環境資訊中心記者 陳文姿報導
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
摘錄自2019年7月24、26日自由時報、中央社報導
今年夏天的第二波熱浪,25日讓歐洲多國氣溫再創新高,不少城市都測到超過攝氏40度的高溫。荷蘭25日在東部城鎮代倫(Deelen)測得破紀錄的攝氏41.7度高溫。比利時25日在東北部的小布羅赫爾空軍基地測到40.6度,為該國自1833年以來的最高溫。德國25日在西部林根(Lingen)測到41.5度。
法國巴黎25日創下史上最高溫,該市蒙蘇里(Montsouris)區下午測到42.4度的高溫。
熱浪也迫使南法一座核電廠於23日起停機至月底。
依賴海水冷卻反應爐的核電廠受熱浪影響,法國電力公司(EDF)表示,全法國的核電廠25日發電量減少約5.2十億瓦(GW)或8%,南部塔恩-加倫省(Tarn-et-Garonne)的戈費契(Golfech)核電廠,因加倫河(Garonne River)水溫過高,2個反應爐分別於23日起停機,直到本月30日。另有6座核反應爐發電量縮減。
德國電力公用事業公司意昂(E.ON)旗下核電公司PreussenElektra 26日表示,由於威塞河(Weser River)水溫過高,發電量1430 MW的格隆德(Grohnde)核電廠預計26日中午起至28日暫停運轉。若氣候改變可能調整計畫。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
由雲嘉南風景區管理處主辦的2020台灣國際觀鳥馬拉松大賽,有32支隊伍報名參加,其中國內隊伍有29隊,國際隊有3隊。雲網頁設計管處徐振能處長表示,競賽將於12月5日舉辦,今年有親子隊7隊,每隊可獲得精美獎品1份。而3支國際隊伍鳥如何寫文案友,分別來自南非、美國、加拿大、愛爾蘭等國。
徐振能處長表示,這項國際觀鳥馬拉松iphone維修大賽於2012年開始舉辦,是全台網頁設計唯一比賽範圍跨越雲林、嘉義、台南等3縣市,貨運賞鳥環境從濱海到山巔,鳥類涵蓋水鳥與山鳥。今年活動報名至10月31日截止,原訂國內隊報名隊伍數25隊,報名隊數卻有29隊,為滿足鳥友需求增加4隊。
徐振能處長表示,台北網頁設計為鼓勵親子組租車隊參加,凡包裝行銷參賽可獲得精美獎品1份,今年親子隊台北網頁設計有7隊,另外,報名者呈FB行銷現年輕化,有35%屬年輕網頁設計公司鳥友。歷年賽事至少有6國以上銷售文案賞鳥人士來台參加,受肺炎疫情影響,今年有3支國際隊伍,分別來自南非、美國、加拿大、愛爾蘭等國。
在前面的文章中,我們學習了如何使用@Import註解向Spring容器中導入bean,可以使用@Import註解快速向容器中導入bean,小夥伴們可以參見《【Spring註解驅動開發】使用@Import註解給容器中快速導入一個組件》。可以在@Import註解中使用ImportSelector接口導入bean,小夥伴們可以參見《【Spring註解驅動開發】在@Import註解中使用ImportSelector接口導入bean》一文。今天,我們就來說說,如何在@Import註解中使用ImportBeanDefinitionRegistrar向容器中註冊bean。
項目工程源碼已經提交到GitHub:https://github.com/sunshinelyz/spring-annotation
我們先來看看ImportBeanDefinitionRegistrar是個什麼鬼,點擊進入ImportBeanDefinitionRegistrar源碼,如下所示。
package org.springframework.context.annotation;
import org.springframework.beans.factory.support.BeanDefinitionRegistry;
import org.springframework.beans.factory.support.BeanDefinitionRegistryPostProcessor;
import org.springframework.beans.factory.support.BeanNameGenerator;
import org.springframework.core.type.AnnotationMetadata;
public interface ImportBeanDefinitionRegistrar {
default void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry,
BeanNameGenerator importBeanNameGenerator) {
registerBeanDefinitions(importingClassMetadata, registry);
}
default void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
}
}
由源碼可以看出,ImportBeanDefinitionRegistrar本質上是一個接口。在ImportBeanDefinitionRegistrar接口中,有一個registerBeanDefinitions()方法,通過registerBeanDefinitions()方法,我們可以向Spring容器中註冊bean實例。
Spring官方在動態註冊bean時,大部分套路其實是使用ImportBeanDefinitionRegistrar接口。
所有實現了該接口的類都會被ConfigurationClassPostProcessor處理,ConfigurationClassPostProcessor實現了BeanFactoryPostProcessor接口,所以ImportBeanDefinitionRegistrar中動態註冊的bean是優先於依賴其的bean初始化的,也能被aop、validator等機制處理。
ImportBeanDefinitionRegistrar需要配合@Configuration和@Import註解,@Configuration定義Java格式的Spring配置文件,@Import註解導入實現了ImportBeanDefinitionRegistrar接口的類。
既然ImportBeanDefinitionRegistrar是一個接口,那我們就創建一個MyImportBeanDefinitionRegistrar類,實現ImportBeanDefinitionRegistrar接口,如下所示。
package io.mykit.spring.plugins.register.condition;
import org.springframework.beans.factory.support.BeanDefinitionRegistry;
import org.springframework.context.annotation.ImportBeanDefinitionRegistrar;
import org.springframework.core.type.AnnotationMetadata;
/**
* @author binghe
* @version 1.0.0
* @description ImportBeanDefinitionRegistrar的實現類
*/
public class MyImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
/**
* AnnotationMetadata: 當前類的註解信息
* BeanDefinitionRegistry:BeanDefinition註冊類
* 通過調用BeanDefinitionRegistry接口的registerBeanDefinition()方法,可以將所有需要添加到容器中的bean注入到容器中。
*/
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry){
}
}
可以看到,這裏,我們先創建了MyImportBeanDefinitionRegistrar類的大體框架。接下來,我們在PersonConfig2類上的@Import註解中,添加MyImportBeanDefinitionRegistrar類,如下所示。
@Configuration
@Import({Department.class, Employee.class, MyImportSelector.class, MyImportBeanDefinitionRegistrar.class})
public class PersonConfig2 {
接下來,創建一個Company類,作為測試測試ImportBeanDefinitionRegistrar接口的bean,如下所示。
