線程(Thread)是併發編程的基礎,也是程序執行的最小單元,它依託進程而存在。
一個進程中可以包含多個線程,多線程可以共享一塊內存空間和一組系統資源,因此線程之間的切換更加節省資源、更加輕量化,也因此被稱為輕量級的進程。
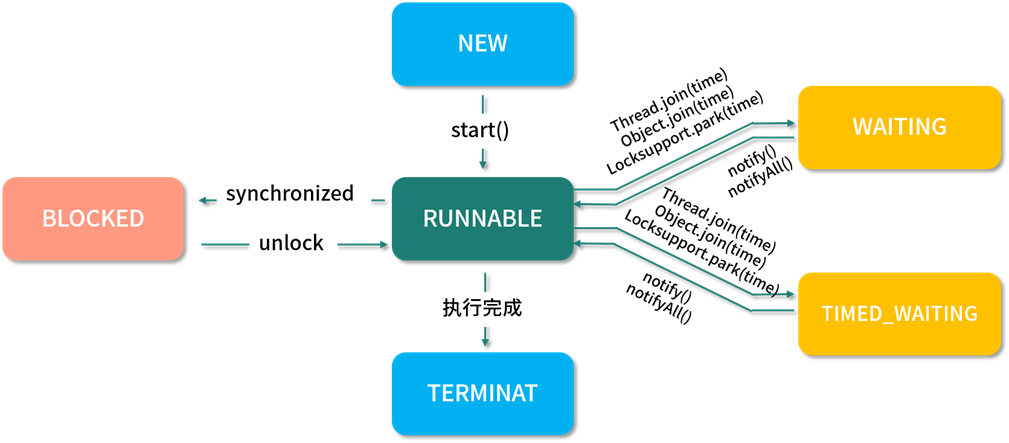
線程的狀態在 JDK 1.5 之後以枚舉的方式被定義在 Thread 的源碼中,它總共包含以下 6 個狀態:
NEW,新建狀態,線程被創建出來,但尚未啟動時的線程狀態;
RUNNABLE,就緒狀態,表示可以運行的線程狀態,它可能正在運行,或者是在排隊等待操作系統給它分配 CPU 資源;
BLOCKED,阻塞等待鎖的線程狀態,表示處於阻塞狀態的線程正在等待監視器鎖,比如等待執行 synchronized 代碼塊或者使用 synchronized 標記的方法;
WAITING,等待狀態,一個處於等待狀態的線程正在等待另一個線程執行某個特定的動作,比如,一個線程調用了 Object.wait() 方法,那它就在等待另一個線程調用 Object.notify() 或 Object.notifyAll() 方法;
TIMED_WAITING,計時等待狀態,和等待狀態(WAITING)類似,它只是多了超時時間,比如調用了有超時時間設置的方法 Object.wait(long timeout) 和 Thread.join(long timeout) 等這些方法時,它才會進入此狀態;
TERMINATED,終止狀態,表示線程已經執行完成。
線程狀態的源代碼如下:
|
public enum State { /** * 新建狀態,線程被創建出來,但尚未啟動時的線程狀態 */ NEW,
/** * 就緒狀態,表示可以運行的線程狀態,但它在排隊等待來自操作系統的 CPU 資源 */ RUNNABLE,
/** * 阻塞等待鎖的線程狀態,表示正在處於阻塞狀態的線程 * 正在等待監視器鎖,比如等待執行 synchronized 代碼塊或者 * 使用 synchronized 標記的方法 */ BLOCKED,
/** * 等待狀態,一個處於等待狀態的線程正在等待另一個線程執行某個特定的動作。 * 例如,一個線程調用了 Object.wait() 它在等待另一個線程調用 * Object.notify() 或 Object.notifyAll() */ WAITING,
/** * 計時等待狀態,和等待狀態 (WAITING) 類似,只是多了超時時間,比如 * 調用了有超時時間設置的方法 Object.wait(long timeout) 和 * Thread.join(long timeout) 就會進入此狀態 */ TIMED_WAITING,
/** * 終止狀態,表示線程已經執行完成 */ } |
線程的工作模式是,首先先要創建線程並指定線程需要執行的業務方法,然後再調用線程的 start() 方法,此時線程就從 NEW(新建)狀態變成了 RUNNABLE(就緒)狀態;
然後線程會判斷要執行的方法中有沒有 synchronized 同步代碼塊,如果有並且其他線程也在使用此鎖,那麼線程就會變為 BLOCKED(阻塞等待)狀態,當其他線程使用完此鎖之後,線程會繼續執行剩餘的方法。
當遇到 Object.wait() 或 Thread.join() 方法時,線程會變為 WAITING(等待狀態)狀態;
如果是帶了超時時間的等待方法,那麼線程會進入 TIMED_WAITING(計時等待)狀態;
當有其他線程執行了 notify() 或 notifyAll() 方法之後,線程被喚醒繼續執行剩餘的業務方法,直到方法執行完成為止,此時整個線程的流程就執行完了,執行流程如下圖所示:
【BLOCKED 和 WAITING 的區別】
雖然 BLOCKED 和 WAITING 都有等待的含義,但二者有着本質的區別。
首先它們狀態形成的調用方法不同。
其次 BLOCKED 可以理解為當前線程還處於活躍狀態,只是在阻塞等待其他線程使用完某個鎖資源;
而 WAITING 則是因為自身調用了 Object.wait() 或着是 Thread.join() 又或者是 LockSupport.park() 而進入等待狀態,只能等待其他線程執行某個特定的動作才能被繼續喚醒。
比如當線程因為調用了 Object.wait() 而進入 WAITING 狀態之後,則需要等待另一個線程執行 Object.notify() 或 Object.notifyAll() 才能被喚醒。
【start() 和 run() 的區別】
首先從 Thread 源碼來看,start() 方法屬於 Thread 自身的方法,並且使用了 synchronized 來保證線程安全,源碼如下:
|
