一 資源限制
1.1 pod資源限制
pod可以包括資源請求和資源限制:
- 資源請求
用於調度,並控制pod不能在計算資源少於指定數量的情況下運行。調度程序試圖找到一個具有足夠計算資源的節點來滿足pod請求。
- 資源限制
用於防止pod耗盡節點的所有計算資源,基於pod的節點配置Linux內核cgroups特性,以執行pod的資源限制。
儘管資源請求和資源限制是pod定義的一部分,但通常建議在dc中設置。OpenShift推薦的實踐規定,不應該單獨創建pod,而應該由dc創建。
1.2 應用配額
OCP可以執行跟蹤和限制兩種資源使用的配額:
對象的數量:Kubernetes資源的數量,如pod、service和route。
計算資源:物理或虛擬硬件資源的數量,如CPU、內存和存儲容量。
通過避免master的Etcd數據庫的無限制增長,對Kubernetes資源的數量設置配額有助於OpenShift master服務器的穩定性。對Kubernetes資源設置配額還可以避免耗盡其他有限的軟件資源,比如服務的IP地址。
同樣,對計算資源的數量施加配額可以避免耗盡OpenShift集群中單個節點的計算能力。還避免了一個應用程序使用所有集群容量,從而影響共享集群的其他應用程序。
OpenShift通過使用ResourceQuota對象或簡單的quota來管理對象使用的配額及計算資源。
ResourceQuota對象指定項目的硬資源使用限制。配額的所有屬性都是可選的,這意味着任何不受配額限制的資源都可以無限制地使用。
注意:一個項目可以包含多個ResourceQuota對象,其效果是累積的,但是對於同一個項目,兩個不同的 ResourceQuota 不會試圖限制相同類型的對象或計算資源。
1.3 ResourceQuota限制資源
下錶显示 ResourceQuota 可以限制的主要對象和計算資源:
Quota屬性可以跟蹤項目中所有pod的資源請求或資源限制。默認情況下,配額屬性跟蹤資源請求。要跟蹤資源限制,可以在計算資源名稱前面加上限制,例如limit.cpu。
示例一:使用YAML語法定義的ResourceQuota資源,它為對象計數和計算資源指定了配額:
1 $ cat 2 apiVersion: v1 3 kind: ResourceQuota 4 metadata: 5 name: dev-quota 6 spec: 7 hard: 8 services: "10" 9 cpu: "1300m" 10 memory: "1.5Gi" 11 $ oc create -f dev-quota.yml
示例二:使用oc create quota命令創建:
1 $ oc create quota dev-quota \ 2 --hard=services=10 \ 3 --hard=cpu=1300m \ 4 --hard=memory=1.5Gi 5 $ oc get resourcequota #列出可用的配額 6 $ oc describe resourcequota NAME #查看與配額中定義的任何與限制相關的統計信息 7 $ oc delete resourcequota compute-quota #按名稱刪除活動配額
提示:若oc describe resourcequota命令不帶參數,只显示項目中所有resourcequota對象的累積限制集,而不显示哪個對象定義了哪個限制。
當在項目中首次創建配額時,項目將限制創建任何可能超出配額約束的新資源的能力,然後重新計算資源使用情況。在創建配額和使用數據統計更新之後,項目接受新內容的創建。當創建新資源時,配額使用量立即增加。當一個資源被刪除時,在下一次對項目的 quota 統計數據進行全面重新計算時,配額使用將減少。
ResourceQuota 應用於整個項目,但許多 OpenShift 過程,例如 build 和 deployment,在項目中創建 pod,可能會失敗,因為啟動它們將超過項目 quota。
如果對項目的修改超過了對象數量的 quota,則服務器將拒絕操作,並向用戶返回錯誤消息。但如果修改超出了計算資源的quota,則操作不會立即失敗。OpenShift 將重試該操作幾次,使管理員有機會增加配額或執行糾正操作,比如上線新節點,擴容節點資源。
注意:如果設置了計算資源的 quota,OpenShift 拒絕創建不指定該計算資源的資源請求或資源限制的pod。
1.3 應用限制範圍
LimitRange資源,也稱為limit,定義了計算資源請求的默認值、最小值和最大值,以及項目中定義的單個pod或單個容器的限制,pod的資源請求或限制是其容器的總和。
要理解limit rang和resource quota之間的區別,limit rang為單個pod定義了有效範圍和默認值,而resource quota僅為項目中所有pod的和定義了最高值。
通常可同時定義項目的限制和配額。
LimitRange資源還可以為image、is或pvc的存儲容量定義默認值、最小值和最大值。如果添加到項目中的資源不提供計算資源請求,那麼它將接受項目的limit ranges提供的默認值。如果新資源提供的計算資源請求或限制小於項目的limit range指定的最小值,則不創建該資源。同樣,如果新資源提供的計算資源請求或限制高於項目的limit range所指定的最大值,則不會創建該資源。
OpenShift 提供的大多數標準 S2I builder image 和 templabe 都沒有指定。要使用受配額限制的 template 和 builder,項目需要包含一個 limit range 對象,該對象為容器資源請求指定默認值。
如下為描述了一些可以由LimitRange對象指定的計算資源。
示例一:limit rang的yaml示例:
1 $ cat dev-limits.yml 2 apiVersion: "v1" 3 kind: "LimitRange" 4 metadata: 5 name: "dev-limits" 6 spec: 7 limits: 8 - type: "Pod" 9 max: 10 cpu: "2" 11 memory: "1Gi" 12 min: 13 cpu: "200m" 14 memory: "6Mi" 15 - type: "Container" 16 default: 17 cpu: "1" 18 memory: "512Mi" 19 $ oc create -f dev-limits.yml 20 $ oc describe limitranges NAME #查看項目中強制執行的限制約束 21 $ oc get limits #查看項目中強制執行的限制約束 22 $ oc delete limitranges name #按名稱刪除活動的限制範圍
提示:OCP 3.9不支持使用oc create命令參數形式創建limit rang。
