環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
居家、公司行號垃圾清運、廢棄物處理、大型家具回收,服務快速,包月及計重或計桶供客戶選擇,合法登記的清潔公司、廢棄物清除許可,專業技術人員及專業廢棄物清運車輛
 |
全球各國很少在什麼事情上取得共識,對抗氣候變遷倒是頭一遭,讓各懷鬼胎的人類能夠一致以減少排放溫室氣體為目標。在這個願景下,各國想盡辦法減少碳排放,如台灣廠商將電動機車變成一種時尚,南韓則是立志要大力推廣氫動力汽車。
目前汽車製造商包括現代、豐田都有生產氫動力車,現代在 2013 年開始大量生產氫動力車,主要是在歐洲與加州銷售,豐田是在去年開始販售第一款消費性燃料電池汽車,但因全球氫動力車因為價格太高與缺少加氣站,銷售仍不見起色。 《華爾街日報》報導,巴黎氣候變遷會議之後,南韓宣誓未來五年要增加氫動力車銷售數量從現在的 50 輛到 9,000 輛,2030 年要到 63 萬輛,等於每賣出十輛新車,就有一輛是氫動力汽車。氫動力車結合氫與氧來產生電力,副產品就是從排氣管排放的水蒸氣。 南韓政府將補貼每輛氫動力車 275 萬韓圜,約當 23,250 美元,氫動力車售價大約 8,500 萬韓圜,接近 240 萬台幣,補貼約 3%。 除了補貼,南韓還要增加加氣站從目前的 10 座,到 2030 年的 520 座。南韓宣誓未來五年,減少運輸工具碳排放 11%,約 380 萬噸。低碳排放汽車包括混合動力車與電動車將在 2020 年占南韓總汽車銷售量的 20%,現在約 2%。
(首圖來源:)
(本文授權轉載自《》─〈〉)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
 |
Tesla 去(2015)年前三季在中國賣了約3000 輛Model S 和Model X 頂級款電動車,在全球全年交車輛更是達到50,580 輛,但有沒有可能,中國冒出的競爭對手會威脅Tesla 在電動車市場的領先地位?中國最大的汽車設計公司之一「北京長城華冠」在2015 年發表該公司第一款、也是中國第一款電動超跑「K50」,性能和價格都相當於Tesla Model S,而負責K50 生產的子公司「前途汽車」2 月於蘇州動土設廠,也意味著K50 量產在即。
K50 號稱5 秒就能加速至100公里,北京長城華冠董事長陸群受訪時說到,K50 有著碳纖維的車身、鋁製車架,預計2017 年就會亮相,售價約在70 萬人民幣(相當於10 萬6000 美元、345 萬台幣),價格相當於鋁製車身的Tesla Model S,而比起同樣是碳纖維車身的插電式油電混合車BMW i8,K50 的售價只有1/3。
陸群說,公司從Tesla 身上和其他電動車廠商身上學習,他們的目標就是打造高品質的汽車。前途汽車這個全資子公司自2015 年成立,任務就是打造電動汽車,而自己設廠,對他們來說是唯一的解決方案,因為在中國沒有其他在做碳纖維模型的工廠,這個花20 億人民幣打造的廠房,未來也會為其他車廠代工製造,預計初期的產值可以達到一年5 萬輛車。
至於在K50 之外,前途汽車也計畫再發表兩款便宜一些的電動車,陸群為前途汽車訂立目標,在2020 年獲得電動車市場15% 的市佔,又或者是45 萬輛。「我們會讓消費者相信,中國也是有能力打造一個全新的汽車品牌,一個頂尖的汽車品牌,一個頂尖的純電動車品牌。」陸群說。
分析師:打造電動車要看長期續航力
Bloomberg Intelligence 駐香港的汽車分析師Steve Man 是這樣看的,他認為前途汽車最終若要成功,得看他的行銷和市場聲望,但在那之前,打造一台經得起時間考驗的電動車可是需要相當多的耐心和資本,「我們就來看看前途有沒有這麼長的續航力」。
Elon Musk 對此表示,聽聽就好?
這番話透露出些許不信任的意味,至於身為市場領先者、被挑戰的對象,Tesla 創辦人兼執行長Elon Musk 又是怎麼看的呢?Elon Musk 曾在日前一場演講中對市場上充滿電動車和自駕車新近者眾多做出以下回應,「現在有太多新創公司發布電動車、自駕車的消息,我都在等哪天我媽也跳出來發布一輛。」
Elon Musk 這番話不是針對前途汽車,光是在中國市場,這類宣布要做電動車的新創公司可真不少。中國科技創業家李斌在2015 年創立「未來汽車」(NextEV,Inc),獲得騰訊和高瓴資本投資;樂視創辦人兼CEO賈躍亭在今年4 月也揭示一輛四門電動跑車「LeSEE」的概念;傳統車廠長安汽車也和福特合夥,投資180 億人民幣研發低能源汽車。
本文授權轉載自《科技新報》──〈〉
(首圖來源:截自官網)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※新北清潔公司,居家、辦公、裝潢細清專業服務
大眾汽車集團管理董事會成員、大眾汽車集團(中國)總裁兼CEO海茲曼接受媒體專訪時表示,大眾將以年均40億歐元(約287億人民幣)以上的投資規模加大對中國市場投資,資金主要來自大眾在中國合資企業;
部署新能源戰略達成百公里油耗5L目標
新能源車相關的投資將是大眾未來投資重點,對此,海茲曼表示,這一部署也是為了達成2020年前要達到產品平均油耗5L的目標。不僅是新能源,對於傳統能源乘用車大眾也在不斷的引入最新技術,將節油降耗的潛力進一步挖掘。
大眾汽車集團在華的新能源車戰略是一個階段性的戰略,分為三個階段。海茲曼稱,目前大眾正處於第一個階段,就是通過進口的方式來為中國車主提供插電 式混合動力車型以及純電動車,這包括保時捷Panamera插電式混合動力車型、奧迪A3插電式混合動力、GolfGTE、e-Golf以及e-up!等。
第二階段,從2016年開始,大眾將會尋求插電式混合動力車型在中國的本土生產。在插電式混合動力車型上實現國產的首先是奧迪A6,接下來就是大眾品牌一款C Model,與奧迪A6同級別的一款插電式混合動力車型。
第三階段,大眾計畫實現純電動新能源車在中國本土的生產,2020年之前大眾將實現第一款基於MQB平臺的純電動車型的國產。海茲曼強調,大眾戰略實現全面的國產化,包括零部件的國產化以及研發的當地語系化。
海茲曼表示,大眾會在2-3年期間內不斷的實現插電式混合動力車型的國產。在此之後的第三階段,大眾會啟動純電動車型在中國本土的生產。第三階段實 現國產化的新能源車就基於MLB和MQB平臺。MLB和MQB平臺可以實現協同增效的作用,能夠實現傳統發動機車型、插電式混合動力車型和純電動車型的共 線生產。
不僅如此,海茲曼稱,大眾將在華引入一條全新的電動車生產線,一汽大眾和上汽大眾都將會生產純電動車型。大眾在MLB和MQB平臺的基礎上,定制了一個MEB電動車模組化平臺,在續航里程上可以支援400公里-600公里長途續航里程。
目標:2020年在中國新能源車份額佔據第一
對於大眾新能源車銷售目標,海茲曼並不掩飾對於未來的信心,他表示,2020年中國的新能源車年銷售大約是200萬輛的規模,屆時大眾集團新能源車 在中國市場的銷量應該在幾十萬輛的水準。或者說,2020年,大眾集團在中國新能源車市場的份額應該是與其乘用車在中國整體乘用車的市場份額相似。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!