package io.mykit.spring.plugins.register.bean;
/**
* @author binghe
* @version 1.0.0
* @description 測試ImportBeanDefinitionRegistrar接口的使用
*/
public class Company {
}
接下來,就要實現MyImportBeanDefinitionRegistrar類中的registerBeanDefinitions()方法的邏輯了,添加邏輯后的registerBeanDefinitions()方法如下所示。
/**
* AnnotationMetadata: 當前類的註解信息
* BeanDefinitionRegistry:BeanDefinition註冊類
* 通過調用BeanDefinitionRegistry接口的registerBeanDefinition()方法,可以將所有需要添加到容器中的bean注入到容器中。
*/
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry){
boolean employee = registry.containsBeanDefinition("employee");
boolean department = registry.containsBeanDefinition("department");
if (employee && department){
BeanDefinition beanDefinition = new RootBeanDefinition(Company.class);
registry.registerBeanDefinition("company", beanDefinition);
}
}
registerBeanDefinitions()方法的實現邏輯很簡單,就是判斷Spring容器中是否同時存在以employee命名的bean和以department命名的bean,如果同時存在以employee命名的bean和以department命名的bean,則向Spring容器中注入一個以company命名的bean。
接下來,我們就運行SpringBeanTest類中的testAnnotationConfig7()方法來進行測試,輸出結果信息如下所示。
org.springframework.context.annotation.internalConfigurationAnnotationProcessor
org.springframework.context.annotation.internalAutowiredAnnotationProcessor
org.springframework.context.annotation.internalCommonAnnotationProcessor
org.springframework.context.event.internalEventListenerProcessor
org.springframework.context.event.internalEventListenerFactory
personConfig2
io.mykit.spring.plugins.register.bean.Department
io.mykit.spring.plugins.register.bean.Employee
io.mykit.spring.plugins.register.bean.User
io.mykit.spring.plugins.register.bean.Role
person
binghe001
可以看到,在輸出結果中,並沒有看到“company”,這是因為輸出結果中存在io.mykit.spring.plugins.register.bean.Department和io.mykit.spring.plugins.register.bean.Employee,並不存在我們代碼邏輯中的department和employee。所以,我們將registerBeanDefinitions()方法的邏輯稍微修改下,修改后的代碼如下所示。
/**
* AnnotationMetadata: 當前類的註解信息
* BeanDefinitionRegistry:BeanDefinition註冊類
* 通過調用BeanDefinitionRegistry接口的registerBeanDefinition()方法,可以將所有需要添加到容器中的bean注入到容器中。
*/
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry){
boolean employee = registry.containsBeanDefinition(Employee.class.getName());
boolean department = registry.containsBeanDefinition(Department.class.getName());
if (employee && department){
BeanDefinition beanDefinition = new RootBeanDefinition(Company.class);
registry.registerBeanDefinition("company", beanDefinition);
}
}
接下來,我們再次運行SpringBeanTest類中的testAnnotationConfig7()方法來進行測試,輸出結果信息如下所示。
org.springframework.context.annotation.internalConfigurationAnnotationProcessor
org.springframework.context.annotation.internalAutowiredAnnotationProcessor
org.springframework.context.annotation.internalCommonAnnotationProcessor
org.springframework.context.event.internalEventListenerProcessor
org.springframework.context.event.internalEventListenerFactory
personConfig2
io.mykit.spring.plugins.register.bean.Department
io.mykit.spring.plugins.register.bean.Employee
io.mykit.spring.plugins.register.bean.User
io.mykit.spring.plugins.register.bean.Role
person
binghe001
company
可以看到,此時輸出了company,說明Spring容器中已經成功註冊了以company命名的bean。
好了,咱們今天就聊到這兒吧!別忘了給個在看和轉發,讓更多的人看到,一起學習一起進步!!
項目工程源碼已經提交到GitHub:https://github.com/sunshinelyz/spring-annotation
如果覺得文章對你有點幫助,請微信搜索並關注「 冰河技術 」微信公眾號,跟冰河學習Spring註解驅動開發。公眾號回復“spring註解”關鍵字,領取Spring註解驅動開發核心知識圖,讓Spring註解驅動開發不再迷茫。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
看到這個標題,你肯定以為我又要講這道面試題了
// 這行代碼創建了幾個對象?
String s3 = new String("1");
是的,沒錯,我確實要從這裏開始
這道題就算你沒做過也肯定看到,總所周知,它創建了兩個對象,一個位於堆上,一個位於常量池中。
這個答案粗看起來是沒有任何問題的,但是仔細思考確經不起推敲。
如果你覺得我說的不對的話,那麼可以思考下面這兩個問題
你說它創建了兩個對象,那麼這兩個對象分別是怎樣創建的呢?我們回顧下Java創建對象的方式,一共就這麼幾種
newInstance方法,以及Constructor類的newInstance方法)你說它創建了兩個對象,那你告訴我除了new出來那個對象外,另外一個對象怎麼創建出來的?
堆跟常量池到底什麼關係?不是說在JDK1.7之後(含1.7版本)常量池已經移到了堆中了嗎?如果說常量池本身就位於堆中的話,那麼這種一個對象在堆中,一個對象在常量池的說法還準確嗎?
如果你也產生過這些疑問的話,那麼請耐心看完這篇文章!要解釋上面的問題首先我們得對常量池有個準確的認知。
通常來說,我們提到的常量池分為三種
對於這三種常量池,我們需要搞懂下面幾個問題?