在項目中創建limit rang之後,將根據項目中的每個limit rang資源評估所有資源創建請求。如果新資源違反由任何limit rang設置的最小或最大約束,則拒絕該資源。如果新資源沒有聲明配置值,且約束支持默認值,則將默認值作為其使用值應用於新資源。
所有資源更新請求也將根據項目中的每個limit rang資源進行評估,如果更新后的資源違反了任何約束,則拒絕更新。
注意:避免將LimitRange設的過高,或ResourceQuota設的過低。違反LimitRange將阻止pod創建,並清晰保存。違反ResourceQuota將阻止pod被調度,狀態轉為pending。
1.4 多項目quota配額
ClusterResourceQuota資源是在集群級別創建的,創建方式類似持久卷,並指定應用於多個項目的資源約束。
可以通過以下兩種方式指定哪些項目受集群資源配額限制:
- 使用openshift.io/requester標記,定義項目所有者,該所有者的所有項目均應用quota;
- 使用selector,匹配該selector的項目將應用quota。
示例1:
1 $ oc create clusterquota user-qa \ 2 --project-annotation-selector openshift.io/requester=qa \ 3 --hard pods=12 \ 4 --hard secrets=20 #為qa用戶擁有的所有項目創建集群資源配額 5 $ oc create clusterquota env-qa \ 6 --project-label-selector environment=qa \ 7 --hard pods=10 \ 8 --hard services=5 #為所有具有environment=qa標籤的項目創建集群資源配額 9 $ oc describe QUOTA NAME #查看應用於當前項目的集群資源配額 10 $ oc delete clusterquota NAME #刪除集群資源配額
提示:不建議使用一個集群資源配額來匹配超過100個項目。這是為了避免較大的locking開銷。當創建或更新項目中的資源時,在搜索所有適用的資源配額時鎖定項目需要較大的資源消耗。
二 限制資源使用
2.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
2.2 本練習準備
1 [student@workstation ~]$ lab monitor-limit setup
2.3 查看當前資源
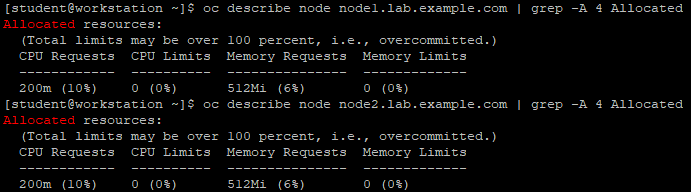
1 [student@workstation ~]$ oc login -u admin -p redhat https://master.lab.example.com 2 [student@workstation ~]$ oc describe node node1.lab.example.com | grep -A 4 Allocated 3 [student@workstation ~]$ oc describe node node2.lab.example.com | grep -A 4 Allocated
2.4 創建應用
1 [student@workstation ~]$ oc new-project resources 2 [student@workstation ~]$ oc new-app --name=hello \ 3 --docker-image=registry.lab.example.com/openshift/hello-openshift 4 [student@workstation ~]$ oc get pod -o wide 5 NAME READY STATUS RESTARTS AGE IP NODE 6 hello-1-znk56 1/1 Running 0 24s 10.128.0.16 node1.lab.example.com
2.5 刪除應用
1 [student@workstation ~]$ oc delete all -l app=hello
2.6 添加資源限制
作為集群管理員,向項目quota和limit range,以便為項目中的pod提供默認資源請求。
1 [student@workstation ~]$ cd /home/student/DO280/labs/monitor-limit/ 2 [student@workstation monitor-limit]$ cat limits.yml #創建limit range 3 apiVersion: "v1" 4 kind: "LimitRange" 5 metadata: 6 name: "project-limits" 7 spec: 8 limits: 9 - type: "Container" 10 default: 11 cpu: "250m 12 [student@workstation monitor-limit]$ oc create -f limits.yml #創建limit range 13 [student@workstation monitor-limit]$ oc describe limitrange #查看limit range
1 [student@workstation monitor-limit]$ cat quota.yml #創建配額 2 apiVersion: v1 3 kind: ResourceQuota 4 metadata: 5 name: project-quota 6 spec: 7 hard: 8 cpu: "900m" 9 [student@workstation monitor-limit]$ oc create -f quota.yml 10 [student@workstation monitor-limit]$ oc describe quota #確保創建了resource限制
2.7 授權項目
1 [student@workstation monitor-limit]$ oc adm policy add-role-to-user edit developer
2.8 驗證資源限制
