前言
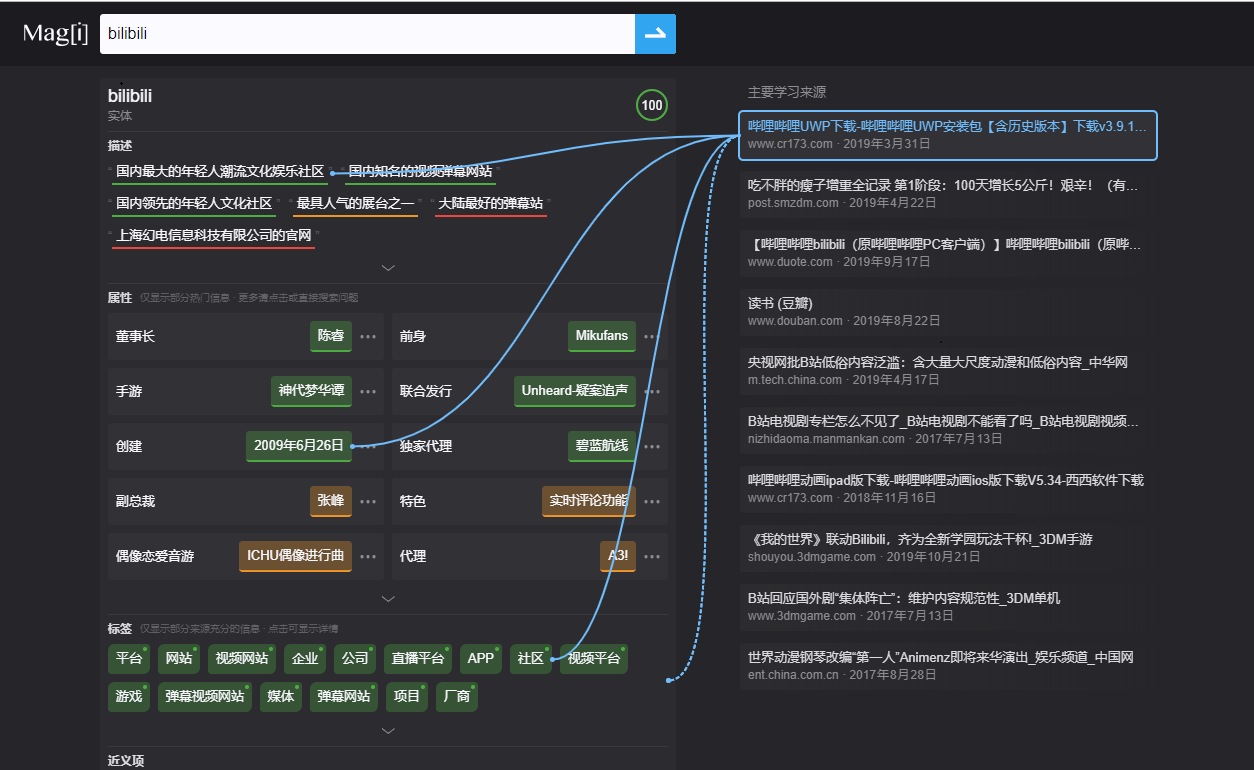
之前看到一篇推薦這個搜索引擎的新聞,對於這個搜索引擎是否好用咱們不予置評,但是我在這個搜索引擎上面發現了一個好玩的前端功能。
如上圖,將鼠標浮動到學習來源上時,會展示一堆指引線。
本博客的右側文章目錄也集成了這個功能,諸位可以玩一玩。
當時覺得這個功能很好玩,而且前端領域其實這種指引線還是有很多用處的,比如新手指引,功能指引,腦圖之類的功能。
鑒於以後很可能需要用到,當時就調試了一下這個網站,發現使用了這個庫。
然後百度了一下,發現網上也沒什麼人介紹這個庫,所以這裏寫個安利文吧。
LeaderLine
這個庫在Github上的介紹很簡單:
Draw a leader line in your web page.意思就是在網頁上畫指引線。
使用起來也非常方便:
<script src="leader-line.min.js"></script>
<script>
new LeaderLine(
document.getElementById('start'),
document.getElementById('end')
);
</script>new一個LeaderLine對象即可,只需要輸入兩個dom元素節點而已。
當然也可以輸入更多的參數來繪製各種各樣的指引線:
具體的使用方法可以去查看lead-line的,這裏就不贅述了。
而且這個庫本身就提供了hover繪製指引線的功能,並且能偏移起始點和結束點的位置,同時當起始點和結束點變動時,也可以實時調整指引線。
這兩個功能可以將鼠標hover到右側的文章目錄上,然後滾動鼠標輪來查看效果。
原理
這個庫的實現原理其實很簡單,根據提供的兩個dom元素,找到這兩個dom元素的位置,然後通過svg在body下繪製一條指引線。
這個庫雖然只是個js,但是在引入後會將一些樣式寫到一個id為leader-line-defs的svg元素內。
這些指引線使用了一個叫leader-line的樣式class,如果繪製指引線時出現遮擋情況,可以通過調整這個樣式class的z-index或者position來處理。
可以預想一下,這些指引線都是position:absolute的,因為position:fixed的元素在滾動時肯定會存在問題。
原理都講了,所以諸位請在頁面有fixed元素或者absolute元素時,仔細查看指引線是否會與這些元素產生遮擋。
示例代碼
這裏就以我博客右側目錄集成的指引線功能作為示例代碼:
// 生成目錄上的指引線
function createCatalogLeaderLine($h2Arr) { // $h2Arr是一個dom元素集合,注意不是數組哦
// lines的目的是為了保留leader-line變量,方便重繪
var lines = {};
var options = {
color: '#5bf', // 指引線顏色
endPlug: "disc", // 指引線結束點的樣式
