環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
近日,豐田和克萊門森大學國際汽車研究中心合作,為下一代的司機創造出了一個全新的概念電動汽車——uBox。

豐田曾經發起了一個名為“Deep Orange”的合作專案,uBox正是項目的結晶。
據瞭解,豐田和克萊門森大學在過去的兩年裡一直致力於這款概念車的開發工作。uBox概念車使用了方形的設計、自動式車門,並用複合碳纖維和鋁合金支撐著一塊弧形玻璃。其全新設計的套件裝備均極大程度提升了整車的舒適性與功能性。
豐田表示汽車的內部配置可以根據司機的品味進行配置。座位安裝在導軌上,並且通風口、內飾、車內顏色方案都可以定制,可以下載新設計然後用3D印表機重新構建。它還擁有一個110伏的插座,可以為筆記型電腦等眾多設備充電。
至於動力系統方面,除了豐田將在uBox上搭載一台電動機引擎之外,目前並沒有獲得更多這方面的消息。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?

全球電動車用鋰電池領導廠商日本松下(Panasonic)宣布,將投資500億日圓(約新台幣136億元、人民幣27億元)在中國成立以電動車鋰電池為主要產品的電池工廠,預計在2017年投入生產。這是繼松下與特斯拉(Tesla)合作在美國內華達州成立Gigafactory之後,另一大車用鋰電池生產計劃,將鞏固松下在美、中兩大市場的發展基礎。
中國電動車市場後市看好,松下積極搶進
中國政府將電動車列為減輕空污方案的方案之一,在政策與產業面上皆有積極作為,包括提供民眾每輛車最高5.5萬元人民幣的購車補貼,以及比亞迪(BYD)、北企集團等業者發展電動車的獎勵措施等。根據《日經》新聞中文網的報導,中國純電動車(EV)與插電式油電混和車(PHEV)的市場規模目前雖然不及10萬輛,但在未來十年內將成長7.5倍到約65萬輛之譜;而根據中國汽車工業協會的統計,今年1~11月之間,EV與PHEV的產量比去年同期增加了4.4倍,來到29萬輛。且不僅中國大陸本土廠商,日產、福斯汽車等也已展開中國市場的布局。
中國EV與PHEV的需求爆發直接帶動車用鋰電池的成長,也因而促成松下宣布到中國設廠的決定。松下將與中國當地企業合作,投資500億日圓在遼寧省大連市建造鋰電池工廠,主要產品將供給EV與PHEV,預計年產量可供20萬輛電動車使用,以目前技術換算,電池容量年產量約為20GWh。
在松下之前,南韓LG Chem已於十月宣布將在江蘇省南京市建立車用鋰電池工廠,且已在中國展開推銷業務。
松下戰略:搶入美、中兩大市場
松下已是全球最大的車用鋰電池製造商,市佔率高達45.7%;第二名為日產NEC,佔17.3%,先前宣布在中國設廠的LG Chem的市占率10.5%則為全球第三。而在本次設立車用鋰電池廠之前,松下在中國大陸已有個人電腦的電池工廠。
松下於2014年宣布與Tesla合作在美國內華達州建設一座超大型鋰電池工廠Gigafactory,初期預估投資額約1,500億日圓。但隨著今年Tesla發表Powerwall/Powerpack並奪下大筆訂單、加上全球電動車需求暴漲的預期,Gigafactory的投資額最後估計將來到50億美元,且投產時程也從原先的2017提前到2016年。到了2020年整體廠房完成並產能全開時,Gigafactory總產能估計將達50GWh,可供50萬輛EV/PHEV使用;不過,該廠也有部分產能將用於生產Powerwall與Powerpack產品。
以日本企業近年對中國的投資額來看,500~600億日圓屬於較罕見的大手筆投資,同時顯示松下積極開發美、中兩大電動車市場的野心。目前美國是全球第一大電動車需求市場,中國、日本分列第二與第三。到了2025年,美國市場需求預計將來到95萬輛以上、中國也會成長到65萬輛左右。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※別再煩惱如何寫文案,掌握八大原則!
大眾汽車集團管理董事會成員、大眾汽車集團(中國)總裁兼CEO海茲曼接受媒體專訪時表示,大眾將以年均40億歐元(約287億人民幣)以上的投資規模加大對中國市場投資,資金主要來自大眾在中國合資企業;
部署新能源戰略達成百公里油耗5L目標
新能源車相關的投資將是大眾未來投資重點,對此,海茲曼表示,這一部署也是為了達成2020年前要達到產品平均油耗5L的目標。不僅是新能源,對於傳統能源乘用車大眾也在不斷的引入最新技術,將節油降耗的潛力進一步挖掘。
大眾汽車集團在華的新能源車戰略是一個階段性的戰略,分為三個階段。海茲曼稱,目前大眾正處於第一個階段,就是通過進口的方式來為中國車主提供插電 式混合動力車型以及純電動車,這包括保時捷Panamera插電式混合動力車型、奧迪A3插電式混合動力、GolfGTE、e-Golf以及e-up!等。
第二階段,從2016年開始,大眾將會尋求插電式混合動力車型在中國的本土生產。在插電式混合動力車型上實現國產的首先是奧迪A6,接下來就是大眾品牌一款C Model,與奧迪A6同級別的一款插電式混合動力車型。
第三階段,大眾計畫實現純電動新能源車在中國本土的生產,2020年之前大眾將實現第一款基於MQB平臺的純電動車型的國產。海茲曼強調,大眾戰略實現全面的國產化,包括零部件的國產化以及研發的當地語系化。
海茲曼表示,大眾會在2-3年期間內不斷的實現插電式混合動力車型的國產。在此之後的第三階段,大眾會啟動純電動車型在中國本土的生產。第三階段實 現國產化的新能源車就基於MLB和MQB平臺。MLB和MQB平臺可以實現協同增效的作用,能夠實現傳統發動機車型、插電式混合動力車型和純電動車型的共 線生產。
不僅如此,海茲曼稱,大眾將在華引入一條全新的電動車生產線,一汽大眾和上汽大眾都將會生產純電動車型。大眾在MLB和MQB平臺的基礎上,定制了一個MEB電動車模組化平臺,在續航里程上可以支援400公里-600公里長途續航里程。
目標:2020年在中國新能源車份額佔據第一
對於大眾新能源車銷售目標,海茲曼並不掩飾對於未來的信心,他表示,2020年中國的新能源車年銷售大約是200萬輛的規模,屆時大眾集團新能源車 在中國市場的銷量應該在幾十萬輛的水準。或者說,2020年,大眾集團在中國新能源車市場的份額應該是與其乘用車在中國整體乘用車的市場份額相似。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!
本文介紹了作者所在團隊在某次上線前測試發現問題、定位問題並修復上線的過程,最後給出幾點經驗總結,希望對大家有用。
(1)今天需要上線,但昨晚才合併了所有分支,時間很緊迫。不幸的是,打包測試后發現有一個Springboot應用(模塊R)啟動失敗,但進程沒有死,一直在輸出報錯日誌。
(2)Google了相關的報錯日誌,並沒有找到相關信息。查看了模塊R的代碼變更,並沒有什麼改動,以為是環境問題;部署到其它環境后,發現問題依舊存在,而且這個問題從未出現過,基本排除環境問題,問題還是出在代碼上。
(3)啟動模塊R上一個版本(現生產環境)的代碼,正常啟動。所以問題還是出現模塊R的改動上。
(4)對比模塊R的發布包的新版本與生產版本的差異,發現第三方依賴包都一致,但自己項目的依賴包不同。
(5)想到一個有效的辦法,依次用生產版本替換掉自己項目的包,最終定位了問題出在通用模塊D上。
(6)查看模塊D的代碼變更記錄,改動比較大,比較難發現是哪裡的改動造成的。
(7)重新看日誌。為何要重看呢?並不是心血來潮,主要是想找關聯。既然已經知道了問題在哪個模塊代碼上,通過查看日誌與該模塊可能相關的信息,或許能找到蛛絲馬跡。
(8)果然!!!重新查看日誌發現,模塊R啟動時,報了一個其它錯誤ErrorA,但被後面不斷重複出現的錯誤ErrorB刷掉了,所以一開始並沒有注意到它。通過該報錯,與模塊D的代碼改動對比。終於定位出了問題!
(9)創建hotfix分支,修改代碼提交,重新merge,打包,測試通過,部署生產!!!
因為部署上線是有特定的時間窗口的,如果錯過了時間,就要下次再上線,還好及時定位,及時解決!