1 [student@workstation ~]$ oc login -u developer -p redhat https://master.lab.example.com 2 [student@workstation ~]$ oc project resources #選擇項目 3 Already on project "resources" on server "https://master.lab.example.com:443". 4 [student@workstation ~]$ oc get limits #查看limit 5 NAME AGE 6 project-limits 14m 7 [student@workstation ~]$ oc delete limits project-limits #驗證限制是否有效,但developer用戶不能刪除該限制 8 Error from server (Forbidden): limitranges "project-limits" is forbidden: User "developer" cannot delete limitranges in the namespace "resources": User "developer" cannot delete limitranges in project "resources" 9 [student@workstation ~]$ oc get quota 10 NAME AGE 11 project-quota 15m
2.9 創建應用
1 [student@workstation ~]$ oc new-app --name=hello \ 2 --docker-image=registry.lab.example.com/openshift/hello-openshift 3 [student@workstation ~]$ oc get pod 4 NAME READY STATUS RESTARTS AGE 5 hello-1-t7tfn 1/1 Running 0 35s
2.10 查看quota
1 [student@workstation ~]$ oc describe quota 2 Name: project-quota 3 Namespace: resources 4 Resource Used Hard 5 -------- ---- ---- 6 cpu 250m 900m
2.11 查看節點可用資源
1 [student@workstation ~]$ oc login -u admin -p redhat \ 2 https://master.lab.example.com 3 [student@workstation ~]$ oc get pod -o wide -n resources 4 [student@workstation ~]$ oc describe node node1.lab.example.com | grep -A 4 Allocated 5 [student@workstation ~]$ oc describe pod hello-1-t7tfn | grep -A2 Requests
2.12 擴容應用
1 [student@workstation ~]$ oc scale dc hello --replicas=2 #擴容應用 2 [student@workstation ~]$ oc get pod #查看擴容后的pod 3 [student@workstation ~]$ oc describe quota #查看擴容后的quota情況 4 [student@workstation ~]$ oc scale dc hello --replicas=4 #繼續擴容至4個 5 [student@workstation ~]$ oc get pod #查看擴容的pod 6 [student@workstation ~]$ oc describe dc hello | grep Replicas #查看replaces情況
結論:由於超過了配額規定,會提示控制器無法創建第四個pod。
2.13 添加配額請求
1 [student@workstation ~]$ oc scale dc hello --replicas=1 2 [student@workstation ~]$ oc get pod 3 [student@workstation ~]$ oc set resources dc hello --requests=memory=256Mi #設置資源請求 4 [student@workstation ~]$ oc get pod 5 [student@workstation ~]$ oc describe pod hello-2-4jvpw | grep -A 3 Requests 6 [student@workstation ~]$ oc describe quota #查看quota
結論:由上可知從項目的配額角度來看,沒有什麼變化。
2.14 增大配額請求
1 [student@workstation ~]$ oc set resources dc hello --requests=memory=8Gi #將內存請求增大到超過node最大值 2 [student@workstation ~]$ oc get pod #查看pod 3 [student@workstation ~]$ oc logs hello-3-deploy #查看log 4 [student@workstation ~]$ oc status
結論:由於資源請求超過node最大值,最終显示一個警告,說明由於內存不足,無法將pod調度到任何節點。
三 OCP升級
3.1 升級OPENSHIFT
當OCP的新版本發布時,可以升級現有集群,以應用最新的增強功能和bug修復。這包括從以前的次要版本(如從3.7升級到3.9)升級,以及對次要版本(3.7)應用更新。
提示:OCP 3.9包含了Kubernetes 1.8和1.9的特性和補丁的合併。由於主要版本之間的核心架構變化,OpenShift Enterprise 2環境無法升級為OpenShift容器平台3,必須需要重新安裝。
通常,主版本中不同子版本的node是向前和向後兼容的。但是,運行不匹配的版本的時間不應超過升級整個集群所需的時間。此外,不支持使用quick installer將版本3.7升級到3.9。
3.2 升級方式
有兩種方法可以執行OpenShift容器平台集群升級,一種為in-place升級(可以自動升級或手動升級),也可以使用blue-green部署方法進行升級。
in-place升級:使用此方式,集群升級將在單個運行的集群中的所有主機上執行。首先升級master,然後升級node。在node升級開始之前,Pods被遷移到集群中的其他節點。這有助於減少用戶應用程序的停機時間。
注意:對於使用quick和高級安裝方法安裝的集群,可以使用自動in-place方式升級。
當使用高級安裝方法安裝集群時,您可以通過重用它們的庫存文件執行自動化或手動就地升級。
blue-green部署:blue-green部署是一種旨在減少停機時間同時升級環境的方法。在blue-green部署中,相同的環境與一個活動環境一起運行,而另一個環境則被更新。OpenShift升級方法標記了不可調度節點,並將pod調度到可用節點。升級成功后,節點將恢復到可調度狀態。
3.3 執行自動化集群升級
