一、什麼是堆?
維基百科的解釋是:堆是一種特別的樹狀數據結構,它需要滿足任意的子節點必須都大於等於(最大堆)或者小於等於(最小堆)其父節點。
二、堆排序
堆排序是通過二叉堆數據結構實現,二叉堆滿足一下兩個特性:
1、滿足對的基本特性
2、完全二叉樹,除了最底層外,其它層都已填充滿,且是從左到右填充。
二叉堆的高度即為根節點到恭弘=叶 恭弘子節點的最長簡單路徑長度,即為θ(lgn)。
二叉堆上的操作時間複雜度為O(lgn)。
1、二叉堆中的元素個數
根據二叉堆的特性2,我們知道高度為h的二叉堆重元素個數如下:
根節點為1
第一層為2=21
第二層為4=22
…
第h-1層為2h-1
第h層元素個數範圍為[1,2h]
最底層之外的元素個數和為1+2+22+…+2h-1=(1-2h-1)/(1-2)=2h-1
高度為h的二叉堆元素個數範圍:[2h-1 + 1,2h-1+2h]=[2h,2h+1-1]
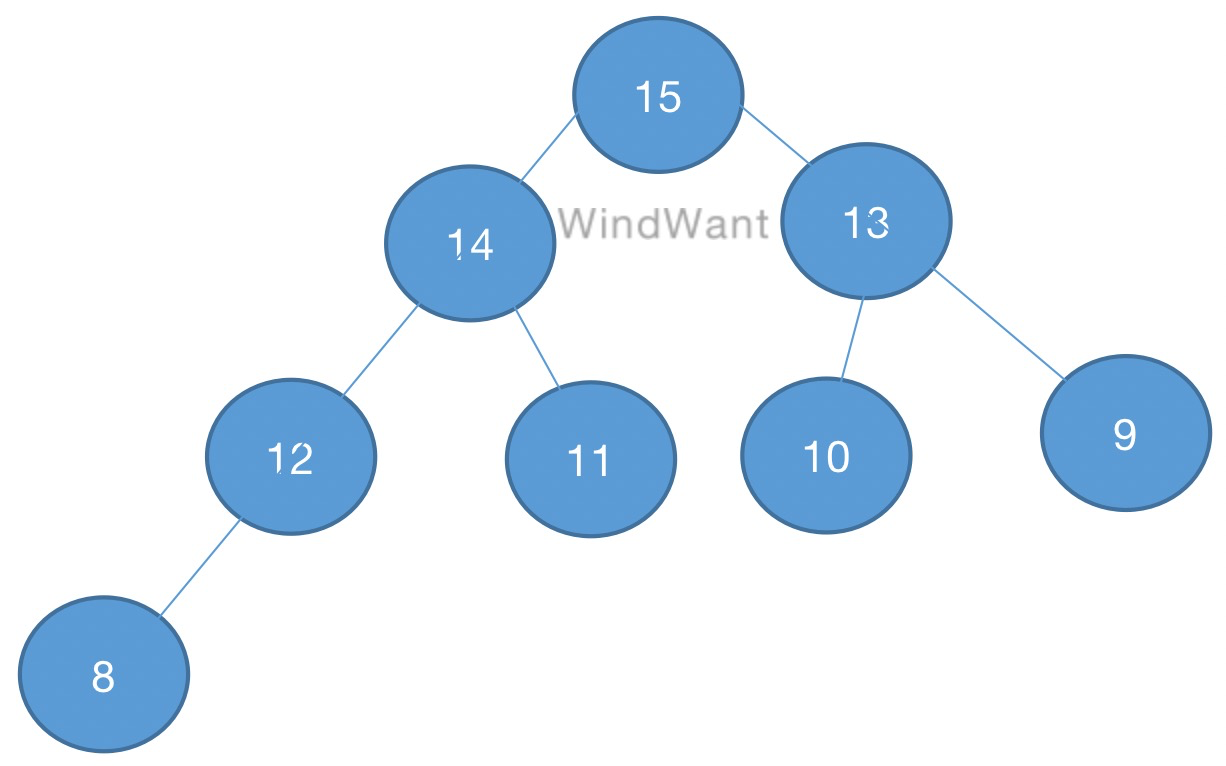
以高度為3的最大堆為例:
圖1
圖2
2、二叉堆的高度
由二.1推導,我們知道高度為h的二叉堆的元素個數n滿足:
2h ≦ n ≦ 2h+1-1
=>
2h ≦ 2lgn ≦ 2h+1-1
=>
h ≦ lgn < h+1
由此可得,含有n個元素的二叉堆的高度為θ(lgn)
3、使用數組表示堆存儲
節點下標 i,則父節點下標為 i/2,左子節點下標為 2i,右子節點下標 2i + 1。
以圖1最大堆為例:
從根節點開始,根節點下標 1。
第一層節點下標:2、3
第二層節點下標:4、5、6、7
第三層節點下標:8
圖3
數組形式:
圖4
具體到特定的編程語言,數組以0開始下標的,推導:
對於節點 i,則其父節點為 (i – 1)/2,左子節點下標為 2i + 1,右子節點下標 2i + 2。
4、堆的恭弘=叶 恭弘子節點
對於有n個元素的二叉堆,最後一個元素的下標為為n,根據二叉堆的性質,其父節點下標為n/2,因為每一層是由左向右進行構建,所以其父節點也是倒數第二層的最後一個節點,所以,其後的節點都為最底層節點,為恭弘=叶 恭弘子節點,下標為n/2 + 1、n/2 + 2… n。
具體到特定的編程語言,數組以0開始下標的,推到:
恭弘=叶 恭弘子節點下標為(n-1)/2 + 1、(n-1)/2 + 2… n。
5、堆維護
所謂堆維護,即保持堆的基本特性,以最大堆為例:給定某個節點,維護使得以其為根節點的子堆為滿足子節點都小於等於父節點。
如下,給定堆構建數組,及特定元素下標i:
public static void maxHeapify(int[] arr, int i) { int size = arr.length; //堆大小 int maxIndex = i; //記錄當前節點及其子節點的最大值節點索引 int left = 2 * i + 1; //左子節點索引 int right = 2 * i + 2; //右子節點索引 //對比節點及其左子節點 if (left < size && arr[left] > arr[maxIndex]) { maxIndex = left; } //對比節點及其右子節點 if (right < size && arr[right] > arr[maxIndex]) { maxIndex = right; } //不滿足最大堆性質,則進行下沉節點i,遞歸處理 if (maxIndex != i) { int tmp = arr[i]; arr[i] = arr[maxIndex]; arr[maxIndex] = tmp; maxHeapify(arr, maxIndex); } }
如下圖,堆中元素9的維護過程:
圖5
堆維護過程的時間複雜度:O(lgn)。
6、構建堆
根據二.4我們可以得到所有恭弘=叶 恭弘子節點的下標。我們可以使用二.5中的堆維護過程,對所堆中所有的非恭弘=叶 恭弘子節點執行堆維護操作進行堆的構建。
public static void buildHeap(int[] arr) { for (int i = (arr.length - 1) / 2; i >= 0; i--) { maxHeapify(arr, i); } }
以數組 {27,17,3,16,13,10,1,5,7,12,4,8,9,0} 為例進行堆構建,結果為:{27,17,10,16,13,9,1,5,7,12,4,8,3,0}
圖6
構建最大堆的時間複雜度為O(n)。
7、堆排序
