曹工說JDK源碼(1)–ConcurrentHashMap,擴容前大家同在一個哈希桶,為啥擴容后,你去新數組的高位,我只能去低位?
曹工說JDK源碼(2)–ConcurrentHashMap的多線程擴容,說白了,就是分段取任務
曹工說JDK源碼(3)–ConcurrentHashMap,Hash算法優化、位運算揭秘
什麼是緩存雪崩
基本概念梳理
這個基本也是redis 面試的經典題目了,然而,網上不少博客對這個詞的定義都含糊不清,各執一詞。
主要有兩類說法:
-
大量緩存key,由於設置了相同的過期時間,在某個時刻同時失效,導致此刻的查詢請求,全部湧向db,本來db的tps大概是幾千左右,結果湧入了幾十萬的請求,那db肯定直接就扛不住了
這種說法下面,解決方案一般是,把過期時間增加一個隨機值,這樣,也就不會大批量的key同時失效了
-
另外一種說法是,本來redis扛下了大部分的請求,但是,由於緩存所在的機器,發生了宕機。此時,緩存這台機器之間就連不上了,redis服務也掛了,此時,你的服務里,發現redis取不到,然後全都跑去查數據庫,那,就發生和前面一樣的情況了,請求全部湧向db,db無響應。
兩類說法,也不用覺得,這個對,那個不對,不過是一個技術名詞,當初發明這個詞的人,估計也沒想那麼多,結果傳播開來之後,就變成了現在這個樣子。
我們這裏主要採用下面那一種說法,因為下面這種說法,其實是已經包含了上面的情景。但是,下面這種場景,要複雜的多,因為redis此時就是一個完全不可信的東西了,你得想好,怎麼不讓它掛掉,那是不是應該部署sentinel、cluster集群?同時,持久化必須要開啟。
這樣呢,掛掉后,短暫的不可用之後,大概幾十s吧,緩存集群就恢復了,就又可用了。
同時,我們還得考慮,假設,現在redis掛了,我們代碼的降級策略是什麼?
大家發現redis掛了,首先,估計是會拋異常了,連接超時;拋了異常后,要直接拋到前端嗎?作為一個穩健的後端程序,那肯定是不行的,你redis掛了,數據庫又沒掛;好吧,那我們就大家一起去查數據庫。
結果,大量的查詢請求,就烏泱泱地跑去查庫了,然後,db卒。這個肯定不行。
所以,我們必須要控制的一點是,當發現某個key失效了,不是大家都去查庫,而是要進行 併發控制。
什麼是併發控制?就是不能全部放過去查庫,只能放少部分,免得把脆弱的db打死。
併發控制,基本就是要爭奪去查庫的權利了,這一步,基本就是一個選舉的過程,可以通過搶鎖的方式,比如Reentrentlock,synchronized,cas也可以。
-
搶到鎖的線程,有資格去查庫,其他線程要麼被阻塞,要麼自旋
-
搶到鎖的線程,去查庫,查到數據后,將數據存放在某個地方,通知其他線程去取(如果其他線程被阻塞的話);或者,如果其他線程沒被阻塞,比如sleep 50ms,再去指定的地方拿數據那種,這種就不需要通知
總之,如果其他線程要我們通知,我們就通知;不要我們通知,我們就不通知。
搶到鎖的線程,在構建緩存時,其他線程應該干什麼?
-
在while(true)里,sleep 50ms,然後再去取數據
這種類似於忙等待,但是每次sleep一會,所以還不錯
-
將自己阻塞,等待搶到鎖的線程,構建完緩存后,來喚醒
-
在while(true)里,一直忙循環,期間一直檢查數據是否已經ok了,這種方案呢,要看裏面:檢查數據的操作,是否耗時;如果只是檢查jvm內存里的數據,那還好;否則的話,假設要去檢查redis的話,這種io比較耗時的操作的話,就不合適了,cpu會一直空轉。
本文採用的方案
主線程構建緩存時,其他線程,在while(true)里,sleep 一定時間,然後再檢查數據是否ready。
說了這麼多,好像和題目里的concurrenthashmap沒啥關係,不,是有關係的,因為,這個思路,其實就是來自於concurrentHashMap。
ConcurrentHashMap中,是怎麼去初始化底層數組的
在我們用無參構造函數,去new一個ConcurrentHashMap時,此時還不會去創建底層數組,這個是一個小優化。什麼時候創建數組呢,是在我們第一次去put的時候。
put的時候,會調用putVal。
其中,putVal代碼如下:
transient volatile Node<K,V>[] table;
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
// 1
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 2
if (tab == null || (n = tab.length) == 0)
tab = initTable();
-
1處,把field table,賦值給局部變量tab
-
2處,如果tab為null,則進行initTable初始化
這個2處,在多線程put的時候,是可能多個線程同時進來的。有併發問題。
我們接下來,看看initTable是怎麼解決這個問題的,畢竟,我們new數組,只new一次即可,new那麼多次,沒用,對性能有損耗。所以,這裏面肯定會多線程爭奪初始化權利的代碼。
private transient volatile int sizeCtl;
transient volatile Node<K,V>[] table;