size: 2, // 線條尺寸
startSocket: "left", //在指引線開始的地方從元素左側開始
endSocket: "right", //在指引線開始的地方從元素右側結束
hide:true // 繪製時隱藏,默認為false,在初始化時可能會出現閃爍的線條
};
[].slice.call($h2Arr).forEach(function (item) {
var anchor = LeaderLine.mouseHoverAnchor(document.getElementById('catalog' + item.id), 'draw', {
// 指引線動效
animOptions: {
duration: 500
},
// 清除默認的hover樣式
hoverStyle:{
backgroundColor: null
},
// 起始點樣式,這裏為了清除默認樣式
style: {
paddingTop: null,
paddingRight: null,
paddingBottom: null,
paddingLeft: null,
cursor: null,
backgroundColor: null,
backgroundImage: null,
backgroundSize: null,
backgroundPosition: null,
backgroundRepeat: null
},
// 當起始點被hover時調用的事件
onSwitch: function (event) {
var line = lines[item.id]
// 浮動上去就重繪
if (event.type == "mouseenter") {
line.position();
}
}
});
lines[item.id] = new LeaderLine(
anchor,
document.getElementById(item.id),
options
);
})
// 滾動時重繪指引線
$(window).scroll(function () {
for (var key in lines) {
lines[key].position()
}
})
}其中LeaderLine.mouseHoverAnchor為leader-line提供的api,顧名思義即可。
代碼就不講了,關鍵點都有註釋。
總結
沒什麼好總結的,這裏發一個小吐槽。
其實我博客集成這個功能時,最開始是直接把這個庫的js複製粘貼到了博客園的自定義js代碼中,沒想到博客園這方面做了大小限制。
所以我就把Magi這個搜索引擎的引用地址拿來用了,萬一哪天這個搜索引擎不能用了或者js地址變了那麼我目錄的指引功能可能就掛了。
N年之後你看到這篇文章,也許功能失效了,到時候別忘了給我發個短消息提醒我一下。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※別再煩惱如何寫文案,掌握八大原則!