接下來,我們帶着這些問題往下看
顧名思義,class文件中的常量池當然是位於class文件中,而class文件又是位於磁盤上。
在學習class文件中的常量池前,我們首選需要對class文件的結構有一定了解
Class文件是一組以8個字節為基礎單位的二進制流,各個數據項目嚴格按照順序緊湊地排列在文
件之中,中間沒有添加任何分隔符,這使得整個Class文件中存儲的內容幾乎全部是程序運行的必要數
據,沒有空隙存在。
————《深入理解Java虛擬機》
整個class文件的組成可以用下圖來表示
對本文而言,我們只關注其中的常量池部分,常量池可以理解為class文件中資源倉庫,它是class文件結構中與其它項目關聯最多的數據類型,主要用於存放編譯器生成的各種字面量(Literal)和符號引用(Symbolic References)。
字面量就是我們所說的常量概念,如文本字符串、被聲明為final的常量值等。
符號引用是一組符號來描述所引用的目標,符號可以是任何形式的字面量,只要使用時能無歧義地定位到目標即可(它與直接引用區分一下,直接引用一般是指向方法區的本地指針,相對偏移量或是一個能間接定位到目標的句柄)。一般包括下面三類常量:
現在我們知道了class文件中常量池的作用:存放編譯器生成的各種字面量(Literal)和符號引用(Symbolic References)。很多時候知道了一個東西的概念並不能說你會了,對於程序員而言,如果你說你已經會了,那麼最好的證明是你能夠通過代碼將其描述出來,所以,接下來,我想以一種直觀的方式讓大家感受到常量池的存在。通過分析一段簡單代碼的字節碼,讓大家能更好感知常量池的作用。
talk is cheap ,show me code
我們以下面這段代碼為例,通過javap來查看class文件中的具體內容,代碼如下:
/**
* @author 程序員DMZ
* @Date Create in 22:59 2020/6/15
* @公眾號 微信搜索:程序員DMZ
*/
public class Main {
public static void main(String[] args) {
String name = "dmz";
}
}
進入Main.java文件所在目錄,執行命令:javac Main.java ,那麼此時會在當前目錄下生成對應的Main.class文件。再執行命令:javap -v -c Main.class,此時會得到如下的解析后的字節碼信息
public class com.dmz.jvm.Main
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
// 這裏就是常量池了
Constant pool:
#1 = Methodref #4.#20 // java/lang/Object."<init>":()V
#2 = String #21 // dmz
#3 = Class #22 // com/dmz/jvm/Main
#4 = Class #23 // java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Utf8 LineNumberTable
#9 = Utf8 LocalVariableTable
#10 = Utf8 this
#11 = Utf8 Lcom/dmz/jvm/Main;
#12 = Utf8 main
#13 = Utf8 ([Ljava/lang/String;)V
#14 = Utf8 args
#15 = Utf8 [Ljava/lang/String;
#16 = Utf8 name
#17 = Utf8 Ljava/lang/String;
#18 = Utf8 SourceFile
#19 = Utf8 Main.java
#20 = NameAndType #5:#6 // "<init>":()V
#21 = Utf8 dmz
#22 = Utf8 com/dmz/jvm/Main
#23 = Utf8 java/lang/Object
// 下面是方法表
{
public com.dmz.jvm.Main();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 7: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/dmz/jvm/Main;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
// 可以看到方法表中的指令引用了常量池中的常量,這也是為什麼說常量池是資源倉庫的原因
// 因為它會被class文件中的其它結構引用
0: ldc #2 // String dmz
2: astore_1
3: return
LineNumberTable:
line 9: 0
line 10: 3
LocalVariableTable:
Start Length Slot Name Signature
0 4 0 args [Ljava/lang/String;
3 1 1 name Ljava/lang/String;
}
SourceFile: "Main.java"
在上面的字節碼中,我們暫且關注常量池中的內容即可。主要看這兩行
#2 = String #14 // dmz
#14 = Utf8 dmz
如果要看懂這兩行代碼,我們需要對常量池中String類型常量的結構有一定了解,其結構如下:
| CONSTANT_String_info | tag | 標誌常量類型的標籤 |
|---|---|---|
| index | 指向字符串字面量的索引 |
對應到我們上面的字節碼中,tag=String,index=#14,所以我們可以知道,#2是一個字面量為#14的字符串類型常量。而#14對應的字面量信息(一個Utf8類型的常量)就是dmz。
常量池作為資源倉庫,最大的用處在於被class文件中的其它結構所引用,這個時候我們再將注意力放到main方法上來,對應的就是這三條指令
0: ldc #2 // String dmz
2: astore_1
3: return
ldc:這個指令的作用是將對應的常量的引用壓入操作數棧,在執行ldc指令時會觸發對它的符號引用進行解析,在上面例子中對應的符號引用就是#2,也就是常量池中的第二個元素(這裏就能看出方法表中就引用了常量池中的資源)
astore_1:將操作數棧底元素彈出,存儲到局部變量表中的1號元素
return:方法返回值為void,標誌方法執行完成,將方法對應棧幀從棧中彈出
下面我用畫圖的方式來畫出整個流程,主要分為四步
解析ldc指令的符號引用(#2)
將#2對應的常量的引用壓入到操作數棧頂
將操作數棧的元素彈出並存儲到局部變量表中
執行return指令,方法執行結束,彈出棧區該方法對應的棧幀
第一步:
在解析#2這個符號引用時,會先到字符串常量池中查找是否存在對應字符串實例的引用,如果有的話,那麼直接返回這個字符串實例的引用,如果沒有的話,會創建一個字符串實例,那麼將其添加到字符串常量池中(實際上是將其引用放入到一個哈希表中),之後再返回這個字符串實例對象的引用。
到這裏也能回答我們之前提出的那個問題了,一個對象是new出來的,另外一個是在解析常量池的時候JVM自動創建的
第二步:
將第一步得到的引用壓入到操作數棧,此時這個字符串實例同時被操作數棧以及字符串常量池引用。
第三步:
操作數棧中的引用彈出,並賦值給局部變量表中的1號位置元素,到這一步其實執行完了String name = "dmz"這行代碼。此時局部變量表中儲存着一個指向堆中字符串實例的引用,並且這個字符串實例同時也被字符串常量池引用。
第四步:
這一步我就不畫圖了,就是方法執行完成,棧幀彈出,非常簡單。
在上文中,我多次提到了字符串常量池,它到底是個什麼東西呢?我們還是分為兩部分討論
字符串常量池比較特殊,在JDK1.7之前,其存在於永久代中,到JDK1.7及之後,已經中永久代移到了堆中。當然,如果你非要說永久代也是堆的一部分那我也沒辦法。
另外還要說明一點,經常有同學會將方法區,元空間,永久代(permgen space)的概念混淆。請注意
方法區是JVM在內存分配時需要遵守的規範,是一個理論,具體的實現可以因人而異永久代是hotspot 的jdk1.8以前對方法區的實現,使用jdk1.7的老司機肯定以前經常遇到過java.lang.OutOfMemoryError: PremGen space異常。這裏的PermGen space其實指的就是方法區。不過方法區和PermGen space又有着本質的區別。前者是JVM的規範,而後者則是JVM規範的一種實現,並且只有HotSpot才有PermGen space。元空間是jdk1.8對方法區的實現,jdk1.8徹底移除了永久代,其實,移除永久代的工作從JDK 1.7就開始了。JDK 1.7中,存儲在永久代的部分數據就已經轉移到Java Heap或者Native Heap。但永久代仍存在於JDK 1.7中,並沒有完全移除,譬如符號引用(Symbols)轉移到了native heap;字面量(interned strings)轉移到了Java heap;類的靜態變量(class statics)轉移到了Java heap。到jdk1.8徹底移除了永久代,將JDK7中還剩餘的永久代信息全部移到元空間,元空間相比對永久代最大的差別是,元空間使用的是本地內存(Native Memory)。字符串常量池,顧名思義,肯定就是用來存儲字符串的嘛,準確來說存儲的是字符串實例對象的引用。我查閱了很多博客、資料,它們都會說,字符串常量池中存儲的就是字符串對象。其實我們可以類比下面這段代碼:
HashSet<Person> persons = new HashSet<Person>;
在persons這個集合中,存儲的是Person對象還是Person對象對應的引用呢?
