廣汽菲克-Jeep自由本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※台中搬家遵守搬運三大原則,讓您的家具不再被破壞!
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
有了這種材質,某些司機要偷着樂了。相對於前臉、車身的個性,尾部的設計要平常許多了。內飾部分整體設計偏向矩形的設計,雙色搭配也是恰到好處,看起來和外觀一樣也是活力十足,C3的設計師說內飾的設計靈感主要來源於家庭室內設計,力求為C3設計出更為現代、舒適的座艙。
最近看到不少讀者在後台留言說想要了解一下雪鐵龍C3的情況,所以今天我們就來看一下這款個性十足的法系車-雪鐵龍C3。
說起雪鐵龍C3,大家的第一反應應該是C3-XR吧,但是這個C3可不是大家熟悉的那個小型SUV C3-XR,而是雪鐵龍的的一款小型車。
C3的歷史要比C3-XR更長,因為第一代的C3早在2002年的時候就推出了。一經推出就獲得了熱銷,到目前為止累計銷量近400萬台,當然,C3的主要戰場還是在歐洲。
全新一代的雪鐵龍C3早在今年9月份就發布了,一發布便引起了熱議,因為這款非常個性的小車給大家留下了深刻的印象。
C3的長度只有3990mm,其他尺寸暫時未知,長度還不到四米,所以C3看起來比較短小,但是較短的尺寸並不會影響法國人天馬行空的設計。C3的造型極其可愛,前臉渾圓一體,造型獨特。
比如前臉獨特的大燈組設計,LED日行燈和引擎蓋部分的鍍鉻裝飾條相互融合,大燈和霧燈造型為凹進去矩形設計,看起來比較別緻。
前臉的造型已經夠獨特了,側面的設計也充滿看點,轉向指示燈裝在了有着黑色塗裝的后視鏡上。整個車身側面的個性塗裝讓C3看起來更加與眾不同。
不過輪圈的造型,也會讓我過目不忘的。
既然喜歡玩個性,那就一玩到底,C3將會提供9種車身顏色和3種車頂顏色,總計36種顏色組合,滿足消費者對個性的需求。
新車還採用了Airbump技術,特殊的TpU柔軟材質可以抵抗輕微的刮蹭。有了這種材質,某些司機要偷着樂了。
相對於前臉、車身的個性,尾部的設計要平常許多了。
內飾部分整體設計偏向矩形的設計,雙色搭配也是恰到好處,看起來和外觀一樣也是活力十足,C3的設計師說內飾的設計靈感主要來源於家庭室內設計,力求為C3設計出更為現代、舒適的座艙。
空調出風口搞成這個樣子,估計只有法國人能幹出來。新車也會有全景天窗,只是不能開啟。
至於空間,肯定是比較局促的,正常體格的成年人坐在後排不管是頭部空間還是腿部空間都不會太寬敞。
C3的發動機為1.2T三缸汽油發動機和1.6T柴油發動機,其中1.2T發動機將會有三種不同的動力調教,變速箱為手動擋和6擋自動。
遺憾的是這個車子目前會在歐洲上市,中國未來只是有可能引進,畢竟雪鐵龍在國內沒有一款小型車。如果真的引進國內國產了,小編希望原封不動的引進,或者盡可能的保持原來的面貌。如果售價能七萬起,憑藉如此個性的C3,絕對會吸引年輕消費者的青睞。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※推薦台中搬家公司優質服務,可到府估價
它還是會打一個激靈再往前沖。不過調到運動模式之後,你才會更深的感受到這輛車的動力。儀錶盤隨即變為紅色主題,好像是有點鋼炮的意思。只不過它增加的是心理馬力,但是對於速度的提升還是很明顯的。V40的懸挂調校是那種偏硬的感覺,對於車身的支撐是相當足,但是舒適性和1系來比會打點折扣。
自從吉利把沃爾沃收了之後,大家對這個北歐品牌的熟悉程度就更高了。只不過知名度歸知名度,要真是讓你買車選一輛沃爾沃,可能大家都未必願意。所以今天就給大家試一下它的入門級車型-V40。
就在試駕車剛剛到公司,小喬就撲了上去,並引發了以下對話…
既然是北歐的廠商,那必然要帶有北歐特色才行。沒錯,“雷神之錘”大家都聽說過了吧,說的就是沃爾沃的頭燈,V40打開日間行車燈后,視覺效果確實很不錯,但這種畫風更適合年輕買家。相對於能見度較高的A3、1系或A級來說,V40就是小眾但不失氣質的存在。
V40提供了T3/T4/T5三個代號的車型選擇,分別搭載1.5T/2.0T四缸發動機。畢竟是輛買菜車,V40的動力輸出都是相當穩當般的存在。正常模式下想急加速?它還是會打一個激靈再往前沖。
不過調到運動模式之後,你才會更深的感受到這輛車的動力。儀錶盤隨即變為紅色主題,好像是有點鋼炮的意思。只不過它增加的是心理馬力,但是對於速度的提升還是很明顯的。
V40的懸挂調校是那種偏硬的感覺,對於車身的支撐是相當足,但是舒適性和1系來比會打點折扣。值得一提的是V40的隔音相當不錯,但問題是這個不錯只局限於風噪。正常行駛下路面的噪聲就直接從車底傳進來,這很尷尬,但也沒辦法。
V40的內飾還是保持了一貫的沃爾沃風格。最明顯的就是中控台萬年不變的数字鍵。而它又長又大的手剎把就成為了中控台的一道風景。
反觀V40的空間表現,還是能讓家人滿意的。最起碼它的後排空間沒有給人覺得任何憋屈的感覺。
V40作為一輛入門級車型,官方售價終端為18.89-30.99萬元,對於那些追求獨特的年輕車主來說,這是一個不小的誘惑。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※網頁設計最專業,超強功能平台可客製化
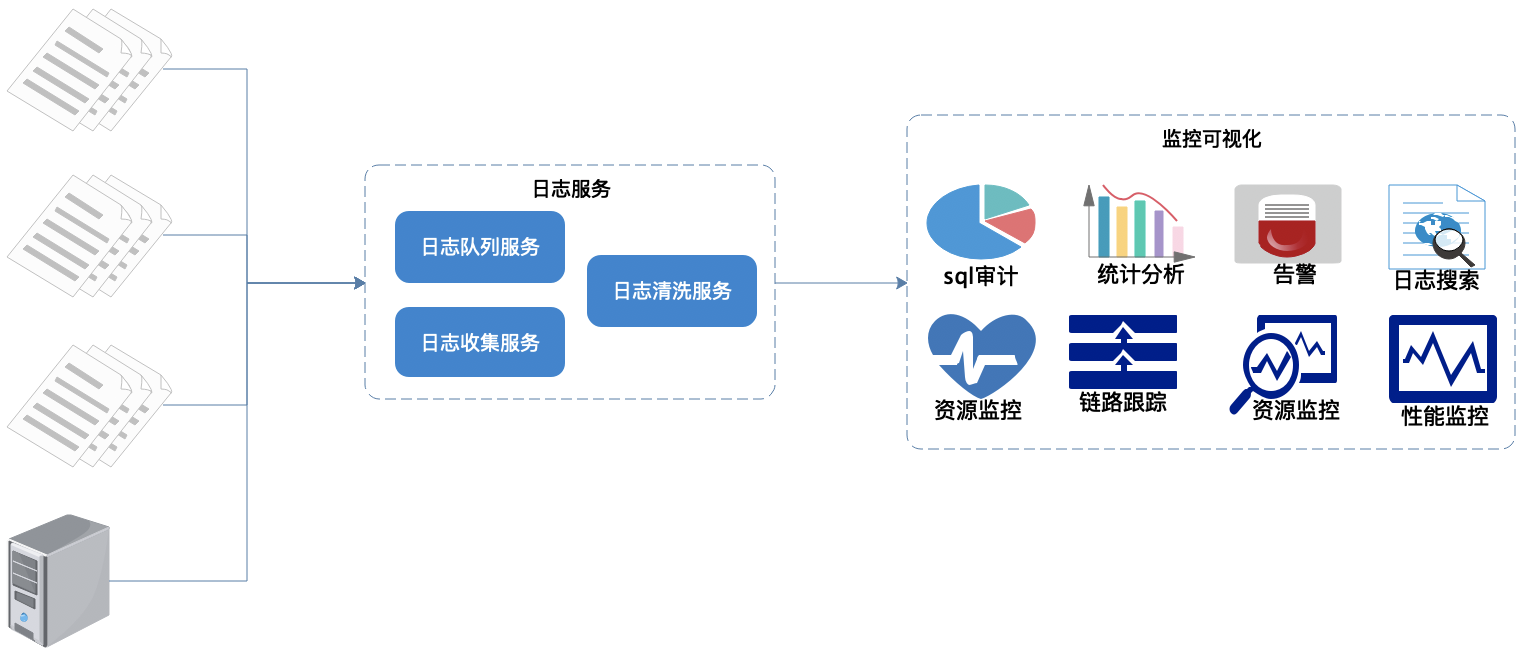
前面幾章蜻蜓點水的介紹了elasticsearch、apm相關的內容。本片主要介紹怎麼使用ELK Stack幫助我們打造一個支撐起日產TB級的日誌監控系統
在企業級的微服務環境中,跑着成百上千個服務都算是比較小的規模了。在生產環境上,日誌扮演着很重要的角色,排查異常需要日誌,性能優化需要日誌,業務排查需要業務等等。然而在生產上跑着成百上千個服務,每個服務都只會簡單的本地化存儲,當需要日誌協助排查問題時,很難找到日誌所在的節點。也很難挖掘業務日誌的數據價值。那麼將日誌統一輸出到一個地方集中管理,然後將日誌處理化,把結果輸出成運維、研發可用的數據是解決日誌管理、協助運維的可行方案,也是企業迫切解決日誌的需求。
通過上面的需求我們推出了日誌監控系統。
7. 可視化界面我們主要使用grafana,它支持的眾多數據源中,其中就有普羅米修斯和elasticsearch,與普羅米修斯可謂是無縫對接。而kibana我們主要用於apm的可視分析
【版權聲明】
本文版權歸作者(深圳伊人網網絡有限公司)和博客園共有,歡迎轉載,但未經作者同意必須在文章頁面給出原文鏈接,否則保留追究法律責任的權利。如您有任何商業合作或者授權方面的協商,請給我留言:siqing0822@163.com
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※別再煩惱如何寫文案,掌握八大原則!
因為Java對象主要存放在Java堆里,所以垃圾收集器(Garbage Collection)在對Java堆進行回收前,第一件事情就是要確定這些對象之中哪些還“存活”着,哪些已經“死去”(不被引用了)。
引用計數算法,很容易理解,在對象中添加一個引用計數器,每有一個地方引用它時,計數器值就加一;當引用失效是,計數器值就減一;任何時刻計數器為零的對象就是不可以能再被使用的對象。
引用計數算法的原理簡單,判定效率也很高。市面上也確實有一些技術使用的此類算法來判定對象是否存活,像ActionScript 3 的FlashPlayer、Python語言等。但是在主流的Java虛擬機裏面都沒有選用引用計算法來管理內存,主要是使用此算法時,必須要配合大量的額外處理才能保證正確的工作,例如要解決對象之間的相互循環引用的問題。
public class OneTest {
public Object oneTest = null;
private static final int _1MB = 1024 * 1024;
private byte[] bigSize = new byte[256 * _1MB];
/**
* 這個成員屬性的唯一意義就是占點內存,以便能在GC日誌中看清楚是否有回收過。
*/
@Test
public void testGC(){
OneTest test1 = new OneTest();
OneTest test2 = new OneTest();
test1.oneTest = test2;
test2.oneTest = test1;
test1 = null;
test2 = null;
// 假設在這行發生GC,test1和test2是否能被回收?
