文:郭依潔(政大外交所研究生)
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
電動版奔馳B級是戴姆勒繼Smart ForTwo電動版之後的第二款純電動車,由戴姆勒和特斯拉聯合開發,其電動馬達由特斯拉提供,今年將先後在美國和歐洲上市。

電動版奔馳B級擁有大約200公里的續航里程,0到100km/h加速僅需時7.9秒,最高速度為160km/h。其電動馬達由特斯拉提供,規律達174馬力,同寶馬i3電動車的規律相比還高出8馬力。目前戴姆勒尚未公佈新款奔馳B級電動車的售價。
電動版奔馳B級由戴姆勒位於德國的拉施塔特(Rastatt)工廠負責生產,汽油、柴油及天然氣版本的奔馳B級也在該工廠投產。據戴姆勒一名女發言人透露,電動版奔馳B級在其整個生命週期中的產量預計將達到五位數。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
日前,銀河電子為拓展新能源汽車領域,以8.73億人民幣(下同)收購福建駿鵬通信科技有限公司和洛陽嘉盛電源科技有限公司。 福建駿鵬主要業務為新能源電動車和高端LED關鍵結構件的供應商,嘉盛電源主營業務定位於新能源電動汽車充電類產品。2015年前4個月兩公司的營業收入分別是6622.59萬元和2331.76萬元,實現淨利潤1146.11萬元和685.14萬元。 交易對方承諾:福建駿鵬2015年、2016年和2017年經審計的扣除非經常性損益後歸屬于母公司股東的淨利潤分別為5500萬元、7200萬元和9500萬元;嘉盛電源2015年、2016年和2017年經審計的扣除非經常性損益後歸屬于母公司股東的淨利潤分別為2000萬元、3000萬元和4000萬元。 銀河電子錶示,此次收購後將進一步擴大和提升了公司在新能源電動汽車行業的業務機會和盈利能力
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
互聯網公司程序員,前些天項目趕進度,被強制加班。 我們公司以前也是鼓勵員工加班,但比較隱晦, 不是強制的,而這次是上司直接發話,必須要加班,否則工作無法完成的責任會扣到你頭上。
被要求強行加班,無償的,而且是喪心病狂的996,我臉上顯得很平靜,但是內心一萬頭草泥馬在奔騰。當天晚上,我就發微信給上司,我說:
“趕項目我一定不拖進度,該完成的工作按時完成,但是你別讓我加班,第一天弄的太晚,直接影響第二天工作效率,這樣得不償失”
工作只是生活的一部分,如果每天9點以後下班,就表示沒時間陪家人,沒時間娛樂活動,沒時間弄好吃的,沒有時間做自己感興趣的事情,到家直接洗洗睡,第二天醒來繼續上班,這樣的生活豈不是很無趣,加班是罪魁禍首。
寫程序是腦力勞動與體力勞動的結合,聚精會神寫一整天代碼,效率很高,但到了下班點,整個人會非常疲乏,如果繼續工作,會影響第二天狀態,所以後面所謂的加班其實是在划水,根本做不了什麼東西。當然,也可以平均分佈工作和划水,正常上班時也不用那麼認真,那麼加班的時候好像還能做點東西, 但是一整天的總工作成果沒有變化。所以,與其把工作分佈到12個小時,還不如前8個小時多做產出,后4個小時下班回家,這樣有效工作量並不會減少,還有了自由時間, 只是看起來沒那麼积極,但不用怕完不成工作而被問責。
程序員俗稱碼農,也叫IT民工,這是自黑,可在不懂技術的領導眼中就跟搬磚工沒區別,在他們眼裡,程序員多加班一小時,就會多一小時工作成果,搬磚嘛,或多或少總能搬幾塊。他們不知道,寫程序雖然不像搞藝術,非常依賴靈感,沒靈感什麼都幹不成,但在精神良好、腦子靈活的狀態下,工作效率絕對要高於無精打采、混混沌沌的狀態,有時候幾小時搞不定的問題,忽然間靈光一閃就能解決,這就不是靠加班加出來的。良好的工作狀態下產生的工作成果不是靠堆時間可以趕超的。所以很多時候在一個不開明的領導指揮下,團隊所有人看似很努力的在加班工作,其實所花的時間都是沒有意義的冤枉時間,原本這些時間可以做更有意義的事情。
還有一種加班,更加無厘頭,這種加班叫做:我也不知道為什麼要加班,別人在加, 那麼我也加一會。
這種加班,到下班時間點后員工們手上的工作停下來了,但沒人動屁股,大家看網頁的看網頁,看視頻的看視頻,打遊戲的打遊戲,下班,不存在的。因為別人都在加班,我下班了,感覺就像在犯罪,有強烈的罪惡感。這種加班比前一種加班更加可惡,沒半分實際意義, 但是偏偏就很難打破。其實每個人都在抱怨,可又沒有人敢越雷池一步。
說實話我挺佩服能不加班的人,雖然加班有很多外部因素,比如工作真的忙,比如公司文化就是這樣,在比如領導犯渾,但加班表達出來的意思其實就是工作任務完不成了,要多花時間。那麼不加班也意味着在正常的工作時間內能游刃有餘的完成工作,是能力的體現。
我也想實現這個夢想,所以我拒絕加班,領導也同意了,他說:“那你自己看着辦吧, 我不強迫你”,然而我知道,我在這家公司只能在地板上混了,連天花板都別想碰到,更別談升級,但是我覺得值,因為我想要更多的自由生活時間。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
引用自: 《重構 改善既有代碼的設計》
重構是在不改變軟件可觀察行為的前提下改善其內部結構。當你面對一個最需要重構的遺留系統時,其規模之大、歷史之久、代碼質量之差,常會使得添加單元測試或者理解其邏輯都成為不可能的任務。此時你唯一能依靠的就是那些已經被證明是行為保持的重構手法: 用絕對安全的手法從焦油坑中整理出可測試的接口,給它添加測試,以此作為繼續重構的立足點。
因為我們部門內容平台的文章系統之前遺留了很多問題,急需解決這些具有”壞味道”的代碼。最後因為其他人手頭裡都有其他工作,最後這些任務就交給了我。以下是急需解決的問題。
內容平台新增/更新/取消/刪除文章,同步各集團下文章行為狀態,消息鏈路過長的問題。
問題導火索: 運營後台文章發布,發送消息到marketing-base
慢鏈路,鏈路過長
mysql數據同步,單條執行n次
es索引數據同步,dubbo接口調用n次
圖1 鏈路圖
//開啟同步開關的集團
List<Integer> groupList = autoSyncStatusService.getAutoSyncGroupByManageType(MANAGE_TYPE_GROUP_ARTICLE);
for (Integer groupId : syncSubjectList) {
SiteGroupInfoDTO siteGroupInfo = siteSPI.getGroupInfoById(groupId);
Set<String> groupBrandSet = carOnSaleManage.getGroupBrandSet(siteGroupInfo);
List<String> matchedBrandCodes = extractBrandCodesFromArticleLabel(article.getLabelInfos());
if (CollectionUtils.isEmpty(matchedBrandCodes) || CollectionUtils.containsAny(groupBrandSet, matchedBrandCodes)) {
ArticleGroupMaterialBO groupMaterialBO =
ArticleBeanConverter.convertMaterial2GroupMaterial(article, groupId, groupList);