使用高級安裝方法,可以使用Ansible playbook自動化執行OpenShift集群升級過程。用於升級的劇本位於/usr/share/ansible/openshift-ansible/Playbooks/common/openshift-cluster/updates/中。該目錄包含一組用於升級集群的子目錄,例如v3_9。
注意:將集群升級到 OCP 3.9 前,集群必須已經升級到 3.7。集群升級一次不能跨越一個以上的次要版本,因此,如果集群的版本早於3.6,則必須先漸進地升級,例如從3.5升級到3.6,然後從3.6升級到3.7
要執行升級,可以使用ansible-playbook命令運行升級劇本,如使用v3_9 playbook將運行3.7版本的現有OpenShift集群升級到3.9版本。
自動升級主要執行以下任務:
- 應用最新的配置更改;
- 保存Etcd數據;
- 將api從3.7更新到3.8,然後從3.8更新到3.9;
- 如果存在,將默認路由器從3.7更新到3.9;
- 如果存在,則將默認倉庫從3.7更新到3.9;
- 更新默認is和Templates。
注意:在繼續升級之前,確保已經滿足了所有先決條件,否則可能導致升級失敗。
如果使用容器化的GlusterFS,節點將不會從pod中撤離,因為GlusterFS pod作為daemonset的一部分運行。要正確地升級運行容器化GlusterFS的集群,需要:
1:升級master服務器、Etcd和基礎設施服務(route、內部倉庫、日誌記錄和metric)。
2:升級運行應用程序容器的節點。
3:一次升級一個運行GlusterFS的節點。
注意:在升級之前,使用oc adm diagnostics命令驗證集群的健康狀況。這確認節點處於ready狀態,運行預期的啟動版本,並且沒有診斷錯誤或警告。對於離線安裝,使用–network-pod-image=’REGISTRY URL/ IMAGE參數指定要使用的image。
3.4 準備自動升級
下面的過程展示了如何為自動升級準備環境,在執行升級之前,Red Hat建議檢查配置Inventory文件,以確保對Inventory文件進行了手動更新。如果配置沒有修改,則使用默認值覆蓋更改。
- 如果這是從OCP 3.7升級到3.9,手動禁用3.7存儲庫,並在每個master節點和node節點上啟用3.8和3.9存儲庫:
1 [root@demo ~]# subscription-manager repos \ 2 --disable="rhel-7-server-ose-3.7-rpms" \ 3 --enable="rhel-7-server-ose-3.9-rpms" \ 4 --enable="rhel-7-server-ose-3.8-rpms" \ 5 --enable="rhel-7-server-rpms" \ 6 --enable="rhel-7-server-extras-rpms" \ 7 --enable="rhel-7-server-ansible-2.4-rpms" \ 8 --enable="rhel-7-fast-datapath-rpms" 9 [root@demo ~]# yum clean all
- 確保在每個RHEL 7系統上都有最新版本的atom-openshift-utils包,它還更新openshift-ansible-*包。
1 [root@demo ~]# yum update atomic-openshift-utils
- 在OpenShift容器平台的以前版本中,安裝程序默認將master節點標記為不可調度,但是,從OCP 3.9開始,master節點必須標記為可調度的,這是在升級過程中自動完成的。
如果沒有設置默認的節點選擇器(如下配置),它們將在升級過程中添加。則master節點也將被標記為master節點角色。所有其他節點都將標記為compute node角色。
1 openshift_node_labels="{'region':'infra', 'node-role.kubernetes.io/compute':'true'}
- 如果將openshift_disable_swap=false變量添加到的Ansible目錄中,或者在node上手動配置swap,那麼在運行升級之前禁用swap內存。
3.5 升級master節點和node節點
在滿足了先決條件(如準備工作)之後,則可以按照如下步驟進行升級:
- 在清單文件中設置openshift_deployment_type=openshift-enterprise變量。
- 如果使用自定義Docker倉庫,則必須顯式地將倉庫的地址指定為openshift_web_console_prefix和template_service_broker_prefix變量。這些值由Ansible在升級過程中使用。
1 openshift_web_console_prefix=registry.demo.example.com/openshift3/ose- 2 template_service_broker_prefix=registry.demo.example.com/openshift3/ose-
- 如果希望重啟service或重啟node,請在Inventory文件中設置openshift_rolling_restart_mode=system選項。如果未設置該選項,則默認值表明升級過程在master節點上執行service重啟,但不重啟系統。
- 可以通過運行一個Ansible Playbook (upgrade.yml)來更新環境中的所有節點,也可以通過使用單獨的Playbook分多個階段進行升級。
- 重新啟動所有主機,重啟之後,如果沒有部署任何額外的功能,可以驗證升級。
3.6 分階段升級集群
如果決定分多個階段升級環境,根據Ansible Playbook (upgrade_control_plan .yml)確定的第一個階段,升級以下組件:
- master節點;
- 運行master節點的節點services;
- Docker服務位於master節點和任何獨立Etcd主機上。
第二階段由upgrade_nodes.yml playbook,升級了以下組件。在運行此第二階段之前,必須已經升級了master節點。
- node節點的服務;
- 運行在獨立節點上的Docker服務。
兩個階段的升級過程允許通過指定自定義變量自定義升級的運行方式。例如,要升級總節點的50%,可以運行以下命令:
1 [root@demo ~]# ansible-playbook \ 2 /usr/share/ansible/openshift-ansible/playbooks/common/openshift-cluster/upgrades/ 3 v3_9/upgrade_nodes.yml \ 4 -e openshift_upgrade_nodes_serial="50%"
若要在HA region一次升級兩個節點,請運行以下命令:
1 [root@demo ~]# ansible-playbook \ 2 /usr/share/ansible/openshift-ansible/playbooks/common/openshift-cluster/upgrades/ 3 v3_9/upgrade_nodes.yml \ 4 -e openshift_upgrade_nodes_serial="2" 5 -e openshift_upgrade_nodes_label="region=HA"
要指定每個更新批處理中允許有多少節點失敗,可使用openshift_upgrade_nodes_max_fail_percent選項。當故障百分比超過定義的值時,Ansible將中止升級。
使用openshift_upgrade_nodes_drain_timeout選項指定中止play前等待的時間。
示例:如下所示一次升級10個節點,以及如果20%以上的節點(兩個節點)失敗,以及終止play執行的等待時間。
1 [root@demo ~]# ansible-playbook \ 2 /usr/share/ansible/openshift-ansible/playbooks/common/openshift-cluster/upgrades/ 3 v3_9/upgrade_nodes.yml \ 4 -e openshift_upgrade_nodes_serial=10 \ 5 -e openshift_upgrade_nodes_max_fail_percentage=20 \ 6 -e openshift_upgrade_nodes_drain_timeout=600
3.7 使用Ansible Hooks
可以通過hook為特定的操作執行定製的任務。hook允許通過定義在升級過程中特定點之前或之後執行的任務來擴展升級過程的默認行為。例如,可以在升級集群時驗證或更新自定義基礎設施組件。
提示:hook沒有任何錯誤處理機制,因此,hook中的任何錯誤都會中斷升級過程。需要修復hook並重新運行升級過程。
使用Inventory文件的[OSEv3:vars]部分來定義hook。每個hook必須指向一個.yaml文件,該文件定義了可能的任務。該文件是作為include語句的一部分集成的,該語句要求定義一組任務,而不是一個劇本。Red Hat建議使用絕對路徑來避免任何歧義。
以下hook可用於定製升級過程:
1. openshift_master_upgrade_pre_hook:hook在更新每個master節點之前運行。
2. openshift_master_upgrade_hook:hook在每個master節點升級之後、主服務或節點重新啟動之前運行。
3.openshift_master_upgrade_post_hook:hook在每個master節點升級並重啟服務或系統之後運行。
示例:在庫存文件中集成一個鈎子。
1 [OSEv3:vars] 2 openshift_master_upgrade_pre_hook=/usr/share/custom/pre_master.yml 3 openshift_master_upgrade_hook=/usr/share/custom/master.yml 4 openshift_master_upgrade_post_hook=/usr/share/custom/post_master.yml
如上示例,引入了一個pre_master.yml,包括了以下任務:
1 --- 2 - name: note the start of a master upgrade 3 debug: 4 msg: "Master upgrade of {{ inventory_hostname }} is about to start" 5 - name: require an operator agree to start an upgrade pause: 6 prompt: "Hit enter to start the master upgrade"
3.8 驗證升級
升級完成后,應該執行以下步驟以確保升級成功。
1 [root@demo ~]# oc get nodes #驗證node處於ready 2 [root@demo ~]# oc get -n default dc/docker-registry -o json | grep \"image\" 3 #驗證倉庫版本 4 [root@demo ~]# oc get -n default dc/router -o json | grep \"image\ 5 #驗證image版本 6 [root@demo ~]# oc adm diagnostics #使用診斷工具
3.9 升級步驟匯總
- 確保在每個RHEL 7系統上都有atom-openshift-utils包的最新版本。
- 如果使用自定義Docker倉庫,可以選擇將倉庫的地址指定為openshift_web_console_prefix和template_service_broker_prefix變量。
- 禁用所有節點上的swap。
- 重新啟動所有主機,重啟之後,檢查升級。
- 可選地:檢查Inventory文件中的節點選擇器。
- 禁用3.7存儲庫,並在每個master主機和node節點主機上啟用3.8和3.9存儲庫。
- 通過使用合適的Ansible劇本集,使用單個或多個階段策略進行更新。
- 在清單文件中設置openshift_deployment_type=openshift-enterprise變量。
四 使用probes監視應用
4.1 OPENSHIFT探針介紹
OpenShift應用程序可能會因為臨時連接丟失、配置錯誤或應用程序錯誤等問題而異常。開發人員可以使用探針來監視他們的應用程序。探針是一種Kubernetes操作,它定期對正在運行的容器執行診斷。可以使用oc客戶端命令或OpenShift web控制台配置探針。
目前,可以使用兩種類型的探測:
- Liveness探針
Liveness探針確定在容器中運行的應用程序是否處於健康狀態。如果Liveness探針返回檢測到一個不健康的狀態,OpenShift將殺死pod並試圖重新部署它。開發人員可以通過配置template.spec.container.livenessprobe來設置Liveness探針。
- Readiness探針
Readiness探針確定容器是否準備好為請求服務,如果Readiness探針返回失敗狀態,OpenShift將從所有服務的端點刪除容器的IP地址。開發人員可以使用Readiness探針向OpenShift發出信號,即使容器正在運行,它也不應該從代理接收任何流量。開發人員可以通過配置template.spec.containers.readinessprobe來設置Readiness探針。
OpenShift為探測提供了許多超時選項,有五個選項控制支持如上兩個探針:
initialDelaySeconds:強制性的。確定容器啟動后,在開始探測之前要等待多長時間。
timeoutSeconds:強制性的確定等待探測完成所需的時間。如果超過這個時間,OpenShift容器平台會認為探測失敗。
periodSeconds:可選的,指定檢查的頻率。
successThreshold:可選的,指定探測失敗后被認為成功的最小連續成功數。
failureThreshold:可選的,指定探測器成功后被認為失敗的最小連續故障。
4.2 檢查應用程序健康
Readiness和liveness probes可以通過三種方式檢查應用程序的健康狀況:
HTTP檢查:當使用HTTP檢查時,OpenShift使用一個webhook來確定容器的健康狀況。如果HTTP響應代碼在200到399之間,則認為檢查成功。
示例:演示如何使用HTTP檢查方法實現readiness probe 。
1 ... 2 readinessProbe: 3 httpGet: 4 path: /health #檢測的URL 5 port: 8080 #端口 6 initialDelaySeconds: 15 #在容器啟動后多久才能檢查其健康狀況 7 timeoutSeconds: 1 #要等多久探測器才能完成 8 ...
4.3 容器執行檢查
當使用容器執行檢查時,kubelet agent在容器內執行命令。退出狀態為0的檢查被認為是成功的。
示例:實現容器檢查。
1 ... 2 livenessProbe: 3 exec: 4 command: 5 - cat 6 - /tmp/health 7 initialDelaySeconds: 15 8 timeoutSeconds: 1 9 ...
4.4 TCP Socket檢查
當使用TCP Socket檢查時,kubelet agent嘗試打開容器的socket。如果檢查能夠建立連接,則認為容器是健康的。
示例:使用TCP套接字檢查方法實現活動探測。
1 ... 2 livenessProbe: 3 tcpSocket: 4 port: 8080 5 initialDelaySeconds: 15 6 timeoutSeconds: 1 7 ...
4.5 使用Web管理probes
開發人員可以使用OpenShift web控制台管理readiness和liveness探針。對於每個部署,探針管理都可以從Actions下拉列表中獲得。
對於每種探針類型,開發人員可以選擇該類型,例如HTTP GET、TCP套接字或命令,併為每種類型指定參數。web控制台還提供了刪除探針的選項。
web控制台還可以用於編輯定義部署配置的YAML文件。在創建探針之後,將一個新條目添加到DC的配置文件中。使用DC編輯器來檢查或編輯探針。實時編輯器允許編輯周期秒、成功閾值和失敗閾值選項。
五 使用探針監視應用程序實驗
5.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
5.2 本練習準備
1 [student@workstation ~]$ lab probes setup
5.3 創建應用
1 [student@workstation ~]$ oc login -u developer -p redhat \ 2 https://master.lab.example.com 3 [student@workstation ~]$ oc new-project probes 4 [student@workstation ~]$ oc new-app --name=probes \ 5 http://services.lab.example.com/node-hello 6 [student@workstation ~]$ oc status
1 [student@workstation ~]$ oc get pods -w 2 NAME READY STATUS RESTARTS AGE 3 probes-1-build 0/1 Completed 0 1m 4 probes-1-nqpwh 1/1 Running 0 12s
5.4 暴露服務
1 [student@workstation ~]$ oc expose svc probes --hostname=probe.apps.lab.example.com 2 [student@workstation ~]$ curl http://probe.apps.lab.example.com 3 Hi! I am running on host -> probes-1-nqpwh
5.5 檢查服務
1 [student@workstation ~]$ curl http://probe.apps.lab.example.com/health 2 OK 3 [student@workstation ~]$ curl http://probe.apps.lab.example.com/ready 4 READY
5.6 創建readiness探針
使用Web控制台登錄。並創建readiness探針。
Add readiness probe
參考5.5存在的用於檢查健康的鏈接添加probe。
5.7 創建Liveness探針
使用Web控制台登錄。並創建Liveness探針。
參考5.5存在的用於檢查健康,特意使用healtz錯誤的值而不是health創建,從而測試相關報錯。這個錯誤將導致OpenShift認為pod不健康,這將觸發pod的重新部署。
提示:由於探針更新了部署配置,因此更改將觸發一個新的部署。
5.8 確認探測
通過單擊側欄上的Monitoring查看探測的實現。觀察事件面板的實時更新。此時將標記為不健康的條目,這表明liveness探針無法訪問/healtz資源。
view details查看詳情。
[student@workstation ~]$ oc get events –sort-by=’.metadata.creationTimestamp’ | grep ‘probe failed’ #查看probe失敗事件
5.9 修正probe
修正healtz為health。
5.10 再次確認
1 [student@workstation ~]$ oc get events \ 2 --sort-by='.metadata.creationTimestamp'
#從終端重新運行oc get events命令,此時OpenShift在重新部署DC新版本,以及殺死舊pod。同時將不會有任何關於pod不健康的信息。
六 Web控制台使用
6.1 WEB控制台簡介
OpenShift web控制台是一個可以從web瀏覽器訪問的用戶界面。它是管理和監視應用程序的一種方便的方法。儘管命令行界面可以用於管理應用程序的生命周期,但是web控制台提供了額外的優勢,比如部署、pod、服務和其他資源的狀態,以及
關於系統範圍內事件的信息。
可使用Web查看基礎設施內的重要信息,包括:
- pod各種狀態;
- volume的可用性;
- 通過使用probes獲得應用程序的健康行;
登錄並選擇項目之後,web控制台將提供項目項目的概述。
- 項目允許在授權訪問的項目之間切換。
- Search Catalog:瀏覽image目錄。
- Add to project:向項目添加新的資源和應用程序。可以從文件或現有項目導入資源。
- Overview:提供當前項目的高級視圖。它显示service的名稱及其在項目中運行的相關pod。
- Applications:提供對部署、pod、服務和路由的訪問。它還提供了對Stateful set的訪問,Kubernetes hat特性為pod提供了一個惟一的標識,用於管理部署的順序。
- build:提供對構建和IS的訪問。
- Resources:提供對配額管理和各種資源(如角色和端點)的訪問。
- Storage:提供對持久卷和存儲請求的訪問。
- Monitoring選項卡提供對構建、部署和pod日誌的訪問。它還提供了對項目中各種對象的事件通知的訪問。
- Catalog選項卡提供對可用於部署應用程序包的模板的訪問。
6.2 使用HAWKULAR管理指標
Hawkular是一組用於監控環境的開源項目。它由各種組件組成,如Hawkular services、Hawkular Application Performance Management (APM)和Hawkular metrics。Hawkular可以通過Hawkular OpenShift代理在OpenShift集群中收集應用程序指標。通過在OpenShift集群中部署Hawkular,可以訪問各種指標,比如pod使用的內存、cpu數量和網絡使用情況。
在部署了Hawkular代理之後,web控制台可以查看各種pod的圖表了。
6.3 管理Deployments和Pods
·Actions按鈕可用於pod和部署,允許管理各種設置。例如,可以向部署添加存儲或健康檢查(包括準備就緒和活動探測)。該按鈕還允許訪問YAML編輯器,以便通過web控制台實時更新配置。
6.4 管理存儲
web控制台允許訪問存儲管理,可以使用該接口創建卷聲明,以使用向項目公開的卷。注意,該接口不能用於創建持久卷,因為只有管理員才能執行此任務。管理員創建持久性卷之後,可以使用web控制台創建請求。該接口支持使用選擇器和標籤屬性。
定義卷聲明之後,控制台將显示它所使用的持久性卷,這是由管理員定義的。、
七 Web控制台監控指標
7.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
同時安裝OpenShift Metrics,參考《008.OpenShift Metric應用》3.1
7.2 本練習準備
1 [student@workstation ~]$ lab web-console setup
7.3 創建項目
1 [student@workstation ~]$ oc login -u developer -p redhat \ 2 https://master.lab.example.com 3 [student@workstation ~]$ oc new-project load 4 [student@workstation ~]$ oc new-app --name=load http://services.lab.example.com/node-hello
7.4 ·暴露服務
1 [student@workstation ~]$ oc expose svc load 2 [student@workstation ~]$ oc get pod 3 NAME READY STATUS RESTARTS AGE 4 load-1-build 1/1 Running 0 48s
7.5 壓力測試
1 [student@workstation ~]$ sudo yum install httpd-tools 2 [student@workstation ~]$ ab -n 3000000 -c 20 \ 3 http://load-load.apps.lab.example.com/
7.6 控制台擴容pod
workstation節點上登錄控制填,並擴展應用。
查看概覽頁面,確保有一個pod在運行。單擊部署配置load #1,所显示的第一個圖,它對應於pod使用的內存。並指示pod使用了多少內存,突出显示第二張圖,該圖表示pods使用的cpu數量。突出显示第三個圖,它表示pod的網絡流量。
單擊pod視圖圈旁的向上指向的箭頭,將此應用程序的pod數量增加到兩個。
導航到應用程序→部署以訪問項目的部署
注意右側的Actions按鈕,單擊它並選擇Edit YAML來編輯部署配置。
檢查部署的YAML文件,確保replicas條目的值為2,該值與為該部署運行的pod的數量相匹配。
7.7 查看metric
單擊Metrics選項卡訪問項目的度量,可以看到應用程序的四個圖:使用的內存數量、使用的cpu數量、接收的網絡數據包數量和發送的網絡數據包數量。對於每個圖,有兩個圖,每個圖被分配到一個pod。
7.8 查看web控制監視
在側窗格中,單擊Monitoring以訪問Monitoring頁面。Pods部分下應該有兩個條目,deployment部分下應該有一個條目。
向下滾動以訪問部署,並單擊部署名稱旁邊的箭頭以打開框架。日誌下面應該有三個圖表:一個表示pod使用的內存數量,一個表示pod使用的cpu數量,一個表示pod發送和接收的網絡數據包。
7.9 創建PV
為應用程序創建PVC,此練習環境已經提供了聲明將綁定到的持久卷。
單擊Storage創建持久卷聲明,單擊Create Storage來定義聲明。輸入web-storage作為名稱。選擇Shared Access (RWX)作為訪問模式。輸入1作為大小,並將單元保留為GiB
單擊Create創建持久卷聲明。
7.10 嚮應用程序添加存儲
導航到應用程序——>部署來管理部署,單擊load條目以訪問部署。單擊部署的Actions,然後選擇Add Storage選項。此選項允許將現有的持久卷聲明添加到部署配置的模板中。選擇web-storage作為存儲聲明,輸入/web-storage作為掛載路徑,web-storage作為卷名。
7.11 檢查存儲
從deployment頁面中,單擊由(latest)指示的最新部署。等待兩個副本被標記為活動的。確保卷部分將卷web存儲作為持久卷。從底部的Pods部分中,選擇一個正在運行的Pods。單擊Terminal選項卡打開pod的外殼。
也可在任何一個pod中運行如下命令查看:
八 管理和監控OpenShift
8.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
8.2 本練習準備
1 [student@workstation ~]$ lab review-monitor setup