System.gc();
}
}
分析代碼,test1和test2對象都被設置成了null,在後面發生GC的時候,如果按照引用計數算法,這兩個對象雖然都被設置成了null,但是test1引用了test2,test2又引用了test1,所以這兩個對象的引用計數值都不為0,所以都不會被回收,但是真正的實際運行結果是,這兩個對象都被回收了,這也說明HotSpot虛擬機並不是用引用計數法來進行的內存管理。
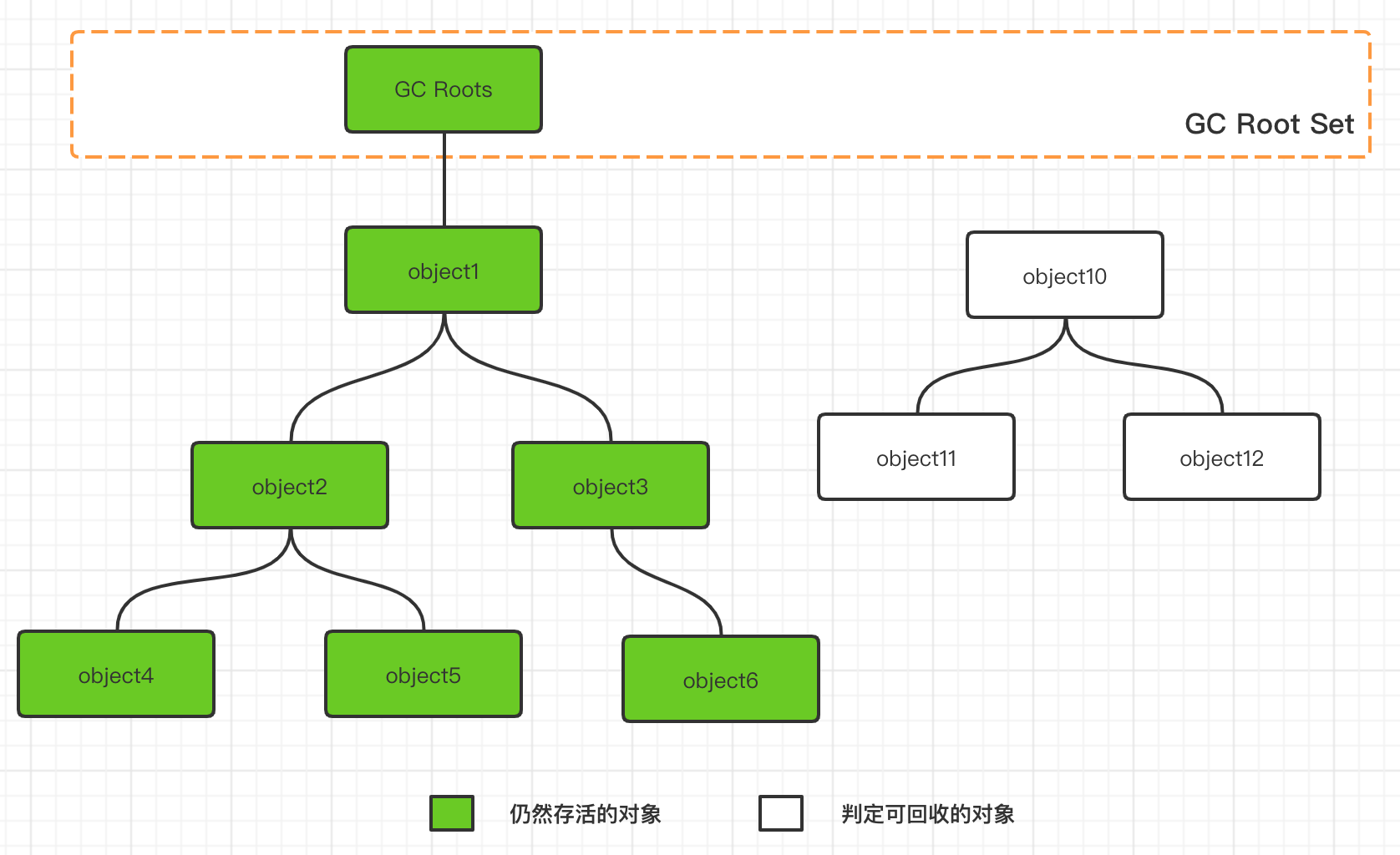
當前主流的商用程序語言(Java、C#等),都是通過可達性分析(Reachability Analysis)算法來判斷對象是否存活的。這個算法的基本思路就是通過一一系列稱為“GC Roots” 的根對象作為起始節點集,從這些節點開始根據引用關係向下搜索,搜索走過的的路徑稱為“引用鏈”(Reference Chain),如果某個對象到GC Roots 間沒有任何引用鏈相連,或者從GC Roots 到這個對象不可達時,則證明此對象是不可能再被使用的。
如下圖,object10、object11、object12這三個對象,雖然互相有關聯,但是它們到GC Roots是不可達的,因此它們會被判定為可回收的對象。
在Java程序中,固定可作為GC Roots 的對象包括以下幾種:
無論是通過引用計數算法判斷對象的引用數量,還是通過可達性分析算法判斷對象是否引用鏈可達,判斷對象是否存活都和“引用”離不開關係。在JDK1.2之前,Java里對引用的概念是:如果reference類型的數據中存儲的數值代表的是另外一塊兒內存的地址,就稱該reference數據是代表某塊內存、某個對象的引用。
在JDK1.2版之後,Java對引用的概念進行了擴充,將引用分為強引用(Strongly Reference)、軟引用(Soft Reference)、弱引用(Weak Reference)、虛引用(Phantom Reference)4種,這4種引用強度依次逐漸減弱。
Object obj = new Object()
這種引用關係。無論在任何情況下,只要強引用關係還存在,垃圾收集器就不會回收掉被引用的對象。
即使在可達性分析算法中,判斷為不可達的對象,也不是“非死不可”的,要真正宣告一個對象死亡,至少要經歷兩次標記過程:
需要注意的是:任何一個對象的finalize()方法都只會被系統自動調用一次,如果對象面臨第二次回收,它的finalize()方法不會被再次執行。
還有一點就是Java官方已經明確聲明不推薦手動調用finalize()方法了,因為它的運行代價高昂,不確定性大,無法保證各個對象的調用順序,並且finanlize()能做的所有工作,使用try-finally或其他方式都可以做的更好、更及時。
方法區垃圾收集的“性價比”通常比較低,並且方法區回收也有過於苛刻的判定條件。
方法區的垃圾收集主要回收兩部分內容:廢棄的常量和不再使用的類型,回收廢棄常量時,如果當前系統沒有一個常量的值是當前常量值,且虛擬機中也沒有其他地方引用這個常量。如果這個時候發生垃圾回收,常量就會被系統清理出常量池。
判定一個類型是否屬於“不再使用的類”的條件就比較苛刻了,要同時滿足如下三個條件:
同時滿足了上述的三個條件后,也只是被允許進行回收了,關於是否要對類型進行回收還要對虛擬機進行一系列的參數設置,這裏就不贅述了,感興趣的可以自己去查詢。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
原作:BRETT CANNON
譯者:豌豆花下貓@Python貓
英文:https://snarky.ca/the-many-ways-to-pass-code-to-python-from-the-terminal
為了我們推出的 VS Code 的 Python 插件 [1],我寫了一個簡單的腳本來生成變更日誌 [2](類似於Towncrier [3],但簡單些,支持 Markdown,符合我們的需求)。在發布過程中,有一個步驟是運行python news ,它會將 Python 指向我們代碼中的”news”目錄。
前幾天,一位合作者問這是如何工作的,似乎我們團隊中的每個人都知道如何使用-m ?(請參閱我的有關帶 -m 使用 pip 的文章 [4],了解原因)(譯註:關於此話題,我也寫過一篇更為詳細的文章 )
這使我意識到其他人可能不知道有五花八門的方法可以將 Python 指向要執行的代碼,因此有了這篇文章。
因為如何用管道傳東西給一個進程是屬於 shell 的內容,我不打算深入解釋。毋庸置疑,你可以將代碼傳遞到 Python 中。
# 管道傳內容給 python
echo "print('hi')" | python
如果將文件重定向到 Python,這顯然也可以。
# 重定向一個文件給 python
python < spam.py
歸功於 Python 的 UNIX 傳統,這些都不太令人感到意外。
-c 指定的字符串如果你只需要快速地檢查某些內容,則可以在命令行中將代碼作為字符串傳遞。
# 使用 python 的 -c 參數
python -c "print('hi')"
當需要檢查僅一行或兩行代碼時,我個人會使用它,而不是啟動 REPL(譯註:Read Eval Print Loop,即交互式解釋器,例如在 windows 控制台中輸入python, 就會進入交互式解釋器。-c 參數用法可以省去進入解釋器界面的過程) 。
最眾所周知的傳代碼給 python 的方法很可能是通過文件路徑。
# 指定 python 的文件路徑
python spam.py
要實現這一點的關鍵是將包含該文件的目錄放到sys.path 里。這樣你的所有導入都可以繼續使用。但這也是為什麼你不能/不應該傳入包含在一個包里的模塊路徑。因為sys.path 可能不包含該包的目錄,因此所有的導入將相對於與你預期的包不同的目錄。
執行 Python 包的正確方法是使用 -m 並指定要運行的包名。
python -m spam
它在底層使用了runpy [5]。要在你的項目中做到這點,只需要在包里指定一個__main__.py 文件,它將被當成__main__ 執行。而且子模塊可以像任何其它模塊一樣導入,因此你可以對其進行各種測試。
我知道有些人喜歡在一個包里寫一個main 子模塊,然後將其__main__.py 寫成:
from . import main
if __name__ == "__main__":
main.main()
就我個人而言,我不感冒於單獨的main 模塊,而是直接將所有相關的代碼放入__main__.py ,因為我感覺這些模塊名是多餘的。
(譯註:即作者不關心作為入口文件的”main”或者“__main__”模塊,因為執行時只需用它們的包名即可。我認為這也暗示了入口模塊不該再被其它模塊 import。我上篇文章 [6]比作者的觀點激進,認為連那句 if 語句都不該寫。)
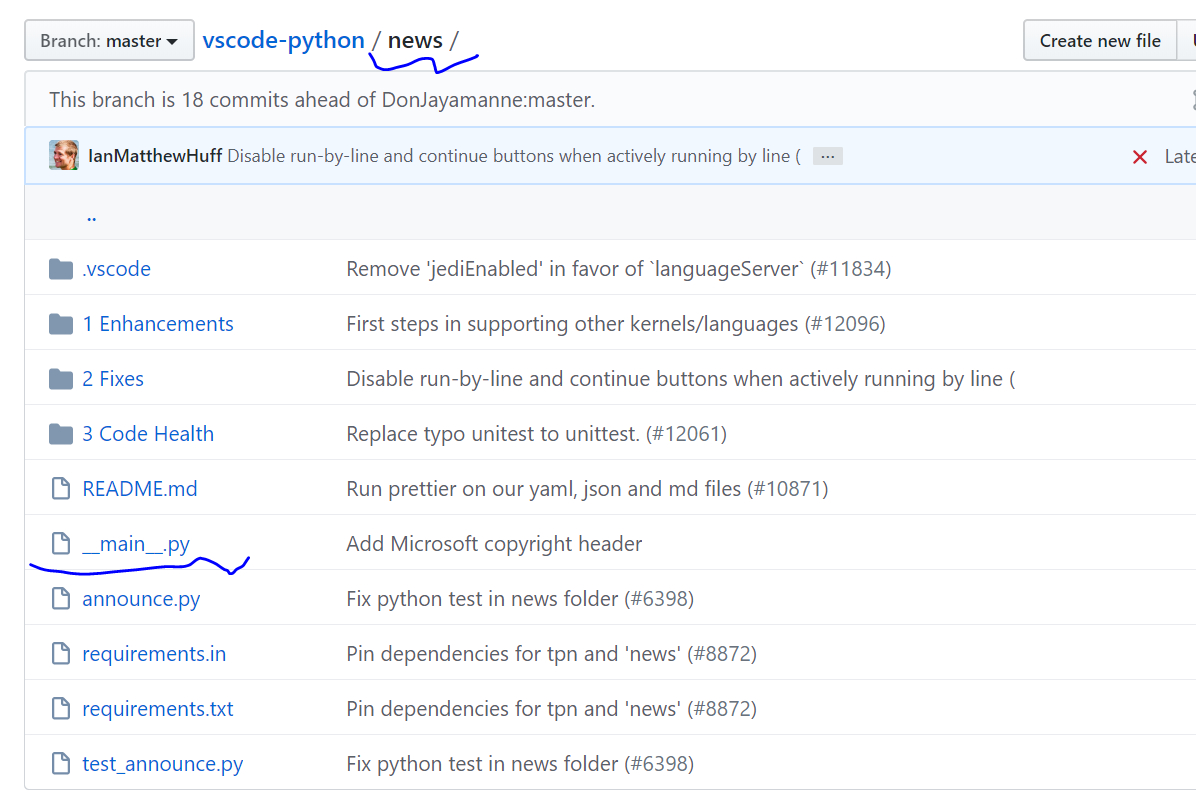
定義__main__.py也可以擴展到目錄。如果你看一下促成此博客文章的示例,python news 可執行,就是因為 news 目錄有一個 __main__.py 文件。該目錄就像一個文件路徑被 Python 執行了。
現在你可能會問:“為什麼不直接指定文件路徑呢?”好吧,坦白說,關於文件路徑,有件事得說清楚。在發布過程中,我可以簡單地寫上說明,讓運行python news/announce.py ,但是並沒有確切的理由說明這種機制何時存在。
再加上我以後可以更改文件名,而且沒人會注意到。再加上我知道代碼會帶有輔助文件,因此將其放在目錄中而不是單獨作為單個文件是有意義的。
當然,我也可以將它變為一個使用 -m 的包,但是沒必要,因為 announce 腳本很簡單,我知道它要保持成為一個單獨的自足的文件(少於 200 行,並且測試模塊也大約是相同的長度)。
況且,__main__.py 文件非常簡單。
import runpy
# Change 'announce' to whatever module you want to run.
runpy.run_module('announce', run_name='__main__', alter_sys=True)
現在顯然必須要處理依賴關係,但是如果你的腳本僅使用標準庫或將依賴模塊放在__main__.py 旁邊(譯註:即同級目錄),那麼就足夠了!
