前言
先預先說明,我這邊jdk的代碼版本為1.8.0_11,同時,因為我直接在本地jdk源碼上進行了部分修改、調試,所以,導致大家看到的我這邊貼的代碼,和大家的不太一樣。
不過,我對源碼進行修改、重構時,會保證和原始代碼的功能、邏輯嚴格一致,更多時候,可能只是修改變量名,方便理解。
大家也知道,jdk代碼寫得實在是比較深奧,變量名經常都是單字符,i,j,k啥的,實在是很難理解,所以,我一般會根據自己的理解,去重命名,為了減輕我們的頭腦負擔。
至於怎麼去修改代碼並調試,可以參考我之前的文章:
曹工力薦:調試 jdk 中 rt.jar 包部分的源碼(可自由增加註釋,修改代碼並debug)
文章中,我改過的代碼放在:
https://gitee.com/ckl111/jdk-debug
sizeCtl field的初始化
大家知道,concurrentHashMap底層是數組+鏈表+紅黑樹,數組的長度假設為n,在hashmap初始化的時候,這個n除了作為數組長度,還會作為另一個關鍵field的值。
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
該字段非常關鍵,根據取值不同,有不同的功能。
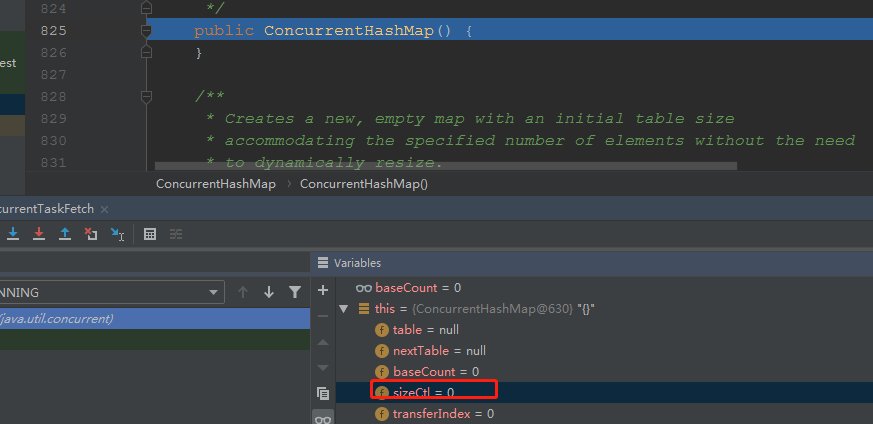
使用默認構造函數時
public ConcurrentHashMap() {
}
此時,sizeCtl被初始化為0.
使用帶初始容量的構造函數時
此時,sizeCtl也是32,和容量一致。
使用另一個map來初始化時
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
此時,sizeCtl,直接使用了默認值,16.
使用初始容量、負載因子來初始化時
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
這裏重載了:
這裏,我們傳入的負載因子為0.75,這也是默認的負載因子,傳入的初始容量為14.
這裏面會根據: 1 + 14/0.75 = 19,拿到真正的size,然後根據size,獲取到第一個大於19的2的n次方,即32,來作為數組容量,然後sizeCtl也被設置為32.
initTable時,對sizeCtl field的修改
實際上,new一個hashmap的時候,我們並沒有創建支撐數組,那,什麼時候創建數組呢?是在真正往裡面放數據的時候,比如put的時候。
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
ConcurrentHashMapPutResultVO vo = new ConcurrentHashMapPutResultVO();
vo.setBinCount(0);
for (Node<K,V>[] tab = table;;) {
int tableLength;
// 1
if (tab == null) {
tab = initTable();
continue;
}
...
}
1處,即會去初始化table。
/**
* Initializes table, using the size recorded in sizeCtl.
* 初始化hashmap,使用sizeCtl作為容量
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
sc = sizeCtl;
if (sc < 0){
Thread.yield(); // lost initialization race; just spin
continue;
}
/**
* 走到這裏,說明sizeCtl大於0,大於0,代表什麼,可以去看下其構造函數,此時,sizeCtl表示
* capacity的大小。
* {@link #ConcurrentHashMap(int)}
*
* cas修改為-1,如果成功修改為-1,則表示搶到了鎖,可以進行初始化
*
*/
// 1
boolean bGotChanceToInit = U.compareAndSwapInt(this, SIZECTL, sc, -1);
if (bGotChanceToInit) {
try {
tab = table;
/**
* 如果當前表為空,尚未初始化,則進行初始化,分配空間
*/
if (tab == null || tab.length == 0) {
/**
* sc大於0,則以sc為準,否則使用默認的容量
*/
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n];
table = tab = nt;
/**
* n >>> 2,無符號右移2位,則是n的四分之一。
* n- n/4,結果為3/4 * n
* 則,這裏修改sc為 3/4 * n
* 比如,默認容量為16,則修改sc為12
*/
// 2
sc = n - (n >>> 2);
}
} finally {
/**
* 修改sizeCtl到field
*/
// 3
sizeCtl = sc;
}
break;
}
}
return tab;
}
- 1處,cas修改sizeCtl為-1,成功了的,獲得初始化table的權利
- 2處,修改局部變量sc為: n – (n >>> 2),也就是修改為 0.75n,假設此時的數組容量為16,那麼sc就是16 * 0.75 = 12.