8.3 創建項目
1 [student@workstation ~]$ oc login -u developer -p redhat https://master.lab.example.com、 2 [student@workstation ~]$ oc new-project load-review
8.4 創建limit range
1 [student@workstation ~]$ oc login -u admin -p redhat 2 [student@workstation ~]$ oc project load-review 3 [student@workstation ~]$ cat /home/student/DO280/labs/monitor-review/limits.yml 4 apiVersion: "v1" 5 kind: "LimitRange" 6 metadata: 7 name: "review-limits" 8 spec: 9 limits: 10 - type: "Container" 11 max: 12 memory: "300Mi" 13 default: 14 memory: "200Mi" 15 [student@workstation ~]$ oc create -f /home/student/DO280/labs/monitor-review/limits.yml 16 [student@workstation ~]$ oc describe limitrange 17 Name: review-limits 18 Namespace: load-review 19 Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio 20 ---- -------- --- --- --------------- ------------- ----------------------- 21 Container memory - 300Mi 200Mi 200Mi -
8.5 創建應用
1 [student@workstation ~]$ oc login -u developer -p redhat 2 [student@workstation ~]$ oc new-app --name=load http://services.lab.example.com/node-hello 3 [student@workstation ~]$ oc get pods 4 NAME READY STATUS RESTARTS AGE 5 load-1-6szhm 1/1 Running 0 6s 6 load-1-build 0/1 Completed 0 43s 7 [student@workstation ~]$ oc describe pod load-1-6szhm
8.6 擴大資源請求
1 [student@workstation ~]$ oc set resources dc load --requests=memory=350M 2 [student@workstation ~]$ oc get events | grep Warning
結論:請求資源超過limit限制,則會出現如上告警。
1 [student@workstation ~]$ oc set resources dc load --requests=memory=200Mi
8.7 創建ResourceQuota
1 [student@workstation ~]$ oc status ; oc get pod
1 [student@workstation ~]$ oc login -u admin -p redhat 2 [student@workstation ~]$ cat /home/student/DO280/labs/monitor-review/quotas.yml 3 apiVersion: "v1" 4 kind: "LimitRange" 5 metadata: 6 name: "review-limits" 7 spec: 8 limits: 9 - type: "Container" 10 max: 11 memory: "300Mi" 12 default: 13 memory: "200Mi" 14 [student@workstation ~]$ oc create -f /home/student/DO280/labs/monitor-review/quotas.yml 15 [student@workstation ~]$ oc describe quota 16 Name: review-quotas 17 Namespace: load-review 18 Resource Used Hard 19 -------- ---- ---- 20 requests.memory 200M 600Mi -
8.8 創建應用
1 [student@workstation ~]$ oc login -u developer -p redhat 2 [student@workstation ~]$ oc scale --replicas=4 dc load 3 [student@workstation ~]$ oc get pods 4 NAME READY STATUS RESTARTS AGE 5 load-1-build 0/1 Completed 0 7m 6 load-3-577fc 1/1 Running 0 5s 7 load-3-nnncf 1/1 Running 0 4m 8 load-3-nps4w 1/1 Running 0 5s 9 [student@workstation ~]$ oc get events | grep Warning
結論:當前已應用配額規定會阻止創建第四個pod。
1 [student@workstation ~]$ oc scale --replicas=1 dc load
8.9 暴露服務
1 [student@workstation ~]$ oc expose svc load --hostname=load-review.apps.lab.example.com
8.10 創建探針
Web控制台創建。
Applications ——> Deployments ——> Actions ——> Edit Health Checks。
9.11 確認驗證
導航到Applications ——> Deployments,選擇應用程序的最新部署。
在Template部分中,找到以下條目:
1 [student@workstation ~]$ lab review-monitor grade #腳本判斷結果 2
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準