implements IA {
}
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"
default-autowire="constructor"><!--必須要開啟自動注入,並且是通過構造函數進行自動注入,否則選用無參構造-->
<!--factoryObject 提供了創建對象的方法-->
<bean id="factoryObject" class="com.dmz.spring.instantiation.service.FactoryObject"/>
<bean class="com.dmz.spring.instantiation.service.OrderService" id="orderService"/>
<bean id="dmzService" factory-bean="factoryObject" factory-method="getDmz" />
<bean class="com.dmz.spring.instantiation.service.ServiceImpl" id="iService"/>
<bean class="com.dmz.spring.instantiation.service.IndexService" id="indexService"/>
</beans>
/**
* @author 程序員DMZ
* @Date Create in 23:59 2020/6/1
* @Blog https://daimingzhi.blog.csdn.net/
*/
public class XMLMain {
public static void main(String[] args) {
ClassPathXmlApplicationContext cc =
new ClassPathXmlApplicationContext("application.xml");
}
}
運行程序發現,選用了第三個(getDmz(OrderService orderService, IndexService indexService))構造方法。雖然最後一個方法的參數更長,但是因為其方法申明的參數上存在接口,所以它的差異值會大於第三個方法,因為不會被選用
這種情況下,會選取一個參數盡量長的方法
測試代碼:
/**
* @author 程序員DMZ
* @Date Create in 6:28 2020/6/1
* @Blog https://daimingzhi.blog.csdn.net/
*/
@ComponentScan("com.dmz.spring.instantiation")
@Configuration
public class Config {
@Bean
public DmzService dmzService() {
System.out.println(0);
return new DmzService();
}
@Bean
public DmzService dmzService(OrderService indexService) {
System.out.println(1);
return new DmzService();
}
@Bean
public DmzService dmzService(OrderService orderService, IndexService indexService) {
System.out.println(2);
return new DmzService();
}
@Bean
public DmzService dmzService(OrderService orderService, IndexService indexService, IA ia) {
System.out.println("config " +3);
return new DmzService();
}
@Bean
public DmzService dmzService(OrderService orderService, IndexService indexService, IA ia, IService iService) {
System.out.println("config " +4);
return new DmzService();
}
}
/**
* @author 程序員DMZ
* @Date Create in 6:29 2020/6/1
* @Blog https://daimingzhi.blog.csdn.net/
*/
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(Config.class);
ac.refresh();
}
}
運行程序,發現選用了最後一個構造函數,這是因為在遍歷候選方法時,會先遍歷參數最長的,而在計算類型差異時,因為嚴格模式下,上面所有方法的差異值都是一樣的,都會返回Integer.MAX_VALUE - 1024。實際上,在不進行手動干預的情況下,都會返滬這個值。
這種情況下,也會選取一個參數盡量長的方法
之所以會這樣,主要是因為在autowireConstructor方法中進行了一次短路判斷,如下所示:
在上圖中,如果已經找到了合適的方法,那麼直接就不會再找了,而在遍歷的時候是從參數最長的方法開始遍歷的,測試代碼如下:
@Component
public class DmzService {
// 沒有添加@Autowired註解,也會被當作候選方法
public DmzService(){
System.out.println(0);
}
@Autowired(required = false)
public DmzService(OrderService orderService) {
System.out.println(1);
}
@Autowired(required = false)
public DmzService(OrderService orderService, IService iService) {
System.out.println(2);
}
@Autowired(required = false)
public DmzService(OrderService orderService, IndexService indexService, IService iService,IA ia) {
System.out.println("DmzService "+3);
}
}
/**
* @author 程序員DMZ
* @Date Create in 6:29 2020/6/1
* @Blog https://daimingzhi.blog.csdn.net/
*/
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(Config.class);
ac.refresh();
}
}
這篇文章就到這裏啦~~!
文章很長,希望你耐心看完,碼字不易,如果有幫助到你的話點個贊吧~!