// 設置對應的集團主題id
ArticleGroupSubjectBO groupSubjectBO =
articleGroupSubjectService.getGroupSubjectBySoucheId(groupId, article.getSubjectId());
if (Objects.nonNull(groupSubjectBO.getId())) {
groupMaterialBO.setSubjectId(groupSubjectBO.getId());
groupMaterialBO.setMaterialId(myArticleId);
articleGroupMaterialService.addArticleGroupMaterial(groupMaterialBO);
}
}
} else {
//查詢同步的文章數據是否存在
List<ArticleGroupMaterialBO> list = articleGroupMaterialService.getListByMaterialId(myArticleId);
for (ArticleGroupMaterialBO a : list) {
if (groupList.contains(a.getGroupId())) {
articleGroupMaterialService.changeRecommendStatus(a.getId(), a.getGroupId(), recommend, article.getLastOperatorName(), article.getLastOperatorName());
}
}
}第4行中我們可以看到這裡有一個for循環️,假設開啟同步開關的集體有1000家,則第18行中mysql插入操作就需要執行1000次。
第24行這裏同樣有一個for循環體️,則26行內部的es數據同步則需要調用1000次。它的實現如下:
@Override
public boolean changeRecommendStatus(int id, int groupId, int recommended, String lastOperatorUserId, String lastOperatorName) {
final boolean success = articleGroupMaterialDAO.changeRecommendStatus(
id, groupId, recommended, lastOperatorUserId, lastOperatorName) > 0;
if (success) {
//更新索引,更改推薦狀態
articleSearchManage.updateArticleIndex(ArticleIndexUtil.getUpdateRecommendIndex(recommended, id, lastOperatorName));
}
return success;
}對於第一個循環️體中,我們需要將數據批量添加到數據庫,mybatis提供了將list集合循環添加到數據庫的方法。
insertForeach(List < Fund > list) 方法,返回值是批量添加的數據條數public interface FundMapper {
int insertForeach(List<Fund> list);
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.center.manager.mapper.FundMapper">
<insert id="insertForeach" parameterType="java.util.List" useGeneratedKeys="false">
insert into fund
( id,fund_name,fund_code,date_x,data_y,create_by,create_date,update_by,update_date,remarks,del_flag)
values
<foreach collection="list" item="item" index="index" separator=",">
(
#{item.id},
#{item.fundName},
#{item.fundCode},
#{item.dateX},
#{item.dataY},
#{item.createBy},
#{item.createDate},
#{item.updateBy},
#{item.updateDate},
#{item.remarks},
#{item.delFlag}
)
</foreach>
</insert>
</mapper>com.souche.elastic.search.api.IndexService
方法:BulkUpdateResponse bulkUpdate(String index, Map<String, Object> event, String query, String origin)
參數:
index:要操作的索引
event:更新的數據,可以只包含需要更新的字段,相當於mysql的update語句中的set語句中的字段
query:query中的條件相當於mysql中的where,具體語法與下面的搜索接口中【querys:string 複雜的複合查詢 不同字段的OR 查詢】相同
origin:操作源,一般寫調用方自己的應用名,用於區分不同調用方
返回值:
BulkUpdateResponse:
{
requestId:本次操作的唯一標示
status:狀態,目前返回默認都是true
updated:成功更新的條數
failed:更新失敗的條數
message:第一條更新失敗的原因
}
調用示例:1Map<String, Object> data = new HashMap<>();
2 data.put("id", 20);
3 data.put("title", "xue yin");
4 data.put("content", "kuang dao");
5 BulkUpdateResponse response = indexService.bulkUpdate("test_index", data, "address=bj AND contry=cn", "shenfl");這條更新將test_index索引中所有 address是bj並且contry是cn 的數據的 title更新成‘xue yin’ content更新成‘kuang dao’,注意:address和contry兩個字段在索引中需要加索引
當前article數據表數據量:
select count(*) as 總數 from article;結果如下:
總數
369737 @Override
public String addSharedArticle(ArticleBO articleBO) {
ArticleDO articleDO = new ArticleDO();
BeanUtils.copyProperties(articleBO, articleDO);
String shortUUID = UUIDUtil.getShortUUID();
articleDO.setUid(shortUUID);
if (articleDAO.addSharedArticle(articleDO) > 0) {
