環境資訊中心綜合外電;黃鈺婷 翻譯;林大利 審校;稿源:Mongabay
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
摘錄自2020年7月29日自由時報報導
日本海洋研究開發機構和高知大學所組成的團隊,在南太平洋海底下約有1億年至430萬年的地層從發現微生物,這些微生物並未變成化石,而是在提供營養後,竟然可以從長期休眠中復甦。
據日本《共同社》報導,日本研究團隊在2010年於紐西蘭以東的海域進行挖掘研究,他們從3700至5700公尺深的海底中挖掘7處地層,發現了像是被封閉在細微粒子組成的粘土之中的微生物,為了確認微生物是否仍然存活還是變成化石,團隊開始提供氧氣和糖等餌食進行了觀察。
實驗啟動3週後,微生物竟然復甦開始進食,約2個月後最大增至1萬倍以上。細胞分裂平均從喂餌5天後開始,微生物平均復甦率為77%,而年代最久遠的1億年地層,存活率更是高達99.1%。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
本系列文章:
讀源碼,我們可以從第一行讀起
你知道Spring是怎麼解析配置類的嗎?
配置類為什麼要添加@Configuration註解?
推薦閱讀:
Spring官網閱讀 | 總結篇
Spring雜談
本系列文章將會帶你一行行的將Spring的源碼吃透,推薦閱讀的文章是閱讀源碼的基礎!
在開始探討源碼前,我們先思考兩個問題:
通過new關鍵字,反射,克隆等手段創建出來的就是對象。在Spring中,Bean一定是一個對象,但是對象不一定是一個Bean,一個被創建出來的對象要變成一個Bean要經過很多複雜的工序,例如需要被我們的
BeanPostProcessor處理,需要經過初始化,需要經過AOP(AOP本身也是由後置處理器完成的)等。
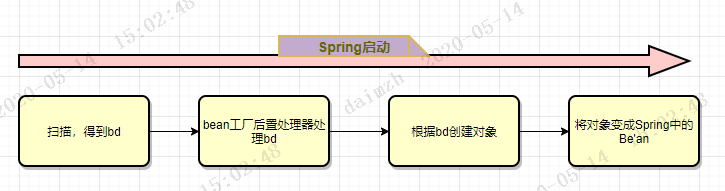
我們還是回到流程圖中,其中相關的步驟如下:
在前面的三篇文章中,我們已經分析到了第3-5步的源碼,而如果你對Spring源碼稍有了解的話,就是知道創建對象以及將對象變成一個Bean的過程發生在第3-11步驟中。中間的五步分別做了什麼呢?
就像名字所說的那樣,註冊BeanPostProcessor,這段代碼在Spring官網閱讀(八)容器的擴展點(三)(BeanPostProcessor)已經分析過了,所以在本文就直接跳過了,如果你沒有看過之前的文章也沒有關係,你只需要知道,在這裏Spring將所有的BeanPostProcessor註冊到了容器中
初始化容器中的messageSource,如果程序員沒有提供,默認會創建一個org.springframework.context.support.DelegatingMessageSource,Spring官網閱讀(十一)ApplicationContext詳細介紹(上) 已經介紹過了。
初始化事件分發器,如果程序員沒有提供,那麼默認創建一個org.springframework.context.event.ApplicationEventMulticaster,Spring官網閱讀(十二)ApplicationContext詳解(中)已經做過詳細分析,不再贅述
留給子類複寫擴展使用
註冊事件監聽器,就是將容器中所有實現了org.springframework.context.ApplicationListener接口的對象放入到監聽器的集合中。
在完成了上面的一些準備工作后,Spring開始來創建Bean了,按照流程,首先被調用的就是
finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory)方法,我們就以這個方法為入口,一步步跟蹤源碼,看看Spring中的Bean到底是怎麼創建出來的,當然,本文主要關注的是創建對象的這個過程,對象變成Bean的流程我們在後續文章中再分析
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// 初始化一個ConversionService用於類型轉換,這個ConversionService會在實例化對象的時候用到
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
// 添加一個StringValueResolver,用於處理佔位符,可以看到,默認情況下就是使用環境中的屬性值來替代佔位符中的屬性
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
// 創建所有的LoadTimeWeaverAware
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// 靜態織入完成后將臨時的類加載器設置為null,所以除了創建LoadTimeWeaverAware時可能會用到臨時類加載器,其餘情況下都為空
beanFactory.setTempClassLoader(null);
// 將所有的配置信息凍結
beanFactory.freezeConfiguration();
// 開始進行真正的創建
beanFactory.preInstantiateSingletons();
}
上面的方法最終調用了org.springframework.beans.factory.support.DefaultListableBeanFactory#preInstantiateSingletons來創建Bean。
其源碼如下:
public void preInstantiateSingletons() throws BeansException {
// 所有bd的名稱
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// 遍歷所有bd,一個個進行創建
for (String beanName : beanNames) {
// 獲取到指定名稱對應的bd
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
// 對不是延遲加載的單例的Bean進行創建
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// 判斷是否是一個FactoryBean
if (isFactoryBean(beanName)) {
// 如果是一個factoryBean的話,先創建這個factoryBean,創建factoryBean時,需要在beanName前面拼接一個&符號
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
final FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged((PrivilegedAction<Boolean>)
((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
// 判斷是否是一個SmartFactoryBean,並且不是懶加載的,就意味着,在創建了這個factoryBean之後要立馬調用它的getObject方法創建另外一個Bean
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
// 不是factoryBean的話,我們直接創建就行了
getBean(beanName);
}
}
}
// 在創建了所有的Bean之後,遍歷
for (String beanName : beanNames) {
// 這一步其實是從緩存中獲取對應的創建的Bean,這裏獲取到的必定是單例的
Object singletonInstance = getSingleton(beanName);
// 判斷是否是一個SmartInitializingSingleton,最典型的就是我們之前分析過的EventListenerMethodProcessor,在這一步完成了對已經創建好的Bean的解析,會判斷其方法上是否有 @EventListener註解,會將這個註解標註的方法通過EventListenerFactory轉換成一個事件監聽器並添加到監聽器的集合中
if (singletonInstance instanceof SmartInitializingSingleton) {
final SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
}
上面這段代碼整體來說應該不難,不過它涉及到了一個點就是factoryBean,如果你對它不夠了解的話,請參考我之前的一篇文章:Spring官網閱讀(七)容器的擴展點(二)FactoryBean
從上面的代碼分析中我們可以知道,Spring最終都會調用到getBean方法,而getBean並不是真正幹活的,doGetBean才是。另外doGetBean可以分為兩種情況
FactoryBean,此時實際傳入的name = & + beanNamename = beanName其代碼如下:
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
// 前面我們說過了,傳入的name可能時& + beanName這種形式,這裏做的就是去除掉&,得到beanName
final String beanName = transformedBeanName(name);
Object bean;
// 這個方法就很牛逼了,通過它解決了循環依賴的問題,不過目前我們只需要知道它是從單例池中獲取已經創建的Bean即可,循環依賴後面我單獨寫一篇文章
// 方法作用:已經創建的Bean會被放到單例池中,這裏就是從單例池中獲取
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
// 如果直接從單例池中獲取到了這個bean(sharedInstance),我們能直接返回嗎?
// 當然不能,因為獲取到的Bean可能是一個factoryBean,如果我們傳入的name是 & + beanName 這種形式的話,那是可以返回的,但是我們傳入的更可能是一個beanName,那麼這個時候Spring就還需要調用這個sharedInstance的getObject方法來創建真正被需要的Bean
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
// 在緩存中獲取不到這個Bean
// 原型下的循環依賴直接報錯
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// 核心要義,找不到我們就從父容器中再找一次
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
String nameToLookup = originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory) {
return ((AbstractBeanFactory) parentBeanFactory).doGetBean(
nameToLookup, requiredType, args, typeCheckOnly);
}
else if (args != null) {
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else if (requiredType != null) {
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
else {
return (T) parentBeanFactory.getBean(nameToLookup);
}
}
// 如果不僅僅是為了類型推斷,也就是代表我們要對進行實例化
// 那麼就將bean標記為正在創建中,其實就是將這個beanName放入到alreadyCreated這個set集合中
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
try {
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
// 檢查合併后的bd是否是abstract,這個檢查現在已經沒有作用了,必定會通過
checkMergedBeanDefinition(mbd, beanName, args);
// @DependsOn註解標註的當前這個Bean所依賴的bean名稱的集合,就是說在創建當前這個Bean前,必須要先將其依賴的Bean先完成創建
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
// 遍歷所有申明的依賴
for (String dep : dependsOn) {
// 如果這個bean所依賴的bean又依賴了當前這個bean,出現了循環依賴,直接報錯
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
// 註冊bean跟其依賴的依賴關係,key為依賴,value為依賴所從屬的bean
registerDependentBean(dep, beanName);
try {
// 先創建其依賴的Bean
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}
// 我們目前只分析單例的創建,單例看懂了,原型自然就懂了
if (mbd.isSingleton()) {
// 這裏再次調用了getSingleton方法,這裏跟方法開頭調用的getSingleton的區別在於,這個方法多傳入了一個ObjectFactory類型的參數,這個ObjectFactory會返回一個Bean
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 省略原型跟域對象的相關代碼
return (T) bean;
}
配合註釋看這段代碼應該也不難吧,我們重點關注最後在調用的這段方法即可
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
// 從單例池中獲取,這個地方肯定也獲取不到
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 工廠已經在銷毀階段了,這個時候還在創建Bean的話,就直接拋出異常
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
// 在單例創建前,記錄一下正在創建的單例的名稱,就是把beanName放入到singletonsCurrentlyInCreation這個set集合中去
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 這裏調用了singletonFactory的getObject方法,對應的實現就是在doGetBean中的那一段lambda表達式
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// 省略異常處理
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// 在單例完成創建后,將beanName從singletonsCurrentlyInCreation中移除
// 標志著這個單例已經完成了創建
afterSingletonCreation(beanName);
}
if (newSingleton) {
// 添加到單例池中
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
分析完上面這段代碼,我們會發現,核心的創建Bean的邏輯就是在singletonFactory.getObject()這句代碼中,而其實現就是在doGetBean方法中的那一段lambda表達式,如下:
實際就是通過createBean這個方法創建了一個Bean然後返回,createBean又幹了什麼呢?
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
RootBeanDefinition mbdToUse = mbd;
// 解析得到beanClass,為什麼需要解析呢?如果是從XML中解析出來的標籤屬性肯定是個字符串嘛
// 所以這裏需要加載類,得到Class對象
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
// 對XML標籤中定義的lookUp屬性進行預處理,如果只能根據名字找到一個就標記為非重載的,這樣在後續就不需要去推斷到底是哪個方法了,對於@LookUp註解標註的方法是不需要在這裏處理的,AutowiredAnnotationBeanPostProcessor會處理這個註解
try {
mbdToUse.prepareMethodOverrides();
}
// 省略異常處理...
try {
// 在實例化對象前,會經過後置處理器處理
// 這個後置處理器的提供了一個短路機制,就是可以提前結束整個Bean的生命周期,直接從這裏返回一個Bean
// 不過我們一般不會這麼做,它的另外一個作用就是對AOP提供了支持,在這裡會將一些不需要被代理的Bean進行標記,就本文而言,你可以暫時理解它沒有起到任何作用
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
// 省略異常處理...
try {
// doXXX方法,真正幹活的方法,doCreateBean,真正創建Bean的方法
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
// 省略異常處理...
}
本文只探討對象是怎麼創建的,至於怎麼從一個對象變成了Bean,在後面的文章我們再討論,所以我們主要就關注下面這段代碼
// 這個方法真正創建了Bean,創建一個Bean會經過 創建對象 > 依賴注入 > 初始化 這三個過程,在這個過程中,BeanPostPorcessor會穿插執行,本文主要探討的是創建對象的過程,所以關於依賴注入及初始化我們暫時省略,在後續的文章中再繼續研究
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
// 這行代碼看起來就跟factoryBean相關,這是什麼意思呢?
// 在下文我會通過例子介紹下,你可以暫時理解為,這個地方返回的就是個null
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
// 這裏真正的創建了對象
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 省略依賴注入,初始化
}
這裏我先分析下this.factoryBeanInstanceCache.remove(beanName)這行代碼。這裏需要說一句,我寫的這個源碼分析的系列非常的細節,之所以選擇這樣一個個扣細節是因為我自己在閱讀源碼過程中經常會被這些問題阻塞,那麼藉著這些文章將自己踩過的坑分享出來可以減少作為讀者的你自己在閱讀源碼時的障礙,其次也能夠提升自己閱讀源碼的能力。如果你對這些細節不感興趣的話,可以直接跳過,能把握源碼的主線即可。言歸正傳,我們回到這行代碼this.factoryBeanInstanceCache.remove(beanName)。什麼時候factoryBeanInstanceCache這個集合中會有值呢?這裏我還是以示例代碼來說明這個問題,示例代碼如下:
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(Config.class);
}
}
// 沒有做什麼特殊的配置,就是掃描了需要的組件,測試時換成你自己的包名
@ComponentScan("com.dmz.source.instantiation")
@Configuration
public class Config {
}
// 這裏申明了一個FactoryBean,並且通過@DependsOn註解申明了這個FactoryBean的創建要在orderService之後,主要目的是為了在DmzFactoryBean創建前讓容器發生一次屬性注入
@Component
@DependsOn("orderService")
public class DmzFactoryBean implements FactoryBean<DmzService> {
@Override
public DmzService getObject() throws Exception {
return new DmzService();
}
@Override
public Class<?> getObjectType() {
return DmzService.class;
}
}
// 沒有通過註解的方式將它放到容器中,而是通過上面的DmzFactoryBean來管理對應的Bean
public class DmzService {
}
// OrderService中需要注入dmzService
@Component
public class OrderService {
@Autowired
DmzService dmzService;
}
在這段代碼中,因為我們明確的表示了DmzFactoryBean是依賴於orderService的,所以必定會先創建orderService再創建DmzFactoryBean,創建orderService的流程如下:
其中的屬性注入階段,我們需要細化,也可以畫圖如下:
為orderService進行屬性注入可以分為這麼幾步
找到需要注入的注入點,也就是orderService中的dmzService字段
根據字段的類型以及名稱去容器中查詢符合要求的Bean
當遍歷到一個FactroyBean時,為了確定其getObject方法返回的對象的類型需要創建這個FactroyBean(只會到對象級別),然後調用這個創建好的FactroyBean的getObjectType方法明確其類型並與注入點需要的類型比較,看是否是一個候選的Bean,在創建這個FactroyBean時就將其放入了factoryBeanInstanceCache中。
在確定了唯一的候選Bean之後,Spring就會對這個Bean進行創建,創建的過程又經過三個步驟
在創建對象時,因為此時factoryBeanInstanceCache已經緩存了這個Bean對應的對象,所以直接通過this.factoryBeanInstanceCache.remove(beanName)這行代碼就返回了,避免了二次創建對象。
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
Class<?> beanClass = resolveBeanClass(mbd, beanName);
// 省略異常
// 通過bd中提供的instanceSupplier來獲取一個對象
// 正常bd中都不會有這個instanceSupplier屬性,這裏也是Spring提供的一個擴展點,但實際上不常用
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}
// bd中提供了factoryMethodName屬性,那麼要使用工廠方法的方式來創建對象,工廠方法又會區分靜態工廠方法跟實例工廠方法
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
// 在原型模式下,如果已經創建過一次這個Bean了,那麼就不需要再次推斷構造函數了
boolean resolved = false; // 是否推斷過構造函數
boolean autowireNecessary = false; // 構造函數是否需要進行注入
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
if (autowireNecessary) {
return autowireConstructor(beanName, mbd, null, null);
}
else {
return instantiateBean(beanName, mbd);
}
}
// 推斷構造函數
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// 調用無參構造函數創建對象
return instantiateBean(beanName, mbd);
}
上面這段代碼在Spring官網閱讀(一)容器及實例化 已經分析過了,但是當時我們沒有深究創建對象的細節,所以本文將詳細探討Spring中的這個對象到底是怎麼創建出來的,這也是本文的主題。
在Spring官網閱讀(一)容器及實例化 這篇文章中,我畫了下面這麼一張圖
從上圖中我們可以知道Spring在實例化對象的時候有這麼幾種方式
我們接下來就一一分析其中的細節:
在Spring官網閱讀(一)容器及實例化 文中介紹過這種方式,因為這種方式我們基本不會使用,並不重要,所以這裏就不再贅述,我這裏就直接給出一個使用示例,大家自行體會吧
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
// 直接註冊一個Bean,並且指定它的supplier就是Service::new
ac.registerBean("service", Service.class,Service::new,zhe'sh);
ac.refresh();
System.out.println(ac.getBean("service"));
}
對應代碼如下:
protected BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
return new ConstructorResolver(this).instantiateUsingFactoryMethod(beanName, mbd, explicitArgs);
}
上面這段代碼主要幹了兩件事
ConstructorResolver對象,從類名來看,它是一個構造器解析器instantiateUsingFactoryMethod方法,這個方法見名知意,使用FactoryMethod來完成實例化基於此,我們解決一個問題,ConstructorResolver是什麼?
