所有知識體系文章,GitHub已收錄,歡迎Star!再次感謝,願你早日進入大廠!
GitHub地址: https://github.com/Ziphtracks/JavaLearningmanual
Java註解
一、Java註解概述
註解(Annotation),也叫元數據。一種代碼級別的說明。它是JDK1.5及以後版本引入的一個特性,與類、接口、枚舉是在同一個層次。它可以聲明在包、類、字段、方法、局部變量、方法參數等的前面,用來對這些元素進行說明,註釋。
二、註解的作用分類
- 編寫文檔: 通過代碼里標識的元數據生成文檔【生成文檔doc文檔】
- 代碼分析: 通過代碼里標識的元數據對代碼進行分析【使用反射】
- 編譯檢查: 通過代碼里標識的元數據讓編譯器能夠實現基本的編譯檢查【Override等】
編寫文檔
首先,我們要知道Java中是有三種註釋的,分別為單行註釋、多行註釋和文檔註釋。而文檔註釋中,也有@開頭的元註解,這就是基於文檔註釋的註解。我們可以使用javadoc命令來生成doc文檔,此時我們文檔的內元註解也會生成對應的文檔內容。這就是編寫文檔的作用。
代碼分析
我們頻繁使用之一,也是包括使用反射來通過代碼里標識的元數據對代碼進行分析的,此內容我們在後續展開講解。
編譯檢查
至於在編譯期間在代碼中標識的註解,可以用來做特定的編譯檢查,它可以在編譯期間就檢查出“你是否按規定辦事”,如果不按照註解規定辦事的話,就會在編譯期間飄紅報錯,並予以提示信息。可以就可以為我們代碼提供了一種規範制約,避免我們後續在代碼中處理太多的代碼以及功能的規範。比如,@Override註解是在我們覆蓋父類(父接口)方法時出現的,這證明我們覆蓋方法是繼承於父類(父接口)的方法,如果該方法稍加改變就會報錯;@FunctionInterface註解是在編譯期檢查是否是函數式接口的,如果不遵循它的規範,同樣也會報錯。
三、jdk的內置註解
3.1 內置註解分類
- @Override: 標記在成員方法上,用於標識當前方法是重寫父類(父接口)方法,編譯器在對該方法進行編譯時會檢查是否符合重寫規則,如果不符合,編譯報錯。
- @Deprecated: 用於標記當前類、成員變量、成員方法或者構造方法過時如果開發者調用了被標記為過時的方法,編譯器在編譯期進行警告。
- @SuppressWarnings: 壓制警告註解,可放置在類和方法上,該註解的作用是阻止編譯器發出某些警告信息。
3.2 @Override註解
標記在成員方法上,用於標識當前方法是重寫父類(父接口)方法,編譯器在對該方法進行編譯時會檢查是否符合重寫規則,如果不符合,編譯報錯。
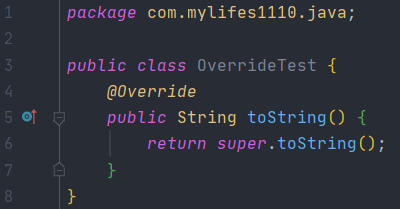
這裏解釋一下@Override註解,在我們的Object基類中有一個方法是toString方法,我們通常在實體類中去重寫此方法來達到打印對象信息的效果,這時候也會發現重寫的toString方法上方就有一個@Override註解。如下所示:
image-20200604203535421
於是,我們試圖去改變重寫后的toString方法名稱,將方法名改為toStrings。你會發現在編譯期就報錯了!如下所示:
image-20200604203645332
那麼這說明什麼呢?這就說明該方法不是我們重寫其父類(Object)的方法。這就是@Override註解的作用。
3.3 @Deprecated註解
用於標記當前類、成員變量、成員方法或者構造方法過時如果開發者調用了被標記為過時的方法,編譯器在編譯期進行警告。
我們解釋@Deprecated註解就需要模擬一種場景了。假設我們公司的產品,目前是V1.0版本,它為用戶提供了show1方法的功能。這時候我們為產品的show1方法的功能又進行了擴展,打算髮布V2.0版本。但是,我們V1.0版本的產品需要拋棄嗎?也就是說我們V1.0的產品功能還繼續讓用戶使用嗎?答案肯定是不能拋棄的,因為有一部分用戶是一直用V1.0版本的。如果拋棄了該版本會損失很多的用戶量,所以我們不能拋棄該版本。這時候,我們對功能進行了擴展后,發布了V2.0版本,我們給予用戶的通知就可以了,也就是告知用戶我們在V2.0版本中為功能進行了擴展。可以讓用戶自行選擇版本。
但是,除了發布告知用戶版本情況之外,我們還需要在原來版本的功能上給予提示,在上面的模擬場景中我們需要在show1方法上方加@Deprecated註解給予提示。通過這種方式也告知用戶“這是舊版本時候的功能了,我們不建議再繼續使用舊版本的功能”,這句話的意思也就正是給用戶做了提示。用戶也會這麼想“奧,這版本的這個功能不好用了,肯定有新版本,又更好用的功能。我要去官網查一下下載新版本”,還會有用戶這麼想“我明白了,又更新出更好的功能了,但是這個版本的功能我已經夠用了,不需要重新下載新版本了”。