return shortUUID;
}
return StringUtil.EMPTY_STRING;
}從上面這個業務邏輯實現類中,我們可以看到事實上我們想得到的是插入表數據的uid。但是之前的邏輯中,我們並沒有判斷該條數據是否已經存在,我們需要在上面代碼中判斷數據是否存在,已存在,查詢最後一天數據的uid返回給上層。不存在的話,執行插入操作。
article_material | CREATE TABLE `article_material` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`my_article_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '內容平台我的文章id',
`status` tinyint(3) unsigned NOT NULL COMMENT '1-待發布、2-發布、3-取消發布',
`subject_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '主題id',
`platform_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '平台id',
`source` varchar(32) NOT NULL DEFAULT '' COMMENT '版塊',
`crawler_article_id` varchar(32) NOT NULL DEFAULT '0' COMMENT '爬蟲的文章id',
`title` varchar(64) NOT NULL DEFAULT '' COMMENT '標題',
`cover_img` varchar(128) NOT NULL COMMENT '封面圖',
`summary` varchar(255) NOT NULL DEFAULT '' COMMENT '摘要',
`labels` varchar(512) NOT NULL DEFAULT '' COMMENT '標籤',
`label_infos` varchar(1024) NOT NULL DEFAULT '' COMMENT '標籤詳細信息',
`content` text NOT NULL COMMENT '內容,用戶看到的',
`content_imgs` text NOT NULL COMMENT '內容中圖片',
`content_videos` varchar(255) NOT NULL DEFAULT '' COMMENT '內容中視頻',
`content_draft` text NOT NULL COMMENT '草稿內容,編輯后保存到這裏,發布后內容會複製到content,此字段清空',
`content_imgs_draft` text NOT NULL COMMENT '草稿內容的圖片,同上',
`content_videos_draft` varchar(255) NOT NULL DEFAULT '' COMMENT '草稿內容的視頻',
`recommended` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '0-不推薦、1-推薦',
`author_user_id` varchar(64) NOT NULL DEFAULT '' COMMENT '作者userId',
`author_name` varchar(16) NOT NULL COMMENT '作者名稱',
`last_operator_user_id` varchar(64) NOT NULL DEFAULT '' COMMENT '最後操作人userId',
`last_operator_name` varchar(16) NOT NULL COMMENT '最後操作人名字',
`publish_date` datetime DEFAULT NULL COMMENT '發布時間',
`publisher_user_id` varchar(64) NOT NULL DEFAULT '' COMMENT '發布者userId',
`publisher_name` varchar(16) NOT NULL DEFAULT '' COMMENT '發布者名字',
`pv` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '流量pv',
`uv` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '流量uv',
`share_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '分享次數',
`share_people_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '分享人數',
`date_create` datetime NOT NULL,
`date_update` datetime NOT NULL,
`date_delete` datetime DEFAULT NULL,
`deleted` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '0 表示未刪除,刪除后是毫秒級時間戳',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_id` (`my_article_id`),
KEY `idx_title_label_status` (`subject_id`,`platform_id`,`title`,`label_infos`(255),`source`)
) ENGINE=InnoDB AUTO_INCREMENT=861 DEFAULT CHARSET=utf8 COMMENT='文章素材庫,給集團提供文章素材'上表中content, content_imgs,content_videos都是text類型等大字段,對於這種類型,我們需要把這種類型的表拆分成2張表 article_metedata和article_content 兩張表。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
文:宋瑞文(媽媽監督核電廠聯盟特約撰述)
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
據報導,特斯拉將於3月31日發佈全新MODEL 3車型,新車將於同期開始接受預訂,最快有望於2017年晚些時候交付客戶。新車的預估售價約為35000美元(約合人民幣22.77萬元)。
發佈當日,特斯拉將同期開始接受現場預訂,訂金為1000美元(約合人民幣6506元),次日(4月1日)起接受線上預訂,而新車實際交付將會於2017年晚些時候進行。根據消息,預售價為35000美元(約合人民幣22.77萬元)的MODEL 3作為入門車型,其電池續航里程或低於定位更高的MODEL S和MODEL X車型。即將發佈的MODEL 3車型為一款三廂轎車,但未來不排除有跨界版本出現的可能。
特斯拉CEO埃隆•馬斯克曾經表示,MODEL 3未來有望在中國投產,而價格預計只有MODEL S的一半。作為特斯拉的入門車型,MODEL 3將是一款肩負走量任務的產品,適合進行當地語系化生產。未來國產後,其價格可能會下降三分之一。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