在要研究一個類前,我們最先應該從哪裡入手呢?很多沒有經驗的同學可能會悶頭看代碼,但是實際上最好的學習方式是先閱讀類上的javaDoc
ConstructorResolver上的javaDoc如下:
上面這段javaDoc翻譯過來就是這個類就是用來解析構造函數跟工廠方法的代理者,並且它是通過參數匹配的方式來進行推斷構造方法或者工廠方法。
看到這裏不知道小夥伴們是否有疑問,就是明明這個類不僅負責推斷構造函數,還會負責推斷工廠方法,那麼為什麼類名會叫做ConstructorResolver呢?我們知道Spring的代碼在業界來說絕對是最規範的,沒有之一,這樣來說的話,這個類最合適的名稱應該是ConstructorAndFactoryMethodResolver才對,因為它不僅負責推斷了構造函數還負責推斷了工廠方法嘛!
這裏我需要說一下我自己的理解。對於一個Bean,它是通過構造函數完成實例化的,或者通過工廠方法實例化的,其實在這個Bean看來都沒有太大區別,這兩者都可以稱之為這個Bean的構造器,因為通過它們都能構造出一個Bean。所以Spring就把兩者統稱為構造器了,所以這個類名也就被稱為ConstructorResolver了。
Spring在很多地方體現了這種實現,例如在XML配置的情況下,不論我們是使用構造函數創建對象還是使用工廠方法創建對象,其參數的標籤都是使用constructor-arg。比如下面這個例子
<bean id="dmzServiceGetFromStaticMethod"
factory-bean="factoryBean"
factory-method="getObject">
<constructor-arg type="java.lang.String" value="hello" name="s"/>
<constructor-arg type="com.dmz.source.instantiation.service.DmzFactory" ref="factoryBean"/>
</bean>
<!--測試靜態工廠方法創建對象-->
<bean id="service"
class="com.dmz.official.service.MyFactoryBean"
factory-method="staticGet">
<constructor-arg type="java.lang.String" value="hello"/>
</bean>
<bean id="dmzService" class="com.dmz.source.instantiation.service.DmzService">
<constructor-arg name="s" value="hello"/>
</bean>
在對這個類有了大概的了解后,我們就需要來分析它的源碼,這裏我就不把它單獨拎出來分析了,我們藉著Spring的流程看看這個類幹了什麼事情
核心目的:推斷出要使用的factoryMethod以及調用這個FactoryMethod要使用的參數,然後反射調用這個方法實例化出一個對象
這個方法的代碼太長了,所以我們將它拆分成為一段一段的來分析
在分析上面的代碼之前,我們先來看看這個方法的參數都是什麼含義
方法上關於參數的介紹如圖所示
beanName:當前要實例化的Bean的名稱mbd:當前要實例化的Bean對應的BeanDefinitionexplicitArgs:這個參數在容器啟動階段我們可以認定它就是null,只有显示的調用了getBean方法,並且傳入了明確的參數,例如:getBean("dmzService","hello")這種情況下才會不為null,我們分析這個方法的時候就直接認定這個參數為null即可。public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代碼:創建並初始話一個BeanWrapperImpl
BeanWrapperImpl bw = new BeanWrapperImpl();
this.beanFactory.initBeanWrapper(bw);
// ......
}
BeanWrapperImpl是什麼呢?如果你看過我之前的文章:Spring官網閱讀(十四)Spring中的BeanWrapper及類型轉換,那麼你對這個類應該不會陌生,它就是對Bean進行了一層包裝,並且在創建Bean的時候以及進行屬性注入的時候能夠進行類型轉換。就算你沒看過之前的文章也沒關係,只要記住兩點
其層級關係如下:
回到我們的源碼分析,我們先來看看new BeanWrapperImpl()做了什麼事情?
對應代碼如下:
// 第一步:調用空參構造
public BeanWrapperImpl() {
// 調用另外一個構造函數,表示要註冊默認的屬性編輯器
this(true);
}
// 這個構造函數表明是否要註冊默認編輯器,上面傳入的值為true,表示需要註冊
public BeanWrapperImpl(boolean registerDefaultEditors) {
super(registerDefaultEditors);
}
// 調用到父類的構造函數,確定要使用默認的屬性編輯器
protected AbstractNestablePropertyAccessor(boolean registerDefaultEditors) {
if (registerDefaultEditors) {
registerDefaultEditors();
}
// 對typeConverterDelegate進行初始化
this.typeConverterDelegate = new TypeConverterDelegate(this);
}
總的來說創建的過程非常簡單。第一,確定要註冊默認的屬性編輯器;第二,對typeConverterDelegate屬性進行初始化。
緊接着,我們看看在初始化這個BeanWrapper做了什麼?
// 初始化BeanWrapper,主要就是將容器中配置的conversionService賦值到當前這個BeanWrapper上
// 同時註冊定製的屬性編輯器
protected void initBeanWrapper(BeanWrapper bw) {
bw.setConversionService(getConversionService());
registerCustomEditors(bw);
}
還記得conversionService在什麼時候被放到容器中的嗎?就是在finishBeanFactoryInitialization的時候啦~!
對conversionService屬性完成賦值后就開始註冊定製的屬性編輯器,代碼如下:
// 傳入的參數就是我們的BeanWrapper,它同時也是一個屬性編輯器註冊表
protected void registerCustomEditors(PropertyEditorRegistry registry) {
PropertyEditorRegistrySupport registrySupport =
(registry instanceof PropertyEditorRegistrySupport ? (PropertyEditorRegistrySupport) registry : null);
if (registrySupport != null) {
// 這個配置的作用就是在註冊默認的屬性編輯器時,可以增加對數組到字符串的轉換功能
// 默認就是通過","來切割字符串轉換成數組,對應的屬性編輯器就是StringArrayPropertyEditor
registrySupport.useConfigValueEditors();
}
// 將容器中的屬性編輯器註冊到當前的這個BeanWrapper
if (!this.propertyEditorRegistrars.isEmpty()) {
for (PropertyEditorRegistrar registrar : this.propertyEditorRegistrars) {
registrar.registerCustomEditors(registry);
// 省略異常處理~
}
}
// 這裏我們沒有添加任何的自定義的屬性編輯器,所以肯定為空
if (!this.customEditors.isEmpty()) {
this.customEditors.forEach((requiredType, editorClass) ->
registry.registerCustomEditor(requiredType, BeanUtils.instantiateClass(editorClass)));
}
}
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 省略已經分析的第一段代碼,到這裏已經得到了一個具有類型轉換功能的BeanWrapper
// 實例化這個Bean的工廠Bean
Object factoryBean;
// 工廠Bean的Class
Class<?> factoryClass;
// 靜態工廠方法或者是實例化工廠方法
boolean isStatic;
/*下面這段代碼就是為上面申明的這三個屬性賦值*/
String factoryBeanName = mbd.getFactoryBeanName();
// 如果創建這個Bean的工廠就是這個Bean本身的話,那麼直接拋出異常
if (factoryBeanName != null) {
if (factoryBeanName.equals(beanName)) {
throw new BeanDefinitionStoreException(mbd.getResourceDescription(), beanName,
"factory-bean reference points back to the same bean definition");
}
// 得到創建這個Bean的工廠Bean
factoryBean = this.beanFactory.getBean(factoryBeanName);
if (mbd.isSingleton() && this.beanFactory.containsSingleton(beanName)) {
throw new ImplicitlyAppearedSingletonException();
}
factoryClass = factoryBean.getClass();
isStatic = false;
}
else {
// factoryBeanName為null,說明是通過靜態工廠方法來實例化Bean的
// 靜態工廠進行實例化Bean,beanClass屬性必須要是工廠的class,如果為空,直接報錯
if (!mbd.hasBeanClass()) {
throw new BeanDefinitionStoreException(mbd.getResourceDescription(), beanName,
"bean definition declares neither a bean class nor a factory-bean reference");
}
factoryBean = null;
factoryClass = mbd.getBeanClass();
isStatic = true;
}
// 省略後續代碼
}
小總結:
這段代碼很簡單,就是確認實例化當前這個Bean的工廠方法是靜態工廠還是實例工廠,如果是實例工廠,那麼找出對應的工廠Bean。
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 省略第一段,第二段代碼
// 到這裏已經得到了一個BeanWrapper,明確了實例化當前這個Bean到底是靜態工廠還是實例工廠
// 並且已經確定了工廠Bean
// 最終確定的要用來創建對象的方法
Method factoryMethodToUse = null;
ArgumentsHolder argsHolderToUse = null;
Object[] argsToUse = null;
// 參數分析時已經說過,explicitArgs就是null
if (explicitArgs != null) {
argsToUse = explicitArgs;
}
else {
// 下面這段代碼是什麼意思呢?
// 在原型模式下,我們會多次創建一個Bean,所以Spring對參數以及所使用的方法做了緩存
// 在第二次創建原型對象的時候會進入這段緩存的邏輯
// 但是這裡有個問題,為什麼Spring對參數有兩個緩存呢?
// 一:resolvedConstructorArguments
// 二:preparedConstructorArguments
// 這裏主要是因為,直接使用解析好的構造的參數,因為這樣會導致創建出來的所有Bean都引用同一個屬性
Object[] argsToResolve = null;
synchronized (mbd.constructorArgumentLock) {
factoryMethodToUse = (Method) mbd.resolvedConstructorOrFactoryMethod;
// 緩存已經解析過的工廠方法或者構造方法
if (factoryMethodToUse != null && mbd.constructorArgumentsResolved) {
// resolvedConstructorArguments跟preparedConstructorArguments都是對參數的緩存
argsToUse = mbd.resolvedConstructorArguments;
if (argsToUse == null) {
argsToResolve = mbd.preparedConstructorArguments;
}
}
}
if (argsToResolve != null) {
// preparedConstructorArguments需要再次進行解析
argsToUse = resolvePreparedArguments(beanName, mbd, bw, factoryMethodToUse, argsToResolve);
}
}
// 省略後續代碼
}
小總結:
上面這段代碼應該沒什麼大問題,其核心思想就是從緩存中取已經解析出來的方法以及參數,這段代碼只會在原型模式下生效,因為單例的話對象只會創建一次嘛~!最大的問題在於,為什麼在對參數進行緩存的時候使用了兩個不同的集合,並且緩存后的參數還需要再次解析,這個問題我們暫且放着,不妨帶着這個問題往下看。
因為接下來要分析的代碼就比較複雜了,所以為了讓你徹底看到代碼的執行流程,下面我會使用示例+流程圖+文字的方式來分析源碼。
示例代碼如下(這個例子覆蓋接下來要分析的所有流程):
配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"
default-autowire="constructor"><!--這裏開啟自動注入,並且是通過構造函數進行自動注入-->
<!--factoryObject 提供了創建對象的方法-->
<bean id="factoryObject" class="com.dmz.spring.first.instantiation.service.FactoryObject"/>
<!--提供一個用於測試自動注入的對象-->
<bean class="com.dmz.spring.first.instantiation.service.OrderService" id="orderService"/>
<!--主要測試這個對象的實例化過程-->
<bean id="dmzService" factory-bean="factoryObject" factory-method="getDmz" scope="prototype">
<constructor-arg name="name" value="dmz"/>
<constructor-arg name="age" value="18"/>
<constructor-arg name="birthDay" value="2020-05-23"/>
</bean>
<!--測試靜態方法實例化對象的過程-->
<bean id="indexService" class="com.dmz.spring.first.instantiation.service.FactoryObject"
factory-method="staticGetIndex"/>
<!--提供這個轉換器,用於轉換dmzService中的birthDay屬性,從字符串轉換成日期對象-->
<bean class="org.springframework.context.support.ConversionServiceFactoryBean" id="conversionService">
<property name="converters">
<set>
<bean class="com.dmz.spring.first.instantiation.service.ConverterStr2Date"/>
</set>
</property>
</bean>
</beans>
測試代碼:
public class FactoryObject {
public DmzService getDmz(String name, int age, Date birthDay, OrderService orderService) {
System.out.println("getDmz with "+"name,age,birthDay and orderService");
return new DmzService();
}
public DmzService getDmz(String name, int age, Date birthDay) {
System.out.println("getDmz with "+"name,age,birthDay");
return new DmzService();
}
public DmzService getDmz(String name, int age) {
System.out.println("getDmz with "+"name,age");
return new DmzService();
}
public DmzService getDmz() {
System.out.println("getDmz with empty arg");
return new DmzService();
}
public static IndexService staticGetIndex() {
return new IndexService();
}
}
public class DmzService {
}
public class IndexService {
}
public class OrderService {
}
public class ConverterStr2Date implements Converter<String, Date> {
@Override
public Date convert(String source) {
try {
return new SimpleDateFormat("yyyy-MM-dd").parse(source);
} catch (ParseException e) {
return null;
}
}
}
/**
* @author 程序員DMZ
* @Date Create in 23:14 2020/5/21
* @Blog https://daimingzhi.blog.csdn.net/
*/
public class Main {
public static void main(String[] args) {
ClassPathXmlApplicationContext cc = new ClassPathXmlApplicationContext();
cc.setConfigLocation("application.xml");
cc.refresh();
cc.getBean("dmzService");
// 兩次調用,用於測試緩存的方法及參數
// cc.getBean("dmzService");
}
}
運行上面的代碼會發現,程序打印:
getDmz with name,age,birthDay and orderService
具體原因我相信你看了接下來的源碼分析自然就懂了
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代碼:到這裏已經得到了一個BeanWrapper,並對這個BeanWrapper做了初始化
// 第二段代碼:明確了實例化當前這個Bean到底是靜態工廠還是實例工廠
// 第三段代碼:以及從緩存中取過了對應了方法以及參數
// 進入第四段代碼分析,執行到這段代碼說明是第一次實例化這個對象
if (factoryMethodToUse == null || argsToUse == null) {
// 如果被cglib代理的話,獲取父類的class
factoryClass = ClassUtils.getUserClass(factoryClass);
// 獲取到工廠類中的所有方法,接下來要一步步從這些方法中篩選出來符合要求的方法
Method[] rawCandidates = getCandidateMethods(factoryClass, mbd);
List<Method> candidateList = new ArrayList<>();
// 第一步篩選:之前 在第二段代碼中已經推斷了方法是靜態或者非靜態的
// 所以這裏第一個要求就是要滿足靜態/非靜態這個條件
// 第二個要求就是必須符合bd中定義的factoryMethodName的名稱
// 其中第二個要求請注意,如果bd是一個configurationClassBeanDefinition,也就是說是通過掃描@Bean註解產生的,那麼在判斷時還會添加是否標註了@Bean註解
for (Method candidate : rawCandidates) {
if (Modifier.isStatic(candidate.getModifiers()) == isStatic && mbd.isFactoryMethod(candidate)) {
candidateList.add(candidate);
}
}
// 將之前得到的方法集合轉換成數組
// 到這一步得到的其實就是某一個方法的所有重載方法
// 比如dmz(),dmz(String name),dmz(String name,int age)
Method[] candidates = candidateList.toArray(new Method[0]);
// 排序,public跟參數多的優先級越高
AutowireUtils.sortFactoryMethods(candidates);
// 用來保存從配置文件中解析出來的參數
ConstructorArgumentValues resolvedValues = null;
// 是否使用了自動注入,本段代碼中沒有使用到這個屬性,但是在後面用到了
boolean autowiring = (mbd.getResolvedAutowireMode() == AutowireCapableBeanFactory.AUTOWIRE_CONSTRUCTOR);
int minTypeDiffWeight = Integer.MAX_VALUE;
// 可能出現多個符合要求的方法,用這個集合保存,實際上如果這個集合有值,就會拋出異常了
Set<Method> ambiguousFactoryMethods = null;
int minNrOfArgs;
// 必定為null,不考慮了
if (explicitArgs != null) {
minNrOfArgs = explicitArgs.length;
}
else {
// 就是說配置文件中指定了要使用的參數,那麼需要對其進行解析,解析后的值就存儲在resolvedValues這個集合中
if (mbd.hasConstructorArgumentValues()) {
// 通過解析constructor-arg標籤,將參數封裝成了ConstructorArgumentValues
// ConstructorArgumentValues這個類在下文我們專門分析
ConstructorArgumentValues cargs = mbd.getConstructorArgumentValues();
resolvedValues = new ConstructorArgumentValues();
// 解析標籤中的屬性,類似進行類型轉換,後文進行詳細分析
minNrOfArgs = resolveConstructorArguments(beanName, mbd, bw, cargs, resolvedValues);
}
else {
// 配置文件中沒有指定要使用的參數,所以執行方法的最小參數個數就是0
minNrOfArgs = 0;
}
}
// 省略後續代碼....