那麼我們怎麼查看我上述所說的在功能上給予的提示呢?這時候我需要去創建一個方法,然後去調用show1方法,並查看調用時它是如何提示的。
圖已經貼出來了,你是否發現的新舊版本功能的異同點呢?很明顯,在方法中的提示是在調用的方法名上加了一道橫線把該方法劃掉了。這就體現了show1方法過時了,已經不建議使用了,我們為你提供了更好的。
回想起來,在我們的api中也會有方法是過時的,比如我們的Date日期類中的方法有很多都已經過時了。如下圖:
image-20200604210154348 image-20200604210416762
如你所見,是不是有很多方法都過時了呢?那它的方法上是加了@Deprecated註解嗎?來跟着我的腳步,我帶你們看一下。
我們已經知道的Date類中的這些方法已經是過時的了,如果我們使用該方法並執行該程序的話。執行的過程中就會提示該方法已過時的內容,但是只是提示,並不影響你使用該方法。如下:
image-20200604221938895
OK!這也就是@Deprecated註解的作用了。
3.4 @SuppressWarnings註解
壓制警告註解,可放置在類和方法上,該註解的作用是阻止編譯器發出某些警告信息,該註解為單值註解,只有 一個value參數,該參數為字符串數組類型,參數值常用的有如下幾個。
- unchecked:未檢查的轉化,如集合沒有指定類型還添加元素
- unused:未使用的變量
- resource:有泛型未指定類型
- path:在類路徑,原文件路徑中有不存在的路徑
- deprecation:使用了某些不贊成使用的類和方法
- fallthrough:switch語句執行到底沒有break關鍵字
- rawtypes:沒有寫泛型,比如: List list = new ArrayList();
- all:全部類型的警告
壓制警告註解,顧名思義就是壓制警告的出現。我們都知道,在Java代碼的編寫過程中,是有很多黃色警告出現的。但是我不知道你的導師是否教過你,程序員只需要處理紅色的error,不需要理會黃色的warning。如果你的導師說過此問題,那是有原因的。因為在你學習階段,我們認清處理紅色的error即可,這樣可以減輕你學習階段在腦部的記憶內容。如果你剛剛加入學習Java的隊列中,需要大腦記憶的東西就有太多了,也就是我們目前不需要額外記憶其他的東西,只記憶重點即可。至於黃色warning嘛,在你的學習過程中慢慢就會有所了解的,而不是死記硬背的。
那為了解釋@SuppressWarnings註解,我們還使用上一個例子,因為在那個例子中就有黃色的warning出現。
而每一個黃色的warning都會有警告信息的。比如,這一個圖中的警告信息,就告知你show2()方法沒有被使用,簡單來說,你創建的show2方法,但是你在代碼中並沒有調用過此方法。以後你便會遇到各種各樣黃色的warning。然後, 我們就可以使用不同的註解參數來壓制不同的註解。但是在該註解的參數中,提供了一個all參數可以壓制全部類型的警告。而這個註解是需要加到類的上方,並賦予all參數,即可壓制所有警告。如下:
image-20200604213943722
我們加入註解並賦予all參數后,你會發現use方法和show2方法的警告沒有了,實際上導Date包的警告還在,因為我們Date包導入到了該類中,但是我們並沒有創建Date對象,也就是並沒有寫入Date在代碼中,你也會發現那一行是灰色的,也就證明了我們沒有去使用導入這個包的任何信息的說法,出現這種情況我們就需要把這個沒有用的導包內容刪除掉,使用Ctrl + X刪除導入沒有用到的包即可。還有一種辦法就是在包的上方修飾壓制警告註解,但是我認為在一個沒有用的包上加壓制註解是毫無意義的,所以,我們直接刪除就好。
然後,我們還見到上圖,註解那一行出現了警告信息提示。這一行的意思是冗餘的警告壓制。這就是說我們壓制以下的警告並沒有什麼意義而造成的冗餘,但是如果我們使用了該類並做了點什麼的話,壓制註解的冗餘警告就會消失,畢竟我們使用了該類,此時就不會早場冗餘了。
上述解釋@SuppressWarnings註解也差不多就這些了。OK,繼續向下看吧。持續為大家講解。
3.5 @Repeatable註解
@Repeatable 表明標記的註解可以多次應用於相同的聲明或類型,此註解由Java8版本引入。我們知道註解是不能重複定義的,其實該註解就是一個語法糖,它可以重複多此使用,更適用於我們的特殊場景。