MySQL InnoDB支持三種行鎖定
行鎖(Record Lock):鎖直接加在索引記錄上面,鎖住的是key。
間隙鎖(Gap Lock):鎖定索引記錄間隙,確保索引記錄的間隙不變。間隙鎖是針對事務隔離級別為可重複讀或以上級別而設計的。
后碼鎖(Next-Key Lock):行鎖和間隙鎖組合起來就叫Next-Key Lock。
默認情況下,InnoDB工作在可重複讀隔離級別下,並且會以Next-Key Lock的方式對數據行進行加鎖,這樣可以有效防止幻讀的發生。Next-Key Lock是行鎖和間隙鎖的組合,當InnoDB掃描索引記錄的時候,會首先對索引記錄加上行鎖(Record Lock),再對索引記錄兩邊的間隙加上間隙鎖(Gap Lock)。加上間隙鎖之後,其他事務就不能在這個間隙修改或者插入記錄。
create table x(`id` int, `num` int, index `idx_id` (`id`));
insert into x values(1, 1), (2, 2);
-- 事務A
START TRANSACTION;
update x set id = 1 where id = 1;
-- 事務B
-- 如果事務A沒有commit,id=1的記錄拿不到X鎖,將出現等待
START TRANSACTION;
update x set id = 1 where id = 1;
-- 事務C
-- id=2的記錄可以拿到X鎖,不會出現等待
START TRANSACTION;
update x set id = 2 where id = 2;-- 事務A
START TRANSACTION;
update x set num = 1 where num = 1;
-- 事務B
-- 由於事務A中num字段上沒有索引將產生表鎖,導致整張表的寫操作都會出現等待
START TRANSACTION;
update x set num = 1 where num = 1;
-- 事務C
-- 同理,會出現等待
START TRANSACTION;
update x set num = 2 where num = 2;
-- 事務D
-- 等待
START TRANSACTION;
insert into x values(3, 3);在MySQL中select稱為快照讀,不需要鎖,而insert、update、delete、select for update則稱為當前讀,需要給數據加鎖,幻讀中的“讀”即是針對當前讀。
RR事務隔離級別允許存在幻讀,但InnoDB RR級別卻通過Gap鎖避免了幻讀
測試環境
MySQL,InnoDB,默認的隔離級別(RR)數據表
CREATE TABLE `test` (
`id` int(1) NOT NULL AUTO_INCREMENT,
`name` varchar(8) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;數據
INSERT INTO `test` VALUES ('1', '小羅');
INSERT INTO `test` VALUES ('5', '小黃');
INSERT INTO `test` VALUES ('7', '小明');
INSERT INTO `test` VALUES ('11', '小紅');以上數據,會生成隱藏間隙
(-infinity, 1]
(1, 5]
(5, 7]
(7, 11]
(11, +infinity]
/* 開啟事務1 */
BEGIN;
/* 查詢 id = 5 的數據並加記錄鎖 */
SELECT * FROM `test` WHERE `id` = 5 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
-- 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條添加語句
/* 事務2插入一條 name = '小張' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (4, '小張'); # 正常執行
/* 事務3插入一條 name = '小張' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (8, '小東'); # 正常執行
/* 提交事務1,釋放事務1的鎖 */
COMMIT;以上,由於主鍵是唯一索引,而且是只使用一個索引查詢,並且只鎖定一條記錄,所以,只會對 id = 5 的數據加上記錄鎖,而不會產生間隙鎖。
/* 開啟事務1 */
BEGIN;
/* 查詢 id 在 7 - 11 範圍的數據並加記錄鎖 */
SELECT * FROM `test` WHERE `id` BETWEEN 5 AND 7 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
-- 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條添加語句
/* 事務2插入一條 id = 3,name = '小張1' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (3, '小張1'); # 正常執行
/* 事務3插入一條 id = 4,name = '小白' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (4, '小白'); # 正常執行
/* 事務4插入一條 id = 6,name = '小東' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (6, '小東'); # 阻塞
/* 事務5插入一條 id = 8, name = '大羅' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (8, '大羅'); # 阻塞
/* 事務6插入一條 id = 9, name = '大東' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (9, '大東'); # 阻塞
/* 事務7插入一條 id = 11, name = '李西' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (11, '李西'); # 阻塞
/* 事務8插入一條 id = 12, name = '張三' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (12, '張三'); # 正常執行
/* 提交事務1,釋放事務1的鎖 */
COMMIT;從上面我們可以看到,(5, 7]、(7, 11] 這兩個區間,都不可插入數據,其它區間,都可以正常插入數據。所以當我們給 (5, 7] 這個區間加鎖的時候,會鎖住 (5, 7]、(7, 11] 這兩個區間。
/* 開啟事務1 */
BEGIN;
/* 查詢 id = 3 這一條不存在的數據並加記錄鎖 */
SELECT * FROM `test` WHERE `id` = 3 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
