Raft共識算法在分佈式系統中是常用的共識算法之一,論文原文In Search of an Understandable Consensus Algorithm ,作者在論文中指出Poxas共識算法的兩大問題,其一是難懂,其二是應用到實際系統存在困難。針對Paxos存在的問題,作者的目的是提出一個易懂的共識算法,論文中有單獨一小節論述Raft是一個實用的、安全可用、有效易懂的共識算法。本文描述了Raft共識算法的細節,很多內容描述及引用圖片均摘自論文原文。
Raft概述
我們主要分以下三部分對Raft進行討論:
- Leader election——a new leader must be chosen when
an existing leader fails. (領導人選舉)
- Log replication——the leader must accept log entries from clients and replicate them across the cluster,
forcing the other logs to agree with its own.(日誌複製)
- Safety——the key safety property for Raft. (安全性)
正常工作過程中,Raft分為兩部分,首先是leader選舉過程,然後在選舉出來的leader基礎上進行正常操作,比如日誌複製操作等。
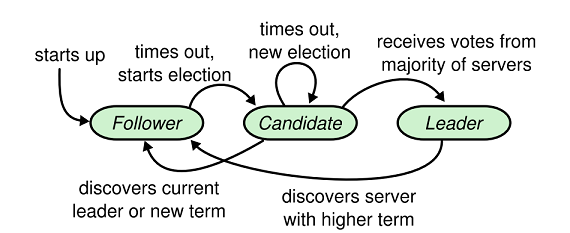
一個Raft集群通常包含\(2N+1\)個服務器,允許系統有\(N\)個故障服務器。每個服務器處於3個狀態之一:leader、follower或candidate。正常操作狀態下,僅有一個leader,其他的服務器均為follower。follower是被動的,不會對自身發出的請求而是對來自leader和candidate的請求做出響應。leader處理所有的client請求(若client聯繫follower,則該follower將轉發給leader)。candidate狀態用來選舉leader。狀態轉換如下圖所示:
為了進行領導人選舉和日誌複製等,需要服務器節點存儲如下狀態信息:
| 狀態 |
所有服務器上持久存在的 |
| currentTerm |
服務器最後一次知道的任期號(初始化為 0,持續遞增) |
| votedFor |
在當前獲得選票的候選人的 Id |
| log[] |
日誌條目集;每一個條目包含一個用戶狀態機執行的指令,和收到時的任期號 |
| 狀態 |
所有服務器上經常變的 |
| commitIndex |
已知的最大的已經被提交的日誌條目的索引值 |
| lastApplied |
最後被應用到狀態機的日誌條目索引值(初始化為 0,持續遞增) |
| 狀態 |
在領導人里經常改變的 (選舉后重新初始化) |
| nextIndex[] |
對於每一個服務器,需要發送給他的下一個日誌條目的索引值(初始化為領導人最後索引值加一) |
| matchIndex[] |
對於每一個服務器,已經複製給他的日誌的最高索引值 |
Raft在任何時刻都滿足如下特性:
- Election Safety:在一個任期中只能有一個leader;
- Leader Append-Only:leader不會覆蓋或刪除日誌中的entry,只有添加entry(follower存在依據leader回滾日誌的情況);
- Log Matching:如果兩個日誌包含了一條具有相同index和term的entry,那麼這兩個日誌在這個index之前的所有entry都相同;
- Leader Completeness: 如果在某一任期一條entry被提交committed了,那麼在更高任期的leader中這條entry一定存在;(領導人選舉時會保證這一性質,後面會講到這個問題)
- State Machine Safety:如果一個節點將一條entry應用到狀態機中,那麼任何節點也不會再次將該index的entry應用到狀態機里;
下面我們詳細討論這幾部分。
Leader選舉(Leader election)