(1)不要放過任何日誌,特別是報錯的日誌,日誌是極其有用的。不要只看最後面的報錯,也不要只看最前面的報錯,任何報錯都可能提供新的方向和線索。如果日誌信息不夠,可以嘗試打開debug模式,會有大量的日誌信息,當然也要求你有足夠強的過濾和整理信息的能力。
(2)提取有用日誌,可以用grep、tail、less等linux命令。
(3)組件化、模塊化很重要,能快速縮小問題範圍。能通過只回退某個模塊實現部分功能先上線。
(4)善用對比工具,如diff命令,BeyondCompare軟件等。
(5)善用代碼變更記錄,這是版本控制給我們帶來的好處,可以方便我們對比代碼改動了什麼,什麼時候改的,能加速問題定位;也能及時回退代碼。
(6)上線前要做充分的測試。這次問題的出現項目流程上的原因在於沒有進行充分的測試。(1)寫代碼的人修改了通用模塊,卻沒有測試依賴它的其它模塊的功能會不會受影響,而只測試了自己那一部分;(2)合併代碼后,沒有足夠的時間來進行測試。部署前一天,才合併了代碼打包測試。所以時間非常緊迫,在短時間要定位問題並解決,容易造成壓力。
(7)要有獨立的測試環境。這個是導致方向性錯誤的原因,經過是這樣的:A同學打包了自己的分支,這時剛好B同學稍晚一點也打包了分支,而打包的環境只有一個,B同學的包覆蓋了A同學的包。所以在A部署的時候,實際用了B同學的代碼打的包,導致啟動失敗。所以一直以為是A同學代碼的問題,這個方向性的錯誤浪費了很多時間。應該要讓每個分支可以同時打包,但不會覆蓋。
(8)不要先入為主。不要過早認定某個模塊就是有問題的,請參考上一條。
(9)團隊作戰,分工合作。整個過程全靠團隊一起協作才能快速定位並解決;打造一個開放包容、溝通順暢的團隊是多麼的重要。
If You Want to Go Fast, Go Alone. If You Want to Go Far, Go Together.
運維和問題定位的知識很多,也非常重要,需要持續學習。本文僅講述了本次過程用到的方法。更多的知識以後慢慢再介紹…
歡迎關注公眾號<南瓜慢說>,將持續為你更新…
多讀書,多分享;多寫作,多整理。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
動態規劃難嗎?說實話,我覺得很難,特別是對於初學者來說,我當時入門動態規劃的時候,是看 0-1 背包問題,當時真的是一臉懵逼。後來,我遇到動態規劃的題,看的懂答案,但就是自己不會做,不知道怎麼下手。就像做遞歸的題,看的懂答案,但下不了手,關於遞歸的,我之前也寫過一篇套路的文章,如果對遞歸不大懂的,強烈建議看一看:
對於動態規劃,春招秋招時好多題都會用到動態規劃,一氣之下,再 leetcode 連續刷了幾十道題
之後,豁然開朗 ,感覺動態規劃也不是很難,今天,我就來跟大家講一講,我是怎麼做動態規劃的題的,以及從中學到的一些套路。相信你看完一定有所收穫
如果你對動態規劃感興趣,或者你看的懂動態規劃,但卻不知道怎麼下手,那麼我建議你好好看以下,這篇文章的寫法,和之前那篇講遞歸的寫法,是差不多一樣的,將會舉大量的例子。如果一次性看不完,建議收藏,同時別忘了素質三連。
為了兼顧初學者,我會從最簡單的題講起,後面會越來越難,最後面還會講解,該如何優化。因為 80% 的動規都是可以進行優化的。不過我得說,如果你連動態規劃是什麼都沒聽過,可能這篇文章你也會壓力山大。
動態規劃,無非就是利用歷史記錄,來避免我們的重複計算。而這些歷史記錄,我們得需要一些變量來保存,一般是用一維數組或者二維數組來保存。下面我們先來講下做動態規劃題很重要的三個步驟,
如果你聽不懂,也沒關係,下面會有很多例題講解,估計你就懂了。之所以不配合例題來講這些步驟,也是為了怕你們腦袋亂了
第一步驟:定義數組元素的含義,上面說了,我們會用一個數組,來保存歷史數組,假設用一維數組 dp[] 吧。這個時候有一個非常非常重要的點,就是規定你這個數組元素的含義,例如你的 dp[i] 是代表什麼意思?
第二步驟:找出數組元素之間的關係式,我覺得動態規劃,還是有一點類似於我們高中學習時的歸納法的,當我們要計算 dp[n] 時,是可以利用 dp[n-1],dp[n-2]…..dp[1],來推出 dp[n] 的,也就是可以利用歷史數據來推出新的元素值,所以我們要找出數組元素之間的關係式,例如 dp[n] = dp[n-1] + dp[n-2],這個就是他們的關係式了。而這一步,也是最難的一步,後面我會講幾種類型的題來說。
學過動態規劃的可能都經常聽到最優子結構,把大的問題拆分成小的問題,說時候,最開始的時候,我是對最優子結構一夢懵逼的。估計你們也聽多了,所以這一次,我將換一種形式來講,不再是各種子問題,各種最優子結構。所以大佬可別噴我再亂講,因為我說了,這是我自己平時做題的套路。
第三步驟:找出初始值。學過數學歸納法的都知道,雖然我們知道了數組元素之間的關係式,例如 dp[n] = dp[n-1] + dp[n-2],我們可以通過 dp[n-1] 和 dp[n-2] 來計算 dp[n],但是,我們得知道初始值啊,例如一直推下去的話,會由 dp[3] = dp[2] + dp[1]。而 dp[2] 和 dp[1] 是不能再分解的了,所以我們必須要能夠直接獲得 dp[2] 和 dp[1] 的值,而這,就是所謂的初始值。
由了初始值,並且有了數組元素之間的關係式,那麼我們就可以得到 dp[n] 的值了,而 dp[n] 的含義是由你來定義的,你想求什麼,就定義它是什麼,這樣,這道題也就解出來了。
不懂?沒事,我們來看三四道例題,我講嚴格按這個步驟來給大家講解。
問題描述:一隻青蛙一次可以跳上1級台階,也可以跳上2級。求該青蛙跳上一個n級的台階總共有多少種跳法。
按我上面的步驟說的,首先我們來定義 dp[i] 的含義,我們的問題是要求青蛙跳上 n 級的台階總共由多少種跳法,那我們就定義 dp[i] 的含義為:跳上一個 i 級的台階總共有 dp[i] 種跳法。這樣,如果我們能夠算出 dp[n],不就是我們要求的答案嗎?所以第一步定義完成。
我們的目的是要求 dp[n],動態規劃的題,如你們經常聽說的那樣,就是把一個規模比較大的問題分成幾個規模比較小的問題,然後由小的問題推導出大的問題。也就是說,dp[n] 的規模為 n,比它規模小的是 n-1, n-2, n-3…. 也就是說,dp[n] 一定會和 dp[n-1], dp[n-2]….存在某種關係的。我們要找出他們的關係。
那麼問題來了,怎麼找?
這個怎麼找,是最核心最難的一個,我們必須回到問題本身來了,來尋找他們的關係式,dp[n] 究竟會等於什麼呢?
對於這道題,由於情況可以選擇跳一級,也可以選擇跳兩級,所以青蛙到達第 n 級的台階有兩種方式
一種是從第 n-1 級跳上來
一種是從第 n-2 級跳上來
由於我們是要算所有可能的跳法的,所以有 dp[n] = dp[n-1] + dp[n-2]。
當 n = 1 時,dp[1] = dp[0] + dp[-1],而我們是數組是不允許下標為負數的,所以對於 dp[1],我們必須要直接給出它的數值,相當於初始值,顯然,dp[1] = 1。一樣,dp[0] = 0.(因為 0 個台階,那肯定是 0 種跳法了)。於是得出初始值:
dp[0] = 0.
dp[1] = 1.
即 n <= 1 時,dp[n] = n.
三個步驟都做出來了,那麼我們就來寫代碼吧,代碼會詳細註釋滴。
int f( int n ){
if(n <= 1)
return n;
// 先創建一個數組來保存歷史數據
int[] dp = new int[n+1];
// 給出初始值
dp[0] = 0;
dp[1] = 1;
// 通過關係式來計算出 dp[n]
for(int i = 2; i <= n; i++){
dp[i] = dp[i-1] + dp[-2];
}
// 把最終結果返回
return dp[n];
}大家先想以下,你覺得,上面的代碼有沒有問題?