-- 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條添加語句
/* 事務2插入一條 id = 3,name = '小張1' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (2, '小張1'); # 阻塞
/* 事務3插入一條 id = 4,name = '小白' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (4, '小白'); # 阻塞
/* 事務4插入一條 id = 6,name = '小東' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (6, '小東'); # 正常執行
/* 事務5插入一條 id = 8, name = '大羅' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (8, '大羅'); # 正常執行
/* 提交事務1,釋放事務1的鎖 */
COMMIT;我們可以看出,指定查詢某一條記錄時,如果這條記錄不存在,會產生間隙鎖
結論
id = 5 FOR UPDATE;id BETWEEN 5 AND 7 FOR UPDATE;數據準備
創建 test1 表:
CREATE TABLE `test1` (
`id` int(1) NOT NULL AUTO_INCREMENT,
`number` int(1) NOT NULL COMMENT '数字',
PRIMARY KEY (`id`),
KEY `number` (`number`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;id 是主鍵,number上建立了一個普通索引。先加一些數據:
INSERT INTO `test1` VALUES (1, 1);
INSERT INTO `test1` VALUES (5, 3);
INSERT INTO `test1` VALUES (7, 8);
INSERT INTO `test1` VALUES (11, 12);test1表中 number 索引存在的隱藏間隙:
(-infinity, 1]
(1, 3]
(3, 8]
(8, 12]
(12, +infinity]
/* 開啟事務1 */
BEGIN;
/* 查詢 number = 5 的數據並加記錄鎖 */
SELECT * FROM `test1` WHERE `number` = 3 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
-- 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條添加語句
/* 事務2插入一條 number = 0 的數據 */
INSERT INTO `test1` (`number`) VALUES (0); -- 正常執行
/* 事務3插入一條 number = 1 的數據 */
INSERT INTO `test1` (`number`) VALUES (1); -- 被阻塞
/* 事務4插入一條 number = 2 的數據 */
INSERT INTO `test1` (`number`) VALUES (2); -- 被阻塞
/* 事務5插入一條 number = 4 的數據 */
INSERT INTO `test1` (`number`) VALUES (4); -- 被阻塞
/* 事務6插入一條 number = 8 的數據 */
INSERT INTO `test1` (`number`) VALUES (8); -- 正常執行
/* 事務7插入一條 number = 9 的數據 */
INSERT INTO `test1` (`number`) VALUES (9); -- 正常執行
/* 事務8插入一條 number = 10 的數據 */
INSERT INTO `test1` (`number`) VALUES (10); -- 正常執行
/* 提交事務1 */
COMMIT;這裏可以看到,number (1 – 8) 的間隙中,插入語句都被阻塞了,而不在這個範圍內的語句,正常執行,這就是因為有間隙鎖的原因。
將數據還原成初始化的那樣
/* 開啟事務1 */
BEGIN;
/* 查詢 number = 5 的數據並加記錄鎖 */
SELECT * FROM `test1` WHERE `number` = 3 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
/* 事務1插入一條 id = 2, number = 1 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (2, 1); -- 阻塞
/* 事務2插入一條 id = 3, number = 2 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (3, 2); -- 阻塞
/* 事務3插入一條 id = 6, number = 8 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (6, 8); -- 阻塞
/* 事務4插入一條 id = 8, number = 8 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (8, 8); -- 正常執行
/* 事務5插入一條 id = 9, number = 9 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (9, 9); -- 正常執行
/* 事務6插入一條 id = 10, number = 12 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (10, 12); -- 正常執行
/* 事務7修改 id = 11, number = 12 的數據 */
UPDATE `test1` SET `number` = 5 WHERE `id` = 11 AND `number` = 12; -- 阻塞
/* 提交事務1 */
COMMIT;這裡有一個奇怪的現象:
事務3添加 id = 6,number = 8 的數據,給阻塞了;
事務4添加 id = 8,number = 8 的數據,正常執行了。
事務7將 id = 11,number = 12 的數據修改為 id = 11, number = 5的操作,給阻塞了;
這是為什麼呢?我們來看看下邊的圖
從圖中可以看出,當 number 相同時,會根據主鍵 id 來排序,所以:
事務3添加的 id = 6,number = 8,這條數據是在 (3, 8) 的區間裡邊,所以會被阻塞;
事務4添加的 id = 8,number = 8,這條數據則是在(8, 12)區間裡邊,所以不會被阻塞;
事務7的修改語句相當於在 (3, 8) 的區間裡邊插入一條數據,所以也被阻塞了。
后碼鎖是記錄鎖與間隙鎖的組合,它的封鎖範圍,既包含索引記錄,又包含索引區間。