}
小總結:
因為在實例化對象前必定要先確定具體要使用的方法,所以這裏先做的第一件事就是確定要在哪個範圍內去推斷要使用的factoryMethod呢?
最大的範圍就是這個factoryClass的所有方法,也就是源碼中的
rawCandidates其次需要在
rawCandidates中進一步做推斷,因為在前面第二段代碼的時候已經確定了是靜態方法還是非靜態方法,並且BeanDefinition也指定了factoryMethodName,那麼基於這兩個條件這裏就需要對rawCandidates進一步進行篩選,得到一個candidateList集合。我們對示例的代碼進行調試會發現
確實如我們所料,
rawCandidates是factoryClass中的所有方法,candidateList是所有getDmz的重載方法。在確定了推斷factoryMethod的範圍后,那麼接下來要根據什麼去確定到底使用哪個方法呢?換個問題,怎麼區分這麼些重載的方法呢?肯定是根據方法參數嘛!
所以接下來要做的就是去解析要使用的參數了~
對於Spring而言,方法的參數會分為兩種
- 配置文件中指定的
- 自動注入模式下,需要去容器中查找的
在上面的代碼中,Spring就是將配置文件中指定的參數做了一次解析,對應方法就是
resolveConstructorArguments。在查看這個方法的源碼前,我們先看看
ConstructorArgumentValues這個類public class ConstructorArgumentValues { // 通過下標方式指定的參數 private final Map<Integer, ValueHolder> indexedArgumentValues = new LinkedHashMap<>(); // 沒有指定下標 private final List<ValueHolder> genericArgumentValues = new ArrayList<>(); // 省略無關代碼..... }在前文的註釋中我們也說過了,它主要的作用就是封裝解析
constructor-arg標籤得到的屬性,解析標籤對應的方法就是org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parseConstructorArgElement,這個方法我就不帶大家看了,有興趣的可以自行閱讀。它主要有兩個屬性
- indexedArgumentValues
- genericArgumentValues
對應的就是我們兩種指定參數的方法,如下:
<bean id="dmzService" factory-bean="factoryObject" factory-method="getDmz" scope="prototype"> <constructor-arg name="name" value="dmz"/> <constructor-arg name="age" value="18"/> <constructor-arg index="2" value="2020-05-23"/> <!-- <constructor-arg name="birthDay" value="2020-05-23"/>--> </bean>其中的name跟age屬性會被解析為
genericArgumentValues,而index=2會被解析為indexedArgumentValues。在對
ConstructorArgumentValues有一定認知之後,我們再來看看resolveConstructorArguments的代碼:// 方法目的:解析配置文件中指定的方法參數 // beanName:bean名稱 // mbd:beanName對應的beanDefinition // bw:通過它進行類型轉換 // ConstructorArgumentValues cargs:解析標籤得到的屬性,還沒有經過解析(類型轉換) // ConstructorArgumentValues resolvedValues:已經經過解析的參數 // 返回值:返回方法需要的最小參數個數 private int resolveConstructorArguments(String beanName, RootBeanDefinition mbd, BeanWrapper bw, ConstructorArgumentValues cargs, ConstructorArgumentValues resolvedValues) { // 是否有定製的類型轉換器,沒有的話直接使用BeanWrapper進行類型轉換 TypeConverter customConverter = this.beanFactory.getCustomTypeConverter(); TypeConverter converter = (customConverter != null ? customConverter : bw); // 構造一個BeanDefinitionValueResolver,專門用於解析constructor-arg中的value屬性,實際上還包括ref屬性,內嵌bean標籤等等 BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this.beanFactory, beanName, mbd, converter); // minNrOfArgs 記錄執行方法要求的最小參數個數,一般情況下就是等於constructor-arg標籤指定的參數數量 int minNrOfArgs = cargs.getArgumentCount(); for (Map.Entry<Integer, ConstructorArgumentValues.ValueHolder> entry : cargs.getIndexedArgumentValues().entrySet()) { int index = entry.getKey(); if (index < 0) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid constructor argument index: " + index); } // 這是啥意思呢? // 這個代碼我認為是有問題的,並且我給Spring官方已經提了一個issue,官方將會在5.2.7版本中修復 // 暫且你先這樣理解 // 假設A方法直接在配置文件中指定了index=3上要使用的參數,那麼這個時候A方法至少需要4個參數 // 但是其餘的3個參數可能不是通過constructor-arg標籤指定的,而是直接自動注入進來的,那麼在配置文件中我們就只配置了index=3上的參數,也就是說 int minNrOfArgs = cargs.getArgumentCount()=1,這個時候 index=3,minNrOfArgs=1, 所以 minNrOfArgs = 3+1 if (index > minNrOfArgs) { minNrOfArgs = index + 1; } ConstructorArgumentValues.ValueHolder valueHolder = entry.getValue(); // 如果已經轉換過了,直接添加到resolvedValues集合中 if (valueHolder.isConverted()) { resolvedValues.addIndexedArgumentValue(index, valueHolder); } else { // 解析value/ref/內嵌bean標籤等 Object resolvedValue = valueResolver.resolveValueIfNecessary("constructor argument", valueHolder.getValue()); // 將解析后的resolvedValue封裝成一個新的ValueHolder,並將其source設置為解析constructor-arg得到的那個ValueHolder,後期會用到這個屬性進行判斷 ConstructorArgumentValues.ValueHolder resolvedValueHolder = new ConstructorArgumentValues.ValueHolder(resolvedValue, valueHolder.getType(), valueHolder.getName()); resolvedValueHolder.setSource(valueHolder); resolvedValues.addIndexedArgumentValue(index, resolvedValueHolder); } } // 對getGenericArgumentValues進行解析,代碼基本一樣,不再贅述 return minNrOfArgs; }可以看到,最終的解析邏輯就在
resolveValueIfNecessary這個方法中,那麼這個方法又做了什麼呢?// 這個方法的目的就是將解析constructor-arg標籤得到的value值進行一次解析 // 在解析標籤時ref屬性會被封裝為RuntimeBeanReference,那麼在這裏進行解析時就會去調用getBean // 在解析value屬性會會被封裝為TypedStringValue,那麼這裡會嘗試去進行一個轉換 // 關於標籤的解析大家有興趣的話可以去看看org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parsePropertyValue // 這裏不再贅述了 public Object resolveValueIfNecessary(Object argName, @Nullable Object value) { // 解析constructor-arg標籤中的ref屬性,實際就是調用了getBean if (value instanceof RuntimeBeanReference) { RuntimeBeanReference ref = (RuntimeBeanReference) value; return resolveReference(argName, ref); } // ...... /** * <constructor-arg> * <set value-type="java.lang.String"> * <value>1</value> * </set> * </constructor-arg> * 通過上面set標籤中的value-type屬性對value進行類型轉換, * 如果value-type屬性為空,那麼這裏不會進行類型轉換 */ else if (value instanceof TypedStringValue) { TypedStringValue typedStringValue = (TypedStringValue) value; Object valueObject = evaluate(typedStringValue); try { Class<?> resolvedTargetType = resolveTargetType(typedStringValue); if (resolvedTargetType != null) { return this.typeConverter.convertIfNecessary(valueObject, resolvedTargetType); } else { return valueObject; } } catch (Throwable ex) { // Improve the message by showing the context. throw new BeanCreationException( this.beanDefinition.getResourceDescription(), this.beanName, "Error converting typed String value for " + argName, ex); } } // 省略後續代碼.... }就我們上面的例子而言,經過
resolveValueIfNecessary方法並不能產生實際的影響,因為在XML中我們沒有配置ref屬性或者value-type屬性。畫圖如下:
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代碼:到這裏已經得到了一個BeanWrapper,並對這個BeanWrapper做了初始化
// 第二段代碼:明確了實例化當前這個Bean到底是靜態工廠還是實例工廠
// 第三段代碼:以及從緩存中取過了對應了方法以及參數
// 第四段代碼:明確了方法需要的最小的參數數量並對配置文件中的標籤屬性進行了一次解析
// 進入第五段代碼分析
// 保存在創建方法參數數組過程中發生的異常,如果最終沒有找到合適的方法,那麼將這個異常信息封裝后拋出
LinkedList<UnsatisfiedDependencyException> causes = null;
// 開始遍歷所有在第四段代碼中查詢到的符合要求的方法
for (Method candidate : candidates) {
// 方法的參數類型
Class<?>[] paramTypes = candidate.getParameterTypes();
// 候選的方法的參數必須要大於在第四段這推斷出來的最小參數個數
if (paramTypes.length >= minNrOfArgs) {
ArgumentsHolder argsHolder;
// 必定為null,不考慮
if (explicitArgs != null) {
// Explicit arguments given -> arguments length must match exactly.
if (paramTypes.length != explicitArgs.length) {
continue;
}
argsHolder = new ArgumentsHolder(explicitArgs);
}
else {
// Resolved constructor arguments: type conversion and/or autowiring necessary.
try {
// 獲取參數的具體名稱
String[] paramNames = null;
ParameterNameDiscoverer pnd = this.beanFactory.getParameterNameDiscoverer();
if (pnd != null) {
paramNames = pnd.getParameterNames(candidate);
}
// 根據方法的參數名稱以及配置文件中配置的參數創建一個參數數組用於執行工廠方法
argsHolder = createArgumentArray(
beanName, mbd, resolvedValues, bw, paramTypes, paramNames, candidate, autowiring);
}
// 在創建參數數組的時候可能發生異常,這個時候的異常不能直接拋出,要確保所有的候選方法遍歷完成,只要有一個方法符合要求即可,但是如果遍歷完所有方法還是沒找到合適的構造器,那麼直接拋出這些異常
catch (UnsatisfiedDependencyException ex) {
if (logger.isTraceEnabled()) {
logger.trace("Ignoring factory method [" + candidate + "] of bean '" + beanName + "': " + ex);
}
// Swallow and try next overloaded factory method.
if (causes == null) {
causes = new LinkedList<>();
}
causes.add(ex);
continue;
}
// 計算類型差異
// 首先判斷bd中是寬鬆模式還是嚴格模式,目前看來只有@Bean標註的方法解析得到的Bean會使用嚴格模式來計算類型差異,其餘都是使用寬鬆模式
// 嚴格模式下,
int typeDiffWeight = (mbd.isLenientConstructorResolution() ?
argsHolder.getTypeDifferenceWeight(paramTypes) : argsHolder.getAssignabilityWeight(paramTypes));
// 選擇一個類型差異最小的方法
if (typeDiffWeight < minTypeDiffWeight) {
factoryMethodToUse = candidate;
argsHolderToUse = argsHolder;
argsToUse = argsHolder.arguments;
minTypeDiffWeight = typeDiffWeight;
ambiguousFactoryMethods = null;
}
// 省略後續代碼.......
}
小總結:這段代碼的核心思想就是根據
第四段代碼從配置文件中解析出來的參數構造方法執行所需要的實際參數數組。如果構建成功就代表這個方法可以用於實例化Bean,然後計算實際使用的參數跟方法上申明的參數的”差異值“,並在所有符合要求的方法中選擇一個差異值最小的方法接下來,我們來分析方法實現的細節
- 構建方法使用的參數數組,也就是
createArgumentArray方法,其源碼如下:/* beanName:要實例化的Bean的名稱 * mbd:對應Bean的BeanDefinition * resolvedValues:從配置文件中解析出來的並嘗試過類型轉換的參數 * bw:在這裏主要就是用作類型轉換器 * paramTypes:當前遍歷到的候選的方法的參數類型數組 * paramNames:當前遍歷到的候選的方法的參數名稱 * executable:當前遍歷到的候選的方法 * autowiring:是否時自動注入 */ private ArgumentsHolder createArgumentArray( String beanName, RootBeanDefinition mbd, @Nullable ConstructorArgumentValues resolvedValues, BeanWrapper bw, Class<?>[] paramTypes, @Nullable String[] paramNames, Executable executable, boolean autowiring) throws UnsatisfiedDependencyException { TypeConverter customConverter = this.beanFactory.getCustomTypeConverter(); TypeConverter converter = (customConverter != null ? customConverter : bw); ArgumentsHolder args = new ArgumentsHolder(paramTypes.length); Set<ConstructorArgumentValues.ValueHolder> usedValueHolders = new HashSet<>(paramTypes.length); Set<String> autowiredBeanNames = new LinkedHashSet<>(4); // 遍歷候選方法的參數,跟據方法實際需要的類型到resolvedValues中去匹配 for (int paramIndex = 0; paramIndex < paramTypes.length; paramIndex++) { Class<?> paramType = paramTypes[paramIndex]; String paramName = (paramNames != null ? paramNames[paramIndex] : ""); ConstructorArgumentValues.ValueHolder valueHolder = null; if (resolvedValues != null) { // 首先,根據方法參數的下標到resolvedValues中找對應的下標的屬性 // 如果沒找到再根據方法的參數名/類型去resolvedValues查找 valueHolder = resolvedValues.getArgumentValue(paramIndex, paramType, paramName, usedValueHolders); // 如果都沒找到 // 1.是自動注入並且方法的參數長度正好跟配置中的參數數量相等 // 2.不是自動注入 // 那麼按照順序一次選取 if (valueHolder == null && (!autowiring || paramTypes.length == resolvedValues.getArgumentCount())) { valueHolder = resolvedValues.getGenericArgumentValue(null, null, usedValueHolders); } } // 也就是說在配置的參數中找到了合適的值可以應用於這個方法上 if (valueHolder != null) { // 防止同一個參數被應用了多次 usedValueHolders.add(valueHolder); Object originalValue = valueHolder.getValue(); Object convertedValue; // 已經進行過類型轉換就不會需要再次進行類型轉換 if (valueHolder.isConverted()) { convertedValue = valueHolder.getConvertedValue(); args.preparedArguments[paramIndex] = convertedValue; } else { // 嘗試將配置的值轉換成方法參數需要的類型 MethodParameter methodParam = MethodParameter.forExecutable(executable, paramIndex); try { // 進行類型轉換 convertedValue = converter.convertIfNecessary(originalValue, paramType, methodParam); } catch (TypeMismatchException ex) { // 拋出UnsatisfiedDependencyException,在調用該方法處會被捕獲 } Object sourceHolder = valueHolder.getSource(); // 只要是valueHolder存在,到這裏這個判斷必定成立 if (sourceHolder instanceof ConstructorArgumentValues.ValueHolder) { Object sourceValue = ((ConstructorArgumentValues.ValueHolder) sourceHolder).getValue(); args.resolveNecessary = true; args.preparedArguments[paramIndex] = sourceValue; } } args.arguments[paramIndex] = convertedValue; args.rawArguments[paramIndex] = originalValue; } else { // 方法執行需要參數,但是resolvedValues中沒有提供這個參數,也就是說這個參數是要自動注入到Bean中的 MethodParameter methodParam = MethodParameter.forExecutable(executable, paramIndex); // 不是自動注入,直接拋出異常 if (!autowiring) { // 拋出UnsatisfiedDependencyException,在調用該方法處會被捕獲 } try { // 自動注入的情況下,調用getBean獲取需要注入的Bean Object autowiredArgument = resolveAutowiredArgument(methodParam, beanName, autowiredBeanNames, converter); // 把getBean返回的Bean封裝到本次方法執行時需要的參數數組中去 args.rawArguments[paramIndex] = autowiredArgument; args.arguments[paramIndex] = autowiredArgument; // 標誌這個參數是自動注入的 args.preparedArguments[paramIndex] = new AutowiredArgumentMarker(); // 自動注入的情況下,在第二次調用時,需要重新處理,不能直接緩存 args.resolveNecessary = true; } catch (BeansException ex) { // 拋出UnsatisfiedDependencyException,在調用該方法處會被捕獲 } } } // 註冊Bean之間的依賴關係 for (String autowiredBeanName : autowiredBeanNames) { this.beanFactory.registerDependentBean(autowiredBeanName, beanName); if (logger.isDebugEnabled()) { logger.debug("Autowiring by type from bean name '" + beanName + "' via " + (executable instanceof Constructor ? "constructor" : "factory method") + " to bean named '" + autowiredBeanName + "'"); } } return args; }上面這段代碼說難也難,說簡單也簡單,如果要徹底看懂它到底幹了什麼還是很有難度的。簡單來說,它就是從第四段代碼解析出來的參數中查找當前的這個候選方法需要的參數。如果找到了,那麼嘗試對其進行類型轉換,將其轉換成符合方法要求的類型,如果沒有找到那麼還需要判斷當前方法的這個參數能不能進行自動注入,如果可以自動注入的話,那麼調用getBean得到需要的Bean,並將其注入到方法需要的參數中。