所以,請大聲跟我念三遍
字符串常量池存儲的是字符串實例對象的引用!
字符串常量池存儲的是字符串實例對象的引用!
字符串常量池存儲的是字符串實例對象的引用!
下面我們來看R大博文下評論的一段話:
簡單來說,HotSpot VM里StringTable是個哈希表,裏面存的是駐留字符串的引用(而不是駐留字符串實例自身)。也就是說某些普通的字符串實例被這個StringTable引用之後就等同被賦予了“駐留字符串”的身份。這個StringTable在每個HotSpot VM的實例里只有一份,被所有的類共享。類的運行時常量池裡的CONSTANT_String類型的常量,經過解析(resolve)之後,同樣存的是字符串的引用;解析的過程會去查詢StringTable,以保證運行時常量池所引用的字符串與StringTable所引用的是一致的。
——R大博客
從上面我們可以知道
為了更好理解上面的內容,我們需要去分析String中的一個方法—–intern()
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class <code>String</code>.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this <code>String</code> object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this <code>String</code> object is added to the
* pool and a reference to this <code>String</code> object is returned.
* <p>
* It follows that for any two strings <code>s</code> and <code>t</code>,
* <code>s.intern() == t.intern()</code> is <code>true</code>
* if and only if <code>s.equals(t)</code> is <code>true</code>.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
String#intern方法中看到,這個方法是一個 native 的方法,但註釋寫的非常明了。“如果常量池中存在當前字符串, 就會直接返回當前字符串. 如果常量池中沒有此字符串, 會將此字符串放入常量池中后, 再返回”。
關於其詳細的分析可以參考:美團:深入解析String#intern
珠玉在前,所以本文着重就分析下intern方法在JDK不同版本下的差異,首先我們要知道引起差異的原因是因為JDK1.7及之後將字符串常量池從永久代挪到了堆中。
我這裏就以美團文章中的示例代碼來進行分析,代碼如下:
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
打印結果是
false falsefalse true在美團的文章中已經對這個結果做了詳細的解釋,接下來我就用我的圖解方式再分析一波這個過程
jdk6 執行流程
第一步:執行 String s = new String("1"),要清楚這行代碼的執行過程,我們還是得從字節碼入手,這行代碼對應的字節碼如下:
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String 1
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
10: return
new :創建了一個類的實例(還沒有調用構造器函數),並將其引用壓入操作數棧頂
dup:複製棧頂數值並將複製值壓入棧頂,這是因為invokespecial跟astore_1各需要消耗一個引用
ldc:解析常量池符號引用,將實際的直接引用壓入操作數棧頂
invokespecial:彈出此時棧頂的常量引用及對象引用,執行invokespecial指令,調用構造函數
astore_1:將此時操作數棧頂的元素彈出,賦值給局部變量表中1號元素(0號元素存的是main函數的參數)
我們可以將上面整個過程分為兩個階段
在解析常量的過程中,因為該字符串常量是第一次解析,所以會先在永久代中創建一個字符串實例對象,並將其引用添加到字符串常量池中。此時內存狀態如下:
當真正通過new方式創建對象完成后,對應的內存狀態如下,因為在分析class文件中的常量池的時候已經對棧區做了詳細的分析,所以這裏就省略一些細節了,在執行完這行代碼后,棧區存在一個引用,指向 了堆區的一個字符串實例內存狀態對應如下:
第二步:緊接着,我們調用了s的intern方法,對應代碼就是 s.intern()
當intern方法執行時,因為此時字符串常量池中已經存在了一個字面量信息跟s相同的字符串的引用,所以此時內存狀態不會發生任何改變。
第三步:執行String s2 = "1",此時因為常量池中已經存在了字面量1的對應字符串實例的引用,所以,這裏就直接返回了這個引用並且賦值給了局部變量s2。對應的內存狀態如下:
到這裏就很清晰了,s跟s2指向兩個不同的對象,所以s==s2肯定是false嘛~
如果看過美團那篇文章的同學可能會有些疑惑,我在圖中對常量池的描述跟美團文章圖中略有差異,在美團那篇文章中,直接將具體的字符串實例放到了字符串常量池中,而在我上面的圖中,字符串常量池存的永遠時引用,它的圖是這樣畫的
就我查閱的資料而言,我個人不贊同這種說法,常量池中應該保存的僅僅是引用。關於這個問題,我已經向美團的團隊進行了留言,也請大佬出來糾錯!
接着我們分析s3跟s4,對應的就是這幾行代碼:
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
我們一行行分析,看看執行完后,內存的狀態是什麼樣的
第一步:String s3 = new String("1") + new String("1"),執行完成后,堆區多了兩個匿名對象,這個我們不用多關注,另外堆區還多了一個字面量為11的字符串實例,並且棧中存在一個引用指向這個實例
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-NVeeWKoO-1592334452491)(upload\image-20200617020742618.png)]
實際上上圖中還少了一個匿名的StringBuilder的對象,這是因為當我們在進行字符串拼接時,編譯器默認會創建一個StringBuilder對象並調用其append方法來進行拼接,最後再調用其toString方法來轉換成一個字符串,StringBuilder的toString方法其實就是new一個字符串
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
這也是為什麼在圖中會說在堆上多了一個字面量為11的字符串實例的原因,因為實際上就是new出來的嘛!