- 3處,將sc賦值到field: sizeCtl
經過上面的分析,initTable時,這個字段可能有兩種取值:
- -1,有線程正在對該table進行初始化
- 0.75*數組長度,此時,已經初始化完成
上面說的是,在put的時候去initTable,實際上,這個initTable,也會在以下函數中被調用,其共同點就是,都是往裡面放數據的操作:
擴容時機
上面說了很多,目前,我們知道的是,在initTable后,sizeCtl的值,是舊的數組的長度 * 0.75。
接下來,我們看看擴容時機,在put時,會調用putVal,這個函數的大體步驟:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 1
int hash = spread(key.hashCode());
int binCount = 0;
System.out.println("binCount:" + binCount);
// 2
ConcurrentHashMapPutResultVO vo = new ConcurrentHashMapPutResultVO();
vo.setBinCount(0);
for (Node<K,V>[] tab = table;;) {
int tableLength;
// 3
if (tab == null) {
tab = initTable();
continue;
}
tableLength = tab.length;
if (tableLength == 0) {
tab = initTable();
continue;
}
int entryNodeHashCode;
// 4
int entryNodeIndex = (tableLength - 1) & hash;
Node<K,V> entryNode = tabAt(tab,entryNodeIndex);
/**
* 5 如果我們要放的桶,還是個空的,則直接cas放進去
*/
if (entryNode == null) {
Node<K, V> node = new Node<>(hash, key, value, null);
// no lock when adding to empty bin
boolean bSuccess = casTabAt(tab, entryNodeIndex, null, node);
if (bSuccess) {
break;
} else {
/**
* 如果沒成功,則繼續下一輪循環
*/
continue;
}
}
entryNodeHashCode = entryNode.hash;
/**
* 6 如果要放的這個桶,正在遷移,則幫助遷移
*/
if (entryNodeHashCode == MOVED){
tab = helpTransfer(tab, entryNode);
continue;
}
/**
* 7 對entryNode加鎖
*/
V oldVal = null;
System.out.println("sync");
synchronized (entryNode) {
/**
* 這一行是判斷,在我們執行前面的一堆方法的時候,看看entryNodeIndex處的node是否變化
*/
if (tabAt(tab, entryNodeIndex) != entryNode) {
continue;
}
/**
* 8 hashCode大於0,說明不是處於遷移狀態
*/
if (entryNodeHashCode >= 0) {
/**
* 9 鏈表中找到合適的位置並放入
*/
findPositionAndPut(key, value, onlyIfAbsent, hash, vo, entryNode);
binCount = vo.getBinCount();
oldVal = (V) vo.getOldValue();
}
else if (entryNode instanceof TreeBin) {
...