一個節點初始狀態為follower,當follower在選舉超時時間內未收到leader的心跳消息,則轉換為candidate狀態。為了避免選舉衝突,這個超時時間是一個隨機數(一般為150~300ms)。超時成為candidate后,向其他節點發出RequestVoteRPC請求,假設有\(2N+1\)個節點,收到\(N+1\)個節點以上的同意回應,即被選舉為leader節點,開始下一階段的工作。如果在選舉期間接收到eader發來的心跳信息,則candidate轉為follower狀態。
在選舉期間,可能會出現多個candidate的情況,可能在一輪選舉過程中都沒有收到多數的同意票,此時再次隨機超時,進入第二輪選舉過程,直至選出leader或着重新收到leader心跳信息,轉為follower狀態。
正常狀態下,leader會不斷的廣播心跳信息,follower收到leader的心跳信息後會重置超時。當leader崩潰或者出現異常離線,此時網絡中follower節點接收不到心跳信息,超時再次進入選舉流程,選舉出一個leader。
這裏還有補充一些細節,每個leader可以理解為都是有自己的任期(term)的,每一期起始於選舉階段,直到因節點失效等原因任期結束。每一期選舉期間,每個follower節點只能投票一次。圖中t3可能是因為沒有獲得超半數票等造成選舉失敗,須進行下一輪選舉,此時follower可以再次對最先到達的candidate發出的RequestVote請求投票(先到先得)。
對所有的請求(RequestVote、AppendEntry等請求),如果發現其Term小於當前節點,則拒絕請求,如果是candidate選舉期間,收到不小於當前節點任期的leader節點發來的AppendEntry請求,則認可該leader,candidate轉換為follower。
日誌複製(Log replication)
leader選舉成功后,將進入有效工作階段,即日誌複製階段,其中日誌複製過程會分記錄日誌和提交數據兩個階段。
整個過程如下:
- 首先client向leader發出command指令;(每一次command指令都可以認為是一個entry,或者說是日誌項)
- leader收到client的command指令后,將這個command entry追加到本地日誌中,此時這個command是uncommitted狀態,因此並沒有更新節點的當前狀態;
- 之後,leader向所有follower發送這條entry,也就是通過日誌複製AppendEntries消息 (可以是一條也可以是多條日誌項) 將日誌項複製到集群其他節點上,follower接收到后 (這裡有判斷條件的,並不是所有leader發送來的日誌項都無條件接收,而且還可能存在本地與leader日誌不一致的情況,後面會詳細說明,這裏先看正常情況) 追加到本地日誌中,並回應leader成功或者失敗;
- leader收到大多數follower的確認回應后,此entry在leader節點由uncommitted變為committed狀態,此時按這條command更新leader狀態,或者說將該日誌項應用到狀態機,然後向client返回執行結果;
- 在下一心跳中(這裏也可以是或者說多數情況下是新的日誌複製AppendEntries消息,會帶有相關信息,後面后詳細的字段說明會講到),leader會通知所有follower更新確認的entry,follower收到后,更新狀態,這樣,所有節點都完成client指定command的狀態更新。
可以看到client每次提交command指令,服務節點都先將該指令entry追加記錄到日誌中,等leader確認大多數節點已追加記錄此條日誌后,在進行提交確認,更新節點狀態。如果還對這個過程有些模糊的話,可以參考Raft動畫演示,較為直觀的演示了領導人選舉及日誌複製的過程。
安全(Safety)
前面描述了Raft算法是如何選舉和複製日誌的。然而,到目前為止描述的機制並不能充分的保證每一個狀態機會按照相同的順序執行相同的指令。我們需要再繼續深入思考以下幾個問題:
- 第一個問題,leader選舉時follower收到candidate發起的投票請求,如果同意就進行回應,但具體的規則是什麼呢?是所有的follower都有可能被選舉為領導人嗎?
- 第二個問題,leader可能在任何時刻掛掉,新任期的leader怎麼提交之前任期的日誌條目呢?