首先,我們先創建一個可以重複使用的註解。
package com.mylifes1110.anno;
import java.lang.annotation.Repeatable;
@Repeatable(Hour.class)
public @interface Hours {
double[] hours() default 0;
}
你會發現註解要求傳入的值是一個類對象,此類對象就需要傳入另外一個註解,這裏也就是另外一個註解容器的類對象。我們去創建一下。
package com.mylifes1110.anno;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
//容器
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Hour {
Hours[] value();
}
其實,這兩個註解的套用,就是將一個普通的註解封裝了一個可重複使用的註解,來達到註解的復用性。最後,我們創建一下測試類,隨後帶你去看一下源碼。
package com.mylifes1110.java;
import com.mylifes1110.anno.Hours;
@Hours(hours = 4)
@Hours(hours = 4.5)
@Hours(hours = 2)
public class Worker {
public static void main(String[] args) {
//通過Hours註解類型來獲取Worker中的值數組對象
Hours[] hours = Worker.class.getAnnotationsByType(Hours.class);
//遍曆數組
for (Hours h : hours) {
System.out.println(h);
}
}
}
測試類,是一個工人測試類,該工人使用註解記錄早中晚的工作時間。測試結果如下:
image-20200606183652359
然後我們進入到源碼一探究竟。
image-20200606183737877
我們發現進入到源碼后,就只看見一個返回值為類對象的抽象方法。這也就驗證了該註解只是一個可實現重複性註解的語法糖而已。
四、註解分類
4.1 註解分類
註解可以根據註解參數分為三大類:
- 標記註解: 沒有參數的註解,僅用自身的存在與否為程序提供信息,如@Override註解,該註解沒有參數,用於表示當前方法為重寫方法。
- 單值註解: 只有一個參數的註解,如果該參數的名字為value,那麼可以省略參數名,如 @SuppressWarnings(value = “all”),可以簡寫為@SuppressWarnings(“all”)。
- 完整註解: 有多個參數的註解。
4.2 標記註解
說到@Override註解是一個標記註解,那我們進入到該註解的源碼查看一下。從上往下看該註解源碼,發現它繼承了導入了
java.lang.annotation.*,也就是有使用到該包的內容。然後下面就又是兩個看不懂的註解,其實發現註解的定義格式是public修飾的@Interface,最終看到該註解中方法體並沒有任何參數,也就是只起到標記作用。
4.3 單值註解
在上面我們用到的@SuppressWarnings註解就是一個單值註解。那我們進入到它的源碼看一下是怎麼個情況。其實,和標記註解比較,它就多一個value參數而已,而這就是單值註解的必要條件,即只有一個參數。並且這一個參數為value時,我們可以省略value。
4.4 完整註解
上述兩個類型註解講解完,至於完整註解嘛,這下就能更明白了。其中的方法體就是有多個參數而已。
五、自定義註解
5.1 自定義註解格式
格式: public @Interface 註解名 {屬性列表/無屬性}
注意: 如果註解體中無任何屬性,其本質就是標記註解。但是與其標註註解還少了上邊修飾的元註解。
如下,這就是一個註解。但是它與jdk自定義註解有點區別,jdk自定義註解的上方還有註解來修飾該註解,而那註解就叫做元註解。元註解我會在後面詳細的說到。
image-20200606104149069
這裏我們的確不知道@Interface是什麼,那我們就把自定義的這個註解反編譯一下,看一下反編譯信息。反編譯操作如下:
image-20200606104818131
反編譯后的反編譯內容如下:
public interface com.mylifes1110.anno.MyAnno extends java.lang.annotation.Annotation {