(譯註:我覺得作者在此有點“炫技”了,因為這種寫法的前提是得知道 runpy 的用法,但是就像前一條所寫的用 -m 參數運行一個包,在底層也是用了 runpy。不過炫技的好處也非常明顯,即__main__.py 里不用導入 announce 模塊,還是以它為主模塊執行,也就不會破壞原來的依賴導入關係)
如果你確實有多個文件和/或依賴模塊,並且希望將所有代碼作為一個單元發布,你可以用一個__main__.py ,放置在一個壓縮文件中,並把壓縮文件所在目錄放在 sys.path 里,Python 會替你運行__main__.py 文件。
# 將一個壓縮包傳給 Python
python app.pyz
人們現在習慣上用 .pyz 文件擴展名來命名此類壓縮文件,但這純粹是傳統,不會影響任何東西;你當然也可以用 .zip 文件擴展名。
為了簡化創建此類可執行的壓縮文件,標準庫提供了zipapp [7]模塊。它會為你生成__main__.py並添加一條組織行(shebang line),因此你甚至不需要指定 python,如果你不想在 UNIX 上指定它的話。如果你想移動一堆純 Python 代碼,這是一種不錯的方法。
不幸的是,僅當壓縮文件包含的所有代碼都是純 Python 時,才能這樣運行壓縮文件。執行壓縮文件對擴展模塊無效(這就是為什麼 setuptools 有一個 zip_safe [8]標誌的原因)。(譯註:擴展模塊 extension module,即 C/C++ 之類的非 Python 文件)
要加載擴展模塊,Python 必須調用 dlopen() [9]函數,它要傳入一個文件路徑,但當該文件路徑就包含在壓縮文件內時,這顯然不起作用。
我知道至少有一個人與 glibc 團隊交談過,關於支持將內存緩衝區傳入壓縮文件,以便 Python 可以將擴展模塊讀入內存,並將其傳給壓縮文件,但是如果內存為此服務,glibc 團隊並不同意。
但是,並非所有希望都喪失了!你可以使用諸如shiv [10]之類的項目,它會捆綁(bundle)你的代碼,然後提供一個__main__.py 來處理壓縮文件的提取、緩存,然後為你執行代碼。儘管不如純 Python 解決方案理想,但它確實可行,並且在這種情況下算得上是優雅的。
(譯註:翻譯水平有限,難免偏差。我加註了部分內容,希望有助於閱讀。請搜索關注“Python貓”,閱讀更多優質的原創或譯作。)
[0] https://snarky.ca/the-many-ways-to-pass-code-to-python-from-the-terminal/
[1] https://marketplace.visualstudio.com/items?itemName=ms-python.python
[2] https://github.com/microsoft/vscode-python/tree/master/news
[3] https://pypi.org/project/towncrier
[4] https://snarky.ca/why-you-should-use-python-m-pip
[5] https://docs.python.org/3/library/runpy.html#module-runpy
[6] https://mp.weixin.qq.com/s/1ehySR5NH2v1U8WIlXflEQ
[7] https://docs.python.org/3/library/zipapp.html#module-zipapp
[8] https://setuptools.readthedocs.io/en/latest/setuptools.html#setting-the-zip-safe-flag
[9] https://linux.die.net/man/3/dlopen
[10] https://pypi.org/project/shiv/
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
Linux 服務器我們天天打交道,特別是 Linux 工程師更是如此。為了保證服務器的安全與性能,我們經常需要監控服務器的一些狀態,以保證工作能順利開展。
本文介紹的幾個命令,不僅僅適用於服務器監控,也適用於我們日常情況下的開發。
watch 命令我們的使用頻率很高,它的基本作用是,按照指定頻率重複執行某一條指令。使用這個命令,我們可以重複調用一些命令來達到監控服務器的作用。
默認情況下,watch 命令的執行周期是 2 秒,但我們可以使用 -n 選項來指定運行頻率,比如我們想要每隔 5 秒執行 date 命令,可以這麼執行:
$ watch -n 5 date
一台服務器肯定有多人在用,特別是本部門的小夥伴。對於這些小夥伴有沒渾水摸魚,我們可以使用一些命令來監控他們。
我們可以每隔 10 秒執行 who 命令,來看看都有誰在使用服務器。
$ watch -n 10 who
Every 10.0s: who butterfly: Tue Jan 23 16:02:03 2019
shs :0 2019-01-23 09:45 (:0)
dory pts/0 2019-01-23 15:50 (192.168.0.5)
alvin pts/1 2019-01-23 16:01 (192.168.0.15)
shark pts/3 2019-01-23 11:11 (192.168.0.27)
如果發現系統運行很慢,我們可以調用 uptime 命令來查看系統平均負載情況。
$ watch uptime
Every 2.0s: uptime butterfly: Tue Jan 23 16:25:48 2019
16:25:48 up 22 days, 4:38, 3 users, load average: 1.15, 0.89, 1.02
一些關鍵的進程肯定不能掛,否則可能會影響到業務開展,所以我們可以重複統計服務器中的所有進程數量。
$ watch -n 5 'ps -ef | wc -l'
Every 5.0s: ps -ef | wc -l butterfly: Tue Jan 23 16:11:54 2019
245
想動態知道服務器內存使用情況,可以重複執行 free 命令。
$ watch -n 5 free -m
Every 5.0s: free -m butterfly: Tue Jan 23 16:34:09 2019
total used free shared buff/cache available
Mem: 5959 776 3276 12 1906 4878
Swap: 2047 0 2047
當然不僅僅是這些,我們還可以重複調用很多命令來對服務器一些關鍵參數進行監控,
使用 top 命令我們可以知道系統的很多關鍵參數,而且是動態更新的。默認情況下,top 監控的是系統的整體狀態,如果我們只想知道某個人的使用情況,可以使用 -u 選項來指定這個人。
$ top -u alvin
top - 16:14:33 up 2 days, 4:27, 3 users, load average: 0.00, 0.01, 0.02
Tasks: 199 total, 1 running, 198 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 5959.4 total, 3277.3 free, 776.4 used, 1905.8 buff/cache
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 4878.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
23026 alvin 20 0 46340 7820 6504 S 0.0 0.1 0:00.05 systemd
23033 alvin 20 0 149660 3140 72 S 0.0 0.1 0:00.00 (sd-pam)
23125 alvin 20 0 63396 5100 4092 S 0.0 0.1 0:00.00 sshd
23128 alvin 20 0 16836 5636 4284 S 0.0 0.1 0:00.03 zsh
在這個結果里,你不僅僅可以看到 alvin 這個用戶運行的所有的進程數,也可以看到每個進程所消耗的系統資源(CPU,內存),同時依然可以看到整個系統的關鍵參數。
如果你想知道每個用戶登錄服務器所使用的時間,你可以使用 ac 命令。這個命令需要你安裝 acct 包(Debian)或 psacct 包(RHEL,Centos)。
如果我們想知道所有用戶登陸服務器所使用的時間之和,我們可以直接運行 ac 命令,無需任何參數。
$ ac
total 1261.72
如果我們想知道各個用戶所使用時間,可以加上 -p 選項。
$ ac -p
shark 5.24
alvin 5.52
shs 1251.00
total 1261.76
我們還可以通過加上 -d 選項來查看具體每一天用戶使用服務器時間之和。
$ ac -d | tail -10
Jan 11 total 0.05
Jan 12 total 1.36
Jan 13 total 16.39
Jan 15 total 55.33
Jan 16 total 38.02
Jan 17 total 28.51
Jan 19 total 48.66
Jan 20 total 1.37
Jan 22 total 23.48
Today total 9.83
我們可以使用很多命令來監控系統的運行狀態,本文主要介紹了三個:watch 命令可以讓你重複執行某一條命令來監控一些參數的變化,top 命令可以查看某個用戶運行的進程數以及消耗的資源,而 ac 命令則可以查看每個用戶使用服務器時間。你經常使用哪個命令呢?歡迎留言討論!
公眾號:良許Linux
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※回頭車貨運收費標準
所有知識體系文章,GitHub已收錄,歡迎Star!再次感謝,願你早日進入大廠!
GitHub地址: https://github.com/Ziphtracks/JavaLearningmanual
註解(Annotation),也叫元數據。一種代碼級別的說明。它是JDK1.5及以後版本引入的一個特性,與類、接口、枚舉是在同一個層次。它可以聲明在包、類、字段、方法、局部變量、方法參數等的前面,用來對這些元素進行說明,註釋。
- 編寫文檔: 通過代碼里標識的元數據生成文檔【生成文檔doc文檔】
- 代碼分析: 通過代碼里標識的元數據對代碼進行分析【使用反射】
- 編譯檢查: 通過代碼里標識的元數據讓編譯器能夠實現基本的編譯檢查【Override等】
編寫文檔
首先,我們要知道Java中是有三種註釋的,分別為單行註釋、多行註釋和文檔註釋。而文檔註釋中,也有@開頭的元註解,這就是基於文檔註釋的註解。我們可以使用javadoc命令來生成doc文檔,此時我們文檔的內元註解也會生成對應的文檔內容。這就是編寫文檔的作用。
代碼分析
我們頻繁使用之一,也是包括使用反射來通過代碼里標識的元數據對代碼進行分析的,此內容我們在後續展開講解。
編譯檢查
至於在編譯期間在代碼中標識的註解,可以用來做特定的編譯檢查,它可以在編譯期間就檢查出“你是否按規定辦事”,如果不按照註解規定辦事的話,就會在編譯期間飄紅報錯,並予以提示信息。可以就可以為我們代碼提供了一種規範制約,避免我們後續在代碼中處理太多的代碼以及功能的規範。比如,@Override註解是在我們覆蓋父類(父接口)方法時出現的,這證明我們覆蓋方法是繼承於父類(父接口)的方法,如果該方法稍加改變就會報錯;@FunctionInterface註解是在編譯期檢查是否是函數式接口的,如果不遵循它的規範,同樣也會報錯。
- @Override: 標記在成員方法上,用於標識當前方法是重寫父類(父接口)方法,編譯器在對該方法進行編譯時會檢查是否符合重寫規則,如果不符合,編譯報錯。
- @Deprecated: 用於標記當前類、成員變量、成員方法或者構造方法過時如果開發者調用了被標記為過時的方法,編譯器在編譯期進行警告。
- @SuppressWarnings: 壓制警告註解,可放置在類和方法上,該註解的作用是阻止編譯器發出某些警告信息。
標記在成員方法上,用於標識當前方法是重寫父類(父接口)方法,編譯器在對該方法進行編譯時會檢查是否符合重寫規則,如果不符合,編譯報錯。
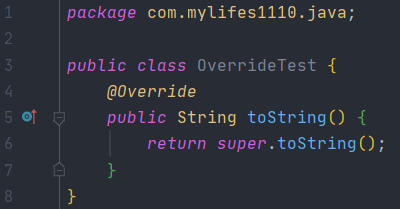
這裏解釋一下@Override註解,在我們的Object基類中有一個方法是toString方法,我們通常在實體類中去重寫此方法來達到打印對象信息的效果,這時候也會發現重寫的toString方法上方就有一個@Override註解。如下所示:
image-20200604203535421
於是,我們試圖去改變重寫后的toString方法名稱,將方法名改為toStrings。你會發現在編譯期就報錯了!如下所示:
image-20200604203645332
那麼這說明什麼呢?這就說明該方法不是我們重寫其父類(Object)的方法。這就是@Override註解的作用。
用於標記當前類、成員變量、成員方法或者構造方法過時如果開發者調用了被標記為過時的方法,編譯器在編譯期進行警告。
我們解釋@Deprecated註解就需要模擬一種場景了。假設我們公司的產品,目前是V1.0版本,它為用戶提供了show1方法的功能。這時候我們為產品的show1方法的功能又進行了擴展,打算髮布V2.0版本。但是,我們V1.0版本的產品需要拋棄嗎?也就是說我們V1.0的產品功能還繼續讓用戶使用嗎?答案肯定是不能拋棄的,因為有一部分用戶是一直用V1.0版本的。如果拋棄了該版本會損失很多的用戶量,所以我們不能拋棄該版本。這時候,我們對功能進行了擴展后,發布了V2.0版本,我們給予用戶的通知就可以了,也就是告知用戶我們在V2.0版本中為功能進行了擴展。可以讓用戶自行選擇版本。
但是,除了發布告知用戶版本情況之外,我們還需要在原來版本的功能上給予提示,在上面的模擬場景中我們需要在show1方法上方加@Deprecated註解給予提示。通過這種方式也告知用戶“這是舊版本時候的功能了,我們不建議再繼續使用舊版本的功能”,這句話的意思也就正是給用戶做了提示。用戶也會這麼想“奧,這版本的這個功能不好用了,肯定有新版本,又更好用的功能。我要去官網查一下下載新版本”,還會有用戶這麼想“我明白了,又更新出更好的功能了,但是這個版本的功能我已經夠用了,不需要重新下載新版本了”。
