環境資訊中心綜合外電;黃鈺婷 翻譯;林大利 審校;稿源:Mongabay
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
當我們寫printf("%d\n", 1);的時候,printf函數並不能通過C語言語法得知第二個參數是int類型。printf是一個變參函數(variadic function):
int printf(const char *restrict format, ...);
參數的類型都是通過格式串format推導出的。如果參數類型與格式串中指定的不匹配,或提供的參數數量少於需要的,將導致未定義行為。
由於參數類型是動態的,printf和scanf比靜態類型的std::cout和std::cin慢,前提是後者的眾多overhead被手動消除。
C為可變參數提供了va_start、va_arg、va_copy、va_end、va_list等工具,定義在頭文件<stdarg.h>中。va_arg用於取出參數,va_copy用於拷貝參數供多次使用。引用cppreference上的例子:
#include <stdio.h>
#include <stdarg.h>
#include <math.h>
double sample_stddev(int count, ...)
{
/* Compute the mean with args1. */
double sum = 0;
va_list args1;
va_start(args1, count);
va_list args2;
va_copy(args2, args1); /* copy va_list object */
for (int i = 0; i < count; ++i) {
double num = va_arg(args1, double);
sum += num;
}
va_end(args1);
double mean = sum / count;
/* Compute standard deviation with args2 and mean. */
double sum_sq_diff = 0;
for (int i = 0; i < count; ++i) {
double num = va_arg(args2, double);
sum_sq_diff += (num-mean) * (num-mean);
}
va_end(args2);
return sqrt(sum_sq_diff / count);
}
int main(void)
{
printf("%f\n", sample_stddev(4, 25.0, 27.3, 26.9, 25.7));
}
<stdio.h>還定義了vprintf系列函數,與不帶v的相比,可變參數...都換成了va_list的實例:
int vprintf(const char *format, va_list vlist);
可以藉此實現自己的printf。
可變參數在傳遞的過程中會被執行默認參數提升(default argument promotion),對於整數類型執行整數提升(提升為int或unsigned int),對於float類型提升成double。
格式串format中的普通字符直接拷貝到輸出流,由%引導的稱為轉換格式(conversion specification),在%和轉換說明符(conversion specifier)之間可以有若干修飾符,實現對齊、精度等功能,轉換說明符有c、s、d、f等,詳見cppreference。
單片機開發板並沒有可以用於輸出的控制台,printf調用最後都會歸結為_write函數:
int _write(int file, char* ptr, int len);
_write函數需要把ptr指向的len字節的數據以想要的形式發送,在此就沿用上一篇中的UART異步IO,於是printf就可以打印在串口上了。
為了方便日後使用,我把USART相關的代碼抽離出來放在一個新的源文件里,IDE生成的代碼去掉MX_USART1_UART_Init和USART1_IRQHandler兩個函數,再加上這一對文件就可以使用了。
usart1.h:
#include <stdio.h>
void MX_USART1_UART_Init();
void usart1_transmit(char c);
char usart1_receive();
usart1.c:
#include "usart1.h"
#include <stdbool.h>
#include <stdint.h>
#include <stdlib.h>
#include "cmsis_gcc.h"
#include "stm32f4xx_hal.h"
typedef char queue_element_t;
typedef struct
{
uint16_t mask;
uint16_t head;
uint16_t tail;
queue_element_t data[0];
} queue_t;
static inline queue_t* queue_create(uint16_t _size)
{
if (_size & (_size - 1))
_size = 256;
queue_t* q = malloc(sizeof(queue_t) + _size * sizeof(queue_element_t));
if (q)
{
q->mask = _size - 1;
q->head = q->tail = 0;
}
return q;
}
static inline bool queue_empty(const queue_t* _queue)
{
return _queue->head == _queue->tail;
}
static inline uint16_t queue_size(const queue_t* _queue)
{
return (_queue->tail - _queue->head) & _queue->mask;
}
static inline uint16_t queue_capacity(const queue_t* _queue)
{
return _queue->mask;
}
static inline queue_element_t queue_peek(const queue_t* _queue)
{
return _queue->data[_queue->head];
}
static inline void queue_push(queue_t* _queue, const queue_element_t _ele)
{
_queue->data[_queue->tail] = _ele;
_queue->tail = (_queue->tail + 1) & _queue->mask;
}
static inline void queue_pop(queue_t* _queue)
{
_queue->head = (_queue->head + 1) & _queue->mask;
}
extern UART_HandleTypeDef huart1;
extern void Error_Handler();
queue_t* tx_buffer;
queue_t* rx_buffer;
void USART1_IRQHandler()
{
uint32_t isrflags = USART1->SR;
uint32_t cr1its = USART1->CR1;
uint32_t errorflags = 0x00U;
errorflags = (isrflags & (uint32_t)(USART_SR_PE | USART_SR_FE | USART_SR_ORE | USART_SR_NE));
if (errorflags == RESET)
{
if (((isrflags & USART_SR_RXNE) != RESET) && ((cr1its & USART_CR1_RXNEIE) != RESET))
{
queue_push(rx_buffer, USART1->DR);
return;
}
if (((isrflags & USART_SR_TXE) != RESET) && ((cr1its & USART_CR1_TXEIE) != RESET))
{
USART1->DR = queue_peek(tx_buffer);
queue_pop(tx_buffer);
if (queue_empty(tx_buffer))
USART1->CR1 &= ~USART_CR1_TXEIE & UART_IT_MASK;
return;
}
}
HAL_UART_IRQHandler(&huart1);
}
void MX_USART1_UART_Init()
{
tx_buffer = queue_create(1024);
rx_buffer = queue_create(1024);
huart1.Instance = USART1;
huart1.Init.BaudRate = 115200;
huart1.Init.WordLength = UART_WORDLENGTH_8B;
huart1.Init.StopBits = UART_STOPBITS_1;
huart1.Init.Parity = UART_PARITY_NONE;
huart1.Init.Mode = UART_MODE_TX_RX;
huart1.Init.HwFlowCtl = UART_HWCONTROL_NONE;
huart1.Init.OverSampling = UART_OVERSAMPLING_16;
if (HAL_UART_Init(&huart1) != HAL_OK)
{
Error_Handler();
}
USART1->CR1 |= USART_CR1_RXNEIE & UART_IT_MASK;
}
void usart1_transmit(char c)
{
uint16_t capacity = queue_capacity(tx_buffer);
bool ok = false;
while (1)
{
__disable_irq();
ok = capacity - queue_size(tx_buffer) >= 1;
if (ok)
break;
__enable_irq();
__NOP();
}
queue_push(tx_buffer, c);
USART1->CR1 |= USART_CR1_TXEIE & UART_IT_MASK;
__enable_irq();
}
char usart1_receive()
{
bool ok = false;
while (1)
{
__disable_irq();
ok = !queue_empty(rx_buffer);
if (ok)
break;
__enable_irq();
__NOP();
}
char c = queue_peek(rx_buffer);
queue_pop(rx_buffer);
__enable_irq();
return c;
}
int _write(int file, char* ptr, int len)
{
for (int i = 0; i != len; ++i)
usart1_transmit(*ptr++);
return len;
}
main.c(部分):
#include "main.h"
#include "usart1.h"
UART_HandleTypeDef huart1;
uint8_t count = 0;
void SystemClock_Config(void);
static void MX_GPIO_Init(void);
int main(void)
{
HAL_Init();
SystemClock_Config();
MX_GPIO_Init();
MX_USART1_UART_Init();
while (1)
{
printf("Hello world: %d\n", count);
HAL_GPIO_TogglePin(LED_GPIO_Port, LED_Pin);
++count;
HAL_Delay(500);
}
}
明明已經用調試器連接了開發板和電腦,還要加個USB轉串口工具就顯得很累贅;IDE和串口監視器兩個窗口的頻繁切換也讓Alt和Tab鍵損壞的幾率增加了幾成。有沒有辦法讓開發板通過調試器和IDE就能輸出呢?