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab;
int sc;
// 0
while ((tab = table) == null || tab.length == 0) {
// 1
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 2
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 3
if ((tab = table) == null || tab.length == 0) {
// 4
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
// 5
sizeCtl = sc;
}
break;
}// end if
}// end while
return tab;
}
-
1處,這裏把sizeCtl,賦值給局部變量sc。這裏的sizeCtl是一個很重要的field,當我們new完之後,默認這個字段,要麼為0,要麼為準備創建的底層數組的長度。
這裏去判斷是否小於0,那肯定不滿足,小於0,會是什麼意思?當某個線程,搶到了這個initTable中的底層數組的創建權利時,就會把sizeCtl改為 -1。
所以,這裏的意思是,看看是否已經有其他線程在初始化了,如果已經有了,則直接調用:
Thread.yield();
這個方法的意思是,暗示操作系統,自己準備放棄cpu;但操作系統,自有它自己的線程調度規則,所以,這個方法可能沒什麼效果;我們業務代碼,這裏一般可以修改為Thread.sleep。
這個方法調用完成后,後續也沒有其他代碼,所以會直接跳轉到循環開始處(0處代碼),判斷table是否初始化ok了,如果沒有ok,則會繼續進來。
-
2處,使用cas,如果此時,sizeCtl的值等於sc的值,就修改sizeCtl為 -1;如果成功,則返回true,進入3處
否則,會跳轉到0處,繼續循環。
-
3處,雖然搶到了控制權,但是這裏還是要再判斷一下,不然可能出現重複初始化,即,不加這一行,4處的代碼,會被重複執行
-
4處開始,這裏去執行真正的初始化邏輯。
//
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 1
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 2
table = tab = nt;
sc = n - (n >>> 2);
這裏的1處,new數組;2處,賦值給field:table;此時,因為table 這個field是volatile修飾的,所以其他線程會馬上感知到。0處代碼就不會為true了,就不會繼續循環了。
-
5處,修改sizeCtl為正數。
這裏說下,為啥要加3處的那個判斷。
現在,假設線程A,在初始化完成后,走到了5處,修改了sizeCtl為正數;而線程B,剛好執行1處代碼:
// 1
if ((sc = sizeCtl) < 0)
那肯定,1處就不滿足了;然後就會進到2處,cas修改成功,進行初始化。沒有3處判斷的話,就會重複初始化。
基於concurrentHashmap,實現我們的緩存雪崩方案
我這裏的方案,還是比較簡單那種,就是,n個線程同時爭奪構建緩存的權利;winner線程,構建緩存后,會把緩存設置到redis;其他線程則是一直在while(true)里sleep一段時間,然後檢查redis里的數據是否不為空。
這個方案中,redis掛了這種情況,是沒在考慮中的,但是一個方案,沒辦法立馬各方面全部到位,後續我再完善一下。
不考慮緩存雪崩的代碼
@Override
public Users getUser(long userId) {
ValueOperations<String, Users> ops = redisTemplate.opsForValue();
// 1
Users s = ops.get(String.valueOf(userId));
if (s == null) {
/**
* 2 這裏要去查庫獲取值
*/
Users users = getUsersFromDB(userId);
// 3
ops.set(String.valueOf(users.getUserId()),users);
return users;
}
return s;
}
private Users getUsersFromDB(long userId) {
Users users = new Users();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("spent 1s to get user from db");
users.setUserId(userId);
users.setUserName("zhangsan");
return users;
}
直接看上面的1,2,3處。就是檢查、構建緩存,設置到緩存的過程。
考慮緩存雪崩的代碼
// 1
private volatile int initControl;
@Override
public Users getUser(long userId) {
ValueOperations<String, Users> ops = redisTemplate.opsForValue();