首先執行最大堆構建,當前堆中最大值會上升到根節點,也就是堆數組的首節點。
我們可以通過交換首尾節點,使得最大值轉移至尾部,然後對除尾部元素外的堆數組執行根元素堆維護,上浮堆最大值。
然後,將最大值交換至數組尾部倒數第二個元素位置,重新執行剩餘堆數組的根元素堆維護,依次類推,直至剩餘堆數組大小變為2為止。
以二.6中數組為例:{27,17,3,16,13,10,1,5,7,12,4,8,9,0}
第一次執行:
{27,17,10,16,13,9,1,5,7,12,4,8,3,0},max:27
第二次執行:
{17,16,10,7,13,9,1,5,0,12,4,8,3},max:17
第三詞執行:
{16,13,10,7,12,9,1,5,0,3,4,8},max:16
第四次執行:
{13,12,10,7,8,9,1,5,0,3,4},max:13
第五次執行:
{12,8,10,7,4,9,1,5,0,3},max:12
第六次執行:
{10,8,9,7,4,3,1,5,0},max:10
第七次執行:
{9,8,3,7,4,0,1,5},max:9
第八次執行:
{8,7,3,5,4,0,1},max:8
第九次執行:
{7,5,3,1,4,0},max:7
第十次執行:
{5,4,3,1,0},max:5
第十一次執行:
{4,1,3,0},max:4
第十二次執行:
{3,1,0},max:3
第十三次執行:
{1,0},max:1
改造代碼實現:
/** * 最大堆維護 * * @param arr 堆數組 * @param i 維護元素下標 * @param offSet 原址偏移量 */ public static void maxHeapify(int[] arr, int i, int offSet) { int size = arr.length - offSet; //堆大小 int maxIndex = i; //記錄當前節點及其子節點的最大值節點索引 int left = 2 * i + 1; //左子節點索引 int right = 2 * i + 2; //右子節點索引 //對比節點及其左子節點 if (left < size && arr[left] > arr[maxIndex]) { maxIndex = left; } //對比節點及其右子節點 if (right < size && arr[right] > arr[maxIndex]) { maxIndex = right; } //不滿足最大堆性質,則進行下沉節點i,遞歸處理 if (maxIndex != i) { int tmp = arr[i]; arr[i] = arr[maxIndex]; arr[maxIndex] = tmp; //因為交換了子節點的值,則以子節點為根節點的子堆特性可能發生變化,需要維護 maxHeapify(arr, maxIndex, offSet); } } /** * 構建最大堆 * * @param arr */ public static void buildHeap(int[] arr) { for (int i = (arr.length - 1) / 2; i >= 0; i--) { maxHeapify(arr, i, 0); } } /** * 交換最大值 * * @param arr 堆數組 * @param maxIndex 最大值元素待交換位置 */ public static void swapMax(int[] arr, int maxIndex) { int tmp = arr[maxIndex]; arr[maxIndex] = arr[0]; arr[0] = tmp; } /** * 堆排序 * * @param arr */ public static void heapSort(int[] arr) { buildHeap(arr); //構建堆 swapMax(arr, arr.length - 1); //交換最大值 for (int i = 0; i < arr.length - 2 ; i++) { maxHeapify(arr, 0, i + 1); //根節點堆維護 offset 偏移元素個數 swapMax(arr, arr.length - 1 - (i + 1)); //交換最大值 } }
堆排序時間複雜度:O(nlgn)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※推薦評價好的iphone維修中心