官網:
源代碼:
Spring Security 是強大的,且容易定製的,基於Spring開發的實現認證登錄與資源授權的應用安全框架。
SpringSecurity 的核心功能:
目前在java web應用安全框架中,與Spring Security形成直接競爭的就是shiro,二者在核心功能上幾乎差不多,但從使用的角度各有優缺點。筆者認為:沒有最好的,只有最合適的。
從使用情況上看,二者都在逐步提高使用量。shiro的使用量一直高於spring security.
通常來說,shiro入門更加容易,使用起來也非常簡單,這也是造成shiro的使用量一直高於Spring Security的主要原因。但是從筆者的角度來看,二者其實都簡單,我說說我的理由:
也就是說,如果有人能幫你把Spring Security最重要的那20%摘出來,二者的入門門檻、複雜度其實是差不太多的。
Spring Security依託於Spring龐大的社區支持,這點自不必多說。shiro屬於apache社區,因為它的廣泛使用,文檔也非常的全面。二者從社區支持來看,幾乎不相上下。
但是從社區發展的角度看,Spring Security明顯更佔優勢,隨着Spring Cloud、Spring Boot、Spring Social的長足進步,這種優勢會越來越大。因為Spring Security畢竟是Spring的親兒子,Spring Security未來在於Spring系列框架集成的時候一定會有更好的融合性,前瞻性、兼容性!這也是為什麼我們要學Spring Security的主要原因!
Spring Security因為它的複雜,所以從功能的豐富性的角度更勝一籌。其中比較典型的如:
如果你只是想實現一個簡單的web應用,shiro更加的輕量級,學習成本也更低。如果您正在開發一個分佈式的、微服務的、或者與Spring Cloud系列框架深度集成的項目,筆者還是建議您使用Spring Security。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
動態規劃難嗎?說實話,我覺得很難,特別是對於初學者來說,我當時入門動態規劃的時候,是看 0-1 背包問題,當時真的是一臉懵逼。後來,我遇到動態規劃的題,看的懂答案,但就是自己不會做,不知道怎麼下手。就像做遞歸的題,看的懂答案,但下不了手,關於遞歸的,我之前也寫過一篇套路的文章,如果對遞歸不大懂的,強烈建議看一看:
對於動態規劃,春招秋招時好多題都會用到動態規劃,一氣之下,再 leetcode 連續刷了幾十道題
之後,豁然開朗 ,感覺動態規劃也不是很難,今天,我就來跟大家講一講,我是怎麼做動態規劃的題的,以及從中學到的一些套路。相信你看完一定有所收穫
如果你對動態規劃感興趣,或者你看的懂動態規劃,但卻不知道怎麼下手,那麼我建議你好好看以下,這篇文章的寫法,和之前那篇講遞歸的寫法,是差不多一樣的,將會舉大量的例子。如果一次性看不完,建議收藏,同時別忘了素質三連。
為了兼顧初學者,我會從最簡單的題講起,後面會越來越難,最後面還會講解,該如何優化。因為 80% 的動規都是可以進行優化的。不過我得說,如果你連動態規劃是什麼都沒聽過,可能這篇文章你也會壓力山大。
動態規劃,無非就是利用歷史記錄,來避免我們的重複計算。而這些歷史記錄,我們得需要一些變量來保存,一般是用一維數組或者二維數組來保存。下面我們先來講下做動態規劃題很重要的三個步驟,
如果你聽不懂,也沒關係,下面會有很多例題講解,估計你就懂了。之所以不配合例題來講這些步驟,也是為了怕你們腦袋亂了
第一步驟:定義數組元素的含義,上面說了,我們會用一個數組,來保存歷史數組,假設用一維數組 dp[] 吧。這個時候有一個非常非常重要的點,就是規定你這個數組元素的含義,例如你的 dp[i] 是代表什麼意思?
第二步驟:找出數組元素之間的關係式,我覺得動態規劃,還是有一點類似於我們高中學習時的歸納法的,當我們要計算 dp[n] 時,是可以利用 dp[n-1],dp[n-2]…..dp[1],來推出 dp[n] 的,也就是可以利用歷史數據來推出新的元素值,所以我們要找出數組元素之間的關係式,例如 dp[n] = dp[n-1] + dp[n-2],這個就是他們的關係式了。而這一步,也是最難的一步,後面我會講幾種類型的題來說。
學過動態規劃的可能都經常聽到最優子結構,把大的問題拆分成小的問題,說時候,最開始的時候,我是對最優子結構一夢懵逼的。估計你們也聽多了,所以這一次,我將換一種形式來講,不再是各種子問題,各種最優子結構。所以大佬可別噴我再亂講,因為我說了,這是我自己平時做題的套路。
第三步驟:找出初始值。學過數學歸納法的都知道,雖然我們知道了數組元素之間的關係式,例如 dp[n] = dp[n-1] + dp[n-2],我們可以通過 dp[n-1] 和 dp[n-2] 來計算 dp[n],但是,我們得知道初始值啊,例如一直推下去的話,會由 dp[3] = dp[2] + dp[1]。而 dp[2] 和 dp[1] 是不能再分解的了,所以我們必須要能夠直接獲得 dp[2] 和 dp[1] 的值,而這,就是所謂的初始值。
由了初始值,並且有了數組元素之間的關係式,那麼我們就可以得到 dp[n] 的值了,而 dp[n] 的含義是由你來定義的,你想求什麼,就定義它是什麼,這樣,這道題也就解出來了。
不懂?沒事,我們來看三四道例題,我講嚴格按這個步驟來給大家講解。
問題描述:一隻青蛙一次可以跳上1級台階,也可以跳上2級。求該青蛙跳上一個n級的台階總共有多少種跳法。
按我上面的步驟說的,首先我們來定義 dp[i] 的含義,我們的問題是要求青蛙跳上 n 級的台階總共由多少種跳法,那我們就定義 dp[i] 的含義為:跳上一個 i 級的台階總共有 dp[i] 種跳法。這樣,如果我們能夠算出 dp[n],不就是我們要求的答案嗎?所以第一步定義完成。
我們的目的是要求 dp[n],動態規劃的題,如你們經常聽說的那樣,就是把一個規模比較大的問題分成幾個規模比較小的問題,然後由小的問題推導出大的問題。也就是說,dp[n] 的規模為 n,比它規模小的是 n-1, n-2, n-3…. 也就是說,dp[n] 一定會和 dp[n-1], dp[n-2]….存在某種關係的。我們要找出他們的關係。
那麼問題來了,怎麼找?
這個怎麼找,是最核心最難的一個,我們必須回到問題本身來了,來尋找他們的關係式,dp[n] 究竟會等於什麼呢?
對於這道題,由於情況可以選擇跳一級,也可以選擇跳兩級,所以青蛙到達第 n 級的台階有兩種方式
一種是從第 n-1 級跳上來
一種是從第 n-2 級跳上來
由於我們是要算所有可能的跳法的,所以有 dp[n] = dp[n-1] + dp[n-2]。
當 n = 1 時,dp[1] = dp[0] + dp[-1],而我們是數組是不允許下標為負數的,所以對於 dp[1],我們必須要直接給出它的數值,相當於初始值,顯然,dp[1] = 1。一樣,dp[0] = 0.(因為 0 個台階,那肯定是 0 種跳法了)。於是得出初始值:
dp[0] = 0.
dp[1] = 1.