選舉限制
針對第一個問題,之前並沒有細講,如果當前leader節點掛了,需要重新選舉一個新leader,此時follower節點的狀態可能是不同的,有的follower可能狀態與剛剛掛掉的leader相同,狀態較新,有的follower可能記錄的當前index比原leader節點的少很多,狀態更新相對滯后,此時,從系統最優的角度看,選狀態最新的candidate為佳,從正確性的角度看,要確保Leader Completeness,即如果在某一任期一條entry被提交成功了,那麼在更高任期的leader中這條entry一定存在,反過來講就是如果一個candidate的狀態舊於目前被committed的狀態,它一定不能被選為leader。具體到投票規則:
1) 節點只投給擁有不比自己日誌狀態舊的節點;
2)每個節點在一個term內只能投一次,在滿足1的條件下,先到先得;
我們看一下請求投票 RPC(由候選人負責調用用來徵集選票)的定義:
| 參數 |
解釋 |
| term |
候選人的任期號 |
| candidateId |
請求選票的候選人的 Id |
| lastLogIndex |
候選人的最後日誌條目的索引值 |
| lastLogTerm |
候選人最後日誌條目的任期號 |
| 返回值 |
解釋 |
| term |
當前任期號,以便於候選人去更新自己的任期號 |
| voteGranted |
候選人贏得了此張選票時為真 |
接收者實現:
- 如果
term < currentTerm返回 false
- 如果 votedFor 為空或者為 candidateId,並且候選人的日誌至少和自己一樣新,那麼就投票給他
可以看到RequestVote投票請求中包含了lastLogIndex和lastLogTerm用於比較日誌狀態。這樣,雖然不能保證最新狀態的candidate成為leader,但能夠保證被選為leader的節點一定擁有最新被committed的狀態,但不能保證擁有最新uncommitted狀態entries。
提交之前任期的日誌條目
領導人知道一條當前任期內的日誌記錄是可以被提交的,只要它被存儲到了大多數的服務器上。但是之前任期的未提交的日誌條目,即使已經被存儲到大多數節點上,也依然有可能會被後續任期的領導人覆蓋掉。下圖說明了這種情況:
如圖的時間序列展示了為什麼領導人無法決定對老任期號的日誌條目進行提交。在 (a) 中,S1 是領導者,部分的複製了索引位置 2 的日誌條目。在 (b) 中,S1崩潰了,然後S5在任期3里通過S3、S4和自己的選票贏得選舉,然後從客戶端接收了一條不一樣的日誌條目放在了索引 2 處。然後到 (c),S5又崩潰了;S1重新啟動,選舉成功,開始複製日誌。在這時,來自任期2的那條日誌已經被複制到了集群中的大多數機器上,但是還沒有被提交。如果S1在(d)中又崩潰了,S5可以重新被選舉成功(通過來自S2,S3和S4的選票),然後覆蓋了他們在索引 2 處的日誌。反之,如果在崩潰之前,S1 把自己主導的新任期里產生的日誌條目複製到了大多數機器上,就如 (e) 中那樣,那麼在後面任期裏面這些新的日誌條目就會被提交(因為S5 就不可能選舉成功)。 這樣在同一時刻就同時保證了,之前的所有老的日誌條目就會被提交。
為了消除上圖裡描述的情況,Raft永遠不會通過計算副本數目的方式去提交一個之前任期內的日誌條目。只有領導人當前任期里的日誌條目通過計算副本數目可以被提交;一旦當前任期的日誌條目以這種方式被提交,那麼由於日誌匹配特性,之前的日誌條目也都會被間接的提交。
當領導人複製之前任期里的日誌時,Raft 會為所有日誌保留原始的任期號。
對Raft中幾種情況的思考
follower節點與leader日誌內容不一致時怎麼處理?