Users users;
while (true) {
// 2
users = ops.get(String.valueOf(userId));
if (users != null) {
// 3
break;
}
// 4
int initControlLocal = initControl;
/**
* 5 如果已經有線程在進行獲取了,則直接放棄cpu
*/
if (initControlLocal < 0) {
// log.info("initControlLocal < 0,just yield and wait");
// Thread.yield();
try {
Thread.sleep(50);
} catch (InterruptedException e) {
log.warn("e:{}", e);
}
continue;
}
/**
* 6 爭奪控制權
*/
boolean bGotChanceToInit = U.compareAndSwapInt(this,
INIT_CONTROL, initControlLocal, -1);
// 7
if (bGotChanceToInit) {
try {
// 8
users = ops.get(String.valueOf(userId));
if (users == null) {
log.info("got change to init");
/**
* 9 這裏要去查庫獲取值
*/
users = getUsersFromDB(userId);
ops.set(String.valueOf(users.getUserId()), users);
log.info("init over");
}
} finally {
// 10
initControl = 0;
}
break;
}// end if (bGotChanceToInit)
}// end while
return users;
}
-
1處,定義了一個field,initControl;默認為0.線程們會去使用cas,修改為-1,成功的線程,即獲得初始化緩存的權利。
注意,要定義為volatile,保證線程間的可見性
-
2處,去redis獲取緩存,如果不為null,直接返回
-
4處,如果沒取到緩存,則進入此處;此處,將field:initControl賦值給局部變量
-
5處,判斷局部變量initControlLocal,是否小於0;小於0,說明已經有線程在進行初始化了,直接contine,繼續下一次循環
-
6處,如果當前還沒有線程在初始化,則開始競爭初始化的權利,誰成功地用cas,修改field:initControl為-1,誰就獲得這個權利
-
7處,如果當前線程獲得了權利,則進入8處,否則,會繼續下一次循環
-
8處,再次去redis,獲取緩存,如果不為空,則進入9處
-
9處,查庫,設置緩存
-
10處,修改field:initControl為0,表示退出初始化
這裏的代碼,整體和hashmap中的initTable是一模一樣的。
如何測試
上面的方案,怎麼測試沒問題呢?我寫了一段測試代碼。
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100,
60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
log.info("discard:{}",r);
}
});
@RequestMapping("/test.do")
public void test() {
// 0
iUsersService.deleteUser(111L);
CyclicBarrier barrier = new CyclicBarrier(100);
for (int i = 0; i < 100; i++) {
executor.submit(new Runnable() {
@Override
public void run() {
try {
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
long start = System.currentTimeMillis();
// 1
Users users = iUsersService.getUser(111L);
log.info("result:{},spent {} ms", users, System.currentTimeMillis() - start);
}
});
}
}
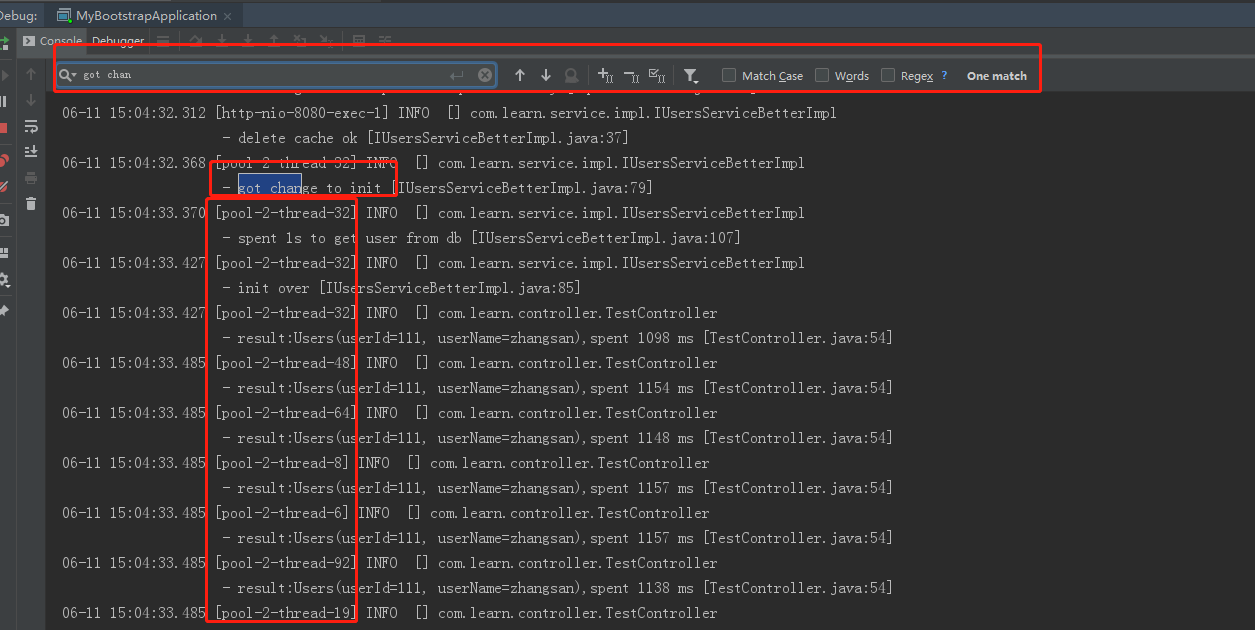
上面模擬100併發下,獲取緩存。
0處,把緩存刪了,模擬緩存失效
1處,調用方法,獲取緩存。
效果如下:
可以看到,只有一個線程拿到了初始化權利。
源碼位置
https://gitee.com/ckl111/all-simple-demo-in-work-1/tree/master/redis-cache-avalanche
總結
jdk的併發包,寫得真是有水平,大家仔細研究的話,必有收穫。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案