可以用ARM的ITM(Instrumentation Trace Macroblock),通過TRACESWO發送。SWO與JTAG的JTDIO是同一個引腳,用標準ST-LINK的20-pin排線可以連接,但是10-pin的簡版ST-LINK沒有引出SWO,因此要使用ITM調試不能用簡版的4線接法。
ITM無需初始化,直接調用ITM_SendChar函數即可發送,該函數定義在\Drivers\CMSIS\Include\core_cmx.h中。ITM版的_write函數,不過是把usart1_transmit換成ITM_SendChar而已。
#include "main.h"
#include <stdio.h>
void SystemClock_Config(void);
static void MX_GPIO_Init(void);
int _write(int file, char* ptr, int len)
{
for (int i = 0; i != len; ++i)
ITM_SendChar(*ptr++);
return len;
}
uint8_t count = 0;
int main(void)
{
HAL_Init();
SystemClock_Config();
MX_GPIO_Init();
while (1)
{
printf("Hello world: %d\n", count);
HAL_GPIO_TogglePin(LED_GPIO_Port, LED_Pin);
++count;
HAL_Delay(500);
}
}
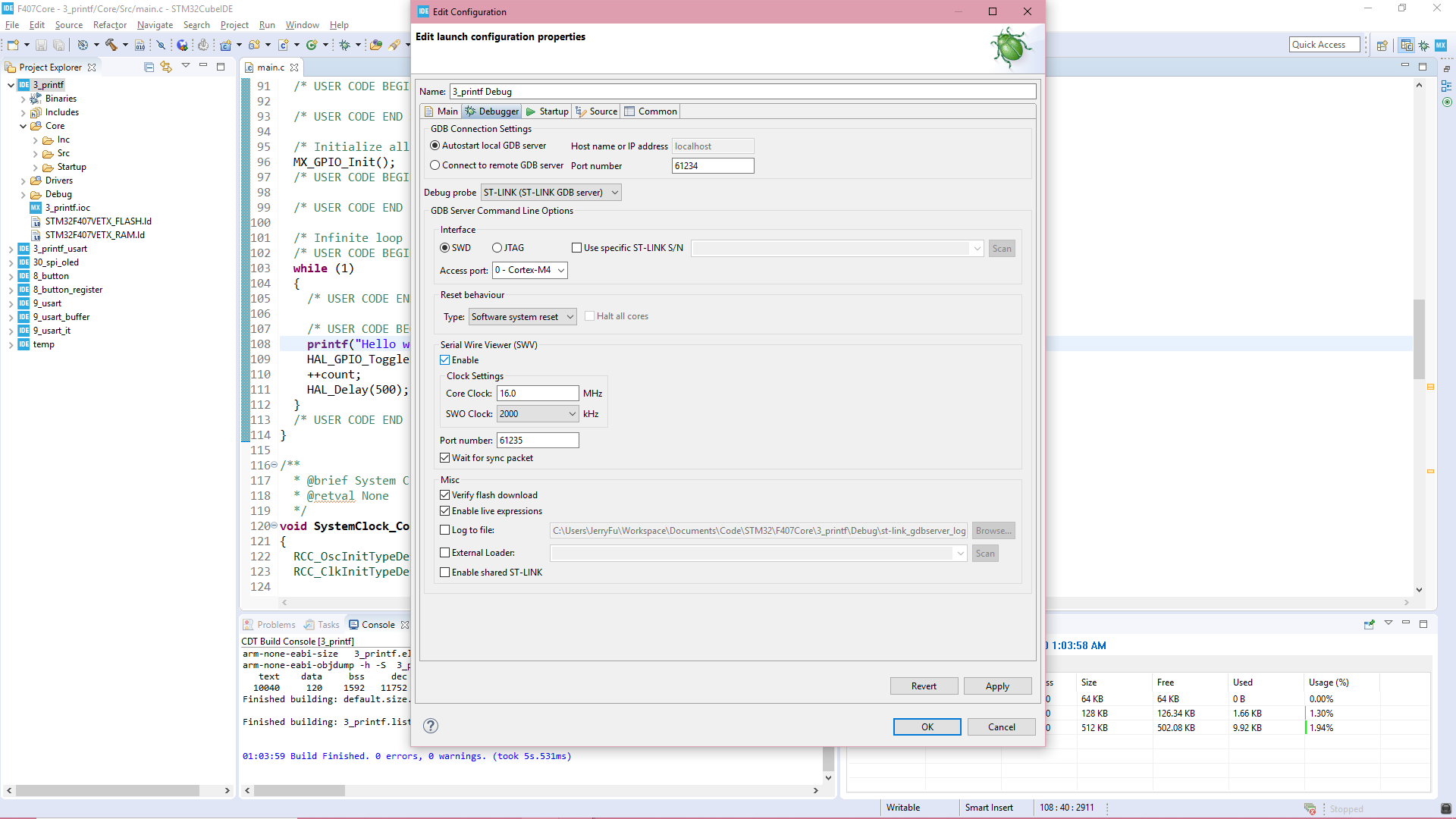
為了在IDE中看到printf輸出的內容,需要做幾步配置。首先進入Debug模式,在調試選項的Debugger頁啟用SWV:
找到SWV ITM Data Console窗口:
窗口右上角Configure trace,勾選Port 0:
點擊Start Trace。這樣就可以看見printf的輸出了:
好久沒更博客了。這兩周一直在做搖搖棒,硬件軟件交替着改,總算是做出一個比較穩定的显示效果了。計劃本月再更兩篇。
有一次下載器與搖搖棒的連接有鬆動,數據傳輸錯誤,導致熔絲位被修改,時鐘源選擇了不存在的,程序無法啟動,也無法下載新的程序。還好我帶着這塊STM32開發板,在一個引腳上產生一個較高頻率的方波,連接到單片機的晶振引腳,改回熔絲位,算是把單片機救活了。本來STM32開發板帶着是要寫這篇printf的,博客沒寫,倒是有救場的用途。
與printf相對的scanf,我也嘗試過實現,但是有兩個問題,一是我沒有找到在STM32CubeIDE中如何通過ITM向單片機發送,二是_read函數的len參數總是1024,這是想讓我一次性讀1024個字節再返回嗎?
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※別再煩惱如何寫文案,掌握八大原則!
老孟導讀:大家好,這是【Flutter實戰】系列文章的第一篇,這並不是一篇Flutter技術文章,而是介紹智能手機操作系統、跨平台技術的演進以及我對各種跨平台技術看法的文章。
後浪們可能都沒有聽說過塞班系統,而很多前浪們也會詫異,塞班是智能手機操作系統嗎?讓我們先來看下智能手機的定義:
智能手機,是指像個人電腦一樣,具有獨立的操作系統,獨立的運行空間,可以由用戶自行安裝軟件、遊戲、導航等第三方服務商提供的程序,並可以通過移動通訊網絡來實現無線網絡接入的手機類型的總稱。目前智能手機的發展趨勢是充分加入了人工智能、5G等多項專利技術,使智能手機成為了用途最為廣泛的專利產品。
所以按照如上的定義,塞班系統屬於智能手機操作系統,那為什麼很多人都認為塞班系統不屬於智能手機操作系統呢?主要是因為塞班和現在的Android、iOS智能系統比起來差遠了。
雖然現在塞班系統已經Game Over了,但當年塞班系統是當之無愧的王者,根本就沒有一個與之匹配的對手。
2008年12月2日,塞班公司被諾基亞收購。
2011年12月21日,諾基亞官方宣布放棄塞班品牌。由於缺乏新技術支持,塞班的市場份額日益萎縮。
截止至2012年2月,塞班系統的全球市場佔有量僅為3%。
2012年5月27日,諾基亞徹底放棄開發塞班系統,但是服務將一直持續到2016年。
2013年1月24日晚間,諾基亞宣布,今後將不再發布塞班系統的手機,意味着塞班這個智能手機操作系統,在長達14年的歷史之後,終於迎來了謝幕。
至此,塞班時代終結,一個時代的終結,必將伴隨着新時代的到來。
Windows Phone(簡稱為WP)是微軟於2010年10月21日正式發布的一款手機操作系統,初始版本命名為Windows Phone7.0。
2019年12月10日這一天,微軟宣布停止對Windows 10 Mobile的支持,也就宣告Windows 10 Mobile告別了歷史的舞台。
Windows Phone當年的市場份額一度超過50%,到退出歷史的舞台,在我看來微軟犯了一個很大的錯誤:
那就是Windows Phone 8的發布,由於使用了新的內核導致以前的手機無法升級而且軟件不向下兼容,導致用戶和開發者極度不爽,用戶剛買了手機,結果你告訴用戶系統不能升級?
新系統導致以前開發的App無法運行,開發者重新開發一遍?而且還要維護兩套?
系統最核心的資產是生態,當你拋棄了開發者也就意味着生態的殘缺,沒有大量優質的應用用戶怎麼可能買你的手機?
Android系統大家都非常熟悉了,畢竟是當前市場份額最大的移動操作系統,看一下Android的發展歷程:
iOS是由蘋果公司開發的移動操作系統 。蘋果公司最早於2007年1月9日的Macworld大會上公布這個系統,其發展歷程如下:
2008年7月IPhone推出第一代手機IPhone 3G,同年9月谷歌正式發布了Android 1.0系統,標志著我們正式步入移動端發展期,按照技術開發的歷程移動端(目前特指Android和iOS)的發展大致可以分為4個階段:原生階段->Hybird階段->RN階段->Flutter 階段。
使用原生語言(Android使用Java或Kotlin,iOS使用Objective-C 或 Swift )開發應用,稱之為原生階段。
在此階段發現一樣的功能需要在Android和iOS兩端開發,開發和維護成本較高,同時無動態化更新能力,緊急問題的修復和添加新功能都需要到相應平台發版,尤其是iOS審核的周期非常長,在國內Android雖然有動態化方案,但如果上架Google Play很有可能審核不通過或者下架,iOS也有動態化,但蘋果官方基本審核不通過,所以原生的動態化更新受政策影響很大。
從開發者的角度出發,是否有一種方案可以開發一套代碼在多個平台運行且可以動態化更新,無需在走平台的審核。基於這個需求H5興起,也就是我們所說的Hybird階段。
Hybird實現的基本原理是通過原生的WebView容器加載H5網頁進行渲染,通過JavaScript Bridge調用一部分系統能力,同步更新服務器上的H5網頁也實現了動態更新,俗稱混合應用。
當時大量的公司使用此方案進行開發,最出名的就是Facebook,早期的Facebook在H5上投入了大量的精力,一次開發、快速迭代這是使用H5技術巨大的優勢。
然而一切看似美好,但很快發現,H5方案存在致命的缺陷-用戶體驗極差。
Facebook創始人兼CEO馬克·扎克伯格在接受採訪的時候承認:專註在HTML 5上面是他有史以來犯過的最大的錯誤。
然而福兮禍所伏,雖然在Facebook上大量使用H5而導致用戶體驗極差,但Facebook基於強大的H5技術積累開發出了偉大的React框架,此框架是React Native框架的基礎。
React Native簡稱RN,是FaceBook在2015年開源,基於 JavaScript,具備動態配置能力跨平台開發框架。React Native框架原理如下:
React Native 使用React開發,然後生成虛擬DOM樹,虛擬 DOM 是一個 JavaScript 的樹形結構,通過虛擬DOM樹映射到不同平台的本地控件,最終显示的UI是原生控件,因此在性能體驗上和原生非常相近。和React Native 類似的框架還有阿里巴巴的Weex框架,Weex是在React Native基礎上重新設計了一套開發模式,原理上和React Native 一樣。
React Native 解決了繼承了H5的優點,同時解決了性能體驗上的問題,2015年React Native一經發布,就在技術圈引起了巨大的反響,在當時看來React Native 是一個非常完美的跨平台解決方案,很快大量開發者湧入。
當年使用React Native 的開發者最擔心的不是React Native 性能如何?體驗如何?而是擔心蘋果會不會封掉React Native,可想而之React Native 的火爆程度,當年著名的JSPatch事件起初,起初大家都在說蘋果開始對React Native下手了,雖然後來證實和React Native無關,但多多少少都對React Native 開發者造成了一定的影響。
隨着時間的流逝,發現React Native 和原生橋接的成本非常高,在複雜場景下會出現嚴重的性能問題,比如早期的ListView滑動卡頓問題。
React Native要橋接到原生控件,但Android和IOS控件的差異導致React Native無法統一API,有的屬性IOS支持,Android不支持,有的Android支持,IOS不支持,這就導致經常需要開發Android和IOS兩套插件,隨着項目的複雜度提升,也導致維護成本大幅提升。
還有一個很大的問題就是React Native 依賴於 Facebook 的維護,而每次iOS和Android系統版本更新,很大程度上會受到影響。
從技術上來說,小程序(指微信小程序,下同)並不是新的跨平台方案,它使用瀏覽器內核來渲染界面,小部分由原生組件渲染,原理圖如下:
小程序的運行環境分成渲染層和邏輯層,通信會經由微信客戶端(Native)做中轉。
微信小程序目前來看是非常成功的,在我看來微信小程序成功主要原因並不是因為技術,而是生態,當然微信小程序體驗也是非常好的。
對商家來說,微信小程序擁有月活10億的微信用戶,獲客成本低,這是一個流量極佳的平台,因此很多商家開發了體驗極好的小程序,甚至一些商家把主要平台遷移到了微信小程序。
對於用戶來說,無需下載,用完就走,極大的提升了用戶體驗,微信提供基礎服務平台,商家獲客成本低,用戶體驗提升,三方形成完美的平衡,因此微信小程序的生態越來越完善。
除了小程序外,類似的方案還有百度的輕應用和快應用,但都不溫不火。