答是有問題的,還是錯的,錯在對初始值的尋找不夠嚴謹,這也是我故意這樣弄的,意在告訴你們,關於初始值的嚴謹性。例如對於上面的題,當 n = 2 時,dp[2] = dp[1] + dp[0] = 1。這顯然是錯誤的,你可以模擬一下,應該是 dp[2] = 2。
也就是說,在尋找初始值的時候,一定要注意不要找漏了,dp[2] 也算是一個初始值,不能通過公式計算得出。有人可能會說,我想不到怎麼辦?這個很好辦,多做幾道題就可以了。
下面我再列舉三道不同的例題,並且,再在未來的文章中,我也會持續按照這個步驟,給大家找幾道有難度且類型不同的題。下面這幾道例題,不會講的特性詳細哈。實際上 ,上面的一維數組是可以把空間優化成更小的,不過我們現在先不講優化的事,下面的題也是,不講優化版本。
我做了幾十道 DP 的算法題,可以說,80% 的題,都是要用二維數組的,所以下面的題主要以二維數組為主,當然有人可能會說,要用一維還是二維,我怎麼知道?這個問題不大,接着往下看。
一個機器人位於一個 m x n 網格的左上角 (起始點在下圖中標記為“Start” )。
機器人每次只能向下或者向右移動一步。機器人試圖達到網格的右下角(在下圖中標記為“Finish”)。
問總共有多少條不同的路徑?
這是 leetcode 的 62 號題:
還是老樣子,三個步驟來解決。
由於我們的目的是從左上角到右下角一共有多少種路徑,那我們就定義 dp[i] [j]的含義為:當機器人從左上角走到(i, j) 這個位置時,一共有 dp[i] [j] 種路徑。那麼,dp[m-1] [n-1] 就是我們要的答案了。
注意,這個網格相當於一個二維數組,數組是從下標為 0 開始算起的,所以 右下角的位置是 (m-1, n – 1),所以 dp[m-1] [n-1] 就是我們要找的答案。
想象以下,機器人要怎麼樣才能到達 (i, j) 這個位置?由於機器人可以向下走或者向右走,所以有兩種方式到達
一種是從 (i-1, j) 這個位置走一步到達
一種是從(i, j – 1) 這個位置走一步到達
因為是計算所有可能的步驟,所以是把所有可能走的路徑都加起來,所以關係式是 dp[i] [j] = dp[i-1] [j] + dp[i] [j-1]。
顯然,當 dp[i] [j] 中,如果 i 或者 j 有一個為 0,那麼還能使用關係式嗎?答是不能的,因為這個時候把 i – 1 或者 j – 1,就變成負數了,數組就會出問題了,所以我們的初始值是計算出所有的 dp[0] [0….n-1] 和所有的 dp[0….m-1] [0]。這個還是非常容易計算的,相當於計算機圖中的最上面一行和左邊一列。因此初始值如下:
dp[0] [0….n-1] = 1; // 相當於最上面一行,機器人只能一直往左走
dp[0…m-1] [0] = 1; // 相當於最左面一列,機器人只能一直往下走
三個步驟都寫出來了,直接看代碼
public static int uniquePaths(int m, int n) {
if (m <= 0 || n <= 0) {
return 0;
}
int[][] dp = new int[m][n]; //
// 初始化
for(int i = 0; i < m; i++){
dp[i][0] = 1;
}
for(int i = 0; i < n; i++){
dp[0][i] = 1;
}
// 推導出 dp[m-1][n-1]
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}O(n*m) 的空間複雜度可以優化成 O(min(n, m)) 的空間複雜度的,不過這裏先不講
寫到這裏,有點累了,,但還是得寫下去,所以看的小夥伴,你們可得繼續看呀。下面這道題也不難,比上面的難一丟丟,不過也是非常類似
給定一個包含非負整數的 m x n 網格,請找出一條從左上角到右下角的路徑,使得路徑上的数字總和為最小。
說明:每次只能向下或者向右移動一步。
舉例:
輸入:
arr = [
[1,3,1],
[1,5,1],
[4,2,1]
]
輸出: 7
解釋: 因為路徑 1→3→1→1→1 的總和最小。和上面的差不多,不過是算最優路徑和,這是 leetcode 的第64題:
還是老樣子,可能有些人都看煩了,哈哈,但我還是要按照步驟來寫,讓那些不大懂的加深理解。有人可能覺得,這些題太簡單了吧,別慌,小白先入門,這些屬於 medium 級別的,後面在給幾道 hard 級別的。
由於我們的目的是從左上角到右下角,最小路徑和是多少,那我們就定義 dp[i] [j]的含義為:當機器人從左上角走到(i, j) 這個位置時,最下的路徑和是 dp[i] [j]。那麼,dp[m-1] [n-1] 就是我們要的答案了。
注意,這個網格相當於一個二維數組,數組是從下標為 0 開始算起的,所以 由下角的位置是 (m-1, n – 1),所以 dp[m-1] [n-1] 就是我們要走的答案。
想象以下,機器人要怎麼樣才能到達 (i, j) 這個位置?由於機器人可以向下走或者向右走,所以有兩種方式到達
一種是從 (i-1, j) 這個位置走一步到達
一種是從(i, j – 1) 這個位置走一步到達
不過這次不是計算所有可能路徑,而是計算哪一個路徑和是最小的,那麼我們要從這兩種方式中,選擇一種,使得dp[i] [j] 的值是最小的,顯然有
dp[i] [j] = min(dp[i-1][j],dp[i][j-1]) + arr[i][j];// arr[i][j] 表示網格種的值顯然,當 dp[i] [j] 中,如果 i 或者 j 有一個為 0,那麼還能使用關係式嗎?答是不能的,因為這個時候把 i – 1 或者 j – 1,就變成負數了,數組就會出問題了,所以我們的初始值是計算出所有的 dp[0] [0….n-1] 和所有的 dp[0….m-1] [0]。這個還是非常容易計算的,相當於計算機圖中的最上面一行和左邊一列。因此初始值如下:
dp[0] [j] = arr[0] [j] + dp[0] [j-1]; // 相當於最上面一行,機器人只能一直往左走
dp[i] [0] = arr[i] [0] + dp[i] [0]; // 相當於最左面一列,機器人只能一直往下走
public static int uniquePaths(int[][] arr) {
int m = arr.length;
int n = arr[0].length;
if (m <= 0 || n <= 0) {
return 0;
}
int[][] dp = new int[m][n]; //
// 初始化
dp[0][0] = arr[0][0];
// 初始化最左邊的列
for(int i = 1; i < m; i++){
dp[i][0] = dp[i-1][0] + arr[i][0];
}
// 初始化最上邊的行
for(int i = 1; i < n; i++){
dp[0][i] = dp[0][i-1] + arr[0][i];
}
// 推導出 dp[m-1][n-1]
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = Math.min(dp[i-1][j], dp[i][j-1]) + arr[i][j];
}
}
return dp[m-1][n-1];
}O(n*m) 的空間複雜度可以優化成 O(min(n, m)) 的空間複雜度的,不過這裏先不講
這次給的這道題比上面的難一些,在 leetcdoe 的定位是 hard 級別。好像是 leetcode 的第 72 號題。
問題描述
給定兩個單詞 word1 和 word2,計算出將 word1 轉換成 word2 所使用的最少操作數 。
你可以對一個單詞進行如下三種操作:
插入一個字符
刪除一個字符