注:Next-key Lock的主要目的,也是為了避免幻讀(Phantom Read)。如果把事務的隔離級別降級為RC,Next-key Lock則也會失效。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
摘錄自2019年12月25日東網報導
外形搶眼的虎鯨素來是水族館明星,惟圈養做法引來不合人道的質疑。美國佛羅里達州「奧蘭多海洋世界」(SeaWorld Orlando)近日宣布,明年元旦將取締虎鯨表演節目,改由介紹虎鯨的參觀項目取而代之。
虎鯨節目「一個海洋」自2011年推出,是一個主題圍繞保育的23分鐘表演,亦是海洋世界首個沒有訓練員在水中參與的項目。該節目下周二(31日)除夕將上演最後一場,其後會改為舉行名為「邂逅虎鯨」的參觀項目。
海洋世界的動物學團隊主管多爾德(Chris Dold)則介紹,新節目將向遊客解釋虎鯨在海洋生態中的角色,以及保護其棲息地的重要性等;又指節目具教育價值,與公園致力推廣動物救援及保護的信念相符。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
上一篇文章我們主要介紹了什麼是 Kafka,Kafka 的基本概念是什麼,Kafka 單機和集群版的搭建,以及對基本的配置文件進行了大致的介紹,還對 Kafka 的幾個主要角色進行了描述,我們知道,不管是把 Kafka 用作消息隊列、消息總線還是數據存儲平台來使用,最終是繞不過消息這個詞的,這也是 Kafka 最最核心的內容,Kafka 的消息從哪裡來?到哪裡去?都干什麼了?別著急,一步一步來,先說說 Kafka 的消息從哪來。
在 Kafka 中,我們把產生消息的那一方稱為生產者,比如我們經常回去淘寶購物,你打開淘寶的那一刻,你的登陸信息,登陸次數都會作為消息傳輸到 Kafka 後台,當你瀏覽購物的時候,你的瀏覽信息,你的搜索指數,你的購物愛好都會作為一個個消息傳遞給 Kafka 後台,然後淘寶會根據你的愛好做智能推薦,致使你的錢包從來都禁不住誘惑,那麼這些生產者產生的消息是怎麼傳到 Kafka 應用程序的呢?發送過程是怎麼樣的呢?
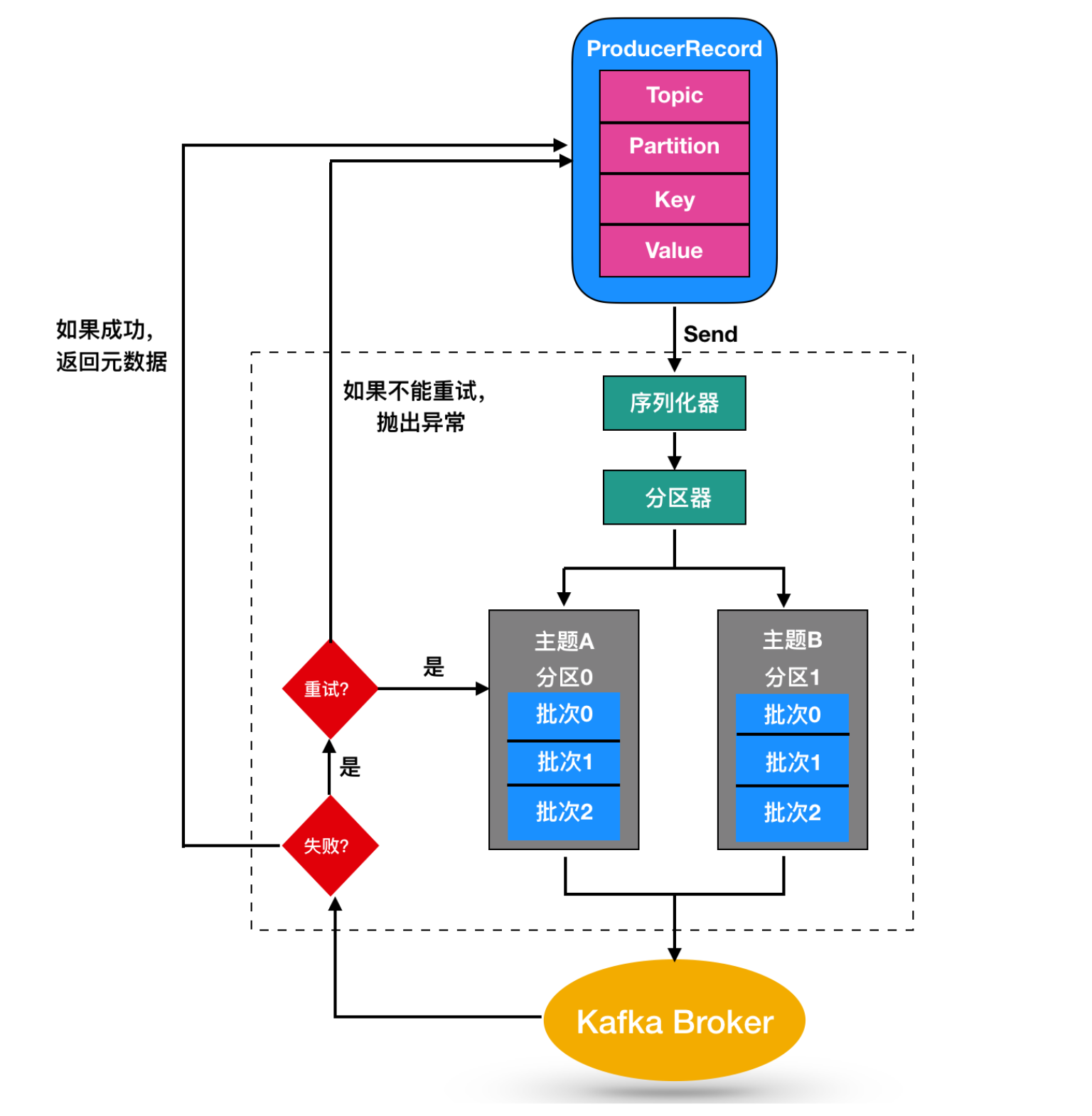
儘管消息的產生非常簡單,但是消息的發送過程還是比較複雜的,如圖
我們從創建一個ProducerRecord 對象開始,ProducerRecord 是 Kafka 中的一個核心類,它代表了一組 Kafka 需要發送的 key/value 鍵值對,它由記錄要發送到的主題名稱(Topic Name),可選的分區號(Partition Number)以及可選的鍵值對構成。
在發送 ProducerRecord 時,我們需要將鍵值對對象由序列化器轉換為字節數組,這樣它們才能夠在網絡上傳輸。然後消息到達了分區器。
如果發送過程中指定了有效的分區號,那麼在發送記錄時將使用該分區。如果發送過程中未指定分區,則將使用key 的 hash 函數映射指定一個分區。如果發送的過程中既沒有分區號也沒有,則將以循環的方式分配一個分區。選好分區后,生產者就知道向哪個主題和分區發送數據了。
ProducerRecord 還有關聯的時間戳,如果用戶沒有提供時間戳,那麼生產者將會在記錄中使用當前的時間作為時間戳。Kafka 最終使用的時間戳取決於 topic 主題配置的時間戳類型。
CreateTime,則生產者記錄中的時間戳將由 broker 使用。LogAppendTime,則生產者記錄中的時間戳在將消息添加到其日誌中時,將由 broker 重寫。然後,這條消息被存放在一個記錄批次里,這個批次里的所有消息會被發送到相同的主題和分區上。由一個獨立的線程負責把它們發到 Kafka Broker 上。
Kafka Broker 在收到消息時會返回一個響應,如果寫入成功,會返回一個 RecordMetaData 對象,它包含了主題和分區信息,以及記錄在分區里的偏移量,上面兩種的時間戳類型也會返回給用戶。如果寫入失敗,會返回一個錯誤。生產者在收到錯誤之後會嘗試重新發送消息,幾次之後如果還是失敗的話,就返回錯誤消息。
要往 Kafka 寫入消息,首先需要創建一個生產者對象,並設置一些屬性。Kafka 生產者有3個必選的屬性
該屬性指定 broker 的地址清單,地址的格式為 host:port。清單里不需要包含所有的 broker 地址,生產者會從給定的 broker 里查找到其他的 broker 信息。不過建議至少要提供兩個 broker 信息,一旦其中一個宕機,生產者仍然能夠連接到集群上。
broker 需要接收到序列化之後的 key/value值,所以生產者發送的消息需要經過序列化之後才傳遞給 Kafka Broker。生產者需要知道採用何種方式把 Java 對象轉換為字節數組。key.serializer 必須被設置為一個實現了org.apache.kafka.common.serialization.Serializer 接口的類,生產者會使用這個類把鍵對象序列化為字節數組。這裏拓展一下 Serializer 類
Serializer 是一個接口,它表示類將會採用何種方式序列化,它的作用是把對象轉換為字節,實現了 Serializer 接口的類主要有 ByteArraySerializer、StringSerializer、IntegerSerializer ,其中 ByteArraySerialize 是 Kafka 默認使用的序列化器,其他的序列化器還有很多,你可以通過 查看其他序列化器。要注意的一點:key.serializer 是必須要設置的,即使你打算只發送值的內容。
與 key.serializer 一樣,value.serializer 指定的類會將值序列化。
下面代碼演示了如何創建一個 Kafka 生產者,這裏只指定了必要的屬性,其他使用默認的配置
private Properties properties = new Properties();
properties.put("bootstrap.servers","broker1:9092,broker2:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties = new KafkaProducer<String,String>(properties);來解釋一下這段代碼
StringSerializer 序列化器序列化 key / value 鍵值對實例化生產者對象后,接下來就可以開始發送消息了,發送消息主要由下面幾種方式
直接發送,不考慮結果
使用這種發送方式,不會關心消息是否到達,會丟失一些消息,因為 Kafka 是高可用的,生產者會自動嘗試重發,這種發送方式和 UDP 運輸層協議很相似。
同步發送
同步發送仍然使用 send() 方法發送消息,它會返回一個 Future 對象,調用 get() 方法進行等待,就可以知道消息時候否發送成功。
異步發送
異步發送指的是我們調用 send() 方法,並制定一個回調函數,服務器在返迴響應時調用該函數。
下一節我們會重新討論這三種實現。
Kafka 最簡單的消息發送如下:
ProducerRecord<String,String> record =
new ProducerRecord<String, String>("CustomerCountry","West","France");