千呼萬喚始出來,主角-Flutter終於登場了,Flutter是谷歌的移動UI框架,可以快速在iOS和Android上構建高質量的原生用戶界面。
Flutter吸收了前面的經驗,它既沒有使用WebView,也沒有使用原生控件進行繪製,而是自己實現了一套高性能渲染引擎來繪製UI,這個引擎就是大名鼎鼎的Skia,Skia是一個2D繪圖引擎庫,Chrome和Android都是採用Skia作為引擎。Flutter完美的解決了跨平台代碼復用和性能問題,大家都在感嘆:似乎UI迎來了終極解決方案。
Flutter並不是無所不能的,當你選取Flutter作為技術方案時,首先要了解Flutter無法實現哪些功能。
由於Flutter使用自己的引擎進行UI渲染,而不是用原生控件渲染,導致控件显示效果和原生不是完全一樣,雖然肉眼看起來基本一樣,但還是有一些細微的差別,尤其當Android和iOS系統升級導致原生控件效果發生變化時,Flutter開發的App並不會進行相應的變化,如果您的App需要原生控件保持完全一致,Flutter可能並不適合您。
動態化功能在國內來說是一項非常重要的功能,Google官方已經明確現階段不會實現動態化功能。
此功能並不是技術上無法實現,更多的還是政策和法律上的約束。
因此如果您的App需要動態化功能,那麼Flutter可能並不適合您。
既然Flutter已經如此優秀了,那是不是以後使用Flutter就可以了呢?答案是否定的,未來很長一段時間應該是原生、Hybird、React Native、Flutter共存時代。
老孟Flutter博客地址(330個控件用法):http://laomengit.com
歡迎加入Flutter交流群(微信:laomengit)、關注公眾號【老孟Flutter】:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
摘錄自2020年6月15日中央社報導
英國石油公司(BP)今(15日)預警,第2季將承受最多175億美元(約新台幣5200億元)損失。因武漢肺炎(COVID-19)疫情帶來「持續」經濟衝擊,重創全球石油需求。
受疫情影響,英國石油日前才公布裁減1萬個職位的計畫,今天又發布聲明表示,現行季將承受130億到175億美元的非現金資產減值和沖銷。
能源轉型
能源議題
國際新聞
英國
疫情
原油
武漢肺炎
經濟衝擊
疫情看氣候與能源
石油
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
摘錄自2020年6月21日聯合報報導
美國舊金山動物園近日舉行戶外展覽,孰料兩隻大袋鼠(wallaroos)和一隻紅袋鼠(red kangaroo)卻遭咬死,經過調查和可能是當地食肉動物犯案,目前已鎖定一隻美洲獅(山獅)涉有重嫌。
據《ABC》報導,這隻美洲獅之前因為在舊金山街道上遊蕩被捕獲,由加州大學聖克魯斯美洲獅計畫(University of California Santa Cruz Puma Project)為其戴上追蹤項圈,隨後便將牠野放。
加州野生動物局發言人帕格里亞(Ken Paglia)透露,在美洲獅重獲自由之前,舊金山動物園戶外展覽並沒有任何動物死亡因此,目前當局正朝著美洲獅犯案的方向進行調查,舊金山動物園則強調,園區已採取了額外的措施來保護動物的安全,但並未透露相關措施的細節。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※別再煩惱如何寫文案,掌握八大原則!
摘錄自2020年6月22日自由時報報導
一架載著約500隻法國鬥牛犬的烏克蘭國際航空(UIA)航班,從俄國基輔起飛到達加拿大多倫多皮爾遜國際機場(Toronto Pearson Airport)時,發現貨艙內滿滿的法國鬥牛犬幼犬,其中38隻已經死亡,還有數十隻有脫水、嘔吐現象。
案件發生於本月13日,驚動加拿大官方,加拿大食品檢驗局(CFIA)在20日宣佈,就此事展開調查。烏克蘭航空雖在19日發聲明配合加拿大當局進行調查,也承諾要做必要改變來防止類似情況發生,但是至今仍未能解釋為何允許500隻動物登機。
國際航空運輸協會(IATA)對活體動物運輸有相關的規定,大多數加國航空只允許每航班載運2個動物運籠,且氣溫超過攝氏29.5°C,就一律拒載相關的籠內動物。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
這樣的產品布局能更好地與對手競爭。它的外觀,相信看過的人都對其印象深刻。相對於其他比較傳統造型的SUV車型,標緻4008的外觀造型更加的激進。宛如概念車的造型非常具有未來感,犀利的前臉造型配合鍍鉻裝飾質感與氣場並存。
對於很多人先入為主的印象,SUV車型相比傳統的轎車來說,車身更重;同時更高的車身高度與方正的造型油耗會高不少。或許前幾年還存在這種情況,但在科技日新月異的今天;SUV的調校與動力匹配已經上升了不止一個台階。它們日常的使用成本與傳統轎車已經相差無異。今天就要介紹幾款日常使用非常省油的SUV車型。
一汽豐田 RAV4榮放
售價:17.98-26.98萬元
為了與一種競爭對手相抗衡,RAV4這款已經上市多年的車型已經迎來最新的改款。雖然還不是換代車型,但更加時尚外觀造型,全系標配ESp使得它更加性價比。
豐田最近年輕化趨勢很猛,前有卡羅拉與雷凌。如今RAV4改款之後採用了家族式的前臉造型,變得更加的年輕時尚。簡潔的前臉造型配合修長的大燈造型,整體的視覺效果很出色。作為改款車型,它的車身與車尾的變化不大,除了把之前不太美觀的排氣管換成了帶鍍鉻裝飾的排氣管,變得更加和諧。
它內飾依然保持之前的設計風格,但整體仍然有不少的變化。例如更加活潑的配色使得它整體年輕了不少。亮銀色的裝飾條則提升了內飾的質感。由於軸距沒有變化,整體的空間還是與老款差不多,實用性不用擔心。
動力依然還是之前的排量,但換裝了新發動機后動力與扭矩都有一定程度的上升。日常使用中2.0L/2.5L的動力不成很大的問題,更高效率的CVT變速箱在日常行駛的平順性與燃油經濟性非常出色。而且輕盈的轉向使得掌控起來非常輕鬆。整體的油耗表現,2.5L的車型整體也不會超過10L/100km。
東風日產 奇駿
售價:18.18-26.78萬元
激進的年輕化是否正確,或許前期會有些陣痛。但只要消費者接受了你的變化,銷量就會重新上來,日產就是這樣的一個品牌,它這兩年推出的車型非常激進,但整體的市場表現一直往上,說明消費者還是認可的。
奇駿雖然之前是一款傾向於硬派SUV的車型,在經過換代之後煥然一新變成了一個帥氣的小伙子。採用家族式的前臉造型變得更加的犀利,V型的鍍鉻條配合LED日常間行車燈,呈現出非常強烈的氣場。飽滿流暢的車身造型配合簡潔的車尾,顯得非常耐看。
進入它的車內,奇駿的內飾造型相比外觀而言新意不足。雖然相比老款進步很大,但與日產其他車型相差不大。規整的中控台層次感頗強,上深下淺的配色也符合它家用的定位。而寬敞的空間配合舒適的座椅,長途乘坐的體驗良好。
作為一款日產車,它的動力就很常規了。依然是2.0L/2.5L與CVT的主流搭配,當然低配還有手動車型。而這樣的搭配也是為了日常的平順性與省油為主,而它的舒適的底盤調校也是在闡述這種理念。日常行駛中2.0L的車型相對平庸一些,因此預算足夠的更為推薦2.5L的車型。至於油耗上,日產車一向表現出色,2.5L的車型也不過9.5L/100km。
東風標緻 4008
售價:18.57-27.37萬元
雖然標緻換了一個概念,把海外版本的3008國產之後換了一個新名字。但不可否認的是,如今標緻以3008與4008形成高低搭配,把15-30萬的價格區間覆蓋了。這樣的產品布局能更好地與對手競爭。
它的外觀,相信看過的人都對其印象深刻。相對於其他比較傳統造型的SUV車型,標緻4008的外觀造型更加的激進。宛如概念車的造型非常具有未來感,犀利的前臉造型配合鍍鉻裝飾質感與氣場並存。流暢的車身造型配以懸浮式車頂整體效果很出眾,而車尾部分則採用家族式的獅爪造型,辨識度很高。
除了外觀是其一大亮點之外,4008的內飾設計也不逞多讓。法系車的浪漫優雅呈現得非常完美。環繞式的中控造型配合亮銀色的裝飾面板與獨特的鋼琴撥鍵非常引人注目。造型獨特的座椅與優雅的內飾氛圍,坐在車內體驗非常好。
至於標緻4008的動力總成,依然是大家熟悉的那套1.6T/1.8T與6AT的搭配,整體的動力表現還可以,至少不落後競爭對手。日常行駛當中,1.6T的車型動力相對會弱一些,但相比其他的2.0L車型還是好很多。1.8T的車型會更好一些,6AT換擋足夠积極。底盤的響應也做得不錯。當然1.8T的車型油耗會相當高些,達到10.3L/100km左右。
長安馬自達 CX-5
售價:16.98-24.58萬元
作為馬自達魂動理念較早國產的一款SUV,CX-5雖然目前的熱度稍微降低了一些。但相對CX-4,它的表現更加均衡;而且目前市場終端上有不少的優惠,加上不錯的操控與燃油經濟性確實非常值得入手。
CX-5的外觀相信大家很熟悉了,雖然如今沒有剛上市那麼驚艷。但在魂動理念的加持下,依然非常的美觀。橫向的啞光進氣格柵配合大嘴設計,辨識度還是很高的。車身的造型則設計得比較緊湊一些,有點俯衝的姿態。車尾的造型變化不大,簡潔的造型配合雙邊單出的排氣還是挺美觀的。
它的內飾是被最多人吐槽的,雖然現款經過重新設計,加入了鍍鉻裝飾條使得內飾變得質感更強。層次感分明的中控整體來說還是很耐看的。沒有對比就沒有傷害。目前CX-4也用上了懸浮式的中控多媒體系統,CX-5確實很難拿得出手。
除了魂動外觀造型,CX-5的優勢還有一套出色的創馳藍天技術。雖然2.0L/2.5L的動力不算出眾,但配合的6AT變速箱換擋非常聰明,加上出色的底盤響應與力度十足的轉向,整體而言CX-5是一款操控樂趣的SUV車型。而且除此之外,它的油耗也相當出色,2.5L的車型油耗也不過9.5L/100km左右。
前幾天油價又升了,大家掙的每一分錢都不容易;因此日常開車的成本當然是越低越好了。今天介紹的這幾款車型都是其中出色的代表。RAV4榮放就不用多說了吧,豐田車一貫都是實用耐用的代表,新款不僅更加時尚,日常的使用成本也相當低廉。奇駿,雖然以前是一款硬派SUV,但如今變身為城市SUV的它變得更加美觀。日產一貫的大空間舒適的沙發也有繼承,同時省油的優勢也沒有丟掉。
雖然標緻4008是新款車型,但它搭載的動力是標緻比較成熟的那一套動力。從網友的反映來看,它的綜合油耗也是相當出色,就算1.8T的車型也不過10L/100km左右。至於最後的CX-5應該是目前優惠最低的SUV車型之一了,擁有創馳藍天技術的它不僅操控出色,而且在燃油經濟性也有很好的表現,非常值得購買。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※別再煩惱如何寫文案,掌握八大原則!