}
}
System.out.println("binCount:" + binCount);
// 10
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, entryNodeIndex);
if (oldVal != null)
return oldVal;
break;
}
}
// 11
addCount(1L, binCount);
return null;
}
-
1處,計算key的hashcode
-
2處,我這邊new了一個對象,裏面兩個字段:
public class ConcurrentHashMapPutResultVO<V> {
int binCount;
V oldValue;
}
其中,oldValue用來存放,如果put進去的key/value,其中key已經存在的話,一般會直接覆蓋之前的舊值,這裏主要存放之前的舊值,因為我們需要返回舊值。
binCount,則存放:在找到對應的hash桶之後,在鏈表中,遍歷了多少個元素,該值後面會使用,作為一個標誌,當該標誌大於0的時候,才去進一步檢查,看看是否擴容。
-
3處,如果table為null,說明table里沒有任何一個鍵值對,數組也還沒創建,則初始化table
-
4處,根據hashcode,和(數組長度 – 1)相與,計算出應該存放的哈希桶在數組中的索引
-
5處,如果要放的哈希桶,還是空的,則直接cas設置進去,成功則跳出循環,否則重試
-
6處,如果要放的這個桶,該節點的hashcode為MOVED(一個常量,值為-1),說明有其他線程正在擴容該hashmap,則幫助擴容
-
7處,對要存放的hash桶的頭節點加鎖
-
8處,如果頭節點的hashcode大於0,說明是拉了一條鏈表,則調用子方法(我這邊自己抽的),去找到合適的位置並插入到鏈表
-
9處,findPositionAndPut,在鏈表中,找到合適的位置,並插入
-
10處,在findPositionAndPut函數中,會返回:為了找到合適的位置,遍歷了多少個元素,這個值,就是binCount。
如果這個binCount大於8,則說明遍歷了8個元素,則需要轉紅黑樹了。
-
11處,因為我們新增了一個元素,總數自然要加1,這裏面會去增加總數,和檢查是否需要擴容。
其中,第9步,因為是自己抽的函數,所以這裏貼出來給大家看下:
/**
* 遍歷鏈表,找到應該放的位置;如果遍歷完了還沒找到,則放到最後
* @param key
* @param value
* @param onlyIfAbsent
* @param hash
* @param vo
* @param entryNode
*/
private void findPositionAndPut(K key, V value, boolean onlyIfAbsent, int hash, ConcurrentHashMapPutResultVO vo, Node<K, V> entryNode) {
vo.setBinCount(1);
for (Node<K,V> currentIterateNode = entryNode;
;
vo.setBinCount(vo.getBinCount() + 1)) {
/**
* 如果當前遍歷指向的節點的hash值,與參數中的key的hash值相等,則,
* 繼續判斷
*/
K currentIterateNodeKey = currentIterateNode.key;
boolean bKeyEqualOrNot = Objects.equals(currentIterateNodeKey, key);
/**
* key的hash值相等,且equals比較也相等,則就是我們要找的
*/
if (currentIterateNode.hash == hash && bKeyEqualOrNot) {
/**
* 獲取舊的值
*/
vo.setOldValue(currentIterateNode.val);
/**
* 覆蓋舊的node的val
*/
if (!onlyIfAbsent)
currentIterateNode.val = value;
// 這裏直接break跳出循環
break;
}
/**
* 把當前節點保存起來
*/
Node<K,V> pred = currentIterateNode;
/**
* 獲取下一個節點
*/
currentIterateNode = currentIterateNode.next;
/**
* 如果下一個節點為null,說明當前已經是鏈表的最後一個node了
*/
if ( currentIterateNode == null) {
/**
* 則在當前節點後面,掛上新的節點
*/
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
第11步,也是我們要看的重點:
private final void addCount(long delta, int check) {
CounterCell[] counterCellsArray = counterCells;
// 1
long b = baseCount;
// 2
long newBaseCount = b + delta;
/**
* 3 直接cas在baseCount上增加
*/
boolean bSuccess = U.compareAndSwapLong(this, BASECOUNT, b, newBaseCount);
if ( counterCellsArray != null || !bSuccess) {
...
newBaseCount = sumCount();
}
// 4
if (check >= 0) {
while (true) {
Node<K,V>[] tab = table;
Node<K,V>[] nt;
int n = 0;
// 5
int sc = sizeCtl;
// 6
boolean bSumExteedSizeControl = newBaseCount >= (long) sc;
// 7
boolean bContinue = bSumExteedSizeControl && tab != null && (n = tab.length) < MAXIMUM_CAPACITY;
if (bContinue) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
} else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
// 8
transfer(tab, null);
newBaseCount = sumCount();
} else {
break;
}
}
}
}
-
1處,baseCount是一個field,存儲當前hashmap中,有多少個鍵值對,你put一次,就一個;remove一次,就減一個。
-
2處,b + delta,其中,b就是baseCount,是舊的數量;dalta,我們傳入的是1,就是要增加的元素數量
所以,b + delta,得到的,就是經過這次put后,預期的數量
-
3處,直接cas,修改baseCount這個field為 新值,也就是第二步拿到的值。
-
4處,這裏檢查check是否大於0,check,是第二個形參;這個參數,我們外邊怎麼傳的?