即 n <= 1 時,dp[n] = n.
三個步驟都做出來了,那麼我們就來寫代碼吧,代碼會詳細註釋滴。
int f( int n ){
if(n <= 1)
return n;
// 先創建一個數組來保存歷史數據
int[] dp = new int[n+1];
// 給出初始值
dp[0] = 0;
dp[1] = 1;
// 通過關係式來計算出 dp[n]
for(int i = 2; i <= n; i++){
dp[i] = dp[i-1] + dp[-2];
}
// 把最終結果返回
return dp[n];
}大家先想以下,你覺得,上面的代碼有沒有問題?
答是有問題的,還是錯的,錯在對初始值的尋找不夠嚴謹,這也是我故意這樣弄的,意在告訴你們,關於初始值的嚴謹性。例如對於上面的題,當 n = 2 時,dp[2] = dp[1] + dp[0] = 1。這顯然是錯誤的,你可以模擬一下,應該是 dp[2] = 2。
也就是說,在尋找初始值的時候,一定要注意不要找漏了,dp[2] 也算是一個初始值,不能通過公式計算得出。有人可能會說,我想不到怎麼辦?這個很好辦,多做幾道題就可以了。
下面我再列舉三道不同的例題,並且,再在未來的文章中,我也會持續按照這個步驟,給大家找幾道有難度且類型不同的題。下面這幾道例題,不會講的特性詳細哈。實際上 ,上面的一維數組是可以把空間優化成更小的,不過我們現在先不講優化的事,下面的題也是,不講優化版本。
我做了幾十道 DP 的算法題,可以說,80% 的題,都是要用二維數組的,所以下面的題主要以二維數組為主,當然有人可能會說,要用一維還是二維,我怎麼知道?這個問題不大,接着往下看。
一個機器人位於一個 m x n 網格的左上角 (起始點在下圖中標記為“Start” )。
機器人每次只能向下或者向右移動一步。機器人試圖達到網格的右下角(在下圖中標記為“Finish”)。
問總共有多少條不同的路徑?
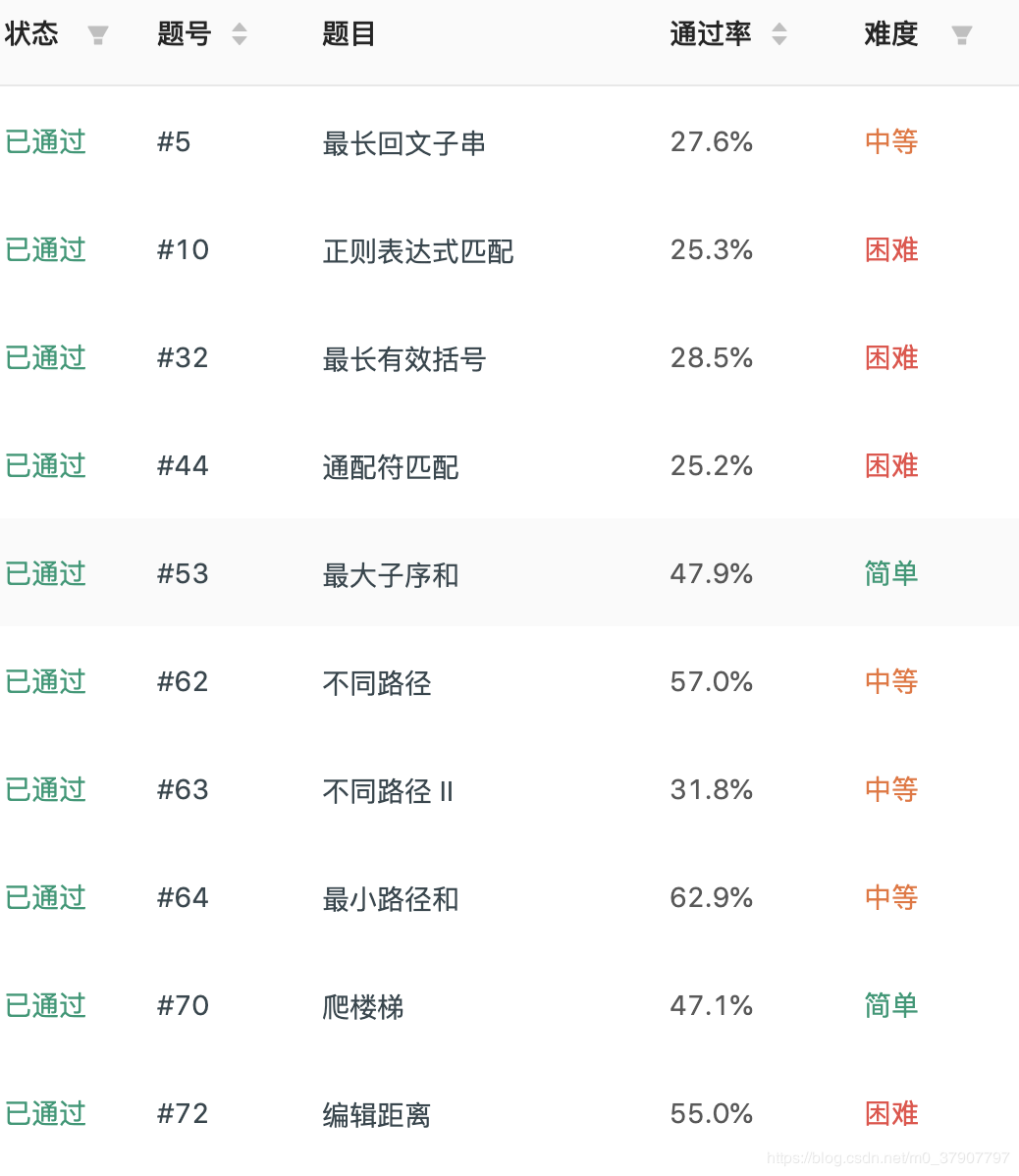
這是 leetcode 的 62 號題:
還是老樣子,三個步驟來解決。
由於我們的目的是從左上角到右下角一共有多少種路徑,那我們就定義 dp[i] [j]的含義為:當機器人從左上角走到(i, j) 這個位置時,一共有 dp[i] [j] 種路徑。那麼,dp[m-1] [n-1] 就是我們要的答案了。
注意,這個網格相當於一個二維數組,數組是從下標為 0 開始算起的,所以 右下角的位置是 (m-1, n – 1),所以 dp[m-1] [n-1] 就是我們要找的答案。
想象以下,機器人要怎麼樣才能到達 (i, j) 這個位置?由於機器人可以向下走或者向右走,所以有兩種方式到達
一種是從 (i-1, j) 這個位置走一步到達
一種是從(i, j – 1) 這個位置走一步到達
因為是計算所有可能的步驟,所以是把所有可能走的路徑都加起來,所以關係式是 dp[i] [j] = dp[i-1] [j] + dp[i] [j-1]。
顯然,當 dp[i] [j] 中,如果 i 或者 j 有一個為 0,那麼還能使用關係式嗎?答是不能的,因為這個時候把 i – 1 或者 j – 1,就變成負數了,數組就會出問題了,所以我們的初始值是計算出所有的 dp[0] [0….n-1] 和所有的 dp[0….m-1] [0]。這個還是非常容易計算的,相當於計算機圖中的最上面一行和左邊一列。因此初始值如下:
dp[0] [0….n-1] = 1; // 相當於最上面一行,機器人只能一直往左走
dp[0…m-1] [0] = 1; // 相當於最左面一列,機器人只能一直往下走
三個步驟都寫出來了,直接看代碼
public static int uniquePaths(int m, int n) {
if (m <= 0 || n <= 0) {
return 0;
}
int[][] dp = new int[m][n]; //
// 初始化
for(int i = 0; i < m; i++){
dp[i][0] = 1;
}
for(int i = 0; i < n; i++){
dp[0][i] = 1;
}
// 推導出 dp[m-1][n-1]
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}O(n*m) 的空間複雜度可以優化成 O(min(n, m)) 的空間複雜度的,不過這裏先不講
寫到這裏,有點累了,,但還是得寫下去,所以看的小夥伴,你們可得繼續看呀。下面這道題也不難,比上面的難一丟丟,不過也是非常類似
給定一個包含非負整數的 m x n 網格,請找出一條從左上角到右下角的路徑,使得路徑上的数字總和為最小。
說明:每次只能向下或者向右移動一步。
舉例:
輸入:
arr = [
[1,3,1],
[1,5,1],
[4,2,1]
]
輸出: 7
解釋: 因為路徑 1→3→1→1→1 的總和最小。和上面的差不多,不過是算最優路徑和,這是 leetcode 的第64題:
還是老樣子,可能有些人都看煩了,哈哈,但我還是要按照步驟來寫,讓那些不大懂的加深理解。有人可能覺得,這些題太簡單了吧,別慌,小白先入門,這些屬於 medium 級別的,後面在給幾道 hard 級別的。
由於我們的目的是從左上角到右下角,最小路徑和是多少,那我們就定義 dp[i] [j]的含義為:當機器人從左上角走到(i, j) 這個位置時,最下的路徑和是 dp[i] [j]。那麼,dp[m-1] [n-1] 就是我們要的答案了。
注意,這個網格相當於一個二維數組,數組是從下標為 0 開始算起的,所以 由下角的位置是 (m-1, n – 1),所以 dp[m-1] [n-1] 就是我們要走的答案。
想象以下,機器人要怎麼樣才能到達 (i, j) 這個位置?由於機器人可以向下走或者向右走,所以有兩種方式到達
一種是從 (i-1, j) 這個位置走一步到達
一種是從(i, j – 1) 這個位置走一步到達
不過這次不是計算所有可能路徑,而是計算哪一個路徑和是最小的,那麼我們要從這兩種方式中,選擇一種,使得dp[i] [j] 的值是最小的,顯然有
dp[i] [j] = min(dp[i-1][j],dp[i][j-1]) + arr[i][j];// arr[i][j] 表示網格種的值顯然,當 dp[i] [j] 中,如果 i 或者 j 有一個為 0,那麼還能使用關係式嗎?答是不能的,因為這個時候把 i – 1 或者 j – 1,就變成負數了,數組就會出問題了,所以我們的初始值是計算出所有的 dp[0] [0….n-1] 和所有的 dp[0….m-1] [0]。這個還是非常容易計算的,相當於計算機圖中的最上面一行和左邊一列。因此初始值如下:
dp[0] [j] = arr[0] [j] + dp[0] [j-1]; // 相當於最上面一行,機器人只能一直往左走
dp[i] [0] = arr[i] [0] + dp[i] [0]; // 相當於最左面一列,機器人只能一直往下走
public static int uniquePaths(int[][] arr) {
int m = arr.length;