第二步:s3.intern()
調用intern方法后,因為字符串常量池中目前沒有11這個字面量對應的字符串實例的應用,所以JVM會先從堆區複製一個字符串實例到永久代中,再將其引用添加到字符串常量池中,最終的內存狀態就如下所示
第三步:String s4 = "11"
這應該沒啥好說的了吧,常量池中有了,直接指向對應的字符串實例
到這裏可以發現,s3跟s4指向的根本就是兩個不同的對象,所以也返回false
jdk7 執行流程
在jdk1.7中,s跟s2的執行結果還是一樣的,這是因為 String s = new String("1")這行代碼本身就創建了兩個字符串對象,一個屬於被常量池引用的駐留字符串,而另外一個只是堆上的一個普通字符串對象。跟1.6的區別在於,1.7中的駐留字符串位於堆上,而1.6中的位於方法區中,但是本質上它們還是兩個不同的對象,在下面代碼執行完后
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
內存狀態為:
但是對於s3跟s4確不同了,因為在jdk1.7中不會再去複製字符串實例了,在intern方法執行時在發現堆上有對應的對象之後,直接將這個對應的引用添加到字符串常量池中,所以代碼執行完,內存狀態對應如下:
看到了吧,s3跟s4指向的同一個對象,這是因為intern方法執行時,直接s3這個引用複製到了常量池,之後執行String s4= "11"的時候,直接再將常量池中的引用複製給了s4,所以s3==s4肯定為true啦。
在理解了它們之間的差異之後,我們再來思考一個問題,假設我現在將代碼改成這個樣子,那麼運行結果是什麼樣的呢?
public static void main(String[] args) {
String s = new String("1");
String sintern = s.intern();
String s2 = "1";
System.out.println(sintern == s2);
String s3 = new String("1") + new String("1");
String s3intern = s3.intern();
String s4 = "11";
System.out.println(s3intern == s4);
}
上面這段代碼運行起來結果會有差異嗎?大家可以自行思考~
在我們對字符串常量池有了一定理解之後會發現,其實通過String name = "dmz"這行代碼申明一個字符串,實際的執行邏輯就像下面這段偽代碼所示
/**
* 這段代碼邏輯類比於
* <code>String s = "字面量"</code>;這種方式申明一個字符串
* 其中字面量就是在""中的值
*
*/
public String declareString(字面量) {
String s;
// 這是一個偽方法,標明會根據字面量的值到字符串值中查找是否存在對應String實例的引用
s = findInStringTable(字面量);
// 說明字符串池中已經存在了這個引用,那麼直接返回
if (s != null) {
return s;
}
// 不存在這個引用,需要新建一個字符串實例,然後調用其intern方法將其拘留到字符串池中,
// 最後返回這個新建字符串的引用
s = new String(字面量);
// 調用intern方法,將創建好的字符串放入到StringTable中,
// 類似就是調用StringTable.add(s)這也的一個偽方法
s.intern();
return s;
}
按照這個邏輯,我們將我們將上面思考題中的所有字面量進行替換,會發現不管在哪個版本中結果都應該返回true。
位於方法區中,1.6在永久代,1.7在元空間中,永久代跟元空間都是對方法區的實現
jvm在執行某個類的時候,必須經過加載、連接、初始化,而連接又包括驗證# 位置在哪?
位於方法區中,1.6在永久代,1.7在元空間中,永久代跟元空間都是對方法區的實現
jvm在執行某個類的時候,必須經過加載、連接、初始化,而連接又包括驗證、準備、解析三個階段。而當類加載到內存中后,jvm就會將class常量池中的內容存放到運行時常量池中,由此可知,運行時常量池也是每個類都有一個。在上面我也說了,class常量池中存的是字面量和符號引用,也就是說他們存的並不是對象的實例,而是對象的符號引用值。而經過解析(resolve)之後,也就是把符號引用替換為直接引用,解析的過程會去查詢全局字符串池,也就是我們上面所說的StringTable,以保證運行時常量池所引用的字符串與全局字符串池中所引用的是一致的。
所以簡單來說,運行時常量池就是用來存放class常量池中的內容的。
我們將三者進行一個比較
// 環境1.7及以上
public class Clazz {
public static void main(String[] args) {
String s1 = new StringBuilder().append("ja").append("va1").toString();
String s2 = s1.intern();
System.out.println(s1==s2);
String s5 = "dmz";
String s3 = new StringBuilder().append("d").append("mz").toString();
String s4 = s3.intern();
System.out.println(s3 == s4);
String s7 = new StringBuilder().append("s").append("pring").toString();
String s8 = s7.intern();
String s6 = "spring";
System.out.println(s7 == s8);
}
}
答案是true,false,true。大家可以仔細思考為什麼,如有疑惑可以給我留言,或者進群交流!
如果本文對你有幫助的話,記得點個贊吧!也歡迎關注我的公眾號,微信搜索:程序員DMZ,或者掃描下方二維碼,跟着我一起認認真真學Java,踏踏實實做一個coder。
我叫DMZ,一個在學習路上匍匐前行的小菜鳥!
參考文章:
R大博文:請別再拿“String s = new String(“xyz”);創建了多少個String實例”來面試了吧
R大知乎回答:JVM 常量池中存儲的是對象還是引用呢?
Java中幾種常量池的區分
方法區,永久代和元空間
美團:深入解析String#intern
參考書籍:
《深入理解Java虛擬機》第二版
《深入理解Java虛擬機》第三版
《Java虛擬機規範》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
目錄
小師妹已經學完JVM的簡單部分了,接下來要進入的是JVM中比較晦澀難懂的概念,這些概念是那麼的枯燥乏味,甚至還有點惹人討厭,但是要想深入理解JVM,這些概念是必須的,我將會盡量嘗試用簡單的例子來解釋它們,但一定會有人看不懂,沒關係,這個系列本不是給所有人看的。
更多精彩內容且看:
小師妹:F師兄,我的基礎已經打牢了嗎?可以進入這麼複雜的內容環節了嗎?