替換一個字符
示例:
輸入: word1 = "horse", word2 = "ros"
輸出: 3
解釋:
horse -> rorse (將 'h' 替換為 'r')
rorse -> rose (刪除 'r')
rose -> ros (刪除 'e')解答
還是老樣子,按照上面三個步驟來,並且我這裏可以告訴你,90% 的字符串問題都可以用動態規劃解決,並且90%是採用二維數組。
由於我們的目的求將 word1 轉換成 word2 所使用的最少操作數 。那我們就定義 dp[i] [j]的含義為:當字符串 word1 的長度為 i,字符串 word2 的長度為 j 時,將 word1 轉化為 word2 所使用的最少操作次數為 dp[i] [j]。
有時候,數組的含義並不容易找,所以還是那句話,我給你們一個套路,剩下的還得看你們去領悟。
接下來我們就要找 dp[i] [j] 元素之間的關係了,比起其他題,這道題相對比較難找一點,但是,不管多難找,大部分情況下,dp[i] [j] 和 dp[i-1] [j]、dp[i] [j-1]、dp[i-1] [j-1] 肯定存在某種關係。因為我們的目標就是,**從規模小的,通過一些操作,推導出規模大的。對於這道題,我們可以對 word1 進行三種操作
插入一個字符
刪除一個字符
替換一個字符
由於我們是要讓操作的次數最小,所以我們要尋找最佳操作。那麼有如下關係式:
一、如果我們 word1[i] 與 word2 [j] 相等,這個時候不需要進行任何操作,顯然有 dp[i] [j] = dp[i-1] [j-1]。(別忘了 dp[i] [j] 的含義哈)。
二、如果我們 word1[i] 與 word2 [j] 不相等,這個時候我們就必須進行調整,而調整的操作有 3 種,我們要選擇一種。三種操作對應的關係試如下(注意字符串與字符的區別):
(1)、如果把字符 word1[i] 替換成與 word2[j] 相等,則有 dp[i] [j] = dp[i-1] [j-1] + 1;
(2)、如果在字符串 word1末尾插入一個與 word2[j] 相等的字符,則有 dp[i] [j] = dp[i] [j-1] + 1;
(3)、如果把字符 word1[i] 刪除,則有 dp[i] [j] = dp[i-1] [j] + 1;
那麼我們應該選擇一種操作,使得 dp[i] [j] 的值最小,顯然有
dp[i] [j] = min(dp[i-1] [j-1],dp[i] [j-1],dp[[i-1] [j]]) + 1;
於是,我們的關係式就推出來了,
顯然,當 dp[i] [j] 中,如果 i 或者 j 有一個為 0,那麼還能使用關係式嗎?答是不能的,因為這個時候把 i – 1 或者 j – 1,就變成負數了,數組就會出問題了,所以我們的初始值是計算出所有的 dp[0] [0….n] 和所有的 dp[0….m] [0]。這個還是非常容易計算的,因為當有一個字符串的長度為 0 時,轉化為另外一個字符串,那就只能一直進行插入或者刪除操作了。
public int minDistance(String word1, String word2) {
int n1 = word1.length();
int n2 = word2.length();
int[][] dp = new int[n1 + 1][n2 + 1];
// dp[0][0...n2]的初始值
for (int j = 1; j <= n2; j++)
dp[0][j] = dp[0][j - 1] + 1;
// dp[0...n1][0] 的初始值
for (int i = 1; i <= n1; i++) dp[i][0] = dp[i - 1][0] + 1;
// 通過公式推出 dp[n1][n2]
for (int i = 1; i <= n1; i++) {
for (int j = 1; j <= n2; j++) {
// 如果 word1[i] 與 word2[j] 相等。第 i 個字符對應下標是 i-1
if (word1.charAt(i - 1) == word2.charAt(j - 1)){
p[i][j] = dp[i - 1][j - 1];
}else {
dp[i][j] = Math.min(Math.min(dp[i - 1][j - 1], dp[i][j - 1]), dp[i - 1][j]) + 1;
}
}
}
return dp[n1][n2];
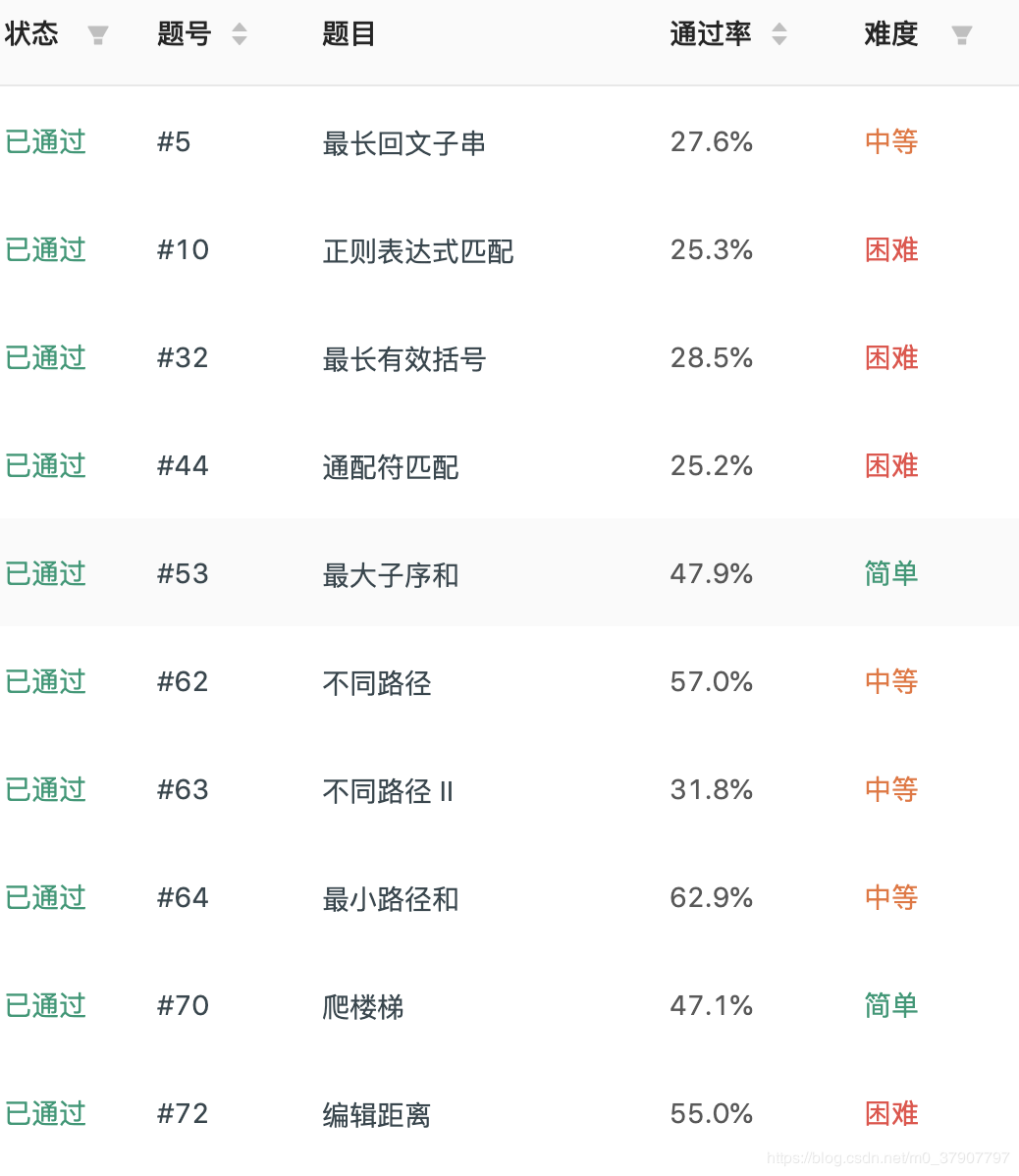
}最後說下,如果你要練習,可以去 leetcode,選擇動態規劃專題,然後連續刷幾十道,保證你以後再也不怕動態規劃了。當然,遇到很難的,咱還是得掛。
Leetcode 動態規劃直達:
前两天寫一篇長達 8000 子的關於動態規劃的文章
這篇文章更多講解我平時做題的套路,不過由於篇幅過長,舉了 4 個案例之後,沒有講解優化,今天這篇文章就來講解下,對動態規劃的優化如何下手,並且以前幾天那篇文章的題作為例子直接講優化,如果沒看過的建議看一下(不看也行,我會直接給出題目以及沒有優化前的代碼):
沒錯,80% 的動態規劃題都可以畫圖,其中 80% 的題都可以通過畫圖一下子知道怎麼優化,當然,DP 也有一些很難的題,想優化可沒那麼容易,不過,今天我要講的,是屬於不怎麼難,且最常見,面試筆試最經常考的難度的題。
下面我們直接通過三道題目來講解優化,你會發現,這些題,優化過後,代碼只有細微的改變,你只要會一兩道,可以說是會了 80% 的題。
上次那個青蛙跳台階的 dp 題是可以把空間複雜度 O( n) 優化成 O(1),本來打算從這道題講起的,但想了下,想要學習 dp 優化的感覺至少都是 小小大佬了,所以就不講了,就從二維數組的 dp 講起。
一個機器人位於一個 m x n 網格的左上角 (起始點在下圖中標記為“Start” )。
機器人每次只能向下或者向右移動一步。機器人試圖達到網格的右下角(在下圖中標記為“Finish”)。
問總共有多少條不同的路徑?
這是 leetcode 的 62 號題:
這道題的 dp 轉移公式是 dp[i] [j] = dp[i-1] [j] + dp[i] [j-1],代碼如下
不懂的看我之前文章:
public static int uniquePaths(int m, int n) {
if (m <= 0 || n <= 0) {
return 0;
}
int[][] dp = new int[m][n]; //
// 初始化
for(int i = 0; i < m; i++){
dp[i][0] = 1;
}
for(int i = 0; i < n; i++){
dp[0][i] = 1;
}
// 推導出 dp[m-1][n-1]
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}這種做法的空間複雜度是 O(n * m),下面我們來講解如何優化成 O(n)。
dp[i] [j] 是一個二維矩陣,我們來畫個二維矩陣的圖,對矩陣進行初始化
然後根據公式 dp[i][j] = dp[i-1][j] + dp[i][j-1] 來填充矩陣的其他值。下面我們先填充第二行的值。
大家想一個問題,當我們要填充第三行的值的時候,我們需要用到第一行的值嗎?答是不需要的,不行你試試,當你要填充第三,第四….第 n 行的時候,第一行的值永遠不會用到,只要填充第二行的值時會用到。
根據公式 dp[i][j] = dp[i-1][j] + dp[i][j-1],我們可以知道,當我們要計算第 i 行的值時,除了會用到第 i – 1 行外,其他第 1 至 第 i-2 行的值我們都是不需要用到的,也就是說,對於那部分用不到的值我們還有必要保存他們嗎?