int n = arr[0].length;
if (m <= 0 || n <= 0) {
return 0;
}
int[][] dp = new int[m][n]; //
// 初始化
dp[0][0] = arr[0][0];
// 初始化最左邊的列
for(int i = 1; i < m; i++){
dp[i][0] = dp[i-1][0] + arr[i][0];
}
// 初始化最上邊的行
for(int i = 1; i < n; i++){
dp[0][i] = dp[0][i-1] + arr[0][i];
}
// 推導出 dp[m-1][n-1]
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = Math.min(dp[i-1][j], dp[i][j-1]) + arr[i][j];
}
}
return dp[m-1][n-1];
}O(n*m) 的空間複雜度可以優化成 O(min(n, m)) 的空間複雜度的,不過這裏先不講
這次給的這道題比上面的難一些,在 leetcdoe 的定位是 hard 級別。好像是 leetcode 的第 72 號題。
問題描述
給定兩個單詞 word1 和 word2,計算出將 word1 轉換成 word2 所使用的最少操作數 。
你可以對一個單詞進行如下三種操作:
插入一個字符
刪除一個字符
替換一個字符
示例:
輸入: word1 = "horse", word2 = "ros"
輸出: 3
解釋:
horse -> rorse (將 'h' 替換為 'r')
rorse -> rose (刪除 'r')
rose -> ros (刪除 'e')解答
還是老樣子,按照上面三個步驟來,並且我這裏可以告訴你,90% 的字符串問題都可以用動態規劃解決,並且90%是採用二維數組。
由於我們的目的求將 word1 轉換成 word2 所使用的最少操作數 。那我們就定義 dp[i] [j]的含義為:當字符串 word1 的長度為 i,字符串 word2 的長度為 j 時,將 word1 轉化為 word2 所使用的最少操作次數為 dp[i] [j]。
有時候,數組的含義並不容易找,所以還是那句話,我給你們一個套路,剩下的還得看你們去領悟。
接下來我們就要找 dp[i] [j] 元素之間的關係了,比起其他題,這道題相對比較難找一點,但是,不管多難找,大部分情況下,dp[i] [j] 和 dp[i-1] [j]、dp[i] [j-1]、dp[i-1] [j-1] 肯定存在某種關係。因為我們的目標就是,**從規模小的,通過一些操作,推導出規模大的。對於這道題,我們可以對 word1 進行三種操作
插入一個字符
刪除一個字符
替換一個字符
由於我們是要讓操作的次數最小,所以我們要尋找最佳操作。那麼有如下關係式:
一、如果我們 word1[i] 與 word2 [j] 相等,這個時候不需要進行任何操作,顯然有 dp[i] [j] = dp[i-1] [j-1]。(別忘了 dp[i] [j] 的含義哈)。
二、如果我們 word1[i] 與 word2 [j] 不相等,這個時候我們就必須進行調整,而調整的操作有 3 種,我們要選擇一種。三種操作對應的關係試如下(注意字符串與字符的區別):
(1)、如果把字符 word1[i] 替換成與 word2[j] 相等,則有 dp[i] [j] = dp[i-1] [j-1] + 1;
(2)、如果在字符串 word1末尾插入一個與 word2[j] 相等的字符,則有 dp[i] [j] = dp[i] [j-1] + 1;
(3)、如果把字符 word1[i] 刪除,則有 dp[i] [j] = dp[i-1] [j] + 1;
那麼我們應該選擇一種操作,使得 dp[i] [j] 的值最小,顯然有
dp[i] [j] = min(dp[i-1] [j-1],dp[i] [j-1],dp[[i-1] [j]]) + 1;
於是,我們的關係式就推出來了,
顯然,當 dp[i] [j] 中,如果 i 或者 j 有一個為 0,那麼還能使用關係式嗎?答是不能的,因為這個時候把 i – 1 或者 j – 1,就變成負數了,數組就會出問題了,所以我們的初始值是計算出所有的 dp[0] [0….n] 和所有的 dp[0….m] [0]。這個還是非常容易計算的,因為當有一個字符串的長度為 0 時,轉化為另外一個字符串,那就只能一直進行插入或者刪除操作了。
public int minDistance(String word1, String word2) {
int n1 = word1.length();
int n2 = word2.length();
int[][] dp = new int[n1 + 1][n2 + 1];
// dp[0][0...n2]的初始值
for (int j = 1; j <= n2; j++)
dp[0][j] = dp[0][j - 1] + 1;
// dp[0...n1][0] 的初始值
for (int i = 1; i <= n1; i++) dp[i][0] = dp[i - 1][0] + 1;
// 通過公式推出 dp[n1][n2]
for (int i = 1; i <= n1; i++) {
for (int j = 1; j <= n2; j++) {
// 如果 word1[i] 與 word2[j] 相等。第 i 個字符對應下標是 i-1
if (word1.charAt(i - 1) == word2.charAt(j - 1)){
p[i][j] = dp[i - 1][j - 1];
}else {
dp[i][j] = Math.min(Math.min(dp[i - 1][j - 1], dp[i][j - 1]), dp[i - 1][j]) + 1;
}
}
}
return dp[n1][n2];
}最後說下,如果你要練習,可以去 leetcode,選擇動態規劃專題,然後連續刷幾十道,保證你以後再也不怕動態規劃了。當然,遇到很難的,咱還是得掛。
Leetcode 動態規劃直達:
前两天寫一篇長達 8000 子的關於動態規劃的文章
這篇文章更多講解我平時做題的套路,不過由於篇幅過長,舉了 4 個案例之後,沒有講解優化,今天這篇文章就來講解下,對動態規劃的優化如何下手,並且以前幾天那篇文章的題作為例子直接講優化,如果沒看過的建議看一下(不看也行,我會直接給出題目以及沒有優化前的代碼):
沒錯,80% 的動態規劃題都可以畫圖,其中 80% 的題都可以通過畫圖一下子知道怎麼優化,當然,DP 也有一些很難的題,想優化可沒那麼容易,不過,今天我要講的,是屬於不怎麼難,且最常見,面試筆試最經常考的難度的題。
下面我們直接通過三道題目來講解優化,你會發現,這些題,優化過後,代碼只有細微的改變,你只要會一兩道,可以說是會了 80% 的題。
上次那個青蛙跳台階的 dp 題是可以把空間複雜度 O( n) 優化成 O(1),本來打算從這道題講起的,但想了下,想要學習 dp 優化的感覺至少都是 小小大佬了,所以就不講了,就從二維數組的 dp 講起。