}
首先,看過反編譯內容后,我們可以直觀的得知他是一個接口,因為它的public修飾符後面的關鍵字是interface。
其次,我們發現MyAnno這個接口是繼承了java.lang.annotation包下的Annotation接口。
所以,我們可以得知註解的本質就是一個接口,該接口默認繼承了Annotation接口。
既然,是繼承的Annotation接口,那我們就去進入到這個接口中,看它定義了什麼。以下是我抽取出來的接口內容。我們發現它看似很常見,其實它們不是很常用,作為了解即可。
public interface Annotation {
boolean equals(Object obj);
int hashCode();
String toString();
Class<? extends Annotation> annotationType();
}
最後,我們的註解中也是可以寫有屬性的,它的屬性不同於普通的屬性,它的屬性是抽象方法。既然註解也是一個接口,那麼我們可以說接口體中可以定義什麼,它同樣也可以定義,而它的修飾符與接口一樣,也是默認被public abstract修飾。
而註解體中的屬性也是有要求的。其屬性要求如下:
- 屬性的返回值類型必須是以下幾種:
- 基本數據類型
- String類型
- 枚舉類型
- 註解
- 以上類型的數組
- 注意: 在這裏不能有void的無返回值類型和以上類型以外的類型
- 定義的屬性,在使用時需要給註解中的屬性賦值
- 如果定義屬性時,使用
default關鍵字給屬性默認初始化值,則使用註解時可以不為屬性賦值,它取的是默認值。如果為它再次傳入值,那麼就發生了對原值的覆蓋。- 如果只有一個屬性需要賦值,並且屬性的名稱為value,則賦值時value可以省略,可以直接定義值
- 數組賦值時,值使用
{}存儲值。如果數組中只有一個值,則可以省略{}。
5.2 自定義註解屬性的返回值
屬性返回值既然有以上幾種,那麼我就在這裏寫出這幾種演示一下是如何寫的。
首先,定義一個枚舉類和另外一個註解備用。
package com.mylifes1110.enums;
public enum Lamp {
RED, GREEN, YELLOW
}
package com.mylifes1110.anno;
public @interface MyAnno2 {
}
其次,我們來定義上述幾種類型,如下:
package com.mylifes1110.anno;
import com.mylifes1110.enums.Lamp;
public @interface MyAnno {
//基本數據類型
int num();
//String類型
String value();
//枚舉類型
Lamp lamp();
//註解類型
MyAnno2 myAnno2();
//以上類型的數組
String[] values();
Lamp[] lamps();
MyAnno2[] myAnno2s();
int[] nums();
}
5.3 自定義註解的屬性賦值
這裏我們演示一下,首先,我們使用該註解來進行演示。
package com.mylifes1110.anno;
public @interface MyAnno {
//基本數據類型
int num();
//String類型
String value();
}
隨後創建一個測試類,在類的上方寫上註解,你會發現,註解的參數中會讓你寫這兩個參數(int、String)。
image-20200606113037920
此時,傳參是這樣來做的。格式為:名稱 = 返回值類型參數。如下:
上述所說,如果使用default關鍵字給屬性默認初始化值,就不需要為其參數賦值,如果賦值的話,就把默認初始化的值覆蓋掉了。
當然還有一個規則,如果只有一個屬性需要賦值,並且屬性的名稱為value,則賦值時value可以省略,可以直接定義值。那麼,我們的num已經有了默認值,就可以不為它傳值。我們發現,註解中定義的屬性就剩下了一個value屬性值,那麼我們就可以來演示這個規則了。
image-20200606113849685
這裏,我並沒有寫屬性名稱value,而是直接為value賦值。如果我將num的default關鍵字修飾去掉呢,那意思也就是說在使用該註解時必須為num賦值,這樣可以省略value嗎?那我們看一下。
image-20200606114216801