實測:在發動機測試實里我們看到各種不同的發動機,所有機油在路試之前都要在這裏分別進行100小時高溫測試、冷機潤滑性能測試、模擬實際使用情況長測,以及整車測試等。在探訪過程中我們還發現了送測的日產雷諾新1。6T機器,整車合作廠家會把最新的發動機送來研發中心,因應發動機的特性開發專用機油並加以改進,所以所謂品牌專用機油和市場上買到的還真是有區別。
說起汽車機油,相信大家都知道每次保養時需要更換,但不同機油之間的差別,好像一般用家不會太在意。比較資深的老司機會知道機油有合成、礦物油之分,也知道機油有不同標號、等級之分,但怎麼選擇一款最適合自己愛車的機油,一款好機油的技術含量有多高,你又知道多少?
在出發前,我們先掃一下盲。
發動機裏面有無數金屬部件在運動,運動過程中會產生摩擦,就好像人的關節一樣,使用了不良或是不合適的機油,發動機就好像得了關節炎一樣,運動不順暢,久而久之,甚至會得大病。
機油具有潤滑、清潔、冷卻、密封、減磨、防鏽 的功能。因此選擇機油是不能馬虎的。
Jacky 此次特意飛往來自法國的品牌—道達爾的集團總部参觀學習,給大家窺探一款優異的機油的研發過程。
什麼?只聽過殼牌、美孚、嘉實多?那你就Out 了!
道達爾是世界第四大石油天然氣公司,業務遍及130多個國家。
在汽車賽事方面,道達爾一直活躍於國內外頂級賽車運動的賽場上,在頂級的賽車運動場上始終能看到道達爾的身影,如一級方程式錦標賽(F1)、世界拉力錦標賽(WRC)、世界耐力錦標賽(WEC)、以及勒芒24小時耐力賽、達喀爾拉力賽(Dakar)。
亞洲勒芒系列賽事(ALMS)、世界房車錦標賽(WTCC)、中國越野拉力賽(CGR)、絲綢之路拉力賽(Silk Way Rally)等其它著名賽事。通過這些頂級賽事,道達爾的產品性能(潤滑油和燃油)在非常嚴苛的環境下都得到了驗證。
到底一款優良的機油是怎樣研發的呢?第一站我們來到了位於里昂近郊的道達爾Soliaze研發中心。
在這裏每年有超過1200種不同特性的潤滑油誕生。
機油研發分為調配、試驗、分析、實測幾個重要步驟:
調配:因應不同的訴求,加入不同的添加劑來達到相應的效果,你所使用的機油和F1車隊使用的機油都是在同一個實驗室由同一幫工程師調配出來的。
試驗:調和好的機油會送到實驗室進行高溫、低溫、各種耐久測試,這裏的溫度控制精度必須達到小數點后2位,因為實驗室屬於整個生產流程的最頂端,不能允許有任何誤差。在這裏我們也看到了標緻和雷諾的廠家機油測試標準,比一般的歐標和美標都要更嚴格一些。
實測:在發動機測試實里我們看到各種不同的發動機,所有機油在路試之前都要在這裏分別進行100小時高溫測試、冷機潤滑性能測試、模擬實際使用情況長測,以及整車測試等。在探訪過程中我們還發現了送測的日產雷諾新1.6T機器,整車合作廠家會把最新的發動機送來研發中心,因應發動機的特性開發專用機油並加以改進,所以所謂品牌專用機油和市場上買到的還真是有區別。
在巴黎車展上,我們看到了道達爾贊助的雷諾F1賽車、標緻3008 DKR 賽車和208WRX 賽車,在208 WRX 的宣傳片上我甚至看到添加道達爾快馳潤滑油的片段,所以我很好奇到底賽用機油跟我們民用機油的相似度有多少。
為此我特意來到了道達爾集團位於巴黎的總公司,和他們的拉力和耐力賽經理聊了一下。
道達爾多年來积極支持各大國際知名賽事,如世界房車錦標賽WTCC、世界耐力錦標賽WEC、世界拉力錦標賽WRC,一級方程式比賽F1等等,併為贊助車隊提供高品質的潤滑油產品和技術支持。
這些參賽車輛在運行過程中擁有非常高的轉速,這樣的環境對賽車發動機及潤滑油都有着嚴苛的考驗,所以賽車用油或多或少都與民用油有所不同,尤其是像F1這樣對速度要求十分高的賽事,所需的機油和民用油差別則更大,但在賽事嚴苛的使用環境中,機油可以得到深度的測試,賽後進行樣本分析,再把數據應用到民用產品當中。
和賽事中純性能取向不同,一款良好的民用機油應該具備以下特性,我們可以拿道達爾快馳9000 5W-40汽車潤滑油舉個例子:
它有哪些特性呢?:
1、全合成產品,性能穩定可本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
結構化查詢語言(SQL)是第四代編程語言的典型,這種命令式的語言更像一種指令,使用它,你只需要告訴計算機“做什麼”,而不用告訴計算機“怎麼做”。第四代編程語言普遍具有簡單、易學、能更快的投入生產等優點,但也失去了部分第三代編程語言(C,C++,Java等)的靈活性。PL/SQL 在 SQL 的基礎上,保留了部分第三代編程語言特性,它主要運行在 Oracle 數據庫上,它同時兼備了第四代語言簡單、易用的特點,又保留了高級程序設計語言的靈活性與完整性,這使得開發人員可以只使用 PL/SQL 就能進行複雜業務邏輯的編寫。
一 PL/SQL 簡介
1,簡介
標準 SQL 提供了定義和操縱數據庫對象的能力,但與傳統高級編程語言相比,由於其具有更高的抽象性,所以註定缺乏諸多高級編程語言的特性,比如封裝函數、流程控制、進行錯誤檢測和處理等。
PL/SQL 是 Oracle 在標準 SQL 的基礎上進行功能擴充后的一門編程語言,這使它保留了部分第三代編程語言的部分特性,比如變量聲明、流程控制、錯誤處理等。
PL/SQL 的全稱是 Procedural Language/SQL,即過程化結構查詢語言,正如其名所示,PL/SQL 增加了過程性語言中的結構,以對標準 SQL 進行擴充。在PL/SQL 中,最基本的程序單元是語句塊(block),所有的程序都應該由各種塊構成,塊與塊之間可以相互嵌套。在塊中,可以定義變量,執行條件判斷,循環等。
2,開發工具
Oracle 官方提供了兩款開發工具:SQL*Plus 和 Oracle SQL Developer。前者是一款命令行開發工具,後者則擁有方便的圖形化操作界面(類似SQL Server 的 SSMS)。
除了官方提供的兩款工具外,PL/SQL Develpoer 是一款由第三方公司開發的,非常流行的 Oracle 數據庫集成開發環境。除此之外,市面上還有很多其他工具也具備 Oracle 數據庫開發的能力,大家可以根據需要選擇合適的開發工具。
3,基本概念
如果你對 SQL Server 有一定了解,你應該知道,它裏面可以創建很多的數據庫,用於存儲不同業務或系統的數據,每個數據庫都有單獨的數據文件(物理磁盤存儲的)。Oracle 中有點不同,嚴格來說 Oracle 通常只有一個數據庫,然後通過表空間和方案來實現多業務的數據分離。
Oracle 通過表空間來存儲不同的內容,表空間是數據庫的邏輯劃分,每個數據庫至少有一個表空間(SYSTEM 表空間)。為了便於管理和提高運行效率,可以使用一些附加表空間來劃分用戶和應用程序。例如:USER 表空間供一般用戶使用,RBS 表空間供回滾段使用,一個表空間只能屬於一個數據庫。
方案是另一個 Oracle 中特有的概念,方案是比表空間更細粒度的另一種單元,方案用於存放用戶相關的信息。通常每個用戶都對應一個方案,並且名稱一樣。多個用戶可以共用一個表空間,但不能通用一個方案,正是由於這種方案-用戶一一對應的關係,所以我們通常也把方案理解成用戶權限所能及的對象的集合。
二 PL/SQL基礎
1,SQL 與 PL/SQL
前面提到,PL/SQL 是對標準 SQL 的擴展,所以,在 PL/SQL 中不僅可以執行 SQL 語句,還支持很多增強的特性,比如在 SQL 語句中使用變量、使用 PL/SQL 定義的函數等。在 PL/SQL 語句塊中,可以使用 SQL 語句操作數據庫,它支持所有的 SQL 數據操作、游標和事務處理命令,支持所有的 SQL 函數、操作符,完全支持 SQL 數據類型。
需要注意的是:在 PL/SQL 語句塊中,不能直接使用 DDL 語句,這是因為 PL/SQL 引擎在編譯時會檢測語句塊中所涉及的對象,如果其不存在,通常都會引發錯誤,導致 DDL 語句執行失敗。
為了解決這類綁定性錯誤,可以使用動態SQL,即把需要執行的 DDL 操作存儲在字符串中,並通過 execute immediate 來執行這個字符串,從而達到間接執行 DDL 操作的目的。
2,數據定義
數據管理主要使用 DDL 數據定義語言:create、alter、drop。
創建表和約束:
1 --在列后添加約束
2 create table table_name 3 ( 4 col1 type constraint, 5 ... 6 ) 7 --單獨添加約束
8 create table table_name 9 ( 10 col1 type, 11 ...., 12 constration cons_name cons_type 13 ) 14 --在Oracle中創建表和約束與標準SQL相同
創建索引和視圖:
1 --創建索引(非唯一)
2 --默認系統會在具有unique和primary key的列上創建唯一約束
3 create index index_name on (col1...); 4 --當提供多個列時,即創建複合索引
5 --創建視圖
6 create or replace view view_name 7 as
8 select ...; 9 --創建,如果已存在則修改視圖
10 create view ...