掃描下方二維碼,關注我的公眾號,更多精彩文章在等您!~~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
老孟導讀:大家好,這是【Flutter實戰】系列文章的第二篇,這一篇講解文本組件,文本組件包括文本展示組件(Text和RichText)和文本輸入組件(TextField),基礎用法和五個案例助你快速掌握。
第一篇鏈接:【Flutter實戰】移動技術發展史
Text是显示文本的組件,最常用的組件,沒有之一。基本用法如下:
Text('老孟')
注意:Text組件一定要包裹在Scaffold組件下,否則效果如下:
文本的樣式在style中設置,類型為TextStyle,TextStyle中包含很多文本樣式屬性,下面介紹一些常用的。
設置文本大小和顏色:
Text('老孟',style: TextStyle(color: Colors.red,fontSize: 20),),
上面黑色的字體為沒有設置的效果,作為對比。
設置字體粗細:
Text('老孟',style: TextStyle(fontWeight: FontWeight.bold))
字體粗細共有9個級別,為w100至w900,FontWeight.bold是w700。
設置斜體:
Text('老孟',style: TextStyle(fontStyle: FontStyle.italic,))
設置自定義的字體:
pubspec.yaml:fonts:
- family: maobi
fonts:
- asset: assets/fonts/maobi.ttf
maobi:是自己對當前字體的命名,有意義即可。
asset:字體文件的目錄。
使用:
Text('老孟', style: TextStyle(fontFamily: 'maobi',)),
設置對齊方式:
Container(
height: 100,
width: 200,
color: Colors.blue.withOpacity(.4),
child: Text('老孟', textAlign: TextAlign.center),
),
textAlign只是控制水平方向的對齊方式,值說明如下:
TextDirection屬性有關,如果設置TextDirection.ltr,則左對齊,設置TextDirection.rtl則右對齊。TextDirection屬性有關,如果設置TextDirection.ltr,則右對齊,設置TextDirection.rtl則左對齊。設置文本自動換行:
Container(
height: 100,
width: 200,
color: Colors.blue.withOpacity(.4),
child: Text('老孟,專註分享Flutter技術和應用實戰',softWrap: true,),
)
文本超出範圍時的處理:
Container(
height: 100,
width: 200,
color: Colors.blue.withOpacity(.4),
child: Text('老孟,專註分享Flutter技術和應用實戰',overflow: TextOverflow.ellipsis,),
)
溢出的處理方式:
設置全局字體樣式:
在MaterialApp的theme中設置如下
MaterialApp(
title: 'Flutter Demo',
theme: ThemeData(
...
textTheme: TextTheme(
bodyText2: TextStyle(color: Colors.red,fontSize: 24),
)
),
home: Scaffold(
body: TextDemo(),
),
)
Text組件默認為紅色,
Text('老孟'),
Text('老孟',style: TextStyle(color: Colors.blue,fontSize: 20),),
RichText的屬性和Text基本一樣,使用如下:
RichText(
text: TextSpan(
style: DefaultTextStyle.of(context).style,
children: <InlineSpan>[
TextSpan(text: '老孟', style: TextStyle(color: Colors.red)),
TextSpan(text: ','),
TextSpan(text: '專註分享Flutter技術和應用實戰'),
]),
)
TextField是文本輸入組件,即輸入框,常用組件之一。基本用法:
TextField()
不需要任何參數,一個最簡單的文本輸入組件就出來了,效果如下:
decoration是TextField組件的裝飾(外觀)參數,類型是InputDecoration。
icon显示在輸入框的前面,用法如下:
TextField(
decoration: InputDecoration(
icon: Icon(Icons.person),
),
)
當輸入框是空而且沒有焦點時,labelText显示在輸入框上邊,當獲取焦點或者不為空時labelText往上移動一點,labelStyle參數表示文本樣式,具體參考TextStyle, 用法如下:
TextField(
decoration: InputDecoration(
labelText: '姓名:',
labelStyle: TextStyle(color:Colors.red)
),
)
hasFloatingPlaceholder參數控制當輸入框獲取焦點或者不為空時是否還显示labelText,默認為true,显示。
helperText显示在輸入框的左下部,用於提示用戶,helperStyle參數表示文本樣式,具體參考TextStyle用法如下:
TextField(
decoration: InputDecoration(
helperText: '用戶名長度為6-10個字母',
helperStyle: TextStyle(color: Colors.blue),
helperMaxLines: 1
),
)
hintText是當輸入框為空時的提示,不為空時不在显示,用法如下:
TextField(
decoration: InputDecoration(
hintText: '請輸入用戶名',
hintStyle: TextStyle(color: Colors.grey),
hintMaxLines: 1
),
)
errorText显示在輸入框的左下部,默認字體為紅色,用法如下:
TextField(
decoration: InputDecoration(
errorText: '用戶名輸入錯誤',
errorStyle: TextStyle(fontSize: 12),
errorMaxLines: 1,
errorBorder: OutlineInputBorder(borderSide: BorderSide(color: Colors.red)),
),
)