我們先舉例說明:正常情況下,follower節點應該向B節點一樣與leader節點日誌內容一致,但也會出現A、C等情況,出現了不一致,以A、B節點為例,當leader節點向follower節點發送AppendEntries<prevLogIndex=7,prevLogTerm=3,entries=[x<-4]>,leaderCommit=7時,我們分析一下發生了什麼,B節點日誌與prevLogIndex=7,prevLogTerm=3相匹配,將index=7(x<-5)這條entry提交committed,並在日誌中新加入entryx<-4,處於uncommitted狀態;A節點接收到時,當前日誌index<prevLogIndex與prevLogIndex=7,prevLogTerm=3不相匹配,拒接該請求,不會將x<-4添加到日誌中,當leader知道A節點因日誌不一致拒接了該請求后,不斷遞減preLogIndex重新發送請求,直到A節點index,term與prevLogIndex,prevLogTerm相匹配,將leader的entries複製到A節點中,達成日誌狀態一致。
我們看一下附加日誌AppendEntries RPC(由領導人負責調用複製日誌指令;也會用作heartbeat)的定義:
| 參數 |
解釋 |
| term |
領導人的任期號 |
| leaderId |
領導人的 Id,以便於跟隨者重定向請求 |
| prevLogIndex |
新的日誌條目緊隨之前的索引值 |
| prevLogTerm |
prevLogIndex 條目的任期號 |
| entries[] |
準備存儲的日誌條目(表示心跳時為空;一次性發送多個是為了提高效率) |
| leaderCommit |
領導人已經提交的日誌的索引值 |
| 返回值 |
解釋 |
| term |
當前的任期號,用於領導人去更新自己 |
| success |
跟隨者包含了匹配上 prevLogIndex 和 prevLogTerm 的日誌時為真 |
接收者實現:
- 如果
term < currentTerm 就返回 false;
- 如果日誌在 prevLogIndex 位置處的日誌條目的任期號和 prevLogTerm 不匹配,則返回 false;
- 如果已經存在的日誌條目和新的產生衝突(索引值相同但是任期號不同),刪除這一條和之後所有的;(raft中follower處理不一致的一個原則就是一切聽從leader)
- 附加日誌中尚未存在的任何新條目;
- 如果
leaderCommit > commitIndex,令 commitIndex 等於 leaderCommit 和 新日誌條目索引值中較小的一個;
簡單總結一下,出現不一致時核心的處理原則是一切遵從leader。當leader向follower發送AppendEntry請求,follower對AppendEntry進行一致性檢查,如果通過,則更新狀態信息,如果發現不一致,則拒絕請求,leader發現follower拒絕請求,出現了不一致,此時將遞減nextIndex,並重新給該follower節點發送日誌複製請求,直到找到日誌一致的地方為止。然後把follower節點的日誌覆蓋為leader節點的日誌內容。
leader掛掉了,怎麼處理?
前面可能斷斷續續的提到這種情況的處理方法,首要的就是選出新leader,選出新leader后,可能上一任期還有一些entries並沒有提交,處於uncommitted狀態,該怎麼辦呢?處理方法是新leader只處理提交新任期的entries,上一任期未提交的entries,如果在新leader選舉前已經被大多數節點記錄在日誌中,則新leader在提交最新entry時,之前處於未提交狀態的entries也被committed了,因為如果兩個日誌包含了一條具有相同index和term的entry,那麼這兩個日誌在這個index之前的所有entry都相同;如果在新leader選舉前沒有被大多數節點記錄在日誌中,則原有未提交的entries有可能被新leader的entries覆蓋掉。
出現網絡分區時怎麼處理?
分佈式系統中網絡分區的情況基本無法避免,出現網絡分區時,原有leader在分區的一側,此時如果客戶端發來指令,舊leader依舊在分區一測進行日誌複製的過程,但因收不到大多數節點的確認,客戶端所提交的指令entry只能記錄在日誌中,無法進行提交確認,處於uncommitted狀態。而在分區的另一側,此時收不到心跳信息,會進入選舉流程重新選舉一個leader,新leader負責分區零一側的請求,進行日誌複製等操作。因為新leader可以收到大多數follower確認,客戶端的指令entry可以被提交,並更新節點狀態,當網絡分區恢復時,此時兩個leader會收到彼此廣播的心跳信息,此時,舊leader發現更大term的leader,舊leader轉為follower,此時舊leader分區一側的所有操作都要回滾,接受新leader的更新。
成員變更