那麼我們怎麼查看我上述所說的在功能上給予的提示呢?這時候我需要去創建一個方法,然後去調用show1方法,並查看調用時它是如何提示的。
圖已經貼出來了,你是否發現的新舊版本功能的異同點呢?很明顯,在方法中的提示是在調用的方法名上加了一道橫線把該方法劃掉了。這就體現了show1方法過時了,已經不建議使用了,我們為你提供了更好的。
回想起來,在我們的api中也會有方法是過時的,比如我們的Date日期類中的方法有很多都已經過時了。如下圖:
image-20200604210154348 image-20200604210416762
如你所見,是不是有很多方法都過時了呢?那它的方法上是加了@Deprecated註解嗎?來跟着我的腳步,我帶你們看一下。
我們已經知道的Date類中的這些方法已經是過時的了,如果我們使用該方法並執行該程序的話。執行的過程中就會提示該方法已過時的內容,但是只是提示,並不影響你使用該方法。如下:
image-20200604221938895
OK!這也就是@Deprecated註解的作用了。
壓制警告註解,可放置在類和方法上,該註解的作用是阻止編譯器發出某些警告信息,該註解為單值註解,只有 一個value參數,該參數為字符串數組類型,參數值常用的有如下幾個。
- unchecked:未檢查的轉化,如集合沒有指定類型還添加元素
- unused:未使用的變量
- resource:有泛型未指定類型
- path:在類路徑,原文件路徑中有不存在的路徑
- deprecation:使用了某些不贊成使用的類和方法
- fallthrough:switch語句執行到底沒有break關鍵字
- rawtypes:沒有寫泛型,比如: List list = new ArrayList();
- all:全部類型的警告
壓制警告註解,顧名思義就是壓制警告的出現。我們都知道,在Java代碼的編寫過程中,是有很多黃色警告出現的。但是我不知道你的導師是否教過你,程序員只需要處理紅色的error,不需要理會黃色的warning。如果你的導師說過此問題,那是有原因的。因為在你學習階段,我們認清處理紅色的error即可,這樣可以減輕你學習階段在腦部的記憶內容。如果你剛剛加入學習Java的隊列中,需要大腦記憶的東西就有太多了,也就是我們目前不需要額外記憶其他的東西,只記憶重點即可。至於黃色warning嘛,在你的學習過程中慢慢就會有所了解的,而不是死記硬背的。
那為了解釋@SuppressWarnings註解,我們還使用上一個例子,因為在那個例子中就有黃色的warning出現。
而每一個黃色的warning都會有警告信息的。比如,這一個圖中的警告信息,就告知你show2()方法沒有被使用,簡單來說,你創建的show2方法,但是你在代碼中並沒有調用過此方法。以後你便會遇到各種各樣黃色的warning。然後, 我們就可以使用不同的註解參數來壓制不同的註解。但是在該註解的參數中,提供了一個all參數可以壓制全部類型的警告。而這個註解是需要加到類的上方,並賦予all參數,即可壓制所有警告。如下:
image-20200604213943722
我們加入註解並賦予all參數后,你會發現use方法和show2方法的警告沒有了,實際上導Date包的警告還在,因為我們Date包導入到了該類中,但是我們並沒有創建Date對象,也就是並沒有寫入Date在代碼中,你也會發現那一行是灰色的,也就證明了我們沒有去使用導入這個包的任何信息的說法,出現這種情況我們就需要把這個沒有用的導包內容刪除掉,使用Ctrl + X刪除導入沒有用到的包即可。還有一種辦法就是在包的上方修飾壓制警告註解,但是我認為在一個沒有用的包上加壓制註解是毫無意義的,所以,我們直接刪除就好。
然後,我們還見到上圖,註解那一行出現了警告信息提示。這一行的意思是冗餘的警告壓制。這就是說我們壓制以下的警告並沒有什麼意義而造成的冗餘,但是如果我們使用了該類並做了點什麼的話,壓制註解的冗餘警告就會消失,畢竟我們使用了該類,此時就不會早場冗餘了。
上述解釋@SuppressWarnings註解也差不多就這些了。OK,繼續向下看吧。持續為大家講解。
@Repeatable 表明標記的註解可以多次應用於相同的聲明或類型,此註解由Java8版本引入。我們知道註解是不能重複定義的,其實該註解就是一個語法糖,它可以重複多此使用,更適用於我們的特殊場景。
首先,我們先創建一個可以重複使用的註解。
package com.mylifes1110.anno;
import java.lang.annotation.Repeatable;
@Repeatable(Hour.class)
public @interface Hours {
double[] hours() default 0;
}
你會發現註解要求傳入的值是一個類對象,此類對象就需要傳入另外一個註解,這裏也就是另外一個註解容器的類對象。我們去創建一下。
package com.mylifes1110.anno;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
//容器
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Hour {
Hours[] value();
}
其實,這兩個註解的套用,就是將一個普通的註解封裝了一個可重複使用的註解,來達到註解的復用性。最後,我們創建一下測試類,隨後帶你去看一下源碼。
package com.mylifes1110.java;
import com.mylifes1110.anno.Hours;
@Hours(hours = 4)
@Hours(hours = 4.5)
@Hours(hours = 2)
public class Worker {
public static void main(String[] args) {
//通過Hours註解類型來獲取Worker中的值數組對象
Hours[] hours = Worker.class.getAnnotationsByType(Hours.class);
//遍曆數組
for (Hours h : hours) {
System.out.println(h);
}
}
}
測試類,是一個工人測試類,該工人使用註解記錄早中晚的工作時間。測試結果如下:
image-20200606183652359
然後我們進入到源碼一探究竟。
image-20200606183737877
我們發現進入到源碼后,就只看見一個返回值為類對象的抽象方法。這也就驗證了該註解只是一個可實現重複性註解的語法糖而已。
註解可以根據註解參數分為三大類:
- 標記註解: 沒有參數的註解,僅用自身的存在與否為程序提供信息,如@Override註解,該註解沒有參數,用於表示當前方法為重寫方法。
- 單值註解: 只有一個參數的註解,如果該參數的名字為value,那麼可以省略參數名,如 @SuppressWarnings(value = “all”),可以簡寫為@SuppressWarnings(“all”)。
- 完整註解: 有多個參數的註解。
說到@Override註解是一個標記註解,那我們進入到該註解的源碼查看一下。從上往下看該註解源碼,發現它繼承了導入了
java.lang.annotation.*,也就是有使用到該包的內容。然後下面就又是兩個看不懂的註解,其實發現註解的定義格式是public修飾的@Interface,最終看到該註解中方法體並沒有任何參數,也就是只起到標記作用。
在上面我們用到的@SuppressWarnings註解就是一個單值註解。那我們進入到它的源碼看一下是怎麼個情況。其實,和標記註解比較,它就多一個value參數而已,而這就是單值註解的必要條件,即只有一個參數。並且這一個參數為value時,我們可以省略value。
上述兩個類型註解講解完,至於完整註解嘛,這下就能更明白了。其中的方法體就是有多個參數而已。
格式: public @Interface 註解名 {屬性列表/無屬性}
注意: 如果註解體中無任何屬性,其本質就是標記註解。但是與其標註註解還少了上邊修飾的元註解。
如下,這就是一個註解。但是它與jdk自定義註解有點區別,jdk自定義註解的上方還有註解來修飾該註解,而那註解就叫做元註解。元註解我會在後面詳細的說到。
image-20200606104149069
這裏我們的確不知道@Interface是什麼,那我們就把自定義的這個註解反編譯一下,看一下反編譯信息。反編譯操作如下:
image-20200606104818131
反編譯后的反編譯內容如下:
public interface com.mylifes1110.anno.MyAnno extends java.lang.annotation.Annotation {
}
首先,看過反編譯內容后,我們可以直觀的得知他是一個接口,因為它的public修飾符後面的關鍵字是interface。
其次,我們發現MyAnno這個接口是繼承了java.lang.annotation包下的Annotation接口。
所以,我們可以得知註解的本質就是一個接口,該接口默認繼承了Annotation接口。
既然,是繼承的Annotation接口,那我們就去進入到這個接口中,看它定義了什麼。以下是我抽取出來的接口內容。我們發現它看似很常見,其實它們不是很常用,作為了解即可。
public interface Annotation {
boolean equals(Object obj);
int hashCode();
String toString();
Class<? extends Annotation> annotationType();
}
最後,我們的註解中也是可以寫有屬性的,它的屬性不同於普通的屬性,它的屬性是抽象方法。既然註解也是一個接口,那麼我們可以說接口體中可以定義什麼,它同樣也可以定義,而它的修飾符與接口一樣,也是默認被public abstract修飾。
而註解體中的屬性也是有要求的。其屬性要求如下:
- 屬性的返回值類型必須是以下幾種:
- 基本數據類型
- String類型
- 枚舉類型
- 註解
- 以上類型的數組
- 注意: 在這裏不能有void的無返回值類型和以上類型以外的類型
- 定義的屬性,在使用時需要給註解中的屬性賦值
- 如果定義屬性時,使用
default關鍵字給屬性默認初始化值,則使用註解時可以不為屬性賦值,它取的是默認值。如果為它再次傳入值,那麼就發生了對原值的覆蓋。- 如果只有一個屬性需要賦值,並且屬性的名稱為value,則賦值時value可以省略,可以直接定義值
- 數組賦值時,值使用
{}存儲值。如果數組中只有一個值,則可以省略{}。
屬性返回值既然有以上幾種,那麼我就在這裏寫出這幾種演示一下是如何寫的。
首先,定義一個枚舉類和另外一個註解備用。
package com.mylifes1110.enums;
public enum Lamp {
RED, GREEN, YELLOW
}
package com.mylifes1110.anno;
public @interface MyAnno2 {
}
其次,我們來定義上述幾種類型,如下:
package com.mylifes1110.anno;
import com.mylifes1110.enums.Lamp;
public @interface MyAnno {
//基本數據類型
int num();
//String類型
String value();
//枚舉類型
Lamp lamp();
//註解類型
MyAnno2 myAnno2();
//以上類型的數組
String[] values();
Lamp[] lamps();
MyAnno2[] myAnno2s();
int[] nums();
}
這裏我們演示一下,首先,我們使用該註解來進行演示。
package com.mylifes1110.anno;
public @interface MyAnno {
//基本數據類型
int num();
//String類型
String value();
}
隨後創建一個測試類,在類的上方寫上註解,你會發現,註解的參數中會讓你寫這兩個參數(int、String)。
image-20200606113037920
此時,傳參是這樣來做的。格式為:名稱 = 返回值類型參數。如下:
上述所說,如果使用default關鍵字給屬性默認初始化值,就不需要為其參數賦值,如果賦值的話,就把默認初始化的值覆蓋掉了。
當然還有一個規則,如果只有一個屬性需要賦值,並且屬性的名稱為value,則賦值時value可以省略,可以直接定義值。那麼,我們的num已經有了默認值,就可以不為它傳值。我們發現,註解中定義的屬性就剩下了一個value屬性值,那麼我們就可以來演示這個規則了。
image-20200606113849685
這裏,我並沒有寫屬性名稱value,而是直接為value賦值。如果我將num的default關鍵字修飾去掉呢,那意思也就是說在使用該註解時必須為num賦值,這樣可以省略value嗎?那我們看一下。
image-20200606114216801
結果,就是我們所想的,它報錯了,必須讓我們給num賦值。其實想想這個規則也是很容易懂的,定義一個為value的值,就可以省略其value名稱。如果定義多個值,它們可以省略名稱就無法區分定義的是那個值了,關鍵是還有數組,數組內定義的是多個值呢,對吧。
這裏我們演示一下,上述的多種返回值類型是如何賦值的。這裏我們定義這幾個參數來看一下,是如何為屬性賦值的。
num是一個int基本數據類型,即num = 1
value是一個String類型,即value = "str"
lamp是一個枚舉類型,即lamp = Lamp.RED
myAnno2是一個註解類型,即myAnno2 = @MyAnno2
values是一個String類型數組,即values = {"s1", "s2", "s3"}
values是一個String類型數組,其數組中只有一個值,即values = "s4"
注意: 值與值之間是,隔開的;數組是用{}來存儲值的,如果數組中只有一個值可以省略{};枚舉類型是枚舉名.枚舉值