prefix系列的組件是輸入框前面的部分,用法如下:
TextField(
decoration: InputDecoration(
prefixIcon: Icon(Icons.person)
),
)
注意prefix和icon的區別,icon是在輸入框邊框的外部,而prefix在裏面。
suffix和prefix相反,suffix在輸入框的尾部,用法如下:
TextField(
decoration: InputDecoration(
suffixIcon: Icon(Icons.person)
),
)
counter組件統計輸入框文字的個數,counter僅僅是展示效果,不具備自動統計字數的功能, 自動統計字數代碼如下:
var _textFieldValue = '';
TextField(
onChanged: (value){
setState(() {
_textFieldValue = value;
});
},
decoration: InputDecoration(
counterText: '${_textFieldValue.length}/32'
),
)
filled為true時,輸入框將會被fillColor填充,仿QQ登錄輸入框代碼如下:
Container(
height: 60,
width: 250,
child: TextField(
decoration: InputDecoration(
fillColor: Color(0x30cccccc),
filled: true,
enabledBorder: OutlineInputBorder(
borderSide: BorderSide(color: Color(0x00FF0000)),
borderRadius: BorderRadius.all(Radius.circular(100))),
hintText: 'QQ號/手機號/郵箱',
focusedBorder: OutlineInputBorder(
borderSide: BorderSide(color: Color(0x00000000)),
borderRadius: BorderRadius.all(Radius.circular(100))),
),
),
)
controller是輸入框文本編輯的控制器,可以獲取TextField的內容、設置TextField的內容,下面將輸入的英文變為大寫:
TextEditingController _controller;
@override
void initState() {
super.initState();
_controller = TextEditingController()
..addListener(() {
//獲取輸入框的內容,變為大寫
_controller.text = _controller.text.toUpperCase();
});
}
@override
Widget build(BuildContext context) {
return TextField(
controller: _controller,
);
}
@override
dispose() {
super.dispose();
_controller.dispose();
}
有時輸入框後面帶有“清除”功能,需要controller來實現。如果需要2個TextField的內容進行同步,只需要給2個TextField設置同一個controller即可實現。
keyboardType參數控制軟鍵盤的類型,說明如下:
textInputAction參數控制軟鍵盤右下角的按鍵,說明如下:
大家可能發現了,Android上显示的按鈕大部分是不確定的,比如next有的显示向右的箭頭,有的显示前進,這是因為各大廠商對Android ROM定製引發的。
textCapitalization參數是配置鍵盤是大寫還是小寫,僅支持鍵盤模式為text,其他模式下忽略此配置,說明如下:
這裏僅僅是控制軟鍵盤是大寫模式還是小寫模式,你也可以切換大小寫,系統並不會改變輸入框內的內容。
textAlignVertical表示垂直方向的對齊方式,textDirection表示文本方向,用法如下:
TextField(
textAlignVertical: TextAlignVertical.center,
textDirection: TextDirection.rtl,
)
toolbarOptions表示長按時彈出的菜單,有copy、cut、paste、selectAll,用法如下:
TextField(
toolbarOptions: ToolbarOptions(
copy: true,
cut: true,
paste: true,
selectAll: true
),
)
cursor表示光標,用法如下:
TextField(
showCursor: true,
cursorWidth: 3,
cursorRadius: Radius.circular(10),
cursorColor: Colors.red,
)
效果如下:
將輸入框設置為密碼框,只需obscureText屬性設置true即可,用法如下:
TextField(
obscureText: true,
)
通過inputFormatters可以限制用戶輸入的內容,比如只想讓用戶輸入字符,設置如下:
TextField(
inputFormatters: [
WhitelistingTextInputFormatter(RegExp("[a-zA-Z]")),
],
)
這時用戶是無法輸入数字的。
onChanged是當內容發生變化時回調,onSubmitted是點擊回車或者點擊軟鍵盤上的完成回調,onTap點擊輸入框時回調,用法如下:
TextField(
onChanged: (value){
print('onChanged:$value');
},
onEditingComplete: (){
print('onEditingComplete');
},
onTap: (){
print('onTap');
},
)
輸入框右下角經常需要字數統計,除了使用上面介紹的方法外,還可以使用buildCounter,建議使用此方法,用法如下:
TextField(
maxLength: 100,
buildCounter: (
BuildContext context, {
int currentLength,
int maxLength,
bool isFocused,
}) {
return Text(
'$currentLength/$maxLength',
);
},
)
動態獲取焦點
FocusScope.of(context).requestFocus(_focusNode);
_focusNode為TextField的focusNode:
_focusNode = FocusNode();
TextField(
focusNode: _focusNode,
...