addCount(1L, binCount);
不就是bincount嗎,也就是說,這裏檢查:我們在put過程中,在鏈表中遍歷了幾個元素,如果遍歷了至少1個元素,這裏要進入下面的邏輯:檢查是否要擴容,因為,你binCount大於0,說明可能已經開始出現哈希衝突了。
-
5處,取field:sizeCtl的值,給局部變量sc
-
6處,判斷當前的新的鍵值對總數,是否大於sc了;比如容量是16,那麼sizeCtl是12,如果此時,hashmap中存放的鍵值對已經大於等於12了,則要檢查是否擴容了
-
7處,幾個組合條件,查看是否要擴容,其中,主要的條件就是第6步的那個。
-
8處,調用transfer,進行擴容
總結一下,經過前面的第6處,我們知道,如果存放的鍵值對總數,已經大於等於0.75*哈希桶(也就是底層數組的長度)的數量了,那麼,就基本要擴容了。
擴容的大體過程
擴容也是一個相對複雜的過程,這裏只說大概,詳細的放下講。
假設,現在底層數組長度,128,也就是128個哈希桶,當存放的鍵值對數量,大於等於 128 * 0.75的時候,就會開始擴容,擴容的過程,大概是:
- 申請一個256(容量翻倍)的數組
- 現在有128個桶,相當於,需要對128個桶進行遍歷,遍歷每個桶拉出去的鏈表或紅黑樹,查看每個鍵值對,是需要放到新數組的什麼位置
這個過程,昨天的博文,畫了個圖,這裏再貼一下。
擴容后:
可是,如果我們要一個個去遍歷所有哈希桶,然後遍歷對應的鏈表/紅黑樹,會不會太慢了?完全是單線程工作啊。
換個思路,我們能不能加快點呢?比如,線程1可以去處理數組的 0 -15這16個桶,16- 31這16個桶,完全可以讓線程2去做啊,這樣的話,不就多線程了嗎,不是就快了嗎?
沒錯,jdk就是這麼乾的。
jdk維護了一個field,這個field,專門用來存當前可以獲取的任務的索引,舉個例子:
大家看上圖就懂了,一開始,這裏假設我們有128個桶,每次每個線程,去拿16個桶來處理。
剛開始的時候,field:transferIndex就等於127,也就是最後一個桶的位置,然後我們要從后往前取,那麼,127 到112,剛好就是16個桶,所以,申請任務的時候,就會用cas去更新field為112,則表示,自己取到了112 到127這一個區間的hash桶遷移任務。
如果自始至終,只有一個線程呢,它處理完了112 – 127這一批hash桶后,會繼續取下一波任務,96 – 112;以此類推。
如果多線程的話呢,也是類似的,反正都是去嘗試cas更新transferIndex的值為任務區間的開始下標的值,成功了,就算任務認領成功了。
多線程,怎麼知道需要去幫助擴容呢? 發起擴容的線程,在處理完bucket[k]時,會把老的table中的對應的bucket[k]的頭節點,修改為下面這種類型的節點:
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
}
其他線程,在put或者其他操作時,發現頭結點變成了這個,就會去協助擴容了。
多線程擴容,和分段取任務的差別?
我個人感覺,差別不大,多線程擴容,就是多線程去獲取自己的那一段任務,然後來完成。我這邊寫了簡單的demo,不過感覺還是很有用的,可以幫助我們理解。
import sun.misc.Unsafe;
import java.lang.reflect.Field;
import java.util.concurrent.*;
import java.util.concurrent.locks.LockSupport;
public class ConcurrentTaskFetch {
/**
* 空閑任務索引,獲取任務時,從該下標開始,往前獲取。
* 比如當前下標為10,表示tasks數組中,0-10這個區間的任務,沒人領取
*/
// 0
private volatile int freeTaskIndexForFetch;
// 1
private static final int TASK_COUNT_PER_FETCH = 16;
// 2
private String[] tasks = new String[128];
public static void main(String[] args) {
ConcurrentTaskFetch fetch = new ConcurrentTaskFetch();
// 3
fetch.init();
ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 10, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100));
executor.prestartAllCoreThreads();
CyclicBarrier cyclicBarrier = new CyclicBarrier(10);
// 4
for (int i = 0; i < 10; i++) {
executor.execute(new Runnable() {
@Override
public void run() {
try {
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
// 5
FetchedTaskInfo fetchedTaskInfo = fetch.fetchTask();
if (fetchedTaskInfo != null) {
System.out.println("thread:" + Thread.currentThread().getName() + ",get task success:" + fetchedTaskInfo);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("thread:" + Thread.currentThread().getName() + ", process task finished");
}
}
});
}
LockSupport.park();
}
public void init() {
for (int i = 0; i < 128; i++) {
tasks[i] = "task" + i;
}
freeTaskIndexForFetch = tasks.length;
}
// 6
public FetchedTaskInfo fetchTask() {
System.out.println("Thread start fetch task:"+Thread.currentThread().getName()+",time: "+System.currentTimeMillis());
while (true){
// 6.1
if (freeTaskIndexForFetch == 0) {
System.out.println("thread:" + Thread.currentThread().getName() + ",get task failed,there is no task");
return null;
}
/**
* 6.2 獲取當前任務的集合的上界
*/
int subTaskListEndIndex = this.freeTaskIndexForFetch;
/**
* 6.3 獲取當前任務的集合的下界
*/
int subTaskListStartIndex = subTaskListEndIndex > TASK_COUNT_PER_FETCH ?