11 as
12 ... 13 with read only; 14 --創建只讀的視圖(推薦)
修改表或視圖:
1 --為表增加新的列
2 alter table table_name 3 add col_name type constration; 4 --移除表中已有的列
5 alter table table_name 6 drop column col_name;
刪除數據庫對象:
1 --刪除表
2 drop table table_name; 3 --刪除視圖
4 drop view view_name; 5 ...
3,數據查詢
A:標準查詢
Oracle 中的數據查詢遵循 SQL 標準,常規查詢請移步我的《SQL入門,就這麼簡單》。
B:dual 表
dual 是 Oracle 系統中對所有用戶可用的一個實際存在的表,它不能用來存儲信息,在實際開發中只能用來執行 SELECT 語句,我們可以用它來獲取系統信息,比如獲取當前系統日期,或輸出一些測試信息。
1 --獲取系統日期
2 select sysdate from dual; 3 --轉換日期格式
4 select to_char(sysdate,'yyyy-mm-dd');
5 ...
C: 偽列
常用的偽列有兩個:rownum、rowid。
在 Oracle 中沒有類似 SQL Server 中 TOP 這樣可以提取結果集前幾條記錄的關鍵字,但 Oracle 提供了一個更方便的方法,rownum 偽列。rownum 是一個動態的序號,從 1 開始,為所有查詢到的數據編號。
1 --查詢員工表中前10位員工相關信息
2 select rownum,ename,sal from emp 3 where rownum<=10; 4 -- 測試數據庫 Oracle 11g
使用 rownum 偽列時需要注意:rownum 是在基礎查詢之後動態添加上去的序號,所以,如果你想通過一條查詢語句實現提取結果集中間的部分記錄是不能成功的,必須使用子查詢,把 rownum 當做普通列才能實現。
1 select row_num,empno,ename,sal from ( 2 select rownum as row_num,empno,ename,sal from emp 3 )a 4 where row_num >5 and row_num <=10; 5 -- 別名是為了防止服務器把外層的rownum再次當做偽列
同理,提取使用 order by 排序后的記錄,也需要使用子查詢。
和 rownum 不同,rowid 偽列是和表中的數據一樣實際存在的列,它是一種數據類型,是基於 64 位編碼的 18 個字符,用來唯一的表示一條記錄物理位置的一個id。我們可以通過 rowidtochar 函數把它轉換成字符串進行显示,還可以通過它來刪除表中重複的記錄。
1 --查看rowid
2 select rowidtochar(rowid) ename,sal from emp; 3 --基於rowid刪除表中形同的記錄
4 delete from emp 5 where rowid not in ( 6 select min(rowid) from emp group by empno 7 );
4,數據操縱
數據操縱主要包含以下操作:insert、update、delete、merge。
A:insert 插入
1 --方式一
2 insert into table_name(column list)--如果不提供字段列表,下面的值列表需要提供每個字段的值,即使可以為空或有默認值
3 values
4 (value list), 5 (value list), 6 .... 7 --方式二
8 insert into table_name 9 select ... 10 --從其他查詢獲取數據,並插入表,數據必須符合表的約束
B:update 更新
1 --方式一
2 update table_name 3 set col=newValue 4 where ...--如果不提供過濾條件,則更新表中所有的列
5 --方式二
6 update table_name 7 set (column list)=
8 (select ...) 9 --通過子查詢更新表,如果只更新一列,則可以省略column list 的括號,需要注意子查詢的字段順序需要和更新的字段順序一致
C:delete
1 --方式一
2 delete from table_name 3 where ...--如果不提供過濾條件,則會刪除所有記錄
5,序列
Oracle 中沒有 SQL Server 中 identity() 標識函數,也沒有 MySQL 中 auto_increnent 這樣的選項來實現自增的列。但 Oracle 提供了更有用的“序列”。類似一個封裝好的函數,每次執行會返回一個按指定步長增長或減小的数字。常用來為表設置自增的主鍵。
1 create sequence seq_name 2 increment by n --自增的步長,(省略該選項則)默認為1,負數表示遞減
3 start with n --序列的初始值,默認為1
4 max value n | nomaxvalue --指定最大值或沒有最大值(無限增長)
5 min value n | nominvalue --指定最小值或沒有最小值(無限減小)
6 cycle | nocycle --規定設置的序列到達最大或最小時是否從開頭循環
7 cache n | nocache --規定是否在內存中緩存序列值,以改善性能
通常情況下,我們只需要指定初始值,最大值和循環三項,即可創建一個序列。
1 create sequence my_seq 2 start with 1
3 nomaxvalue 4 nocycle;
序列也是 Oracle 數據庫對象之一,序列有兩個常用的屬性:nextval、currval。
1 select my_seq.nextval from dual;--獲取下一個序列值
2 select my_seq.currval from dual;--查看當前序列值
3 --在插入數據是使用序列
4 insert into table_name 5 values
6 (my_seq.nextval,...) 7 --使用循環批量插入時非常方便
我們可以為每個表創建單獨的序列,從而為每個表提供沒有間隙(無刪除數據或回滾等操作干擾)的自增字段作為主鍵。
修改和刪除序列:
1 alter sequence seq_name 2 ... 3 --為了保證主鍵的變化有相同的規律可循,一般不建議修改已創建的序列
4 drop sequence seq_name
三 Oracle 內置函數
1,字符串函數
1 --把二進制轉換成字符
2 select CHR(0101) from dual; 3 --連接字符串
4 select concat(111,'aaa') from dual; 5 select 111 || 'aaa' from dual; 6 --首字母大寫
7 select INITCAP('char') from dual; 8 --全大/小寫轉換
9 select lower('ABC'),upper('abc') from dual; 10 --左/右填充
11 select lpad('aa',5,'*'),rpad('aa',5,'*') from dual; 12 --刪除字符串左/右指定字符(第二個參數中包含的字符都會被刪除)
13 select ltrim('aaa123aaa','1a'),rtrim('aa123aa','a') from dual; 14 --刪除左右空格
15 select trim(' aaa ') from dual; 16 --從左邊開始刪除指定字符(單個),可選參數還包括:trailing(從右邊開始),both(兩邊一起)
17 select trim(leading 'a' from 'aa123aa') from dual; 18 --從指定位置開始截取指定長度的字符串
19 select substr('abcdefg',2,3) from dual; 20 --字符替換(第二個參數中包含的字符都會被替換)
21 select translate('11aa22aa11', 'a2', 'bb') from dual; 22 --替換 NULL 值
23 select nvl(NULL,'aha') from dual;
2,數學函數
1 --絕對值
2 select abs(-123) from dual; 3 --向上取整
4 select ceil(1.2),ceil(-1.2) from dual; 5 --向下取整
6 select floor(1.8),floor(-1.8) from dual; 7 --返回自然常數 e 的 n 次方
8 select exp(5) from dual; 9 --返回以第一個參數為底的第二個參數的對數
10 select log(3,10) from dual; 11 --求模,如果第二個參數為0,則返回第一個參數
12 select mod(10,3) from dual; 13 --返回第一個參數的第二個參數次方
14 select power(2,3) from dual; 15 --保留指定小數位,最後一位小數四舍五入得來
16 select round(1.2345,3) from dual; 17 --保留指定小數位,其餘直接截斷
18 select trunc(1.2345,3) from dual; 19
20 --格式化数字(格式位數應該與数字位數相同)
21
22 --用0格式化時,如果数字位數不夠,結果會用0補齊位數
23 select to_char(123456789000,'000,000,000,000,000') from dual; 24 --用9格式化時,如果数字位數不夠,結果會用空格補齊位數
25 select to_char(123456789000,'999,999,999,999,999') from dual; 26 --使用fm格式化小數
27 select to_char(123456.258,'fm999,999,999.99') from dual; 28 --使用 $(美元) 或 L(當地) 添加貨幣符號
29 select to_char(123.456,'L999.999') from dual; 30 /* 注意貨幣符號和小數不能一起使用 */
3,時間和日期函數
1 --返回操作系統日期
2 select sysdate from dual; 3 --返回日期部分
4 select current_date from dual; 5 --返回日期+時間
6 select current_timestamp from dual; 7 --返回操作系統日期—+時間(包含時區信息)
8 select systimestamp from dual; 9 --按格式化日期為字符串
10 select to_char(sysdate,'YYYY-MM-DD HH:MM:SS') from dual; 11 --把字符串表示的日期轉換成日期類型的值返回(前後格式需保持一致)
12 select to_date('2020-05-28 17:02:00','YYYY-MM-DD HH24:MI:SS') from dual; 13 --把字符串表示的日期轉換成日期 + 時間類型的值返回(前後格式需保持一致)
14 select to_timestamp('2020-05-28 17:02:00','YYYY-MM-DD HH24:MI:SS') from dual; 15 --返回指定日期後幾個月的日期
16 select add_months(sysdate,1) from dual; 17 --返回兩個日期間間隔月數(注意正負)
18 select months_between(sysdate,to_date('2020-07-01','YYYY-MM-DD')) from dual; 19 --把日期按指定精度截斷,可選參數有yyyy(精確到年,返回當年的第一天的日期),mm(精確到月,返回當月第一天的日期),rr(精確到日,返回當天的日期)
20 select trunc(sysdate,'mm') from dual; 21
22 /* ----------------------日期可選格式--------------------- */
23 TO_CHAR(sysdate, 'DD-MON-YYYY HH24:MI:SS') 24 TO_CHAR(sysdate, 'DD-MON-YYYY HH12:MI:SS PM') 25 TO_CHAR(systimestamp, 'DD-MON-YYYY HH24:MI:SS.FF') 26 TO_CHAR(sysdate, 'DY, DD-MON-YYYY') 27 TO_CHAR(sysdate,'Month DDth, YYYY') 28 TO_CHAR(systimestamp, 'DD-MON-YYYY HH24:MI:SS TZH:TZM') 29 TO_CHAR(sysdate, 'MM/DD/YYYY HH24:MI:SS') 30 TO_CHAR(sysdate, 'MM/DD/YY HH24:MI:SS') 31 TO_CHAR(sysdate, 'MM/DD/RRRR HH12:MI:SS PM') 32 TO_CHAR(sysdate, 'MM/DD/RR HH12:MI:SS PM')