元註解就是用來描述註解的註解。一般使用元註解來限制自定義註解的使用範圍、生命周期等等。
而在jdk的中java.lang.annotation包中定義了四個元註解,如下:
| 元註解 | 描述 |
|---|---|
| @Target | 指定被修飾的註解的作用範圍 |
| @Retention | 指定了被修飾的註解的生命周期 |
| @Documented | 指定了被修飾的註解是可以Javadoc等工具文檔化 |
| @Inherited | 指定了被修飾的註解修飾程序元素的時候是可以被子類繼承的 |
@Target 指定被修飾的註解的作用範圍。其作用範圍可以在源碼中找到參數值。
| 屬性 | 描述 |
|---|---|
| CONSTRUCTOR | 用於描述構造器 |
| FIELD(常用) | 用於描述屬性 |
| LOCAL_VARIABLE | 用於描述局部變量 |
| METHOD(常用) | 用於描述方法 |
| PACKAGE | 用於描述包 |
| PARAMETER | 用於描述參數 |
| TYPE(常用) | 用於描述類、接口(包括註解類型) 或enum聲明 |
| ANNOTATION_TYPE | 用於描述註解類型 |
| TYPE_USE | 用於描述使用類型 |
由此可見,該註解體內只有一個value屬性值,但是它的類型是一個ElementType數組。那我們進入到這個數組中繼續查看。
進入到該數組中,你會發現他是一個枚舉類,其中定義了上述表格中的各個屬性。
了解了@Target的作用和屬性值后,我們來使用一下該註解。首先,我們要先用該註解來修飾一個自定義註解,定義該註解的指定作用在類上。如下:
而你觀察如下測試類,我們把註解作用在類上時是沒有錯誤的。而當我們的註解作用在其他地方就會報錯。這也就說明了,我們@Target的屬性起了作用。
注意: 如果我們定義多個作用範圍時,也是可以省略該參數名稱了,因為該類型是一個數組,雖然能省略名稱但是,我們還需要用{}來存儲。
@Retention 指定了被修飾的註解的生命周期
| 屬性 | 描述 |
|---|---|
| RetentionPolicy.SOURCE | 註解只在源碼階段保留,在編譯器進行編譯時它將被丟棄忽視。 |
| RetentionPolicy.CLASS | 註解只被保留到編譯進行時的class文件,但 JVM 加載class文件時候被遺棄,也就是在這個階段不會讀取到該class文件。 |
| RetentionPolicy.RUNTIME(常用) | 註解可以保留到程序運行的時候,它會被加載進入到 JVM 中,所以在程序運行時可以獲取到它們。 |
注意: 我們常用的定義即是RetentionPolicy.RUNTIME,因為我們使用反射來實現的時候是需要從JVM中獲取class類對象並操作類對象的。
首先,我們要了解反射的三個生命周期階段,這部分內容我在Java反射機制中也是做了非常詳細的說明,有興趣的小夥伴可以去看看我寫的Java反射機制,相信你在其中也會有所收穫。
這裏我再次強調一下這三個生命周期是源碼階段 – > class類對象階段 – > Runtime運行時階段。
那我們進入到源碼,看看@Retention註解中是否有這些參數。
我們看到該註解中的屬性只有一個value,而它的類型是一個RetentionPolicy類型,我們進入到該類型中看看有什麼參數,是否與表格中的參數相同呢?
image-20200606145449931
至於該註解怎麼使用,其實是相同的,用法如下:
這就證明了我們的註解可以保留到Runtime運行階段,而我們在反射中大多數是定義到Runtime運行時階段的,因為我們需要從JVM中獲取class類對象並操作類對象。
@Documented 指定了被修飾的註解是可以Javadoc等工具文檔化
@Documented註解是比較好理解的,它是一個標記註解。被該標記註解標記的註解,生成doc文檔時,註解是可以被加載到文檔中显示的。
image-20200606152526551
還拿api中過時的Date中的方法來說,在api中显示Date中的getYear方法是這樣的。
正如你看到的,註解在api中显示了出來,證明該註解是@Documented註解修飾並文檔化的。那我們就看看這個註解是否被@Documented修飾吧。
然後,我們發現該註解的確是被文檔化了。所以在api中才會显示該註解的。如果不信,你可以自己使用javadoc命令來生成一下doc文檔,看看被該註解修飾的註解是否存在。
至於Javadoc文檔生成,我在javadoc文檔生成一文中有過詳細記載,大家可以進行參考,生成doc文檔查看。
@Inherited 指定了被修飾的註解修飾程序元素的時候是可以被子類繼承的
首先進入到源碼中,我們也可以清楚的知道,該註解也是一個標記註解。而且它也是被文檔化的註解。
其次,我們去在自定義註解中,標註上@Inherited註解。
演示@Inherited註解,我需要創建兩個類,同時兩個類中有一層的繼承關係。如下:
我們在Person類中標記了@MyAnno註解,由於該註解被@Inherited註解修飾,我們就可以得出繼承於Person類的Student類也同樣被@MyAnno註解標記了,如果你要獲取該註解的值的話,肯定獲取的也是父類上註解值的那個”1″。
自定義註解
package com.mylifes1110.anno;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* @InterfaceName Sign
* @Description 描述需要執行的類名和方法名
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Sign {
String methodName();
String className();
}
Cat
package com.mylifes1110.java;
/**
* @ClassName Cat
* @Description 描述一隻貓的類
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
public class Cat {
/*
* @Description 描述一隻貓吃魚的方法
* @Author Ziph
* @Date 2020/6/6
* @Param []
* @return void
*/
public void eat() {
System.out.println("貓吃魚");
}
}
準備好,上述代碼后,我們就可以開始編寫使用反射技術來解析註解的測試類。如下:
首先,我們先通過反射來獲取註解中的methodName和className參數。
package com.mylifes1110.java;
import com.mylifes1110.anno.Sign;
/**
* @ClassName SignTest
* @Description 要求創建cat對象並執行其類中eat方法
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@Sign(className = "com.mylifes1110.java.Cat", methodName = "eat")
public class SignTest {
public static void main(String[] args) {
//獲取該類的類對象
Class<SignTest> signTestClass = SignTest.class;
//獲取類對象中的註解對象
//原理實際上是在內存中生成了一個註解接口的子類實現對象
Sign sign = signTestClass.getAnnotation(Sign.class);
//調用註解對象中定義的抽象方法(註解中的屬性)來獲取返回值
String className = sign.className();
String methodName = sign.methodName();
System.out.println(className);
System.out.println(methodName);
}
}
此時的打印結果證明我們已經成功獲取到了該註解的兩個參數。
image-20200606162810165
注意: 獲取類對象中的註解對象時,其原理實際上是在內存中生成了一個註解接口的子類實現對象並返回的字符串內容。如下:
public class SignImpl implements Sign {
public String methodName() {
return "eat";
}
public String className() {
return "com.mylifes1110.java.Cat";
}
}
繼續編寫我們後面的代碼,代碼完整版如下:
完整版代碼
package com.mylifes1110.java;
import com.mylifes1110.anno.Sign;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
/**
* @ClassName SignTest
* @Description 要求創建cat對象並執行其類中eat方法
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@Sign(className = "com.mylifes1110.java.Cat", methodName = "eat")
public class SignTest {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException, NoSuchMethodException, InvocationTargetException {
//獲取該類的類對象
Class<SignTest> signTestClass = SignTest.class;
//獲取類對象中的註解對象
//原理實際上是在內存中生成了一個註解接口的子類實現對象
Sign sign = signTestClass.getAnnotation(Sign.class);
//調用註解對象中定義的抽象方法(註解中的屬性)來獲取返回值
String className = sign.className();
String methodName = sign.methodName();
//獲取className名稱的類對象
Class<?> clazz = Class.forName(className);
//創建對象
Object o = clazz.newInstance();
//獲取methodName名稱的方法對象
Method method = clazz.getMethod(methodName);
//執行該方法
method.invoke(o);
}
}
執行結果
執行后成功的調用了eat方法,並打印了貓吃魚的結果,如下:
首先,我們在使用JDBC的時候是需要通過properties文件來獲取配置JDBC的配置信息的,這次我們通過自定義註解來獲取配置信息。其實使用註解並沒有用配置文件好,但是我們需要了解這是怎麼做的,獲取方法也是魚使用反射機制解析註解,所謂“萬變不離其宗”,它就是這樣的。
package com.mylifes1110.java.anno;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* @InterfaceName DBInfo
* @Description 給予註解聲明周期為運行時並限定註解只能用在類上
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface DBInfo {
String driver() default "com.mysql.jdbc.Driver";
String url() default "jdbc:mysql://localhost:3306/temp?useUnicode=true&characterEncoding=utf8";
String username() default "root";
String password() default "123456";
}
為了代碼的健全我也在裏面加了properties文件獲取連接的方式。
package com.mylifes1110.java.utils;
import com.mylifes1110.java.anno.DBInfo;
import java.io.IOException;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
/**
* @ClassName DBUtils
* @Description 數據庫連接工具類
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
@DBInfo()
public class DBUtils {
private static final Properties PROPERTIES = new Properties();
private static String driver;
private static String url;
private static String username;
private static String password;
static {
Class<DBUtils> dbUtilsClass = DBUtils.class;
boolean annotationPresent = dbUtilsClass.isAnnotationPresent(DBInfo.class);
if (annotationPresent) {
/**
* DBUilts類上有DBInfo註解,並獲取該註解
*/
DBInfo dbInfo = dbUtilsClass.getAnnotation(DBInfo.class);
// System.out.println(dbInfo);
driver = dbInfo.driver();
url = dbInfo.url();
username = dbInfo.username();
password = dbInfo.password();
