分享嘉賓:孫宇,百度NLP主任研發架構師、語義計算技術負責人。
本文根據作者在“2019自然語言處理前沿論壇”語義理解主題的特邀報告整理而成。
本報告提綱分為以下3個部分:
· 語義表示
· 語義匹配
· 未來重點工作
語義計算方向在百度NLP成立之初就開始研究,研究如何利用計算機對人類語言的語義進行表示、分析和計算,使機器具備語義理解能力。相關技術包含語義表示、語義匹配、語義分析、多模態計算等。
本文主要介紹百度在語義表示方向的技術發展和最新的研究成果艾尼(ERNIE),同時也會介紹工業應用價值很大、百度積累多年的語義匹配SimNet的相關內容,最後再談談未來的重點工作。
一、語義表示
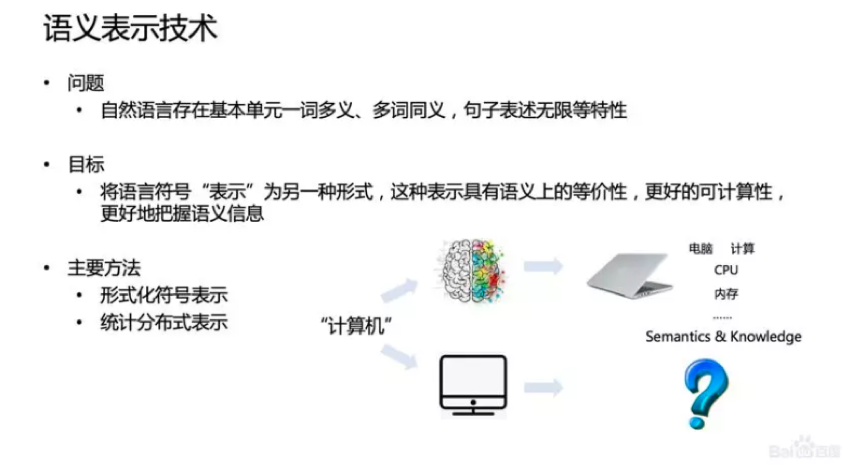
計算機理解語言是一個具有很大挑戰的問題。人類在理解語言的過程中,除了語言符號本身的識別,還包含符號背後的語義和知識。舉個例子,當人看到“計算機”這個符號時,腦子里能迅速浮現出計算機的畫面以及和計算機相關的知識和概念,但是這對於計算機就比較困難。所以如何讓計算機能夠表示語言是研究的重點,讓其既能夠蘊含語義信息又可以計算。
當前主要有兩類方法,一是基於形式化規則的方法,如通過構建語義關係網絡來描述語義的信息;二是基於統計的方法,包括主題模型、Word Embedding等技術。
1、百度早期語義表示技術:基於檢索的表示方法
2007年百度便開始語義表示研究,最開始的思路是利用搜索引擎來完成。通過搜索引擎把要表示的句子或者詞語檢索出來,再根據檢索的結果通過Term的分析以及網頁的分析,把相關的詞、信息抽取出來,做成語言符號的表示。但是這個表示實際上停留在原始詞彙空間,表示的空間大小依然是詞表的維度,只是相對於One-Hot的表示來說更精細,這個方法是基於1954年Harris提出來的“上下文相似的詞,其語義也相似”的假設。
2、百度早期語義表示技術:Topic Model
此後,百度又研究了Topic Model的語義表示技術,這種方法的核心思路是把文檔詞彙空間降維,將文檔映射到淺層主題的分佈上,而這種主題空間要比詞的分佈空間更小一些。通過降維的方法,可以得到每個詞到主題的映射,通過這種主題的方法做語義的表示。
當時百度主要解決的問題是怎樣做這種新文檔的表示,難點是超大規模語料訓練、Online EM、MPI并行化。此外,百度還將自研的主題模型以及一些主流的主題模型整理為工業應用工具,對外開源了百度NLP主題模型工具包FAMILIA。
3、基於DNN的語義表示技術:Word Embedding
深度學習技術興起,基於Word Embedding的表示佔了主流,此類技術在各種NLP任務中也表現出色。從NNLM到現在BERT的技術,取得了很多進展。2013年的Word2vec成為NLP標配性的初始化向量,2018年有了上下文相關的詞向量ELMo等。
從2013年到2016年,百度也大力投入到Word Embedding的研究,主要研究工作是在工業界如何用大規模分佈式從海量數據中計算詞向量。比如,怎麼才能高效訓練規模為1T的語料?如何構建大規模分佈式文本計算?此外,算法上我們也有一些研究,比如,如何在一百萬超大規模的詞表裡完成Softmax分類?我們通過一些策略和技術,做成啟髮式Hierarchical Softmax的方法,從而有效地提升分類的效率。2016年,百度把訓練的1T的網頁數據和100萬詞表規模的詞向量對業界進行了開放。
4、多特徵融合的表示模型
BERT的核心思路還是大力出奇迹,它利用了大規模的無監督數據,同時藉助Transformer這種高性能的Encoder的能力,在MASK建模任務上做了一些優化,導致這個效果能夠在各個任務上顯著提升。
百度實際在2017年進行了這方面的探索,當時是研究基於對話的口語理解問題,這個問題的核心是做意圖的分類和槽位的標註。難點在於口語理解的問題標註語料非常少。當時想能不能利用海量的搜索語料做Pre-Training,把這個Model作為初始化模型用到下游的SLU任務里。