)
動態失去焦點
_focusNode.unfocus();
Builder(
builder: (BuildContext context) {
RenderBox box = context.findRenderObject();
final Shader linearGradient = LinearGradient(
colors: <Color>[Colors.purple, Colors.blue],
).createShader(
Rect.fromLTWH(0.0, 0.0, box?.size?.width, box?.size?.height));
return Text(
'老孟,專註分享Flutter技術和應用實戰',
style: new TextStyle(
fontSize: 18.0,
fontWeight: FontWeight.bold,
foreground: Paint()..shader = linearGradient),
);
},
)
Builder組件是為了計算當前Text組件大小,生成LinearGradient。
RichText(
text: TextSpan(
style: DefaultTextStyle.of(context).style,
children: <InlineSpan>[
WidgetSpan(
child: Container(
margin: EdgeInsets.only(right: 10),
padding: EdgeInsets.symmetric(horizontal: 10),
decoration: BoxDecoration(
shape: BoxShape.rectangle,
borderRadius: BorderRadius.all(Radius.circular(20)),
color: Colors.blue),
child: Text(
'判斷題',
style: TextStyle(color: Colors.white),
),
)),
TextSpan(text: '泡沫滅火器可用於帶電滅火'),
]),
)
通常在登錄頁面的底部會出現登錄即代表同意並閱讀 《服務協議》,其中《服務協議》為藍色且可點擊:
Text.rich(
TextSpan(
text: '登錄即代表同意並閱讀',
style: TextStyle(fontSize: 11, color: Color(0xFF999999)),
children: [
TextSpan(
text: '《服務協議》',
style: TextStyle(color: Colors.blue, fontWeight: FontWeight.bold),
recognizer: TapGestureRecognizer()
..onTap = () {
print('onTap');
},
),
]),
)
TextField(
decoration: InputDecoration(
fillColor: Color(0x30cccccc),
filled: true,
enabledBorder: OutlineInputBorder(
borderSide: BorderSide(color: Color(0x00FF0000)),
borderRadius: BorderRadius.all(Radius.circular(100))),
hintText: '輸入密碼',
focusedBorder: OutlineInputBorder(
borderSide: BorderSide(color: Color(0x00000000)),
borderRadius: BorderRadius.all(Radius.circular(100))),
),
textAlign: TextAlign.center,
obscureText: true,
onChanged: (value) {
},
)
Text.rich(
TextSpan(
text: '回復',
style: TextStyle(fontSize: 11, color: Color(0xFF999999)),
children: [
TextSpan(
text: '@老孟:',
style: TextStyle(color: Colors.blue, fontWeight: FontWeight.bold),
recognizer: TapGestureRecognizer()
..onTap = () {
print('onTap');
},
),
TextSpan(
text: '你好,想知道Flutter發展前景如何?',
),
]),
)
老孟Flutter博客地址(330個控件用法):http://laomengit.com
歡迎加入Flutter交流群(微信:laomengit)、關注公眾號【老孟Flutter】:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準