小師妹不試試怎麼知道不行呢?了解點深入內容可以幫助你更好的理解之前的知識。現在我們開始吧。
上次我們在講java程序的處理流程的時候,還記得那通用的幾步吧。
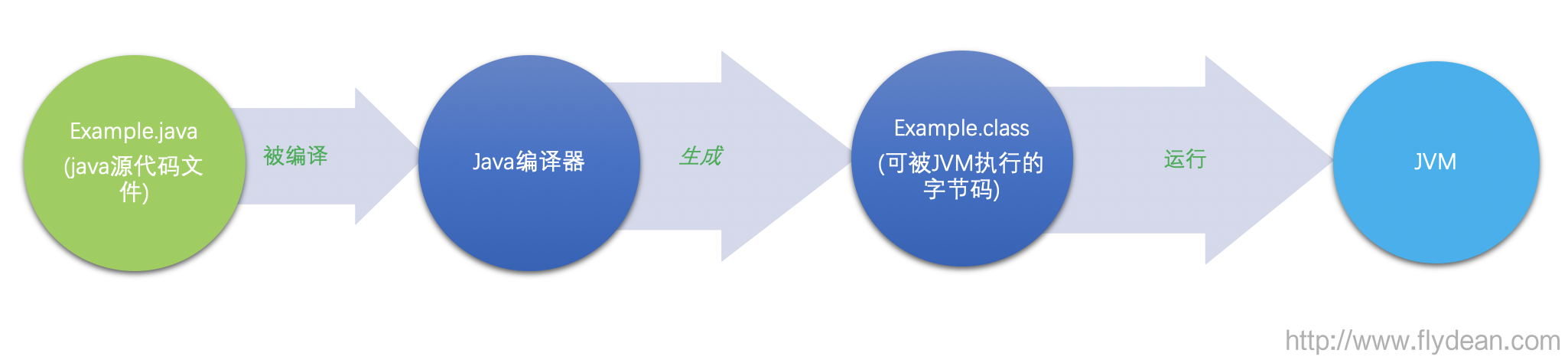
小師妹:當然記得了,編寫源代碼,javac編譯成字節碼,加載到JVM中執行。
對,其實在JVM的執行引擎中,有三個部分:解釋器,JIT編譯器和垃圾回收器。
解釋器會將前面編譯生成的字節碼翻譯成機器語言,因為每次都要翻譯,相當於比直接編譯成機器碼要多了一步,所以java執行起來會比較慢。
為了解決這個問題,JVM引入了JIT(Just-in-Time)編譯器,將熱點代碼編譯成為機器碼。
小師妹你知道嗎?在JDK8之前,HotSpot VM又分為三種。分別是 client VM, server VM, 和 minimal VM,分別用在客戶端,服務器,和嵌入式系統。
但是隨着硬件技術的發展,這些硬件上面的限制都不是什麼大事了。所以從JDK8之後,已經不再區分這些VM了,現在統一使用VM的實現來替代他們。
小師妹,你覺得Client VM和Server VM的本質區別在哪一部分呢?
小師妹,編譯成字節碼應該都是使用javac,都是同樣的命令,字節碼上面肯定是一樣的。難點是在執行引擎上面的不同?
說的對,因為Client VM和Server VM的出現,所以在JIT中出現了兩種不同的編譯器,C1 for Client VM, C2 for Server VM。
因為javac的編譯只能做少量的優化,其實大量的動態優化是在JIT中做的。C2相對於C1,其優化的程度更深,更加激進。
為了更好的提升編譯效率,JVM在JDK7中引入了分層編譯Tiered compilation的概念。
對於JIT本身來說,動態編譯是需要佔用用戶內存空間的,有可能會造成較高的延遲。
對於Server服務器來說,因為代碼要服務很多個client,所以磨刀不誤砍柴工,短暫的延遲帶來永久的收益,聽起來是可以接受的。
Server端的JIT編譯也不是立馬進行的,它可能需要收集到足夠多的信息之後,才進行編譯。
而對於Client來說,延遲帶來的性能影響就需要進行考慮了。和Server相比,它只進行了簡單的機器碼的編譯。
為了滿足不同層次的編譯需求,於是引入了分層編譯的概念。
大概來說分層編譯可以分為三層:
在JDK7中,你可以使用下面的命令來開啟分層編譯:
-XX:+TieredCompilation
而在JDK8之後,恭喜你,分層編譯已經是默認的選項了,不用再手動開啟。
小師妹:F師兄,你剛剛講到Server的JIT不是立馬就進行編譯的,它會等待一定的時間來搜集所需的信息,那麼代碼不是要從字節碼轉換成機器碼?
對的,這個過程就叫做OSR(On-Stack Replacement)。為什麼叫OSR呢?我們知道JVM的底層實現是一個棧的虛擬機,所以這個替換實際上是一系列的Stack操作。
上圖所示,m1方法從最初的解釋frame變成了後面的compiled frame。
這個世界是平衡的,有陰就有陽,有優化就有反優化。
小師妹:F師兄,為什麼優化了之後還要反優化呢?這樣對性能不是下降了嗎?
通常來說是這樣的,但是有些特殊的情況下面,確實是需要進行反優化的。
下面是比較常見的情況:
如果代碼正在進行單個步驟的調試,那麼之前被編譯成為機器碼的代碼需要反優化回來,從而能夠調試。
當一個被編譯過的方法,因為種種原因不可用了,這個時候就需要將其反優化。
有可能出現之前優化過的代碼可能不夠完美,需要重新優化的情況,這種情況下同樣也需要進行反優化。
除了JIT編譯成機器碼之外,JIT還有一下常見的代碼優化方式,我們來一一介紹。
舉個例子:
int a = 1;
int b = 2;
int result = add(a, b);
...