public synchronized void start() { // 狀態驗證,不等於 NEW 的狀態會拋出異常 if (threadStatus != 0) throw new IllegalThreadStateException(); // 通知線程組,此線程即將啟動
group.add(this); boolean started = false; try { start0(); started = true; } finally { try { if (!started) { group.threadStartFailed(this); } } catch (Throwable ignore) { // 不處理任何異常,如果 start0 拋出異常,則它將被傳遞到調用堆棧上 } } } |
run() 方法為 Runnable 的抽象方法,必須由調用類重寫此方法,重寫的 run() 方法其實就是此線程要執行的業務方法,源碼如下:
|
public class Thread implements Runnable { // 忽略其他方法…… private Runnable target; @Override public void run() { if (target != null) { target.run(); } } } @FunctionalInterface public interface Runnable { public abstract void run(); } |
從執行的效果來說,start() 方法可以開啟多線程,讓線程從 NEW 狀態轉換成 RUNNABLE 狀態,而 run() 方法只是一個普通的方法。
其次,它們可調用的次數不同,start() 方法不能被多次調用,否則會拋出 java.lang.IllegalStateException;而 run() 方法可以進行多次調用,因為它只是一個普通的方法而已。
【線程優先級】
在 Thread 源碼中和線程優先級相關的屬性有 3 個:
|
// 線程可以擁有的最小優先級 public final static int MIN_PRIORITY = 1;
// 線程默認優先級 public final static int NORM_PRIORITY = 5;
// 線程可以擁有的最大優先級 public final static int MAX_PRIORITY = 10 |
線程的優先級可以理解為線程搶佔 CPU 時間片的概率,優先級越高的線程優先執行的概率就越大,但並不能保證優先級高的線程一定先執行。
在程序中我們可以通過 Thread.setPriority() 來設置優先級,setPriority() 源碼如下:
|
public final void setPriority(int newPriority) { ThreadGroup g; checkAccess(); // 先驗證優先級的合理性 if (newPriority > MAX_PRIORITY || newPriority < MIN_PRIORITY) { throw new IllegalArgumentException(); } if((g = getThreadGroup()) != null) { // 優先級如果超過線程組的最高優先級,則把優先級設置為線程組的最高優先級 if (newPriority > g.getMaxPriority()) { newPriority = g.getMaxPriority(); } setPriority0(priority = newPriority); } } |
【線程的常用方法】
線程的常用方法有以下幾個。
join()
在一個線程中調用 other.join() ,這時候當前線程會讓出執行權給 other 線程,直到 other 線程執行完或者過了超時時間之後再繼續執行當前線程,join() 源碼如下:
|
public final synchronized void join(long millis) throws InterruptedException { long base = System.currentTimeMillis(); long now = 0; // 超時時間不能小於 0 if (millis < 0) { throw new IllegalArgumentException(“timeout value is negative”); } // 等於 0 表示無限等待,直到線程執行完為之 if (millis == 0) { // 判斷子線程 (其他線程) 為活躍線程,則一直等待 while (isAlive()) { wait(0); } } else { // 循環判斷 while (isAlive()) { long delay = millis – now; if (delay <= 0) { break; } wait(delay); now = System.currentTimeMillis() – base; } } } |