4,聚合函數
1 --計算行數(不計算空值)
2 select count(*) from emp;--根據所有列計算
3 select count(comm) from emp;--根據某一列計算(注意該列是否有空值)
4 select count(distinct deptno) from emp;--計算deptno中不同值的個數
5 --計算列的最大/小值
6 select max(sal),min(sal) from emp; 7 --返回中間值
8 select median(sal) from emp; 9 --返回標準差
10 select stddev(sal) from emp; 11 --求和
12 select sum(sal) from emp; 13 --計算方差
14 select variance(sal) from emp; 15 --偽列 rownum,每條數據的序號
16 select rownum,empno,ename,sal from emp;
四 變量和類型
1,PL/SQL 基礎
如果想通過 PL/SQL 程序輸出內容,需要先執行以下命令,以打開輸出功能,否則即使 PL/SQL 程序正常執行,也不會有任何信息輸出。
1 set serveroutput on--可以不需要語句結束標記';',這是開發工具的命令
2 dbms_output.enable;--這是 Pl/SQL 提供的
PL/SQL 程序由不同的 block(程序塊)組成,塊是 PL/SQL 程序的基本組成單位,塊又可以分為匿名塊和命名塊。
一個完整的 PL/SQL 程序一般包含 3 部分:declare(聲明),execution code(執行代碼,即業務邏輯代碼),exception(異常處理),聲明和異常處理不是必須的。
1 declare
2 --... 包括變量、游標等
3 begin
4 --... 業務代碼
5 exception 6 --... 異常處理
7 end;
讓我們來看一個最簡單的 PL/SQL 程序:
1 --注意,PL/SQL業務代碼必須運行在 begin...end 中
2 begin
3 dbms_output.put_line('hello world'); 4 end; 5 --沒有聲明和異常部分
塊與塊之間可以相互嵌套,PL/SQL 中程序塊可以限制變量的作用域(變量的作用域問題稍後的章節將會詳細講解),另外,使用<<name>>為塊命名可以讓整個程序可讀性更好:
1 <<outer>>--oracle 11g 不允許給最外層塊命名
2 begin
3 dbms_output.put_line('outer block'); 4 <<inner>>
5 begin
6 dbms_output.put_line('inner block'); 7 end; 8 end;
2,變量
PL/SQL 中的變量在 declare 區域聲明,不需要額外的標識符,只需要提供變量名和值類型即可。
1 declare
2 v_name emp.ename%type;--通過動態獲取表中列的數據類型,來確定變量的數據類型
3 v_job varchar(50);--直接指定具體的數據類型
4 begin
5 v_name:='&name';--通過:=為變量賦值
6 end;
&name,這種形式是 SQL Developer 工具提供的一種變量形式:替換變量,在執行程序時,你可以手動指定變量的值,提升程序的交互性,測試程序時非常有用。需要注意的是,它並不是 PL/SQL 提供的功能,當使用 & 標識變量時,每次執行該程序都需要提供值,如果使用 && 標識,則只需要在第一次執行時提供,後續執行都默認為第一次提供的值。
給變量賦值除了通過 := 的方式,還可以使用 select…into 的方式,直接從查詢中獲取值並賦給變量。
1 declare
2 v_job emp.job%type; 3 begin
4 select job into v_job from emp where ename=v_name;--通過select...into 為變量賦值
5 dbms_output.put_line(v_job);--輸出變量值
6 end;
3,記錄類型
當有多個邏輯相關的變量需要聲明時,我們可以使用記錄類型來封裝他們,封裝好這個東西就是記錄類型(record)。
1 declare
2 type emp_record is record(--這裏相當於定義了一種新的數據類型,類型名稱是emp_record,和varcahr,int等類型一樣
3 v_name emp.ename%type, 4 v_job emp.job%type, 5 v_sal emp.sal%type 6 ); 7 --記錄類型類似其他編程語言中的類
8 v_emp_record emp_record;--聲明一個emp_record類型的變量,相當於創建一個類的實例
9 begin
10 select ename,job,sal into v_emp_record from emp where ename='ALLEN';--注意查詢的順序必須和記錄類型中定義的順序一致
11 dbms_output.put_line(v_emp_record.v_name||' '||v_emp_record.v_job||' '||v_emp_record.v_sal); 12 --通過實例訪問相關屬性
13 end;
%rowtype:
1 declare
2 v_emp_record emp%rowtype;--聲明一個包含指定表中所有列的rowtype變量,使用上和記錄類型完全一致,但它本質上並不是記錄類型
3 begin
4 select * into v_emp_record from emp where ename='ALLEN';--把所有的列都查詢出來賦值給該變量
5 dbms_output.put_line(v_emp_record.ename||' '||v_emp_record.sal); 6 --該變量中的屬性和表的列名完全一致,可以根據需要,只使用部分數據
7 end;
4,集合
集合類似其他編程語言中的數組,也可以通過下標來訪問數據。
如果把它和記錄類型、變量相比教,你會發現,標量標量是用來處理單行單列數據的,記錄類型適合處理單行多列的數據,而集合則是用來處理單列多行數據的。
Oracle 提供了三種類型的集合:索引表(又稱關聯數組)、嵌套表、可變長度數組。
索引表可以通過数字或字符串來作為下標存儲數據,下標可以不連續,索引表的容量即是数字的最大值,但它只能存儲在內存中。
1 declare
2 type idx_table is table of varchar(20) index by pls_integer;--創建索引表類型
3 -- index by 后可選的參數有pls_integer、binary_integer、varcahr(size)和使用%type 指定的varchar2類型
4 v_idx_table idx_table;--聲明索引表類型的變量
5 begin
6 v_idx_table(1):='hello';--插入值
7 v_idx_table(2):='world'; 8 dbms_output.put_line(v_idx_table(1)||' '||v_idx_table(2)); 9 end;
嵌套表只能使用数字作為下標,数字必須是有序的,嵌套表的容量沒有限制,可以保存到數據庫中。
1 declare
2 type nest_table is table of varchar(20);--創建嵌套表類型
3 v_nest_table nest_table:=nest_table('x');--聲明嵌套表類型的變量並初始化
4 --未初始化的嵌套表類型實際上是一個null,如果試圖為其賦值會報錯。初始化就是調用一個和創建的嵌套表類型同名的函數,
5 --函數的參數值類型需要和嵌套表類型定義的存儲值類型(of 后的類型)相同,並且參數的個數默認就是這個嵌套表類型變量的初始容量
6 begin
7 v_nest_table.extend(5);--擴充嵌套表類型變量的容量
8 --如果要增加嵌套表的容量,需要調用extend方法(該方法將在稍後詳細說明)
9 v_nest_table(1):='hello';--插入值
10 v_nest_table(2):='world'; 11 dbms_output.put_line(v_nest_table(1)||' '||v_nest_table(2)); 12 dbms_output.put_line(nvl(v_nest_table(3),'it is null'));--沒被使用的位置為null
13 end;
可變長度數組和嵌套表類似,都只能使用有序的数字作為下標,可變數組在定義時必須指定容量,但在運行時可以手動的擴充其容量,所以,可變數組的真實容量也可以是無限的,可變數組也可以存儲到數據庫中。
1 declare
2 type varr is varray(5) of int;--創建可變數組類型
3 v_varr varr:=varr();--聲明可變數組類型的變量並初始化
4 --和嵌套表一樣的原因,必須初始化
5 begin
6 for i in 1..5 loop--循環插入值
7 v_varr.extend(); 8 v_varr(i):=i; 9 end loop; dbms_output.put_line(v_varr(1)||','||v_varr(2)||','||v_varr(3)||','||v_varr(4)||','||v_varr(5)); 10 end;
嵌套表和可變數組能存入數據庫是指:他們可以和普通數據類型一樣,用來定義表的列。
1 --第一步,創建一個保存在數據庫中的嵌套表類型
2 create or replace type nest is table of varchar(20); 3 --第二步,創建一個帶有嵌套表類型列的數據表
4 create table x( 5 x_id int, 6 x_nest nest 7 )nested table x_nest store as y;--使用nest table 指定這是一個包含嵌套表類型值的數據表,並通過 store as 創建一個關聯表來專門存儲嵌套表 8 --插入一條數據(包含初始化的嵌套表類型值)
9 insert into x values(1,nest('x','y','z')); 10 --第三步,在PL/SQL中讀取嵌套表類型的值(多行操作使用游標)。數據表並沒有直接存儲嵌套表,所以不能直接使用select查詢,而應該在PL/SQL程序塊中查詢
11 declare
12 v_nest nest; 13 begin
14 select x_nest into v_nest from x; 15 for i in 1..3 loop 16 dbms_output.put_line(v_nest(i)); 17 end loop; 18 end;
把可變長度數組存放到數據庫就不需要使用 nested table 和 store as 指定相關信息,而且可以直接使用 select 查詢存儲了可變長度數組的數據表。所以,通常的建議是,當只是臨時使用集合,那麼索引表是最好的選擇,如果需要把集合存入數據庫,可變數組更操作起來更簡單。
5,集合常用方法
集合的方法通過“.”點的形式調用:集合.方法。
1 集合.exists(n)--判斷是否存在某個集合的值
2 集合.count--統計集合中值的個數
3 集合.limit--查詢集合容量(長度)
4 集合.first/集合.last--集合中第一個/最後一個值的索引
5 集合.prior(n)/集合.nest(n)--指定索引位置前一個/下一個值的索引(一般用在索引表中,因為其下標可能不連續)
6 集合.extend/集合.extend(n)--為集合增加1個/n個容量(一般用在嵌套表和可變數組中)
7 集合.trim/集合.trim(n)--從集合末尾刪除1個/n個元素(一般用在嵌套表和可變數組中)
8 集合.delete/集合.delete(n)--從集合中刪除所有元素/第n個元素(一般用在索引表和嵌套表中)
6,變量的作用域
1 declare
2 v1 int default 1;--外層塊變量v1
3 begin
4 dbms_output.put_line(v1); 5 --dbms_output.put_line(v2);error 必須聲明v2
6 declare
7 v2 int default 2;---內層塊變量
8 v1 int default 3; 9 begin
10 dbms_output.put_line(v1);--返回3
11 end; 12 end;
變量只在聲明的塊中起作用,內層塊可以訪問外層塊的變量,但外層塊無法訪問內層塊的變量,如果內外塊聲明的相同的變量,那麼 PL/SQL 採用就近原則。
五 流程控制
1,case
case 語句有兩種語法,簡單 case 語法只做等值匹配,搜索 case 語法可以做區間匹配。
先來看簡單 case 語法:
1 declare
2 v_sal int; 3 begin