一個機器人位於一個 m x n 網格的左上角 (起始點在下圖中標記為“Start” )。
機器人每次只能向下或者向右移動一步。機器人試圖達到網格的右下角(在下圖中標記為“Finish”)。
問總共有多少條不同的路徑?
這是 leetcode 的 62 號題:
這道題的 dp 轉移公式是 dp[i] [j] = dp[i-1] [j] + dp[i] [j-1],代碼如下
不懂的看我之前文章:
public static int uniquePaths(int m, int n) {
if (m <= 0 || n <= 0) {
return 0;
}
int[][] dp = new int[m][n]; //
// 初始化
for(int i = 0; i < m; i++){
dp[i][0] = 1;
}
for(int i = 0; i < n; i++){
dp[0][i] = 1;
}
// 推導出 dp[m-1][n-1]
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}這種做法的空間複雜度是 O(n * m),下面我們來講解如何優化成 O(n)。
dp[i] [j] 是一個二維矩陣,我們來畫個二維矩陣的圖,對矩陣進行初始化
然後根據公式 dp[i][j] = dp[i-1][j] + dp[i][j-1] 來填充矩陣的其他值。下面我們先填充第二行的值。
大家想一個問題,當我們要填充第三行的值的時候,我們需要用到第一行的值嗎?答是不需要的,不行你試試,當你要填充第三,第四….第 n 行的時候,第一行的值永遠不會用到,只要填充第二行的值時會用到。
根據公式 dp[i][j] = dp[i-1][j] + dp[i][j-1],我們可以知道,當我們要計算第 i 行的值時,除了會用到第 i – 1 行外,其他第 1 至 第 i-2 行的值我們都是不需要用到的,也就是說,對於那部分用不到的值我們還有必要保存他們嗎?
答是沒必要,我們只需要用一個一維的 dp[] 來保存一行的歷史記錄就可以了。然後在計算機的過程中,不斷着更新 dp[] 的值。單說估計你可能不好理解,下面我就手把手來演示下這個過程。
1、剛開始初始化第一行,此時 dp[0..n-1] 的值就是第一行的值。
2、接着我們來一邊填充第二行的值一邊更新 dp[i] 的值,一邊把第一行的值拋棄掉。
為了方便描述,下面我們用arr (i,j)表示矩陣中第 i 行 第 j 列的值。從 0 開始哈,就是說有第 0 行。
(1)、顯然,矩陣(1, 0) 的值相當於以往的初始化值,為 1。然後這個時候矩陣 (0,0)的值不在需要保存了,因為再也用不到了。
這個時候,我們也要跟着更新 dp[0] 的值了,剛開始 dp[0] = (0, 0),現在更新為 dp[0] = (1, 0)。
(2)、接着繼續更新 (1, 1) 的值,根據之前的公式 (i, j) = (i-1, j) + (i, j- 1)。即 (1,1)=(0,1)+(1,0)=2。
大家看圖,以往的二維的時候, dp[i][j] = dp[i-1] [j]+ dp[i][j-1]。現在轉化成一維,不就是 dp[i] = dp[i] + dp[i-1] 嗎?
即 dp[1] = dp[1] + dp[0],而且還動態幫我們更新了 dp[1] 的值。因為剛開始 dp[i] 的保存第一行的值的,現在更新為保存第二行的值。
(3)、同樣的道理,按照這樣的模式一直來計算第二行的值,順便把第一行的值拋棄掉,結果如下
此時,dp[i] 將完全保存着第二行的值,並且我們可以推導出公式
dp[i] = dp[i-1] + dp[i]
dp[i-1] 相當於之前的 dp[i-1][j],dp[i] 相當於之前的 dp[i][j-1]。
於是按照這個公式不停着填充到最後一行,結果如下:
最後 dp[n-1] 就是我們要求的結果了。所以優化之後,代碼如下:
public static int uniquePaths(int m, int n) {
if (m <= 0 || n <= 0) {
return 0;
}
int[] dp = new int[n]; //
// 初始化
for(int i = 0; i < n; i++){
dp[i] = 1;
}
// 公式:dp[i] = dp[i-1] + dp[i]
for (int i = 1; i < m; i++) {
// 第 i 行第 0 列的初始值
dp[0] = 1;
for (int j = 1; j < n; j++) {
dp[j] = dp[j-1] + dp[j];
}
}
return dp[n-1];
}接着我們來看昨天的另外一道題,就是編輯矩陣,這道題的優化和這一道有一點點的不同,上面這道 dp[i][j] 依賴於 dp[i-1][j] 和 dp[i][j-1]。而還有一種情況就是 dp[i][j] 依賴於 dp[i-1][j],dp[i-1][j-1] 和 dp[i][j-1]。
問題描述
給定兩個單詞 word1 和 word2,計算出將 word1 轉換成 word2 所使用的最少操作數 。
你可以對一個單詞進行如下三種操作:
插入一個字符
刪除一個字符
替換一個字符
示例:
輸入: word1 = "horse", word2 = "ros"
輸出: 3
解釋:
horse -> rorse (將 'h' 替換為 'r')
rorse -> rose (刪除 'r')
rose -> ros (刪除 'e')解答
昨天的代碼如下所示,不懂的記得看之前的文章哈:
public int minDistance(String word1, String word2) {
int n1 = word1.length();
int n2 = word2.length();
int[][] dp = new int[n1 + 1][n2 + 1];
// dp[0][0...n2]的初始值
for (int j = 1; j <= n2; j++)
dp[0][j] = dp[0][j - 1] + 1;
// dp[0...n1][0] 的初始值
for (int i = 1; i <= n1; i++) dp[i][0] = dp[i - 1][0] + 1;
// 通過公式推出 dp[n1][n2]
for (int i = 1; i <= n1; i++) {
for (int j = 1; j <= n2; j++) {
// 如果 word1[i] 與 word2[j] 相等。第 i 個字符對應下標是 i-1
if (word1.charAt(i - 1) == word2.charAt(j - 1)){
p[i][j] = dp[i - 1][j - 1];
}else {
dp[i][j] = Math.min(Math.min(dp[i - 1][j - 1], dp[i][j - 1]), dp[i - 1][j]) + 1;
}
}
}
return dp[n1][n2];
}沒有優化之間的空間複雜度為 O(n*m)
大家可以自己動手做下,按照上面的那個模式,你會優化嗎?