producer.send(record);代碼中生產者(producer)的 send() 方法需要把 ProducerRecord 的對象作為參數進行發送,ProducerRecord 有很多構造函數,這個我們下面討論,這裏調用的是
public ProducerRecord(String topic, K key, V value) {}這個構造函數,需要傳遞的是 topic主題,key 和 value。
把對應的參數傳遞完成后,生產者調用 send() 方法發送消息(ProducerRecord對象)。我們可以從生產者的架構圖中看出,消息是先被寫入分區中的緩衝區中,然後分批次發送給 Kafka Broker。
發送成功后,send() 方法會返回一個 Future(java.util.concurrent) 對象,Future 對象的類型是 RecordMetadata 類型,我們上面這段代碼沒有考慮返回值,所以沒有生成對應的 Future 對象,所以沒有辦法知道消息是否發送成功。如果不是很重要的信息或者對結果不會產生影響的信息,可以使用這種方式進行發送。
我們可以忽略發送消息時可能發生的錯誤或者在服務器端可能發生的錯誤,但在消息發送之前,生產者還可能發生其他的異常。這些異常有可能是 SerializationException(序列化失敗),BufferedExhaustedException 或 TimeoutException(說明緩衝區已滿),又或是 InterruptedException(說明發送線程被中斷)
第二種消息發送機制如下所示
ProducerRecord<String,String> record =
new ProducerRecord<String, String>("CustomerCountry","West","France");
try{
RecordMetadata recordMetadata = producer.send(record).get();
}catch(Exception e){
e.printStackTrace();
}
這種發送消息的方式較上面的發送方式有了改進,首先調用 send() 方法,然後再調用 get() 方法等待 Kafka 響應。如果服務器返回錯誤,get() 方法會拋出異常,如果沒有發生錯誤,我們會得到 RecordMetadata 對象,可以用它來查看消息記錄。
生產者(KafkaProducer)在發送的過程中會出現兩類錯誤:其中一類是重試錯誤,這類錯誤可以通過重發消息來解決。比如連接的錯誤,可以通過再次建立連接來解決;無主錯誤則可以通過重新為分區選舉首領來解決。KafkaProducer 被配置為自動重試,如果多次重試后仍無法解決問題,則會拋出重試異常。另一類錯誤是無法通過重試來解決的,比如消息過大對於這類錯誤,KafkaProducer 不會進行重試,直接拋出異常。
同步發送消息都有個問題,那就是同一時間只能有一個消息在發送,這會造成許多消息無法直接發送,造成消息滯后,無法發揮效益最大化。
比如消息在應用程序和 Kafka 集群之間一個來回需要 10ms。如果發送完每個消息后都等待響應的話,那麼發送100個消息需要 1 秒,但是如果是異步方式的話,發送 100 條消息所需要的時間就會少很多很多。大多數時候,雖然Kafka 會返回 RecordMetadata 消息,但是我們並不需要等待響應。
為了在異步發送消息的同時能夠對異常情況進行處理,生產者提供了回掉支持。下面是回調的一個例子
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("CustomerCountry", "Huston", "America");
producer.send(producerRecord,new DemoProducerCallBack());
class DemoProducerCallBack implements Callback {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null){
exception.printStackTrace();;
}
}
}首先實現回調需要定義一個實現了org.apache.kafka.clients.producer.Callback的類,這個接口只有一個 onCompletion方法。如果 kafka 返回一個錯誤,onCompletion 方法會拋出一個非空(non null)異常,這裏我們只是簡單的把它打印出來,如果是生產環境需要更詳細的處理,然後在 send() 方法發送的時候傳遞一個 Callback 回調的對象。
Kafka 對於數據的讀寫是以分區為粒度的,分區可以分佈在多個主機(Broker)中,這樣每個節點能夠實現獨立的數據寫入和讀取,並且能夠通過增加新的節點來增加 Kafka 集群的吞吐量,通過分區部署在多個 Broker 來實現負載均衡的效果。
上面我們介紹了生產者的發送方式有三種:不管結果如何直接發送、發送並返回結果、發送並回調。由於消息是存在主題(topic)的分區(partition)中的,所以當 Producer 生產者發送產生一條消息發給 topic 的時候,你如何判斷這條消息會存在哪個分區中呢?
這其實就設計到 Kafka 的分區機制了。
Kafka 的分區策略指的就是將生產者發送到哪個分區的算法。Kafka 為我們提供了默認的分區策略,同時它也支持你自定義分區策略。
如果要自定義分區策略的話,你需要显示配置生產者端的參數 Partitioner.class,我們可以看一下這個類它位於 org.apache.kafka.clients.producer 包下
public interface Partitioner extends Configurable, Closeable {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
public void close();
default public void onNewBatch(String topic, Cluster cluster, int prevPartition) {}
}Partitioner 類有三個方法,分別來解釋一下
topic,表示需要傳遞的主題;key 表示消息中的鍵值;keyBytes表示分區中序列化過後的key,byte數組的形式傳遞;value 表示消息的 value 值;valueBytes 表示分區中序列化后的值數組;cluster表示當前集群的原數據。Kafka 給你這麼多信息,就是希望讓你能夠充分地利用這些信息對消息進行分區,計算出它要被發送到哪個分區中。Closeable 接口能夠實現 close() 方法,在分區關閉時調用。其中與分區策略息息相關的就是 partition() 方法了,分區策略有下面這幾種
順序輪訓
順序分配,消息是均勻的分配給每個 partition,即每個分區存儲一次消息。就像下面這樣
上圖表示的就是輪訓策略,輪訓策略是 Kafka Producer 提供的默認策略,如果你不使用指定的輪訓策略的話,Kafka 默認會使用順序輪訓策略的方式。
隨機輪訓
隨機輪訓簡而言之就是隨機的向 partition 中保存消息,如下圖所示
實現隨機分配的代碼只需要兩行,如下
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());先計算出該主題總的分區數,然後隨機地返回一個小於它的正整數。