subTaskListEndIndex - TASK_COUNT_PER_FETCH : 0;
/**
* 6.4
* 現在,我們拿到了集合的上下界,即[subTaskListStartIndex,subTaskListEndIndex)
* 該區間為前開后閉,所以,實際的區間為:
* [subTaskListStartIndex,subTaskListEndIndex - 1]
*/
/**
* 6.5 使用cas,嘗試更新{@link freeTaskIndexForFetch} 為 subTaskListStartIndex
*/
if (U.compareAndSwapInt(this, FREE_TASK_INDEX_FOR_FETCH, subTaskListEndIndex, subTaskListStartIndex)) {
// 6.6
FetchedTaskInfo info = new FetchedTaskInfo();
info.setStartIndex(subTaskListStartIndex);
info.setEndIndex(subTaskListEndIndex - 1);
return info;
}
}
}
// Unsafe mechanics
private static final sun.misc.Unsafe U;
private static final long FREE_TASK_INDEX_FOR_FETCH;
static {
try {
// U = sun.misc.Unsafe.getUnsafe();
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
U = (Unsafe) f.get(null);
Class<?> k = ConcurrentTaskFetch.class;
FREE_TASK_INDEX_FOR_FETCH = U.objectFieldOffset
(k.getDeclaredField("freeTaskIndexForFetch"));
} catch (Exception e) {
throw new Error(e);
}
}
static class FetchedTaskInfo{
int startIndex;
int endIndex;
public int getStartIndex() {
return startIndex;
}
public void setStartIndex(int startIndex) {
this.startIndex = startIndex;
}
public int getEndIndex() {
return endIndex;
}
public void setEndIndex(int endIndex) {
this.endIndex = endIndex;
}
@Override
public String toString() {
return "FetchedTaskInfo{" +
"startIndex=" + startIndex +
", endIndex=" + endIndex +
'}';
}
}
}
-
0處,定義了一個field,類似於前面的transferIndex
/**
* 空閑任務索引,獲取任務時,從該下標開始,往前獲取。
* 比如當前下標為10,表示tasks數組中,0-10這個區間的任務,沒人領取
*/
// 0
private volatile int freeTaskIndexForFetch;
-
1,定義了每次取多少個任務,這裏也是16個
private static final int TASK_COUNT_PER_FETCH = 16;
-
2,定義任務列表,共128個任務
-
3,main函數中,進行任務初始化
public void init() {
for (int i = 0; i < 128; i++) {
tasks[i] = "task" + i;
}
freeTaskIndexForFetch = tasks.length;
}
主要初始化任務列表,其次,將freeTaskIndexForFetch 賦值為128,後續取任務,從這個下標開始
-
4處,啟動10個線程,每個線程去執行取任務,按理說,我們128個任務,每個線程取16個,只能有8個線程取到任務,2個線程取不到
-
5處,線程邏輯里,去獲取任務
-
6處,獲取任務的方法定義
-
6.1 ,如果可獲取的任務索引為0了,說明沒任務了,直接返回
-
6.2,獲取當前任務的集合的上界
-
6.3,獲取當前任務的集合的下界,減去16就行了
-
6.4,拿到了集合的上下界,即[subTaskListStartIndex,subTaskListEndIndex)
-
6.5, 使用cas,更新field為:6.4中的任務下界。
執行效果演示:
可以看到,8個線程取到任務,2個線程沒取到。
該思想在內存分配時的應用
其實jvm內存分配時,也是類似的思路,比如,設置堆內存為200m,那這200m是啟動時立馬從操作系統分配了的。
接下來,就是每次new對象的時候,去這個大內存里,找個小空間,這個過程,也是需要cas去競爭的,比如肯定也有個全局的字段,來表示當前可用內存的索引,比如該索引為100,表示,第100個字節后的空間是可以用的,那我要new個對象,這個對象有3個字段,需要大概30個字節,那我是不是需要把這個索引更新為130。
這中間是多線程的,所以也是要cas操作。
道理都是類似的。
總結
時間倉促,有問題在所難免,歡迎及時指出或加群討論。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!