結果,就是我們所想的,它報錯了,必須讓我們給num賦值。其實想想這個規則也是很容易懂的,定義一個為value的值,就可以省略其value名稱。如果定義多個值,它們可以省略名稱就無法區分定義的是那個值了,關鍵是還有數組,數組內定義的是多個值呢,對吧。
5.4 自定義註解的多種返回值類型賦值
這裏我們演示一下,上述的多種返回值類型是如何賦值的。這裏我們定義這幾個參數來看一下,是如何為屬性賦值的。
num是一個int基本數據類型,即num = 1
value是一個String類型,即value = "str"
lamp是一個枚舉類型,即lamp = Lamp.RED
myAnno2是一個註解類型,即myAnno2 = @MyAnno2
values是一個String類型數組,即values = {"s1", "s2", "s3"}
values是一個String類型數組,其數組中只有一個值,即values = "s4"
注意: 值與值之間是,隔開的;數組是用{}來存儲值的,如果數組中只有一個值可以省略{};枚舉類型是枚舉名.枚舉值
六、元註解
6.1 元註解分類
元註解就是用來描述註解的註解。一般使用元註解來限制自定義註解的使用範圍、生命周期等等。
而在jdk的中java.lang.annotation包中定義了四個元註解,如下:
| 元註解 | 描述 |
|---|---|
| @Target | 指定被修飾的註解的作用範圍 |
| @Retention | 指定了被修飾的註解的生命周期 |
| @Documented | 指定了被修飾的註解是可以Javadoc等工具文檔化 |
| @Inherited | 指定了被修飾的註解修飾程序元素的時候是可以被子類繼承的 |
6.2 @Target
@Target 指定被修飾的註解的作用範圍。其作用範圍可以在源碼中找到參數值。
| 屬性 | 描述 |
|---|---|
| CONSTRUCTOR | 用於描述構造器 |
| FIELD(常用) | 用於描述屬性 |
| LOCAL_VARIABLE | 用於描述局部變量 |
| METHOD(常用) | 用於描述方法 |
| PACKAGE | 用於描述包 |
| PARAMETER | 用於描述參數 |
| TYPE(常用) | 用於描述類、接口(包括註解類型) 或enum聲明 |
| ANNOTATION_TYPE | 用於描述註解類型 |
| TYPE_USE | 用於描述使用類型 |
由此可見,該註解體內只有一個value屬性值,但是它的類型是一個ElementType數組。那我們進入到這個數組中繼續查看。
進入到該數組中,你會發現他是一個枚舉類,其中定義了上述表格中的各個屬性。
了解了@Target的作用和屬性值后,我們來使用一下該註解。首先,我們要先用該註解來修飾一個自定義註解,定義該註解的指定作用在類上。如下:
而你觀察如下測試類,我們把註解作用在類上時是沒有錯誤的。而當我們的註解作用在其他地方就會報錯。這也就說明了,我們@Target的屬性起了作用。
注意: 如果我們定義多個作用範圍時,也是可以省略該參數名稱了,因為該類型是一個數組,雖然能省略名稱但是,我們還需要用{}來存儲。
6.3 @Retention
@Retention 指定了被修飾的註解的生命周期
| 屬性 | 描述 |
|---|---|
| RetentionPolicy.SOURCE | 註解只在源碼階段保留,在編譯器進行編譯時它將被丟棄忽視。 |
| RetentionPolicy.CLASS | 註解只被保留到編譯進行時的class文件,但 JVM 加載class文件時候被遺棄,也就是在這個階段不會讀取到該class文件。 |
| RetentionPolicy.RUNTIME(常用) | 註解可以保留到程序運行的時候,它會被加載進入到 JVM 中,所以在程序運行時可以獲取到它們。 |
注意: 我們常用的定義即是RetentionPolicy.RUNTIME,因為我們使用反射來實現的時候是需要從JVM中獲取class類對象並操作類對象的。
首先,我們要了解反射的三個生命周期階段,這部分內容我在Java反射機制中也是做了非常詳細的說明,有興趣的小夥伴可以去看看我寫的Java反射機制,相信你在其中也會有所收穫。
這裏我再次強調一下這三個生命周期是源碼階段 – > class類對象階段 – > Runtime運行時階段。
那我們進入到源碼,看看@Retention註解中是否有這些參數。
我們看到該註解中的屬性只有一個value,而它的類型是一個RetentionPolicy類型,我們進入到該類型中看看有什麼參數,是否與表格中的參數相同呢?