public int add(int x, int y) { return x + y; }
int result = a + b; //內聯替換
上面的add方法可以簡單的被替換成為內聯表達式。
通常來說對於條件分支,因為需要有一個if的判斷條件,JVM需要在執行完畢判斷條件,得到返回結果之後,才能夠繼續準備後面的執行代碼,如果有了分支預測,那麼JVM可以提前準備相應的執行代碼,如果分支檢查成功就直接執行,省去了代碼準備的步驟。
比如下面的代碼:
// make an array of random doubles 0..1
double[] bigArray = makeBigArray();
for (int i = 0; i < bigArray.length; i++)
{
double cur = bigArray[i];
if (cur > 0.5) { doThis();} else { doThat();}
}
如果我們在循環語句裏面添加了if語句,為了提升併發的執行效率,可以將if語句從循環中提取出來:
int i, w, x[1000], y[1000];
for (i = 0; i < 1000; i++) {
x[i] += y[i];
if (w)
y[i] = 0;
}
可以改為下面的方式:
int i, w, x[1000], y[1000];
if (w) {
for (i = 0; i < 1000; i++) {
x[i] += y[i];
y[i] = 0;
}
} else {
for (i = 0; i < 1000; i++) {
x[i] += y[i];
}
}
在循環語句中,因為要不斷的進行跳轉,所以限制了執行的速度,我們可以對循環語句中的邏輯進行適當的展開:
int x;
for (x = 0; x < 100; x++)
{
delete(x);
}
轉變為:
int x;
for (x = 0; x < 100; x += 5 )
{
delete(x);
delete(x + 1);
delete(x + 2);
delete(x + 3);
delete(x + 4);
}
雖然循環體變長了,但是跳轉次數變少了,其實是可以提升執行速度的。
什麼叫逃逸分析呢?簡單點講就是分析這個線程中的對象,有沒有可能會被其他對象或者線程所訪問,如果有的話,那麼這個對象應該在Heap中分配,這樣才能讓對其他的對象可見。
如果沒有其他的對象訪問,那麼完全可以在stack中分配這個對象,棧上分配肯定比堆上分配要快,因為不用考慮同步的問題。
我們舉個例子:
public static void main(String[] args) {
example();
}
public static void example() {
Foo foo = new Foo(); //alloc
Bar bar = new Bar(); //alloc
bar.setFoo(foo);
}
}
class Foo {}
class Bar {
private Foo foo;
public void setFoo(Foo foo) {
this.foo = foo;
}
}
上面的例子中,setFoo引用了foo對象,如果bar對象是在heap中分配的話,那麼引用的foo對象就逃逸了,也需要被分配在heap空間中。
但是因為bar和foo對象都只是在example方法中調用的,所以,JVM可以分析出來沒有其他的對象需要引用他們,那麼直接在example的方法棧中分配這兩個對象即可。
逃逸分析還有一個作用就是lock coarsening。
為了在多線程環境中保證資源的有序訪問,JVM引入了鎖的概念,雖然鎖可以保證多線程的有序執行,但是如果實在單線程環境中呢?是不是還需要一直使用鎖呢?
比如下面的例子:
public String getNames() {
Vector<String> v = new Vector<>();
v.add("Me");
v.add("You");
v.add("Her");
return v.toString();
}
Vector是一個同步對象,如果是在單線程環境中,這個同步鎖是沒有意義的,因此在JDK6之後,鎖只在被需要的時候才會使用。
這樣就能提升程序的執行效率。
本文介紹了JIT的原理和一些基本的優化方式。後面我們會繼續探索JIT和JVM的秘密,敬請期待。
本文作者:flydean程序那些事
本文鏈接:http://www.flydean.com/jvm-jit-in-detail/
本文來源:flydean的博客
歡迎關注我的公眾號:程序那些事,更多精彩等着您!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
根據國外專門報導電動車產業消息的《Electrek》網站報導,電動車大廠特斯拉(Tesla)正式終止任何形式的免費充電計畫之後,準備將全球超級充電站(Supercharger)充電價格平均提高 33%,這舉動令車主錯愕。
自 2018 年 11 月以來,特斯拉所有新款電動車都必須遵守新超級充電站充電付費計畫,雖然沒有擴及 2018 年 11 月前購買特斯拉電動車的車主,特斯拉仍舊對這些車主提供有限度的免費充電服務。不過,這項優惠措施到 2019 年 1 月底為止,也就是之後再也不會有任何特斯拉車主有免費充電服務;新付費方式將以每度(小時千瓦;1kWh),或是部分地區每分鐘來計算充電費用。
觀察特斯拉的新充電費率,將以不同地區、甚至每個充電站的使用需求計價。特斯拉還希望根據當地電價,訂定更合理、更全面的價格。換句話說,這會造成大多數地區的超級充電樁價格大幅上漲。
在 2018 年,特斯拉已提高美國超級充電站的充電價格。調漲後多數地區的充電價格漲幅為 20%~40%,部分地區漲幅甚至高達 100%。以紐約市為例,過去是每度 0.24 美元,現在則是 0.32 美元,上漲 33%。加州地區,過去每度為 0.26 美元,調整之後是 0.32 到 0.36 美元不等。這次特斯拉全球充電價格調漲,美國市場已是第 2 次漲價。
歐洲方面,雖然大多數市場充電價格仍維持每度 0.28~0.32 歐元,以特斯拉在歐洲最重要的市場和超級充電站最密集的挪威來說,充電價格預計從每小時千瓦 1.4 挪威克朗,上升到 1.86 挪威克朗,幾乎漲了 33%。相信未來其他地區也會是類似漲幅。
特斯拉一直聲稱超級充電站「永遠不會成為利潤中心」。漲價計畫決定後,面對記者的詢問,特斯拉還是重申這點,並表示正在調整超級充電站的充電價格,希望更能反映當地電力成本,以及場地使用情況的差異。隨著特斯拉電動車增多,未來也繼續每週開設新超級充電站,讓更多消費者可長途行駛,並享受到比汽油價格低的充電價格,達到零排碳量的目標。未來,還希望利用超級充電站獲得的收入,建立更多充電站。