我們採用20億搜索的Query,通過LSTM模型做單向Language Model的預訓。我們發現在SLU任務上,在各個垂類上樣本數的增加非常顯著,從10個樣本到2000個樣本。但遺憾的是,當時研究的是一個超小規模數據上效果,即2000的數據,在2萬甚至是20萬的數據上的表現並沒有研究,同時在其他應用的通用性上的研究也不夠充分。
5、知識增強的語義表示模型
BERT提出后,我們發現一個問題,它學習的還是基礎語言單元的Language Model,並沒有充分利用先驗語言知識,這個問題在中文很明顯,它的策略是MASK字,沒有MASK知識或者是短語。在用Transformer預測每個字的時候,很容易根據詞包含字的搭配信息預測出來。比如預測“雪”字,實際上不需要用Global的信息去預測,可以通過“冰”字預測。基於這個假設,我們做了一個簡單的改進,把它做成一個MASK詞和實體的方法,學習這個詞或者實體在句子裏面Global的信號。
基於上述思想我們發布了基於知識增強的語義表示ERNIE(1.0)。
我們在中文上做了ERNIE(1.0)實驗,找了五個典型的中文公開數據集做對比。不管是詞法分析NER、推理、自動問答、情感分析、相似度計算,ERNIE(1.0)都能夠顯著提升效果。
英文上驗證了推廣性,實驗表明ERNIE(1.0)在GLUE和SQuAd1.1上提升也是非常明顯的。為了驗證假設,我們做了一些定性的分析,找了完形填空的數據集,並通過ERNIE和BERT去預測,效果如上圖。
我們對比了ERNIE、BERT、CoVe、GPT、ELMo模型,結果如上圖所示。ELMo是早期做上下文相關表示模型的工作,但它沒有用Transformer,用的是LSTM,通過單向語言模型學習。百度的ERNIE與BERT、GPT一樣,都是做網絡上的Transformer,但是ERNIE在建模Task的時候做了一些改進,取得了很不錯的效果。
在應用上,ERNIE在百度發布的面向工業應用的中文NLP開源工具集進行了驗證,包括ERNIE與BERT在詞法分析、情感分類這些百度內部的任務上做了對比分析。同時也有一些產品已經落地,在廣告相關性的計算、推薦廣告的觸發、新聞推薦上都有實際應用。目前模型已經開源(
7月31日,百度艾尼(ERNIE) 再升級,發布了持續學習語義理解框架ERNIE 2.0,同時藉助飛槳(PaddlePaddle)多機多卡高效訓練優勢發布了基於此框架的ERNIE 2.0 預訓練模型。該模型在共計16个中英文任務上超越了BERT 和XLNet,取得了SOTA 效果。
二、語義匹配
1、文本語義匹配及挑戰
語義匹配在工業界具有非常大的技術價值,它是一個很基礎的問題,很多產品、應用場景都會用到它。很多問題也可以抽象為語義匹配問題,比如,搜索解決的是Query和Document相關性的問題,推薦解決的是User和Item關聯度、興趣匹配度的問題,檢索式問答解決的是問題與答案匹配度,以及檢索對話Query和Response的匹配問題。由於語言比較複雜,匹配靠傳統的方法是比較難的。
百度搜索在匹配相似度計算方面做了較多工作,包括挖掘同義詞、詞級別泛化、語義緊密度、對齊資源挖掘、共線關聯計算等。
2、神經網絡語義匹配模型:SimNet
2013年百度提出SimNet技術,用於解決語義匹配的問題。這個技術基於DNN框架,沿襲Word Embedding的輸入,基於End-to-End的訓練做表示和匹配,並結合Pairwise訓練。當時,微軟也提出了DSSM,中科院、CMU等研究機構也做了很多語義匹配研究工作。
這幾年,百度整體上從語義匹配的框架上做了升級,抽象了三個層次,改進了基礎算法,包括擴展針對不同場景的模型,比如字和語義的匹配模型;在不同的應用場景,針對問題網頁和問題答案的匹配情況分別做了針對性地優化,集成到了匹配框架里。
匹配算法主要有兩種範式,一種是基於表示的匹配,首先把自然語言表示成向量,然後再進行相似度計算,這方面也有一些改進,主要是做一些Attention;另一種新匹配範式Interaction-based Model,強調更細的匹配,即一個句子的表示不再是一個向量,而是原來的Term,並把原來的位置信息保留,最後以Attention的方式表示,讓匹配更加充分和精細。