image-20200606145449931
至於該註解怎麼使用,其實是相同的,用法如下:
這就證明了我們的註解可以保留到Runtime運行階段,而我們在反射中大多數是定義到Runtime運行時階段的,因為我們需要從JVM中獲取class類對象並操作類對象。
6.4 @Documented
@Documented 指定了被修飾的註解是可以Javadoc等工具文檔化
@Documented註解是比較好理解的,它是一個標記註解。被該標記註解標記的註解,生成doc文檔時,註解是可以被加載到文檔中显示的。
image-20200606152526551
還拿api中過時的Date中的方法來說,在api中显示Date中的getYear方法是這樣的。
正如你看到的,註解在api中显示了出來,證明該註解是@Documented註解修飾並文檔化的。那我們就看看這個註解是否被@Documented修飾吧。
然後,我們發現該註解的確是被文檔化了。所以在api中才會显示該註解的。如果不信,你可以自己使用javadoc命令來生成一下doc文檔,看看被該註解修飾的註解是否存在。
至於Javadoc文檔生成,我在javadoc文檔生成一文中有過詳細記載,大家可以進行參考,生成doc文檔查看。
6.5 @Inherited
@Inherited 指定了被修飾的註解修飾程序元素的時候是可以被子類繼承的
首先進入到源碼中,我們也可以清楚的知道,該註解也是一個標記註解。而且它也是被文檔化的註解。
其次,我們去在自定義註解中,標註上@Inherited註解。
演示@Inherited註解,我需要創建兩個類,同時兩個類中有一層的繼承關係。如下:
我們在Person類中標記了@MyAnno註解,由於該註解被@Inherited註解修飾,我們就可以得出繼承於Person類的Student類也同樣被@MyAnno註解標記了,如果你要獲取該註解的值的話,肯定獲取的也是父類上註解值的那個”1″。
七、使用反射機制解析註解
自定義註解
package com.mylifes1110.anno;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* @InterfaceName Sign
* @Description 描述需要執行的類名和方法名
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Sign {
String methodName();
String className();
}
Cat
package com.mylifes1110.java;
/**
* @ClassName Cat
* @Description 描述一隻貓的類
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
public class Cat {
/*
* @Description 描述一隻貓吃魚的方法
* @Author Ziph
* @Date 2020/6/6
* @Param []
* @return void
*/
public void eat() {
System.out.println("貓吃魚");
}
}
準備好,上述代碼后,我們就可以開始編寫使用反射技術來解析註解的測試類。如下:
首先,我們先通過反射來獲取註解中的methodName和className參數。
package com.mylifes1110.java;
import com.mylifes1110.anno.Sign;
/**
* @ClassName SignTest
* @Description 要求創建cat對象並執行其類中eat方法
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@Sign(className = "com.mylifes1110.java.Cat", methodName = "eat")
public class SignTest {
public static void main(String[] args) {
//獲取該類的類對象
Class<SignTest> signTestClass = SignTest.class;
//獲取類對象中的註解對象
//原理實際上是在內存中生成了一個註解接口的子類實現對象
Sign sign = signTestClass.getAnnotation(Sign.class);
//調用註解對象中定義的抽象方法(註解中的屬性)來獲取返回值
String className = sign.className();
String methodName = sign.methodName();
System.out.println(className);
System.out.println(methodName);
}
}
此時的打印結果證明我們已經成功獲取到了該註解的兩個參數。
image-20200606162810165
注意: 獲取類對象中的註解對象時,其原理實際上是在內存中生成了一個註解接口的子類實現對象並返回的字符串內容。如下:
public class SignImpl implements Sign {
public String methodName() {
return "eat";
}
public String className() {
return "com.mylifes1110.java.Cat";
}
}
繼續編寫我們後面的代碼,代碼完整版如下:
完整版代碼
package com.mylifes1110.java;
import com.mylifes1110.anno.Sign;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
/**
* @ClassName SignTest
* @Description 要求創建cat對象並執行其類中eat方法
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@Sign(className = "com.mylifes1110.java.Cat", methodName = "eat")
public class SignTest {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException, NoSuchMethodException, InvocationTargetException {
//獲取該類的類對象
Class<SignTest> signTestClass = SignTest.class;
//獲取類對象中的註解對象
//原理實際上是在內存中生成了一個註解接口的子類實現對象
Sign sign = signTestClass.getAnnotation(Sign.class);
//調用註解對象中定義的抽象方法(註解中的屬性)來獲取返回值
String className = sign.className();
String methodName = sign.methodName();
