終於到了今天了,終於要講RocketMQ最牛X的功能了,那就是事務消息。為什麼事務消息被吹的比較熱呢?近幾年微服務大行其道,整個系統被切成了多個服務,每個服務掌管着一個數據庫。那麼多個數據庫之間的數據一致性就成了問題,雖然有像XA這種強一致性事務的支持,但是這種強一致性在互聯網的應用中並不適合,人們還是更傾向於使用最終一致性的解決方案,在最終一致性的解決方案中,使用MQ保證各個系統之間的數據一致性又是首選。
RocketMQ為我們提供了事務消息的功能,它使得我們投放消息和其他的一些操作保持一個整體的原子性。比如:向數據庫中插入數據,再向MQ中投放消息,把這兩個動作作為一個原子性的操作。貌似其他的MQ是沒有這種功能的。
但是,縱觀全網,講RocketMQ事務消息的博文中,幾乎沒有結合數據庫的,都是直接投放消息,然後講解事務消息的幾個狀態,雖然講的也沒毛病,但是和項目中事務最終一致性的落地方案還相距甚遠。包括我自己在內,在項目中,服務化以後,用MQ保證事務的最終一致性,在網上一搜,根本沒有落地的方案,都是侃侃而談。於是,我寫下這篇博文,結合數據庫,來談一談RocketMQ的事務消息到底怎麼用。
基礎概念
要使用RocketMQ的事務消息,要實現一個TransactionListener的接口,這個接口中有兩個方法,如下:
/**
* When send transactional prepare(half) message succeed, this method will be invoked to execute local transaction.
*
* @param msg Half(prepare) message
* @param arg Custom business parameter
* @return Transaction state
*/
LocalTransactionState executeLocalTransaction(final Message msg, final Object arg);
/**
* When no response to prepare(half) message. broker will send check message to check the transaction status, and this
* method will be invoked to get local transaction status.
*
* @param msg Check message
* @return Transaction state
*/
LocalTransactionState checkLocalTransaction(final MessageExt msg);
RocketMQ的事務消息是基於兩階段提交實現的,也就是說消息有兩個狀態,prepared和commited。當消息執行完send方法后,進入的prepared狀態,進入prepared狀態以後,就要執行executeLocalTransaction方法,這個方法的返回值有3個,也決定着這個消息的命運,
- COMMIT_MESSAGE:提交消息,這個消息由prepared狀態進入到commited狀態,消費者可以消費這個消息;
- ROLLBACK_MESSAGE:回滾,這個消息將被刪除,消費者不能消費這個消息;
- UNKNOW:未知,這個狀態有點意思,如果返回這個狀態,這個消息既不提交,也不回滾,還是保持prepared狀態,而最終決定這個消息命運的,是checkLocalTransaction這個方法。
當executeLocalTransaction方法返回UNKNOW以後,RocketMQ會每隔一段時間調用一次checkLocalTransaction,這個方法的返回值決定着這個消息的最終歸宿。那麼checkLocalTransaction這個方法多長時間調用一次呢?我們在BrokerConfig類中可以找到,
/**
* Transaction message check interval.
*/
@ImportantField
private long transactionCheckInterval = 60 * 1000;
這個值是在brokder.conf中配置的,默認值是60*1000,也就是1分鐘。那麼會檢查多少次呢?如果每次都返回UNKNOW,也不能無休止的檢查吧,
/**
* The maximum number of times the message was checked, if exceed this value, this message will be discarded.