在分佈式系統中,節點數量或者說服務器數量不是一成不變的,我們有可能會隨時增減節點數量,當增加節點時,有可能會出現兩個leader選舉成功的情況,主要是新舊配置不一致造成的,怎麼處理呢?最簡單粗暴的就是把目前所有節點都停掉,更新配置,再重啟所有節點,但會造成一段時間服務不可用,很多情況下這是不能被允許的。raft的解決辦法原論文中是聯合共識(Joint Consensus)的辦法,後來又提出了單節點變更(single-server changes)的方法。我們下面詳細描述一下這個問題。
Raft要求,在任一任期內,只能有一個leader,而成員變更的麻煩就在於,成員變更時可能會出現兩個leader,以一個例子說明:原系統有3個節點,成員為[1,2,3],現新增成員4、5。假設在成員變更時,1、2與3發生分區,此時,[1,2]為一組,1通過1、2兩節點選舉為leader,而5通過3、4、5選舉為leader,就形成了2個leader並存的情況。
因為每個節點新舊配置更新的時間不同,造成了在某一時刻,可能會存在新舊配置的兩個大多數情況的存在,上圖中,舊配置的大多數是兩個節點,而新配置的大多數是三個節點,在圖中紅線頭的時刻存在兩個大多數的情況,如果此時出現網絡分區進行選舉時就會出現兩個leader的情況。
怎麼解決呢?用什麼辦法才能不讓上面兩個大多少情況的出現呢?可通過單節點變更解決,即通過一次變更一個節點實現成員變更。主要思想是利用“一次變更一個節點,不會同時存在舊配置和新配置的兩個大多數”的特性,實現成員變更。比如上面的情況,就可先將3節點集群[A,B,C]變更為4節點集群[A,B,C,D],再將4節點集群變更為5節點集群[A,B,C,D]。
為什麼單節點變更不會造成兩個大多數情況的出現呢?我們可以進行如下推理:假設原節點數為2n+1,則舊配置的大多數major_old=n+1,新加入1個節點,新配置節點數為2n+2,則新配置的大多數為major_new=n+2,同時存在兩個大多數所需節點數目為major=major_old+major_new=n+1+n+2=2n+3>2n+2,也就是兩個大多數所需節點數超出了節點總數,故不存在這種情況,如何是刪除成員,其推理過程類似,結論相同。
具體的,我們依舊以這個3節點集群變更為5節點集群為例進行說明。假設現3節點集群[A,B,C],節點A為leader,配置為[A,B,C],我們先向集群加入節點D,新的配置為[A,B,C,D],成員變更通過以下兩步實現:
- 第一步,leader節點A向新節點D同步數據;
- 第二步,leader將新配置[A,B,C,D]作為一個日誌項複製到新配置中的所有節點(A,B,C,D)上,然後將新配置的日誌項應用到本地狀態機,完成單節點變更。
在變更后,現有集群的配置項就是[A,B,C,D],添加E節點也是同樣的步驟。上面的描述如果理解的比較模糊的話,其實raft是採用將修改集群配置的命令放在日誌條目中來處理的,其修改配置項,就是一條日誌項,其流程與普通的日誌項相同,只不過最後狀態機執行的結果是配置變更。
日誌壓縮
日誌壓縮主要是為了解決無限增長的日誌與有限的存貯空間的矛盾,可以想一個問題:對於已經committed的日誌項,是否有必要一直保存下去?如果沒有必要的話,是否可以對部分已committed的日誌項刪減或壓縮呢?raft的主要的解決辦法是採用快照進行日誌壓縮。
如上圖所示,對於日誌索引5之前的日誌項可以刪除,只保留一個快照(保存有當前狀態以及一些任期索引號等元信息)即可。
具體工程實現時,一般每個節點獨立打快照,當日誌超過一定量會觸發快照操作,具體實現以及更多細節待以後深究。
Client Protocol
raft共識算法真正工作時還需有一個客戶端協議(client protocol),綜合解決一些列的問題。比如會遇到下面這些問題:client怎麼和集群交互呢?client如果知道leader節點的話,可以直接將command發給leader節點,如果不知道的話,可以隨意發給集群中已知的節點,節點會將client的請求轉給leader。其實上面還有個問題,client發送請求(或者command)給leader,但是leader遲遲不給回應怎麼辦?重試是一個辦法。連接的leader崩潰了client怎麼辦?如果client超時重發command,怎麼保證command不被狀態機執行兩次?client生成command的時候要給加上唯一ID,當server的日誌中已存在相同command時會忽略。
附錄
這裏附加一張論文中的截圖,裏面詳細講明了不同節點需要維護什麼信息,每個消息是怎麼定義的,以及消息該如何處理等,不包含日誌壓縮以及成員變更部分:
這裏補充一點,raft共識算法與pbft共識算法解決的是不同的問題,即raft節點不能存在惡意節點,節點消息可以延遲、丟失,但不能造假或作惡,即不能存在拜占庭節點。
本文對raft共識算法做了一個整體的梳理學習,可能會存在某些細節描述不清晰的地方,在真正工程代碼實現時,還會存在更多的細節問題,同時,這裏缺少證明為什麼raft算法是正確的證明,有待今後更深一步理解共識算法后再行補充。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