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
// 第一段代碼:到這裏已經得到了一個BeanWrapper,並對這個BeanWrapper做了初始化
// 第二段代碼:明確了實例化當前這個Bean到底是靜態工廠還是實例工廠
// 第三段代碼:以及從緩存中取過了對應了方法以及參數
// 第四段代碼:明確了方法需要的最小的參數數量並對配置文件中的標籤屬性進行了一次解析
// 第五段代碼:到這裏已經確定了可以使用來實例化Bean的方法是哪個
// 省略拋出異常的代碼,就是在對推斷出來的方法做驗證
// 1.推斷出來的方法不能為null
// 2.推斷出來的方法返回值不能為void
// 3.推斷出來的方法不能有多個
// 對參數進行緩存
if (explicitArgs == null && argsHolderToUse != null) {
argsHolderToUse.storeCache(mbd, factoryMethodToUse);
}
}
try {
Object beanInstance;
if (System.getSecurityManager() != null) {
final Object fb = factoryBean;
final Method factoryMethod = factoryMethodToUse;
final Object[] args = argsToUse;
beanInstance = AccessController.doPrivileged((PrivilegedAction<Object>) () ->
beanFactory.getInstantiationStrategy().instantiate(mbd, beanName, beanFactory, fb, factoryMethod, args),
beanFactory.getAccessControlContext());
}
else {
// 反射調用對應方法進行實例化
// 1.獲取InstantiationStrategy,主要就是SimpleInstantiationStrategy跟CglibSubclassingInstantiationStrategy,其中CglibSubclassingInstantiationStrategy主要是用來處理beanDefinition中的lookupMethod跟replaceMethod。通常來說我們使用的就是SimpleInstantiationStrateg
// 2.SimpleInstantiationStrateg就是單純的通過反射調用方法
beanInstance = this.beanFactory.getInstantiationStrategy().instantiate(
mbd, beanName, this.beanFactory, factoryBean, factoryMethodToUse, argsToUse);
}
// beanWrapper在這裏對Bean進行了包裝
bw.setBeanInstance(beanInstance);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean instantiation via factory method failed", ex);
}
}
上面這段代碼的主要目的就是
- 緩存參數,原型可能多次創建同一個對象
- 反射調用推斷出來的factoryMethod
如果上面你對使用factoryMethd進行實例化對象已經足夠了解的話,那麼下面的源碼分析基本沒有什麼很大區別,我們接着看看代碼。
首先,我們回到createBeanInstance方法中,
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
// 上面的代碼已經分析過了
// 1.使用supplier來得到一個對象
// 2.通過factotryMethod方法實例化一個對象
// 看起來是不是有點熟悉,在使用factotryMethod創建對象時也有差不多這樣的一段代碼,看起來就是使用緩存好的方法直接創建一個對象
boolean resolved = false;
boolean autowireNecessary = false;
// 不對這個參數進行討論,就認為一直為null
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
// bd中的resolvedConstructorOrFactoryMethod不為空,說明已經解析過構造方法了
if (mbd.resolvedConstructorOrFactoryMethod != null) {
// resolved標誌是否解析過構造方法
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
// 構造函數已經解析過了,並且這個構造函數在調用時需要自動注入參數
if (autowireNecessary) {
// 此時部分解析好的參數已經存在了beanDefinition中,並且構造函數也在bd中
// 那麼在這裏只會從緩存中去取構造函數以及參數然後反射調用
return autowireConstructor(beanName, mbd, null, null);
}
else {
// 這裏就是直接反射調用空參構造
return instantiateBean(beanName, mbd);
}
}
// 推斷出能夠使用的需要參數的構造函數
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
// 在推斷出來的構造函數中選取一個合適的方法來進行Bean的實例化
// ctors不為null:說明存在1個或多個@Autowired標註的方法
// mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR:說明是自動注入
// mbd.hasConstructorArgumentValues():配置文件中配置了構造函數要使用的參數
// !ObjectUtils.isEmpty(args):外部傳入的參數,必定為null,不多考慮
// 上面的條件只要滿足一個就會進入到autowireConstructor方法
// 第一個條件滿足,那麼通過autowireConstructor在推斷出來的構造函數中再進一步選擇一個差異值最小的,參數最長的構造函數
// 第二個條件滿足,說明沒有@Autowired標註的方法,但是需要進行自動注入,那麼通過autowireConstructor會去遍歷類中申明的所有構造函數,並查找一個差異值最小的,參數最長的構造函數
// 第三個條件滿足,說明不是自動注入,那麼要通過配置中的參數去類中申明的所有構造函數中匹配
// 第四個必定為null,不考慮
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// 反射調用空參構造
return instantiateBean(beanName, mbd);
}
因為autowireConstructor方法的執行邏輯跟instantiateUsingFactoryMethod方法的執行邏輯基本一致,只是將Method對象換成了Constructor對象,所以對這個方法我不再做詳細的分析。
我們主要就看看determineConstructorsFromBeanPostProcessors這個方法吧,這個方法的主要目的就是推斷出候選的構造方法。
// 實際調用的就是AutowiredAnnotationBeanPostProcessor中的determineCandidateConstructors方法
// 這個方法看起來很長,但實際確很簡單,就是通過@Autowired註解確定哪些構造方法可以作為候選方法,其實在使用factoryMethod來實例化對象的時候也有這種邏輯在其中,後續在總結的時候我們對比一下
public Constructor<?>[] determineCandidateConstructors(Class<?> beanClass, final String beanName)
throws BeanCreationException {
// 這裏做的事情很簡單,就是將@Lookup註解標註的方法封裝成LookupOverride添加到BeanDefinition中的methodOverrides屬性中,如果這個屬性不為空,在實例化對象的時候不能選用SimpleInstantiationStrateg,而要使用CglibSubclassingInstantiationStrategy,通過cglib代理給方法加一層攔截了邏輯
// 避免重複檢查
if (!this.lookupMethodsChecked.contains(beanName)) {
try {
ReflectionUtils.doWithMethods(beanClass, method -> {
Lookup lookup = method.getAnnotation(Lookup.class);
if (lookup != null) {
Assert.state(this.beanFactory != null, "No BeanFactory available"); // 將@Lookup註解標註的方法封裝成LookupOverride
LookupOverride override = new LookupOverride(method, lookup.value());
try {
// 添加到BeanDefinition中的methodOverrides屬性中
RootBeanDefinition mbd = (RootBeanDefinition)
this.beanFactory.getMergedBeanDefinition(beanName);
mbd.getMethodOverrides().addOverride(override);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(beanName,
"Cannot apply @Lookup to beans without corresponding bean definition");
}
}
});
}
catch (IllegalStateException ex) {
throw new BeanCreationException(beanName, "Lookup method resolution failed", ex);
}
this.lookupMethodsChecked.add(beanName);
}
// 接下來要開始確定到底哪些構造函數能被作為候選者
// 先嘗試從緩存中獲取
Constructor<?>[] candidateConstructors = this.candidateConstructorsCache.get(beanClass);
if (candidateConstructors == null) {
// Fully synchronized resolution now...
synchronized (this.candidateConstructorsCache) {
candidateConstructors = this.candidateConstructorsCache.get(beanClass);、
// 緩存中無法獲取到,進入正式的推斷過程
if (candidateConstructors == null) {
Constructor<?>[] rawCandidates;
try {
// 第一步:先查詢這個類所有的構造函數,包括私有的
rawCandidates = beanClass.getDeclaredConstructors();
}
catch (Throwable ex) {
// 省略異常信息
}
List<Constructor<?>> candidates = new ArrayList<>(rawCandidates.length);
// 保存添加了Autowired註解並且required屬性為true的構造方法
Constructor<?> requiredConstructor = null;
// 空參構造
Constructor<?> defaultConstructor = null;
// 看方法註釋上說明的,這裏除非是kotlin的類,否則必定為null,不做過多考慮,我們就將其當作null
Constructor<?> primaryConstructor = BeanUtils.findPrimaryConstructor(beanClass);
int nonSyntheticConstructors = 0;
// 對類中的所有構造方法進行遍歷
for (Constructor<?> candidate : rawCandidates) {
// 非合成方法
if (!candidate.isSynthetic()) {
nonSyntheticConstructors++;
}
else if (primaryConstructor != null) {
continue;
}
// 查詢方法上是否有Autowired註解
AnnotationAttributes ann = findAutowiredAnnotation(candidate);
if (ann == null) {
// userClass != beanClass說明這個類進行了cglib代理
Class<?> userClass = ClassUtils.getUserClass(beanClass);
if (userClass != beanClass) {
try {
// 如果進行了cglib代理,那麼在父類上再次查找Autowired註解
Constructor<?> superCtor =
userClass.getDeclaredConstructor(candidate.getParameterTypes());
ann = findAutowiredAnnotation(superCtor);
}
catch (NoSuchMethodException ex) {
// Simply proceed, no equivalent superclass constructor found...
}
}
}
// 說明當前的這個構造函數上有Autowired註解
if (ann != null) {
if (requiredConstructor != null) {
// 省略異常拋出
}
// 獲取Autowired註解中的required屬性
boolean required = determineRequiredStatus(ann);
if (required) {
// 類中存在多個@Autowired標註的方法,並且某個方法的@Autowired註解上被申明了required屬性要為true,那麼直接報錯
if (!candidates.isEmpty()) {
// 省略異常拋出
}
requiredConstructor = candidate;
}
// 添加到集合中,這個集合存儲的都是被@Autowired註解標註的方法
candidates.add(candidate);
}
// 空參構造函數
else if (candidate.getParameterCount() == 0) {
defaultConstructor = candidate;
}
}
if (!candidates.isEmpty()) {
// 存在多個被@Autowired標註的方法
// 並且所有的required屬性被設置成了false (默認為true)
if (requiredConstructor == null) {
// 存在空參構造函數,注意,空參構造函數可以不被@Autowired註解標註
if (defaultConstructor != null) {
// 將空參構造函數也加入到候選的方法中去
candidates.add(defaultConstructor);
}
// 省略日誌打印
}
candidateConstructors = candidates.toArray(new Constructor<?>[0]);
}
// 也就是說,類中只提供了一個構造函數,並且這個構造函數不是空參構造函數
else if (rawCandidates.length == 1 && rawCandidates[0].getParameterCount() > 0) {
candidateConstructors = new Constructor<?>[] {rawCandidates[0]};
}
// 省略中間兩個判斷,primaryConstructor必定為null,不考慮
// .....
}
else {
// 說明無法推斷出來
candidateConstructors = new Constructor<?>[0];
}
this.candidateConstructorsCache.put(beanClass, candidateConstructors);
}
}
}
return (candidateConstructors.length > 0 ? candidateConstructors : null);
}
這裏我簡單總結下這個方法的作用
獲取到類中的所有構造函數
查找到被
@Autowired註解標註的構造函數
- 如果存在多個被
@Autowired標註的構造函數,並且其required屬性沒有被設置為true,那麼返回這些被標註的函數的集合(空參構造即使沒有添加@Autowired也會被添加到集合中)- 如果存在多個被
@Autowired標註的構造函數,並且其中一個的required屬性被設置成了true,那麼直接報錯- 如果只有一個構造函數被
@Autowired標註,並且其required屬性被設置成了true,那麼直接返回這個構造函數如果沒有被
@Autowired標註標註的構造函數,但是類中有且只有一個構造函數,並且這個構造函數不是空參構造函數,那麼返回這個構造函數上面的條件都不滿足,那麼
determineCandidateConstructors這個方法就無法推斷出合適的構造函數了
可以看到,通過AutowiredAnnotationBeanPostProcessor的determineCandidateConstructors方法可以處理構造函數上的@Autowired註解。
但是,請注意,這個方法並不能決定到底使用哪個構造函數來創建對象(即使它只推斷出來一個,也不一定能夠使用),它只是通過@Autowired註解來確定構造函數的候選者,在構造函數都沒有添加@Autowired註解的情況下,這個方法推斷不出來任何方法。真正確定到底使用哪個構造函數是交由autowireConstructor方法來決定的。前文已經分析過了instantiateUsingFactoryMethod方法,autowireConstructor的邏輯基本跟它一致,所以這裏不再做詳細的分析。
從上圖中可以看到,整體邏輯上它們並沒有什麼區別,只是查找的對象從factoryMethod換成了構造函數
細節的差異主要體現在推斷方法上
它們之間的差異我已經在圖中標識出來了,主要就是兩點
- 通過構造函數實例化對象,多了一層處理,就是要處理構造函數上的@Autowired註解以及方法上的@LookUp註解(要決定選取哪一種實例化策略,
SimpleInstantiationStrategy/CglibSubclassingInstantiationStrategy)- 在最終的選取也存在差異,對於facotyMehod而言,在寬鬆模式下(
除ConfigurationClassBeanDefinition外,也就是掃描@Bean得到的BeanDefinition,都是寬鬆模式),會選取一個最精準的方法,在嚴格模式下,會選取一個參數最長的方法- 對於構造函數而言,會必定會選取一個參數最長的方法
思考了很久,我還是決定再補充一些內容,就是關於上面兩幅圖的最後一步,對應的核心代碼如下:
int typeDiffWeight = (mbd.isLenientConstructorResolution() ?