*/
@ImportantField
private int transactionCheckMax = 5;
這個是檢查的最大次數,超過這個次數,如果還返回UNKNOW,這個消息將被刪除。
事務消息中,TransactionListener這個最核心的概念介紹完后,我們看看代碼如何寫吧。
落地案例
我們在數據庫中有一張表,具體如下:
CREATE TABLE `s_term` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`term_year` year(4) NOT NULL ,
`type` int(1) NOT NULL DEFAULT '1' ,
PRIMARY KEY (`id`)
)
字段的具體含義大家不用管,一會我們將向這張表中插入一條數據,並且向MQ中投放消息,這兩個動作是一個原子性的操作,要麼全成功,要麼全失敗。
我們先來看看事務消息的客戶端的配置,如下:
@Bean(name = "transactionProducer",initMethod = "start",destroyMethod = "shutdown")
public TransactionMQProducer transactionProducer() {
TransactionMQProducer producer = new
TransactionMQProducer("TransactionMQProducer");
producer.setNamesrvAddr("192.168.73.130:9876;192.168.73.131:9876;192.168.73.132:9876;");
producer.setTransactionListener(transactionListener());
return producer;
}
@Bean
public TransactionListener transactionListener() {
return new TransactionListenerImpl();
}
我們使用TransactionMQProducer生命生產者的客戶端,並且生產者組的名字叫做TransactionMQProducer,後面NameServer的地址沒有變化。最後就是設置了一個TransactionListener監聽器,這個監聽器的實現我們也定義了一個Bean,返回的是我們自定義的TransactionListenerImpl,我們看看裡邊怎麼寫的吧。
public class TransactionListenerImpl implements TransactionListener {
@Autowired
private TermMapper termMapper;
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
Integer termId = (Integer)arg;
Term term = termMapper.selectById(termId);
System.out.println("executeLocalTransaction termId="+termId+" term:"+term);
if (term != null) return COMMIT_MESSAGE;
return LocalTransactionState.UNKNOW;
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
String termId = msg.getKeys();
Term term = termMapper.selectById(Integer.parseInt(termId));
System.out.println("checkLocalTransaction termId="+termId+" term:"+term);
if (term != null) {
System.out.println("checkLocalTransaction:COMMIT_MESSAGE");
return COMMIT_MESSAGE;
}
System.out.println("checkLocalTransaction:ROLLBACK_MESSAGE");
return ROLLBACK_MESSAGE;
}
}
在這個類中,我們要實現executeLocalTransaction和checkLocalTransaction兩個方法,其中executeLocalTransaction是在執行完send方法后立刻執行的,裡邊我們根據term表的id去查詢,如果能夠查詢出結果,就commit,消費端可以消費這個消息,如果查詢不到,就返回一個UNKNOW,說明過一會會調用checkLocalTransaction再次檢查。在checkLocalTransaction方法中,我們同樣用termId去查詢,這次如果再查詢不到就直接回滾了。
好了,事務消息中最重要的兩個方法都已經實現了,我們再來看看service怎麼寫吧,
@Autowired
private TermMapper termMapper;
@Autowired
@Qualifier("transactionProducer")
private TransactionMQProducer producer;
@Transactional(rollbackFor = Exception.class)
public void sendTransactionMQ() throws Exception {
Term term = new Term();
term.setTermYear(2020);
term.setType(1);
int insert = termMapper.insert(term);
Message message = new Message();
message.setTopic("cluster-topic");
message.setKeys(term.getId()+"");
message.setBody(new String("this is transaction mq "+new Date()).getBytes());
TransactionSendResult sendResult = producer
.sendMessageInTransaction(message, term.getId());
System.out.println("sendResult:"+sendResult.getLocalTransactionState()
+" 時間:"+new Date());
}
- 在sendTransactionMQ方法上,我們使用了@Transactional註解,那麼在這個方法中,發生任何的異常,數據庫事務都會回滾;
- 然後,我們創建Term對象,向數據庫中插入Term;
- 構建Mesaage的信息,將termId作為message的key;
- 使用sendMessageInTransaction發送消息,傳入message和termId,這兩個參數和executeLocalTransaction方法的入參是對應的。
最後,我們在test方法中,調用sendTransactionMQ方法,如下:
@Test
public void sendTransactionMQ() throws InterruptedException {
try {
transactionService.sendTransactionMQ();
} catch (Exception e) {
e.printStackTrace();
}
Thread.sleep(600000);
}
整個生產端的代碼就是這些了,消費端的代碼沒有什麼變化,就不給大家貼出來了。接下來,我們把消費端的應用啟動起來,消費端的應用最好不要包含生產端的代碼,因為TransactionListener實例化以後,就會進行監聽,而我們在消費者端是不希望看到TransactionListener中的日誌的。
我們運行一下生產端的代碼,看看是什麼情況,日誌如下:
executeLocalTransaction termId=15 term:com.example.rocketmqdemo.entity.Term@4a3509b0
sendResult:COMMIT_MESSAGE 時間:Wed Jun 17 08:56:49 CST 2020
- 我們看到,先執行的是executeLocalTransaction這個方法,termId打印出來了,發送的結果也出來了,是COMMIT_MESSAGE,那麼消費端是可以消費這個消息的;
- 注意一下兩個日誌的順序,先執行的executeLocalTransaction,說明在執行sendMessageInTransaction時,就會調用監聽器中的executeLocalTransaction,它的返回值決定着這個消息是否真正的投放到隊列中;
再看看消費端的日誌,
msgs.size():1
this is transaction mq Wed Jun 17 08:56:49 CST 2020
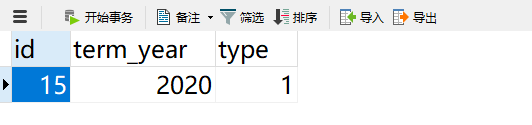
消息被正常消費,沒有問題。那麼數據庫中有沒有termId=15的數據呢?我們看看吧,
數據是有的,插入數據也是成功的。
這樣使用就真的正確的嗎?我們改一下代碼看看,在service方法中拋個異常,讓數據庫的事務回滾,看看是什麼效果。改動代碼如下:
@Transactional(rollbackFor = Exception.class)
public void sendTransactionMQ() throws Exception {
……
throw new Exception("數據庫事務異常");
}
拋出異常后,數據庫的事務會回滾,那麼MQ呢?我們再發送一個消息看看,
生產端的日誌如下:
executeLocalTransaction termId=16 term:com.example.rocketmqdemo.entity.Term@5d6b5d3d
sendResult:COMMIT_MESSAGE 時間:Wed Jun 17 09:07:15 CST 2020
java.lang.Exception: 數據庫事務異常
- 從日誌中,我們可以看到,消息是投放成功的,termId=16,事務的返回狀態是COMMIT_MESSAGE;
- 最後拋出了我們定義的異常,那麼數據庫中應該是不存在這條消息的啊;
我們先看看數據庫吧,
數據庫中並沒有termId=16的數據,那麼數據庫的事務是回滾了,而消息是投放成功的,並沒有保持原子性啊。那麼為什麼在執行executeLocalTransaction方法時,能夠查詢到termId=16的數據呢?還記得MySQL的事務隔離級別嗎?忘了的趕快複習一下吧。在事務提交前,我們是可以查詢到termId=16的數據的,所以消息提交了,看看消費端的情況,
msgs.size():1
this is transaction mq Wed Jun 17 09:07:15 CST 2020
消息也正常消費了,這明顯不符合我們的要求,我們如果在微服務之間使用這種方式保證數據的最終一致性,肯定會有大麻煩的。那我們該怎麼使用s呢?我們可以在executeLocalTransaction方法中,固定返回UNKNOW,數據插入數據庫成功也好,失敗也罷,我們都返回UNKNOW。那麼這個消息是否投放到隊列中,就由checkLocalTransaction決定了。checkLocalTransaction肯定在sendTransactionMQ后執行,而且和sendTransactionMQ不在同一事務中。我們改一下程序吧,
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
return LocalTransactionState.UNKNOW;
}
其他的地方不用改,我們再發送一下消息,
sendResult:UNKNOW 時間:Wed Jun 17 09:56:59 CST 2020
java.lang.Exception: 數據庫事務異常
checkLocalTransaction termId=18 term:null
checkLocalTransaction:ROLLBACK_MESSAGE
- 事務消息發送的結果是UNKNOW,然後拋出異常,事務回滾;
- checkLocalTransaction方法,查詢termId=18的數據,為null,消息再回滾;
又看了一下消費端,沒有日誌。數據庫中也沒有termId=18的數據,這才符合我們的預期,數據庫插入不成功,消息投放不成功。我們再把拋出異常的代碼註釋掉,看看能不能都成功。
@Transactional(rollbackFor = Exception.class)
public void sendTransactionMQ() throws Exception {
……
//throw new Exception("數據庫事務異常");
}
再執行一下發送端程序,日誌如下:
sendResult:UNKNOW 時間:Wed Jun 17 10:02:57 CST 2020
checkLocalTransaction termId=19 term:com.example.rocketmqdemo.entity.Term@3b643475
checkLocalTransaction:COMMIT_MESSAGE
- 發送結果返回UNKNOW;
- checkLocalTransaction方法查詢termId=19的數據,能夠查到;
- 返回COMMIT_MESSAGE,消息提交到隊列中;
先看看數據庫中的數據吧,
termId=19的數據入庫成功了,再看看消費端的日誌,
msgs.size():1
this is transaction mq Wed Jun 17 10:02:56 CST 2020
消費成功,這才符合我們的預期。數據插入數據庫成功,消息投放隊列成功,消費消息成功。
總結
事務消息最重要的就是TransactionListener接口的實現,我們要理解executeLocalTransaction和checkLocalTransaction這兩個方法是干什麼用的,以及它們的執行時間。再一個就是和數據庫事務的結合,數據庫事務的隔離級別大家要知道。把上面這幾點掌握了,就可以靈活的使用RocketMQ的事務消息了。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化