} else {
InputStream inputStream = DBUtils.class.getResourceAsStream("db.properties");
try {
PROPERTIES.load(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static Connection getConnection() {
try {
return DriverManager.getConnection(url, username, password);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return null;
}
public static void closeAll(Connection connection, Statement statement, ResultSet resultSet) {
try {
if (resultSet != null) {
resultSet.close();
resultSet = null;
}
if (statement != null) {
statement.close();
statement = null;
}
if (connection != null) {
connection.close();
connection = null;
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
package com.mylifes1110.java.test;
import com.mylifes1110.java.utils.DBUtils;
import java.sql.Connection;
/**
* @ClassName GetConnectionDemo
* @Description 測試連接是否可以獲取到
* @Author Ziph
* @Date 2020/6/6
* @Since 1.8
*/
public class GetConnectionDemo {
public static void main(String[] args) {
Connection connection = DBUtils.getConnection();
System.out.println(connection);
}
}
為了證明獲取的連接是由註解的配置信息獲取到的連接,我將properties文件中的所有配置信息刪除后測試的。
我不清楚小夥伴們是否了解,Junit單元測試。@Test是單元測試的測試方法上方修飾的註解。此註解的核心原理也是由反射來實現的。如果有小夥伴不知道什麼是單元測試或者對自定義@MyTest註解實現單元測試感興趣的話,可以點進來看看哦!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
※回頭車貨運收費標準
最近看到一些大佬都開始關注blazor,我也想學習一下。做了一個小的demo,todolist,僅是一個小示例,參考此vue項目的實現http://www.jq22.com/code1339
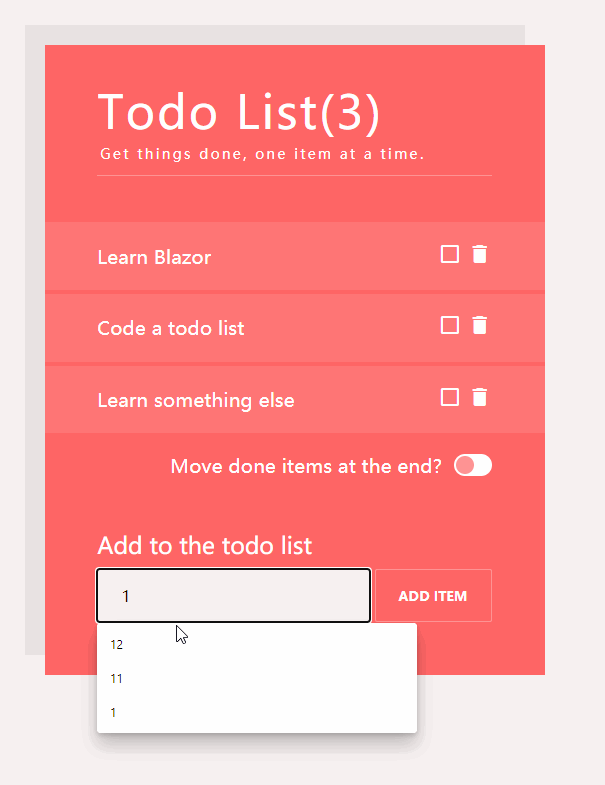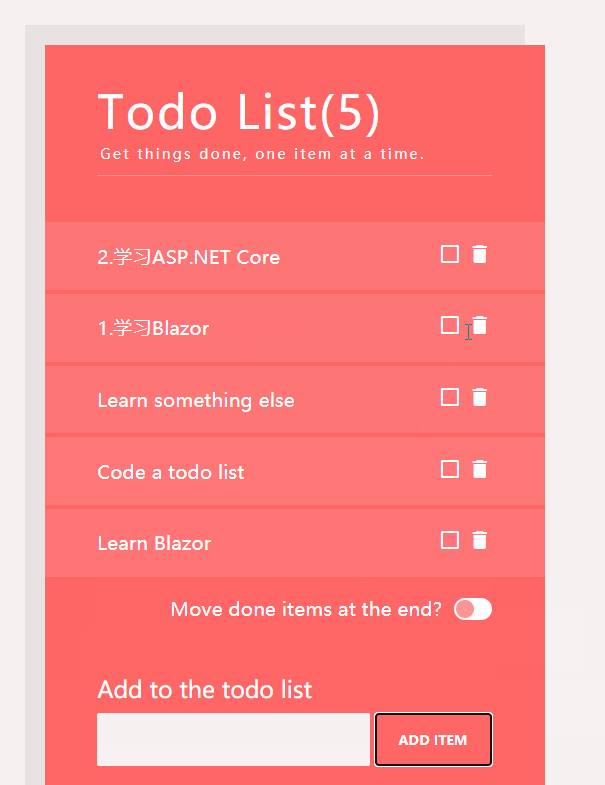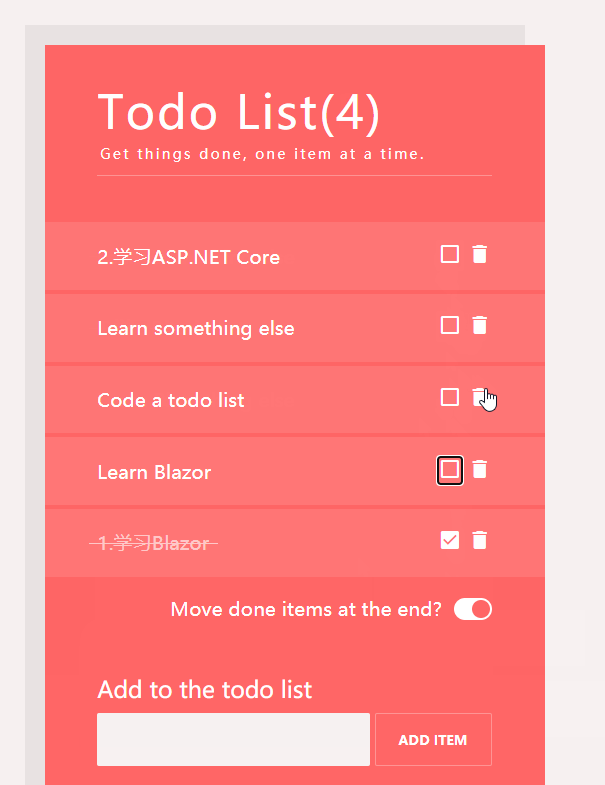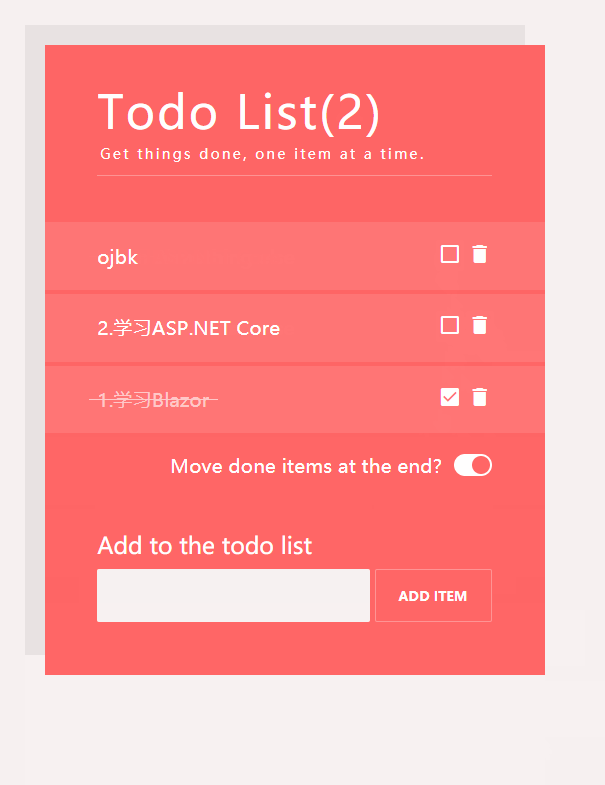
先看實現的效果圖
不BB,直接可以去看
我們這裏刪除了默認的一些源碼。只保留最簡單的結構,在Pages/Index.razor中。
@code代碼結構中寫如下內容
public class TodoItem
{
public TodoItem () { }
public TodoItem (int id, string label, bool isDone)
{
Id = id;
Label = label;
IsDone = isDone;
}
public int Id { get; set; }
public string Label { get; set; }
public bool IsDone { get; set; }
}
private IList<TodoItem> Todos;
private int id = 0;
protected override void OnInitialized ()
{
Todos = new List<TodoItem> ()
{
new TodoItem (++id, "Learn Blazor", false),
new TodoItem (++id, "Code a todo list", false),
new TodoItem (++id, "Learn something else", false)
};
}
展示還有多少未完成的任務
<h1>
Todo List(@Todos.Count(todo => !todo.IsDone))
<span>Get things done, one item at a time.</span>
</h1>
當任務沒有時,我們展示默認效果,提示用戶無任務
<p class="emptylist" style="display: @(Todos.Count()>0?"none":"");">Your todo list is empty.</p>
新增一個任務
<form name="newform">
<label for="newitem">Add to the todo list</label>
<input type="text" name="newitem" id="newitem" @bind-value="Label">
<button type="button" @onclick="AddItem">Add item</button>
</form>
這裏我們用了一個Label變量,一個onclick事件。
private string Label;
private void AddItem()
{
if (!string.IsNullOrWhiteSpace(Label))
{
Todos.Add (new TodoItem { Id = ++id, Label = Label });
Label = string.Empty;
}
this.SortByStatus();
}
this.SortByStatus
因為我們這裏還實現一個功能,就是當勾選(當任務完成時,我們將他移到最下面)
<div class="togglebutton-wrapper@(IsActive==true?" togglebutton-checked":"")">
<label for="todosort">
<span class="togglebutton-Label">Move done items at the end?</span>
<span class="tooglebutton-box"></span>
</label>
<input type="checkbox" name="todosort" id="todosort" value="@IsActive" @onchange="ActiveChanged">
</div>
一個IsActive的變量,用於指示當前checkbox的樣式,是否開啟已完成的任務移動到最下面。當勾選時,改變IsActive的值。並調用排序的功能。
private bool IsActive = false;
private void ActiveChanged()
{
this.IsActive = !this.IsActive;
this.SortByStatus();
}
private void SortByStatus()
{
if (this.IsActive)
{
Todos = Todos.OrderBy(r => r.IsDone).ThenByDescending(r => r.Id).ToList();
}
else
{
Todos = Todos.OrderByDescending(r => r.Id).ToList();
}
}
對於列表的展示我們使用如下ul li @for實現
<ul>
@foreach (var item in Todos)
{
<li stagger="5000" class="@(item.IsDone?"done":"")">
<span class="label">@item.Label</span>
<div class="actions">
<button class="btn-picto" type="button"
@onclick="@((e)=> {MarkAsDoneOrUndone(item);})"
title="@(item.IsDone ? "Undone" :"Done")"
aria-label="@(item.IsDone ? "Undone" :"Done")">
<i aria-hidden="true" class="material-icons">@(item.IsDone ? "check_box" : "check_box_outline_blank")</i>
</button>
<button class="btn-picto" type="button"
@onclick="@((e)=> { DeleteItemFromList(item); })"
aria-Label="Delete" title="Delete">
<i aria-hidden="true" class="material-icons">delete</i>
</button>
</div>
</li>
}
</ul>
循環Todos,然後,根據item.IsDone,改變li的樣式,從而實現一个中劃線的功能,二個按鈕的功能,一個是勾選任務表示此任務已完成,另一個是刪除此任務。同理,我們仍然通過IsDone來標識完成任務的圖標,標題等。
private void MarkAsDoneOrUndone(TodoItem item)
{
item.IsDone = !item.IsDone;
this.SortByStatus();
}
private void DeleteItemFromList(TodoItem item)
{
Todos.Remove(item);
this.SortByStatus();
}
當然,我們可以 在ul,外包裹一層,根據Count判斷有沒有任務,從而显示這個列表。
<div style="display: @(Todos.Count()>0?"":"none");"><ul>xxx</ul></div>
其他的樣式與圖標,請看最上面的源碼wwwroot/css目錄獲取。
在項目根目錄執行如下命令
dotnet publish -c Release
我們就能得到一個發布包,他的位置在 (BlazorAppTodoList\bin\Release\netstandard2.1\publish) ,我們把他複製到服務器上,這裏我放到/var/www/todolilst目錄中。
它相當於一個靜態文件,你可以將他部署到任何一個web服務器上。
這裏我們把他放到nginx中,並在目錄/etc/nginx/conf.d/ 新建一個文件 todolist.conf,然後放入如下內容。
server {
listen 8081;
location / {
root /var/www/todolist/wwwroot;
try_files $uri $uri/ /index.html =404;
}
}
記得在etc/nginx/nginx.conf中配置gzip壓縮。
gzip on;
gzip_min_length 5k; #gzip壓縮最小文件大小,超出進行壓縮(自行調節)
gzip_buffers 4 16k; #buffer 不用修改
gzip_comp_level 8; #壓縮級別:1-10,数字越大壓縮的越好,時間也越長
gzip_types text/plain application/x-javascript application/javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png application/octet-stream; # 壓縮文件類型
gzip_vary on; # 和http頭有關係,加個vary頭,給代理服務器用的,有的瀏覽器支持壓縮,有的不支持,所以避免浪費不支持的也壓縮,所以根據客戶端的HTTP頭來判斷,是否需要壓縮
我遇到dll,wasm,後綴的文件壓縮無效。因為gzip_types ,沒有配置他們的Content-Type。我們在瀏覽器中找到響應頭Content-Type: application/octet-stream,然後在上文中的nginx配置文件中,gzip_types加上application/octet-stream,
最後執行
nginx -t
nginx -s reload
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
/* An object allocator for Python.
Here is an introduction to the layers of the Python memory architecture,
showing where the object allocator is actually used (layer +2), It is
called for every object allocation and deallocation (PyObject_New/Del),
unless the object-specific allocators implement a proprietary allocation
scheme (ex.: ints use a simple free list). This is also the place where
the cyclic garbage collector operates selectively on container objects.