argsHolder.getTypeDifferenceWeight(paramTypes) : argsHolder.getAssignabilityWeight(paramTypes));
if (typeDiffWeight < minTypeDiffWeight) {
factoryMethodToUse = candidate;
argsHolderToUse = argsHolder;
argsToUse = argsHolder.arguments;
minTypeDiffWeight = typeDiffWeight;
ambiguousFactoryMethods = null;
}
判斷bd是嚴格模式還是寬鬆模式,上面說過很多次了,bd默認就是寬鬆模式,只要在ConfigurationClassBeanDefinition中使用嚴格模式,也就是掃描@Bean標註的方法註冊的bd(對應的代碼可以參考:org.springframework.context.annotation.ConfigurationClassBeanDefinitionReader#loadBeanDefinitionsForBeanMethod方法)
我們再看看嚴格模式跟寬鬆模式在計算差異值時的區別
public int getTypeDifferenceWeight(Class<?>[] paramTypes) {
// 計算實際使用的參數跟方法申明的參數的差異值
int typeDiffWeight = MethodInvoker.getTypeDifferenceWeight(paramTypes, this.arguments);
// 計算沒有經過類型轉換的參數跟方法申明的參數的差異值
int rawTypeDiffWeight = MethodInvoker.getTypeDifferenceWeight(paramTypes, this.rawArguments) - 1024;
return (rawTypeDiffWeight < typeDiffWeight ? rawTypeDiffWeight : typeDiffWeight);
}
public static int getTypeDifferenceWeight(Class<?>[] paramTypes, Object[] args) {
int result = 0;
for (int i = 0; i < paramTypes.length; i++) {
// 在出現類型轉換時,下面這個判斷才會成立,也就是在比較rawArguments跟paramTypes的差異時才可能滿足這個條件
if (!ClassUtils.isAssignableValue(paramTypes[i], args[i])) {
return Integer.MAX_VALUE;
}
if (args[i] != null) {
Class<?> paramType = paramTypes[i];
Class<?> superClass = args[i].getClass().getSuperclass();
while (superClass != null) {
// 如果我們傳入的值是方法上申明的參數的子類,那麼每多一層繼承關係,差異值加2
if (paramType.equals(superClass)) {
result = result + 2;
superClass = null;
}
else if (ClassUtils.isAssignable(paramType, superClass)) {
result = result + 2;
superClass = superClass.getSuperclass();
}
else {
superClass = null;
}
}
// 判斷方法的參數是不是一個接口,如果是,那麼差異值加1
if (paramType.isInterface()) {
result = result + 1;
}
}
}
return result;
}
public int getAssignabilityWeight(Class<?>[] paramTypes) {
// 嚴格模式下,只有三種返回值
// 1.Integer.MAX_VALUE,經過類型轉換后還是不符合要求,返回最大的類型差異
// 因為解析后的參數可能返回一個NullBean(創建對象的方法返回了null,Spring會將其包裝成一個NullBean),不過一般不會出現這種情況,所以我們可以當這種情況不存在
for (int i = 0; i < paramTypes.length; i++) {
if (!ClassUtils.isAssignableValue(paramTypes[i], this.arguments[i])) {
return Integer.MAX_VALUE;
}
}
// 2.Integer.MAX_VALUE - 512,進行過了類型轉換才符合要求
for (int i = 0; i < paramTypes.length; i++) {
if (!ClassUtils.isAssignableValue(paramTypes[i], this.rawArguments[i])) {
return Integer.MAX_VALUE - 512;
}
}
// 3.Integer.MAX_VALUE - 1024,沒有經過類型轉換就已經符合要求了,返回最小的類型差異
return Integer.MAX_VALUE - 1024;
}
首先,不管是factoryMethod還是constructor,都是採用上面的兩個方法來計算類型差異,但是正常來說,只有factoryMethod會採用到嚴格模式(除非程序員手動干預,比如通過Bean工廠後置處理器修改了bd中的屬性,這樣通常來說沒有很大意義)
所以我們分為三種情況討論
這種情況下,會選取一個最精確的方法,同時方法的參數要盡量長
測試代碼:
public class FactoryObject {
public DmzService getDmz() {
System.out.println(0);
return new DmzService();
}
public DmzService getDmz(OrderService indexService) {
System.out.println(1);
return new DmzService();
}
public DmzService getDmz(OrderService orderService, IndexService indexService) {
System.out.println(2);
return new DmzService();
}
public DmzService getDmz(OrderService orderService, IndexService indexService,IA ia) {
System.out.println(3);
return new DmzService();
}
}
public class ServiceImpl implements IService {
}
public class IAImpl implements IA {
}
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"
default-autowire="constructor"><!--必須要開啟自動注入,並且是通過構造函數進行自動注入,否則選用無參構造-->
<!--factoryObject 提供了創建對象的方法-->
<bean id="factoryObject" class="com.dmz.spring.instantiation.service.FactoryObject"/>
<bean class="com.dmz.spring.instantiation.service.OrderService" id="orderService"/>
<bean id="dmzService" factory-bean="factoryObject" factory-method="getDmz" />
<bean class="com.dmz.spring.instantiation.service.ServiceImpl" id="iService"/>
<bean class="com.dmz.spring.instantiation.service.IndexService" id="indexService"/>
</beans>
/**
* @author 程序員DMZ
* @Date Create in 23:59 2020/6/1
* @Blog https://daimingzhi.blog.csdn.net/
*/
public class XMLMain {
public static void main(String[] args) {
ClassPathXmlApplicationContext cc =
new ClassPathXmlApplicationContext("application.xml");
}
}
運行程序發現,選用了第三個(getDmz(OrderService orderService, IndexService indexService))構造方法。雖然最後一個方法的參數更長,但是因為其方法申明的參數上存在接口,所以它的差異值會大於第三個方法,因為不會被選用
這種情況下,會選取一個參數盡量長的方法
測試代碼:
/**
* @author 程序員DMZ
* @Date Create in 6:28 2020/6/1
* @Blog https://daimingzhi.blog.csdn.net/
*/
@ComponentScan("com.dmz.spring.instantiation")
@Configuration
public class Config {
@Bean
public DmzService dmzService() {
System.out.println(0);
return new DmzService();
}
@Bean
public DmzService dmzService(OrderService indexService) {
System.out.println(1);
return new DmzService();
}
@Bean
public DmzService dmzService(OrderService orderService, IndexService indexService) {
System.out.println(2);
return new DmzService();
}
@Bean
public DmzService dmzService(OrderService orderService, IndexService indexService, IA ia) {
System.out.println("config " +3);
return new DmzService();
}
@Bean
public DmzService dmzService(OrderService orderService, IndexService indexService, IA ia, IService iService) {
System.out.println("config " +4);
return new DmzService();
}
}
/**
* @author 程序員DMZ
* @Date Create in 6:29 2020/6/1
* @Blog https://daimingzhi.blog.csdn.net/
*/
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(Config.class);
ac.refresh();
}
}
運行程序,發現選用了最後一個構造函數,這是因為在遍歷候選方法時,會先遍歷參數最長的,而在計算類型差異時,因為嚴格模式下,上面所有方法的差異值都是一樣的,都會返回Integer.MAX_VALUE - 1024。實際上,在不進行手動干預的情況下,都會返滬這個值。
這種情況下,也會選取一個參數盡量長的方法
之所以會這樣,主要是因為在autowireConstructor方法中進行了一次短路判斷,如下所示:
在上圖中,如果已經找到了合適的方法,那麼直接就不會再找了,而在遍歷的時候是從參數最長的方法開始遍歷的,測試代碼如下:
@Component
public class DmzService {
// 沒有添加@Autowired註解,也會被當作候選方法
public DmzService(){
System.out.println(0);
}
@Autowired(required = false)
public DmzService(OrderService orderService) {
System.out.println(1);
}
@Autowired(required = false)
public DmzService(OrderService orderService, IService iService) {
System.out.println(2);
}
@Autowired(required = false)
public DmzService(OrderService orderService, IndexService indexService, IService iService,IA ia) {
System.out.println("DmzService "+3);
}
}
/**
* @author 程序員DMZ
* @Date Create in 6:29 2020/6/1
* @Blog https://daimingzhi.blog.csdn.net/
*/
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(Config.class);
ac.refresh();
}
}
這篇文章就到這裏啦~~!
文章很長,希望你耐心看完,碼字不易,如果有幫助到你的話點個贊吧~!
掃描下方二維碼,關注我的公眾號,更多精彩文章在等您!~~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
本文源碼:GitHub·點這裏 || GitEE·點這裏
版本:kafka2.11,zookeeper3.4
注意:這裏zookeeper3.4也是基於集群模式部署。
tar -zxvf kafka_2.11-0.11.0.0.tgz
mv kafka_2.11-0.11.0.0 kafka2.11
創建日誌目錄
[root@en-master kafka2.11]# mkdir logs
注意:以上操作需要同步到集群下其他服務上。
vim /etc/profile
export KAFKA_HOME=/opt/kafka2.11
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
[root@en-master /opt/kafka2.11/config]# vim server.properties
-- 核心修改如下
# 唯一編號
broker.id=0
# 開啟topic刪除
delete.topic.enable=true
# 日誌地址
log.dirs=/opt/kafka2.11/logs
# zk集群
zookeeper.connect=zk01:2181,zk02:2181,zk03:2181
注意:broker.id安裝集群服務個數編排即可,集群下不能重複。
# 啟動命令
[root@node02 kafka2.11]# bin/kafka-server-start.sh -daemon config/server.properties
# 停止命令
[root@node02 kafka2.11]# bin/kafka-server-stop.sh
# 進程查看
[root@node02 kafka2.11]# jps
注意:這裏默認啟動了zookeeper集群服務,並且集群下的kafka分別啟動。
創建topic
bin/kafka-topics.sh --zookeeper zk01:2181 \
--create --replication-factor 3 --partitions 1 --topic one-topic
參數說明:
查看topic列表
bin/kafka-topics.sh --zookeeper zk01:2181 --list
修改topic分區
bin/kafka-topics.sh --zookeeper zk01:2181 --alter --topic one-topic --partitions 5
查看topic
bin/kafka-topics.sh --zookeeper zk01:2181 \
--describe --topic one-topic
發送消息
bin/kafka-console-producer.sh \
--broker-list 192.168.72.133:9092 --topic one-topic
消費消息
bin/kafka-console-consumer.sh \
--bootstrap-server 192.168.72.133:9092 --from-beginning --topic one-topic
刪除topic
bin/kafka-topics.sh --zookeeper zk01:2181 \
--delete --topic first
Kafka集群中有一個broker會被選舉為Controller,Controller依賴Zookeeper環境,管理集群broker的上下線,所有topic的分區副本分配和leader選舉等工作。
Kafka中間件的Producer攔截器主要用於實現消息發送的自定義控制邏輯。用戶可以在消息發送前以及回調邏輯執行前有機會對消息做一些自定義,比如消息修改等,發送狀態監控等,用戶可以指定多個攔截器按順序執行攔截。
核心方法
注意:這裏說的攔截器是針對消息發送流程。
定義方式:實現ProducerInterceptor接口即可。
攔截器一:在onSend方法中,對攔截的消息進行修改。
@Component
public class SendStartInterceptor implements ProducerInterceptor<String, String> {
private final Logger LOGGER = LoggerFactory.getLogger("SendStartInterceptor");
@Override
public void configure(Map<String, ?> configs) {
LOGGER.info("configs...");
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 修改消息內容
return new ProducerRecord<>(record.topic(), record.partition(),
record.timestamp(), record.key(),
"onSend:{" + record.value()+"}");
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
LOGGER.info("onAcknowledgement...");
}
@Override
public void close() {
LOGGER.info("SendStart close...");
}
}
攔截器二:在onAcknowledgement方法中,判斷消息是否發送成功。
@Component
public class SendOverInterceptor implements ProducerInterceptor<String, String> {
private final Logger LOGGER = LoggerFactory.getLogger("SendOverInterceptor");
@Override
public void configure(Map<String, ?> configs) {
LOGGER.info("configs...");
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
LOGGER.info("record...{}", record.value());
return record ;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (exception != null){
LOGGER.info("Send Fail...exe-msg",exception.getMessage());
}
LOGGER.info("Send success...");
}
@Override
public void close() {
LOGGER.info("SendOver close...");
}
}
加載攔截器:基於一個KafkaProducer配置Bean,加入攔截器。
@Configuration
public class KafkaConfig {
@Bean
public Producer producer (){
Properties props = new Properties();
// 省略其他配置...
// 添加攔截器
List<String> interceptors = new ArrayList<>();
interceptors.add("com.kafka.cluster.interceptor.SendStartInterceptor");
interceptors.add("com.kafka.cluster.interceptor.SendOverInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
return new KafkaProducer<>(props) ;
}
}
@RestController
public class SendMsgWeb {
@Resource
private KafkaProducer<String,String> producer ;
@GetMapping("/sendMsg")
public String sendMsg (){
producer.send(new ProducerRecord<>("one-topic", "msgKey", "msgValue"));
return "success" ;
}
}
基於上述自定義Bean類型,進行消息發送,關注攔截器中打印日誌信息。
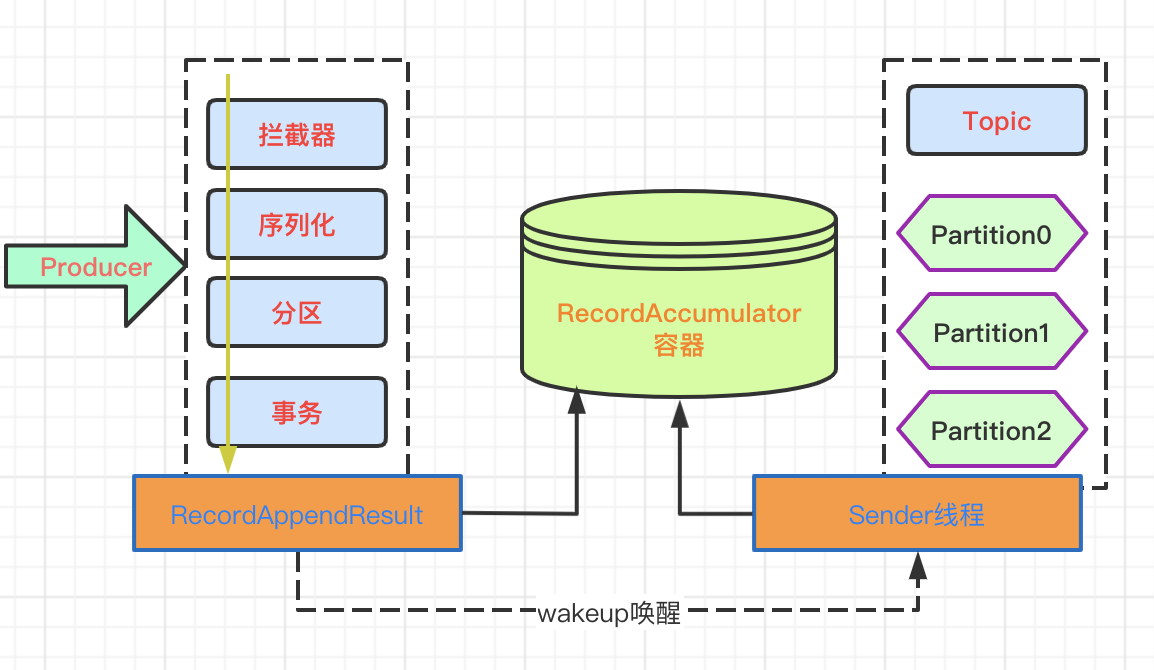
說明:該過程基於上述案例producer.send方法追蹤的源碼執行流程,源碼中的過程相對清楚,涉及的核心流程如下。
Producer發送消息採用的是異步發送的方式,消息發送過程如下:
絮叨一句:讀這些中間件的源碼,不僅能開闊思維,也會讓自己意識到平時寫的代碼可能真的叫搬磚。
Kafka中消息是以topic進行標識分類,生產者面向topic生產消息,topic分區(partition)是物理上的存儲,基於消息日誌文件的方式。
Kafka支持消息的事務控制
Producer事務
跨分區跨會話的事務原理,引入全局唯一的TransactionID,並將Producer獲得的PID和TransactionID綁定。Producer重啟后可以通過正在進行的TransactionID獲得原來的PID。
Kafka基於TransactionCoordinator組件管理Transaction,Producer通過和TransactionCoordinator交互獲得TransactionID對應的任務狀態。TransactionCoordinator將事務狀態寫入Kafka的內部Topic,即使整個服務重啟,進行中的事務狀態可以得到恢復。
Consumer事務
Consumer消息消費,事務的保證強度很低,無法保證消息被精確消費,因為同一事務的消息可能會出現重啟后已經被刪除的情況。
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent
推薦關聯閱讀:數據源管理系列
| 序號 | 標題 |
|---|---|
| 01 | 數據源管理:主從庫動態路由,AOP模式讀寫分離 |
| 02 | 數據源管理:基於JDBC模式,適配和管理動態數據源 |
| 03 | 數據源管理:動態權限校驗,表結構和數據遷移流程 |
| 04 | 數據源管理:關係型分庫分表,列式庫分佈式計算 |
| 05 | 數據源管理:PostGreSQL環境整合,JSON類型應用 |
| 06 | 數據源管理:基於DataX組件,同步數據和源碼分析 |
| 07 | 數據源管理:OLAP查詢引擎,ClickHouse集群化管理 |
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
先談談akka-typed的router actor。route 分pool router, group router兩類。我們先看看pool-router的使用示範:
val pool = Routers.pool(poolSize = 4)( // make sure the workers are restarted if they fail Behaviors.supervise(WorkerRoutee()).onFailure[Exception](SupervisorStrategy.restart)) val router = ctx.spawn(pool, "worker-pool") (0 to 10).foreach { n => router ! WorkerRoutee.DoLog(s"msg $n") }
上面例子里的pool是個pool-router,意思是一個有4個routees的routee池。每個routee都是通過WorkerRoutee()構建的,意味着routee池中只有一個種類的actor。pool-router是通過工廠方法直接在本地(JVM)構建(spawn)所有的routee。也就是說所有routee都是router的子actor。
再看看group-router的使用例子:
val serviceKey = ServiceKey[Worker.Command]("log-worker") // this would likely happen elsewhere - if we create it locally we // can just as well use a pool
val workerRoutee = ctx.spawn(WorkerRoutee(), "worker-route") ctx.system.receptionist ! Receptionist.Register(serviceKey, workerRoutee) val group = Routers.group(serviceKey) val router = ctx.spawn(group, "worker-group") // the group router will stash messages until it sees the first listing of registered // services from the receptionist, so it is safe to send messages right away
(0 to 10).foreach { n => router ! WorkerRoutee.DoLog(s"msg $n") }
group-router與pool-router有較多分別:
1、routee是在router之外構建的,router是用一個key通過Receptionist獲取同key的actor清單作為routee group的
2、Receptionist是集群全局的。任何節點上的actor都可以發送註冊消息在Receptionist上登記
3、沒有size限制,任何actor一旦在Receptionist上登記即變成routee,接受router管理
應該說如果想把運算任務分配在集群里的各節點上并行運算實現load-balance效果,group-router是最合適的選擇。不過對不同的運算任務需要多少routee則需要用戶自行決定,不像以前akka-classic里通過cluster-metrics根據節點負載情況自動增減routee實例那麼方便。
Receptionist: 既然說到,那麼就再深入一點介紹Receptionist的應用:上面提到,Receptionist是集群全局的。就是說任何節點上的actor都可以在Receptonist上註冊形成一個生存在集群中不同節點的actor清單。如果Receptionist把這個清單提供給一個用戶,那麼這個用戶就可以把運算任務配置到各節點上,實現某種意義上的分佈式運算模式。Receptionist的使用方式是:通過向本節點的Receptionist發送消息去登記ActorRef,然後通過Receptionist發布的登記變化消息即可獲取最新的ActorRef清單:
val WorkerServiceKey = ServiceKey[Worker.TransformText]("Worker") ctx.system.receptionist ! Receptionist.Register(WorkerServiceKey, ctx.self) ctx.system.receptionist ! Receptionist.Subscribe(Worker.WorkerServiceKey, subscriptionAdapter)
Receptionist的登記和清單獲取是以ServiceKey作為關聯的。那麼獲取的清單內應該全部是一種類型的actor,只不過它們的地址可能是跨節點的,但它們只能進行同一種運算。從另一個角度說,一項任務是分佈在不同節點的actor并行進行運算的。
在上篇討論里提過:如果發布-訂閱機制是在兩個actor之間進行的,那麼這兩個actor也需要在規定的信息交流協議框架下作業:我們必須注意消息類型,提供必要的消息類型轉換機制。下面是一個Receptionist登記示範:
object Worker { val WorkerServiceKey = ServiceKey[Worker.TransformText]("Worker") sealed trait Command final case class TransformText(text: String, replyTo: ActorRef[TextTransformed]) extends Command with CborSerializable final case class TextTransformed(text: String) extends CborSerializable def apply(): Behavior[Command] = Behaviors.setup { ctx =>
// each worker registers themselves with the receptionist
ctx.log.info("Registering myself with receptionist") ctx.system.receptionist ! Receptionist.Register(WorkerServiceKey, ctx.self) Behaviors.receiveMessage { case TransformText(text, replyTo) => replyTo ! TextTransformed(text.toUpperCase) Behaviors.same } } }
Receptionist登記比較直接:登記者不需要Receptionist返回消息,所以隨便用ctx.self作為消息的sender。注意TransformText的replyTo: ActorRef[TextTransformed],代表sender是個可以處理TextTransformed消息類型的actor。實際上,在sender方是通過ctx.ask提供了TextTransformed的類型轉換。
Receptionist.Subscribe需要Receptionist返回一個actor清單,所以是個request/response模式。那麼發送給Receptionist消息中的replyTo必須是發送者能處理的類型,如下:
def apply(): Behavior[Event] = Behaviors.setup { ctx => Behaviors.withTimers { timers =>
// subscribe to available workers
val subscriptionAdapter = ctx.messageAdapter[Receptionist.Listing] { case Worker.WorkerServiceKey.Listing(workers) => WorkersUpdated(workers) } ctx.system.receptionist ! Receptionist.Subscribe(Worker.WorkerServiceKey, subscriptionAdapter) ... }
ctx.messageAdapter進行了一個從Receptionist.Listing返回類型到WorkersUpdated類型的轉換機制登記:從Receptionist回復的List類型會被轉換成WorkersUpdated類型,如下:
... Behaviors.receiveMessage { case WorkersUpdated(newWorkers) => ctx.log.info("List of services registered with the receptionist changed: {}", newWorkers) ...