4 select sal into v_sal from emp where empno=&empno; 5 case v_sal 6 when 800 then dbms_output.put_line('太少了吧'); 7 when 1600 then dbms_output.put_line('這還差不多'); 8 when 3000 then dbms_output.put_line('這樣更好'); 9 when 5000 then dbms_output.put_line('這樣最好'); 10 else dbms_output.put_line('隨緣吧'); 11 end case; 12 end;
搜索 case 語法:
1 begin
2 select sal into v_sal from emp where empno=&empno; 3 case
4 when v_sal<=1000 then dbms_output.put_line('太少了吧'); 5 when v_sal<=1600 then dbms_output.put_line('這還差不多'); 6 when v_sal<=3000 then dbms_output.put_line('這樣更好'); 7 when v_sal<=5000 then dbms_output.put_line('這樣最好'); 8 else dbms_output.put_line('隨緣吧'); 9 end case; 10 end;
請仔細觀察兩種語法的區別。
2,if…elsif…else
1 declare
2 v_sal int; 3 begin
4 select sal into v_sal from emp where empno=&empno; 5 if v_sal>=5000
6 then dbms_output.put_line('還有頭髮嗎'); 7 elsif v_sal>=3000
8 then dbms_output.put_line('還有一半嗎'); 9 else
10 dbms_output.put_line('好好珍惜頭髮啊,少年'); 11 end if; 12 end;
請注意,PL/SQL 中的多分支結構 elsif 關鍵字與其他語言相比,少了一個字母 e,且 els 和 if 之間沒有空格。
3,循環
PL/SQL 提供了 3 種循環:loop、while、for(集合部分已經見過了)。
在正式介紹循環之前,首先要介紹 PL/SQL 中的循環控制語句:exit,無條件結束整個循環(類似其他語言中的 break)。continue,結束本次循環,繼續下一次循環。接下里讓我們通過例子來詳細說明每個循環的使用方法。
loop 循環:
1 declare
2 i int default 1;--定義,初始化循環控制變量
3 begin
4 loop 5 if i=5 then
6 i:=i+1; 7 continue;--當n等於5時,直接結束本次循環,不輸出
8 end if; 9 dbms_output.put_line(i); 10 i:=i+1;--修改循環控制變量
11 exit when i>10;--根據循環控制比變量,判斷是否退出循環
12 end loop;--結束循環
13 end;
while 循環:
1 declare
2 i int default 1;--定義,初始化循環控制變量
3 begin
4 while i<=10 loop--根據循環控制變量,判斷是否進入循環體
5 dbms_output.put_line(i);--循環體
6 i:=i+1;--修改循環控制變量
7 end loop;--結束循環
8 end;
for 循環:
1 begin
2 --在for循環中,初始化循環控制變量,只需指明變量名即可,類型系統默認為数字,min..max指明控制變量的變化範圍,從min開始,到max結束
3 for i in reverse 1..10 loop--i可以被循環體引用,但不能被賦值
4 dbms_output.put_line(i);--循環體
5 --注意,因為初始化循環變量時已經指定了變化範圍,這相當於限定了循環條件,當變量從min變化到max時將自動結束循環
6 end loop; --結束循環
7 --最後說明,reverse是可選的參數,表示循環變量從max開始,到min結束
8 end;
4,雜項
這裏要介紹兩個東西,null 語句(不是null 值)和 goto 語句。null 語句表示什麼也不做,goto 可以無條件跳轉到程序指定位置。
1 begin
2 if ... then
3 ... 4 else
5 null;--什麼也不做,但使整個語句塊更豐滿,可讀性更高
6 end if; 7 end;
1 declare
2 i int:=0; 3 begin
4 <<outer>>--定義一個標籤
5 i:=i+1; 6 dbms_output.put_line(i); 7 if i<10 then
8 goto outer;--通過goto實現類似循環的結構
9 else
10 null;--通過使用null讓語句塊更易讀
11 end if; 12 end;
使用 goto 語句會破壞程序常規的執行流程,它是有別於順序、分支、循壞的另一種執行流程,如無特別需求,建議不要使用。
六 異常處理
1,異常簡介
無論何時何地何人,在編程的領域,總是無法避開異常。為了保證程序的健壯性,多數語言都提供了異常處理機制,PL/SQL 也不例外。
在 PL/SQL 中,異常大致可分為兩大類:
編譯時錯誤:程序在編寫過程中的錯誤,例如語法錯誤,訪問不存在的對象等,這類錯誤在編譯時 PL/SQL 引擎就會發現,並通知用戶。
執行時錯誤:這類錯誤會順利通過程序的編譯環節,只能等到執行時才能被發現,比如除數是 0 。這類錯誤也是最要命的。
2,異常處理語法
我們知道,PL/SQL 程序分為三個部分:聲明區,執行區,異常處理區。基本的異常處理也包含此三個步驟:
A:在定義區,定義異常。
B:在執行區,觸發異常。
C:只要執行區觸發了異常,那麼執行區後續的業務代碼都會立即停止執行,執行流程跳轉至異常處理區。
1 declare
2 異常變量名 exception; 3 begin
4 ... 5 raise 異常變量名; 6 ... 7 exception 8 when 異常變量名 9 then ... 10 end;
如果有多個異常,可以定義多個變量,並在合適的時候觸發他們,並在異常處理區通過多個 when…then 來捕獲他們,並執行特定操作。
3,預定義異常
大多數編譯時的異常,Oracle 都在內部隱式的定義好了,並且不需要在執行區手動的觸發,這類異常的處理最為簡單:
declare v_tmp varchar(10); begin v_tmp:='超過10字節的長度了'; exception when value_error then dbms_output.put_line('出現value_error錯誤!' || '錯誤編號:'|| sqlcode || '錯誤名稱' || sqlerrm); end;
PL/SQL 中出現的錯誤,都一個錯誤號,一個錯誤編碼(sqlcode),一個錯誤名稱(sqlerrm)。在錯誤處理區通過在 when 後面指定錯誤名稱,既可捕獲到指定錯誤了。常見的預定義錯誤如下:
| 錯誤號 | 異常編碼 | 異常名稱 | 描述 |
| ora-01012 | -1017 | not_logged_on | 在沒有連接數據庫時訪問數據 |
| ora-01403 | 100 | no_date_found | select…into沒有返回值 |
| ora-01422 | -1422 | too_many_rows | select…into結果集超過一行 |
| ora-01476 | -1476 | zero_divide | 除數為0 |
| ora-01722 | -1722 | invalid_number | 字符串和数字相加時,字符串轉換失敗 |
| ora-06502 | -6502 | value-error | 賦值時,變量長度不足 |
| ora-06530 | -6530 | access_into_null | 向null值對象賦值 |
| ora-06592 | -06592 | case_not_found | case語句中沒有任何匹配的值並且沒有else選項 |
更多預定義異常請查詢 Oracle 11g 《Oracle 在線文檔》。
4,自定義錯誤
1 declare
2 e_nocomm exception;--定義一個異常名稱
3 v_comm number(10,2); 4 begin
5 select comm into v_comm from emp where empno=&empno; 6 if v_comm is null
7 then raise e_nocomm;--觸發自定義異常
8 end if; 9 exception 10 when e_nocomm--捕獲自定義異常
11 then dbms_output.put_lne('該員工沒有提成'); 12 when others--捕獲未定義的錯誤 13 then dbms_output.put_line('未知錯誤 !'); 14 end;
同一個塊中不能同時聲明一個異常多次,但不同的塊中可以定義相同的異常,在各自的塊中使用不會相互影響。
七 編程對象
1,事務
在 SQL Server 中,每一條 DML 語句都是一個隱式的事務,除非显示的開始一個事務,否則,這些語句執行完就立即向數據庫提交了這些更改。而在 Oracle 中,每一條 SQL 語句開始都會自動開啟一個事務,除非显示的使用 commit 提交,或退出某個開發工具而斷開連接,才會提交到數據庫,否則這些操作都只會保存在內存中。
1 --在Oracle SQL Developer中
2 begin
3 insert into dept values(88,'開發部','cd'); 4 savepoint a;--設置保存點a
5 insert into dept values(88,'設計部','cd'); 6 exception 7 when dup_val_on_index then
8 dbms_output.put_line('插入出錯'); 9 rollback to a;--回滾到a
10 end; 11 --這裏我們人為的製造了一個違反唯一約束的插入操作,在錯誤區捕獲該錯誤,然後回滾到保存點a
12 select * from dept;--只能查詢到開發部被插入
1 /* 在 SQL*Plus 中 */
2 SQL>select * from dept; 3 /* 連開發部都沒有被插入 */
1 -- 在 Oracle SQL Developer中
2 commit; 3 --現在插入已經被提交到數據庫,在SQL*Plus 中也可以查詢到了
在多個事務併發執行時,大概率會發生:一個事務讀取到另一個事務還未提交的數據(臟讀);一個事務中不同時間點執行的同一個查詢,由於其他事務對涉及的數據進行了修改或刪除(不可重複讀)或插入(幻讀),而導致出現不一樣的結果。
為了解決這樣的問題,Oracle 允許對事務設立隔離級別:
1 begin
2 commit; 3 set transaction read only;--只讀的事務
4 --settransaction read write;--可讀寫的事務
5 --set transaction isolation level [serializable | read commited];
6 --serializable:整個事務只能讀到當前事務開始前就以提交的數據
7 --read commited:當前事務中的查詢,只能讀到該查詢前以提交的數據(不是整個事務,而是該查詢語句。這也是 Oracle 默認的隔離級別)
8 end;
由於一個事務中有且只能存在一條 set transaction 語句,且必須是事務的第一條語句,所以通常先使用 commit 結束前一個事務(理論上rollback也可以),以保證該語句是事務的第一條語句。
2,子程序
Oracle 中子程序事實上就是 SQL Server 中對存儲過程和用戶自定義函數的總稱。過程和函數本質上是一個命名塊,可以被存儲在數據庫中,並在合適的時候調用,這樣可以解決代碼重用的問題,並且由於它是已編譯好的代碼,所以執行起來也更快。
過程和函數相比,過程不會返回值,常用來做數據的增刪改。而函數必須有返回值,通常用來嚮應用程序返回值。其他方面,過程和函數幾無區別。
存儲過程:
1 --無參過程
2 create or replace procedure p2 as
3 begin
4 dbms_output.put_line('hello world'); 5 end p2; 6 --or replace:如果存在則替換存儲過程,建議使用
7 --p1:過程名
8 --as:不能省略,也可以用is代替
9 --end p2:創建完成時也要跟上過程名
1 --帶參數的過程
2 create or replace procedure p2(p_deptno in int)--使用括號添加過程需要的形參
3 as
4 v_empcount number;--定義過程中需要使用的變量,只需指定數據類型,不能添加類型所佔字節長度
5 begin