Object-specific allocators
_____ ______ ______ ________
[ int ] [ dict ] [ list ] ... [ string ] Python core |
+3 | <----- Object-specific memory -----> | <-- Non-object memory --> |
_______________________________ | |
[ Python's object allocator ] | |
+2 | ####### Object memory ####### | <------ Internal buffers ------> |
______________________________________________________________ |
[ Python's raw memory allocator (PyMem_ API) ] |
+1 | <----- Python memory (under PyMem manager's control) ------> | |
__________________________________________________________________
[ Underlying general-purpose allocator (ex: C library malloc) ]
0 | <------ Virtual memory allocated for the python process -------> |
=========================================================================
_______________________________________________________________________
[ OS-specific Virtual Memory Manager (VMM) ]
-1 | <--- Kernel dynamic storage allocation & management (page-based) ---> |
__________________________________ __________________________________
[ ] [ ]
-2 | <-- Physical memory: ROM/RAM --> | | <-- Secondary storage (swap) --> |
*/
reference:Objects/obmalloc.c
layer 3: Object-specific memory(int/dict/list/string....)
python 實現並維護
用戶對Python對象的直接操作,主要是各類特定對象的緩衝池機制,緩衝池,比如小整數對象池等等
layer 2: Python's object allocator
實現了創建/銷毀python對象的接口(PyObject_New/Del),涉及對象參數/引用計數等
layer 1: Python's raw memory allocator (PyMem_ API)
包裝了第0層的內存管理接口,提供同一個raw memory管理接口
封裝的原因:不同操作系統C行為不一致,保證可移植性,相同語義相同行為
layer 0: Underlying general-purpose allocator (ex: C library malloc)
操作系統提供的內存管理接口,由操作系統實現並管理,Python不能干涉這一層的行為,大內存 分配調用malloc函數分配內存
Python中有分為大內存和小內存,512K為分界線
大內存使用系統malloc進行分配
小內存使用python內存池進行分配
1. 如果要分配的內存空間大於 SMALL_REQUEST_THRESHOLD bytes(512 bytes), 將直接使用layer 1的內存分配接口進行分配
2. 否則, 使用不同的block來滿足分配需求
申請一塊大小28字節的內存, 實際從內存中劃到32字節的一個block (從size class index為3的pool裏面劃出)
內存塊block 是python內存的最小單位
* For small requests we have the following table:
*
* Request in bytes Size of allocated block Size class idx
* ----------------------------------------------------------------
* 1-8 8 0
* 9-16 16 1
* 17-24 24 2
* 25-32 32 3
* 33-40 40 4
* 41-48 48 5
* 49-56 56 6
* 57-64 64 7
* 65-72 72 8
* ... ... ...
* 497-504 504 62
* 505-512 512 63
*
* 0, SMALL_REQUEST_THRESHOLD + 1 and up: routed to the underlying
* allocator.
*/
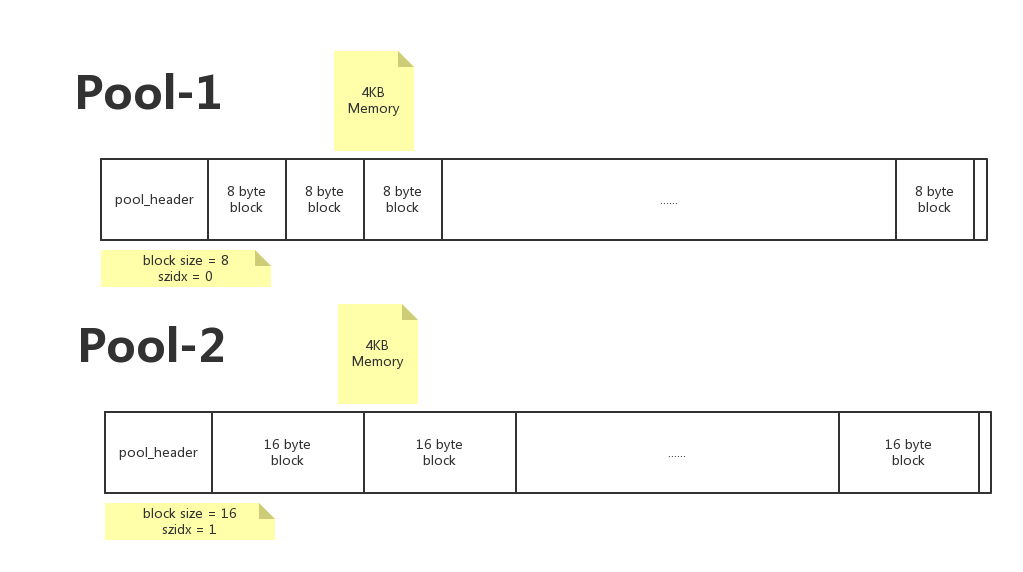
pool內存池,管理block, 一個pool管理着一堆固定大小的內存塊,在Python中, 一個pool的大小通常為一個系統內存頁. 4kB
#define SYSTEM_PAGE_SIZE (4 * 1024)
#define SYSTEM_PAGE_SIZE_MASK (SYSTEM_PAGE_SIZE - 1)
#define POOL_SIZE SYSTEM_PAGE_SIZE /* must be 2^N */
#define POOL_SIZE_MASK SYSTEM_PAGE_SIZE_MASK
pool的4kB內存 = pool_header + block集合(N多大小一樣的block)
typedef uint8_t block;
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref; /* number of allocated blocks */
block *freeblock; /* pool's free list head */
struct pool_header *nextpool; /* next pool of this size class */
struct pool_header *prevpool; /* previous pool "" */
uint arenaindex; /* index into arenas of base adr */
uint szidx; /* block size class index */
uint nextoffset; /* bytes to virgin block */
uint maxnextoffset; /* largest valid nextoffset */
};
pool_header 作用
與其他pool鏈接, 組成雙向鏈表
2. 維護pool中可用的block, 單鏈表
3. 保存 szidx , 這個和該pool中block的大小有關係, (block size=8, szidx=0), (block size=16, szidx=1)...用於內存分配時匹配到擁有對應大小block的pool
void *
PyObject_Malloc(size_t nbytes)
{
...
init_pool:
// 1. 連接到 used_pools 雙向鏈表, 作為表頭
// 注意, 這裏 usedpools[0] 保存着 block size = 8 的所有used_pools的表頭
/* Frontlink to used pools. */
next = usedpools[size + size]; /* == prev */
pool->nextpool = next;
pool->prevpool = next;
next->nextpool = pool;
next->prevpool = pool;
pool->ref.count = 1;
// 如果已經初始化過了...這裏看初始化, 跳過
if (pool->szidx == size) {
/* Luckily, this pool last contained blocks
* of the same size class, so its header
* and free list are already initialized.
*/
bp = pool->freeblock;
pool->freeblock = *(block **)bp;
UNLOCK();
return (void *)bp;
}
/*
* Initialize the pool header, set up the free list to
* contain just the second block, and return the first
* block.
*/
// 開始初始化pool_header
// 這裏 size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT; 其實是Size class idx, 即szidx
pool->szidx = size;
// 計算獲得每個block的size
size = INDEX2SIZE(size);
// 注意 #define POOL_OVERHEAD ROUNDUP(sizeof(struct pool_header))
// bp => 初始化為pool + pool_header size, 跳過pool_header的內存
bp = (block *)pool + POOL_OVERHEAD;
// 計算偏移量, 這裏的偏移量是絕對值
// #define POOL_SIZE SYSTEM_PAGE_SIZE /* must be 2^N */
// POOL_SIZE = 4kb, POOL_OVERHEAD = pool_header size
// 下一個偏移位置: pool_header size + 2 * size
pool->nextoffset = POOL_OVERHEAD + (size << 1);
// 4kb - size
pool->maxnextoffset = POOL_SIZE - size;
// freeblock指向 bp + size = pool_header size + size
pool->freeblock = bp + size;
// 賦值NULL
*(block **)(pool->freeblock) = NULL;
UNLOCK();
return (void *)bp;
}
if (pool != pool->nextpool) { //
/*
* There is a used pool for this size class.
* Pick up the head block of its free list.
*/
++pool->ref.count;
bp = pool->freeblock; // 指針指向空閑block起始位置
assert(bp != NULL);
// 代碼-1
// 調整 pool->freeblock (假設A節點)指向鏈表下一個, 即bp首字節指向的下一個節點(假設B節點) , 如果此時!= NULL
// 表示 A節點可用, 直接返回
if ((pool->freeblock = *(block **)bp) != NULL) {
UNLOCK();
return (void *)bp;
}
// 代碼-2
/*
* Reached the end of the free list, try to extend it.
*/
// 有足夠的空間, 分配一個, pool->freeblock 指向後移
if (pool->nextoffset <= pool->maxnextoffset) {
/* There is room for another block. */
// 變更位置信息
pool->freeblock = (block*)pool +
pool->nextoffset;
pool->nextoffset += INDEX2SIZE(size);
*(block **)(pool->freeblock) = NULL; // 注意, 指向NULL
UNLOCK();
// 返回bp
return (void *)bp;
}
// 代碼-3
/* Pool is full, unlink from used pools. */ // 滿了, 需要從下一個pool獲取
next = pool->nextpool;
pool = pool->prevpool;
next->prevpool = pool;
pool->nextpool = next;
UNLOCK();
return (void *)bp;
}
內存塊尚未分配完, 且此時不存在回收的block, 全新進來的時候, 分配第一塊block
(pool->freeblock = *(block **)bp) == NULL
當進入代碼邏輯2時,表示有空閑的block, 代碼2的執行流程圖如下
回收涉及的代碼:
void
PyObject_Free(void *p)
{
poolp pool;
block *lastfree;
poolp next, prev;
uint size;
pool = POOL_ADDR(p);
if (Py_ADDRESS_IN_RANGE(p, pool)) {
/* We allocated this address. */
LOCK();
/* Link p to the start of the pool's freeblock list. Since
* the pool had at least the p block outstanding, the pool
* wasn't empty (so it's already in a usedpools[] list, or
* was full and is in no list -- it's not in the freeblocks
* list in any case).
*/
assert(pool->ref.count > 0); /* else it was empty */
// p被釋放, p的第一個字節值被設置為當前freeblock的值
*(block **)p = lastfree = pool->freeblock;
// freeblock被更新為指向p的首地址
pool->freeblock = (block *)p;
// 相當於往list中頭插入了一個節點
...
}
}
每釋放一個block,該blcok就會變成pool->freeblock的頭結點, 假設已經連續分配了5塊, 第1塊和第4塊被釋放,此時的內存圖示如下:
此時再一個block分配調用進來, 執行分配, 進入的邏輯是代碼-1
bp = pool->freeblock; // 指針指向空閑block起始位置
// 代碼-1
// 調整 pool->freeblock (假設A節點)指向鏈表下一個, 即bp首字節指向的下一個節點(假設B節點) , 如果此時!= NULL
// 表示 A節點可用, 直接返回
if ((pool->freeblock = *(block **)bp) != NULL) {
UNLOCK();
return (void *)bp;
}
pool中內存空間都用完了, 進入代碼-3
/* Pool is full, unlink from used pools. */ // 滿了, 需要從下一個pool獲取
next = pool->nextpool;
pool = pool->prevpool;
next->prevpool = pool;
pool->nextpool = next;
UNLOCK();
return (void *)bp;
arena: 多個pool聚合的結果, 可放置64個pool
#define ARENA_SIZE (256 << 10) /* 256KB */
一個完整的arena = arena_object + pool集合
/* Record keeping for arenas. */
struct arena_object {
/* The address of the arena, as returned by malloc. Note that 0
* will never be returned by a successful malloc, and is used
* here to mark an arena_object that doesn't correspond to an
* allocated arena.
*/
uintptr_t address;
/* Pool-aligned pointer to the next pool to be carved off. */
block* pool_address;
/* The number of available pools in the arena: free pools + never-
* allocated pools.
*/
uint nfreepools;
/* The total number of pools in the arena, whether or not available. */
uint ntotalpools;
/* Singly-linked list of available pools. */
struct pool_header* freepools;
/* Whenever this arena_object is not associated with an allocated
* arena, the nextarena member is used to link all unassociated
* arena_objects in the singly-linked `unused_arena_objects` list.
* The prevarena member is unused in this case.
*
* When this arena_object is associated with an allocated arena
* with at least one available pool, both members are used in the
* doubly-linked `usable_arenas` list, which is maintained in
* increasing order of `nfreepools` values.
*
* Else this arena_object is associated with an allocated arena
* all of whose pools are in use. `nextarena` and `prevarena`
* are both meaningless in this case.
*/
struct arena_object* nextarena;
struct arena_object* prevarena;
};
arena_object的作用
1. 與其他arena連接, 組成雙向鏈表
2. 維護arena中可用的pool, 單鏈表
uint maxnextoffset; /* largest valid nextoffset *//* The head of the singly-linked, NULL-terminated list of available
* arena_objects.
*/
// 單鏈表
static struct arena_object* unused_arena_objects = NULL;
/* The head of the doubly-linked, NULL-terminated at each end, list of
* arena_objects associated with arenas that have pools available.
*/
// 雙向鏈表
static struct arena_object* usable_arenas = NULL;
* Allocate a new arena. If we run out of memory, return NULL. Else
* allocate a new arena, and return the address of an arena_object
* describing the new arena. It's expected that the caller will set
* `usable_arenas` to the return value.
*/
static struct arena_object*
new_arena(void)
{
struct arena_object* arenaobj;
uint excess; /* number of bytes above pool alignment */
void *address;
static int debug_stats = -1;
if (debug_stats == -1) {
const char *opt = Py_GETENV("PYTHONMALLOCSTATS");
debug_stats = (opt != NULL && *opt != '\0');
}
if (debug_stats)
_PyObject_DebugMallocStats(stderr);
// 判斷是否需要擴充"未使用"的arena_object列表
if (unused_arena_objects == NULL) {
uint i;
uint numarenas;
size_t nbytes;
/* Double the number of arena objects on each allocation.