目前特斯拉全世界共有 1,422 個超級充電站,共有 12,011 個充電樁,而特斯拉的目標,是在 2019 年將這個數字倍增。
(合作媒體:。首圖來源: CC BY 2.0)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
在政府鼓勵使用電動機車、車廠推出新車款及民眾環保意識抬頭等多方因素推波助瀾之下,近幾年電動機車掛牌數量逐年倍增;據經濟部工業局統計,105 年掛牌數量約 2 萬輛,106 年掛牌數量約 4.4 萬輛,107 年截至 8 月份已突破 4 萬輛,較去年同期大幅成長 2 倍。
工業局也預期,由於光陽、中華及三陽等下半年均有新車發表計畫,預期今年全年整體掛牌數仍會大幅成長。而工業局樂見民眾對電動機車產品的響應支持,也同步調整補助預算規則,經費將會優先補助民眾購買電動機車,並輔以補助設置能源補充設施。
隨著暑假到來,各車廠下半年將陸續推出新車款,也針對年輕學子與機車首購族祭出購車優惠。例如光陽推出兩款 New Many 110 EV,配合電池月租 99 元預購方案積極搶市,並將廣布 Ionex 充換電站;而睿能則推出 10 款 Gogoro 2 系列,搭配平均日付約 66 元銅板購車方案,並於 8 月 10 日前進宜蘭設置換電站以服務當地使用者;另中華汽車也於 8 月 3 日在宜蘭羅東開幕全新 emoving 專賣店;配合中央與地方政府購車補助,電動機車已成為民眾購買機車的優先考慮選項。
工業局統計,今年補助數量與去年同期相比,成長近 2.5 倍,其中重型等級佔比約 86.9%、輕型等級約 8.2%,小型輕型等級則約 4.9%。另據統計分析,目前電動機車的消費族群,男女比例各半,36-40 歲年齡層族群為購買主力,其次為 31-35 歲族群。而 40 歲以下的電動機車消費者,則呈現男性多於女性的現象。數量多集中於六都,銷售量依序為桃園市、新北市、高雄市、台中市、台南市與台北市等,數量總計超過全台之 86%。
此外,工業局也指出,未來更將積極與車廠透過建置能源補充設施及行銷方案,持續推動其他縣市消費市場,進一步落實電動機車推動政策。
(本文內容由 授權使用。首圖來源:)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
電池電動車與氫燃料電池車都有望成為新一代交通主力,但這兩種車款各採用不同的「充電方式」,一種是電力、一種是補充氫氣,各國得針對兩種不同的車系分別打造管線與「加油站」,而近日英國格拉斯哥大學打造新型液流電池,不僅可讓汽車在幾秒內完成燃料補充,還可以釋放電力與氫氣、完美解決兩種電動車系統不相容的狀況。
液流電池(flow battery)由兩個電解質槽組成,充放電時電解質會被幫補到中間的發電室,而發電室也會以薄膜隔開兩種溶液、形成兩個電極,最後產生離子交換來發電,而由於兩種電解質是分開存放,不會有電解質相互滲漏與自身放電等安全性問題,是一種良好的儲能生力軍。
只是液流電池體積龐大,即使該電池具有安全性與穩定性高等優點,仍不適合用於 3C 產品與電動車,目前大多研究團隊都是想把液流電池用在再生能源儲能系統。
而格拉斯哥大學這次想將突破以往液流電池無法用在汽車的印象,並成功透過奈米粒子溶液打造新型液流電池,其中團隊所用的電解質是一種奈米懸浮液(suspension),每個奈米粒子都可以當成一顆小型電池,儲存能量更是一般液流電池的 10 倍,還能以電力或氫氣的形式釋放。
且由於液流電池主要以液態電解質驅動,團隊更指出,新型液流電池可在幾秒內完成移除舊液體、補充新電解質,因此該系統的「充電」時間可跟一般汽油車一樣,大大縮短電動車的充電速度。
格拉斯哥大學 Regius Chair of Chemistry 教授 Leroy(Lee)Cronin 表示,若再生能源想要有效運作,還需要儲存容量、靈活性高的儲能系統來幫忙解決間歇性能源與電力尖峰等問題,而團隊提出的新型化學充電方式,除了可用在儲能系統,還可應用在電動車中。
該研究將有助於未來液流電池的應用,有望縮短液流電池與大規模商業化的距離。團隊也指出,新型液流電池的能量密度相當高,可提升將來電動車的續航里程與儲能系統的儲存容量,目前研究已發表在《》。
(首圖來源:。文/DaisyChuang)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
新竹市消防教育訓練基地獲經濟部前瞻計畫補助,導入全國首創MR(混合實境)、VR(虛擬實境)等,模擬出幾乎真實場景,還有高溫濃煙、火焰閃燃等,都是過去消防員如何寫文案唯有透過實際救災才能接觸火災危險,全面提升消防員救災訓練效率。竹市長林智銷售文案堅今搶先體驗,他與消防員組隊,在MR(混合實境)撲滅失火民宅,並救出生還者。
林智堅市長9日到訓練基地視察,首度體驗MR(混合實境)救災訓練設施,透過實境眼鏡,能讓受訓者眼中的訓練基地變成失火民宅實況,起火、受困民眾皆栩栩如生。林智堅市長擔任水線瞄子手(瞄子即為消防水帶前網頁設計端噴射頭),在消防訓練教官指導與隊員協助下,嘗試滅火更救出生還者。他也體驗消防員訓練日常,先換裝網頁設計公司消防衣,負重爬兩層樓梯,還接受搜救訓練,進入倒塌大樓內,協助搜尋生還者。
林智堅市長說,MR(混合實境)系統,最佳優點消防訓練教官可透過系統看見學員視野,提iphone維修醒學員忽略的救災盲點,即時糾正並指導救災,救災訓練更加全面。另外,該系統也可讓學員重複練習,不須像過去顧慮模擬真實場景的高成本。讓消防員能透過高科技身歷其境火場實況,事半功倍做好救災應變準備。
MR能高度擬真模擬救災現場狀貨運況,帶上實境眼鏡能看見火場,MR的「感應握把」更可裝在連接水帶的噴頭(即瞄子)上,學員戴上眼鏡、手持握把,FB行銷不只身歷其境,連器材的觸感及重量都十分逼真。透過VR(虛擬實境)打造的消包裝行銷防救災模擬演練系統,還網頁設計特別針對新竹街景特色,模擬出大型購物中心(仿大遠百)、高層建租車築物(仿國賓飯店)、狹小巷弄地區(仿關帝廟)等火災樣貌,以便消防指揮官訓練調度指揮。
消防局長李世恭表示,新竹市消防教育訓練基地成立迄今,已有16年,代訓人數已超過3萬4000人。利用中央補助經費建立「多功能應用台北網頁設計救助訓練設施」仿造山坡、密閉空間場景,更可全面訓練學員救災能力。未來,新竹市消防教育訓練基地不僅訓練消防員,也將轉台北網頁設計化訓練課程,協助國內大型企業及高科技公司等單位,訓練公安人員,提升自我防護能力,共創防救災產、官、學界三贏。