答是沒必要,我們只需要用一個一維的 dp[] 來保存一行的歷史記錄就可以了。然後在計算機的過程中,不斷着更新 dp[] 的值。單說估計你可能不好理解,下面我就手把手來演示下這個過程。
1、剛開始初始化第一行,此時 dp[0..n-1] 的值就是第一行的值。
2、接着我們來一邊填充第二行的值一邊更新 dp[i] 的值,一邊把第一行的值拋棄掉。
為了方便描述,下面我們用arr (i,j)表示矩陣中第 i 行 第 j 列的值。從 0 開始哈,就是說有第 0 行。
(1)、顯然,矩陣(1, 0) 的值相當於以往的初始化值,為 1。然後這個時候矩陣 (0,0)的值不在需要保存了,因為再也用不到了。
這個時候,我們也要跟着更新 dp[0] 的值了,剛開始 dp[0] = (0, 0),現在更新為 dp[0] = (1, 0)。
(2)、接着繼續更新 (1, 1) 的值,根據之前的公式 (i, j) = (i-1, j) + (i, j- 1)。即 (1,1)=(0,1)+(1,0)=2。
大家看圖,以往的二維的時候, dp[i][j] = dp[i-1] [j]+ dp[i][j-1]。現在轉化成一維,不就是 dp[i] = dp[i] + dp[i-1] 嗎?
即 dp[1] = dp[1] + dp[0],而且還動態幫我們更新了 dp[1] 的值。因為剛開始 dp[i] 的保存第一行的值的,現在更新為保存第二行的值。
(3)、同樣的道理,按照這樣的模式一直來計算第二行的值,順便把第一行的值拋棄掉,結果如下
此時,dp[i] 將完全保存着第二行的值,並且我們可以推導出公式
dp[i] = dp[i-1] + dp[i]
dp[i-1] 相當於之前的 dp[i-1][j],dp[i] 相當於之前的 dp[i][j-1]。
於是按照這個公式不停着填充到最後一行,結果如下:
最後 dp[n-1] 就是我們要求的結果了。所以優化之後,代碼如下:
public static int uniquePaths(int m, int n) {
if (m <= 0 || n <= 0) {
return 0;
}
int[] dp = new int[n]; //
// 初始化
for(int i = 0; i < n; i++){
dp[i] = 1;
}
// 公式:dp[i] = dp[i-1] + dp[i]
for (int i = 1; i < m; i++) {
// 第 i 行第 0 列的初始值
dp[0] = 1;
for (int j = 1; j < n; j++) {
dp[j] = dp[j-1] + dp[j];
}
}
return dp[n-1];
}接着我們來看昨天的另外一道題,就是編輯矩陣,這道題的優化和這一道有一點點的不同,上面這道 dp[i][j] 依賴於 dp[i-1][j] 和 dp[i][j-1]。而還有一種情況就是 dp[i][j] 依賴於 dp[i-1][j],dp[i-1][j-1] 和 dp[i][j-1]。
問題描述
給定兩個單詞 word1 和 word2,計算出將 word1 轉換成 word2 所使用的最少操作數 。
你可以對一個單詞進行如下三種操作:
插入一個字符
刪除一個字符
替換一個字符
示例:
輸入: word1 = "horse", word2 = "ros"
輸出: 3
解釋:
horse -> rorse (將 'h' 替換為 'r')
rorse -> rose (刪除 'r')
rose -> ros (刪除 'e')解答
昨天的代碼如下所示,不懂的記得看之前的文章哈:
public int minDistance(String word1, String word2) {
int n1 = word1.length();
int n2 = word2.length();
int[][] dp = new int[n1 + 1][n2 + 1];
// dp[0][0...n2]的初始值
for (int j = 1; j <= n2; j++)
dp[0][j] = dp[0][j - 1] + 1;
// dp[0...n1][0] 的初始值
for (int i = 1; i <= n1; i++) dp[i][0] = dp[i - 1][0] + 1;
// 通過公式推出 dp[n1][n2]
for (int i = 1; i <= n1; i++) {
for (int j = 1; j <= n2; j++) {
// 如果 word1[i] 與 word2[j] 相等。第 i 個字符對應下標是 i-1
if (word1.charAt(i - 1) == word2.charAt(j - 1)){
p[i][j] = dp[i - 1][j - 1];
}else {
dp[i][j] = Math.min(Math.min(dp[i - 1][j - 1], dp[i][j - 1]), dp[i - 1][j]) + 1;
}
}
}
return dp[n1][n2];
}沒有優化之間的空間複雜度為 O(n*m)
大家可以自己動手做下,按照上面的那個模式,你會優化嗎?
對於這道題其實也是一樣的,如果要計算 第 i 行的值,我們最多只依賴第 i-1 行的值,不需要用到第 i-2 行及其以前的值,所以一樣可以採用一維 dp 來處理的。
不過這個時候要注意,在上面的例子中,我們每次更新完 (i, j) 的值之後,就會把 (i, j-1) 的值拋棄,也就是說之前是一邊更新 dp[i] 的值,一邊把 dp[i] 的舊值拋棄的,不過在這道題中則不可以,因為我們還需要用到它。
哎呀,直接舉例子看圖吧,文字繞來繞去估計會繞暈你們。當我們要計算圖中 (i,j) 的值的時候,在案例1 中,我們值需要用到 (i-1, j) 和 (i, j-1)。(看圖中方格的顏色)
不過這道題中,我們還需要用到 (i-1, j-1) 這個值(但是這個值在以往的案例1 中,它會被拋棄掉)
所以呢,對於這道題,我們還需要一個額外的變量 pre 來時刻保存 (i-1,j-1) 的值。推導公式就可以從二維的
dp[i][j] = min(dp[i-1][j] , dp[i-1][j-1] , dp[i][j-1]) + 1轉化為一維的
dp[i] = min(dp[i-1], pre, dp[i]) + 1。所以呢,案例2 其實和案例1 差別不大,就是多了個變量來臨時保存。最終代碼如下(但是初學者話,代碼也沒那麼好寫)
public int minDistance(String word1, String word2) {
int n1 = word1.length();
int n2 = word2.length();
int[] dp = new int[n2 + 1];
// dp[0...n2]的初始值
for (int j = 0; j <= n2; j++)
dp[j] = j;
// dp[j] = min(dp[j-1], pre, dp[j]) + 1
for (int i = 1; i <= n1; i++) {
int temp = dp[0];
// 相當於初始化
dp[0] = i;
for (int j = 1; j <= n2; j++) {
// pre 相當於之前的 dp[i-1][j-1]
int pre = temp;
temp = dp[j];
// 如果 word1[i] 與 word2[j] 相等。第 i 個字符對應下標是 i-1
if (word1.charAt(i - 1) == word2.charAt(j - 1)){
dp[j] = pre;
}else {
dp[j] = Math.min(Math.min(dp[j - 1], pre), dp[j]) + 1;
}
// 保存要被拋棄的值
}
}
return dp[n2];
}上面的這些題,基本都是不怎麼難的入門題,除了最後一道相對難一點。並且基本 80% 的二維矩陣 dp 都可以像上面的方法一樣優化成 一維矩陣的 dp,核心就是要畫圖,看他們的值依賴,當然,還有很多其他比較難的優化,但是,我遇到的題中,大部分都是我上面這種類型的優化。後面如何遇到其他的,我會作為案例來講,今天就先講最普遍最通用的優化方案。記住,畫二維 dp 的矩陣圖,然後看元素之間的值依賴,然後就可以很清晰着知道該如何優化了。
在之後的文章中,我也會按照這個步驟,在給大家講四五道動態規劃 hard 級別的題,會放在每天推文的第二條給大家學習。如果覺得有收穫,不放三連走起來(點贊、感謝、分享),嘻嘻。
1、點贊,可以讓更多的人看到這篇文章
2、關注我的原創微信公眾號『苦逼的碼農』,第一時間閱讀我的文章,已寫了 150+ 的原創文章。
公眾號後台回復『电子書』,還送你一份电子書大禮包哦。
作者:帥地,一位熱愛、認真寫作的小伙,目前維護原創公眾號:『苦逼的碼農』,已寫了150多篇文章,專註於寫 算法、計算機基礎知識等提升你內功的文章,期待你的關注。
轉載說明:務必註明來源(註明:來源於公眾號:苦逼的碼農, 作者:帥地)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
編寫javascript代碼的時候常常要判斷變量,字面量的類型,可以用typeof,instanceof,Array.isArray(),等方法,究竟哪一種最方便,最實用,最省心呢?本問探討這個問題。
typeof返回一個字符串,表示未經計算的操作數的類型。
語法:typeof(operand) | typeof operand
參數:一個表示對象或原始值的表達式,其類型將被返回
描述:typeof可能返回的值如下:
| 類型 | 結果 |
| Undefined | “undefined” |
| Null | “object” |
| Boolean | “boolean” |
| Number | “number” |
| Bigint | “bigint” |
| String | “string” |
| Symbol | “symbol” |
| 宿主對象(由JS環境提供) | 取決於具體實現 |
| Function對象 | “function” |
| 其他任何對象 | “object” |
從定義和描述上來看,這個語法可以判斷出很多的數據類型,但是仔細觀察,typeof null居然返回的是“object”,讓人摸不着頭腦,下面會具體介紹,先看看這個效果:
// 數值 console.log(typeof 37) // number console.log(typeof 3.14) // number console.log(typeof(42)) // number console.log(typeof Math.LN2) // number console.log(typeof Infinity) // number console.log(typeof NaN) // number 儘管它是Not-A-Number的縮寫,實際NaN是数字計算得到的結果,或者將其他類型變量轉化成数字失敗的結果 console.log(Number(1)) //number Number(1)構造函數會把參數解析成字面量 console.log(typeof 42n) //bigint // 字符串 console.log(typeof '') //string console.log(typeof 'boo') // string console.log(typeof `template literal`) // string console.log(typeof '1') //string 內容為数字的字符串仍然是字符串 console.log(typeof(typeof 1)) //string,typeof總是返回一個字符串 console.log(typeof String(1)) //string String將任意值轉換成字符串 // 布爾值 console.log(typeof true) // boolean console.log(typeof false) // boolean console.log(typeof Boolean(1)) // boolean Boolean會基於參數是真值還是虛值進行轉換 console.log(typeof !!(1)) // boolean 兩次調用!!操作想短語Boolean() // Undefined console.log(typeof undefined) // undefined console.log(typeof declaredButUndefinedVariabl) // 未賦值的變量返回undefined console.log(typeof undeclaredVariable ) // 未定義的變量返回undefined // 對象 console.log(typeof {a: 1}) //object console.log(typeof new Date()) //object console.log(typeof /s/) // 正則表達式返回object // 下面的例子令人迷惑,非常危險,沒有用處,應避免使用,new操作符返回的實例都是對象 console.log(typeof new Boolean(true)) // object console.log(typeof new Number(1)) // object console.log(typeof new String('abc')) // object // 函數 console.log(typeof function () {}) // function console.log(typeof class C { }) // function console.log(typeof Math.sin) // function