* Note that it's possible for `numarenas` to overflow.
*/
// 確定需要申請的個數, 首次初始化, 16, 之後每次翻倍
numarenas = maxarenas ? maxarenas << 1 : INITIAL_ARENA_OBJECTS;
if (numarenas <= maxarenas)
return NULL; /* overflow */
#if SIZEOF_SIZE_T <= SIZEOF_INT
if (numarenas > SIZE_MAX / sizeof(*arenas))
return NULL; /* overflow */
#endif
nbytes = numarenas * sizeof(*arenas);
// 申請內存
arenaobj = (struct arena_object *)PyMem_RawRealloc(arenas, nbytes);
if (arenaobj == NULL)
return NULL;
arenas = arenaobj;
/* We might need to fix pointers that were copied. However,
* new_arena only gets called when all the pages in the
* previous arenas are full. Thus, there are *no* pointers
* into the old array. Thus, we don't have to worry about
* invalid pointers. Just to be sure, some asserts:
*/
assert(usable_arenas == NULL);
assert(unused_arena_objects == NULL);
/* Put the new arenas on the unused_arena_objects list. */
for (i = maxarenas; i < numarenas; ++i) {
arenas[i].address = 0; /* mark as unassociated */
// 新申請的一律為0, 標識着這個arena處於"未使用"
arenas[i].nextarena = i < numarenas - 1 ?
&arenas[i+1] : NULL;
}
// 將其放入unused_arena_objects鏈表中
// unused_arena_objects 為新分配內存空間的開頭
/* Update globals. */
unused_arena_objects = &arenas[maxarenas];
maxarenas = numarenas;
}
/* Take the next available arena object off the head of the list. */
assert(unused_arena_objects != NULL);
// 從unused_arena_objects中, 獲取一個未使用的object
arenaobj = unused_arena_objects;
unused_arena_objects = arenaobj->nextarena; // 更新鏈表
assert(arenaobj->address == 0);
// 申請內存, 256KB, 內存地址賦值給arena的address. 這塊內存可用
address = _PyObject_Arena.alloc(_PyObject_Arena.ctx, ARENA_SIZE);
if (address == NULL) {
/* The allocation failed: return NULL after putting the
* arenaobj back.
*/
arenaobj->nextarena = unused_arena_objects;
unused_arena_objects = arenaobj;
return NULL;
}
arenaobj->address = (uintptr_t)address;
++narenas_currently_allocated;
++ntimes_arena_allocated;
if (narenas_currently_allocated > narenas_highwater)
narenas_highwater = narenas_currently_allocated;
arenaobj->freepools = NULL;
/* pool_address <- first pool-aligned address in the arena
nfreepools <- number of whole pools that fit after alignment */
arenaobj->pool_address = (block*)arenaobj->address;
arenaobj->nfreepools = MAX_POOLS_IN_ARENA;
// 將pool的起始地址調整為系統頁的邊界
// 申請到 256KB, 放棄了一些內存, 而將可使用的內存邊界pool_address調整到了與系統頁對齊
excess = (uint)(arenaobj->address & POOL_SIZE_MASK);
if (excess != 0) {
--arenaobj->nfreepools;
arenaobj->pool_address += POOL_SIZE - excess;
}
arenaobj->ntotalpools = arenaobj->nfreepools;
return arenaobj;
}
從arenas取一個arena進行初始化
new一個全新的arena
static void*
pymalloc_alloc(void *ctx, size_t nbytes)
{
// 剛開始沒有可用的arena
if (usable_arenas == NULL) {
// new一個, 作為雙向鏈表的表頭
usable_arenas = new_arena();
if (usable_arenas == NULL) {
UNLOCK();
goto redirect;
}
usable_arenas->nextarena =
usable_arenas->prevarena = NULL;
}
.......
// 從arena中獲取一個pool
pool = (poolp)usable_arenas->pool_address;
assert((block*)pool <= (block*)usable_arenas->address +
ARENA_SIZE - POOL_SIZE);
pool->arenaindex = usable_arenas - arenas;
assert(&arenas[pool->arenaindex] == usable_arenas);
pool->szidx = DUMMY_SIZE_IDX;
// 更新 pool_address 向下一個節點
usable_arenas->pool_address += POOL_SIZE;
// 可用節點數量-1
--usable_arenas->nfreepools;
}
從全新的arena中獲取一個pool
假設arena是舊的, 怎麼分配的pool, 跟pool分配block原理一樣,使用單鏈表記錄freepools
pool = usable_arenas->freepools;
if (pool != NULL) {
當arena中一整塊pool被釋放的時候
/* Free a memory block allocated by pymalloc_alloc().
Return 1 if it was freed.
Return 0 if the block was not allocated by pymalloc_alloc(). */
static int
pymalloc_free(void *ctx, void *p) {
struct arena_object* ao;
uint nf; /* ao->nfreepools */
/* Link the pool to freepools. This is a singly-linked
* list, and pool->prevpool isn't used there.
*/
ao = &arenas[pool->arenaindex];
pool->nextpool = ao->freepools;
ao->freepools = pool;
nf = ++ao->nfreepools;
}
在pool整塊被釋放的時候, 會將pool加入到arena->freepools作為單鏈表的表頭, 然後, 在從非全新arena中分配pool時, 優先從arena->freepools裏面取, 如果取不到, 再從arena內存塊裏面獲取
注: 上圖中nfreepools = n – 2
當arena1用完了,獲取arena1指向的下一個節點arena2
static void*
pymalloc_alloc(void *ctx, size_t nbytes)
{
// 當發現用完了最後一個pool!!!!!!!!!!!
// nfreepools = 0
if (usable_arenas->nfreepools == 0) {
assert(usable_arenas->nextarena == NULL ||
usable_arenas->nextarena->prevarena ==
usable_arenas);
/* Unlink the arena: it is completely allocated. */
// 找到下一個節點!
usable_arenas = usable_arenas->nextarena;
// 右下一個
if (usable_arenas != NULL) {
usable_arenas->prevarena = NULL; // 更新下一個節點的prevarens
assert(usable_arenas->address != 0);
}
// 沒有下一個, 此時 usable_arenas = NULL, 下次進行內存分配的時候, 就會從arenas數組中取一個
}
}
注意: 這裡有個邏輯, 就是每分配一個pool, 就檢查是不是用到了最後一個, 如果是, 需要變更usable_arenas到下一個可用的節點, 如果沒有可用的, 那麼下次進行內存分配的時候, 會判定從arenas數組中取一個
內存分配和回收最小單位是block, 當一個block被回收的時候, 可能觸發pool被回收, pool被回收, 將會觸發arena的回收機制
關注點:如何尋找到一塊可用的nbytes的blcok內存?
pool = usedpools[size + size]
if pool:
pool 沒滿,取一個blcok返回
pool 滿了,從下一個pool取一個blcok返回
else:
獲取arena, 从里面初始化一個pool, 拿到第一個blcok返回
進行內存分配和銷毀, 所有操作都是在pool上進行的
問題: pool中所有block的size一樣, 但是在arena中, 每個pool的size都可能不一樣, 那麼最終這些pool是怎麼維護的? 怎麼根據大小找到需要的block所在的pool? =>
usedpools
Python內部維護的usedpools數組是一個非常巧妙的實現,維護着所有的處於used狀態的pool,當申請內存時,python就會通過usedpools尋找到一個可用的pool(處於used狀態),從中分配一個block。因此我們想,一定有一個usedpools相關聯的機制,完成從申請的內存的大小到size class index之間的轉換,否則python就無法找到最合適的pool了。這種機制和usedpools的結構有着密切的關係,我們看一下它的結構
usedpools數組: 維護着所有處於used狀態的pool, 當申請內存的時候, 會通過usedpools尋找到一塊可用的(處於used狀態的)pool, 從中分配一個block。
//obmalloc.c
typedef uint8_t block;
#define PTA(x) ((poolp )((uint8_t *)&(usedpools[2*(x)]) - 2*sizeof(block *)))
#define PT(x) PTA(x), PTA(x)
//在我當前的機器就是512/8=64個,對應的size class index就是從0到63
#define NB_SMALL_SIZE_CLASSES (SMALL_REQUEST_THRESHOLD / ALIGNMENT)
static poolp usedpools[2 * ((NB_SMALL_SIZE_CLASSES + 7) / 8) * 8] = {
PT(0), PT(1), PT(2), PT(3), PT(4), PT(5), PT(6), PT(7)
#if NB_SMALL_SIZE_CLASSES > 8
, PT(8), PT(9), PT(10), PT(11), PT(12), PT(13), PT(14), PT(15)
#if NB_SMALL_SIZE_CLASSES > 16
, PT(16), PT(17), PT(18), PT(19), PT(20), PT(21), PT(22), PT(23)
#if NB_SMALL_SIZE_CLASSES > 24
, PT(24), PT(25), PT(26), PT(27), PT(28), PT(29), PT(30), PT(31)
#if NB_SMALL_SIZE_CLASSES > 32
, PT(32), PT(33), PT(34), PT(35), PT(36), PT(37), PT(38), PT(39)
#if NB_SMALL_SIZE_CLASSES > 40
, PT(40), PT(41), PT(42), PT(43), PT(44), PT(45), PT(46), PT(47)
#if NB_SMALL_SIZE_CLASSES > 48
, PT(48), PT(49), PT(50), PT(51), PT(52), PT(53), PT(54), PT(55)
#if NB_SMALL_SIZE_CLASSES > 56
, PT(56), PT(57), PT(58), PT(59), PT(60), PT(61), PT(62), PT(63)
#if NB_SMALL_SIZE_CLASSES > 64
#error "NB_SMALL_SIZE_CLASSES should be less than 64"
#endif /* NB_SMALL_SIZE_CLASSES > 64 */
#endif /* NB_SMALL_SIZE_CLASSES > 56 */
#endif /* NB_SMALL_SIZE_CLASSES > 48 */
#endif /* NB_SMALL_SIZE_CLASSES > 40 */
#endif /* NB_SMALL_SIZE_CLASSES > 32 */
#endif /* NB_SMALL_SIZE_CLASSES > 24 */
#endif /* NB_SMALL_SIZE_CLASSES > 16 */
#endif /* NB_SMALL_SIZE_CLASSES > 8 */
};
如果正在申請28字節, python首先會獲取(size class index) size = (uint )(nbytes - 1) >> ALIGNMENT_SHIFT 顯然這裏size=3, 那麼在usedpools中,尋找第3+3=6個元素,發現usedpools[6]的值是指向usedpools[4]的地址
//obmalloc.c
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref; /* 當然pool裏面的block數量 */
block *freeblock; /* 一個鏈表,指向下一個可用的block */
struct pool_header *nextpool; /* 指向下一個pool */
struct pool_header *prevpool; /* 指向上一個pool "" */
uint arenaindex; /* 在area裏面的索引 */
uint szidx; /* block的大小(固定值?後面說) */
uint nextoffset; /* 下一個可用block的內存偏移量 */
uint maxnextoffset; /* 最後一個block距離開始位置的距離 */
};
顯然是從usedpools[6]
(即usedpools+4)開始向後偏移8個字節(一個ref的大小加上一個freeblock的大小)后的內存,正好是usedpools[6]的地址(即usedpools+6),這是python內部的trick
當我們要申請一個size class為32字節的pool,想要將其放入這個usedpools中時,要怎麼做呢?從上面的描述我們知道,只需要進行usedpools[i+i] -> nextpool = pool即可,其中i為size class index,對應於32字節,這個i為3.當下次需要訪問size class 為32字節(size class index為3)的pool時,只需要簡單地訪問usedpools[3+3]就可以得到了。python正是使用這個usedpools快速地從眾多的pool中快速地尋找到一個最適合當前內存需求的pool,從中分配一塊block。
//obmalloc.c
static int
pymalloc_alloc(void *ctx, void **ptr_p, size_t nbytes)
{
block *bp;
poolp pool;
poolp next;
uint size;
...
LOCK();
//獲得size class index
size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT;
//直接通過usedpools[size+size],這裏的size不就是我們上面說的i嗎?
pool = usedpools[size + size];
//如果usedpools中有可用的pool
if (pool != pool->nextpool) {
... //有可用pool
}
... //無可用pool,嘗試獲取empty狀態的pool
}
參考:
pyhton源碼閱讀-內存管理機制
python源碼解析第17章-python內存管理與垃圾回收
後期查缺補漏需要看的文章
Memory management by Zpoint
Memory management in Python
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準
※台中搬家公司費用怎麼算?