從源碼中可以看出 join() 方法底層還是通過 wait() 方法來實現的。
例如,在未使用 join() 時,代碼如下:
|
public class ThreadExample { public static void main(String[] args) throws InterruptedException { Thread thread = new Thread(() -> { for (int i = 1; i < 6; i++) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(“子線程睡眠:“ + i + “秒。“); } }); thread.start(); // 開啟線程 // 主線程執行 for (int i = 1; i < 4; i++) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(“主線程睡眠:“ + i + “秒。“); } } } |
程序執行結果為:
複製主線程睡眠:1秒。
子線程睡眠:1秒。
主線程睡眠:2秒。
子線程睡眠:2秒。
主線程睡眠:3秒。
子線程睡眠:3秒。
子線程睡眠:4秒。
子線程睡眠:5秒。
從結果可以看出,在未使用 join() 時主子線程會交替執行。
然後我們再把 join() 方法加入到代碼中,代碼如下:
|
public class ThreadExample { public static void main(String[] args) throws InterruptedException { Thread thread = new Thread(() -> { for (int i = 1; i < 6; i++) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(“子線程睡眠:“ + i + “秒。“); } }); thread.start(); // 開啟線程 thread.join(2000); // 等待子線程先執行 2 秒鐘 // 主線程執行 for (int i = 1; i < 4; i++) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(“主線程睡眠:“ + i + “秒。“); } } } |
程序執行結果為:
複製子線程睡眠:1秒。
子線程睡眠:2秒。
主線程睡眠:1秒。
// thread.join(2000); 等待 2 秒之後,主線程和子線程再交替執行
子線程睡眠:3秒。
主線程睡眠:2秒。
子線程睡眠:4秒。
子線程睡眠:5秒。
主線程睡眠:3秒。
從執行結果可以看出,添加 join() 方法之後,主線程會先等子線程執行 2 秒之後才繼續執行。
yield()
看 Thread 的源碼可以知道 yield() 為本地方法,也就是說 yield() 是由 C 或 C++ 實現的,源碼如下:
|
public static native void yield(); |
yield() 方法表示給線程調度器一個當前線程願意出讓 CPU 使用權的暗示,但是線程調度器可能會忽略這個暗示。
比如我們執行這段包含了 yield() 方法的代碼,如下所示:
|
public static void main(String[] args) throws InterruptedException { Runnable runnable = new Runnable() { @Override public void run() { for (int i = 0; i < 10; i++) { System.out.println(“線程:“ + Thread.currentThread().getName() + “ I:“ + i); if (i == 5) { Thread.yield(); } } } }; Thread t1 = new Thread(runnable, “T1”); Thread t2 = new Thread(runnable, “T2”); t1.start(); t2.start(); } |
當我們把這段代碼執行多次之後會發現,每次執行的結果都不相同,這是因為 yield() 執行非常不穩定,線程調度器不一定會採納 yield() 出讓 CPU 使用權的建議,從而導致了這樣的結果。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※聚甘新