對於這道題其實也是一樣的,如果要計算 第 i 行的值,我們最多只依賴第 i-1 行的值,不需要用到第 i-2 行及其以前的值,所以一樣可以採用一維 dp 來處理的。
不過這個時候要注意,在上面的例子中,我們每次更新完 (i, j) 的值之後,就會把 (i, j-1) 的值拋棄,也就是說之前是一邊更新 dp[i] 的值,一邊把 dp[i] 的舊值拋棄的,不過在這道題中則不可以,因為我們還需要用到它。
哎呀,直接舉例子看圖吧,文字繞來繞去估計會繞暈你們。當我們要計算圖中 (i,j) 的值的時候,在案例1 中,我們值需要用到 (i-1, j) 和 (i, j-1)。(看圖中方格的顏色)
不過這道題中,我們還需要用到 (i-1, j-1) 這個值(但是這個值在以往的案例1 中,它會被拋棄掉)
所以呢,對於這道題,我們還需要一個額外的變量 pre 來時刻保存 (i-1,j-1) 的值。推導公式就可以從二維的
dp[i][j] = min(dp[i-1][j] , dp[i-1][j-1] , dp[i][j-1]) + 1轉化為一維的
dp[i] = min(dp[i-1], pre, dp[i]) + 1。所以呢,案例2 其實和案例1 差別不大,就是多了個變量來臨時保存。最終代碼如下(但是初學者話,代碼也沒那麼好寫)
public int minDistance(String word1, String word2) {
int n1 = word1.length();
int n2 = word2.length();
int[] dp = new int[n2 + 1];
// dp[0...n2]的初始值
for (int j = 0; j <= n2; j++)
dp[j] = j;
// dp[j] = min(dp[j-1], pre, dp[j]) + 1
for (int i = 1; i <= n1; i++) {
int temp = dp[0];
// 相當於初始化
dp[0] = i;
for (int j = 1; j <= n2; j++) {
// pre 相當於之前的 dp[i-1][j-1]
int pre = temp;
temp = dp[j];
// 如果 word1[i] 與 word2[j] 相等。第 i 個字符對應下標是 i-1
if (word1.charAt(i - 1) == word2.charAt(j - 1)){
dp[j] = pre;
}else {
dp[j] = Math.min(Math.min(dp[j - 1], pre), dp[j]) + 1;
}
// 保存要被拋棄的值
}
}
return dp[n2];
}上面的這些題,基本都是不怎麼難的入門題,除了最後一道相對難一點。並且基本 80% 的二維矩陣 dp 都可以像上面的方法一樣優化成 一維矩陣的 dp,核心就是要畫圖,看他們的值依賴,當然,還有很多其他比較難的優化,但是,我遇到的題中,大部分都是我上面這種類型的優化。後面如何遇到其他的,我會作為案例來講,今天就先講最普遍最通用的優化方案。記住,畫二維 dp 的矩陣圖,然後看元素之間的值依賴,然後就可以很清晰着知道該如何優化了。
在之後的文章中,我也會按照這個步驟,在給大家講四五道動態規劃 hard 級別的題,會放在每天推文的第二條給大家學習。如果覺得有收穫,不放三連走起來(點贊、感謝、分享),嘻嘻。
1、點贊,可以讓更多的人看到這篇文章
2、關注我的原創微信公眾號『苦逼的碼農』,第一時間閱讀我的文章,已寫了 150+ 的原創文章。
公眾號後台回復『电子書』,還送你一份电子書大禮包哦。
作者:帥地,一位熱愛、認真寫作的小伙,目前維護原創公眾號:『苦逼的碼農』,已寫了150多篇文章,專註於寫 算法、計算機基礎知識等提升你內功的文章,期待你的關注。
轉載說明:務必註明來源(註明:來源於公眾號:苦逼的碼農, 作者:帥地)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
算法:
- 一個有限指令集
- 接受一些輸入(有些情況下不需要收入)
- 產生輸出
- 一定在有限步驟之後終止
- 每一條指令必須:
- 有充分明確的目標,不可以有歧義
- 計算機能處理的範圍之內
- 描述應不依賴於任何一種計算機語言以及具體的實現手段
其實說白了,算法就是一個計算過程解決問題的方法。我們現在已經知道數據結構表示數據是怎麼存儲的,而“程序=數據結構+算法”,數據結構是靜態的,算法是動態的,它們加起來就是程序。
對算法來說有輸入,有輸出,相當於函數有參數有返回值。我們寫算法的時候習慣把算法封裝到一個函數中。
好,從上面我們知道了什麼是算法,下面我再說什麼是好的算法?
在解決同一個問題的時候,我們通常會有很多種不一樣的算法,區別就在於,有的算法比較笨,有的算法比較聰明,那我們怎麼去衡量它們誰好誰壞呢?我們通常有下面兩個指標:
- 空間複雜度:根據算法寫成的程序在執行時佔用存儲單元的長度。
- 時間複雜度:根據算法寫成的程序在執行時耗費時間的長度。
先舉個例子說,如果讓你打印十個整數,你那個程序可能瞬間就給出結果了,如果讓你打印十萬個整數呢?這你就得多等一會了。所以這個程序運行的時間,就跟你要處理的數據是十個還是十萬個是相關的,這個十或十萬就是我們要處理的數據的規模。我們把它叫做n,是一個變量的話,那我們這個程序所用的時間和空間都跟這個n是有直接關係的。解決一個問題有很多中不同的方法,你在設計這個方法的時候,一定要把這兩個要素考慮清楚。一不小心,如果空間複雜度太大的話,你那個程序就可能直接爆掉了,非正常中斷,我一會會在後面講,時間複雜度如果太大的話,你就可能等很長時間都等不出結果。
先來看上面圖片中的幾組代碼,我是用Python表示的,你在看的時候考慮兩個問題:
- 四組代碼中,哪組的運行時間最短?
- 用什麼方式來體現算法運行的快慢?