//獲取className名稱的類對象
Class<?> clazz = Class.forName(className);
//創建對象
Object o = clazz.newInstance();
//獲取methodName名稱的方法對象
Method method = clazz.getMethod(methodName);
//執行該方法
method.invoke(o);
}
}
執行結果
執行后成功的調用了eat方法,並打印了貓吃魚的結果,如下:
八、自定義註解改變JDBC工具類
首先,我們在使用JDBC的時候是需要通過properties文件來獲取配置JDBC的配置信息的,這次我們通過自定義註解來獲取配置信息。其實使用註解並沒有用配置文件好,但是我們需要了解這是怎麼做的,獲取方法也是魚使用反射機制解析註解,所謂“萬變不離其宗”,它就是這樣的。
自定義註解
package com.mylifes1110.java.anno;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* @InterfaceName DBInfo
* @Description 給予註解聲明周期為運行時並限定註解只能用在類上
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface DBInfo {
String driver() default "com.mysql.jdbc.Driver";
String url() default "jdbc:mysql://localhost:3306/temp?useUnicode=true&characterEncoding=utf8";
String username() default "root";
String password() default "123456";
}
數據庫連接工具類
為了代碼的健全我也在裏面加了properties文件獲取連接的方式。
package com.mylifes1110.java.utils;
import com.mylifes1110.java.anno.DBInfo;
import java.io.IOException;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
/**
* @ClassName DBUtils
* @Description 數據庫連接工具類
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@DBInfo()
public class DBUtils {
private static final Properties PROPERTIES = new Properties();
private static String driver;
private static String url;
private static String username;
private static String password;
static {
Class<DBUtils> dbUtilsClass = DBUtils.class;
boolean annotationPresent = dbUtilsClass.isAnnotationPresent(DBInfo.class);
if (annotationPresent) {
/**
* DBUilts類上有DBInfo註解,並獲取該註解
*/
DBInfo dbInfo = dbUtilsClass.getAnnotation(DBInfo.class);
// System.out.println(dbInfo);
driver = dbInfo.driver();
url = dbInfo.url();
username = dbInfo.username();
password = dbInfo.password();
} else {
InputStream inputStream = DBUtils.class.getResourceAsStream("db.properties");
try {
PROPERTIES.load(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static Connection getConnection() {
try {
return DriverManager.getConnection(url, username, password);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return null;
}
public static void closeAll(Connection connection, Statement statement, ResultSet resultSet) {
try {
if (resultSet != null) {
resultSet.close();
resultSet = null;
}
if (statement != null) {
statement.close();
statement = null;
}
if (connection != null) {
connection.close();
connection = null;
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
測試類
package com.mylifes1110.java.test;
import com.mylifes1110.java.utils.DBUtils;
import java.sql.Connection;
/**
* @ClassName GetConnectionDemo
* @Description 測試連接是否可以獲取到
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
public class GetConnectionDemo {
public static void main(String[] args) {
Connection connection = DBUtils.getConnection();
System.out.println(connection);
}
}
測試結果
為了證明獲取的連接是由註解的配置信息獲取到的連接,我將properties文件中的所有配置信息刪除后測試的。
九、自定義@MyTest註解實現單元測試
我不清楚小夥伴們是否了解,Junit單元測試。@Test是單元測試的測試方法上方修飾的註解。此註解的核心原理也是由反射來實現的。如果有小夥伴不知道什麼是單元測試或者對自定義@MyTest註解實現單元測試感興趣的話,可以點進來看看哦!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
※回頭車貨運收費標準