另外,上面提過的TextTransformed轉換如下:
ctx.ask[Worker.TransformText,Worker.TextTransformed](selectedWorker, Worker.TransformText(text, _)) { case Success(transformedText) => TransformCompleted(transformedText.text, text) case Failure(ex) => JobFailed("Processing timed out", text) }
ctx.ask將TextTransformed轉換成TransformCompleted。完整的Behavior定義如下:
object Frontend { sealed trait Event private case object Tick extends Event private final case class WorkersUpdated(newWorkers: Set[ActorRef[Worker.TransformText]]) extends Event private final case class TransformCompleted(originalText: String, transformedText: String) extends Event private final case class JobFailed(why: String, text: String) extends Event def apply(): Behavior[Event] = Behaviors.setup { ctx => Behaviors.withTimers { timers =>
// subscribe to available workers
val subscriptionAdapter = ctx.messageAdapter[Receptionist.Listing] { case Worker.WorkerServiceKey.Listing(workers) => WorkersUpdated(workers) } ctx.system.receptionist ! Receptionist.Subscribe(Worker.WorkerServiceKey, subscriptionAdapter) timers.startTimerWithFixedDelay(Tick, Tick, 2.seconds) running(ctx, IndexedSeq.empty, jobCounter = 0) } } private def running(ctx: ActorContext[Event], workers: IndexedSeq[ActorRef[Worker.TransformText]], jobCounter: Int): Behavior[Event] = Behaviors.receiveMessage { case WorkersUpdated(newWorkers) => ctx.log.info("List of services registered with the receptionist changed: {}", newWorkers) running(ctx, newWorkers.toIndexedSeq, jobCounter) case Tick =>
if (workers.isEmpty) { ctx.log.warn("Got tick request but no workers available, not sending any work") Behaviors.same } else { // how much time can pass before we consider a request failed
implicit val timeout: Timeout = 5.seconds val selectedWorker = workers(jobCounter % workers.size) ctx.log.info("Sending work for processing to {}", selectedWorker) val text = s"hello-$jobCounter" ctx.ask[Worker.TransformText,Worker.TextTransformed](selectedWorker, Worker.TransformText(text, _)) { case Success(transformedText) => TransformCompleted(transformedText.text, text) case Failure(ex) => JobFailed("Processing timed out", text) } running(ctx, workers, jobCounter + 1) } case TransformCompleted(originalText, transformedText) => ctx.log.info("Got completed transform of {}: {}", originalText, transformedText) Behaviors.same case JobFailed(why, text) => ctx.log.warn("Transformation of text {} failed. Because: {}", text, why) Behaviors.same }
現在我們可以示範用group-router來實現某種跨節點的分佈式運算。因為group-router是通過Receptionist來實現對routees管理的,而Receptionist是集群全局的,意味着如果我們在各節點上構建routee,然後向Receptionist登記,就會形成一個跨節點的routee ActorRef清單。如果把任務分配到這個清單上的routee上去運算,應該能實現集群節點負載均衡的效果。下面我們就示範這個loadbalancer。流程很簡單:在一個接入點 (serviceActor)中構建workersRouter,然後3個workerRoutee並向Receptionist登記,把接到的任務分解成子任務逐個發送給workersRouter。每個workerRoutee完成任務后將結果發送給一個聚合器Aggregator,Aggregator在核對完成接收所有workerRoutee返回的結果后再把匯總結果返回serverActor。先看看這個serverActor:
object Service { val routerServiceKey = ServiceKey[WorkerRoutee.Command]("workers-router") sealed trait Command extends CborSerializable case class ProcessText(text: String) extends Command { require(text.nonEmpty) } case class WrappedResult(res: Aggregator.Response) extends Command def serviceBehavior(workersRouter: ActorRef[WorkerRoutee.Command]): Behavior[Command] = Behaviors.setup[Command] { ctx => val aggregator = ctx.spawn(Aggregator(), "aggregator") val aggregatorRef: ActorRef[Aggregator.Response] = ctx.messageAdapter(WrappedResult) Behaviors.receiveMessage { case ProcessText(text) => ctx.log.info("******************** received ProcessText command: {} ****************",text) val words = text.split(' ').toIndexedSeq aggregator ! Aggregator.CountText(words.size, aggregatorRef) words.foreach { word => workersRouter ! WorkerRoutee.Count(word, aggregator) } Behaviors.same case WrappedResult(msg) => msg match { case Aggregator.Result(res) => ctx.log.info("************** mean length of words = {} **********", res) } Behaviors.same } } def singletonService(ctx: ActorContext[Command], workersRouter: ActorRef[WorkerRoutee.Command]) = { val singletonSettings = ClusterSingletonSettings(ctx.system) .withRole("front") SingletonActor( Behaviors.supervise( serviceBehavior(workersRouter) ).onFailure( SupervisorStrategy .restartWithBackoff(minBackoff = 10.seconds, maxBackoff = 60.seconds, randomFactor = 0.1) .withMaxRestarts(3) .withResetBackoffAfter(10.seconds) ) , "singletonActor" ).withSettings(singletonSettings) } def apply(): Behavior[Command] = Behaviors.setup[Command] { ctx => val cluster = Cluster(ctx.system) val workersRouter = ctx.spawn( Routers.group(routerServiceKey) .withRoundRobinRouting(), "workersRouter" ) (0 until 3).foreach { n => val routee = ctx.spawn(WorkerRoutee(cluster.selfMember.address.toString), s"work-routee-$n") ctx.system.receptionist ! Receptionist.register(routerServiceKey, routee) } val singletonActor = ClusterSingleton(ctx.system).init(singletonService(ctx, workersRouter)) Behaviors.receiveMessage { case job@ProcessText(text) => singletonActor ! job Behaviors.same } } }
整體goup-router和routee的構建是在apply()里,並把接到的任務轉發給singletonActor。singletonActor是以serviceBehavior為核心的一個actor。在servceBehavior里把收到的任務分解並分別發送給workersRouter。值得注意的是:serviceBehavior期望接收從Aggregator的回應,它們之間存在request/response模式信息交流,所以需要Aggregator.Response到WrappedResult的類型轉換機制。還有:子任務是通過workersRoute發送給個workerRoutee的,我們需要各workerRoutee把運算結果返給給Aggregator,所以發送給workersRouter的消息包含了Aggregator的ActorRef,如:workersRouter ! WorkerRoutee.Count(cnt,aggregatorRef)。
Aggregator是個persistentActor, 如下:
object Aggregator { sealed trait Command sealed trait Event extends CborSerializable sealed trait Response case class CountText(cnt: Int, replyTo: ActorRef[Response]) extends Command case class MarkLength(word: String, len: Int) extends Command case class TextCounted(cnt: Int) extends Event case class LengthMarked(word: String, len: Int) extends Event case class Result(meanWordLength: Double) extends Response case class State(expectedNum: Int = 0, lens: List[Int] = Nil) var replyTo: ActorRef[Response] = _ def commandHandler: (State,Command) => Effect[Event,State] = (st,cmd) => { cmd match { case CountText(cnt,ref) => replyTo = ref Effect.persist(TextCounted(cnt)) case MarkLength(word,len) => Effect.persist(LengthMarked(word,len)) } } def eventHandler: (State, Event) => State = (st,ev) => { ev match { case TextCounted(cnt) => st.copy(expectedNum = cnt, lens = Nil) case LengthMarked(word,len) => val state = st.copy(lens = len :: st.lens) if (state.lens.size >= state.expectedNum) { val meanWordLength = state.lens.sum.toDouble / state.lens.size replyTo ! Result(meanWordLength) State() } else state } } val takeSnapShot: (State,Event,Long) => Boolean = (st,ev,seq) => { if (st.lens.isEmpty) { if (ev.isInstanceOf[LengthMarked]) true
else
false } else
false } def apply(): Behavior[Command] = Behaviors.supervise( Behaviors.setup[Command] { ctx => EventSourcedBehavior( persistenceId = PersistenceId("33","2333"), emptyState = State(), commandHandler = commandHandler, eventHandler = eventHandler ).onPersistFailure( SupervisorStrategy .restartWithBackoff(minBackoff = 10.seconds, maxBackoff = 60.seconds, randomFactor = 0.1) .withMaxRestarts(3) .withResetBackoffAfter(10.seconds) ).receiveSignal { case (state, RecoveryCompleted) => ctx.log.info("**************Recovery Completed with state: {}***************",state) case (state, SnapshotCompleted(meta)) => ctx.log.info("**************Snapshot Completed with state: {},id({},{})***************",state,meta.persistenceId, meta.sequenceNr) case (state,RecoveryFailed(err)) => ctx.log.error("*************recovery failed with: {}***************",err.getMessage) case (state,SnapshotFailed(meta,err)) => ctx.log.error("***************snapshoting failed with: {}*************",err.getMessage) }.snapshotWhen(takeSnapShot) } ).onFailure( SupervisorStrategy .restartWithBackoff(minBackoff = 10.seconds, maxBackoff = 60.seconds, randomFactor = 0.1) .withMaxRestarts(3) .withResetBackoffAfter(10.seconds) ) }
注意這個takeSnapShot函數:這個函數是在EventSourcedBehavior.snapshotWhen(takeSnapShot)調用的。傳入參數是(State,Event,seqenceNr),我們需要對State,Event的當前值進行分析后返回true代表做一次snapshot。
看看一部分显示就知道任務已經分配到幾個節點上的routee:
20:06:59.072 [ClusterSystem-akka.actor.default-dispatcher-15] INFO com.learn.akka.WorkerRoutee$ - ************** processing [this] on akka://ClusterSystem@127.0.0.1:51182 *********** 20:06:59.072 [ClusterSystem-akka.actor.default-dispatcher-3] INFO com.learn.akka.WorkerRoutee$ - ************** processing [text] on akka://ClusterSystem@127.0.0.1:51182 *********** 20:06:59.072 [ClusterSystem-akka.actor.default-dispatcher-36] INFO com.learn.akka.WorkerRoutee$ - ************** processing [be] on akka://ClusterSystem@127.0.0.1:51182 *********** 20:06:59.236 [ClusterSystem-akka.actor.default-dispatcher-16] INFO com.learn.akka.WorkerRoutee$ - ************** processing [will] on akka://ClusterSystem@127.0.0.1:51173 *********** 20:06:59.236 [ClusterSystem-akka.actor.default-dispatcher-26] INFO com.learn.akka.WorkerRoutee$ - ************** processing [is] on akka://ClusterSystem@127.0.0.1:25251 *********** 20:06:59.236 [ClusterSystem-akka.actor.default-dispatcher-13] INFO com.learn.akka.WorkerRoutee$ - ************** processing [the] on akka://ClusterSystem@127.0.0.1:51173 *********** 20:06:59.236 [ClusterSystem-akka.actor.default-dispatcher-3] INFO com.learn.akka.WorkerRoutee$ - ************** processing [that] on akka://ClusterSystem@127.0.0.1:25251 *********** 20:06:59.236 [ClusterSystem-akka.actor.default-dispatcher-3] INFO com.learn.akka.WorkerRoutee$ - ************** processing [analyzed] on akka://ClusterSystem@127.0.0.1:25251 ***********
這個例子的源代碼如下:
package com.learn.akka import akka.actor.typed._ import akka.persistence.typed._ import akka.persistence.typed.scaladsl._ import scala.concurrent.duration._ import akka.actor.typed.receptionist._ import akka.actor.typed.scaladsl.Behaviors import akka.actor.typed.scaladsl._ import akka.cluster.typed.Cluster import akka.cluster.typed.ClusterSingleton import akka.cluster.typed.ClusterSingletonSettings import akka.cluster.typed.SingletonActor import com.typesafe.config.ConfigFactory object WorkerRoutee { sealed trait Command extends CborSerializable case class Count(word: String, replyTo: ActorRef[Aggregator.Command]) extends Command def apply(nodeAddress: String): Behavior[Command] = Behaviors.setup {ctx => Behaviors.receiveMessage[Command] { case Count(word,replyTo) => ctx.log.info("************** processing [{}] on {} ***********",word,nodeAddress) replyTo ! Aggregator.MarkLength(word,word.length) Behaviors.same } } } object Aggregator { sealed trait Command sealed trait Event extends CborSerializable sealed trait Response case class CountText(cnt: Int, replyTo: ActorRef[Response]) extends Command case class MarkLength(word: String, len: Int) extends Command case class TextCounted(cnt: Int) extends Event case class LengthMarked(word: String, len: Int) extends Event case class Result(meanWordLength: Double) extends Response case class State(expectedNum: Int = 0, lens: List[Int] = Nil) var replyTo: ActorRef[Response] = _ def commandHandler: (State,Command) => Effect[Event,State] = (st,cmd) => { cmd match { case CountText(cnt,ref) => replyTo = ref Effect.persist(TextCounted(cnt)) case MarkLength(word,len) => Effect.persist(LengthMarked(word,len)) } } def eventHandler: (State, Event) => State = (st,ev) => { ev match { case TextCounted(cnt) => st.copy(expectedNum = cnt, lens = Nil) case LengthMarked(word,len) => val state = st.copy(lens = len :: st.lens) if (state.lens.size >= state.expectedNum) { val meanWordLength = state.lens.sum.toDouble / state.lens.size replyTo ! Result(meanWordLength) State() } else state } } val takeSnapShot: (State,Event,Long) => Boolean = (st,ev,seq) => { if (st.lens.isEmpty) { if (ev.isInstanceOf[LengthMarked]) true else false } else false } def apply(): Behavior[Command] = Behaviors.supervise( Behaviors.setup[Command] { ctx => EventSourcedBehavior( persistenceId = PersistenceId("33","2333"), emptyState = State(), commandHandler = commandHandler, eventHandler = eventHandler ).onPersistFailure( SupervisorStrategy .restartWithBackoff(minBackoff = 10.seconds, maxBackoff = 60.seconds, randomFactor = 0.1) .withMaxRestarts(3) .withResetBackoffAfter(10.seconds) ).receiveSignal { case (state, RecoveryCompleted) => ctx.log.info("**************Recovery Completed with state: {}***************",state) case (state, SnapshotCompleted(meta)) => ctx.log.info("**************Snapshot Completed with state: {},id({},{})***************",state,meta.persistenceId, meta.sequenceNr) case (state,RecoveryFailed(err)) => ctx.log.error("*************recovery failed with: {}***************",err.getMessage) case (state,SnapshotFailed(meta,err)) => ctx.log.error("***************snapshoting failed with: {}*************",err.getMessage) }.snapshotWhen(takeSnapShot) } ).onFailure( SupervisorStrategy .restartWithBackoff(minBackoff = 10.seconds, maxBackoff = 60.seconds, randomFactor = 0.1) .withMaxRestarts(3) .withResetBackoffAfter(10.seconds) ) } object Service { val routerServiceKey = ServiceKey[WorkerRoutee.Command]("workers-router") sealed trait Command extends CborSerializable case class ProcessText(text: String) extends Command { require(text.nonEmpty) } case class WrappedResult(res: Aggregator.Response) extends Command def serviceBehavior(workersRouter: ActorRef[WorkerRoutee.Command]): Behavior[Command] = Behaviors.setup[Command] { ctx => val aggregator = ctx.spawn(Aggregator(), "aggregator") val aggregatorRef: ActorRef[Aggregator.Response] = ctx.messageAdapter(WrappedResult) Behaviors.receiveMessage { case ProcessText(text) => ctx.log.info("******************** received ProcessText command: {} ****************",text) val words = text.split(' ').toIndexedSeq aggregator ! Aggregator.CountText(words.size, aggregatorRef) words.foreach { word => workersRouter ! WorkerRoutee.Count(word, aggregator) } Behaviors.same case WrappedResult(msg) => msg match { case Aggregator.Result(res) => ctx.log.info("************** mean length of words = {} **********", res) } Behaviors.same } } def singletonService(ctx: ActorContext[Command], workersRouter: ActorRef[WorkerRoutee.Command]) = { val singletonSettings = ClusterSingletonSettings(ctx.system) .withRole("front") SingletonActor( Behaviors.supervise( serviceBehavior(workersRouter) ).onFailure( SupervisorStrategy .restartWithBackoff(minBackoff = 10.seconds, maxBackoff = 60.seconds, randomFactor = 0.1) .withMaxRestarts(3) .withResetBackoffAfter(10.seconds) ) , "singletonActor" ).withSettings(singletonSettings) } def apply(): Behavior[Command] = Behaviors.setup[Command] { ctx => val cluster = Cluster(ctx.system) val workersRouter = ctx.spawn( Routers.group(routerServiceKey) .withRoundRobinRouting(), "workersRouter" ) (0 until 3).foreach { n => val routee = ctx.spawn(WorkerRoutee(cluster.selfMember.address.toString), s"work-routee-$n") ctx.system.receptionist ! Receptionist.register(routerServiceKey, routee) } val singletonActor = ClusterSingleton(ctx.system).init(singletonService(ctx, workersRouter)) Behaviors.receiveMessage { case job@ProcessText(text) => singletonActor ! job Behaviors.same } } } object LoadBalance { def main(args: Array[String]): Unit = { if (args.isEmpty) { startup("compute", 25251) startup("compute", 25252) startup("compute", 25253) startup("front", 25254) } else { require(args.size == 2, "Usage: role port") startup(args(0), args(1).toInt) } } def startup(role: String, port: Int): Unit = { // Override the configuration of the port when specified as program argument val config = ConfigFactory .parseString(s""" akka.remote.artery.canonical.port=$port akka.cluster.roles = [$role] """) .withFallback(ConfigFactory.load("cluster-persistence")) val frontEnd = ActorSystem[Service.Command](Service(), "ClusterSystem", config) if (role == "front") { println("*************** sending ProcessText command ************") frontEnd ! Service.ProcessText("this is the text that will be analyzed") } } }
cluster-persistence.conf
akka.actor.allow-java-serialization = on akka { loglevel = INFO actor { provider = cluster serialization-bindings { "com.learn.akka.CborSerializable" = jackson-cbor } } remote { artery { canonical.hostname = "127.0.0.1" canonical.port = 0 } } cluster { seed-nodes = [ "akka://ClusterSystem@127.0.0.1:25251", "akka://ClusterSystem@127.0.0.1:25252"] } # use Cassandra to store both snapshots and the events of the persistent actors persistence { journal.plugin = "akka.persistence.cassandra.journal" snapshot-store.plugin = "akka.persistence.cassandra.snapshot" } } akka.persistence.cassandra { # don't use autocreate in production journal.keyspace = "poc" journal.keyspace-autocreate = on journal.tables-autocreate = on snapshot.keyspace = "poc_snapshot" snapshot.keyspace-autocreate = on snapshot.tables-autocreate = on } datastax-java-driver { basic.contact-points = ["192.168.11.189:9042"] basic.load-balancing-policy.local-datacenter = "datacenter1" }
build.sbt
name := "learn-akka-typed" version := "0.1" scalaVersion := "2.13.1" scalacOptions in Compile ++= Seq("-deprecation", "-feature", "-unchecked", "-Xlog-reflective-calls", "-Xlint") javacOptions in Compile ++= Seq("-Xlint:unchecked", "-Xlint:deprecation") val AkkaVersion = "2.6.5" val AkkaPersistenceCassandraVersion = "1.0.0" libraryDependencies ++= Seq( "com.typesafe.akka" %% "akka-cluster-sharding-typed" % AkkaVersion, "com.typesafe.akka" %% "akka-persistence-typed" % AkkaVersion, "com.typesafe.akka" %% "akka-persistence-query" % AkkaVersion, "com.typesafe.akka" %% "akka-serialization-jackson" % AkkaVersion, "com.typesafe.akka" %% "akka-persistence-cassandra" % AkkaPersistenceCassandraVersion, "com.typesafe.akka" %% "akka-slf4j" % AkkaVersion, "ch.qos.logback" % "logback-classic" % "1.2.3" )
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
數據的接入可以通過將數據實時寫入Kafka進行接入,不管是直接的寫入還是通過oracle和mysql的實時接入方式,比如oracle的ogg,mysql的binlog
Golden Gate(簡稱OGG)提供異構環境下交易數據的實時捕捉、變換、投遞。
通過OGG可以實時的將oracle中的數據寫入Kafka中。
對生產系統影響小:實時讀取交易日誌,以低資源佔用實現大交易量數據實時複製
以交易為單位複製,保證交易一致性:只同步已提交的數據
高性能
MySQL 的二進制日誌 binlog 可以說是 MySQL 最重要的日誌,它記錄了所有的 DDL 和 DML 語句(除了數據查詢語句select、show等),以事件形式記錄,還包含語句所執行的消耗的時間,MySQL的二進制日誌是事務安全型的。binlog 的主要目的是複製和恢復。
通過這些手段,可以將數據同步到kafka也就是我們的實時系統中來。
Apache Kafka Connector可以方便對kafka數據的接入。
依賴
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.11</artifactId> <version>1.9.0</version></dependency>
必須有的:
1.topic名稱
2.用於反序列化Kafka數據的DeserializationSchema / KafkaDeserializationSchema
3.配置參數:“bootstrap.servers” “group.id” (kafka0.8還需要 “zookeeper.connect”)
val properties = new Properties()properties.setProperty("bootstrap.servers", "localhost:9092")// only required for Kafka 0.8properties.setProperty("zookeeper.connect", "localhost:2181")properties.setProperty("group.id", "test")stream = env .addSource(new FlinkKafkaConsumer[String]("topic", new SimpleStringSchema(), properties)) .print()
在許多情況下,記錄的時間戳(顯式或隱式)嵌入記錄本身。另外,用戶可能想要周期性地或以不規則的方式發出水印。
我們可以定義好Timestamp Extractors / Watermark Emitters,通過以下方式將其傳遞給消費者
val env = StreamExecutionEnvironment.getExecutionEnvironment()val myConsumer = new FlinkKafkaConsumer[String](...)myConsumer.setStartFromEarliest() // start from the earliest record possiblemyConsumer.setStartFromLatest() // start from the latest recordmyConsumer.setStartFromTimestamp(...) // start from specified epoch timestamp (milliseconds)myConsumer.setStartFromGroupOffsets() // the default behaviour//指定位置//val specificStartOffsets = new java.util.HashMap[KafkaTopicPartition, java.lang.Long]()//specificStartOffsets.put(new KafkaTopicPartition("myTopic", 0), 23L)//myConsumer.setStartFromSpecificOffsets(specificStartOffsets)val stream = env.addSource(myConsumer)
啟用Flink的檢查點后,Flink Kafka Consumer將使用主題中的記錄,並以一致的方式定期檢查其所有Kafka偏移以及其他操作的狀態。如果作業失敗,Flink會將流式程序恢復到最新檢查點的狀態,並從存儲在檢查點中的偏移量開始重新使用Kafka的記錄。
如果禁用了檢查點,則Flink Kafka Consumer依賴於內部使用的Kafka客戶端的自動定期偏移提交功能。
如果啟用了檢查點,則Flink Kafka Consumer將在檢查點完成時提交存儲在檢查點狀態中的偏移量。
val env = StreamExecutionEnvironment.getExecutionEnvironment()env.enableCheckpointing(5000) // checkpoint every 5000 msecs
Flink消費Kafka完整代碼:
import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class KafkaConsumer { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); //構建FlinkKafkaConsumer FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties); //指定偏移量 myConsumer.setStartFromEarliest(); DataStream<String> stream = env .addSource(myConsumer); env.enableCheckpointing(5000); stream.print(); env.execute("Flink Streaming Java API Skeleton"); }
這樣數據已經實時的接入我們系統中,可以在Flink中對數據進行處理了,那麼如何對標籤進行計算呢? 標籤的計算過程極大的依賴於數據倉庫的能力,所以擁有了一個好的數據倉庫,標籤也就很容易計算出來了。
數據倉庫是指一個面向主題的、集成的、穩定的、隨時間變化的數據的集合,以用於支持管理決策的過程。
(1)面向主題
業務數據庫中的數據主要針對事物處理任務,各個業務系統之間是各自分離的。而數據倉庫中的數據是按照一定的主題進行組織的
(2)集成
數據倉庫中存儲的數據是從業務數據庫中提取出來的,但並不是原有數據的簡單複製,而是經過了抽取、清理、轉換(ETL)等工作。
業務數據庫記錄的是每一項業務處理的流水賬,這些數據不適合於分析處理,進入數據倉庫之前需要經過系列計算,同時拋棄一些分析處理不需要的數據。
(3)穩定
操作型數據庫系統中一般只存儲短期數據,因此其數據是不穩定的,記錄的是系統中數據變化的瞬態。
數據倉庫中的數據大多表示過去某一時刻的數據,主要用於查詢、分析,不像業務系統中數據庫一樣經常修改。一般數據倉庫構建完成,主要用於訪問
OLTP 聯機事務處理
OLTP是傳統關係型數據庫的主要應用,主要用於日常事物、交易系統的處理
1、數據量存儲相對來說不大
2、實時性要求高,需要支持事物
3、數據一般存儲在關係型數據庫(oracle或mysql中)
OLAP 聯機分析處理
OLAP是數據倉庫的主要應用,支持複雜的分析查詢,側重決策支持
1、實時性要求不是很高,ETL一般都是T+1的數據;
2、數據量很大;
3、主要用於分析決策;
星形模型是最常用的數據倉庫設計結構。由一個事實表和一組維表組成,每個維表都有一個維主鍵。
該模式核心是事實表,通過事實表將各種不同的維表連接起來,各個維表中的對象通過事實表與另一個維表中的對象相關聯,這樣建立各個維表對象之間的聯繫
維表:用於存放維度信息,包括維的屬性和層次結構;
事實表:是用來記錄業務事實並做相應指標統計的表。同維表相比,事實表記錄數量很多
雪花模型是對星形模型的擴展,每一個維表都可以向外連接多個詳細類別表。除了具有星形模式中維表的功能外,還連接對事實表進行詳細描述的維度,可進一步細化查看數據的粒度
例如:地點維表包含屬性集{location_id,街道,城市,省,國家}。這種模式通過地點維度表的city_id與城市維度表的city_id相關聯,得到如{101,“解放大道10號”,“武漢”,“湖北省”,“中國”}、{255,“解放大道85號”,“武漢”,“湖北省”,“中國”}這樣的記錄。
星形模型是最基本的模式,一個星形模型有多個維表,只存在一個事實表。在星形模式的基礎上,用多個表來描述一個複雜維,構造維表的多層結構,就得到雪花模型
清晰數據結構:每一個數據分層都有它的作用域,這樣我們在使用表的時候能更方便地定位和理解
臟數據清洗:屏蔽原始數據的異常
屏蔽業務影響:不必改一次業務就需要重新接入數據
數據血緣追蹤:簡單來講可以這樣理解,我們最終給業務呈現的是能直接使用的一張業務表,但是它的來源有很多,如果有一張來源表出問題了,我們希望能夠快速準確地定位到問題,並清楚它的危害範圍。
減少重複開發:規範數據分層,開發一些通用的中間層數據,能夠減少極大的重複計算。
把複雜問題簡單化。將一個複雜的任務分解成多個步驟來完成,每一層只處理單一的步驟,比較簡單和容易理解。便於維護數據的準確性,當數據出現問題之後,可以不用修復所有的數據,只需要從有問題的步驟開始修復。
數據倉庫的數據直接對接OLAP或日誌類數據,
用戶畫像只是站在用戶的角度,對數據倉庫數據做進一步的建模加工。因此每天畫像標籤相關數據的調度依賴上游數據倉庫相關任務執行完成。
在了解了數據倉庫以後,我們就可以進行標籤的計算了。在開發好標籤的邏輯以後,將數據寫入hive和druid中,完成實時與離線的標籤開發工作。
Flink從1.9開始支持集成Hive,不過1.9版本為beta版,不推薦在生產環境中使用。在最新版Flink1.10版本,標志著對 Blink的整合宣告完成,隨着對 Hive 的生產級別集成,Hive作為數據倉庫系統的絕對核心,承擔著絕大多數的離線數據ETL計算和數據管理,期待Flink未來對Hive的完美支持。
而 HiveCatalog 會與一個 Hive Metastore 的實例連接,提供元數據持久化的能力。要使用 Flink 與 Hive 進行交互,用戶需要配置一個 HiveCatalog,並通過 HiveCatalog 訪問 Hive 中的元數據。
要與Hive集成,需要在Flink的lib目錄下添加額外的依賴jar包,以使集成在Table API程序或SQL Client中的SQL中起作用。或者,可以將這些依賴項放在文件夾中,並分別使用Table API程序或SQL Client 的-C 或-l選項將它們添加到classpath中。本文使用第一種方式,即將jar包直接複製到$FLINK_HOME/lib目錄下。本文使用的Hive版本為2.3.4(對於不同版本的Hive,可以參照官網選擇不同的jar包依賴),總共需要3個jar包,如下:
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<scope>provided</scope>
</dependency>
package com.flink.sql.hiveintegration;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.catalog.hive.HiveCatalog;
public class FlinkHiveIntegration {
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() // 使用BlinkPlanner
.inBatchMode() // Batch模式,默認為StreamingMode
.build();
//使用StreamingMode
/* EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() // 使用BlinkPlanner
.inStreamingMode() // StreamingMode
.build();*/
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive"; // Catalog名稱,定義一個唯一的名稱表示
String defaultDatabase = "qfbap_ods"; // 默認數據庫名稱
String hiveConfDir = "/opt/modules/apache-hive-2.3.4-bin/conf"; // hive-site.xml路徑
String version = "2.3.4"; // Hive版本號
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);
tableEnv.registerCatalog("myhive", hive);
tableEnv.useCatalog("myhive");
// 創建數據庫,目前不支持創建hive表
String createDbSql = "CREATE DATABASE IF NOT EXISTS myhive.test123";
tableEnv.sqlUpdate(createDbSql);
}
}
可以將Flink分析好的數據寫回kafka,然後在druid中接入數據,也可以將數據直接寫入druid,以下為示例代碼:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.8.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.flinkdruid</groupId>
<artifactId>FlinkDruid</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>FlinkDruid</name>
<description>Flink Druid Connection</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
@SpringBootApplication
public class FlinkDruidApp {
private static String url = "http://localhost:8200/v1/post/wikipedia";
private static RestTemplate template;
private static HttpHeaders headers;
FlinkDruidApp() {
template = new RestTemplate();
headers = new HttpHeaders();
headers.setAccept(Arrays.asList(MediaType.APPLICATION_JSON));
headers.setContentType(MediaType.APPLICATION_JSON);
}
public static void main(String[] args) throws Exception {
SpringApplication.run(FlinkDruidApp.class, args);
// Creating Flink Execution Environment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//Define data source
DataSet<String> data = env.readTextFile("/wikiticker-2015-09-12-sampled.json");
// Trasformation on the data
data.map(x -> {
return httpsPost(x).toString();
}).print();
}
// http post method to post data in Druid
private static ResponseEntity<String> httpsPost(String json) {
HttpEntity<String> requestEntity =
new HttpEntity<>(json, headers);
ResponseEntity<String> response =
template.exchange("http://localhost:8200/v1/post/wikipedia", HttpMethod.POST, requestEntity,
String.class);
return response;
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
標籤的開發工作繁瑣,需要不斷的開發並且優化,但是如何將做好的標籤提供出去產生真正的價值呢? 下一章,我們將介紹用戶畫像產品化,未完待續~
參考文獻
《用戶畫像:方法論與工程化解決方案》
更多實時數據分析相關博文與科技資訊,歡迎關注 “實時流式計算” 獲取用戶畫像相關資料 請關注 “實時流式計算” 回復 “用戶畫像”
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
在上一篇文章中,我們使用Telegraf自帶的Plugin配置好了的監控,但是自帶的Plugin並不能完全覆蓋我們想要的監控指標,就需要收集額外的自定義的監控數據,實現的方法有:
開發自己的Telegraf Plugin
使用可以執行自定義腳本的inputs plugin
此處收集的監控項不多,收集間隔也不是很頻繁,所以我選擇Telegraf預置的Inputs.exec plugin實現。它非常靈活,可以執行任意命令和腳本。在腳本中實現獲取監控數據的邏輯,然後使用inputs.exec執行。獲取數據之後,需要按InfluxDB Line Protocol 格式組織數據,才能寫入到Influxdb。這種格式的組織方式:
measurement,類似於SQL中表的概念,數據存放的容器
tags,K-V格式用於標記數據記錄,一般它們的值不經常變化,如主機名。同時tags上會建立索引,查詢效率會好一些.