剛才說n可以看作數據的規模,規模不一樣,運行時間肯定也不一樣,而且所用時間也不好確定,不同的n會得到不同的時間,所以我們用時間複雜度來表示算法運行的快慢。
先來看下面圖片中的幾個生活中的事件,估計時間:
這裏你會發現我們會用“幾”表示一個大概,後面還有相應的時間單位,那時間複雜度也參照類似的方法:
時間複雜度:用來評估算法運行效率的一個式子
看上面圖片所示,先說print(‘Hello World’),它的時間複雜度表示為O(1),O嚴格來說,它表示數學上一個式子的上界,我們可以簡單的理解為就是一個估計,大約,相當於上面說的“幾”。1可以理解為是個運行單位(類似於秒這樣的單位),為什麼是O(1),因為print(‘Hello World’)只執行了一次,同理分析第二個:
for i in range(n):
print('Hello World')
它的時間複雜度表示為O(n),因為這組代碼執行了n次。n還是個單位,同理,分析第三個:
for i in range(n):
for j in range(n):
print('Hello World')
它的時間複雜度表示為O(),因為是有兩層循環,所以是,還是個單位。第四個你自己就可以分析了,我就不多此一舉了。但千萬不要以為就是這麼簡單,咱再看下面代碼圖片:
看到這個圖片,你是不是感覺很良好,和你猜的差不多是吧,哈哈,不要高興的太早,告訴你們,錯了,它們的時間複雜度不是這樣的。
為什麼?我說了,“1”是單位,但“3”不是單位,3是3乘1,就比如說在生活中,問你一壺水燒多長時間,沒有人回答說是三個幾分鐘或者幾個三分鐘。再說第二個,是單位,n也是個單位,但是比n大,所以我們在估計時用大單位,就好比生活中問你大概睡了多久,你一般說是幾個小時,而不是說幾個小時零幾分鐘,你強調的是一個大概的時間,明白了吧。
所以正確的時間複雜度是這樣的:
第一個為什麼是O(1),首先print(‘Hello World’)打印一次和打印三次實際的影響不大吧,就是不管執行幾次,只要它的規模不上升到n這麼大的時候,換句話說,1是個單位,所以不管怎樣,因為這是表示近似,不是表示精確的,所以是O(1).好,再看下面這個圖片:
當你的循環減半的時候,時間複雜度就會變為O(logn)。所以你可以這樣記,當算法過程出現循環折半的時候,複雜度式子中會出現logn。
- 時間複雜度是用來估計算法運行時間的一個式子(單位)
- 一般來說,時間複雜度高的算法比時間複雜度低的算法慢
在空間複雜度中需要注意的一點就是理解“空間換時間”,在研究一個算法的時候,時間比空間重要。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
目錄
本文介紹Spring的七種事務傳播行為並通過代碼演示下。
事務傳播行為(propagation behavior)指的就是當一個事務方法被另一個事務方法調用時,這個事務方法應該如何運行。
例如:methodA方法調用methodB方法時,methodB是繼續在調用者methodA的事務中運行呢,還是為自己開啟一個新事務運行,這就是由methodB的事務傳播行為決定的。
Spring在TransactionDefinition接口中規定了7種類型的事務傳播行為。事務傳播行為是Spring框架獨有的事務增強特性。這是Spring為我們提供的強大的工具箱,使用事務傳播行為可以為我們的開發工作提供許多便利。
7種事務傳播行為如下:
1.PROPAGATION_REQUIRED
如果當前沒有事務,就創建一個新事務,如果當前存在事務,就加入該事務,這是最常見的選擇,也是Spring默認的事務傳播行為。
2.PROPAGATION_SUPPORTS
支持當前事務,如果當前存在事務,就加入該事務,如果當前不存在事務,就以非事務執行。
3.PROPAGATION_MANDATORY
支持當前事務,如果當前存在事務,就加入該事務,如果當前不存在事務,就拋出異常。
4.PROPAGATION_REQUIRES_NEW
創建新事務,無論當前存不存在事務,都創建新事務。
5.PROPAGATION_NOT_SUPPORTED
以非事務方式執行操作,如果當前存在事務,就把當前事務掛起。
6.PROPAGATION_NEVER
以非事務方式執行,如果當前存在事務,則拋出異常。
7.PROPAGATION_NESTED
如果當前存在事務,則在嵌套事務內執行。如果當前沒有事務,則按REQUIRED屬性執行。
其實這7中我也沒看懂,不過不急,咱們接下來直接看效果。
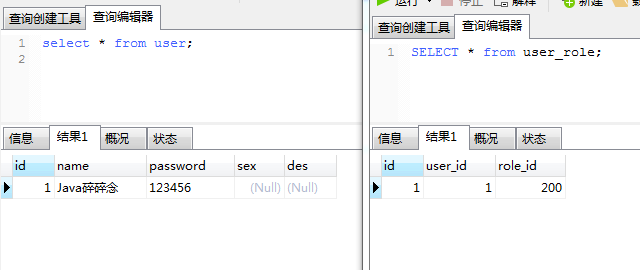
演示前先建兩個表,用戶表和用戶角色表,一開始兩個表裡沒有數據。
需要注意下,為了數據更直觀,每次執行代碼時 先清空下user和user_role表的數據。
user表:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`sex` int(11) DEFAULT NULL,
`des` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;user_role表:
CREATE TABLE `user_role` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`role_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;如果當前沒有事務,就創建一個新事務,如果當前存在事務,就加入該事務,這是最常見的選擇,也是Spring默認的事務傳播行為。
場景一:
此場景外圍方法沒有開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation=Propagation.REQUIRED,然後在測試方法中同時調用兩個方法並在調用結束后拋出異常。
2.主要代碼
外層調用方法代碼:
/**
* 測試 PROPAGATION_REQUIRED
*
* @Author: java_suisui
*/
@Test
void test_PROPAGATION_REQUIRED() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.REQUIRED)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.REQUIRED)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
4.結果分析
外圍方法未開啟事務,插入用戶表和用戶角色表的方法在自己的事務中獨立運行,外圍方法異常不影響內部插入,所以兩條記錄都新增成功。
場景二:
此場景外圍方法開啟事務。
1.主要代碼
測試方法代碼如下:
/**
* 測試 PROPAGATION_REQUIRED
*
* @Author: java_suisui
*/
@Transactional
@Test
void test_PROPAGATION_REQUIRED() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}2.代碼執行后數據庫截圖
兩張表數據都為空,截圖如下:
3.結果分析
外圍方法開啟事務,內部方法加入外圍方法事務,外圍方法回滾,內部方法也要回滾,所以兩個記錄都插入失敗。
結論:以上結果證明在外圍方法開啟事務的情況下Propagation.REQUIRED修飾的內部方法會加入到外圍方法的事務中,所以Propagation.REQUIRED修飾的內部方法和外圍方法均屬於同一事務,只要一個方法回滾,整個事務均回滾。
支持當前事務,如果當前存在事務,就加入該事務,如果當前不存在事務,就以非事務執行。
場景一:
此場景外圍方法沒有開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation=Propagation.SUPPORTS,然後在測試方法中同時調用兩個方法並在調用結束后拋出異常。
2.主要代碼
外層調用方法代碼:
/**
* 測試 PROPAGATION_SUPPORTS
*
* @Author: java_suisui
*/
@Test
void test_PROPAGATION_SUPPORTS() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.SUPPORTS)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.SUPPORTS)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
4.結果分析
外圍方法未開啟事務,插入用戶表和用戶角色表的方法以非事務的方式獨立運行,外圍方法異常不影響內部插入,所以兩條記錄都新增成功。
場景二:
此場景外圍方法開啟事務。
1.主要代碼
test_PROPAGATION_SUPPORTS方法添加註解@Transactional即可。
2.代碼執行后數據庫截圖
兩張表數據都為空,截圖如下:
3.結果分析
外圍方法開啟事務,內部方法加入外圍方法事務,外圍方法回滾,內部方法也要回滾,所以兩個記錄都插入失敗。
結論:以上結果證明在外圍方法開啟事務的情況下Propagation.SUPPORTS修飾的內部方法會加入到外圍方法的事務中,所以Propagation.SUPPORTS修飾的內部方法和外圍方法均屬於同一事務,只要一個方法回滾,整個事務均回滾。