關於SimNet技術前瞻性工作,2019年百度在IJCAI上發表了一篇論文“RLTM:An Efficient Neural IR Framework for Long Documents”,其中長文本匹配有一個很大的挑戰,就是讓Document直接做表示,如果文本太長,很多信息會丟失,計算效率也非常低。但如果我們先做一個粗匹配,選擇好相關的句子以後再做精細化的匹配,效果就比較不錯。
3、SimNet的應用
SimNet技術在百度應用非常廣泛,包括搜索、資訊推薦、廣告、對話平台都在使用。
搜索是百度非常重要的產品,搜索有兩個核心功能,下圖的左側上方是搜索的精準問答,通過問答技術把精準答案直接呈現出來;下方是自然排序,主要採用LTR框架和相關性、權威性、時效性等Features。
SimNet在百度搜索的發展可以分為三個時期。萌芽期,上線了BOW Model,這是業界第一次在搜索引擎上線DNN模型;發展期,做了CNN、RNN,並把知識融合進RNN,在語義相關性計算中,除了標題很多其他文本域在相關性建模中也很重要,所以,我們還做多文本域融合匹配的Model;拓展期,除了相關性,在權威性、點擊模型和搜索問答上都有推廣和使用。
在搜索中,SimNet是用超大規模用戶反饋數據訓練。那麼如何依靠海量數據來提升效果?頻次如何選?我們發現模型應用效果並不是靜態的,而是動態變化的,特別是搜索反饋的數據,隨着時間的推移,網民在搜索的時候,Term的分佈、主題的分佈會發生變化,所以數據的時效性影響還是非常大的。
除了模型上的融合,我們把Bigram知識也融入了進去。儘管RNN已經很厲害了,但加入知識、模型還是會有很大地提升。
4、新模型:SimNet-QC-MM
另外,我們還做了Query和網頁正文的建模,由於Query中每個詞都有一定的用戶意圖,所以在模型建模時,會考慮Query中每個詞被Title和正文覆蓋的情況,並基於Matching Matrix匹配方法計算。此外,搜索架構也做了配合改進,搜索也上線了基於GPU和CPU的異構計算架構。
上圖是一個案例,“羋殊出嫁途中遇到危險”,我們後來做了一些分析,發現“危險”和“投毒”有很強的語義關聯,就把這個結果排了上去。
5、語義模型壓縮技術
在模型裁減壓縮上,我們也做了很多工作,包括量化的壓縮和哈希技術的壓縮。整個語義的模型基本上已經從依靠一個Embedding 32bits來存,到現在達到Embedding一維僅需4bits,節省線上DNN匹配模型87.5%的內存消耗。這項技術,除了搜索的使用,移動端的使用也有非常大的價值。
SimNet技術除了百度搜索,包括Q&A,Query和Answer的匹配等方面都有一些嘗試。
三、未來重點工作
接下來我們會在通用語義表示方面進一步研究與突破,除了如何充分地利用先驗知識,利用一些弱監督信號外,模型方面也會進一步探索創新。技術拓展上,跨語言、多語言表示,面向生成、匹配等任務的表示,面向醫療、法律等領域的表示,多模態表示等都是我們的一些重點方向。
RLTM論文地址:
至此,“2019自然語言處理前沿論壇”語義計算主題《百度語義計算技術及其應用》的分享結束。如果大家想更深入地了解百度持續學習語義理解框架艾尼(ERNIE),歡迎加入ERNIE官方交流群(QQ群號:760439550)。
——————-
划重點!!!
掃碼關注百度NLP官方公眾號,獲取百度NLP技術的第一手資訊!
加入ERNIE官方技術交流群(760439550),百度工程師實時為您答疑解惑!
立即前往GitHub( )為ERNIE點亮Star,馬上學習和使用起來吧!
最強預告!!!
11月23日,艾尼(ERNIE)的巡迴沙龍將在上海加場,乾貨滿滿的現場,行業A級的導師,還有一群志同道合的小夥伴,還在等什麼?感興趣的開發者們趕緊掃描下方“二維碼”或點擊“鏈接”報名參加吧!
報名鏈接:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!