6 select count(ename) into v_empcount from emp where deptno=p_deptno; 7 if v_empcount>0 then
8 dbms_output.put_line('有人'); 9 else
10 dbms_output.put_line('沒人'); 11 end if; 12 end p2;--不要忘了過程名
1 --調用存儲過程
2 begin
3 p2(20);--通過()傳遞實參
4 end; 5 --call p2(20);
函數:
1 --創建函數
2 create or replace function f1 3 return number--需要指定返回值類型,不需要長度
4 as
5 begin
6 return 1;--需要使用return指定返回值
7 end f1; 8 --調用函數
9 declare
10 v_f1 number(10); 11 begin
12 v_f1:=f1();--調用函數,並把返回值賦值給變量
13 dbms_output.put_line(v_f1); 14 end;
在上面帶參數存儲過程中,指定形參時使用關鍵字 in,該關鍵字表示參數的模式是輸入型,可選的還有 out 輸出型,in out 輸入輸出型。如果不提供,默認是輸入型參數。
in 模式的參數被用作輸入參數,在過程內部只能被訪問,不能被賦值。
out 模式的參數被當做輸出參數使用,在過程內部可以被賦值,不能訪問。使用 out 類型參數時,必須在過程外部定義一個變量,用於接收過程在內部需要輸出的值,然後在調用子程序時把該變量當做形參傳入。待過程執行完畢,直接訪問外部定義的這個變量即可得到過程希望輸出的值了。
in out 模式的參數既可以被當做輸入參數,也可以被當做輸出參數。使用方式和 out 型參數一致,但可以給這個變量一個初始化值,一併傳入過程內部。out 型參數即使傳入了初始值,也會被過程忽略。
過程的參數模式和 MySQL 完全一致,例子可以參考我的《MySQL 編程》。函數本身就需要使用 return 返回值,所以不使用 in 或 out 指定參數模式,這樣毫無意義。
3,觸發器
Oracle 中的觸發器本質上也是一個命名的語句塊,定義的方式和 PL/SQL 語句塊差不多,但它和過程或函數不同,它只能被隱式的調用。並且不能接受任何參數。
定義觸發器的語法:
1 create or replace trigger trigger_name--觸發器名稱
2 [before | after | instead of]--在事件之前還是之後執行觸發器中的代碼
3 trigger_event--觸發事件
4 [referenceing_caluse]--通過新的名稱引用當前正在更新的數據
5 [when trigger_condition]--指定觸發條件
6 [for each row]--指定行級觸發器(每一條記錄都觸發一次)
7 trigger_body--觸發體(程序塊)
一個簡單例子:
1 create test(--創建測試表
2 id int primary key, 3 name varchar(20) 4 ) 5 create or replace trigger t_test--創建觸發器
6 after insert or update or delete--觸發操作(也可以是其中一種)
7 on test--在表test上
8 for each row--行級觸發器
9 begin
10 if inserting then--在插入數據時
11 dbms_output.put_line('插入了數據,name:'||:new.name); 12 end if; 13 if updating then--在更新數據時
14 dbms_output.put_line('更新了數據,oldname:'||:old.name||',newname:'||:new.name); 15 end if; 16 if deleting then--在刪除數據時
17 dbms_output.put_line('刪除了數據,name:'||:old.name); 18 end if; 19 end;
謂詞:new 表示引用新的數據(更新后或插入的數據),:old 引用舊的數據(被刪除的或更新前的數據)。可以在創建觸發器時通過 referencing(操作類型之後,for each row 之前) 指定新的謂詞。
1 ... 2 referencing old as test_old new as test_new 3 ... 4 --下面通過:test_old 引用修改前的數據,:test_new引用修改后的數據
測試代碼:
1 insert into test values(1,'r'); 2 update test set name='e' where id=1; 3 delete from test where id=1; 4 --注意觀察輸出結果
4,游標
Oracle 中的游標用來處理多行多列的數據集合,包含四個步驟:定義,打開,遍歷,關閉。游標的語法如下:
1 cursor cursor_name [形參]--形參可以用來在where子句中限定游標記錄
2 [return type]--可選的指定游標返回的值類型
3 is query--通過is指定查詢(在這裏使用形參)
4 [for update[of column_list]]--允許在游標中修改表中的數據,並在游標打開期間鎖定選中的記錄
下面是一個通過游標遍歷輸出 dept 部門信息的例子:
1 declare
2 deptrow dept%rowtype;--定義一個存儲記錄的變量
3 cursor dept_cur is--通過cursor定義游標,is指定需要遍歷的結果集(一個查詢語句)
4 select * from dept; 5 begin
6 open dept_cur;--打開游標
7 loop--通過循環遍歷游標中的記錄
8 fetch dept_cur into deptrow;--通過fetch提取游標中記錄(每次一條)賦值給變量
9 dbms_output.put_line(deptrow.deptno||':'||deptrow.dname); 10 exit when dept_cur%notfound;--通過%notfound判斷游標中是否還有記錄
11 end loop; 12 close dept_cur;--關閉游標
13 end;
游標除了 %notfound 還有以下常用的的屬性:
1 cursor%isopen;--檢測游標是否已打開,打開返回ture,否則返回false
2 cursor%found;--檢測是否提取到值,提取到返回true,否者返回false
3 cursor%notfound;--與%found相反
4 cursor%rowcount;--統計到目前為止已提取的記錄數
PL/SQL 中的三種循環都可以用來循環遍歷游標中的記錄,while 和 loop 相似,這裏不再舉例,for 循環專門對遍歷游標做了強化,工作中使用最多,也最方便:
1 delcare 2 cursor dept_cur is
3 select * from dept; 4 begin
5 for dept_row in dept_cur loop 6 dbms_output.put_line(deptrow.deptno||':'||deptrow.dname); 7 end loop; 8 end;
dept_row 不需要顯式的聲明為記錄類型,PL/SQL 引擎自動隱式的聲明為 %rowtype。for 循環開始,自動打開游標,並自動提取記錄,然後賦值給dept_row,不用顯式的使用 fetch 提取記錄,循環完畢自動關閉游標並退出循環。
5,包
Oracle 中包(package)是一個工程化和面向對象的概念,它就像一個容器或命名空間,把邏輯相關的變量、類型、子程序或異常等組合起來一起存放,形成一個有序的組織單元或模塊,當我們編寫大型的複雜的應用程序時,我們就可以通過包來方便的歸類和管理各個功能模塊。
完整的包由包規範和包體組成,但 Oracle 分開編譯的存儲包規範和包體,這又使得我們可以脫離包體使用包規範(反向不行)。包規範中主要是一些定義信息(也可以看成是 PL/SQL 提供的 API),比如記錄類型、變量、游標、異常和子程序的聲明。包體則負責實現包規範中定義的子程序。
包規範簡單應用:
1 create or replace package pkg1--創建包規範 2 as
3 i int := 1;--標量變量
4 dept_record dept%rowtype;--rowtype類型
5 type dept_tab is table of varchar(20) index by pls_integer;--集合類型 6 end pkg1; 7
8 declare
9 mydept pkg1.dept_tab;--創建一個包中集合類型的變量(通過"包.內容"的方式訪問包中的內容) 10 begin
11 select * into pkg1.dept_record from dept where deptno=10;--給包中定義的rowtype類型變量賦值 12 dbms_output.put_line(pkg1.dept_record.dname);--訪問包中的rowtype類型變量 13 dbms_output.put_line('-------------------------------------------');--分割線 14 for deptrow in (select * from dept) loop--使用游標給包中的集合賦值 15 mydept(pkg1.i) := deptrow.dname; 16 pkg1.i := pkg1.i+1;--修改包中的標量變量 17 end loop; 18 for j in 1..mydept.count loop--使用循環訪問集合 19 dbms_output.put_line(mydept(j)); 20 end loop; 21 pkg1.i := 1;--初始化包中的標量變量(防止下一次游標讀取不到數據) 22 end;
在這個例子中,我們只創建了包規範,沒有包體,並且在包中定義了標量變量,rowtype類型(記錄類型同理),集合這些基本的數據類型,然後在 PL/SQL 程序塊中使用了他們。
包規範中只有聲明,沒有具體的實現,事實上,包規範中的聲明的內容是公共的,對於一個方案來說,相當於一個全局的對象,在包內任何地方都能訪問他們。包規範和包體分別進行獨立的編譯和存儲,所以沒有包體,上訴例子任然能正常運行。
另一個例子:
1 create or replace package pkg2--創建包規範 2 as
3 cursor dept_cur return dept%rowtype;--定義游標類型 4 procedure dept_ins(p_deptno int,p_dname varchar);--定義存儲過程 5 function f2 return varchar;--定義函數 6 end pkg2; 7
8 create or replace package body pkg2--創建包體 9 as
10 cursor dept_cur return dept%rowtype--創建游標 11 is
12 select * from dept; 13 procedure dept_ins(p_deptno in int,p_dname in varchar)--創建存儲過程 14 as
15 begin
16 insert into dept(deptno,dname) values(p_deptno,p_dname); 17 dbms_output.put_line('新增了部門:'|| p_deptno||','||p_dname); 18 end dept_ins; 19 function f2 return varchar--創建函數
20 is
21 begin
22 return '這是個函數'; 23 end f2; 24 end pkg2; 25
26
27 begin
28 for deptrow in pkg2.dept_cur loop--讀取游標 29 dbms_output.put_line(deptrow.dname); 30 end loop; 31 pkg2.dept_ins(99,'TI');--執行存儲過程 32 dbms_output.put_line(pkg2.f2());--執行函數 33 end;
上面的例子在包體中定義了游標,存儲過程和函數,並且在包規範中也聲明了他們,這時候,存儲過程和函數、游標都是公開的了,如果在包體中創建的內容並未在包規範中定義,那麼我們說,這些內容是包私有的,不能在其他地方調用,而只能在包體內部使用。
合理的使用包,有助於我們進行模塊化的程序開發;把邏輯相關的東西放在一個包中進行開發和管理,可以使我們的程序更加規範化;把一些重要的東西定義成包的私有內容,可以大大加強數據的安全性;另外,由於在使用包時, PL/SQL 會把整個包都加載到內存中,所以還可以提高程序運行效率。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※別再煩惱如何寫文案,掌握八大原則!