支持當前事務,如果當前存在事務,就加入該事務,如果當前不存在事務,就拋出異常。
通過上面的測試,“支持當前事務,如果當前存在事務,就加入該事務”,這句話已經驗證了,外層添加@Transactional註解后兩條記錄都新增失敗,所以這個傳播行為只測試下外層沒有開始事務的場景。
場景一:
此場景外圍方法沒有開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation = Propagation.MANDATORY,主要代碼如下。
2.主要代碼
外層調用方法代碼:
/**
* 測試 PROPAGATION_MANDATORY
*
* @Author: java_suisui
*/
@Test
void test_PROPAGATION_MANDATORY() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.MANDATORY)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.MANDATORY)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都為空,截圖如下:
4.結果分析
運行日誌如下,可以發現在調用userService.add()時候已經報錯了,所以兩個表都沒有新增數據,驗證了“如果當前不存在事務,就拋出異常”。
at com.example.springboot.mybatisannotation.service.impl.UserServiceImpl$$EnhancerBySpringCGLIB$$50090f18.add(<generated>)
at com.example.springboot.mybatisannotation.SpringBootMybatisAnnotationApplicationTests.test_PROPAGATION_MANDATORY(SpringBootMybatisAnnotationApplicationTests.java:78)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)創建新事務,無論當前存不存在事務,都創建新事務。
這種情況每次都創建事務,所以我們驗證一種情況即可。
場景一:
此場景外圍方法開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation = Propagation.REQUIRES_NEW,主要代碼如下。
2.主要代碼
外層調用方法代碼:
/**
* 測試 REQUIRES_NEW
*
* @Author: java_suisui
*/
@Test
@Transactional
void test_REQUIRES_NEW() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.REQUIRES_NEW)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.REQUIRES_NEW)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
4.結果分析
無論當前存不存在事務,都創建新事務,所以兩個數據新增成功。
以非事務方式執行操作,如果當前存在事務,就把當前事務掛起。
場景一:
此場景外圍方法不開啟事務。
1.驗證方法
兩個實現類UserServiceImpl和UserRoleServiceImpl制定事物傳播行為propagation = Propagation.NOT_SUPPORTED,主要代碼如下。
2.主要代碼
外層調用方法代碼:
/**
* 測試 PROPAGATION_NOT_SUPPORTED
*
* @Author: java_suisui
*/
@Test
void test_PROPAGATION_NOT_SUPPORTED() {
// 增加用戶表
User user = new User();
user.setName("Java碎碎念");
user.setPassword("123456");
userService.add(user);
// 增加用戶角色表
UserRole userRole = new UserRole();
userRole.setUserId(user.getId());
userRole.setRoleId(200);
userRoleService.add(userRole);
//拋異常
throw new RuntimeException();
}UserServiceImpl代碼:
/**
* 增加用戶
*/
@Transactional(propagation = Propagation.NOT_SUPPORTED)
@Override
public int add(User user) {
return userMapper.add(user);
}UserRoleServiceImpl代碼:
/**
* 增加用戶角色
*/
@Transactional(propagation = Propagation.NOT_SUPPORTED)
@Override
public int add(UserRole userRole) {
return userRoleMapper.add(userRole);
}3.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
4.結果分析
以非事務方式執行,所以兩個數據新增成功。
場景二:
此場景外圍方法開啟事務。
1.主要代碼
test_PROPAGATION_NOT_SUPPORTED方法添加註解@Transactional即可。
2.代碼執行后數據庫截圖
兩張表數據都新增成功,截圖如下:
3.結果分析
如果當前存在事務,就把當前事務掛起,相當於以非事務方式執行,所以兩個數據新增成功。
以非事務方式執行,如果當前存在事務,則拋出異常。
上面已經有類似情況,外層沒有事務會以非事務的方式運行,兩個表新增成功;有事務則拋出異常,兩個表都都沒有新增數據。
如果當前存在事務,則在嵌套事務內執行。如果當前沒有事務,則按REQUIRED屬性執行。
上面已經有類似情況,外層沒有事務會以REQUIRED屬性的方式運行,兩個表新增成功;有事務但是用的是一個事務,方法最後拋出了異常導致回滾,兩個表都都沒有新增數據。
到此Spring的7種事務傳播行為已經全部介紹完成了,有問題歡迎留言溝通哦!
完整源碼地址: https://github.com/suisui2019/springboot-study
推薦閱讀
限時領取免費Java相關資料,涵蓋了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo/Kafka、Hadoop、Hbase、Flink等高併發分佈式、大數據、機器學習等技術。
關注下方公眾號即可免費領取:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
摘錄自2019年12月18日中央社報導
珍芳達將在12月21日歡慶82歲生日,17日她在全國記者俱樂部(National Press Club)表示,她曾試圖在2016年美國總統川普當選後,安排包括女星潘蜜拉安德森在內的一群「美麗、性感、傑出」環保人士與川普會面,以說服他對付全球暖化問題。珍芳達(Jane Fonda)曾經跟川普女婿庫許納(Jared Kushner)和女兒伊凡卡(Ivanka Trump)討論她的想法,但並未得到回覆。最終這讓她搬到華盛頓住上幾個月,利用自己的名人力量動員群眾。
珍芳達曾分別以1971年「柳巷芳草」(Klute)與1978年「歸返家園」(Coming Home)兩部作品,摘下奧斯卡影后殊榮。
長年投身社會運動的珍芳達經常參與氣候變遷抗議活動,曾於今年10月在美國國會山莊外被警方逮捕。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
摘錄自2019年12月22日中央社報導
德國社會上最近有聲音認為應該延長核電廠的使用年限,檢討廢核政策;不過,德國政府發言人強調廢核是朝野共識,政府2022年廢核的計畫不變。
執政的基督教民主黨(CDU)能源政策發言人菲佛(Joachim Pfeiffer)18日接受「明鏡」週刊(Der Spiegel)訪問時表示,廢核是錯誤的政策;不過,他強調基民黨團不會主動提案。
對此,德國聯邦環境部發言人費克特納(Nikolai Fichtner)在例行記者會表示,朝野政黨2011年達成共識,解決了核電數十年來在德國社會的爭議性。核電是高風險的科技,興建核電廠的計畫顯示核電成本太高,此外還有核廢料的問題。總之,核電帶給未來世代許多問題,環境部認為廢核共識不應該翻盤。
總理梅克爾(Angela Merkel)的發言人塞柏特(Steffen Seibert)也指出,政府對核電的態度沒變,廢核將照原計畫執行。
德國西南部菲力普斯堡(Philippsburg)的核電廠,由安能亞太EnBW營運。照片來源:
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!