fields,K-V格式,表示真正收集的不同時間點的數據項,如CPU Load
timestamp,UNIX 時間戳,Influxdb是時序數據庫,所有數據都要與時間關聯起來。
measurement和tag之間用逗號分隔,fields 與它們用空格(whitespace)分隔
不管是運行在Linux還是Windows上的SQL,通常使用T-SQL查詢實例內部的數據和使用操作系統腳本查詢實例外部的數據以實現監控。接下來,以執行T-SQL獲取自定義監控數據為例,看看在Windos和Linux上分別如何實現。
首先在被監控的實例上把相應的邏輯寫成存儲過程,然後通過inputs.exec調用之。
例如我在目標實例的influx庫中創建了一個存儲過程influx.usp_getInstanceInfo獲取一些實例的配置信息。然後需要在telegraf配置文件中啟用inputs.exec調用這個存儲過程。存儲過程的輸出數據如下:
sqlserver_property,host=SQL19N1,sql_instance=SQL19N1 host_platform="Linux",host_distribution="CentOS Linux",host_release=7,edition="Developer Edition (64-bit)",product_version="15.0.4033.1",collation="SQL_Latin1_General_CP1_CI_AS",is_clustered=f,is_hadr=t,cpu_count=2,scheduler_count=2,physical_memory_kb=6523904,max_workers_count=512,max_dop=0,max_memmory=2147483647 1590915136000000000
數據寫入到sqlserver_property,tags包括host,sql_instance,後面的全是fields。
使用SQLCMD調用存儲過程,把SQLCMD命令寫到一個bash文件中/telegraf/get_sqlproperty.sh
#!/bin/bash
/opt/mssql-tools/bin/sqlcmd -S SQL19N1 -U telegraf -P <yourpassword> -d influx -y 0 -Q "EXEC influx.usp_getInstanceInfo"
修改telegraf.conf中的inputs.exec, 然後重啟telegraf生效:
因為收集的是實例屬性信息,收集間隔設置的比較長。
[[inputs.exec]]
# ## Commands array
commands = [
"/telegraf/get_sqlproperty.sh"
]
timeout = "5s"
interval="24h"
data_format = "influx"
Windows上首選使用PowerShell實現,把執行SQL的命令寫到C:\Monitoring\scripts\get_sqlproperty.ps1。col_res是存儲過程輸出的列名。
(Invoke-Sqlcmd -ServerInstance SQL17N1 -Username telegraf -Password "<yourpassword>" -Database influx -Query "exec influx.usp_getInstanceInfo" ).col_res
修改telegraf.conf中的inputs.exec, 然後重啟telegraf生效.
需要特別注意的問題:
指定文件路徑時,要使用Linux路徑表達的forward slash(/), 而不是Windows中的 back slash(\)
ps1文件路徑使用單引號(single quote)
避免文件路徑中有空格(whitespace)
[[inputs.exec]]
# ## Commands array
commands = [
"powershell 'C:/Monitoring/scripts/get_sqlproperty.ps1' "
]
timeout = "5s"
interval="24h"
data_format = "influx"
配置完成后,看看measurement和數據:
在inputs.exec中最好是調用腳本,而不是命令。這樣當你需要變更數據收集邏輯,直接修改腳本即可,而不需要修改Telegraf的配置文件,避免重啟服務和配置干擾
被調用的腳本的輸出,要是stdout,才能被正確寫入influxdb
Windows 上文件路徑和符號escape要特別注意
如果對收集性能特別敏感或者收集頻率特別高時,使用Go自定義Plugin
本文內容僅代表個人觀點,與任何公司和組織無關
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
目錄
springboot 融合了很多插件。springboot相比spring來說有一下有點
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.3.RELEASE</version>
</parent>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
【詳見feature/0002/spring-mybatis 分支】
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
MybatisConfig
@Bean
@ConfigurationProperties("spring.datasource")
public DataSource primaryDataSource() {
// 這裏為了演示,暫時寫死 。 實際上是可以通過autoConfigure裝配參數的
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUsername("root");
dataSource.setPassword("123456");
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://192.168.44.130:3306/others?useUnicode=true&characterEncoding=utf8");
return dataSource;
}
Bean註解,就相當於我們在spring的xml中配置的bean標籤。在java代碼中我們可以進行我們業務處理。個人理解感覺更加的可控。 因為我們使用的mysql。所以這裏我們簡單的使用druid的數據源
@Bean
public SqlSessionFactory primarySqlSessionFactory() {
SqlSessionFactory factory = null;
try {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(primaryDataSource());
sqlSessionFactoryBean.setConfigLocation(new DefaultResourceLoader().getResource("classpath:mybatis-primary.xml"));
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:/com/github/zxhtom.**./*.xml"));
factory = sqlSessionFactoryBean.getObject();
} catch (Exception e) {
e.printStackTrace();
}
return factory;
}
@Bean
public MapperScannerConfigurer mapperScannerConfigurer() {
MapperScannerConfigurer mapperScannerConfigurer = new MapperScannerConfigurer();
mapperScannerConfigurer.setSqlSessionFactory(primarySqlSessionFactory());
//每張表對應的*.java,interface類型的Java文件
mapperScannerConfigurer.setBasePackage("com.github.zxhtom.**.mapper");
return mapperScannerConfigurer;
}
@Bean
public DataSourceTransactionManager primaryTransactionManager() {
return new DataSourceTransactionManager(dataSource);
}
@Bean
public TransactionInterceptor txAdvice() {
DefaultTransactionAttribute txAttr_REQUIRED = new DefaultTransactionAttribute();
txAttr_REQUIRED.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
DefaultTransactionAttribute txAttr_REQUIRED_READONLY = new DefaultTransactionAttribute();
txAttr_REQUIRED_READONLY.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
txAttr_REQUIRED_READONLY.setReadOnly(true);
NameMatchTransactionAttributeSource source = new NameMatchTransactionAttributeSource();
source.addTransactionalMethod("add*", txAttr_REQUIRED);
source.addTransactionalMethod("save*", txAttr_REQUIRED);
source.addTransactionalMethod("delete*", txAttr_REQUIRED);
source.addTransactionalMethod("update*", txAttr_REQUIRED);
source.addTransactionalMethod("exec*", txAttr_REQUIRED);
source.addTransactionalMethod("set*", txAttr_REQUIRED);
source.addTransactionalMethod("get*", txAttr_REQUIRED_READONLY);
source.addTransactionalMethod("query*", txAttr_REQUIRED_READONLY);
source.addTransactionalMethod("find*", txAttr_REQUIRED_READONLY);
source.addTransactionalMethod("list*", txAttr_REQUIRED_READONLY);
source.addTransactionalMethod("count*", txAttr_REQUIRED_READONLY);
source.addTransactionalMethod("is*", txAttr_REQUIRED_READONLY);
return new TransactionInterceptor(primaryTransactionManager(), source);
}
@Bean
public Advisor txAdviceAdvisor() {
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression(AOP_POINTCUT_EXPRESSION);
return new DefaultPointcutAdvisor(pointcut, txAdvice());
}@Bean
public Advisor txAdviceAdvisor() {
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression(AOP_POINTCUT_EXPRESSION);
return new DefaultPointcutAdvisor(pointcut, txAdvice());
}
@Configuration
@Aspect
@EnableTransactionManagement
以上就是mybatis基本的一個配置了。但是這個時候還是不能使用的。因為我們的mapper對應的xml是放在java目錄下的。正常src下都是java。xml文件在maven編譯時不放行的。我們需要特殊處理下
在pom的build下加入放行配置
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
<include>**/*.properties</include>
<include>**/*.yaml</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.*</include>
</includes>
<filtering>false</filtering>
</resource>
</resources>
@SpringBootTest(classes = Application.class)
@RunWith(SpringJUnit4ClassRunner.class)
@WebAppConfiguration
public class TestDataSource {
@Autowired
private TestMapper testMapper;
@Test
public void test() {
List<Map<String, Object>> test = testMapper.test();
System.out.println(test);
}
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource primaryDataSource() {
return new DruidDataSource();
}
【詳見feature/0002/spring-mybatis-tk-page 分支】
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper</artifactId>
<version>3.3.9</version>
</dependency>
這些插件其實就是改寫我們之前學習的myabtis四大組件中的某一個組件而實現的。所以不管是通用mapper還是後面要說的myabtis-plus都是需要重新改寫我們的myabtis配置類的。
首先我們想接入通用mapper時,我們需要改用tk提供的掃包配置
@Bean
public MapperScannerConfigurer mapperScannerConfigurer() {
tk.mybatis.spring.mapper.MapperScannerConfigurer mapperScannerConfigurer = new tk.mybatis.spring.mapper.MapperScannerConfigurer();
//MapperScannerConfigurer mapperScannerConfigurer = new MapperScannerConfigurer();
mapperScannerConfigurer.setSqlSessionFactory(primarySqlSessionFactory());
//每張表對應的*.java,interface類型的Java文件
mapperScannerConfigurer.setBasePackage("com.github.zxhtom.**.mapper");
return mapperScannerConfigurer;
}
@Bean()
public MapperHelper primaryMapperHelper() throws Exception {
MapperHelper mapperHelper = new MapperHelper();
Config config = mapperHelper.getConfig();
//表名字段名使用駝峰轉下劃線大寫形式
config.setStyle(Style.camelhumpAndUppercase);
mapperHelper.registerMapper(Mapper.class);
mapperHelper.processConfiguration(primarySqlSessionFactory().getConfiguration());
return mapperHelper;
}
User user = tkMapper.selectByPrimaryKey(1);
【詳見feature/0002/spring-mybatisplus 分支】
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>
@Data
@TableName(value = "person_info_large")
public class User {
@TableId(value = "id",type = IdType.AUTO)
private Integer id;
private String account;
private String name;
private String area;
private String title;
private String motto;
}
public interface PlusMapper extends BaseMapper<User> {
}
@Bean
public SqlSessionFactory primarySqlSessionFactory() {
SqlSessionFactory factory = null;
try {
MybatisSqlSessionFactoryBean sqlSessionFactoryBean = new MybatisSqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(primaryDataSource());
sqlSessionFactoryBean.setConfigLocation(new DefaultResourceLoader().getResource("classpath:mybatis-primary.xml"));
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:com/github/zxhtom.**./*.xml"));
sqlSessionFactoryBean.setTypeAliasesPackage("com.github.zxhtom.**.model");
factory = sqlSessionFactoryBean.getObject();
} catch (Exception e) {
e.printStackTrace();
}
return factory;
}
@Test
public void plusTest() {
User user = plusMapper.selectById(1);
System.out.println(user);
}
【詳見feature/0002/spring-mybatisplus 分支】
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
return plusMapper.selectPage(page, null);
【詳見feature/0002/spring-mybatis-tk-page 分支】
因為myatis-plus自帶了分頁插件。上面也展示了如何使用myabtis-plus插件。還有一個github上開元的分頁插件。這裏就和通用mapper進行組合使用
pagehelper官方更新還是挺勤奮的。提供了pagehelper 和springboot auto裝配兩種。 筆者這裏測試了pagehelper-spring-boot-starter這個包不適合本案例中。因為本案例中掃描mapper路徑是通過MapperScannerConfigurer註冊的。如果使用pagehelper-spring-boot-starter的話就會導致分頁攔截器失效。我們看看源碼
MapperScannerConfigurer . 經過筆者測試。需要在MybatisConfig類上添加掃描註解@MapperScan(basePackages = {"com.github.zxhtom.**.mapper"}, sqlSessionFactoryRef = "primarySqlSessionFactory")
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.7</version>
</dependency>
SqlSessionFactoryBean設置sqlSessionFactoryBean.setPlugins(new Interceptor[]{new PageInterceptor()});。
@Bean
public SqlSessionFactory primarySqlSessionFactory() {
SqlSessionFactory factory = null;
try {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(primaryDataSource());
sqlSessionFactoryBean.setConfigLocation(new DefaultResourceLoader().getResource("classpath:mybatis-primary.xml"));
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:com/github/zxhtom.**./*.xml"));
sqlSessionFactoryBean.setTypeAliasesPackage("com.github.zxhtom.**.model");
sqlSessionFactoryBean.setPlugins(new Interceptor[]{new PageInterceptor()});
factory = sqlSessionFactoryBean.getObject();
} catch (Exception e) {
e.printStackTrace();
}
return factory;
}
這裏簡單闡述下為什麼不適用註解掃描mapper、或者不在配置文件中配置掃包路徑。因為通過MapperScannerConfigurer我們可以動態控制路徑。這樣顯得比較有逼格。在實際開發中筆者推薦使用註解方式掃描。因為這樣可以避免不必要的坑。
到這裏我們整理了【springboot整合mybaits】、【mybatis-plus】、【通用mapper】、【pagehelper插件整合】 這四個模塊的整理中我們發現離不開myabtis的四大組件。springboot其實我們還未接觸到深的內容。這篇文章主要偏向myabtis . 後續還會繼續衍生探索 【myabtis+druid】監控數據信息 。
喜歡研究源碼和開元框架小試牛刀的歡迎關注我
加入戰隊
非xml配置springboot+mybatis事務管理
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!