javascript誕生以來,typeof null都是返回‘object’的,這個是因為javascript中的值由兩部分組成,一部分是表示類型的標籤,另一部分是表示實際的值。對象類型的值類型標籤是0,不巧的是null表示空指針,它的類型標籤也被設計成0,於是就有這個typeof null === ‘object’這個‘惡魔之子’。
曾經有ECMAScript提案讓typeof null返回‘null’,但是該提案被拒絕了。
除Function之外所有構造函數的類型都是‘object’,如下:
var str = new String('String'); var num = new Number(100) console.log(typeof str) // object console.log(typeof num) // object var func = new Function() console.log(typeof func) // function
typeof運算的優先級要高於“+”操作,但是低於圓括號
var iData = 99 console.log(typeof iData + ' Wisen') // number Wisen console.log(typeof (iData + 'Wisen')) // string
typeof /s/ === 'function'; // Chrome 1-12 , 不符合 ECMAScript 5.1 typeof /s/ === 'object'; // Firefox 5+ , 符合 ECMAScript 5.1
ECMAScript 2015之前,typeof總能保證對任何所給的操作數都返回一個字符串,即使是沒有聲明,沒有賦值的標示符,typeof也能返回undefined,也就是說使用typeof永遠不會報錯。
但是ES6中加入了塊級作用域以及let,const命令之後,在變量聲明之前使用由let,const聲明的變量都會拋出一個ReferenceError錯誤,塊級作用域變量在塊的頭部到聲明變量之間是“暫時性死區”,在這期間訪問變量會拋出錯誤。如下:
console.log(typeof undeclaredVariable) // 'undefined' console.log(typeof newLetVariable) // ReferenceError console.log(typeof newConstVariable) // ReferenceError console.log(typeof newClass) // ReferenceError let newLetVariable const newConstVariable = 'hello' class newClass{}
當前所有瀏覽器都暴露一個類型為undefined的非標準宿主對象document.all。typeof document.all === ‘undefined’。景觀規範允許為非標準的外來對象自定義類型標籤,單要求這些類型標籤與已有的不同,document.all的類型標籤為undefined的例子在web領域被歸類為對原ECMA javascript標準的“故意侵犯”,可能就是瀏覽器的惡作劇。
總結:typeof返回變量或者值的類型標籤,雖然對大部分類型都能返回正確結果,但是對null,構造函數實例,正則表達式這三種不太理想。
instanceof運算符用於檢測實例對象(參數)的原型鏈上是否出現構造函數的prototype。
語法:object instanceof constructor
參數:object 某個實例對象
constructor 某個構造函數
描述:instanceof運算符用來檢測constructor.property是否存在於參數object的原型鏈上。
// 定義構造函數 function C() { } function D() { } var o = new C() console.log(o instanceof C) //true,因為Object.getPrototypeOf(0) === C.prototype console.log(o instanceof D) //false,D.prototype不在o的原型鏈上 console.log(o instanceof Object) //true 同上 C.prototype = {} var o2 = new C() console.log(o2 instanceof C) // true console.log(o instanceof C) // false C.prototype指向了一個空對象,這個空對象不在o的原型鏈上 D.prototype = new C() // 繼承 var o3 = new D() console.log(o3 instanceof D) // true console.log(o3 instanceof C) // true C.prototype現在在o3的原型鏈上
需要注意的是,如果表達式obj instanceof Foo返回true,則並不意味着該表達式會永遠返回true,應為Foo.prototype屬性的值可能被修改,修改之後的值可能不在obj的原型鏈上,這時表達式的值就是false了。另外一種情況,改變obj的原型鏈的情況,雖然在當前ES規範中,只能讀取對象的原型而不能修改它,但是藉助非標準的__proto__偽屬性,是可以修改的,比如執行obj.__proto__ = {}后,obj instanceof Foo就返回false了。此外ES6中Object.setPrototypeOf(),Reflect.setPrototypeOf()都可以修改對象的原型。
instanceof和多全局對象(多個iframe或多個window之間的交互)
瀏覽器中,javascript腳本可能需要在多個窗口之間交互。多個窗口意味着多個全局環境,不同全局環境擁有不同的全局對象,從而擁有不同的內置構造函數。這可能會引發一些問題。例如表達式[] instanceof window.frames[0].Array會返回false,因為Array.prototype !== window.frames[0].Array.prototype。
起初,這樣可能沒有意義,但是當在腳本中處理多個frame或多個window以及通過函數將對象從一個窗口傳遞到另一個窗口時,這就是一個非常有意義的話題。實際上,可以通過Array.isArray(myObj)或者Object.prototype.toString.call(myObj) = “[object Array]”來安全的檢測傳過來的對象是否是一個數組。
String對象和Date對象都屬於Object類型(它們都由Object派生出來)。
但是,使用對象文字符號創建的對象在這裡是一個例外,雖然原型未定義,但是instanceof of Object返回true。
var simpleStr = "This is a simple string"; var myString = new String(); var newStr = new String("String created with constructor"); var myDate = new Date(); var myObj = {}; var myNonObj = Object.create(null); console.log(simpleStr instanceof String); // 返回 false,雖然String.prototype在simpleStr的原型鏈上,但是後者是字面量,不是對象 console.log(myString instanceof String); // 返回 true console.log(newStr instanceof String); // 返回 true console.log(myString instanceof Object); // 返回 true console.log(myObj instanceof Object); // 返回 true, 儘管原型沒有定義 console.log(({}) instanceof Object); // 返回 true, 同上 console.log(myNonObj instanceof Object); // 返回 false, 一種創建非 Object 實例的對象的方法 console.log(myString instanceof Date); //返回 false console.log( myDate instanceof Date); // 返回 true console.log(myDate instanceof Object); // 返回 true console.log(myDate instanceof String); // 返回 false
注意:instanceof運算符的左邊必須是一個對象,像”string” instanceof String,true instanceof Boolean這樣的字面量都會返回false。
下面代碼創建了一個類型Car,以及該類型的對象實例mycar,instanceof運算符表明了這個myca對象既屬於Car類型,又屬於Object類型。
function Car(make, model, year) { this.make = make; this.model = model; this.year = year; } var mycar = new Car("Honda", "Accord", 1998); var a = mycar instanceof Car; // 返回 true var b = mycar instanceof Object; // 返回 true
不是…的實例
要檢測對象不是某個構造函數的實例時,可以使用!運算符,例如if(!(mycar instanceof Car))
instanceof雖然能夠判斷出對象的類型,但是必須要求這個參數是一個對象,簡單類型的變量,字面量就不行了,很顯然,這在實際編碼中也是不夠實用。
總結:obj instanceof constructor雖然能判斷出對象的原型鏈上是否有構造函數的原型,但是只能判斷出對象類型變量,字面量是判斷不出的。
toString()方法返回一個表示該對象的字符串。
語法:obj.toString()
返回值:一個表示該對象的字符串
描述:每個對象都有一個toString()方法,該對象被表示為一個文本字符串時,或一個對象以預期的字符串方式引用時自動調用。默認情況下,toString()方法被每個Object對象繼承,如果此方法在自定義對象中未被覆蓋,toString()返回“[object type]”,其中type是對象的類型,看下面代碼:
var o = new Object(); console.log(o.toString()); // returns [object Object]
注意:如ECMAScript 5和隨後的Errata中所定義,從javascript1.8.5開始,toString()調用null返回[object, Null],undefined返回[object Undefined]
覆蓋默認的toString()方法
可以自定義一個方法,來覆蓋默認的toString()方法,該toString()方法不能傳入參數,並且必須返回一個字符串,自定義的toString()方法可以是任何我們需要的值,但如果帶有相關的信息,將變得非常有用。
下面代碼中定義Dog對象類型,並在構造函數原型上覆蓋toString()方法,返回一個有實際意義的字符串,描述當前dog的姓名,顏色,性別,飼養員等信息。
function Dog(name,breed,color,sex) { this.name = name; this.breed = breed; this.color = color; this.sex = sex; } Dog.prototype.toString = function dogToString() { return "Dog " + this.name + " is a " + this.sex + " " + this.color + " " + this.breed } var theDog = new Dog("Gabby", "Lab", "chocolate", "female"); console.log(theDog.toString()) //Dog Gabby is a female chocolate Lab
目前來看toString()方法能夠基本滿足javascript數據類型的檢測需求,可以通過toString()來檢測每個對象的類型。為了每個對象都能通過Object.prototype.toString()來檢測,需要以Function.prototype.call()或者Function.prototype.apply()的形式來檢測,傳入要檢測的對象或變量作為第一個參數,返回一個字符串”[object type]”。
// null undefined console.log(Object.prototype.toString.call(null)) //[object Null] 很給力 console.log(Object.prototype.toString.call(undefined)) //[object Undefined] 很給力 // Number console.log(Object.prototype.toString.call(Infinity)) //[object Number] console.log(Object.prototype.toString.call(Number.MAX_SAFE_INTEGER)) //[object Number] console.log(Object.prototype.toString.call(NaN)) //[object Number],NaN一般是数字運算得到的結果,返回Number還算可以接受 console.log(Object.prototype.toString.call(1)) //[object Number] var n = 100 console.log(Object.prototype.toString.call(n)) //[object Number] console.log(Object.prototype.toString.call(0)) // [object Number] console.log(Object.prototype.toString.call(Number(1))) //[object Number] 很給力 console.log(Object.prototype.toString.call(new Number(1))) //[object Number] 很給力 console.log(Object.prototype.toString.call('1')) //[object String] console.log(Object.prototype.toString.call(new String('2'))) // [object String] // Boolean console.log(Object.prototype.toString.call(true)) // [object Boolean] console.log(Object.prototype.toString.call(new Boolean(1))) //[object Boolean] // Array console.log(Object.prototype.toString.call(new Array(1))) // [object Array] console.log(Object.prototype.toString.call([])) // [object Array] // Object console.log(Object.prototype.toString.call(new Object())) // [object Object] function foo() {} let a = new foo() console.log(Object.prototype.toString.call(a)) // [object Object] // Function console.log(Object.prototype.toString.call(Math.floor)) //[object Function] console.log(Object.prototype.toString.call(foo)) //[object Function] // Symbol console.log(Object.prototype.toString.call(Symbol('222'))) //[object Symbol] // RegExp console.log(Object.prototype.toString.call(/sss/)) //[object RegExp]
上面的結果,除了NaN返回Number稍微有點差池之外其他的都返回了意料之中的結果,都能滿足實際開發的需求,於是我們可以寫一個通用的函數來檢測變量,字面量的類型。如下:
let Type = (function () { let type = {}; let typeArr = ['String', 'Object', 'Number', 'Array', 'Undefined', 'Function', 'Null', 'Symbol', 'Boolean', 'RegExp', 'BigInt']; for (let i = 0; i < typeArr.length; i++) { (function (name) { type['is' + name] = function (obj) { return Object.prototype.toString.call(obj) === '[object ' + name + ']' } })(typeArr[i]) } return type })() let s = true console.log(Type.isBoolean(s)) // true console.log(Type.isRegExp(/22/)) // true
除了能檢測ECMAScript規定的八種數據類型(七種原始類型,Boolean,Null,Undefined,Number,BigInt,String,Symbol,一種複合類型Object)之外,還能檢測出正則表達式RegExp,Function這兩種類型,基本上能滿足開發中的判斷數據類型需求。
既然說道這裏,不妨說一說另一個開發中常見的問題,判斷一個變量是否等於一個值。ES5中比較兩個值是否相等,可以使用相等運算符(==),嚴格相等運算符(===),但它們都有缺點,== 會將‘4’轉換成4,後者NaN不等於自身,以及+0 !=== -0。ES6中提出”Same-value equality“(同值相等)算法,用來解決這個問題。Object.is就是部署這個算法的新方法,它用來比較兩個值是否嚴格相等,與嚴格比較運算(===)行為基本一致。
console.log(5 == '5') // true console.log(NaN == NaN) // false console.log(+0 == -0) // true console.log({} == {}) // false console.log(5 === '5') // false console.log(NaN === NaN) // false console.log(+0 === -0) // true console.log({} === {}) // false
Object.js()不同之處有兩處,一是+0不等於-0,而是NaN等於自身,如下:
let a = {} let b = {} let c = b console.log(a === b) // false console.log(b === c) // true console.log(Object.is(b, c)) // true
注意兩個空對象不能判斷相等,除非是將一個對象賦值給另外一個變量,對象類型的變量是一個指針,比較的也是這個指針,而不是對象內部屬性,對象原型等。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
目錄
本文介紹Spring的七種事務傳播行為並通過代碼演示下。
事務傳播行為(propagation behavior)指的就是當一個事務方法被另一個事務方法調用時,這個事務方法應該如何運行。
例如:methodA方法調用methodB方法時,methodB是繼續在調用者methodA的事務中運行呢,還是為自己開啟一個新事務運行,這就是由methodB的事務傳播行為決定的。
Spring在TransactionDefinition接口中規定了7種類型的事務傳播行為。事務傳播行為是Spring框架獨有的事務增強特性。這是Spring為我們提供的強大的工具箱,使用事務傳播行為可以為我們的開發工作提供許多便利。
7種事務傳播行為如下:
1.PROPAGATION_REQUIRED
如果當前沒有事務,就創建一個新事務,如果當前存在事務,就加入該事務,這是最常見的選擇,也是Spring默認的事務傳播行為。
2.PROPAGATION_SUPPORTS
支持當前事務,如果當前存在事務,就加入該事務,如果當前不存在事務,就以非事務執行。
3.PROPAGATION_MANDATORY
支持當前事務,如果當前存在事務,就加入該事務,如果當前不存在事務,就拋出異常。
4.PROPAGATION_REQUIRES_NEW
創建新事務,無論當前存不存在事務,都創建新事務。
5.PROPAGATION_NOT_SUPPORTED
以非事務方式執行操作,如果當前存在事務,就把當前事務掛起。
6.PROPAGATION_NEVER
以非事務方式執行,如果當前存在事務,則拋出異常。
7.PROPAGATION_NESTED
如果當前存在事務,則在嵌套事務內執行。如果當前沒有事務,則按REQUIRED屬性執行。
其實這7中我也沒看懂,不過不急,咱們接下來直接看效果。
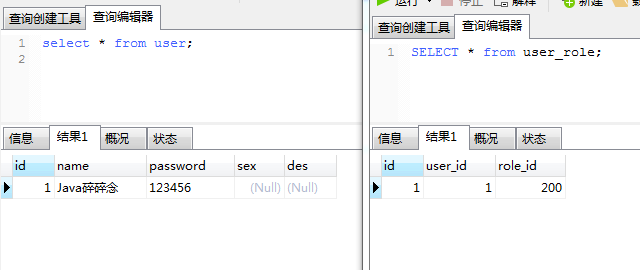
演示前先建兩個表,用戶表和用戶角色表,一開始兩個表裡沒有數據。
需要注意下,為了數據更直觀,每次執行代碼時 先清空下user和user_role表的數據。
user表:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`sex` int(11) DEFAULT NULL,
`des` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;user_role表:
CREATE TABLE `user_role` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`role_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;如果當前沒有事務,就創建一個新事務,如果當前存在事務,就加入該事務,這是最常見的選擇,也是Spring默認的事務傳播行為。
場景一:
此場景外圍方法沒有開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation=Propagation.REQUIRED,然後在測試方法中同時調用兩個方法並在調用結束后拋出異常。
2.主要代碼
外層調用方法代碼:
/**
* 測試 PROPAGATION_REQUIRED
*
* @Author: java_suisui
*/
@Test
void test_PROPAGATION_REQUIRED() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.REQUIRED)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.REQUIRED)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
4.結果分析
外圍方法未開啟事務,插入用戶表和用戶角色表的方法在自己的事務中獨立運行,外圍方法異常不影響內部插入,所以兩條記錄都新增成功。
場景二:
此場景外圍方法開啟事務。
1.主要代碼
測試方法代碼如下:
/**
* 測試 PROPAGATION_REQUIRED
*
* @Author: java_suisui
*/
@Transactional
@Test
void test_PROPAGATION_REQUIRED() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}2.代碼執行后數據庫截圖
兩張表數據都為空,截圖如下:
3.結果分析
外圍方法開啟事務,內部方法加入外圍方法事務,外圍方法回滾,內部方法也要回滾,所以兩個記錄都插入失敗。
結論:以上結果證明在外圍方法開啟事務的情況下Propagation.REQUIRED修飾的內部方法會加入到外圍方法的事務中,所以Propagation.REQUIRED修飾的內部方法和外圍方法均屬於同一事務,只要一個方法回滾,整個事務均回滾。
支持當前事務,如果當前存在事務,就加入該事務,如果當前不存在事務,就以非事務執行。
場景一:
此場景外圍方法沒有開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation=Propagation.SUPPORTS,然後在測試方法中同時調用兩個方法並在調用結束后拋出異常。
2.主要代碼
外層調用方法代碼:
/**
* 測試 PROPAGATION_SUPPORTS
*
* @Author: java_suisui
*/
@Test
void test_PROPAGATION_SUPPORTS() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.SUPPORTS)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.SUPPORTS)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
4.結果分析
外圍方法未開啟事務,插入用戶表和用戶角色表的方法以非事務的方式獨立運行,外圍方法異常不影響內部插入,所以兩條記錄都新增成功。
場景二:
此場景外圍方法開啟事務。
1.主要代碼
test_PROPAGATION_SUPPORTS方法添加註解@Transactional即可。
2.代碼執行后數據庫截圖
兩張表數據都為空,截圖如下:
3.結果分析
外圍方法開啟事務,內部方法加入外圍方法事務,外圍方法回滾,內部方法也要回滾,所以兩個記錄都插入失敗。
結論:以上結果證明在外圍方法開啟事務的情況下Propagation.SUPPORTS修飾的內部方法會加入到外圍方法的事務中,所以Propagation.SUPPORTS修飾的內部方法和外圍方法均屬於同一事務,只要一個方法回滾,整個事務均回滾。
支持當前事務,如果當前存在事務,就加入該事務,如果當前不存在事務,就拋出異常。
通過上面的測試,“支持當前事務,如果當前存在事務,就加入該事務”,這句話已經驗證了,外層添加@Transactional註解后兩條記錄都新增失敗,所以這個傳播行為只測試下外層沒有開始事務的場景。
場景一:
此場景外圍方法沒有開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation = Propagation.MANDATORY,主要代碼如下。
2.主要代碼
外層調用方法代碼:
/**
* 測試 PROPAGATION_MANDATORY
*
* @Author: java_suisui
*/
@Test
void test_PROPAGATION_MANDATORY() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.MANDATORY)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.MANDATORY)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都為空,截圖如下:
4.結果分析
運行日誌如下,可以發現在調用userService.add()時候已經報錯了,所以兩個表都沒有新增數據,驗證了“如果當前不存在事務,就拋出異常”。
at com.example.springboot.mybatisannotation.service.impl.UserServiceImpl$$EnhancerBySpringCGLIB$$50090f18.add(<generated>)
at com.example.springboot.mybatisannotation.SpringBootMybatisAnnotationApplicationTests.test_PROPAGATION_MANDATORY(SpringBootMybatisAnnotationApplicationTests.java:78)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)創建新事務,無論當前存不存在事務,都創建新事務。
這種情況每次都創建事務,所以我們驗證一種情況即可。
場景一:
此場景外圍方法開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation = Propagation.REQUIRES_NEW,主要代碼如下。
2.主要代碼
外層調用方法代碼:
/**
* 測試 REQUIRES_NEW
*
* @Author: java_suisui
*/
@Test
@Transactional
void test_REQUIRES_NEW() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.REQUIRES_NEW)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.REQUIRES_NEW)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
4.結果分析
無論當前存不存在事務,都創建新事務,所以兩個數據新增成功。
以非事務方式執行操作,如果當前存在事務,就把當前事務掛起。
場景一:
此場景外圍方法不開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation = Propagation.NOT_SUPPORTED,主要代碼如下。
2.主要代碼
外層調用方法代碼:
/**
* 測試 PROPAGATION_NOT_SUPPORTED
*
* @Author: java_suisui
*/
@Test
void test_PROPAGATION_NOT_SUPPORTED() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.NOT_SUPPORTED)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.NOT_SUPPORTED)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
4.結果分析
以非事務方式執行,所以兩個數據新增成功。
場景二:
此場景外圍方法開啟事務。
1.主要代碼
test_PROPAGATION_NOT_SUPPORTED方法添加註解@Transactional即可。
2.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
3.結果分析
如果當前存在事務,就把當前事務掛起,相當於以非事務方式執行,所以兩個數據新增成功。
以非事務方式執行,如果當前存在事務,則拋出異常。
上面已經有類似情況,外層沒有事務會以非事務的方式運行,兩個表新增成功;有事務則拋出異常,兩個表都都沒有新增數據。
如果當前存在事務,則在嵌套事務內執行。如果當前沒有事務,則按REQUIRED屬性執行。
上面已經有類似情況,外層沒有事務會以REQUIRED屬性的方式運行,兩個表新增成功;有事務但是用的是一個事務,方法最後拋出了異常導致回滾,兩個表都都沒有新增數據。
到此Spring的7種事務傳播行為已經全部介紹完成了,有問題歡迎留言溝通哦!
完整源碼地址: https://github.com/suisui2019/springboot-study
推薦閱讀
限時領取免費Java相關資料,涵蓋了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo/Kafka、Hadoop、Hbase、Flink等高併發分佈式、大數據、機器學習等技術。
關注下方公眾號即可免費領取:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
摘錄自2019年12月23日中央社報導
紐西蘭白島(White Island)火山9日突然噴發,當時有47人在島上觀光,其中大部分是澳洲旅客,紐西蘭警方23日證實又一人在醫院過世後,白島火山噴發死亡人數升至19人,目前仍有25人在醫院且多人傷勢危急。死亡總數包括遺體尚未尋獲但據信已經罹難的兩人,17歲澳洲公民藍福特(Winona Langford)和40歲紐西蘭導遊馬歇爾-殷曼(Hayden Marshall-Inman)的遺體據信已被捲進海裡。
紐西蘭警方救援白島火山罹難者。照片來源:
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
摘錄自2019年12月22日中央社報導
德國社會上最近有聲音認為應該延長核電廠的使用年限,檢討廢核政策;不過,德國政府發言人強調廢核是朝野共識,政府2022年廢核的計畫不變。
執政的基督教民主黨(CDU)能源政策發言人菲佛(Joachim Pfeiffer)18日接受「明鏡」週刊(Der Spiegel)訪問時表示,廢核是錯誤的政策;不過,他強調基民黨團不會主動提案。
對此,德國聯邦環境部發言人費克特納(Nikolai Fichtner)在例行記者會表示,朝野政黨2011年達成共識,解決了核電數十年來在德國社會的爭議性。核電是高風險的科技,興建核電廠的計畫顯示核電成本太高,此外還有核廢料的問題。總之,核電帶給未來世代許多問題,環境部認為廢核共識不應該翻盤。
總理梅克爾(Angela Merkel)的發言人塞柏特(Steffen Seibert)也指出,政府對核電的態度沒變,廢核將照原計畫執行。
德國西南部菲力普斯堡(Philippsburg)的核電廠,由安能亞太EnBW營運。照片來源:
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!