本質上看隨機策略也是力求將數據均勻地打散到各個分區,但從實際表現來看,它要遜於輪詢策略,所以如果追求數據的均勻分佈,還是使用輪詢策略比較好。事實上,隨機策略是老版本生產者使用的分區策略,在新版本中已經改為輪詢了。
按照 key 進行消息保存
這個策略也叫做 key-ordering 策略,Kafka 中每條消息都會有自己的key,一旦消息被定義了 Key,那麼你就可以保證同一個 Key 的所有消息都進入到相同的分區裏面,由於每個分區下的消息處理都是有順序的,故這個策略被稱為按消息鍵保序策略,如下圖所示
實現這個策略的 partition 方法同樣簡單,只需要下面兩行代碼即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();上面這幾種分區策略都是比較基礎的策略,除此之外,你還可以自定義分區策略。
壓縮一詞簡單來講就是一種互換思想,它是一種經典的用 CPU 時間去換磁盤空間或者 I/O 傳輸量的思想,希望以較小的 CPU 開銷帶來更少的磁盤佔用或更少的網絡 I/O 傳輸。如果你還不了解的話我希望你先讀完這篇文章 ,然後你就明白壓縮是怎麼回事了。
Kafka 的消息分為兩層:消息集合 和 消息。一個消息集合中包含若干條日誌項,而日誌項才是真正封裝消息的地方。Kafka 底層的消息日誌由一系列消息集合日誌項組成。Kafka 通常不會直接操作具體的一條條消息,它總是在消息集合這個層面上進行寫入操作。
在 Kafka 中,壓縮會發生在兩個地方:Kafka Producer 和 Kafka Consumer,為什麼啟用壓縮?說白了就是消息太大,需要變小一點 來使消息發的更快一些。
Kafka Producer 中使用 compression.type 來開啟壓縮
private Properties properties = new Properties();
properties.put("bootstrap.servers","192.168.1.9:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("compression.type", "gzip");
Producer<String,String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord<String,String> record =
new ProducerRecord<String, String>("CustomerCountry","Precision Products","France");上面代碼錶明該 Producer 的壓縮算法使用的是 GZIP
有壓縮必有解壓縮,Producer 使用壓縮算法壓縮消息后併發送給服務器后,由 Consumer 消費者進行解壓縮,因為採用的何種壓縮算法是隨着 key、value 一起發送過去的,所以消費者知道採用何種壓縮算法。
在上一篇文章 中,我們主要介紹了一下 kafka 集群搭建的參數,本篇文章我們來介紹一下 Kafka 生產者重要的配置,生產者有很多可配置的參數,在文檔里(
key.serializer
用於 key 鍵的序列化,它實現了 org.apache.kafka.common.serialization.Serializer 接口
value.serializer
用於 value 值的序列化,實現了 org.apache.kafka.common.serialization.Serializer 接口
acks
acks 參數指定了要有多少個分區副本接收消息,生產者才認為消息是寫入成功的。此參數對消息丟失的影響較大
同步 和 異步,Kafka 為了保證消息的高效傳輸會決定是同步發送還是異步發送。如果讓客戶端等待服務器的響應(通過調用 Future 中的 get() 方法),顯然會增加延遲,如果客戶端使用回調,就會解決這個問題。buffer.memory
此參數用來設置生產者內存緩衝區的大小,生產者用它緩衝要發送到服務器的消息。如果應用程序發送消息的速度超過發送到服務器的速度,會導致生產者空間不足。這個時候,send() 方法調用要麼被阻塞,要麼拋出異常,具體取決於 block.on.buffer.null 參數的設置。
compression.type
此參數來表示生產者啟用何種壓縮算法,默認情況下,消息發送時不會被壓縮。該參數可以設置為 snappy、gzip 和 lz4,它指定了消息發送給 broker 之前使用哪一種壓縮算法進行壓縮。下面是各壓縮算法的對比
retries
生產者從服務器收到的錯誤有可能是臨時性的錯誤(比如分區找不到首領),在這種情況下,reteis 參數的值決定了生產者可以重發的消息次數,如果達到這個次數,生產者會放棄重試並返回錯誤。默認情況下,生產者在每次重試之間等待 100ms,這個等待參數可以通過 retry.backoff.ms 進行修改。
batch.size
當有多個消息需要被發送到同一個分區時,生產者會把它們放在同一個批次里。該參數指定了一個批次可以使用的內存大小,按照字節數計算。當批次被填滿,批次里的所有消息會被發送出去。不過生產者井不一定都會等到批次被填滿才發送,任意條數的消息都可能被發送。
client.id
此參數可以是任意的字符串,服務器會用它來識別消息的來源,一般配置在日誌里
max.in.flight.requests.per.connection
此參數指定了生產者在收到服務器響應之前可以發送多少消息,它的值越高,就會佔用越多的內存,不過也會提高吞吐量。把它設為1 可以保證消息是按照發送的順序寫入服務器。
timeout.ms、request.timeout.ms 和 metadata.fetch.timeout.ms
request.timeout.ms 指定了生產者在發送數據時等待服務器返回的響應時間,metadata.fetch.timeout.ms 指定了生產者在獲取元數據(比如目標分區的首領是誰)時等待服務器返迴響應的時間。如果等待時間超時,生產者要麼重試發送數據,要麼返回一個錯誤。timeout.ms 指定了 broker 等待同步副本返回消息確認的時間,與 asks 的配置相匹配—-如果在指定時間內沒有收到同步副本的確認,那麼 broker 就會返回一個錯誤。
max.block.ms
此參數指定了在調用 send() 方法或使用 partitionFor() 方法獲取元數據時生產者的阻塞時間當生產者的發送緩衝區已捕,或者沒有可用的元數據時,這些方法就會阻塞。在阻塞時間達到 max.block.ms 時,生產者會拋出超時異常。
max.request.size
該參數用於控制生產者發送的請求大小。它可以指能發送的單個消息的最大值,也可以指單個請求里所有消息的總大小。
receive.buffer.bytes 和 send.buffer.bytes
Kafka 是基於 TCP 實現的,為了保證可靠的消息傳輸,這兩個參數分別指定了 TCP Socket 接收和發送數據包的緩衝區的大小。如果它們被設置為 -1,就使用操作系統的默認值。如果生產者或消費者與 broker 處於不同的數據中心,那麼可以適當增大這些值。
文章參考:
《Kafka 權威指南》
極客時間 -《Kafka 核心技術與實戰》
Kafka 源碼
關注公眾號獲取更多優質电子書,關注一下你就知道資源是有多好了
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開